DeepRD:基于Siamese LSTM網絡的Android重打包應用檢測方法?
2018-09-12 02:20:44汪潤唐奔宵王麗娜
通信學報 2018年8期
汪潤,唐奔宵,王麗娜
?
DeepRD:基于Siamese LSTM網絡的Android重打包應用檢測方法?
汪潤1,2,唐奔宵1,2,王麗娜1,2
(1. 空天信息安全與可信計算教育部重點實驗室,湖北 武漢 430072;2. 武漢大學國家網絡安全學院,湖北 武漢 430072)
目前,Android平臺重打包應用檢測方法依賴于專家定義特征,不但耗時耗力,而且其特征容易被攻擊者猜測。另外,現有的應用特征表示難以在常見的重打包應用類型檢測中取得良好的效果,導致在實際檢測中存在漏報率較高的現象。針對以上2個問題,提出了一種基于深度學習的重打包應用檢測方法,自動地學習程序的語義特征表示。首先,對應用程序進行控制流與數據流分析形成序列特征表示;然后,根據詞向量嵌入模型將序列特征轉變為特征向量表示,輸入孿生網絡長短期記憶(LSTM, long short term memory)網絡中進行程序特征自學習;最后,將學習到的程序特征通過相似性度量實現重打包應用的檢測。在公開數據集AndroZoo上測試發現,重打包應用檢測的精準率達到95.7%,漏報率低于6.2%。
重打包;深度學習;孿生網絡;長短期記憶;安全與隱私
1 引言
Android和iOS作為移動應用市場的兩大主流平臺,截至2017年底,它們的官方應用商店Google Play和Apple Store上的移動應用數量已經超過了300多萬。近年來,移動平臺特別是Android平臺已經逐漸成為惡意軟件泛濫的重災區,給用戶的安全和隱私帶來了嚴重的威脅。
報告顯示,超過98%的移動惡意軟件來自Android平臺,在這些惡意軟件中,重打包應用超過了86%[1]。Android重打包應用示例如圖1所示。重打包應用是指惡意開發者在保持正常合法應用功能不變的前提下,通過添加、修改應用程序代碼或資源文件生成的非法應用。這類應用通過各種渠道讓用戶下載安裝使用,達到竊取用戶隱私、攻擊用戶設備等目的。獲取非法收益和傳播惡意軟件是開發者制造重打包應用的兩大動機。
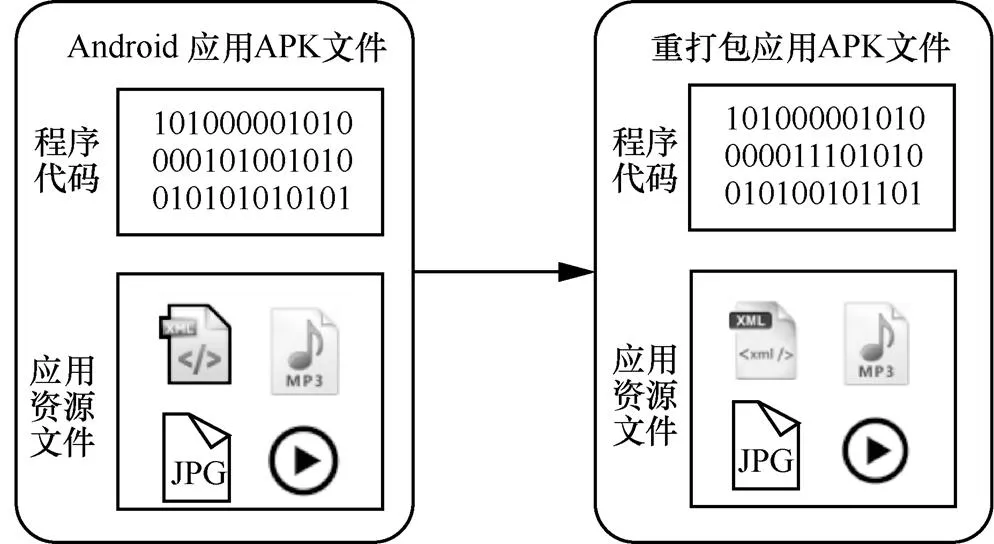
圖1 Android重打包應用示例
研究分析發現,Android平臺上重打包應用傳播廣泛的主要原因如下:①Android應用容易被反編譯修改,應用程序代碼的混淆程度低,反編譯后可讀性強;②Android平臺開放程度高,第三方應用市場沒有嚴格的審查機制,導致用戶可以隨意地安裝非官方應用商店的應用;③Android市場份額高,傳播惡意軟件可以獲取大量的非法收益。
為了構建健康的移動應用市場,國內外研究人員針對Android平臺的重打包應用展開了一系列的相關研究[2-9]。具體來說,分為以下2類:第一類是基于應用相似性比較的方法;第二類是基于重打包應用行為檢測的方法[10-14]。其中,第一類方法又可以分為基于代碼克隆的檢測和基于應用資源文件的檢測這2種方法,分別使用程序代碼特征如控制流圖(CFG, control flow graph)、程序依賴圖(PDG, program dependency graph)以及應用資源文件作為應用的特征表示。通過度量應用特征表示之間的相似性實現重打包應用的檢測。有研究發現,部分重打包應用中惡意的代碼片段與正常的代碼片段邏輯上獨立,但與正常的功能代碼片段交互性差。基于上述發現,研究人員提出了第二類基于重打包應用行為的檢測方法,提取可以表示正常代碼片段與惡意代碼片段行為差異的特征,然后訓練一個機器學習的分類模型實現重打包應用的檢測。
目前,重打包應用檢測方法共同存在的不足在于,這些方法都強烈地依賴專家的特征定義。第一類基于應用相似性比較的檢測方法,需要分析應用的程序代碼或資源文件來定義應用的特征表示;第二類基于重打包應用行為的檢測方法,也需要定義程序代碼的特征表示。然而,針對這類依賴專家特征定義的檢測方法,攻擊者可以通過試探的方法猜測特征表示,精心地構造惡意應用來繞過檢測[15-17]。此外,不同類型的重打包應用,能夠實現最佳檢測效果的應用特征表示也不同。例如,針對漢化等重打包應用,適用于基于應用資源文件特征表示的檢測方法;針對Piggy-packing應用[18]的檢測,則適用于基于重打包應用行為的檢測方法,分析Piggy-packing應用中注入的惡意組件和正常功能代碼在功能上的差異,利用代碼功能的差異抽取重打包應用檢測的特征表示。綜上,現有的依賴專家定義特征的檢測方法,難以定義一種通用的應用特征表示可以適用于所有的重打包應用類型檢測,這導致在實際檢測中存在漏報率高的問題。
針對現有的重打包應用檢測方法依賴于專家定義特征存在耗時耗力,且容易被攻擊者猜測出檢測的特征表示,通過精心構造惡意應用繞過檢測的問題以及現有方法在實際檢測中漏報率高的現象,本文提出一種基于深度學習的Android重打包應用檢測方法,借助于深度學習強大的特征學習能力[19],自動地學習應用的程序代碼特征,通過程序代碼的相似性度量實現重打包應用的檢測。深度學習在圖像識別[20]、語音識別[21]以及自然語言處理[22]等領域已經取得了突破性進展。相關學者利用深度學習研究安全領域中的一些重要問題并取得了非常顯著的效果[23-32],例如,漏洞檢測[23]、缺陷預測[25]、二進制分析[27-28]以及惡意軟件檢測[24,30-32]等。受這類工作的啟發,本文利用深度學習解決目前Android重打包應用檢測中面臨的依賴于專家定義特征表示和漏報率高這2個問題。然而,目前應用深度學習解決圖像識別、語音識別等方法并不能直接應用于重打包應用的檢測。在應用深度學習檢測重打包應用時,需要解決以下3個基本問題。
1) 應用分析與檢測的基本單元。在正常的合法應用基礎上添加完整組件以及部分代碼重用是構造重打包應用的2種主要方式。在Android重打包應用檢測時,不僅需要判斷一對應用是否為重打包應用,還需要識別出被重用的代碼片段。
