基于規則的動物衛生事件輿情信息抽取研究
2018-09-26 07:07:54丁晟春劉夢露
計算機應用與軟件 2018年9期
丁晟春 王 莉 劉夢露
(南京理工大學經濟管理學院 江蘇 南京 210094)
0 引 言
近年來,隨著經濟全球化的發展,動物及其產品流通頻繁,疫病傳播機會大大增加,加之環境嚴重污染,使動物疫病更加復雜,呈現危害加重、種類增加、混合感染等特點,給防制工作帶來了新的挑戰和困難。除了動物養殖人員對動物健康持有高強度的關注外,禽類、魚、牛、羊等多種動物直接或間接的進入大眾餐盤,這也使得每一個民眾時時刻刻都關注著動物健康。在網絡媒體時代,動物衛生事件一旦發生,很容易被推到風口浪尖上。如果不對動物衛生輿情加以有效管理和良性引導,輕則引起企業和行業巨大損失,重則發展為公共安全事件,引起群體恐慌,謠言的散布會危害社會的安定秩序,甚至會引發群體性事件。在海量信息面前很難通過直接瀏覽的方式獲取信息,因此如何高效準確地從動物衛生輿情信息中抽取出衛生事件的主體信息成為研究的要點。本文以動物衛生事件新聞信息為研究對象,使用基于規則的抽取方法實現時間、地點、疫病名稱、動物數量、應對措施等內容的抽取。
當前事故信息抽取研究中的不足主要有:(1) 為了能夠達到較高的語言覆蓋度,現有研究會構建大量抽取規則而且抽取關鍵字大都直接寫入抽取規則,這使得抽取規則的后續查閱和維護變得困難;(2) 對于涉及多個事故信息或包含多個同一屬性項值的文本,現有的基于規則抽取方法僅能抽取到屬性值,無法準確區分抽取到的值哪個是最終有效信息,導致抽取效果差。
為了改善以上缺點,本文總結待抽取屬性項的描述規律以及出現位置和方向,構建觸發詞表,使用各類觸發詞的詞性標注設計抽取規則,提高抽取規則的使用和維護效率。提出基于節點比較的方法有效區分文本中出現的多個動物數量屬性項,提高了抽取效果。
1 相關工作
在網絡信息量呈指數級增長的環境下,如何從大量的信息中及時并準確地抽取、 過濾、歸類形成便于用戶使用的信息變得尤為重要。而信息抽取就是從一個文本中抽取指定信息并將其結構化的存入數據庫中供用戶查詢使用的過程[1]。目前常用的信息抽取方法有:基于統計的信息抽取方法[2-3]和基于規則的信息抽取方法[4-5]。基于統計的信息抽取是一種基于概率性的非確定性的信息抽取方法。該方法首先需要構造一個模型模擬信息抽取過程,應用統計學方法從訓練語料中得到模型的參數,然后利用訓練好的模型進行信息抽取[6]。但是,統計模型通常借助于獨立性假設使模型只能處理結構關系依賴性不強的對象。基于規則的信息抽取技術是相對應用比較廣和比較成熟的一種抽取技術。霍娜等[7]以火山爆發、泥石流、客輪沉沒三種災難性追蹤事件作為研究對象,分析相關事件報道之間的連續性、多角度性等文本特點,構建了54條抽取規則對災難性追蹤事件文本抽取。丁學軍等[8]通過大量領域內文獻的閱讀、分析和歸納構建屬性描述的規則,對《情報學報》2007年和2008年的文章里的學術概念進行抽取。蔣德良[9]把突發事件的結果總共分為20類,并為自然災害事件、人為事件及疾病爆發事件三大類事件共建立了284條抽取規則,實現突發事件結果信息的抽取。余晨等[10]對長江海事局網站險情報告版塊中描述海事險情概況的文本進行分析,人工編制規則實現對海事文本中時間、地點、船名和事故類型四個屬性項的抽取。
