移動云平臺下基于局部復制的結構性文檔協同編輯沖突消解
2018-10-17 12:25:36朱思征高麗萍王山山
小型微型計算機系統 2018年10期
王 丹,朱思征,高麗萍,王山山,徐 燁,史 旻
1(上海理工大學 計算中心,上海 200093)
2(上海理工大學 光電信息與計算機工程學院,上海 200093)
1 引 言
計算機技術的不斷發展,使得人們的日常工作、生活、娛樂方式也隨之發生翻天覆地的變化.辦公地點隨著寬帶、無線網絡的普及,也不再局限于辦公室.近年來,由于各行各業不同領域工作量以及設計規模不斷增大,個人想要獨立完成所有工作往往面臨操作量巨大、用時長等一系列諸多問題.由此計算機支持的協同工作(Computer Supported Cooperative Work,CSCW)技術被提出[1].
實時群組編輯器支持分布在不同區域的用戶同一時刻編輯同一個共享文檔.全復制式架構(full replication architecture)[2-6]中提出在每個協作用戶本地生成副本并對其操作,并將操作類型劃分為本地和遠程兩類,此方法大大提高了本地操作響應速度.而在保證實時協同編輯系統的可用性和準確性[2-6,10-12]方面同時迸發出若干問題,并發控制技術作為攻克這些問題的關鍵技術,一直被更多的研究人員們逐步完善.并發控制技術[10-12]主要包括一致性維護和沖突消解兩部分,一致性維護側重于保證協同站點副本的一致性,沖突消解則是為了能夠在最大程度上滿足多用戶的意愿.最典型的并發控制算法主要有操作轉換算法(Operation Transformation,OT)[13]和地址空間轉換算法(Address Space Transformation,AST)[6].
基于全復制式架構研究的沖突消解算法與開發的協同編輯應用不勝枚舉,其研究成果已相對成熟.但隨著移動設備的快速發展,大量編輯器若想要被移植到移動端,將面臨存儲空間小,內存有限等一系列的問題,最終導致之前研發的實時群組編輯器無法完全的適用于移動設備.而之前的研究成果多是基于全復制式架構的主要原因,是協同編輯的對象多為普通的線性文檔,層次結構較為模糊.但在現實生活或工作中,結構性文檔的使用率相對更高,例如常見的申請專利或軟件著作權等書面材料,具有規定的模板結構;撰寫不同的專著、書籍同樣存在各自的參照模板結構;如果可以將此種具有結構的文檔,按照層次級別、關聯關系進行分類,讓協同編輯者可以各取所需,將在很大程度上提升用戶效率并節省存儲空間.Huanhuan Xia[7]等人提出了局部復制式架構(partial replication architecture),并基于此復制式架構研發了適用于移動端的評論系統,為結構性文檔協同編輯領域的研究奠定了基礎.
計算能力較弱,是移動設備的又一個嚴重缺陷,隨著編輯工作量的增大,協同用戶的增多,即使使用普通的服務器也很難處理龐大的操作集.因此,近年來發展迅猛的云服務器技術成為了解決此問題的關鍵.云服務器又稱為云主機,在架構上與傳統的服務器又很大區別,它能夠接收龐大的數據輸入量[8],高效處理海量數據集[9],并基于集群服務器技術,虛擬出多個獨立服務器部分,其具備的故障自動遷移和快照備份功能,大大提升了存儲安全性.
本文的結構如下:首先對局部復制基本思想進行簡要介紹,針對本文提出的算法給出文檔結構、節點、操作、沖突類型等基本定義;隨后詳細介紹移動云平臺下基于局部復制的結構性文檔協同編輯沖突消解算法,針對不同的沖突類型,給出不同的消解過程;其次是對本文提出的算法進行效率分析,將算法與實例相結合,驗證其準確性;最后提出后續的主要研究內容.
