基于深度學(xué)習(xí)的臺標(biāo)檢測在網(wǎng)絡(luò)視頻審核中的應(yīng)用
2018-09-20 11:29:34劉琨
無線互聯(lián)科技 2018年15期
關(guān)鍵詞:深度學(xué)習(xí)
劉琨


摘要:電視臺標(biāo)檢測是網(wǎng)絡(luò)視頻審核的常用方法,但傳統(tǒng)臺標(biāo)檢測方法檢測成功率較低,文章將基于深度學(xué)習(xí)的SSD算法應(yīng)用于臺標(biāo)檢測。首先選取79類237個常見臺標(biāo)視頻作為臺標(biāo)基準(zhǔn)庫,以每秒一幀的速率對臺標(biāo)基準(zhǔn)庫進(jìn)行處理,共127 980張圖像頓,其中95 586張用于臺標(biāo)檢測模型訓(xùn)練,32 394張用于模型測試,算法每訓(xùn)練2 000次進(jìn)行模型迭代,共訓(xùn)練90 000次并選取最優(yōu)模型。經(jīng)過大量的臺標(biāo)樣本實驗測試,準(zhǔn)確率可達(dá)98.2%,優(yōu)于權(quán)威文獻(xiàn)中經(jīng)典方法。表明該方法具有較高準(zhǔn)確率和高擴(kuò)充性。
關(guān)鍵詞:網(wǎng)絡(luò)視頻審核;臺標(biāo)檢測;深度學(xué)習(xí);SSD;高擴(kuò)充性
電視臺的臺標(biāo)是確定電視臺的臺名、節(jié)目取義的重要信息,是區(qū)分不同電視臺唯一標(biāo)志。為了聲明視頻的所有權(quán),往往會在播放的視頻中加入臺標(biāo)。隨著科技的迅猛發(fā)展,互聯(lián)網(wǎng)每天都會產(chǎn)生大量視頻,電視臺標(biāo)是視頻的特有標(biāo)識,通過識別臺標(biāo)來進(jìn)行網(wǎng)絡(luò)視頻審核顯得尤其重要。因此視頻臺標(biāo)識別一直是學(xué)術(shù)界研究的熱點(diǎn)。
在臺標(biāo)的研究中,王建等采用圖像分割方法進(jìn)行臺標(biāo)識別,通過時域抽樣方法選取代表幀序列,計算梯度圖像序列,并進(jìn)行邊緣匹配;史迎春等利用空間分布直方圖和HSV空間的彩色直方圖相結(jié)合的方法對臺標(biāo)特征進(jìn)行描述,并采用知識庫輔助直方圖統(tǒng)計的方法進(jìn)行臺標(biāo)識別;金陽等提出的極坐標(biāo)角點(diǎn)對匹配方法,雖然較好地解決了半透明臺標(biāo)檢測問題并且準(zhǔn)確率有了較大提升,但算法實時性較差。
2016年李世石在與基于深度學(xué)習(xí)的AlphaGo圍棋比賽中落敗,2017年,深度學(xué)習(xí)在醫(yī)療影像處理、安防安保、金融領(lǐng)域等的應(yīng)用越來越廣泛。故本文提出將深度學(xué)習(xí)應(yīng)用到臺標(biāo)檢測這一研究熱點(diǎn)。臺標(biāo)檢測也屬于目標(biāo)檢測,當(dāng)前目標(biāo)檢測領(lǐng)域最先進(jìn)的SSD(Single Shot Detector)算法,已經(jīng)成功應(yīng)用到體育領(lǐng)域關(guān)于網(wǎng)球鷹眼機(jī)器人的改進(jìn),交通領(lǐng)域?qū)τ诩t綠燈的識別等。因此,本文提出將SSD應(yīng)用到臺標(biāo)檢測。