本文的研究對象為新聞數據,由于各網站對動物衛生事件新聞報道的描寫風格相對一致,且書寫手法發生變化的可能性小,所以本文將總結待抽取實體描述的規律(如在新聞文本的表達方式及位置等),人工構建抽取規則,實現對動物衛生事件輿情信息的抽取。
2 動物衛生事件輿情信息的抽取
本文處理的動物衛生事件新聞數據主要來自我國政府官方網站和人民網、新華網、中國新聞網等新聞網站,從中抽取出動物衛生事件的報道時間、發生地點、引發衛生事件的疫病、衛生事件中涉及的動物數量(染疫、死亡、撲殺)以及為應對該衛生事件采取的措施。
2.1 信息抽取流程
本文的信息抽取主要包括詞庫構建、文本預處理和信息抽取三個模塊,信息抽取流程如圖1所示。

圖1 信息抽取流程
(1) 詞庫構建模塊:為了提高分詞效果和規則制定需要構建動物疫病詞典和信息抽取觸發詞表。動物疫病詞典的主要來源為2016年世界動物衛生組織OIE(Office International Des Epizooties)公布的動物疫病名錄,我國農業部2008年修訂的《一、二、三類動物疫病病種名錄》以及中國動物衛生與流行病學中心較為關注的疫病。
(2) 文本預處理模塊:文本預處理模塊主要包括分句、分詞和詞性標注。本模塊使用動物衛生事件新聞的標題和正文作為實驗語料,將標題拼接到正文前形成一整段文本。首先對待抽取語料以“,”、“。”、“!”、“;”、“?”等符號進行分句,再對分句后的文本使用中科院ICTCLAS分詞工具進行分詞并標注詞性。
(3) 信息抽取模塊:本模塊將通過對待抽取語料的分析,基于觸發詞表制定抽取規則,并使用正則表達式描述抽取規則建立規則庫,最后進行動物衛生事件新聞的信息抽取實驗。
2.2 觸發詞表的構建
信息抽取規則是說明目標信息的約束條件,抽取規則主要有觸發詞、特征詞、開始位置、結束條件等幾項構成。觸發詞是指對某一屬性的抽取起著識別、標志作用,可以觸發抽取任務的詞語。以往研究表明觸發詞一般是動詞或名詞,所以對其他詞性的詞語不予考慮[11]。通過對待抽取語料的文本特征和新聞描述習慣進行分析,構建待抽取屬性項的觸發詞表。
(1) 時間觸發詞 網絡新聞通常會包含新聞發表時間和報道時間,發表時間是指新聞網站刊登新聞時系統自動生成的時間,報道時間是指新聞內容向讀者報道的時間。在網絡中,同一件新聞事件會有多個新聞網站對其進行報道或轉載,而不同網站新聞的發表時間是不同的,并且在數據抓取時不能保證抓取到的新聞為該事件的首條報道,所以新聞的發表時間不能準確地表示輿情信息的出現時間。由此,本文將抽取新聞的報道時間作為輿情信息的出現時間。報道時間作為新聞報道的六大元素之一,一般出現在新聞正文首句,包括年、月、日,不會精確到小時,如:“中新網11月17日電”、“農民日報12月6日訊”。根據對待抽取語料統計得出時間觸發詞有:“電”、“訊”、“報道”、“消息”、“發布”等。