2 相關工作
1989年,Eliis 等人[13]首次提出操作轉換概念,并建立OT[13]算法基本模型,其中提出的dOPT(distributed Operational Transformation)作為第一個基于OT的算法被運用到Grove協同編輯系統中.然而,dOPT在某些場景下協同站點間結果會出現不一致的問題,被Ressel[14]等人發現.一致性維護技術的研究成為協同工作中的熱門問題.1998年 Sun在早期的一致性模型基礎之上提出了CCI(Convergence Causality Intention)[15]模型,指出更為嚴格的一致性標準——意愿維護,即沖突消解策略側重解決的問題,由此,并發控制技術的研究得以完善.圍繞該一致性模型,一系列基于OT的樂觀并發控制技術被提出,如GOTO[15]、COT[10]、SCOT4[16]、LBT[17]、TIBOT[18]、ABST[11]等.由于OT的操作轉換規則較為復雜,準確性證明比較困難,執行效率較低.一種基于地址空間轉換的一致性維護技術AST被提出,對比OT,AST算法效率更高,并被證明可以準確解決已有的并發控制問題.近年來,OT和AST技術被廣泛運用到實時群組編輯領域[23],并研發出諸多協同應用,例如 SketchPad、Co-CAD[19,20]、Co-eclipse[21]等.但這些研究目前只能夠適用于桌面協同應用系統,很難將其平移到移動設備上使用,其中最主要的問題在于移動設備存儲空間有限,計算能力較弱,且之前的研究成果多是基于全復制式結構,致使移動設備很難應對數據量擴張,操作數上漲的情況.面臨此困境,Huanhuan Xia[7]等人在2014年提出了適用于移動端的評論系統,并在考慮移動設備內存限制以及網速較差的前提下,提出了局部復制式架構,利用評論節點存儲用戶請求的詳細內容,根據部分復制規則生成骨干節點從而生成本地局部副本,相比全復制式架構,大大節約了存儲本地副本的空間,節省了副本更新的時間.2016年,Sun等人提出了CSOT[22](Cloud storage Operational Transformation)算法,能夠支持在云存儲下實時文件同步功能,并維護一致性,實現理想的并發操作效果合并.CSOT算法首次將OT的一致性維護能力擴展到云存儲共享空間中,并為基于云的協同技術發展做出了巨大貢獻.
然而,CSOT算法的操作粒度為文件,粒度較大,對于文件內容的更改,也只局限于對內容的整體更新覆蓋.且在之前的并發技術研究中多是基于全復制式架構,考慮到移動設備的存儲空間和計算能力的限制,本文基于局部復制策略的基本思想,將控制算法部署在云服務器下,提出一種適用于移動終端的結構性文檔協同編輯沖突消解算法,簡稱為MCPS算法.
3 準備工作
3.1 局部復制方法回顧
局部復制策略是一種適用于移動評論系統,為了解決移動設備資源有限、評論的突發性等問題,利用樹形結構存儲請求數據,并基于地址空間轉換算法研發的高效一致性維護算法.
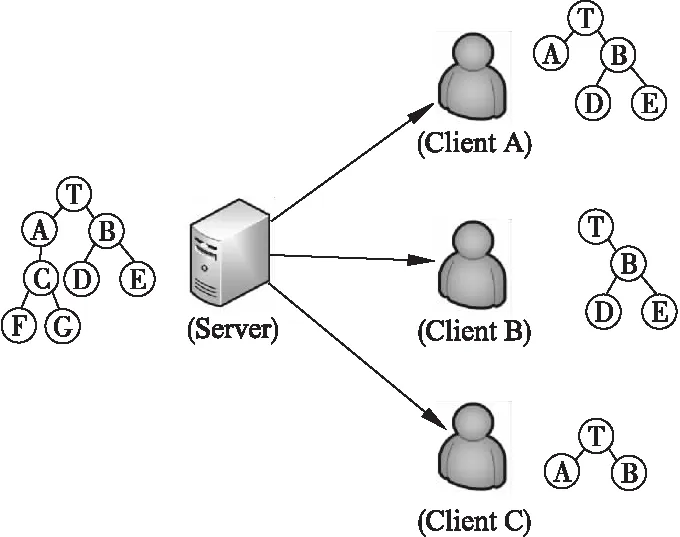
圖1 局部復制原理圖Fig.1 Principle of partial replication architecture
如圖1所示,中央服務器負責維護評論會話的主副本(Primary copy),各個協作客戶端維持本地副本,稱為部分副本.當有新用戶加入并向服務器請求評論內容時,請求的評論將通過操作的形式返回,而返回的數據在客戶端以節點構成的“骨架樹(skeleton tree)”結構存在.通過“釋放”骨架樹中的數據構建部分副本,同時將本地副本通過SYNC請求與主副本同步.對于同步過程中創建、插入、刪除和更新等操作產生的沖突,該策略采用地址空間轉換技術解決,給出具體執行規則,并實現數據的一致性維護.