1 SSD算法
SSD是建立在深度學(xué)習(xí)框架caffe的基礎(chǔ)之上的。現(xiàn)今流行的檢測方法都是先生成一些假設(shè)的邊界盒子,然后再提取特征,之后經(jīng)過一個分類器,判斷里面是什么物體。但這類方法不足以實時地進(jìn)行檢測。而SSD消除了中間的邊界盒子、像素或特征重采樣的過程,算法的核心就是預(yù)測物體以及對其類別進(jìn)行評分,同時在特征地圖上使用小的卷積核,去預(yù)測一系列邊界盒子的盒子偏移。以下為算法的詳細(xì)介紹。
1.1 SSD模型結(jié)構(gòu)
SSD是基于一個前向傳播CNN網(wǎng)絡(luò),產(chǎn)生一系列固定大小(fixed-size)的邊界盒子,以及每一個盒子中包含物體實例的可能性,即得分。之后,進(jìn)行一個非極大值抑制(non-maximum suppression)得到最終的預(yù)測。算法框架的最開始部分,稱作基礎(chǔ)網(wǎng)絡(luò)(base network),是用于圖像分類的標(biāo)準(zhǔn)架構(gòu)。在基礎(chǔ)網(wǎng)絡(luò)后,添加一些卷積層,這些層的大小逐漸減小,可以進(jìn)行多尺度預(yù)測。
1.2 SSD模型訓(xùn)練
1.2.1 目標(biāo)函數(shù)
1.2.2 為默認(rèn)盒子選擇尺度和縱橫比
一般來說,CNN的不同層有著不同的感受野。然而,在SSD結(jié)構(gòu)中,默認(rèn)盒子不需要和每一層的感受野相對應(yīng),特定的特征圖負(fù)責(zé)處理圖像中特定尺度的物體。在每個特征圖上,默認(rèn)盒子的尺度計算如下:
1.2.3 負(fù)樣本選取策略
經(jīng)過匹配后,很多默認(rèn)盒子是負(fù)樣本,這將導(dǎo)致正樣本、負(fù)樣本不均衡,訓(xùn)練難以收斂。因此,將負(fù)樣本根據(jù)置信度進(jìn)行排序,選取最高的幾個,并且保證負(fù)正樣本的比例為3:1。
2 基于SSD的臺標(biāo)檢測
總步驟為數(shù)據(jù)選取,臺標(biāo)數(shù)據(jù)格式轉(zhuǎn)換,臺標(biāo)檢測模型訓(xùn)練,臺標(biāo)檢測模型測試。現(xiàn)選取關(guān)鍵步驟進(jìn)行詳細(xì)介紹。
2.1 數(shù)據(jù)選取
在網(wǎng)上選取相同時間長度的79類237個視頻,抽取視頻圖像幀,對圖像幀中的臺標(biāo)進(jìn)行標(biāo)注,若圖右上角及正下方出現(xiàn)cctvl3,則一張圖像幀對應(yīng)的標(biāo)注格式即為cctv13{106, 20, 178, 20, 178, 67, 106, 67}; cctv13{369,319, 440, 319, 440, 345, 369, 345}。
2.2 臺標(biāo)格式轉(zhuǎn)換
對視頻圖像幀進(jìn)行臺標(biāo)結(jié)果標(biāo)注后,編寫程序?qū)?biāo)注結(jié)果進(jìn)行處理,將txt文本中數(shù)據(jù)按序轉(zhuǎn)換為XML格式。并編寫程序,將127 980個XML格式的文件打亂分成兩部分,其中95 586張用于模型訓(xùn)練,32 394張用于模型測試。
2.3 模型訓(xùn)練
