基于小波分析的BP-SARIMA模型的CPI預測
2018-09-21 05:42:44彭乃馳
統計與決策 2018年16期
彭乃馳,黨 婷
(云南大學旅游文化學院 信息科學與技術系,云南 麗江 674199)
0 引言
建立合適的數學模型精準預測CPI對于相關部門制定宏觀經濟調控政策具有重要的參考意義。目前,在中國知網上可以檢索到的CPI預測的文獻高達130余篇,預測模型高達十余種,如神經網絡、SARIMA、ARCH、VAR、GM等,但尚無公認的最優的預測模型。黃鷹翔[1]實證表明SARIMA能較好地預測CPI的變化情況。石春娟[2]通過實證說明了小波分解和ANFIS模型在CPI預測中的有效性。王宇等[3]利用BP神經網絡對我國CPI進行預測,效果比較理想。本文以云南省CPI數據為例,利用小波分析去除CPI數據中的噪聲,并在CPI預測中有較好效果的BP神經網絡及SARIMA模型的基礎上,建立小波分析的BP-SARIMA預測模型。本文通過對云南省1995年1月至2016年12月CPI的預測和檢驗,驗證該模型在CPI預測中的有效性。
1 小波分析的BP-SARIMA模型
1.1 小波分析
小波分析的思想是用小波序列的迭加來逼近某一信號。小波分析在時間序列預測中的應用主要是基于小波分析中的多分辨率分析理論。多分辨率分析是通過改變伸縮及平移尺度得到信號的近似及細節部分,在不同分辨率下顯示信號的特征,實現對信號不同時間尺度和空間局部特征的分析。采用小波方法可有效消除時間序列中的噪聲[4]。小波分析實現的關鍵是小波函數及分解層數的選擇,實際應用中可根據數據及不同小波函數的特點來選擇。小波分析的過程可大體分為分解、去噪與重構三步。
設時間序列數據為 f(n),則 f(n)的多分辨率分解可以表示為:

其中 ?j0,k(2j0n-k),φj,k(2jn-k)分別是尺度函數 ?(t)和母小波函數 φ(t)的伸縮和平移函數簇。 cj0,k,dj,k分別是在伸縮尺度 j0,j,平移尺度k上的展開系數。Nt是時間序列的點數。
1.2 BP神經網絡
BP神經網絡于1986年提出后,至今已在多方面廣泛應用[5-7]。它是一種多層前饋神經網絡,其特點是信號由輸入層、隱層、到輸出層前向傳播,誤差反向傳播,并根據預測誤差調整網絡權值和閾值使預測輸出不斷逼近期望輸出。
BP神經網絡是一個3層感知器的數學模型。各層之間的數學關系如下:
對于隱層有:
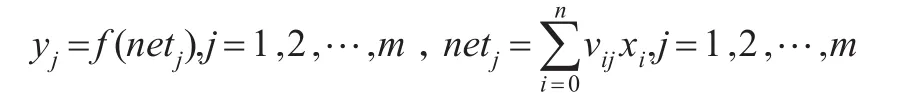
對于輸出層有:

上式中x0=-1是為隱層神經元引入閾值設置的,y0=-1是為輸出神經元引入閾值設置的,一般情形下取
1.3 SARIMA模型
若時間序列{xt} 滿足:H(LS)Δxt=Θ(LS)εt,則稱{xt}為季節性SARIMA(P,D,Q)過程。SARIMA模型可用來描述具有周期性的非平穩的時間序列數據。SARIMA模型的表達式為:

其中S為周期的長度,D為季節差分的階數,P為季節自回歸階數,Q為季節滑動平均階數,ΔS=1-LS為季節差分算子,
1.4 小波分析的BP-SARIMA模型的構建
本文以云南同比月度CPI為例,首先對原始數據作小波閾值去噪處理,再對去噪后數據作BP神經網絡預測,最后通過SARIMA模型修正預測殘差。按此思路結合小波分析、BP神經網絡與SARIMA模型的優點,建立小波分析的BP-SARIMA模型。小波分析的BP-SARIMA模型的建模步驟為:
步驟1:選擇某種小波及分解層數對CPI原始數據作分解。
步驟2:閾值處理,即設定某一閾值,只保留大于閾值的小波系數。
步驟3:用處理后的系數重構數據,得到去噪后的CPI數據。
步驟4:對去噪后的CPI數據再作相空間重構,將相空間重構后的數據分為訓練數據與測試數據,并確定BP神經網絡輸入層神經元個數n與輸出層神經元個數m。
步驟6:建立n-l-m結構的BP神經網絡,多次運行網絡,根據測試的MSE選擇最優網絡并運算出該網絡的預測值。
步驟7:對BP神經網絡預測相對于原始數據的殘差作平穩性與季節性檢驗,若其存在季節性則可建立SARIMA模型。
步驟8:在殘差符合建立SARIMA模型的條件下,進一步確定SARIMA模型的參數(p,d,q)×(P,D,Q)s,從而建立SARIMA(p,d,q)×(P,D,Q)s模型并對殘差作預測。
步驟9:將BP神經網絡的預測結果與SARIMA模型的預測結果相加即得小波分析的BP-SARIMA模型的預測結果。
步驟10:通過平均相對誤差、均方誤差等標準測試建立的小波分析的BP-SARIMA模型,測試效果較好則該模型可用于CPI預測。
2 實證
2.1 數據來源
本文選擇云南省1995年1月至2016年12月的CPI同比月度數據,數據量共264個,數據來源于國家統計局網站。原始數據(記為X)的時序圖見圖1。從圖1可見,1995年的云南月度CPI處于同比增長率在20%左右的高位上,消費者物價處于嚴重的通貨膨脹階段。1995—2000年底,云南月度CPI經歷長達六年的遞減后,CPI達到了增長率-3%左右的歷史最低值。隨后云南CPI又經歷了長期的波動性增長,并于2004年與2008年兩次達到了增長率9%左右的峰值。2014—2016年,云南的同比月度CPI基本控制在增長率1%~3%之間,處于較理想的狀態。將云南CPI數據劃分為1995年1月至2015年12月與2016年1月至2016年12月兩部分,前者用于建立模型,后者留作對模型的預測效果作測試。

圖1 云南CPI原始數據
2.2 數據的小波閾值去噪
云南CPI同比月度數據不可避免地會受到某些擾動項的影響,在采集到的數據中會包含一定的噪聲,這些噪聲不能反映數據的本質特征,對預測結果會存在一定的干擾。因此,為提高預測精度可先對CPI原始數據作小波閾值去噪處理。
目前,對小波函數的選擇尚未有統一方法,由于Haar小波(即db1小波)具有正交性、緊支撐性與對稱性,故選擇該小波。小波分解的層數過少會使去噪后的數據平滑性和平穩性較差,分解的層數過多又會使分解過程中產生的計算誤差較大,綜合考慮這兩方面后選擇三層小波分解。選定db1小波三層分解后,使用MATLAB軟件中的小波工具箱,采用默認閾值重構法,完成對CPI原始數據的小波閾值去噪。去噪后的云南CPI數據記為S,其時序圖如圖2所示。

圖2 去噪后的云南CPI
2.3 去噪后數據的BP預測
將去噪后的云南CPI數據S首先作相空間重構,經多次試驗確定出最小嵌入維為3,時間延時為1,即用前三個月的CPI預測下一個月的CPI。經相空間重構后的數據形式如表1所示:

表1 相空間重構數據形式
其中,Si為S的第i期數據。為了與前文建模數據與測試數據的劃分一致,取表1中1~249號數據對BP模型的網絡作訓練,用于建立BP神經網絡模型,而250~261號數據作為測試數據,不參與模型建立。
相空間重構完畢后就確定了BP神經網絡的輸入層神經元個數n=3,輸出層神經元個數m=1,代入經驗公式得即初步確定出隱層神經元個數的取值范圍為3至12的整數。因為BP神經網絡訓練出來的模型每次都不一致,故隱層神經元個數依次取3,4,…,12各重復建模10次,分別計算出測試均方差MSE的10次平均值,通過比較取隱層神經元個數為3,建立3-3-1結構的BP神經網絡。反復訓練3-3-1結構的BP神經網絡,記錄每次的測試均方差,從中找到一個測試效果最好的網絡并保存。利用該網絡建立的BP模型,產生擬合期的預測值Yi(i=4,5,…,252)與測試期的預測值Yi(i=253,…,264),并計算出其相對于原始數據X的殘差 Ei=Xi-Yi(i=4,5,…,264)。以上BP預測過程通過調用MATLAB軟件中的神經網絡工具箱函數實現。為了提高預測精度,擬合期的殘差Ei(i=4,5,…,252)用于進一步建立SARIMA模型。BP模型的預測值 Y及殘差E的圖像分別如圖3和圖4所示。

