基于langid模型的多語言微博識別研究
2018-10-18 10:33:46郭倩倩
現代計算機 2018年26期
郭倩倩
(新疆大學信息科學與工程學院,烏魯木齊 830046)
語言識別;langid模型;微博
0 引言
計算機技術日益成熟,互聯網的浪潮席卷著地球每一寸土地。越來越多的文化、教育等活動延伸到不同的民族、不同的國家。學者們走出國門參加國際學術會議,不僅是對個人工作的認可,也加速了各國學術技術之間的交流;跨國企業先后在全球范圍內尋求最具優勢的合作伙伴:越來越多的國內人為了感受異域風情從而選擇境外旅游。這些活動使人與人之間的交往更密切,以及促進了科技文化等的共同進步。然而語言之間的難以溝通障礙阻礙著時代的發展。Freeno?de Network的創始人Rober Levin曾說過:The last barri?er for global E-Commerce is the language barrier[1]。如今處在全球化的時代,這句話完全可以擴展到商業以外的各個領域。但值得慶幸的是,計算機技術的迅猛發展,使借助計算機進行自動語言識別的研究一直未離開研究者們的視線[2]。
自動語言識別是許多應用程序中關鍵的一步,但對每個應用程序建立一個定制的解決方案,是非常昂貴的,特別是針對應用領域,人類注釋標記語料庫從而獲得培訓語料。因此,我們需要的是這樣的一種通用的、可用的、現成的語言識別技術的工具。在本文中,我們提出了使用langid模型。langid是一個現有的語言識別工具,被視為有監督的機器學習任務,并極大地受到文本分類研究的影響[3]。同時,langid.py是一個全監督的、基于多項式的樸素貝葉斯分類器。它用共包括97種語言的多場景(domain)的語料對模型進行了訓練,場景包括五類:政府文件、軟件文檔、新聞電訊、在線百科和網絡爬蟲[4]。
但針對本文的多語言微博進行識別分離研究,現有識別工具langid模型并不能直接使用。首先,現有識別工具langid模型語料庫大多是針對比較正式的、長文本數據,并不直接適用于本文的多語言短文本微博數據。為了解決以上問題,本文需要構建適合本文研究的語料庫,并通過反復實驗,訓練出適合本文多語言短文本微博數據識別分離的模型。
1 多語言識別微博語料庫的構建
將微博爬蟲與模擬登錄、網絡爬蟲和Web內容解析相結合,爬取微博信息。根據微博的特點,新浪需要分析微博登錄協議,通過模擬程序登錄到微博瀏覽器獲取用戶登錄信息,獲取種子集,根據采集的URL使用URL調度器進行排序,并按照一定的策略對網頁收集器分配URL。網頁收集器使用GET方法通過HTTP協議收集數據[5]。最后,通過頁面分析提取所獲取的數據。詳細流程圖如圖1所示。
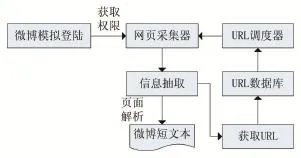
圖1 基于微博爬蟲的信息采集流程圖
本文是手動篩選出多語言微博,并將其作為種子詞,采用自編爬蟲程序爬取更多的微博數據,爬取的微博數據包含:微博正文、點贊數、轉發數、評論數、時間、來源和地點,如下表1所示:
爬取博文步驟具體如下:

表1 保存樣例
(1)模擬登錄,首先獲取客戶端的 cookie,利用cookie進行模擬登錄,用于用戶驗證。
(2)頁面抓取,利用Python中requests庫的get函數,把相應用戶ID的網頁下載到本地。
(3)頁面解析,利用Python中的Beautiful庫提供的函數,對下載到本地的網頁進行網頁元素處理,主要是利用find_all()方法。
(4)在步驟(3)的結果上,利用 Beautiful的find_all('span',class_='ctt')方法,把含有標題的文本取出來。
(5)利用正則表達式和find_all('a',href=re.compile('^http://*'))過濾含有超鏈接的標簽,把點贊數、轉發數,評論數取出來。
(6)同理,利用Beautiful的find_all('span',class_='ct')把發表微博的日期和消息來源取出來。
(7)爬取內容的保存,把爬取到的標題、點贊數、轉發數、評論數、日期和消息來源作為一條完整的數據,寫入到txt文本中保存下來。
(8)接下來,依次爬取該用戶的所有微博頁面的數據,并把這些數據寫入到txt文本中。
(9)依次對所有的用戶ID進行爬取(即對每個用戶ID執行步驟(2)-步驟(8)的操作),并把取得的數據保存到txt文本中。
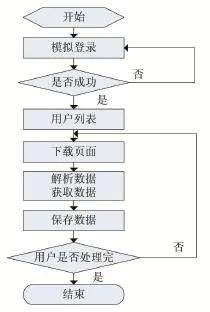
圖2 爬取微博步驟
2 基于langid的短文本多語言識別研究
許多應用程序都能夠從自動語言識別任務上受益。如果人類自動標注語種語料庫來建立一個自動語言識別處理程序從而應用到這些應用領域,那么代價是非常昂貴的。因此,我們急需一個沒有人類標注參與,低配置的這樣一個現成的、可用的語言識別工具。研究表明,在微博方面,現有的語言識別系統中在性能方面表現相當不錯,但針對微博的具體語言識別系統langid似乎做得更好[6]。
2.1 laannggiidd語言識別模型結構
langid.py是基于樸素貝葉斯分類器模型,是一個有監督分類器。langid模型主要包括7個模塊index.py、tokenize.py、DFfeatureselect.py、IGweight.py、LDfea?tureselect.py、scanner.py、NBtrain.py,工具包使用情況如下所示:
(1)準備語料庫,把相應的語料以及與其對應的語言把到規定的文件下,其中每個文本是一個單獨的文件,每個文件放到兩層深的目下,./corpus/domain1/en/File1.txt,通過命令python index.py./corpus來建立相應訓練語料及其語言對。
(2)分別對每種語言的每個文件進行分詞處理,使用的分詞模型是N-Gram,這里的N分別取值是1、2、3、4,經過分詞后形成詞的集合,使用的命令為python tokenize.py corpus.model。
(3)通過采用文檔頻率DF,來選擇特征值,把一些信息貢獻少的詞過濾掉,主要是進行特征值的降維,使用的命令為python DFfeatureselect.py corpus.model。
(4)對選擇的特征值進行權重的賦值,這里使用信息增益來給每個特征值進行賦值,使用命令為python IGweight.py-d corpus.model。
(5)在特征值的權重基礎上,求出每個特征值的LD分數,然后根據LD分數,選擇最終的特征值出來進行訓練樸素貝葉斯分類器,使用的命令為python LD?featureselect.py corpus.model。
(6)通過建立一個掃描器,用來求出每個特征值的詞頻以及貝葉斯分類器的相關參數,使用的命令為py?thon scanner.py corpus.model。
(7)用這些選擇出來的特征值進行貝葉斯分類器的訓練,使用的命令為python NBtrain.py corpus.model。
(8)利用訓練好的貝葉斯分類器進行分類,先導入langid模塊,使用langid.classify方法把帖子中的維吾爾語、音譯維吾爾語、英語以及漢語識別并分離出來。
2.2 laannggiidd模型訓練
基于樸素貝葉斯的langid模型分類器,其工作原理如下:
確定目標函數。使用langid進行語種分類,目的是對于一篇包含n個特征的x1,x2,...xn的文檔D,計算出屬于閉集C中某一分類Ci的概率,并將其分配給最可能的分類[7]。

根據貝葉斯定理:
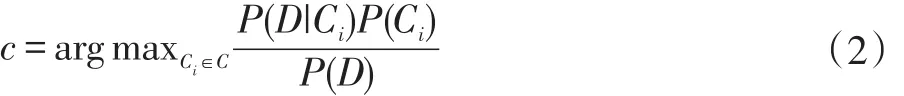
其中P(D)是常數,P(Ci)根據最大似然法得到。為了得到P(D|Ci),假設每一項是條件獨立,即:

ND,ti是ti項在D中出現的頻率。
使用多項式貝葉斯分類模型,將上述問題放在貝葉斯學習框架中建立一個參數模型,使用訓練數據估計出貝葉斯最優的參數模型[8]。設參數為θ,由上式可以得到:

根據訓練數據我們最終可以得到θND,ti|cj的0≤θND,ti|cj≤1最大似然估計值θ∧。
確定目標文檔的分類。根據給定的參數值,我們可以通過計算目標文檔對每個分類后的檢驗概率,并選擇最大概率值作為目標文檔的分類,即:

3 實驗結果及分析
由于微博的短而雜亂以及微博中常含有結構比較相似的音譯維吾爾語和英語,因此本節主要目的是通過langid模型識別漢語、維吾爾語、英語、音譯維吾爾語。本文通過反復實驗發現langid模型語言識別效果主要與以下幾種情況有關:
①訓練語料大小會影響語言的識別效果,語料規模大,會相應的提高語言的識別率;
②當音譯維語和英語比例會影響語言的識別效果;
③訓練文本都是長文本時,對短文本的識別效果不佳;
④增加分組會提高語言的識別效果;
⑤增加域會影響語言的識別效果;
⑥特征的選擇會影響語言的識別效果。
實驗結果表明,因實驗數據全部來源于新浪微博,因而域增加,相應的訓練語料增加,使langid模型提取的特征更能夠較全面地反映出語言的特性,從而直接影響語言的識別效果,如表2所示。

