中國人口預測結果檢驗及影響因素比較
2018-10-09 05:53:40石人炳
統計與決策 2018年17期
石人炳,陳 寧
(華中科技大學 社會學院,武漢 430074)
0 引言
人口預測是依據人口發展內在規律對未來人口圖像的描繪。在計劃生育政策醞釀之初,人口預測就致力于為有計劃的人口控制提供科學依據[1]。發展至今,人口預測不僅應用于人口領域,在社會保障、教育以及城市規劃等方面都被廣泛運用。這一方面說明人口預測在社會經濟決策獲取最優方案中有著重要作用;另一方面,這對人口預測結果的精度也提出了更高的要求。因為預測精度不僅關系到對未來人口態勢的科學研判,也關系到對經濟、社會可持續發展的合理規劃。
過去的二三十年里,各類機構和學者們進行了大量的人口預測研究。根據研究目標判斷以往研究主要集中在兩個方面:一是專門預測未來的人口數量趨勢和結構變動,二是考察人口變動對經濟、社會各領域的影響;同時過往研究也呈現出兩個明顯的特征:一是“重結果預測,輕結果檢驗”,二是“重未來描述,輕過往總結”。可以說人們往往只關注人口預測的結果,而結合人口發展實際對過往人口預測結果的精度進行檢驗的研究卻往往被學界所忽視。其實,過往的人口預測研究中,不同學者和機構對預測過程的處理存在很大的差異,而且呈現出的預測數字之間也是矛盾重重。
那么過往人口預測結果精度究竟如何?哪些因素影響了預測結果的精度?從應用價值上來講,如果人口預測結果的精度得不到有效保證,對相關決策所起到的作用將不是參考而是誤導;從學術研究角度來講,當前學術界尚沒有學者做這項工作,而通過對人口預測過程進行回顧分析,將對推進人口預測研究具有一定的理論價值。基于此,從學術的嚴謹性角度出發,對過往人口預測結果的精度進行梳理、檢驗,有效考察人口預測結果出現偏差的緣由,進而為我國今后的人口預測工作提供借鑒,無疑具有重要的理論和現實意義。
1 預測結果檢驗