2) 應用的向量表示。在深度學習模型的訓練及預測階段,模型的輸入都是向量。因此,需要將應用表示成向量的形式。本文利用深度學習檢測Android平臺的重打包應用,不能將應用表示成任意的向量形式,在應用向量表示時需要保留與應用相似性度量有關的程序語義信息。
3) 深度學習模型的選擇。深度學習在其他領域取得了顯著的效果,但是不同的深度學習模型擅長解決的問題不盡相同。本文中,通過程序代碼的相似性度量實現重打包應用的檢測,這類問題類似于自然語言處理中的文本相似性檢測。因此,選擇的深度學習模型應擅長序列特征數據的表示。
針對應用深度學習檢測Android平臺重打包應用中面臨的3個基本問題,本文提出將應用函數作為分析與檢測的基本單元,應用函數被表示成序列特征形式并進行向量化處理,然后輸入具有LSTM的Siamese網絡中學習程序代碼的語義特征,最后通過應用程序代碼的相似性度量判斷是否為重打包應用。本文中應用函數的序列特征及特征向量表示方法如下:首先,獲取應用函數中API的調用序列以及與API存在數據依賴關系的上下文信息形成應用函數的序列特征;然后,將應用函數的序列特征表示成抽象字符串形式;最后,使用詞向量嵌入模型將抽象字符串表示成向量形式輸入深度學習模型Siamese LSTM網絡中訓練。本文的主要貢獻如下。
1) 提出基于深度學習的Android重打包應用檢測方法,并基于該方法設計并實現一套原型系統DeepRD。利用Siamese LSTM網絡學習程序的語義特征表示,實現重打包應用的檢測。
2) 提出一種基于詞向量嵌入的應用函數向量化表示方法。利用應用函數的API調用序列及與API存在數據依賴的上下文信息來保留程序語義信息,使用詞向量嵌入模型生成應用的向量表示。
3) 在程序代碼的相似性度量中,本文使用2個LSTM網絡自動地學習程序代碼的序列特征表示,利用Siamese網絡度量程序代碼的相似性。
4) 在公開數據集AndroZoo[33]上驗證本文方法的有效性,實驗結果發現,本文方法可以達到檢測精準率為95.7%,漏報率低于6.2%。
2 相關工作
2.1 基于特征的重打包應用檢測
目前,重打包應用檢測方法強烈地依賴于專家定義應用的特征表示,主要分為以下2類方法:基于應用相似性比較的檢測方法和基于重打包應用行為的檢測方法。
基于應用相似性比較的檢測方法又可以分為基于代碼克隆的檢測方法[1,34-39]和基于應用資源文件的相似性檢測方法[40-43]。這2種方法分別將程序代碼的特征和應用資源文件的特征作為應用的特征表示,然后通過度量特征之間的相似性來判斷是否為重打包應用。DNADroid[34]和Andarwin[35]定義程序依賴圖作為應用的特征表示,程序依賴圖的頂點之間通過數據依賴建立關聯,挖掘應用之間的同構子圖來判定是否為重打包應用。ViewDroid[40]定義應用的用戶界面(UI, user interface)作為應用的特征表示,使用有向圖表示應用的用戶界面,圖的頂點表示應用的視圖,邊表示視圖之間可以通過事件調用進行切換。
基于重打包應用行為的檢測方法通過分析應用中正常的功能代碼片段與惡意插入的代碼片段在功能上的差異,定義代碼特征表示,然后訓練分類模型完成檢測。文獻[13]發現重打包應用中加載的惡意組件不是應用的核心代碼,使用基于PDG的模塊解耦技術將應用程序代碼分為核心模塊和非核心代碼,設計了一種特征指紋技術抽取核心模塊的語義特征,實現重打包應用的檢測。
以上基于特征的重打包應用檢測方法強烈地依賴于專家定義各種巧妙的特征,研究發現,攻擊者可以猜測檢測系統所使用的特征,然后通過精心地構造應用繞過檢測[15-17]。此外,現有的應用特征表示方法無法應用于所有的重打包應用類型的檢測中,導致在真實的檢測中產生報率高的問題。本文方法能夠有效地克服現有方法存在的以上不足,不但可以保證較高的檢測精準率,而且漏報率遠低于現有的檢測方法。
2.2 深度學習在網絡安全中的應用
近年來,有學者利用深度學習研究網絡安全中一些重要的問題,例如,漏洞檢測、缺陷預測、二進制程序分析、惡意軟件檢測等,特別是在惡意軟件檢測方面取得了一系列重要的研究成果。Droid-Sec利用靜態分析和動態分析技術提取了200多個移動應用特征,通過訓練一個深信念網絡(DBN, deep belief network)檢測Android惡意應用[24]。DeepSign提出一種基于DBN的惡意軟件特征自動生成及分類檢測方法,捕獲程序在沙箱中運行的行為數據作為DBN的輸入,來識別未知的惡意軟件[31]。Deep4MalDroid通過動態地運行Android應用,獲取應用在執行過程中的動態行為特征(Linux內核層的系統調用),然后將Linux內核層的系統調用表示成帶有權重的有向圖輸入棧式自動編碼器(SAE,stacked auto encoder)中,自動地學習Android惡意應用的特征來檢測未知的惡意應用[32]。
以上這些方法均面向通用的惡意軟件檢測,并將獲取應用的惡意行為特征作為深度學習模型的輸入。這些方法并不適用于本文的重打包應用檢測,主要體現在以下2點:①這些方法均將惡意軟件的檢測看作一個分類問題,而本文研究的是應用的相似性判定問題;②重打包應用的行為與正常合法應用的行為相似,因此上述基于惡意行為的建模方法并不適用于重打包應用的檢測。
本文受到以上工作的啟發,應用深度學習解決Android平臺的重打包應用檢測問題,豐富了深度學習在安全領域中的應用。
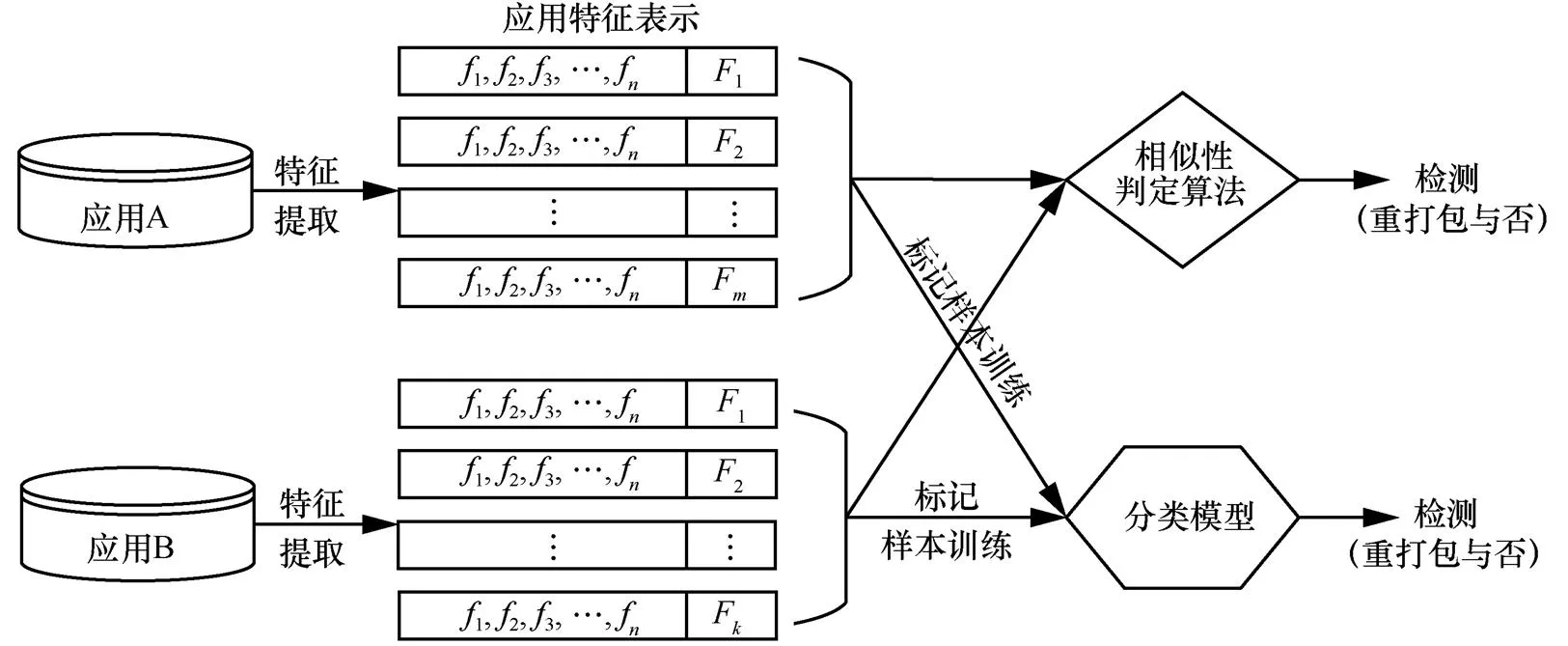
圖2 重打包應用檢測方法示意
3 相關背景知識
3.1 Android重打包應用
重打包應用檢測的2類典型方法如圖2所示。一類方法是基于應用相似性的比較,通過定義應用特征的相似性計算函數,設置閾值來判定是否為重打包應用;另一類方法是抽取重打包應用的行為特征,然后使用大量的重打包應用和原應用的標記樣本訓練分類模型,最后利用訓練好的分類模型預測一對應用是否為重打包應用。本文方法屬于第一類,通過度量應用的相似性來判定是否為一對重打包應用,但是本文中用于應用相似性度量的特征是通過自動學習得到的。
3.2 循環神經網絡