圖3 BP預測值

圖4 BP預測殘差
2.4 BP預測殘差的SARIMA預測
對BP模型擬合期的預測殘差序列E作無截距、無趨勢的ADF單位根檢驗,t統計量為-10.19小于顯著性水平1%下的臨界值-2.57,認為殘差序列E為平穩序列,故序列E無需作差分。作E的相關圖,如圖5所示。從圖5可見,當滯后期k=12時,自相關與偏自相關系數明顯超出置信帶,顯著不為0,這表明序列E存在季節性。為消除季節性,對序列E作步長為s=12的季節差分產生序列SE,再對SE作無截距、無趨勢的ADF單位根檢驗,t=-6.83<-2.57,表明SE仍為平穩序列,符合SARIMA模型的建模條件,可建立 SARIMA(p,d,q)×(P,D,Q)s模型。

圖5 BP預測殘差E相關圖
由于序列E平穩,取d=0;作一階季節差分后季節性大體消除,取D=1;圖5中當k=12時自相關與偏自樣系數顯著不為0,取P=Q=1。SE的相關圖(見圖6)中偏自關系數與自相關系數分別在滯后2階與1階后多數處于置信帶內,為了使模型預測效果更準確,適當擴寬 p,q的取值范圍,取 p=1,2,3與 q=0,1,2 為待選階數。綜上所述,建立的待選模型為 SARIMA(p,0,q)×(1,1,1)12( p=1,2,3,q=0,1,2),共有九個模型。依據調整 R2、AIC準則、SC準則選擇模型,其中調整R2大優,AIC與SC小優。九個待選SARIMA模型的檢驗結果見表2。

圖6 SE相關圖

表2 SARIMA模型檢驗結果
由表2可見 SARIMA(1,0,0)×(1,1,1)12與 SARIMA(3,0,2)×(1,1,1)12兩模型的AIC都很小且幾乎相等,前者的SC最優,后者的調整R2最優,故先排除其余七個模型,從這兩個模型中作選擇。考慮到 SARIMA(1,0,0)×(1,1,1)12模型的各項系數的估計值在1%水平下都顯著,另一模型有兩項系數的估計值不顯著(5%水平),且 SARIMA(1,0,0)×(1,1,1)12模型的殘差通過白噪聲檢驗,最終選擇該模型,其表達式為:
(1-L12)(1-0.449L)(1+0.450L12)Et=(1+0.935L12)εt
利用 SARIMA(1,0,0)×(1,1,1)12模型對序列 E 作靜態滾動預測,得擬合期的預測值 Ei(i=29,…,252)與測試期的預測值 Ei(i=253,…,264)。
2.5 結果分析

表3 模型測試效果對比
由表3可見,三個模型的各期測試相對誤差都控制在0.7%之內,測試效果均比較理想,它們都可用于對云南同比月度CPI作預測。在這三個模型中,小波分析的BP-SARIMA模型平均相對誤差與均方誤差都最小,為最優模型。小波分析的BP-SARIMA模型相對未經小波分析的BP-SARIMA模型,測試期的平均相對誤差與均方誤差各減少了0.06%及0.044。小波分析的BP-SARIMA模型相對未經SARIMA殘差修正的小波分析的BP模型,測試期的平均相對誤差與均方誤差各減少了0.031%及0.021。
3 結論
對小波分析的BP-SARIMA模型的主要研究結論如下:(1)該模型測試期的平均相對誤差為0.239%,均方誤差為0.091,預測精度高,可用于對CPI作預測研究;(2)通過與未經小波分析的BP-SARIMA模型及未經SARIMA殘差修正的小波分析的BP模型作對比,該模型的預測精度更高,測試期的平均相對誤差與均方誤差都有明顯下降。進一步的研究方向:(1)該模型的改進。比如將BP神經網絡換成其他類型的神經網絡(RBF神經網絡、模糊神經網絡等),模型預測精度是否會有提高。(2)該模型是否適合其他類型經濟指標的預測,比如GDP等。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