需要強調的是,當以增量的形式構建本地部分副本時,需遵循如下規則:“如果一個評論節點被復制,該節點的父親節點(如果存在)也必須被復制”.為了區分同步節點類型為請求同步還是自動同步,Huanhuan Xia等人將骨架樹種的節點大致分為三種:評論節點(comment node),即客戶端請求的節點,包含評論內容數據;骨架父節點(skeleton parent node),作為請求節點的未被請求的父節點,自動同步到骨架樹中,但不包含評論數據;骨架葉節點(skeleton leaf node):作為請求節點的未被請求的兄弟節點,為在客戶端副本保持一致的節點兄弟關系而自動同步到骨架樹種的節點,同樣不包含評論數據.
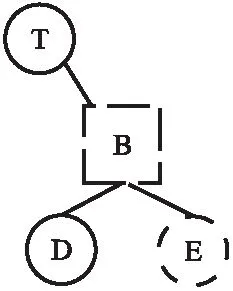
圖2 骨架樹示例圖Fig.2 Example of skeleton tree
舉例說明,如圖2中的用戶B,當其加入到協同評論會話中時,本地的初始部分副本為空,首先發出一條FETCH請求,請求的評論節點集為{T,D },在生成骨架樹時,檢測節點D擁有父節點B,此時將自動同步節點B到骨架樹中,并標記為骨架父節點,且D有一個兄弟節點為E,則標記為骨架葉節點.“執行”骨架樹構建本地部分副本時,部分副本中只包含評論節點中的數據.
3.2 基本定義
3.2.1 文檔結構定義

圖3 等級標題結構文檔Fig.3 Structured document
如圖3所示是一個具有等級標題結構的文檔,我們將此類型的文檔抽象,通過樹結構存儲在云服務器端,即以DOC為主根節點(主副本為空時,首先分配一個id=0 的DOC虛根節點,用來維護主副本樹結構的完整性),按照標題等級構建主副本樹——StrTree,我們將圖3中的文檔構建成StrTree的結果如圖4所示.
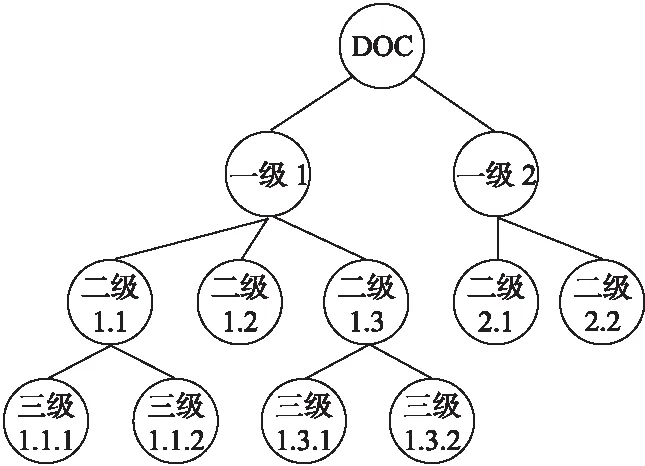
圖4 StrTree示例圖Fig.4 An example of strtree
而客戶端通過請求節點在本地生成的部分副本,可以視為StrTree中的一個子樹.子樹中包含三種節點:
標題節點(TN:Title-Node):客戶端請求節點;
結構父節點(SPN:Str-Parent-Node):客戶端請求節點的父節點,且未被請求,為了維護副本樹結構復制在客戶端但不包含文本內容;
結構兄弟節點(SBN:Str-Brother-Node):客戶端請求節點的兄弟節點,且未被請求,為了維護副本樹結構復制在客戶端但不包含文本內容.