循環神經網絡(RNN, recurrent neural network)是一種擅長處理序列數據的人工神經網絡。近年來,RNN也被應用于程序分析的相關領域[27-28]。RNN與傳統神經網絡的不同在于,隱藏層的節點之間有連接,隱藏層的輸入包括輸入層的輸出和上一時刻隱藏層的輸出。隱藏層第步狀態h的計算式為
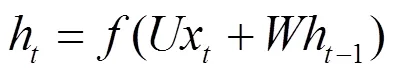
其中,x為第步的輸入,為非線性激活函數,如tanch或ReLU等,、為訓練中共享的權重。由于RNN模型在訓練過程中依賴前面步驟的數據,因此,RNN會隨著序列長度的增加存在梯度消失或梯度爆炸等問題。因此,有學者提出LSTM和GRU(gated recurrent unit)模型。相比于GRU模型,LSTM模型更適用于序列數據的建模。LSTM的長時間記憶網絡特性,使其能夠有效地應用于程序分析等相關領域,本文使用LSTM學習應用程序的序列特征表示。
4 總體設計
本文旨在研究一種不依賴于專家特征定義的重打包應用檢測方法,降低現有方法在實際檢測中存在的高漏報率現象。本節具體描述文中方法DeepRD的總體設計,首先討論在DeepRD設計與實現時面臨的3個基本問題。
1) 應用分析與檢測的基本單元
針對本文重打包應用檢測的兩大目標:判斷一對應用是否為重打包應用;識別被重用的代碼片段,將應用整體作為分析與檢測的單元存在無法識別出被重用的代碼片段的問題。研究發現,超過86.2%的重打包應用是通過修改應用函數的程序代碼生成的。實驗驗證發現,將應用整體作為基本分析與檢測的單元,會存在漏報率高以及檢測精準率低等問題。因此,本文使用應用函數作為分析與檢測的基本單元可以滿足文中細粒度分析的需要。
2) 應用的向量表示
本文將應用函數表示成序列特征的形式,使用詞向量嵌入模型將序列特征進行向量化表示。抽取平臺API及其存在數據依賴的上下文信息,根據API的調用序列形成序列特征表示,可以保留程序的語義信息。此外,基于數據依賴的程序代碼特征表示,可以有效地抵御攻擊者在應用程序中插入代碼、修改代碼順序等攻擊操作。
3) 深度學習模型的選擇
在應用的向量表示中,本文將應用函數表示成序列特征形式。RNN被廣泛地應用于自然語言處理的相關任務中,擅長序列數據的建模。此外,研究顯示RNN在程序分析方面也取得了不錯的效果。3.2節提到在序列長度增加時,RNN會存在梯度消失或爆炸的問題。因此,本文使用LSTM網絡學習程序的序列特征表示,利用Siamese網絡度量特征的相似性。
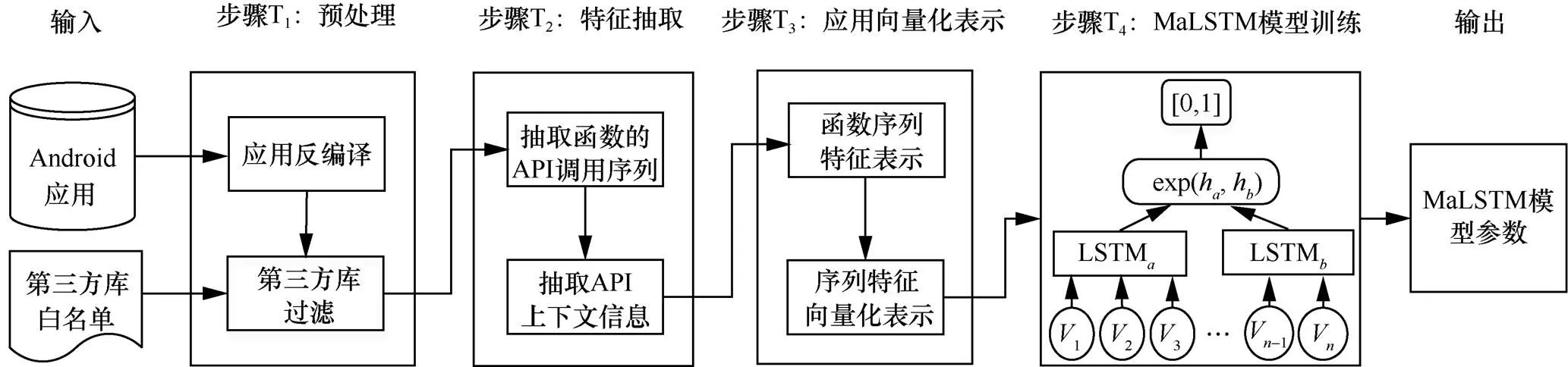
圖3 DeepRD框架—訓練階段
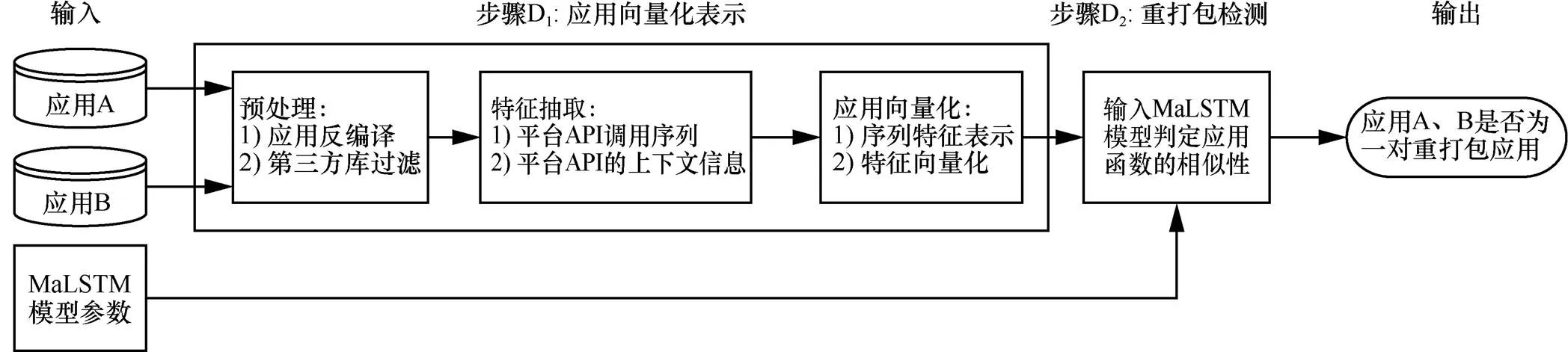
圖4 DeepRD框架—檢測階段
DeepRD主要包括模型訓練和重打包應用檢測這2個階段,分別如圖3和圖4所示。圖3為DeepRD的訓練階段,輸入大量的第三方重打包應用對以及第三方庫的白名單,輸出訓練好的應用函數相似性度量模型。訓練階段主要包括Android應用的預處理、特征抽取、應用向量化表示以及MaLSTM模型訓練這4個步驟。MaLSTM模型是一種用于處理變長序列數據的Siamese LSTM網絡。圖4為DeepRD的檢測階段,輸入為2個待檢測的應用,與訓練階段相似,也包括預處理、特征抽取和應用向量化表示等步驟,然后利用訓練好的MaLSTM模型度量應用函數的相似性來判斷是否為重打包應用。各步驟具體描述的內容如第5節所示。
5 DeepRD方法
5.1 預處理
Android應用安裝(APK, Android package)文件主要由程序代碼dex文件和應用資源文件構成。在預處理階段的應用反編譯是為了獲取APK文件的程序代碼,提取應用函數的特征,生成應用的向量表示。為了提高開發效率或實現應用的某些功能要求,程序開發人員在編寫Android應用程序時,會大量地調用第三方庫,如廣告庫和功能庫等。
由于第三方庫在應用中占用了一定比例的程序代碼片段,因此在本文基于程序代碼相似性度量的重打包應用檢測方法中,第三方庫會嚴重地影響檢測的效果,并在某種程度導致誤報。為了降低檢測中由于第三方庫帶來的誤報,本文使用白名單過濾應用中的第三方庫。
5.2 特征抽取
深度學習模型的輸入都是向量,在應用向量化表示時,需要保留應用程序的語義信息用于程序代碼片段的相似性度量。本文重打包應用分析與檢測的基本單元是應用函數,因此本文抽取應用函數的特征形成應用的特征表示。
本文抽取的特征用于判定應用的相似性,抽取的程序特征應滿足以下基本條件:①特征應包含有應用的語義信息且可分辨性強,相似的程序片段特征相似,不同的程序片段特征差異明顯;②特征易抽取,不依賴于復雜的靜態分析方法,且可抵御常見的代碼混淆攻擊。基于以上程序特征表示中需要滿足的2個基本條件,本文提出了一種基于平臺API調用序列的特征表示方法,抽取平臺API及其存在數據依賴的上下文信息作為程序的特征表示。
Android應用的惡意行為總是與平臺API的不合理使用有關,特別是與應用權限申請有關的敏感API有密切的聯系,它們在惡意應用中被開發者頻繁地調用以達到某些非法的目的。一些研究中將API的調用序列作為惡意應用檢測的特征[44-45]。另外,有研究發現,惡意開發者在修改或插入惡意代碼生成重打包應用時,也會頻繁地調用平臺API,收集用戶的隱私數據或執行其他敏感的惡意操作等[11]。基于以上2點啟發,本文提出了基于API調用序列的特征表示方法。該特征表示方法有如下優點:①平臺API在程序分析中不易受到代碼混淆的影響;②平臺API調用序列提取簡單,不依賴于復雜的靜態分析方法;③API的上下文信息保留了程序的語義信息,且基于數據依賴的平臺API上下文信息可以防御代碼插入等攻擊[34-35];④定義API的上下文信息作為應用的特征表示,還可以抵御攻擊者通過修改API的調用順序,實施針對深度學習模型的對抗攻擊。
特征抽取階段主要包括抽取函數的API調用序列和抽取API的上下文信息這2個步驟,如圖3中步驟T2特征抽取所示。下面詳細描述這2個步驟。
1)抽取函數的API調用序列