過往人口預測研究數量眾多,為確保文獻選擇的權威性,本文設定如下挑選原則:一是選擇有影響的學者、機構發表的人口預測類文章或專著;二是為能夠和已經發生的人口統計結果進行比較,將選擇的預測研究年份限定在2010年以前;三是選擇全國性、中長期和數量型預測為主的研究。此外,鑒于預測研究一般將中方案設為最優方案,故呈現的預測結果為中方案結果。同時,從中按照1980年代、1990年代、2000年代三個時期,抽取8篇[2-9]具有代表性的成果進行深度研究,本文稱之為研究樣本。為了衡量研究樣本的預測效果,本文構造“誤差率”這一指標來測量。鑒于2020年及以后的人口事件尚未發生,將結果檢驗分成兩個部分:一是用“絕對誤差率”測量2015年以前的預測結果與實際統計結果的差異;二是用“相對誤差率”測量2015年以后各類預測結果之間的差異。
絕對誤差率:用實際統計結果衡量絕對誤差率。即同一時點預測結果與實際統計結果之差,然后和實際統計結果之比。用P表示人口實際統計結果,用V表示人口預測結果,用e表示絕對誤差率。用公式可以表示為:
相對誤差率:為便于計算,本文選擇用樣本預測結果的平均值代替2020年及以后的實際統計結果,來衡量相對誤差率,用e′來表示。計算方法同上。由于絕對誤差率和相對誤差率的分母并不一致,所以二者并不具有比較意義,只能反映二者所在時期的結果差異。
表1提供了1990—2015年部分年度《中國統計年鑒》中公布的我國人口發展實際數量,以及人口預測的結果比較和根據上述公式所計算的絕對誤差率和相對誤差率。
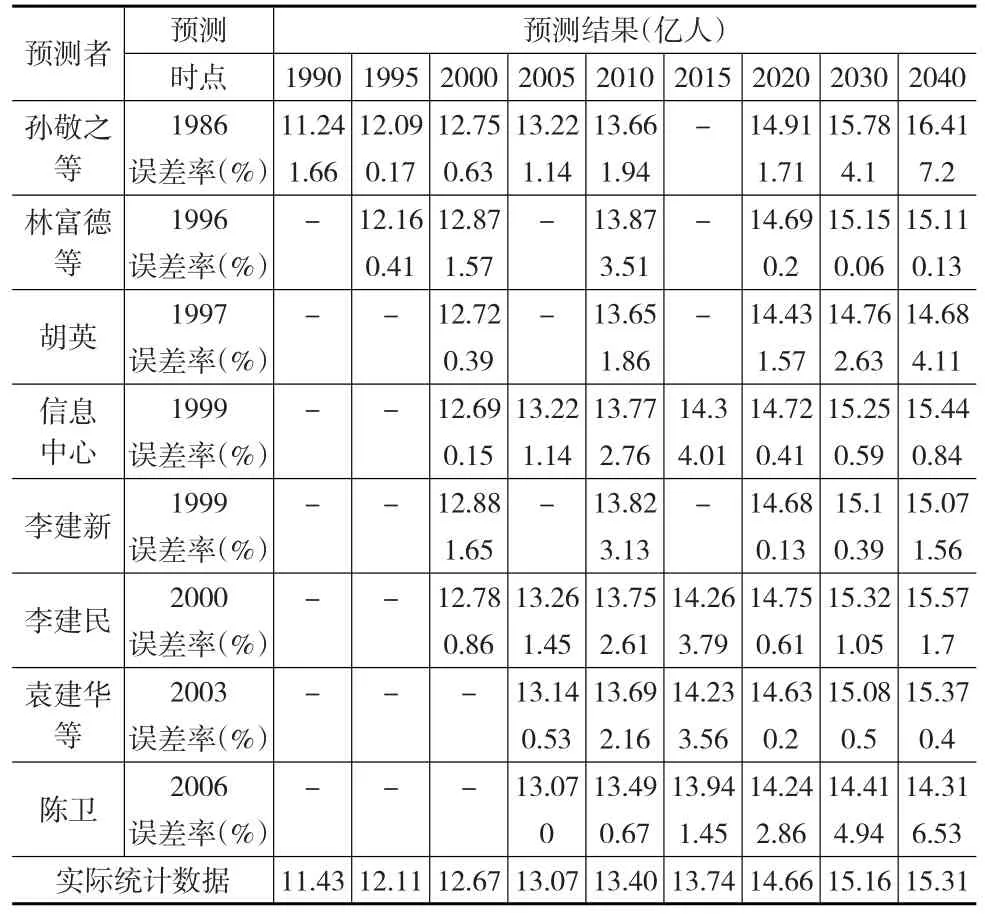
表1 不同來源的人口預測數量與人口實際統計數量以及誤差率比較
從結果比較來看,可以發現:(1)不同來源的人口預測數量與人口實際統計數量存在差異,有的預測結果貼近實際統計結果,而有的預測結果則與統計結果相差較大;(2)不同人口預測結果之間存在明顯差異,而且有的預測結果之間的絕對數量相差很大;(3)人口預測結果基本都大于實際統計結果,而且隨著時間推移二者差距越大。
從誤差率比較來看,不難看出如下特征:(1)人口預測結果精度存在一定的差異,有的預測絕對誤差率較小,而有的預測絕對誤差率則相對較大;(2)人口預測結果的絕對誤差率基本都隨著時間推移而逐漸擴大;(3)2020年及以后人口預測結果的相對誤差率存在明顯差異。