增量式構建本地副本遵循的規則參照文章3.1的介紹.子樹中的節點類型,會在客戶端每次向云服務器請求數據后進行更新.
3.2.2 節點屬性定義
對于StrTree中的每個節點,我們給出以下定義和若干屬性:
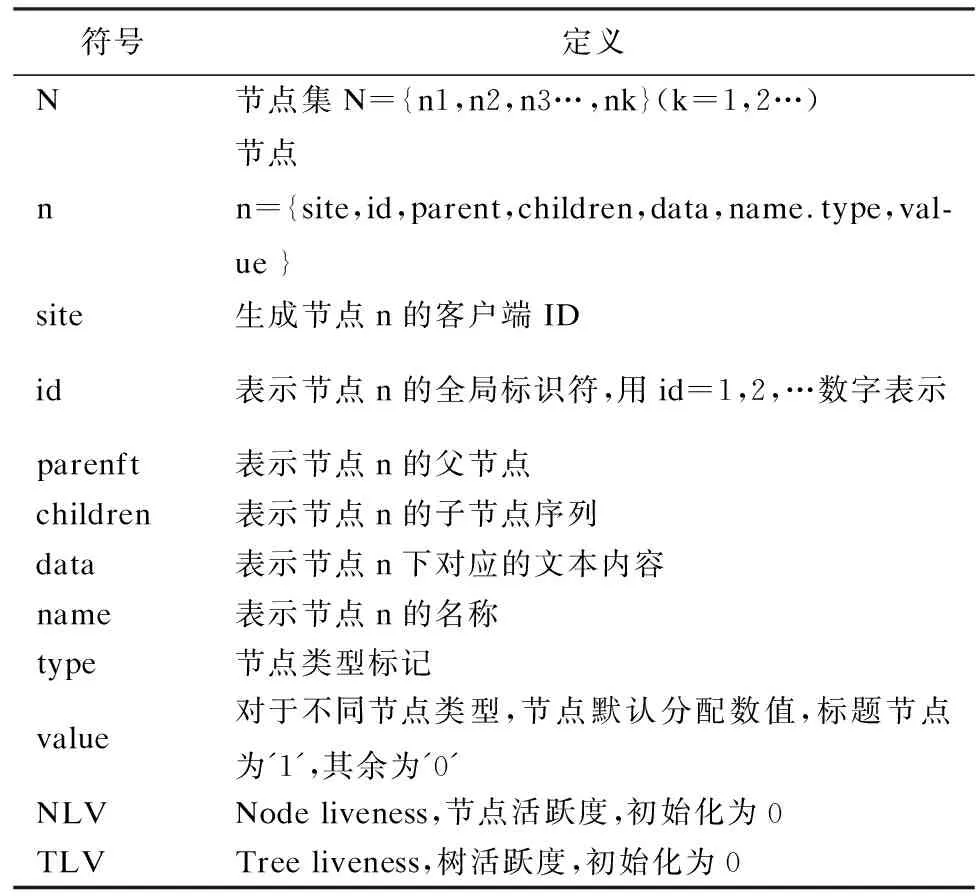
表1 節點和屬性定義Table 1 Definition of node and basic parameters
這里我們提出了活躍度概念,是為了能更大程度上維護用戶的操作意愿,當在協同操作的過程中產生沖突時,解決方式不再局限于判定時間戳、用戶優先級等因素,而是通過云服務器動態更新各個客戶端在每個節點和每棵子樹的活躍度,以活躍度越高,越優先執行為原則,決定操作的執行先后順序.