Android應用開發包括基于SDK(software development kit)的Java語言開發和基于NDK(native development kit)的C/C++語言開發這2種,NDK開發主要用于在APK文件中可以調用由C/C++語言編寫生成的so文件。本文僅考慮修改Java語言生成的重打包應用,且目前尚未有研究發現通過修改C/C++語言生成的重打包應用。因此,本文特征抽取階段分析的API包括Android平臺SDK中的庫和API以及Java平臺JDK中的庫和API。本文通過靜態的控制流分析,獲取應用函數中API的調用序列。
2)抽取API的上下文信息
在應用程序中,語句之間的關系主要分為數據依賴和控制依賴這2種形式。數據依賴是指如果語句數據依賴于,則中有變量的值取決于語句。本文API的上下文信息是指與API在函數體中存在數據依賴的語句,這里的數據依賴包括前向數據依賴和后向數據依賴這2種,如圖5所示。
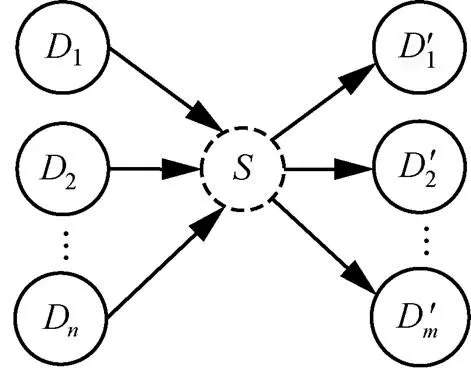
圖5 平臺API的上下文信息示意
在圖5中,為API調用序列中的元素,語句1,2,…,D均數據依賴于,數據依賴于1,2,…,D'。本文用表示的前向數據依賴語句集合,={1,2,…, D};表示的后向數據依賴語句集合,={1,2,…, D'}。本文平臺API及其上下文信息表示為一個三元組的形式,即=<,,>。
在特征抽取階段,API及其上下文信息特征表示為本文深度學習模型輸入的基本單元。本文抽取的程序特征包含程序的語義信息,還可以抵御針對深度學習模型的對抗攻擊。接下來,具體介紹如何將該階段抽取的特征形成應用函數的序列特征并進行向量化表示。
5.3 應用向量化表示
在應用向量化表示中,根據5.2節特征抽取方法形成應用函數的序列特征,然后使用詞向量嵌入模型對應用函數的序列特征進行向量化表示。具體分為函數序列特征表示和序列特征向量化表示這2個部分的內容。接下來,對其進行詳細描述。
1) 函數序列特征表示
在Android應用中,開發人員調用大量的平臺API實現應用的功能需求。應用函數中API的調用順序可用于形成函數的序列特征表示,一些研究將API的調用順序作為惡意軟件檢測的特征。本文則通過靜態的控制流分析獲取應用函數中API的調用序列,然后根據5.2節API上下文信息的提取方法,形成應用函數的序列特征表示。函數序列特征表示如算法1所示。
算法1 函數序列特征表示算法
輸入 應用函數的程序代碼
輸出 應用函數的序列特征表示
1)_=();
/*獲取應用函數的API調用序列*/
2) forin_
3)_=(); /*獲取的前向數據依賴語句*/
4)_=(); /*獲取的后向數據依賴語句*/
5)=<_,,>;/*平臺API及其上下文信息的特征表示*/
6); /*將放入序列特征表示中*/
7) end for
8) return
本文使用表示應用函數的序列特征表示,=(1,2,…,V,…,V),其中,V表示應用函數API調用序列中API的特征表示,V=<,,>,表示函數中調用平臺API的語句,和表示與存在數據依賴關系的語句。
2)序列特征向量化表示
在獲取應用函數的序列特征表示后,生成序列特征的向量化表示作為本文深度學習模型的輸入。序列特征向量化表示主要包括以下幾個步驟:首先,將函數序列特征進行符號化表示;然后,對符號化表示的特征進行抽象化字符串表示;最后,利用詞向量嵌入模型對其進行向量化表示,如圖6所示。接下來,具體描述這3個步驟的細節內容。
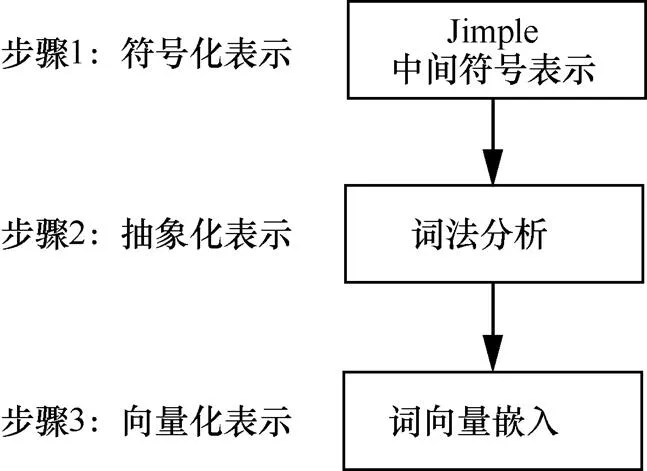
圖6 應用向量化表示步驟
在符號化表示中,將應用函數的序列特征用Jimple中間符號表示。Jimple[46]是Java字節碼的一種抽象表現形式,相比于Java字節碼和Dalvik字節碼均超過200條指令,Jimple只有15條指令,常用于簡化程序的靜態分析。在本文的特征抽取中,將Dalvik字節碼轉化為Jimple中間符號表示,然后對Jimple中間符號表示的應用函數進行靜態的程序分析,抽取應用函數中API調用序列和數據依賴關系。本文選擇Jimple作為序列特征的符號表示是為了簡化應用的向量表示。
在抽象化表示中,通過詞法分析將應用函數的Jimple中間符號表示轉化成抽象字符串表示。在詞法分析中,針對自定義的對象、變量以及函數的處理方式如下:①針對用戶自定義的數據結構或對象,字符串抽象表示為常量STR;②針對用戶自定義的變量,字符串抽象表示為常量VAR;③針對用戶自定義的函數調用,字符串抽象表示為常量FUNC。
在向量化表示中,將應用函數的字符串抽象表式利用詞向量嵌入模型轉化為向量形式,輸入深度學習模型中進行訓練與特征學習。下面介紹應用函數中API調用的一個抽象字符串描述簡化案例。
VAR=staticinvoke
上述案例中,該抽象字符串分割為“VAR”“=”“staticinvoke”“<”“parseInt”“>”“(”“VAR”“)”“;”這10個字符串形式。然后,使用Word2Vec詞向量嵌入模型將分割的10個字符串生成相應的向量表示。
5.4 模型訓練
在應用函數的特征抽取和向量表示中,每個函數的特征向量長度不同,本文使用MaLSTM模型處理變長的序列特征數據,如圖7所示。MaLSTM是具有LSTM的Siamese網絡,它由2個平行的LSTM網絡構成[47]。Siamese網絡用于度量2個輸入特征的相似性,MaLSTM將Siamese中用于特征表示的網絡替換成LSTM網絡,使其適用于序列數據的學習,更加切合本文的研究問題。接下來,詳細介紹Siamese網絡和MaLSTM模型的工作原理。
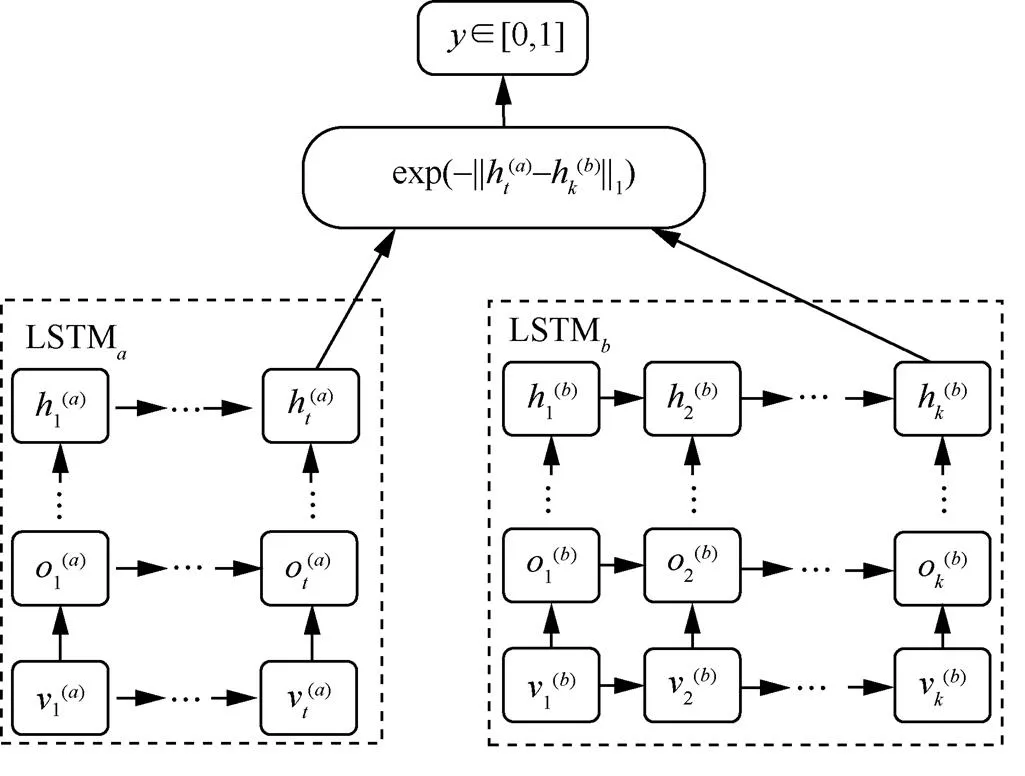
圖7 MaLSTM結構
1) Siamese網絡
Siamese網絡[48]是一種應用廣泛的特征相似性度量方法,它由2個結構相同的網絡組成,這2個網絡共享相同的權值,如圖8所示。Siamese網絡常用于解決標簽樣本缺乏情況下的模型訓練問題,它通過從數據中學習樣本的相似性度量,然后與未知的標簽樣本進行比較。Siamese網絡使用一個函數將特征輸入映射到目標空間,然后使用距離函數進行相似性對比。在圖8中,N和N為結構相同的網絡,輸入1和2分別被映射為N(1)和N(2),1和2相似性度量為E(N(1),N(2))。在Siamese網絡訓練階段,采用的優化策略是最小化相同類別樣本的損失函數值和最大化不同類別樣本的損失函數值。