通過檢驗,發現針對同一個預測總體(中國),并不是所有預測都貼近人口發展實際。同時,不同預測結果之間也存在很大差異。那么是什么原因造成這些現象呢?理論上而言,在人口預測過程中,主要面臨的三大難題就是基礎數據是否完備、參數設定是否符合規律預測以及模型選擇是否恰當。這三者是直接影響人口預測結果是否符合客觀實際的關鍵因素。本文將圍繞影響人口預測結果精度的這幾大關鍵要素作進一步分析。
2 基礎數據的使用與問題
基礎數據是人口預測的基礎,其質量的高低直接影響到預測的精度。現有經常被使用的數據包括人口普查數據、1%人口抽樣調查數據、統計年鑒數據等。在人口預測中,對基礎數據的處理經常存在一定的差異(見表2)。可見,對“三普”和“四普”數據,由于自身漏報率較低,學者們在使用時基本沒有調整。而對“五普”數據,由于存在較高的漏報率,學者們在使用時有的則會進行評估和調整,當然也有學者直接使用。
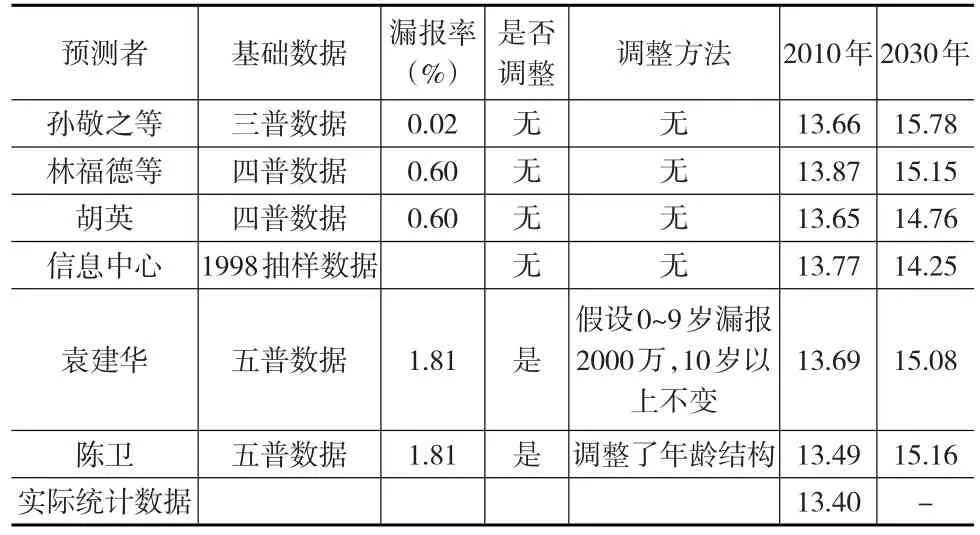
表2 不同人口預測中基礎數據的來源、處理以及部分年份結果比較
從表2可以看到基礎數據不同,預測結果存在明顯差異,即使同一基礎數據所得到的預測結果也存在一定的差異。對于基礎數據的使用與處理,存在兩個方面的問題:
第一,漏報人口的總量與年齡、性別分布問題。國家統計局公布的普查數據以及抽樣調查數據均有一定的漏報率,但并沒有公布漏報人口的性別、年齡以及城鄉分布,尤其是出生人口和低齡人口漏報的數量和孩次分布情況。對于人口預測而言,低齡人口和育齡婦女的數據質量不僅關系到時期生育水平的高低,還關系到育齡婦女的生育基數、生育結構和生育完成情況。針對出生漏報問題,學者們采取隊列法、插補法、存活分析法等人口分析方法對漏報人口進行了估算、回填[10-12],但由于操作方法、認識思路不同,學界對漏報人口的總量與分布問題的處理仍存在較大差異。