表2 實驗結果與域數
實驗結果表明,英語和音譯維吾爾語訓練語料比例會影響對英語和音譯維吾爾語的識別效果。英語和音譯維吾爾語都是以拉丁字母書寫的一種語言,因結構相似、書寫相似,則langid模型對這兩種語言提取的特征也比較相似,故英語和音譯維吾爾語語料比例會直接影響識別效果。
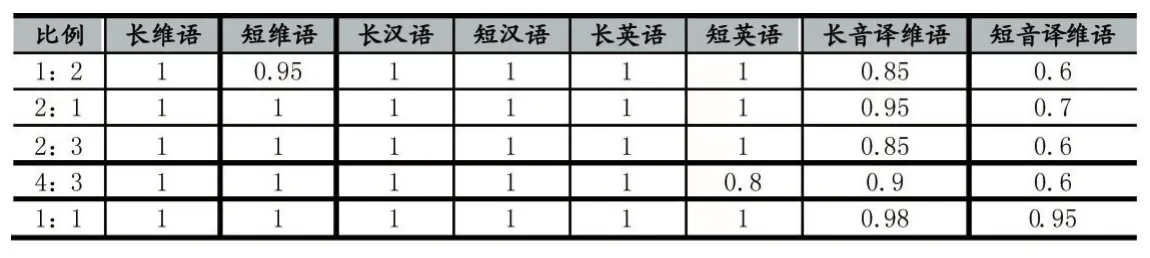
表3 英語和音譯維吾爾語的比例
實驗結果表明,langid模型中訓練語料的長短對長文本、短文本的識別效果有直接影響,如表4所示。相對長文本而言,短文本數據稀疏且雜而亂,直接把比較規范的長文本特征應用到短文本識別方面,不能夠較全面地反映出短文本特性。

表4 實驗結果與訓練文本的長短

表5 實驗結果與分組數
實驗結果表明,預訓練的langid模型在實驗過程中,分組數會影響實驗結果,分組數增加會相應的提高對語言的識別效果,特別是對短文本的識別效果影響較大。因為本模型在每個分組內提取等量的特征,分組越多,每種語言提取的特征數越多,語言的識別率也相應的提高。

表6 實驗結果與特征提取的數量
實驗結果表明,因langid模型對語言的識別依賴于所提取的特征,特征數越多越能夠較全面的反映出特定語言的特性,特征數相對來說對語言的識別效果有直接影響。
結合實驗 1、2、3、4、5,本實驗采用的語料庫是采用自編爬蟲程序爬取來自多語言微博用戶的微博數據,該數據集包含4w條微博樣本(音譯維吾爾語1w,英語1w,漢語1w條,維語1w條)。本文的實驗數據全部來源于多語言用戶發布的新浪微博,以下的domain中數據全部來源于基于多語言用戶發布的新浪微博,本文通過4w條微博樣本進行反復實驗,將實驗結構設計如下效果最好:
domain1(en,yug,zh,ug):每種語言各 2000 條,共8000條
domain2(en,yug,zh,ug):每種語言各 2000 條,共8000條
domain3(en,yug,zh,ug):每種語言各 2000 條,共8000條
domain4(en,yug,zh,ug):每種語言各 2000 條,共8000條
domain5(en,yug,zh,ug):每種語言各 2000 條,共8000條

表7 實驗結果

表8 語言識別模型準確率對比

表9 傳統語言識別工具
傳統的機器學習模型中,相比TextCat模型[9]、CLD模型[10]、LangDetect模型[11],langid 獲得了最優的性能,準確率最低達到了95%。這與基于多項式的樸素貝葉斯分類器模型的訓練目標有關,它追求結構風險最小化。該方法降低了數據規模和數據分布的要求,在小樣本條件下獲得了較好的性能。同時發現對短文本微博維吾爾語和音譯維吾爾語識別率可達100%,對結構比較相似的短文本英語和音譯維吾爾語而言,在識別過程中會相互影響。一方面,音譯維吾爾語和英語都是以拉丁字母書寫的一種語言,結構比較相似,書寫比較相似。另外,音譯維吾爾語和英語在書寫方面,某些單詞通用,例如“man”等,導致提取的特征比較相似,為后期模型訓練埋下了隱患;另一方面,langid模型提取的特征難以反映詞與詞之間的語義關系,使提取的特征無法滿足這種結構相似的語言識別分類。
4 結語
本文根據微博的特點,綜合考慮了影響langid模型識別效果的影響因子,通過反復實驗驗證了langid模型對微博數據的有效性和可行性,同時對結構比較相似、書寫相似的英語和音譯維吾爾語識別效果俱佳。
另外,雖然該方法在維吾爾語和漢語識別準確率為100%。但在英語和音譯維吾爾語識別效果上相對來說較弱一些,未來的工作將考慮在英語和音譯維吾爾語上做進一步的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