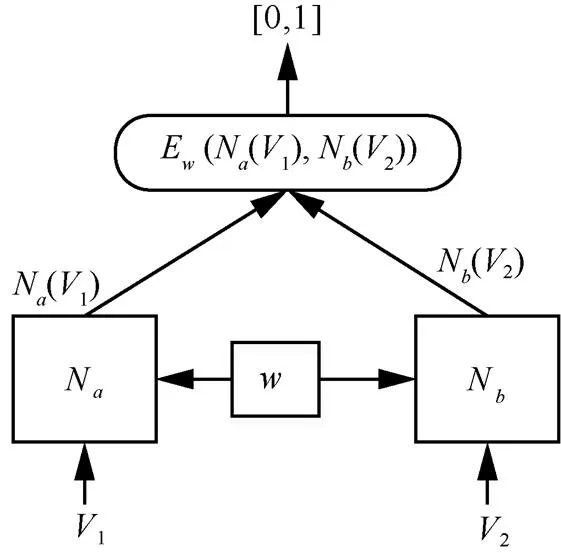
圖8 Siamese網絡結構
2) MaLSTM模型
MaLSTM是由2個結構相同的LSTM網絡組成的Siamese網絡,其中,LSTM和LSTM的權重參數相同,如圖7所示。MaLSTM的相似性度量函數定義為一階范數的指數函數,如式(2)所示。
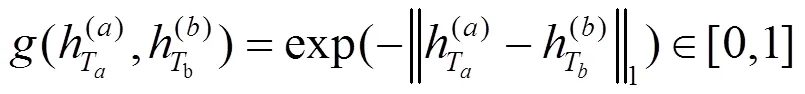
其中,和分別表示輸入LSTMa和LSTMb網絡中最后學習到的特征表示。LSTMa和LSTMb網絡的輸入分別為和,其中,Ta≠Tb。LSTM網絡中的記憶單元組成如圖9所示。LSTM記憶單元通過輸入門it、輸出門ot、遺忘門ft等控制信息的傳遞,最終輸出的ht由式(3)~式(8)計算得出。
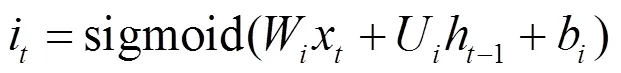
(4)
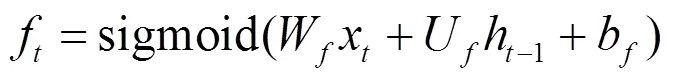
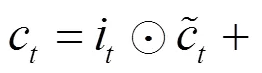
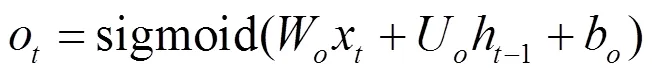
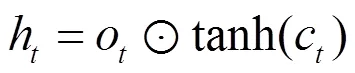

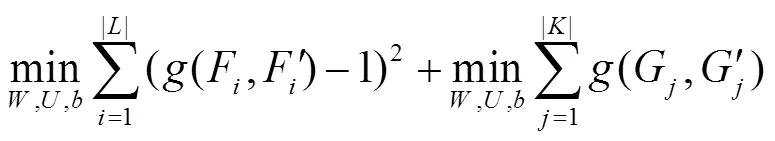
本文使用BPTT算法訓練MaLSTM模型的Siamese網絡,使用均方差(MSE, mean squared error)作為損失函數。通過輸入大量的標記樣本訓練模型參數,將訓練好的模型用于應用函數的相似性度量,通過應用函數的相似性比較判定是否為重打包應用。
5.5 重打包應用檢測
本文方法的訓練階段是為了訓練Siamese LSTM網絡,用于度量應用函數的相似性。測試階段是利用訓練好的模型,通過度量應用函數的相似性,來判斷一對應用是否為重打包應用。
本文方法DeepRD檢測階段(如圖4所示)的步驟D1“應用向量化表示”與訓練階段(如圖3所示)的前3個步驟類似,包括預處理、特征抽取和應用向量化表示。首先,將輸入的3個應用進行預處理,反編譯獲得應用的程序代碼并過濾第三方庫;然后,抽取應用函數的程序特征表示;最后,將應用函數表示成序列特征形式,利用詞向量嵌入模型進行特征向量化表示。檢測階段的步驟D2“檢測”是利用已經訓練好的MaLSTM模型度量應用函數的相似性,然后判斷輸入的一對應用是否為重打包應用。
本文使用應用函數作為分析與檢測的基本單元,通過細粒度的代碼相似性度量來判斷應用的相似性,檢測重打包應用以及識別被重用的代碼片段。本文基于應用函數相似性度量的重打包應用檢測中,需要考慮以下2個因素:①應用中相似函數的個數或比例;②相似應用函數的規模。應用1和應用2的相似性度量如式(10)~式(14)所示。
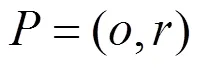
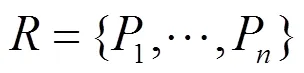
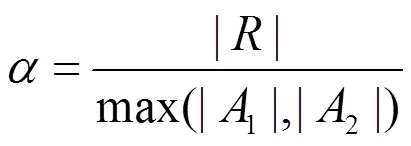

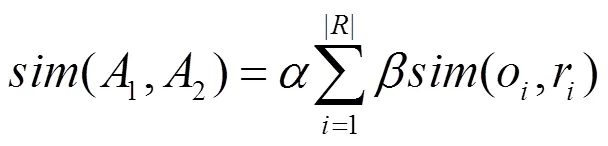
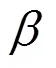
6 實驗與結果分析
6.1方法實現
本文基于深度學習的Android重打包應用檢測的實驗部分主要包括以下4個部分。
1) Android應用APK文件反編譯。Android平臺的每個應用都有唯一的簽名,惡意開發者在修改合法應用重新編譯生成新應用發布時,其應用的簽名信息一定會改變。本文使用Keytool獲取應用的簽名信息,作為唯一的標識區分應用。Apktool用于反編譯應用的APK文件,獲取應用的程序代碼。
2) 應用程序第三方庫過濾。第三方庫主要包括廣告庫和功能庫這2種,本文使用文獻[49]提供的1 113個功能庫和240個廣告庫建立白名單,用于過濾應用中的第三方庫。
3) 特征抽取及應用向量化表示。本文使用soot將Dalvik字節碼轉化為Jimple中間符號表示,然后通過控制流與數據流分析,獲取應用函數的API調用序列及與API存在數據依賴關系的上下文信息。
4) MaLSTM模型實現與訓練。本文基于TensorFlow和Keras實現Siamese LSTM網絡,用于度量應用函數的相似性。
6.2 實驗環境與數據來源
本文實現了基于深度學習的Android重打包應用檢測原型系統DeepRD,具體的實驗環境為CPU Intel(R) Core(TM) i7-6700K 4 GHz,64 GB內存,2塊GPU顯卡NVIDA Titan X Pascal,每塊顯卡的顯存為12 GB,1 TB SSD,操作系統為Ubuntu16.04。
本文的實驗數據來自公開的實驗數據集AndroZoo[33]。該數據集中提供了大量重打包應用的標記樣本數據,在本文模型的訓練及預測階段使用AndroZoo提供的15 297對重打包應用,其中,原始的正常合法應用共計2 776個,重打包應用共計15 297個。
實驗數據集中APK文件的大小分布如圖10所示。實驗中APK文件最小為50 KB,最大為123.5 MB。超過88%的APK文件大小在20 MB以內,超過79%的APK文件大小超過1 MB。實驗樣本數據總量達到147 GB,應用函數的個數超過40萬個。
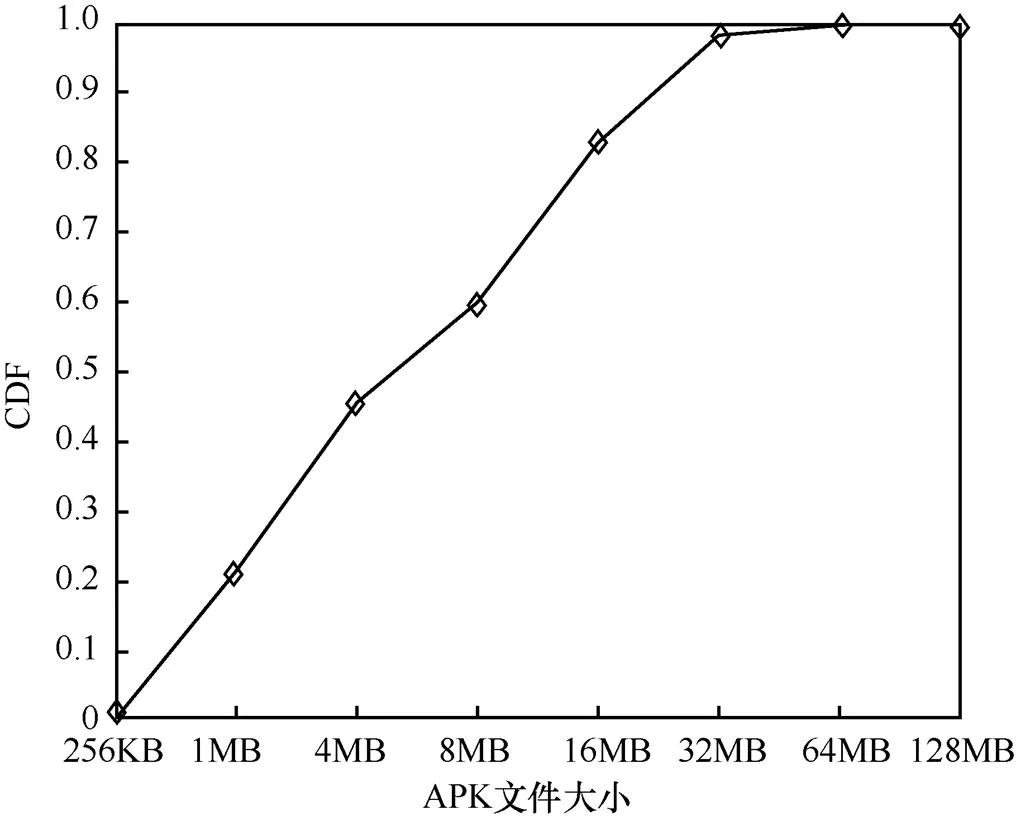
圖10 實驗數據集中APK文件的大小分布
6.3 實驗結果分析
本文從重打包應用檢測的效果以及特征表示的有效性這2個方面評價本文方法。因此,本文實驗評價中回答以下2個問題:①本文方法的精準率和漏報率分別是多少,是否優于現有方法?②本文提出的應用函數序列特征表示方法是否有效?