編寫程序,將95 586個XML格式數(shù)據(jù)文檔及對應(yīng)的視頻圖像幀進(jìn)行編碼轉(zhuǎn)換為1 mdb格式,以便SSD進(jìn)行模型訓(xùn)練。
3 實驗結(jié)果與分析
3.1 實驗平臺
實驗所用平臺設(shè)備為:操作系統(tǒng):Ubuntix 14.04;GPU:NVIDIA GTX1080Ti;驅(qū)動:CUDA 8.0,軟件為caffe(SSD)+ Pycharm Community。
3.2 實驗結(jié)果
實驗選取圖像幀進(jìn)行模型測試,采用的是迭代80 000次模型進(jìn)行測試。
圖1是東方衛(wèi)視(dfws)新聞的截圖,算法對所有臺標(biāo)進(jìn)行了檢測并評分。
3.3 實驗對比
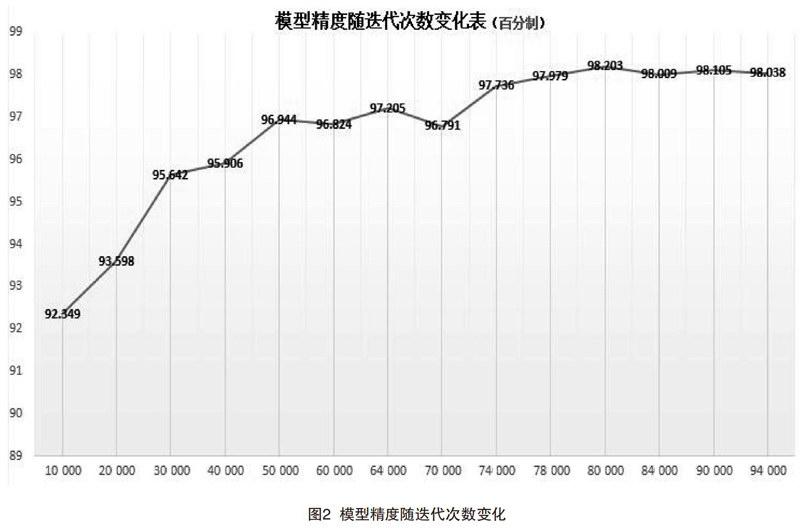
鑒于模型訓(xùn)練所需時間較長,故本文要求每訓(xùn)練2 000次,模型便進(jìn)行一次輸出,輸出到94 000代截止。對模型準(zhǔn)確率的統(tǒng)計如圖2所示。
我們發(fā)現(xiàn),模型大概迭代到80 000代基本達(dá)到收斂,準(zhǔn)確率達(dá)98.2%。
3.4 實驗總結(jié)
本文將當(dāng)下最前沿的深度學(xué)習(xí)技術(shù)與臺標(biāo)檢測這一工程實際問題相結(jié)合,經(jīng)過實驗,明顯提高了臺標(biāo)檢測的準(zhǔn)確率。
4 結(jié)語
臺標(biāo)檢測是網(wǎng)絡(luò)視頻審核的常用方法,但一直以來,很多算法在臺標(biāo)檢測的成功率上一直表現(xiàn)不佳。本文率先提出將基于深度學(xué)習(xí)的目標(biāo)檢測算法應(yīng)用于臺標(biāo)檢測,在進(jìn)行大量實驗后,臺標(biāo)檢測成功率有了明顯提升。此外,為了進(jìn)一步提高臺標(biāo)檢測的速度,以后會選取性能更好的GHJ進(jìn)行模型訓(xùn)練,以及擴(kuò)充樣本類別,使得可檢測的臺標(biāo)種類得到提升。
[參考文獻(xiàn)]
[1]吳月鳳,何小海,張峰.SURF算法和RANSAC算法相結(jié)合的臺標(biāo)檢測與識別[J].電視技術(shù),2014(13):191-195.
[2]王建,賀翼虎,周源華.新聞視頻靜態(tài)圖形標(biāo)識分割[J].上海交通大學(xué)學(xué)報,2006(5):758-761.
[3]史迎春,周獻(xiàn)中,方鵬飛.綜合利用形狀和顏色特征的臺標(biāo)識別[J].模式識別與人工智能,2005(2):216-222.
[4]鄧曄.深度學(xué)習(xí)技術(shù)與安防行業(yè)的超融合[J].中國安防,2017(5):26-30.
[5]LIU W, ANGUELOV D, ERHAN D, et al.SSD:single shot multibox detector[C].Amsterdam:European Conference on ComputerVision, 2016:21-37.
猜你喜歡
中國教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國遠(yuǎn)程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