3.2.3 操作定義
1)Append(N):增量獲取節點集N的數據,請求和執行方式與文章[7]中類似;
2)Insert(parentId,id,site,data):在父節點parentId的子節點后,插入一個新節點;
3)InsertBefore(parentId,refId,id,site,data):創建一個標識符和文本內容為id和data的新節點,并插入到標識符為parentId父節點下子節點隊列中的refId節點前;
4)Delete(id,site):刪除標識符為id的節點;
5)UpdateName(id,newName,oldName,site):更新標識符為id的節點的標題名稱為newName,并記錄之前的名稱oldName;
6)UpdateData(id,data,site):更新標識符為id的節點下的文本內容為data;
3.3 沖突類型
針對上方提出的4種以標題為粒度的操作,1種以標題內文本內容為粒度的操作,我們分析得出了以下5類沖突情況.
CIB:InsertBefore()_InsertBefore(),當云服務器接收兩個指定插入位置的節點插入操作,它們指向同一個父節點,且refId值相同時,操作在客戶端的執行順序不同,將產生不一致結果;
CII:Insert()_Insert(),與CIB的沖突情況類似,插入標題操作在客戶端的執行順序不同,產生的結果不同;
CD:Delete(),當客戶端想要執行一個刪除標題操作時,需先向云服務器發送刪除請求,云服務器判定沒有客戶端在編輯以該節點為根節點的樹后,同意刪除請求,否則駁回;
CDI:Delete()_InsertBefore(),當一個刪除操作被允許,云服務器同時接收一個InsertBefore操作,與被刪除節點父節點相同,且被刪除節點的refId與插入操作的refId相同,操作的執行順序將影響客戶端結果;
CUN:UpdateName()_UpdateName(),當兩個操作同時更改同一個節點的名稱時,客戶端操作執行順序不同結果不同;
CUD:UpdateData()_UpdateData(),與CUN類似,兩個操作都欲更改同一個節點的文本內容時,客戶端操作順序不同將產生沖突.
4 MCPS算法設計
4.1 主副本更新監聽器
為了記錄客戶端活躍度,判斷執行操作的優先級,我們在云服務器開辟空間賦予CL(Cloud Listener),作為記錄主副本變更的操作緩沖區,CL[n]表示節點n變更的操作緩沖區,CL[n]的結構為響應式增加site列的一張表(因為接下來要根據每個節點對應site的緩沖區大小計算對應客戶端在該節點的活躍度即節點活躍度NLV,以及以該節點為根節點的樹,樹中所有節點對應site的緩沖區大小的累加值判斷對應客戶端在對這棵樹的活躍度TLV),需要強調的是,為了保存所有節點的活躍度,當一個節點被刪除,它在CL中依然存在,并且CL的更新不會影響StrTree.
過程1.priCopyListener(operation O)
1. Site = O.site;
2. IF(O.type == “Create”){
3. NEW node CL[n];
4. n.id = O.id;
5. IF(O.type == “Insert”){
6. n→parentId = O→parentId;
7. }
8. ELSE IF(O.type == “InsertBefore”){
9. n→parentId = O→parentId;
10. n→refId = O→refId;
11. }
12. Add CL[n].Site into CL[n];
13. }
14. ELSE{
15. SEARCH n WITCH n.id == O.id;
16. IF(CL[n].Site not exists){
17. Add CL[n].Site into CL[n];
18. }
19. }
20. Append(O)into CL[n].site;
21. n.NLV[site]= n.NLV[site]+ 1;
22. n.TLV[site]= n.TLV[site]+ 1;
23. NEW node p = n;
24. DO WHILE(p→parentId != 0)
25. {
26. childTLV[site]= p.TLV[site];
27. p.id = p→parentId;
28. p.TLV[site]= p.TLV[site]+ childTLV[site];
29. }
4.2 控制算法
云服務器根據操作類型和操作中的節點屬性,判斷執行以下哪種沖突消解算法.