第二,基礎數據的統計口徑、評估與修正標準問題。首先,由于各部門統計口徑的差異,致使不同統計結果存在明顯的差異。例如對一個地區人口數量和結構有著重大影響的流動人口的統計,由于界定標準、統計方式的不同,不同部門、不同時間下的統計就會有不同的結果。其次,即使是同一數據,具體人口預測的操作中有的學者、部門進行調整使用,而有的學者則是直接使用。即使在預測中都對同一基礎數據進行評估調整,但是由于調整的方法不同也導致錄入預測模型的基礎數據不同。這樣一方面導致預測結果的多樣性,另一方面預測結果之間的可比性也大打折扣。
3 人口預測參數的選擇與特征
對于封閉人口系統參數的選擇主要包括反映生育水平的總和生育率和反映死亡水平的平均預期壽命。
3.1 生育水平
基于人口發展規律和統計數據可以發現,如果生育水平被過高估計,預測的人口規模將高于人口統計規模。因為當期的出生人口規模不僅決定了當時的人口規模增量,還決定了這一隊列人口步入婚育期后的未來人口規模增量。那么,眾多人口預測操作中生育水平是如何設定的?通過對生育水平的設定比較的分析(見下頁表3),可以發現以下幾個特征:
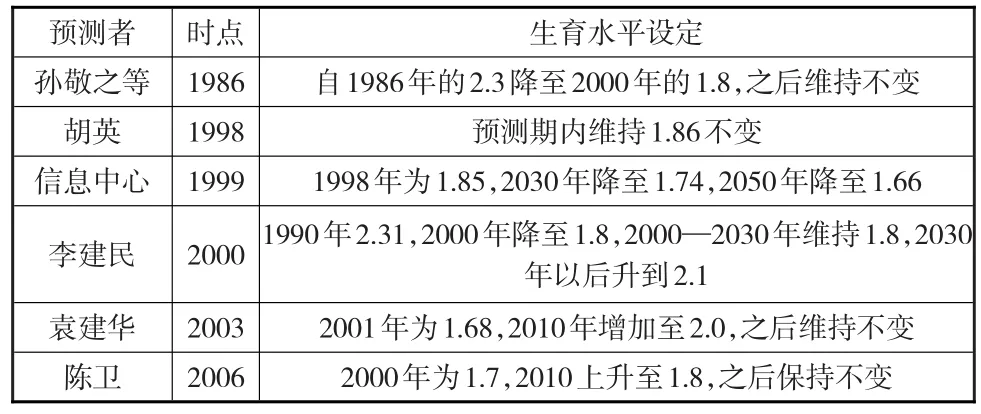
表3 不同預測中生育水平的設定
第一,對總和生育率的設定基本處于1.7~2.2之間。1990—2000年間對總和生育率的設定處于1.8~2.2之間;2000—2010年間基本處于1.8~2.0之間;2010年以后對生育水平的設定方向比較分化,一類是基本維持1.8的水平,一類是呈持續下降,另一種是出現回升。這種現象一方面可能是導致各類預測結果普遍高于人口實際統計結果的原因之一,另一方面也可能是導致各類預測結果出現明顯差異的原因之一。
第二,生育水平的設定存在明顯的差異。由于上述研究的時點存在不同,本文取2000年、2010年、2030年這一各個研究都覆蓋的時間進行比較。可以發現2000年時,總和生育率的最高設定水平為1.85,最低水平為1.68,相差約0.17;2010年時最高水平為2.0,最低水平為1.76左右,相差0.24;2030年時最高水平為2.1,最低水平為1.74,相差約0.36。預測后期,設定的差異愈大,一定程度上導致后期預測結果差異也愈大。