在實驗效果評價中,本文使用漏報率、召回率、精準率以及精準率和召回率的調和平均值-這4個指標來評價本文方法DeepRD的有效性,其中,= 1?。本文4個評價指標的具體計算方法為
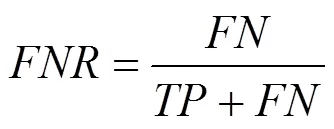
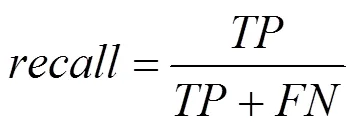
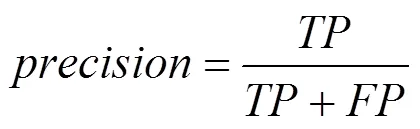
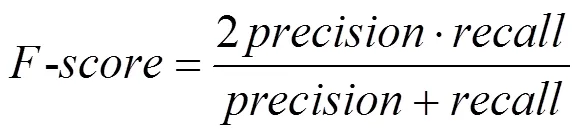
其中,各參數的具體含義為:真陽性(TP, true positive)、假陽性(FP, false positive)、真陰性(TN, true negative)、假陰性(FN, false negative)。
在本文重打包應用檢測中,漏報率越接近0,精準率越接近1,表明本文方法的檢測效果越好。
1) 本文檢測方法的精準率與漏報率分析
本文主要從檢測的精準率和漏報率這2個方面來說明本文方法的有效性。在實驗結果評價中,在公開數據集AndroZoo上將DeepRD與SPRD[50]進行對比,分別從、、和這4項指標來評價2種方法的有效性。
SPRD是一種用于檢測第三方Android應用市場重打包應用的方法,該方法針對現有的檢測方法在實際應用中存在難以有效均衡檢測速度、精準率以及資源開銷這3個方面的問題,提出了一種基于應用UI和程序依賴圖的重打包應用快速檢測方法。并利用重打包應用UI結構相同或相似的特點,設計了一種應用UI抽象表示的散列快速相似性檢測方法,識別出可疑的重打包應用,然后將應用程序依賴圖作為應用的特征表示,實現應用的細粒度相似性比較。但是,該方法并不適用于基于部分代碼復用方式生成的重打包應用。
實驗中,根據以往的經驗,隨機地選擇了70%的數據作為訓練數據,30%的數據作為測試數據。本文模型訓練時隱藏層數=4。圖11和圖12分別表示漏報率及與隱藏層數的關系。從圖11和圖12可以看出,當層數為4時,漏報率最低;當層數為5時,最高。其中,綜合考慮了和。本文目標是為了保持低漏報率,當隱藏層數設置為4和5時,只相差1%左右。因此,本文中隱藏層數設置為4是合理的。
實驗中,根據上述的模型參數設置,通過10折交叉驗證得到本文方法DeepRD與SPRD在數據集AndroZoo的最終對比結果如表1所示。
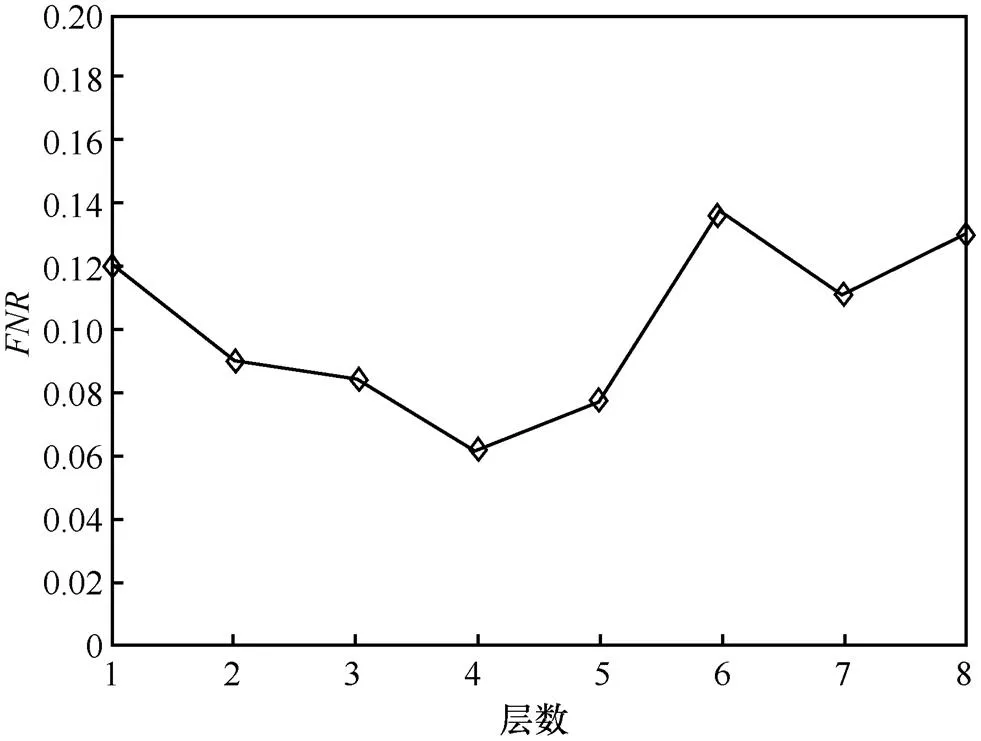
圖11 漏報率與隱藏層數關系
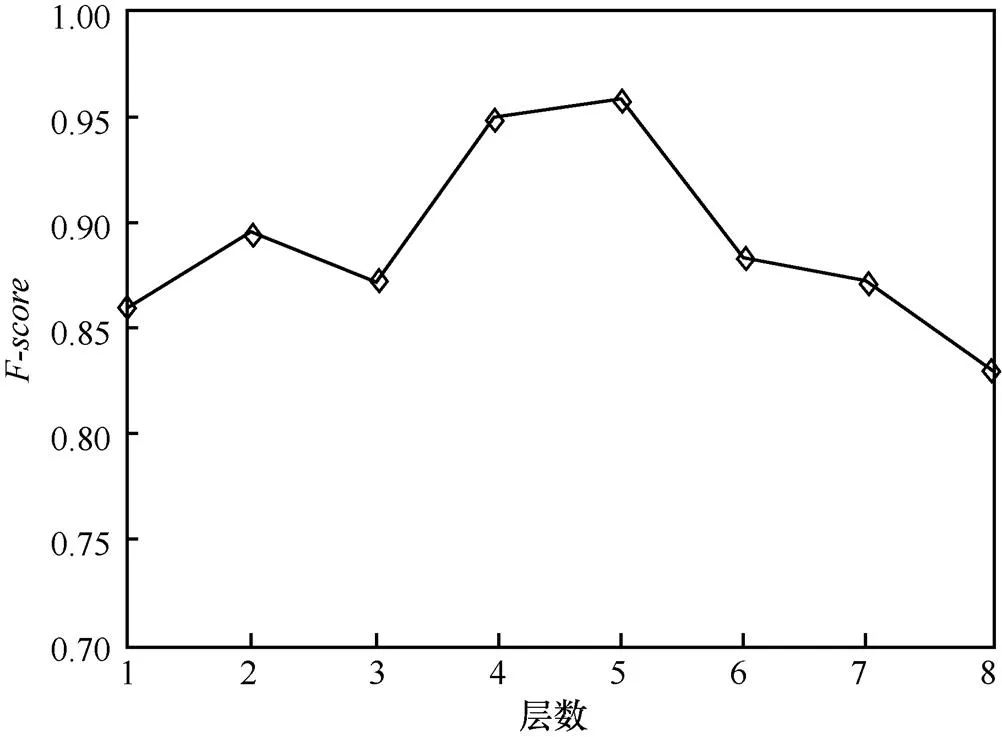
圖12 F-score與隱藏層數關系
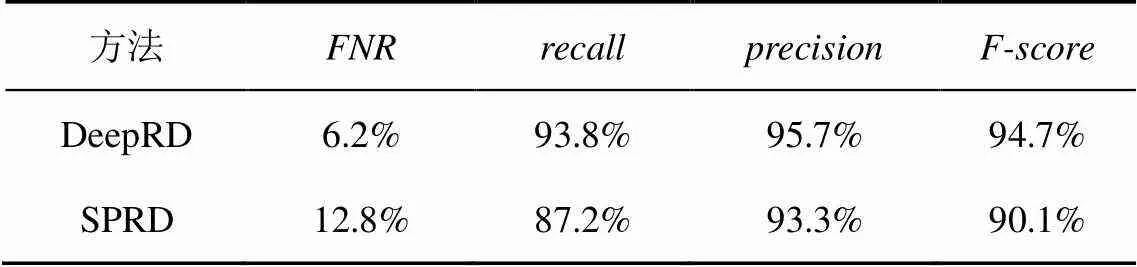
表1 實驗對比結果
從表1可以看出,本文方法DeepRD在真實數據集上測試的漏報率低于SPRD。實驗結果顯示,DeepRD的檢測精準率達到95.7%,漏報率低于6.2%,可以有效地應用于Android應用市場的重打包應用檢測,還可以有效地應對現有重打包應用檢測中漏報率高的問題。
實驗中,通過人工分析SPRD的漏報樣本發現,一些通過程序代碼復用生成的重打包應用的UI不同,SPRD方法無法有效識別,造成了漏報的現象。
2) 本文函數序列特征表示的有效性分析
本文抽取應用函數的序列特征,利用詞向量模型對序列特征進行向量化表示,輸入模型中進行訓練和學習。最后,通過應用函數的相似性度量來檢測重打包應用。本節主要分析本文特征提取方法對于降低漏報率和提高是否有效。
在討論函數序列特征表示的有效性問題時,本文將應用函數表示成任意的特征表示。在實驗中,本文采取2種處理方式。第一種方式將應用函數當成一個完整的字符串來處理,不考慮任何的程序語義信息。是應用函數的特征表示,=(1,2,…,y,…,y),其中,y是將應用函數的完整字符串按照空格進行分割得到的元素,然后利用詞向量嵌入模型對進行特征向量化表示,輸入深度學習模型中進行訓練和學習。第二種方式是僅抽取應用函數調用的API序列,沒有獲得API的上下文信息,向量化表示等與本文方法相同。
實驗中基于相同的訓練與測試數據集,根據以上3種特征表示對模型進行訓練與參數學習。將DeepRD的序列語義特征表示與其他2種特征表示進行比較,實驗結果如表2所示。