過程2.ControllAlgorithm(O1,O2)
1. IF ( O1.type==O2.type==InsertBefore
and O1.refId==O2.refId )
2. { return resolution_CIB(O1,O2); }
3. IF( O1.type==O2.type==Insert
and O1.parentId==O2.parentId )
4. { return resolution_CII(O1,O2); }
5. IF(O1.type==Del or O2.type==Del)
6. { return resolution_CD(O1,O2); }
7. IF((O1.type==Del and O2.type==InserBefore)‖
8. (O1.type==InsertBefore and O2.type==Del))
9. { return resolution_CDI(O1,O2); }
10. IF (O1.type==O2.type==UpdateName
and O1.id==O2.id)
11. { return resolution_CUN(O1,O2); }
12. IF (O1.type==O2.type==UpdateData
and O1.id==O2.id)
13. { return resolution_CUD(O1,O2); }
4.3 CIB消解過程
當云服務器端接受到來自不同客戶端的InsertBefore操作,并檢測到出現CIB沖突時,云服務器端需要通過判斷生成插入操作的站點在此節點的樹活躍度TLV,以及請求客戶端傳送插入節點對應父節點和兄弟節點的類型,并以節點類型為標題節點的客戶端優先;節點類型相同時,對應站點在該節點父節點的的樹活躍度越高,操作執行的優先級越高,其它插入操作的位置將進行適當調整,并將結果反饋給客戶端.具體處理流程參照算法1,Oa和Ob操作分別插入兩個節點na和nb.
算法1.resolution_CIB(Oa,Ob)
1. REQUEST Node and Node Type From Clients
2. Pa = na→parentId; Pb = nb→parentId;
3. Ra = na→refId; Rb = nb→refId;
4. IF(Pa.type==Pb.type&&Ra.type==Rb.type){
5. GET CL[P]from Listener CL WITCH P.id==Pa.id;
6. IF(TLV[P].sitea>=TLV[P].siteb){
7. nb.refId=na.id;
8. }
9. ELSE{
10. na.refId=na.id;}
11. }
12. IF((Pa.value+Ra.value)>(Pb.value+Rb.value)){
13. nb.refId=na.id;
14. }
15. IF((Pa.value+Ra.value)<(Pb.value+Rb.value)){
16. na.refId=na.id;
17. }
18. POST Oa,Ob to Sitea,Siteb;
沖突類型CII的消解過程與CIB同理,這里我們不再贅述.
4.4 CD消解過程
當客戶端想要執行一個刪除操作時,首先需向云服務器發送刪除節點請求,若此時存在操作將要作用于以該節點為根節點的樹,或刪除節點在客戶端部分副本中不屬于標題節點,刪除操作被駁回.具體處理流程參照算法2.
算法2.resolution_CD(Del(na),O(nb))
1. IF(na.type==TN){
2. IF(na.deep<=nb.deep)//刪除節點na是nb的祖先
3. {//由nb向上遞歸尋找父節點是否存在na
4. P=nb;
5. bool=false;
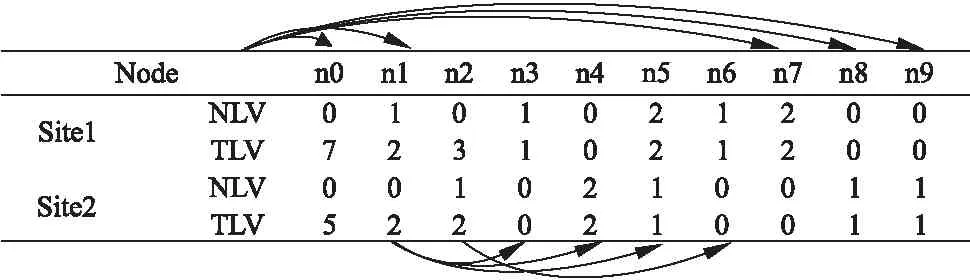