(2) 疫病名稱觸發詞 疫病名稱作為動物衛生事件報道的核心,基本上會直接出現在動物衛生事件新聞的標題中,如:“香港活禽檢出H7N9病毒,撲殺約兩萬只家禽”、“立陶宛野生豬染非洲豬瘟”。如果標題中未出現疫病名稱,新聞正文的前兩句都會對引發動物衛生事件的疫病進行描述。疫病名稱觸發詞有:“檢出”、“出現”、“發現”、“暴發”等。
(3) 動物數量觸發詞 動物衛生事件中涉及的動物數量可以用來判斷事件的暴發程度,因此準確地獲取事件動物數量十分重要。動物衛生事件動物數量主要包括染疫(疑似染疫)動物數量、死亡動物數量和撲殺動物數量三類。在醫學上“染疫”和“發病”是兩種概念,染疫是發病的必要條件,所以染疫動物數量包含發病動物數量,本文將發病動物數量納入到染疫動物數量進行抽取。對應上述三類動物數量將動物數量觸發詞分為三類。染疫(疑似染疫)動物數量觸發詞主要有:“感染”、“發病”、“染病”等;死亡數量觸發詞有:“死亡”、“暴斃”等;撲殺動物數量觸發詞有:“撲殺”、“捕殺”、“宰殺”、“銷毀”等。
(4) 應對措施觸發詞 動物衛生事件是否采取應對措施對該事件的危及程度有重要的影響,而且采取怎樣的應對措施可以在后續事件處理起到借鑒作用。但是,只有少部分新聞會具體描述動物衛生事件的應對措施,而大部分新聞通常是大而空的描述采取應對措施,例如:“疫情發生后,當地按照有關預案和防治技術規范要求,堅持依法防控、科學防控,切實做好疫情處置工作”。大而范的應對措施對后續事件處理的借鑒意義不大,因此本文從控制傳染源、切斷傳播途徑、保護易感群體三個方面抽取具體的應對措施。通過對動物衛生事件常用的應對措施進行總結和對已有的新聞報道進行分析得到應對措施專用詞語,如:“撲殺”、“宰殺”、“滅殺”、“消毒”、“隔離”、“無害化處理”等,將應對措施專用詞作為該類的觸發詞使用。在撲殺動物數量觸發詞中有部分與應對措施觸發詞相同,將這部分詞語以共用觸發詞進行標注。
根據信息抽取流程在觸發詞表構建之后需進行待抽取文本的預處理。本文將動物疫病詞典和觸發詞表中的詞語加入到ICTCLAS分詞工具進行文本的分詞和詞性標注,自定義詞性標注見表1。

表1 自定義詞性標注
2.3 抽取規則表示
為了得知各待抽取項在本文的位置和觸發詞的觸動方向,本文選取了300條動物衛生事件新聞進行待抽取項在文本語料的位置和觸發詞前后的位置進行統計分析。地點和應對措施待抽取屬性項是通過觸發詞詞性標注進行抽取的,所以只對時間、疫病名稱和動物數量三個待抽取屬性項的文本位置和觸發詞位置進行統計分析。統計結果如表2所示。
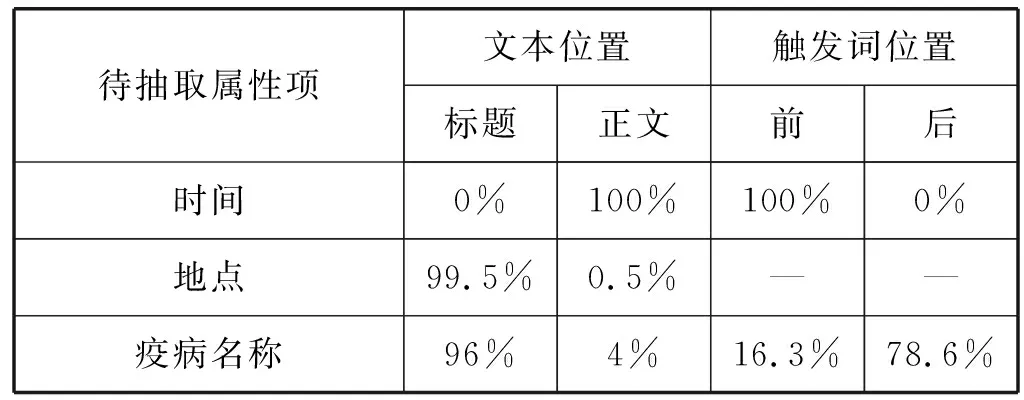
表2 抽取位置及方向統計分析結果

續表2
由表2中的待抽取屬性項文本位置的統計結果可以看出,地點和疫病名稱待抽取項可以直接從新聞標題中獲得。因此,本文將新聞標題作為首句文本加入到正文中進行信息抽取。對觸發詞位置的統計結果可知,時間待抽取屬性項為前向觸發,疫病名稱和動物數量待抽取屬性項觸發詞為雙向觸發,根據位置前后概率可以確定其先行觸發方向。
觸發詞主要是用來識別待抽取項的大概位置,可以通過使用正則表達式來匹配該屬性項。根據對動物衛生事件新聞本文特征的分析,各待抽取屬性項的抽取規則具體如下:
(1) 時間 根據對新聞文本特征的分析發現,時間屬性項通常出現在正文首句,所以,對待抽取文本的第二句使用規則Regex1根據觸發詞向前查找標注為/t的詞。
Regex1:([0-9u4e00-u9fa5]*/t)+(?=((?!/t).)*/date)
(2) 地點 根據表2看出地點待抽取屬性項可以直接從新聞標題中獲得,因此在第一句文本中使用規則Regex2查找標注為/ns或/nsf的詞。
Regex2:([0-9u4e00-u9fa5]+/ns[a-z]*)+
(3) 疫病名稱 疫病名稱屬性項將從新聞標題和正文首句中進行抽取。首先使用規則Regex3根據觸發詞向后查找標注為/disease的詞,如果沒有找到則使用規則Regex4據觸發詞向前查找標注為/disease的詞,如果不存在觸發詞則使用規則Regex5查找標注為/disease的詞。具體規則見表3。
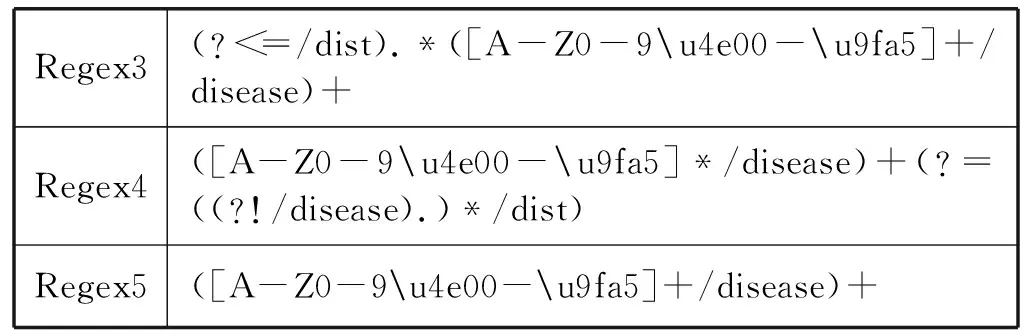
表3 疫病名稱屬性項抽取規則
(4) 動物數量 對于染疫(疑似染疫)動物數量,首先使用Regex6根據觸發詞向前查找與量詞(標注為/q)相連標注為/m的詞。如果沒有找到則使用規則Regex7向后查找與量詞(標注為/q)相連標注為/m的詞。死亡動物數量和撲殺動物數量的抽取方式與染疫(疑似染疫)動物數量相同。具體規則見表4。
(5) 應對措施 從第一句文本開始,使用規則Regex12查找標注為/measure或/q_m的詞語。
Regex12:[u4e00-u9fa5]+(?=/measure|/q_m)
2.4 實驗結果分析
本文從新華網、環球網、中國新聞網等網站抓取了2017年1月至2017年6月期間共計800條動物衛生事件新聞數據。經過分詞、分句、詞性標注等文本預處理之后進行抽取實驗。實驗結果使用準確率(P)、召回率(R)及F1值進行測評,得到的測評結果如表5所示。

表5 動物衛生事件輿情信息抽取實驗結果
從表5中可以看出:
(1) 時間屬性項抽取的召回率和準確率最高,這是因為不同新聞網站對對新聞報道時間的表達方式高度統一。
(2) 地點作為新聞六大要素之一,而且動物衛生事件新聞的標題都會對地點進行描述。本文地點屬性項的抽取僅依靠詞性標注進行,導致地點抽取結果對ICTCLAS分詞工具地名識別的準確度存在較大的依賴。例如:新聞中出現的國家名稱簡寫“澳”和地名“圣海倫娜”ICTCLAS不能正確進行標注,還有少數國內的市、區、縣和國外的州不能準確的標注,導致準確率低。如果將地點粒度變粗(國內精確到省,國外精確到國家),地點屬性項的準確率可以達到92.4%,召回率達到87.7%。
(3) 疫病名稱也是動物衛生事件新聞一定會描述的內容,其準確率達到97.4%,召回率達到94.9%。疫病名稱屬性項根據觸發詞對本文提供的動物疫病詞典中的疫病名稱進行抽取,由此可知,疫病名稱的準確率和召回率與動物疫病詞典中的疫病名稱完備性有較大關聯。后續研究中可以加入動物疫病知識本體以提高抽取效果。
(4) 根據本文動物數量的三類抽取規則對屬性項進行抽取,抽取結果較其他屬性項的效果差距較大。三種動物數量抽取結果的準確率和召回率普遍偏低,主要存在以下幾種錯誤情況:
① 在抽取過程中,本文抽取實驗中默認返回抽取到的第一個匹配項。有些新聞會在標題或者正文前部分先描寫一個粗略的動物數量,再在下文中描寫詳細數據,還有部分新聞會在一個報道中對兩個動物衛生事件進行描述。所以,在包含多個動物數量值的情況下根據抽取機制不能獲取到準確結果。
② 本文制定的動物數量抽取規則是根據觸發詞和量詞詞性標注來定位抽取項,并未對具體量詞進行定義,造成了大量錯誤。
③ 本文設定在死亡和撲殺動物數量觸發詞在抽取中有不錯的適用性,但在對染疫動物數量抽取時新聞文本中出現了多種側面描述方式,如:“表現出……癥狀”、“檢測呈陽性”、“檢測出……病毒”等,抽取觸發詞的不完善導致染疫動物數量抽取的效果差。
由以上分析可知,動物數量的抽取規則存在很多漏洞,需對其進行改進以改善其準確率和召回率。
(5) 動物衛生事件新聞對應對措施的描述方式差異大,而且大部分新聞對動物衛生事件應對措施的描述比較空泛。本文選取了應對動物衛生事件常用的具體措施作為觸發詞直接根據詞性進行抽取。根據詞性直接從文本中進行抽取可以做到抽取的高召回率,但是對其準確率的高低有影響。例如:文本“馬拉維已經采取隔離檢疫措施,尚未對受影響的動物接種疫苗”,根據抽取規則會將“隔離”、“接種疫苗”抽取出來,但是接種疫苗是尚未執行的措施不應該抽取出來。還有部分新聞在描述完當前時間會對過去事件進行描述,而根據抽取規則會將去年事件的應對措施抽取出來。后續研究需要對應對措施的抽取內容和抽取方式進行更詳細的探討。
3 動物數量屬性項抽取的改進
3.1 基于節點關系比較的抽取方法
根據2.4節中對動物數量屬性項抽取結果的分析可知,量詞定義和染疫動物數量觸發詞不準確的問題可以通過表6中的抽取規則解決。但是,抽取效果差的核心問題在于抽取實驗默認返回第一個匹配結果。如果抽取實驗不再默認返回第一個匹配結果,而是返回新聞文本中根據規則可以匹配到的結果,那么如何判斷和處理所有返回結果的關系就成為了改善動物數量屬性項抽取的關鍵。

表6 修改及新增的抽取規則
本文提出基于節點關系比較的方法對動物數量屬性項的抽取效果進行改進。將動物數量抽取所返回的結果記錄在動物數量節點中,并為動物數量節點設置屬性,通過各動物數量節點的屬性值來判斷節點之間的關系。動物數量節點包含的屬性有:時間、地點、疫病、動物種類、結果精度。其中:時間表示該動物數量的動物染疫、死亡或被撲殺的時間;地點表示該動物數量所對應動物衛生事件發生的地點;疫病名稱表示該動物數量的動物染疫、死亡或被撲殺的病因;動物種類表示該動物數量所對應的動物種類;結果精度表示抽取結果是精確值還是模糊值,用T和F表示。依據對動物數量屬性項所在文本的位置分析,使用抽取規則從動物數量節點值前方文本中匹配獲取動物數量節點的時間、地點和疫病屬性值,選取距離動物數量節點值最近的名詞作為動物數量節點的動物種類屬性值,而結果精度屬性值則通過判斷動物數量節點值是否包含“多”、“余”等詞語來確定。
為了簡化判斷各動物數量節點間的關系,本文設置一個參考節點。參考節點是用來表示該新聞報道的動物衛生事件的相關信息。參考節點本身沒有值,其包含時間、地點、疫病三個屬性。因為參考節點作為篩選動物數量節點的基礎參照,所以參考節點的屬性值為新聞描述的動物衛生事件的最粗粒度數據值。即選取新聞報道的時間作為參考節點的時間,地點則選取動物衛生事件發生的國家或省份,不細化到州或區縣,疫病即引發動物衛生事件的疫病。