生育水平是影響人口預測結果的關鍵要素,從結果檢驗來看,過往人口預測結果基本都高于實際統計結果,而且隨著時間的推移,高出的幅度不斷增大。那么是不是因為過往預測研究對生育水平的設定都偏高了呢?同樣可以通過對比以往生育水平的統計結果進行判斷。國家統計局根據“五普”、2005年“小普查”和“六普”調查數據得出的我國總和生育率分別為1.22、1.33和1.18。部分學者對這一數據存在質疑,認為由于瞞報、漏報等導致結果極度偏低[13-16]。
盡管學界對總和生育率究竟是多少存在認識上的差異,但是通過各類數據的比對和印證,可以得出兩個方面的判斷:一方面,各類人口預測中短期內亦或說2015年以前設定的生育水平下所得到的人口預測結果與實際統計結果雖然存在一定的誤差,但是大部分預測結果其實比較貼近實際統計結果,這可以從另一個角度反應出國家統計局官方公布的生育水平是極度偏低的;另一方面,通過比較可以發現,過往人口預測研究對生育水平的判斷是偏高的。20世紀90年代以來我國育齡婦女的生育水平下降非常快,超出了學者們的估計。因為以上研究對總和生育率的設定不僅遠遠高于官方公布的統計水平,而且也高于學者們根據歷次普查以及統計調查數據所推算的生育水平。這一定程度上反應了既往研究中對生育水平的設定偏高,也一定程度上導致了對人口總數的預測結果高于實際人口統計結果。
3.2 死亡水平
平均預期壽命是反映死亡水平的重要指標,死亡是影響人口規模變動的重要因素,死亡水平的高低也就決定了人口減少的多寡。如果對平均預期壽命的設定偏高,相應的對人口死亡率的判斷則會偏低,則一定程度上會導致人口預測結果出現偏高。
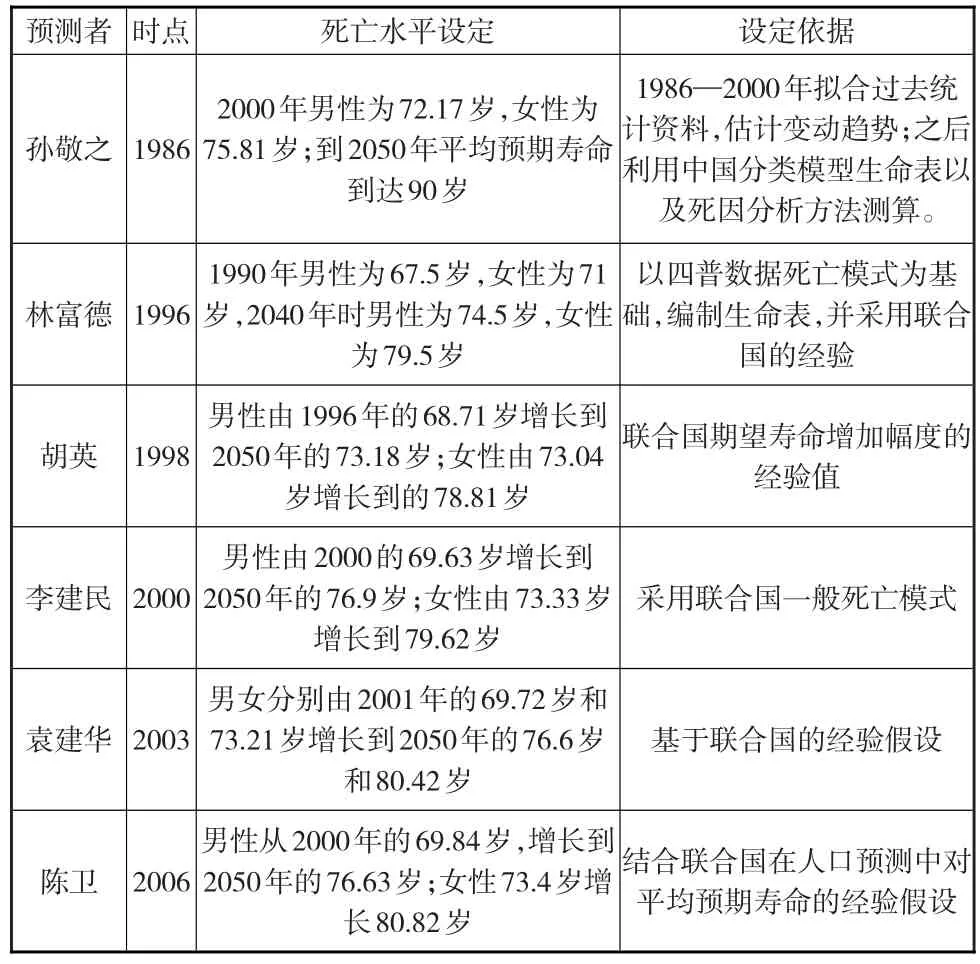
表4 不同預測中死亡水平的設定及依據
通過表4的對比,可以發現對死亡水平的設定以及設定依據存在以下幾點特征:
第一,對平均預期壽命的判斷存在一定的時期差異。20世紀80年代的人口預測對平均預期壽命的設定比較樂觀。如孫文認為到2050年,平均預期壽命有可能達到90歲;90年代的預測基本認為到21世紀中葉男性平均預期壽命基本能夠達到74歲左右,女性基本達到79歲;當然20世紀90年代和2000年以后的平均預期壽命的設定雖然存在一定的差距,但是差別不大,對平均預期壽命整體趨勢的把握具有一定的相似性。2000年以后的預測認為到21世紀中葉男性平均預期壽命基本在76歲左右,女性基本在80歲左右。