6. DO WHILE(P.deep 7. P=P→parentId; 8. IF(P.id==na.id){ 9. BREAK; 10. bool=true;} 11. } 12. IF(bool==true){ 13. POST CANCLE Del to Sitea; } 14. ELSE{ 15. EXCUTE Del ON the SERVER; 16. POST EXCUTE Del to Sitea; } 17. } 18. ELSE{ 19. EXCUTE Del ON the SERVER; 20. POST EXCUTE Del to Sitea; 21. } 22. } 23. ELSE { POST CANCLE Del to Sitea; } 當一個刪除節點操作被允許,且是另一個插入節點的兄弟節點,位置依賴于刪除節點,為了保證插入位置的準確性,需要根據刪除節點位置確認插入節點位置. 算法3.resolution_CDI(Del(na),InsertBefore(nb)) 1. IF(na→parentId==nb→parentId&&na.id==nb.refId){ 2. SELECT nodes in order WHITCH id=na→parentId as set N; 3. IF(N[k].id==na.id) 4. { Addr = k; } 5. nb.refId = N[k+1].id; 6. } 7. POST InsertBefore′(nb)to remote clients; 當存在若干操作都欲更改同一個節點的名稱時,云服務器需要做出判斷,采取哪個操作的結果,此時首先判斷節點在發出更改操作客戶端的類型,與CIB處理方式類似,類型為標題節點的操作優先,不同的是,若節點類型相同,對比站點在該節點的節點活躍度NLV,優先執行NLV高的站點發出的更改操作. 算法4.resolution_CUN(O1,O2) 1. REQUEST Node and Node Type From Clients 2. O1=UpdateName(n1,Name1,oldname,site1); 3. O2=UpdateName(n2,Name2,oldname,site2); 4. IF(n1.type==n2.type){ 5. GET CL[P]from Listener CL WITCH P.id==n1.id; 6. IF(NLV[P].site1>=NLV[P].site2){ 7. EXCUTE O1; 8. POST EXCUTE O1 to site2; } 9. ELSE{ 10. EXCUTE O2; 11. POST EXCUTE O2 to site1; } 12. } 13. IF(n1.value > n2.value){ 14. EXCUTE O1; 15. POST EXCUTE O1 to site2; } 16. IF(n1.value < n2.value){ 17. EXCUTE O2; 18. POST EXCUTE O2 to site1; } 沖突類型CUD的消解過程與CUN同理. 本文提出的MCPS算法部署在云服務器端,處理進程分為兩部分:動態更新各節點對應的的節點活躍度和樹活躍度;檢測沖突類型并消解沖突. 動態更新節點活躍度階段,首先通過操作攜帶節點n的屬性遍歷Cloud Listener查找是否存在該節點信息,不存在則插入該節點;隨后根據操作的生成站點id找到在CL[n]中對應的活躍度,先改變節點活躍度,再向上回溯更新它的祖先節點的活躍度,我們假設最糟糕的情況,查找到樹中的最后一個節點才找到節點n,并要再向上回溯一次,N為樹包含的節點總數,H為樹的高度,則此過程所需的時間復雜度為O(N·H). 本文提出的六種沖突消解情況中,其核心首先時查找節點n,隨后查找CL[n]中相關站點活躍度,最后插入節點或更改節點信息,可以簡單理解為一個雙重遍歷的過程,假設找到節點n遍歷過的節點個數為N,相關站點活躍度在CL[n]中存儲位置最大的為L,則時間復雜度可以表示為:O(N·L).整個并發控制過程的最壞時間復雜度可以抽象為O(N2). 關于空間復雜度,因為將算法部署在云服務器,且加入的節點監聽功能,并利用樹結構存儲主副本與監聽緩存,假設主副本中包含的節點總數為N,那么對應的空間復雜度至少是O(2N),但對于移動客戶端來說,空間復雜度將是一個小于或遠小于O(N)的值. 如圖5所示,服務器端此時的主副本內容為圖5(a)中結構樹中的所有節點,當前的CL中各節點的活躍度如表2所示,表中的n0代表根節點DOC.