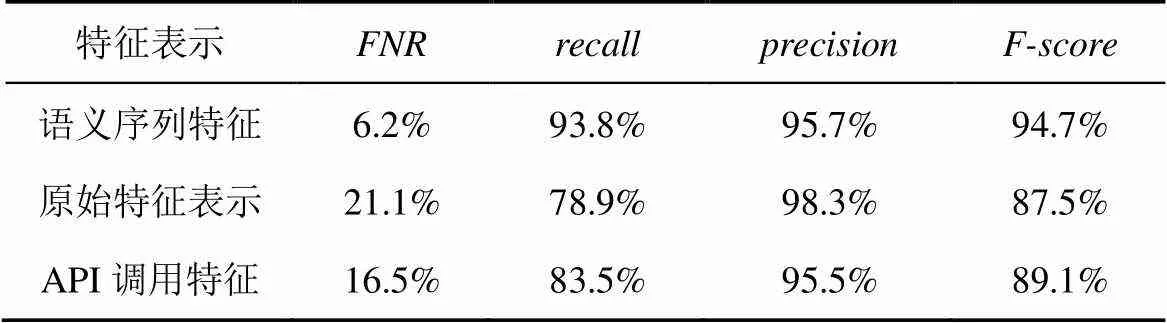
表2 特征對比實驗結果
在表2中,語義序列特征是指本文提出的特征表示方法,原始特征表示是指將應用函數當成完整字符串生成的特征,API調用特征是指獲取應用函數的API調用形成的序列特征。從表2可以看出,如果對應用函數進行任意的特征表示,再利用深度學習模型進行程序特征學習,并不能取得比較好的檢測效果。本文的特征表示方法在漏報率和這2項指標上均優于其他2種特征表示方法。因此,本文的函數序列特征表示方法能夠有效地應用于重打包應用檢測中,相比于任意的程序特征表示方法,可以明顯地降低漏報率和提高。
利用本文基于深度學習的重打包應用檢測系統DeepRD,分析目前國內外主流Android應用市場的重打包應用情況,特別是國內的應用市場。實驗中,我們針對每一個應用市場隨機地下載1萬個應用進行檢測,這5個應用市場的重打包應用分布情況如表3所示。
通過表3可以看出,Android官方應用商店Google Play以及各大手機廠商的應用商店如小米、華為等,由于嚴格的審查機制,重打包應用的比例少。但是,Android應用市場上卻存在大量的重打包應用,通過分析發現,在Android應用市場上,有超過7.8%屬于漢化破解類的重打包應用。
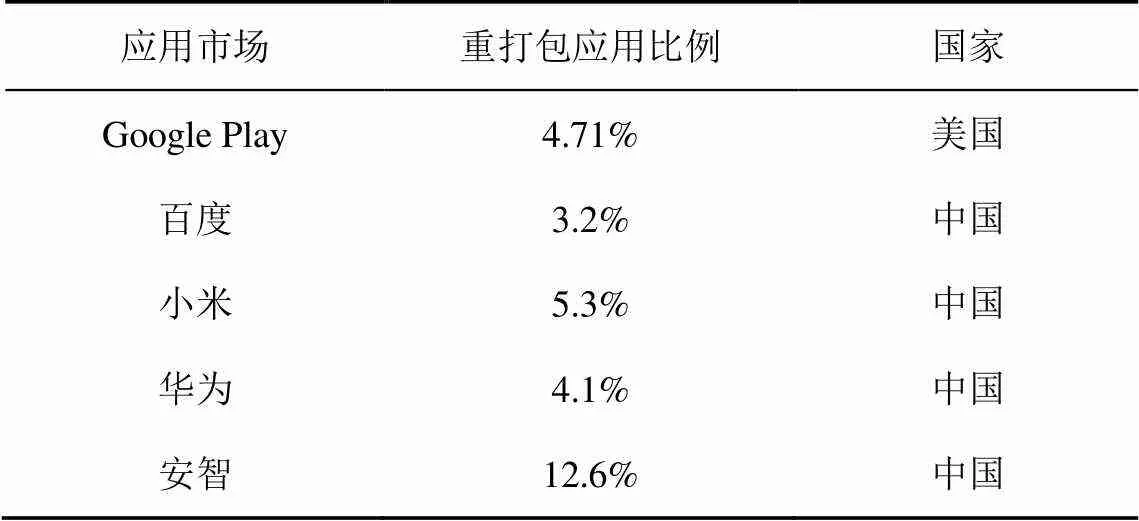
表3 國內外主流應用市場重打包應用的比例
6.4 相關討論
本文方法能夠有效地應用于Android平臺的重打包應用檢測,相比于傳統的檢測方法可以明顯地降低漏報率,但依然存在一些不足或需要改進的地方。主要體現在以下4個方面。
1) 在本文方法的預處理階段,使用白名單過濾第三方庫在應用相似性比較中會帶來干擾。但是由于收集的第三方庫由文獻[49]提供,因此會存在不完備的問題,在檢測中會導致一些誤報。針對第三方庫的完備性問題,可以通過網絡或其他渠道收集更多的第三方庫來擴充白名單。
2) 本文中程序分析對象應用的是Java代碼,沒有分析由C/C++語言編寫的本地代碼。因此,針對修改本地代碼生成的重打包應用,本文方法無效。但是,目前尚未發現由修改本地代碼生成的重打包應用樣本。
3) 本文的模型訓練階段需要標記樣本的支撐。然而,安全領域的標記樣本是極其寶貴的資源。因此,在未來的工作中研究不依賴于標記樣本的學習模型,或在只有少量標記樣本的情況下,也能取得非常好的效果。
4) 在應用向量表示及深度學習模型實現方面,本文抽取應用函數的序列特征并進行向量化表示,使用Siamese LSTM網絡學習應用程序的語義特征。在未來的工作中,研究其他深度學習模型在重打包應用檢測方面的應用,例如深信念網絡等。
7 結束語
針對目前Android重打包應用檢測方法存在依賴于專家定義特征和漏報率高的問題,本文提出了一種基于深度學習的Android重打包應用檢測方法。該方法以應用函數為基本的分析與檢測單元,通過程序的控制流與數據流分析,獲取應用函數的序列特征表示,利用詞向量模型生成應用的向量表示,然后輸入Siamese LSTM網絡中自動地學習應用程序的語義特征,通過程序代碼的相似性度量實現重打包應用的檢測。實驗結果表明,本文方法不依賴于專家定義應用的特征表示,并且能夠有效地檢測Android重打包應用,相比于傳統的基于特征定義的檢測方法,本文方法可以明顯地降低檢測的漏報率。
本文工作表明,深度學習可以有效地應用于Android重打包應用檢測以及程序分析等相關領域。在未來工作中,準備將深度學習方法應用于其他類型的Android惡意軟件檢測中,如隱私泄露、權限濫用等,目前,這類惡意軟件的檢測依然依賴于復雜的靜態分析或動態分析等方法。
[1] ZHOU W, ZHOU Y J, JIANG X X, et al. Detecting repackaged smartphone applications in third-party Android marketplaces[C]//The Second ACM Conference on Data and Application Security and Privacy. 2012: 317-326.