第二,不同的設定依據對平均預期壽命的判斷具有重要的影響。表4主要反映了兩種判斷依據,一是運用統計方法進行判斷,二是運用聯合國經驗數據進行判斷。統計方法依靠趨勢分析和死因分析等手段對未來趨勢進行預測,得出的結果并不一定可靠。一方面根據各國人口轉變經驗,平均預期壽命在達到一定水平后,將出現減速遞增的趨勢,另一方面隨著時代的發展,很多未知的疾病導致的高死亡率并不在當時死因分析的考慮范圍之內。按照趨勢分析和死因分析往往會使得推算結果大幅偏離實際結果。而根據經驗分析,由于人口規律的作用,對平均預期壽命趨勢的大體判斷相對具有一定的穩定性。
4 人口預測模型的比較與問題
建立人口預測模型的基本原則是能夠把握人口過程及其規律,而不僅是數據和模型的簡單拼湊。面對眾多預測模型,如何找到適用于一個國家人口發展特點的模型至關重要。本文通過對比來分析這些人口預測模型的特點(見表5),對人口預測模型之間的共性與差異進行考察。
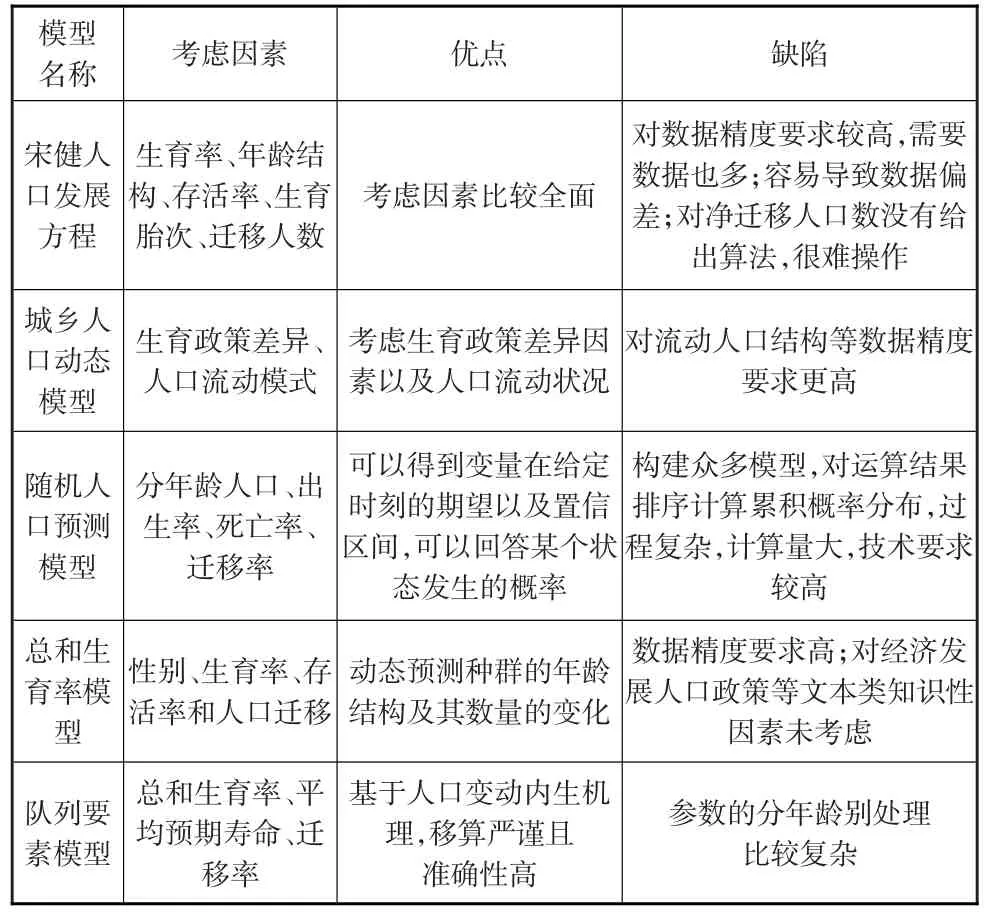
表5 樣本預測模型的對比分析
通過對以上模型的對比分析,針對人口預測模型的使用可以總結出以下特點和問題:
第一,對于以統計分析為基礎的人口預測模型,由于考慮因素相對較少,將觀測數據帶入公式即可,發展至今被廣泛應用。當然這類預測模型對數據精度、數據質量要求較高,某一數據出現的偏差會對整個結果產生較大的影響;同時對于影響人口再生產的經濟性因素和政策性因素沒有加以考慮。如果預測地區的人口統計數據不夠全面、準確或者人口變動受外生經濟和政策等變量影響較大時,運用這類模型進行人口預測往往會產生一定的誤差。此外,從預測期限分析,這類模型短、中、長期預測均可,但短期預測可以取得較好的精度。
第二,對于我國學者自主構建的人口預測模型,人口發展方程由于對數據要求較高,計算龐雜,1990年代以后應用相對較少。而由于我國當前人口流動的鮮明特征,城-鄉人口動態模型等被廣泛使用。這些人口預測方法是學者們利用傳統人口預測方法,針對我國計劃生育政策實際以及特殊的流動人口遷移模式進行了適當的優化和改進所得到。同時中短期預測精度較高,而長期預測則誤差較大。因為結合表1可知,到2040年研究樣本的相對誤差率最大為7.2%,最小僅為0.13%。