有兩個協同用戶site1和site2參與編輯工作,并產生接下來的操作: 圖5 主副本沖突消解結果Fig.5 Result of conflict resolution of primary copy 1)site1:Append(N1),N1={n1,n2}; site2:Append(N2),N2={n2,n4,n5,n6}; 各自生成的部分副本子樹如圖6(a)和圖6(d). 2)site1:O1=InsertBefore(DOC,n2,n7,site1,data); site2:O2=InsertBefore(DOC,n2,n8,site2,data); 表2 CL初始活躍度參照表Table 2 Reference of CL liveness initialization 執行Resolution_CIB(O1,O2)處理進程,兩個協作客戶端都欲在n2前插入一個新標題節點,首先判斷DOC和n2節點在兩站點被復制的類型,均為標題節點,接下來判斷兩站點在他們欲插入節點的父節點DOC的樹活躍度: CL(DOC).TLV[site1]=5; CL(DOC).TLV[site2]=3; CL(DOC).TLV[site1]> CL(DOC).TLV[site2] 樹活躍度越高,操作執行優先級越高,所以先執行site1站點的插入操作,將O2操作轉換為O2′= InsertBefore(DOC,n7,n8,site2,data),發送到站點1執行;O1操作不變發送到站點2執行.生成的結果如圖6(b)和圖6(e).CL中加入兩個節點的信息,并更新site1和site2的活躍度. 3)site1:O3=Del(n1,site1); site2:O4=UpdateData(n4,data,site2); 執行Resolution_CD(O3,O4),site1發送刪除請求至云服務器,同時接收到來自site2的操作O4,首先判斷n1在site1的節點類型為標題節點,再判斷n4的祖先節點中是否包含節點n1,因為n1是n4的父節點,所以刪除操作被駁回,云服務器向site1發送O3操作取消指令和操作O4,同時更新site2的活躍度. 4)site1:O5=Del(n7,site1); site2:O6=InsertBefore(DOC,n7,n9,site2,data); 執行Resolution_CDI(O5,O6),O5是被允許之心的刪除操作,n7.id等于O6.refId,所以優先執行O6,兩站點部分副本更新后結構如圖6(c)和圖6(f).同時更新CL中對應的活躍度數值. 圖6中兩個站點最后生成的部分副本(圖6(c)和圖6(f)所示)中重疊的部分結構一致,證明了沖突消解算法的準確性;最后更新的CL中各節點的站點活躍度為表3中的數據. 隨著移動網絡逐步健全,移動設備迅猛發展,以及其具備的便攜、對地理位置無約束特性使得人們更傾向于在移動終端上進行辦公,移動網絡環境下的協同研究及應用開發將成為未來科技發展的大趨勢.但移動設備的存儲和計算能力較弱,導致之前的協同研究成果不能完全適用于移動端.為了解決此問題,本文基于局部復制策略,提出了一種支持結構性文檔協同編輯的沖突消解算法,并引入了云平臺作為操作中轉站,利用云平臺強大的計算能力,解決協同過程中出現的各種沖突.創新的提出了用戶活躍度這一概念,在最大程度滿足多用戶的意愿方面,不再僅僅依賴于判斷客戶端優先級、時間戳等手段,而是動態更新所有用戶的活躍度,更合理的判斷操作執行優先級. 后續的研究工作包括:1)優化算法執行效率,完善沖突類型; 圖6 site1和site2部分副本沖突消解結果Fig.6 Result of conflicts resolution of site1 and site2 表3 CL更新后的活躍度參照表Table 3 Reference of CL liveness after updating 2)將MCPS算法實現在云平臺與移動設備上,開發一款結構性文檔系統編輯APP;3)在應用中引入圖像[24-26]、表格、文字附加屬性等協同操作功能.4.5 CDI消解過程
4.6 CUN消解過程
5 復雜度分析
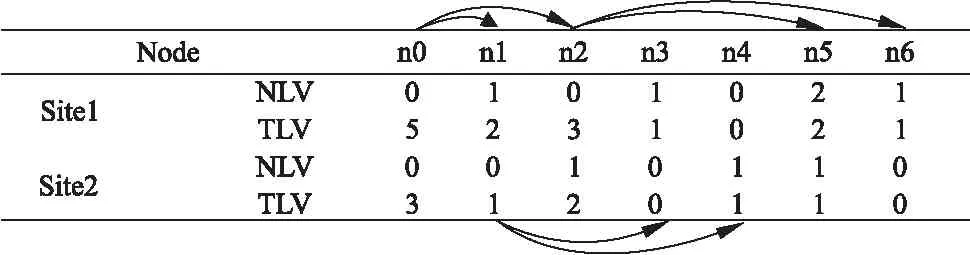
6 算法實現舉例

7 總結及展望