動物數量屬性項的值需要經過參考節點與動物數量節點和動物數量節點間的兩次關系判斷才能最終確定。參考節點與動物數量節點之間的關系分為相關關系和無關關系兩種;動物數量節點之間的關系包括:相等關系、包含關系和并列關系。動物數量屬性項值確定流程如下:
輸入:參考節點,動物數量節點集合。
輸出:動物數量屬性項值。
Step1進行參考節點與動物數量節點集合中每個節點的關系判斷,與參考節點呈相關關系的動物數量節點進入Step2,刪除與參考節點呈無關關系的動物數量節點;
Step2如果僅有一個動物數量節點則以該節點值作為動物數量屬性項的值,進入Step5,如果存在多個動物數量節點則判斷各動物數量節點間的關系,進入Step3;
Step3將動物數量節點以樹形結構排列,進入Step4;
Step4選擇樹形結構頂層的節點,根據節點值及其精度判斷最終結果,進入Step5;
Step5輸出動物數量屬性項值。
3.2 節點關系判斷
參考節點與動物數量節點之間的關系分為相關關系和無關關系。相關關系是指動物數量節點值所描述的是當前新聞報道的動物衛生事件中涉及的動物數量;無關關系是指動物數量節點值描述的不是當前新聞報道的動物衛生事件,一般為過往類似動物衛生事件中涉及的動物數量。
設參考節點R{t1,add1,disease1},動物數量節點N{t2,add2,disease2,animal},R和N的關系判斷方法為:
判定規則1若R和N滿足t2∈[t1-1month,t1]、add2?add1、disease2=disease1,那么R和N兩個節點為相關關系,否則為無關關系。
在判斷完參考節點與動物數量節點之間的關系后,與參考節點呈相關關系的動物數量節點進行動物數量節點間的關系判斷。動物數量節點之間的關系分為相等關系、包含關系和并列關系。由于進行動物數量節點間關系判斷的節點都是與參考節點呈相關關系的節點,各動物數量節點疫病屬性值是一致的,所以將從時間、地點、動物種類屬性值對動物數量節點關系進行判斷。相等關系表示兩個節點描述的為動物衛生事件中的同一個數量值;包含關系表示兩個動物數量節點值在時序或地點或動物種類上存在包含關系;并列關系表示兩個動物數量節點值是對動物衛生事件在地點或動物種類上的細化描述。
設動物數量節點N1{t1,add1,disease1,animal1},N2{t2,add2,disease2,animal2},N1和N2間的關系判斷方法如下:
判定規則2若N1和N2滿足t1=t2、add1=add2、animal1=animal2,那么N1和N2為相等關系。
判定規則3若N1和N2滿足t1≤t2、add1?add2、animal1?animal2,那么N2包含N1。
判定規則4若N1和N2滿足add1≠add2或animal1≠animal2,那么N1和N2為并列關系。
在各動物數量節點關系判斷之后,根據節點樹形結構中頂層節點的個數和各節點的結果精度確定動物數量屬性項的值,判定方法如下:
判定規則5如果頂層節點只有一個,則以該節點的值作為動物數量屬性項的值。
判定規則6如果頂層節點有多個且這些節點呈相等關系,則選擇結果精度屬性為“T”的節點值作為動物數量屬性項的值。
判定規則7如果頂層節點有多個且這些節點呈并列關系,則以這些節點值的和作為動物數量屬性項的值。
3.3 基于節點關系比較方法抽取實驗
使用表6中完善后的抽取規則和基于節點關系比較方法在2.4節的實驗數據上重新進行動物數量屬性項的抽取實驗。基于2.4節中實驗結果分析可知,動物數量節點屬性值的抽取效果對分詞工具、動物疫病詞典和語法分析工具有較大依賴性,這可能會導致基于節點關系比較的動物數量抽取方法結果較之前的規則抽取結果更差。本文在此不再對節點屬性值的抽取進行深入研究,所以為了減小節點屬性值抽取結果對節點關系比較的影響,在自動抽取得到的參考節點和動物數量節點屬性值進行人工審核。審核之后再進行節點關系判斷,最終輸出動物數量屬性項的值。實驗結果使用準確率(P)、召回率(R)及F1值進行測評。得到的測評結果如表7所示,與2.4節動物數量屬性項抽取(改進前)結果對比如圖2和圖3所示。

表7 動物數量屬性項抽取實驗結果
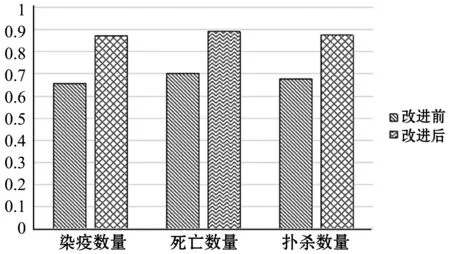
圖2 準確率對比圖

圖3 召回率對比圖
根據表7、圖2、圖3可以看出,基于節點比較的抽取方法提升了三種動物數量屬性項的抽取效果。實驗能取得較好的抽取效果有以下幾個原因:
(1) 基于節點關系比較的抽取方法的抽取效果依賴于動物數量節點值的抽取效果。如果進入節點關系比較的動物數量節點是錯誤的,那么對節點間的關系比較會帶來影響。表6對抽取規則進行補充并對抽取規則中的具體量詞“只”、“頭”、“例”進行定義,減少了因標注“/q”定位而獲取的錯誤抽取結果個數,從而提高了動物數量節點值的抽取效果。
(2) 之前的抽取方法只能返回第一個抽取結果,無法判斷新聞中多個動物數量值的關系。而動物數量節點和參考節點的關系比較排除了過往事件中的動物數量值,動物數量節點的關系比較可以很好地處理新聞中多個動物數量值的關系,提高了抽取結果的準確率和召回率。
4 結 語
本文總結了各待抽取屬性項文本描述和分布規律,并使用正則表達式構建抽取規則實現了動物衛生事件輿情信息的抽取。本文還提出基于節點關系比較的方法對動物數量屬性項的抽取進行改進。兩次抽取實驗可以證明本文提出的方法是可行的,且準確率較高。但是本文未對動物數量節點屬性值的抽取方法進行改進,動物數量節點屬性值抽取的錯誤結果影響了節點間關系的判斷。下一步將對動物數量節點屬性值的抽取方法進行研究,實現準確高效的自動抽取,減少人工工作量。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
幸福(2018年33期)2018-12-05 05:22:42
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
中國科技信息(2016年14期)2016-07-31 21:16:32
小學教學參考(2015年20期)2016-01-15 08:44:38