5 結論
本文以人口實際統計結果為依據,對過往權威人口預測結果精度進行檢驗,同時通過對影響人口預測結果精度的三大要素進行比較分析,得出了以下結論:第一,過往人口預測結果呈現出多樣性,從中短期來看這些研究對人口趨勢的預測基本符合人口實際發展趨勢,但從長期來看這些研究對人口總量的變動預測存在較大差異。第二,過往人口預測結果普遍高于人口實際統計結果,隨著時間推移,高出幅度也越來越大。造成各類預測結果偏高的主要原因是對生育水平的設定偏高。一方面生育水平的設定高于實際統計水平以及學者們結合統計數據修正得到的生育水平;另一方面,死亡水平的設定高于實際死亡水平的變動趨勢,又抵消了一部分因死亡水平設定相對過高所造成的預測結果偏高;第三,過往人口預測結果精度隨時間推移不斷下降,預測結果的絕對誤差率和相對誤差率都隨時間推移而不斷增加;第四,不同預測結果之間呈現出的差異,主要是由于對基礎數據的處理和評估缺乏統一的標準,同時對總和生育率的判斷缺乏共識,而不同的預測模型之間的運算過程、考慮因素、數據處理之間的差異也一定程度上造成預測結果之間出現差異。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂探索(2022年2期)2022-05-30 21:01:37
美與時代·美術學刊(2022年3期)2022-04-27 01:18:15
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
人大建設(2019年12期)2019-05-21 02:55:32
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
光學精密工程(2016年6期)2016-11-07 09:07:19
鄭州大學學報(醫學版)(2015年2期)2015-02-27 14:50:46