[2] 卿斯漢. Android 安全研究進展[J]. 軟件學報, 2016, 27(1): 45-71. QING S H. Research progress on Android security[J]. Journal of Software, 2016, 27(1): 45-71.
[3] 文偉平, 梅瑞, 寧戈, 等. Android 惡意軟件檢測技術分析和應用研究[J]. 通信學報, 2014, 35(8): 78-86. WEN W P, MEI R, NING G, et al. Malware detection technology analysis and applied research of Android platform[J]. Journal on Communications, 2014, 35(8): 78-86.
[4] 張玉清, 王凱, 楊歡, 等. Android安全綜述[J]. 計算機研究與發展, 2014, 51(7): 1385-1396. ZHANG Y Q, WANG K, YANG H, et al. Survey of Android OS security[J]. Journal of Computer Research and Development, 2014, 51(7): 1385-1396.
[5] 張玉清, 方喆君, 王凱, 等. Android 安全漏洞挖掘技術綜述[J]. 計算機研究與發展, 2015, 52(10): 2167-2177. ZHANG Y Q, FANG Z J, WANG K, et al. Survey of Android vulnerability detection[J]. Journal of Computer Research and Development, 2015, 52(10): 2167-2177.
[6] 楊威, 肖旭生, 李鄧鋒, 等. 移動應用安全解析學: 成果與挑戰[J]. 信息安全學報, 2016, 1(2): 1-14. YANG W, XIAO X S, LI D F, et al. Security analytics for mobile apps: achievements and challenges[J]. Journal of Cyber Security, 2016, 1(2): 1-14.
[7] 劉新宇, 翁健, 張悅, 等. 基于APK簽名信息反饋的 Android 惡意應用檢測[J]. 通信學報, 2017, 38(5): 190-198. LIU X Y, WENG J, ZHANG Y, et al. Android malware detection based on APK signature information feedback[J]. Journal on Communications, 2017, 38(5): 190-198.
[8] 楊歡, 張玉清, 胡予濮, 等. 基于多類特征的 Android 應用惡意行為檢測系統[J]. 計算機學報, 2014, 37(1): 15-27. YANG H, ZHANG Y Q, HU Y P, et al. A malware behavior detection system of Android applications based on multi-class features[J]. Chinese Journal of Computers, 2014, 37(1): 15-27.
[9] SADEGHI A, BAGHERI H, GARCIA J, et al. A taxonomy and qualitative comparison of program analysis techniques for security assessment of Android software[J]. IEEE Transactions on Software Engineering, 2017, 43(6): 492-530.
[10] TIAN K, YAO D D, RYDER B G, et al. Detection of repackaged Android malware with code-heterogeneity features[J]. IEEE Transactions on Dependable and Secure Computing, 2017, PP(99): 1.
[11] FAN M, LIU J, WANG W, et al. DAPASA: detecting Android piggybacked apps through sensitive subgraph analysis[J]. IEEE Transactions on Information Forensics and Security, 2017, 12(8): 1772-1785.
[12] LI L, LI D, BISSYANDé T F, et al. Understanding Android app piggybacking: a systematic study of malicious code grafting[J]. IEEE Transactions on Information Forensics and Security, 2017, 12(6): 1269-1284.
[13] ZHOU W, ZHOU Y J, GRACE M, et al. Fast, scalable detection of piggybacked mobile applications[C]//The Third ACM Conference on Data and Application Security and Privacy. 2013: 185-196.
[14] LI L, LI D, BISSYANDé T F, et al. Automatically locating malicious packages in piggybacked Android apps[C]//The 4th International Conference on Mobile Software Engineering and Systems. 2017: 170-174.
[15] ANDERSON H S, KHARKAR A, FILAR B, et al. Evading machine learning malware detection[C]//Black Hat USA. 2017.
[16] DEMONTIS A, MELIS M, BIGGIO B, et al. Yes, machine learning can be more secure! a case study on Android malware detection[J]. IEEE Transactions on Dependable and Secure Computing, 2017, doi: 10.1109/TDSC.2017.2700270.
[17] YANG W, KONG D, XIE T, et al. Malware detection in adversarial settings: exploiting feature evolutions and confusions in Android apps[C]//The 33rd Annual Computer Security Applications Conference. 2017: 288-302.
[18] 劉劍, 蘇璞睿, 楊珉, 等. 軟件與網絡安全研究綜述[J].軟件學報, 2018, 29(1): 42-68. LIU J, SU P R, YANG M, et al. Software and cyber security-a survey[J]. Journal of Software, 2018, 29(1): 42-68
[19] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[20] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//The IEEE Conference on Computer Vision and Pattern Recognition. 2016: 770-778.
[21] HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
[22] PENNINGTON J, SOCHER R, MANNING C. Glove: global vectors for word representation[C]//The 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2014: 1532-1543.
[23] LI Z, ZOU D Q, XU S H, et al. VulDeePecker: a deep learning-based system for vulnerability detection[C]//NDSS. 2018.
[24] YUAN Z, LU Y, WANG Z, et al. Droid-Sec: deep learning in Android malware detection[J]. ACM SIGCOMM Computer Communication Review, 2014, 44(4): 371-372.
[25] WANG S, LIU T, TAN L. Automatically learning semantic features for defect prediction[C]//The 38th International Conference on Software Engineering. 2016: 297-308.
[26] PRADEL M, SEN K. Deep learning to find bugs. technical report[R]. TU Darmstadt, Department of Computer Science. 2017.
[27] SHIN E, SONG D, MOAZZEZI R. Recognizing functions in binaries with neural networks[C]//The 24th USENIX Conference on Security Symposium. 2015: 611-626.
[28] CHUA Z L, SHEN S, SAXENA P, et al. Neural nets can learn function type signatures from binaries[C]//The 26th USENIX Conference on Security Symposium. 2017: 99-116.
[29] XU X, LIU C, FENG Q, et al. Neural network-based graph embedding for cross-platform binary code similarity detection[C]//The 2017 ACM SIGSAC Conference on Computer and Communications Security. 2017: 363-376.
[30] KOLOSNJAJI B, ZARRAS A, WEBSTER G, et al. Deep learning for classification of malware system call sequences[C]//Australasian Joint Conference on Artificial Intelligence. 2016: 137-149.
[31] DAVID O E, NETANYAHU N S. Deepsign: deep learning for automatic malware signature generation and classification[C]//2015 International Joint Conference on Neural Networks (IJCNN). 2015: 1-8.
[32] HOU S, SAAS A, CHEN L, et al. Deep4maldroid: a deep learning framework for Android malware detection based on linux kernel system call graphs[C]//Web Intelligence Workshops (WIW). 2016: 104-111.
[33] ALLIX K, BISSYANDE T F, KLEIN J, et al. AndroZoo: collecting millions of Android apps for the research community[C]//The 13th Working Conference on Mining Software Repositories. 2016: 468-471.
[34] CRUSSELL J, GIBLER C, CHEN H. Attack of the clones: detecting cloned applications on Android markets[C]//European Symposium on Research in Computer Security. 2012: 37-54.
[35] CRUSSELL J, GIBLER C, CHEN H. Andarwin: scalable detection of semantically similar Android applications[C]//European Symposium on Research in Computer Security. 2013: 182-199.
[36] CHEN K, LIU P, ZHANG Y. Achieving accuracy and scalability simultaneously in detecting application clones on Android markets[C]//The 36th International Conference on Software Engineering. 2014: 175-186.
[37] CHEN K, WANG P, LEE Y, et al. Finding unknown malice in 10 seconds: mass vetting for new threats at the google-play scale[C]//The 24th USENIX Conference on Security Symposium. 2015: 659-674.
[38] WANG H Y, GUO Y, MA Z, et al. Wukong: a scalable and accurate two-phase approach to Android app clone detection[C]//The 2015 International Symposium on Software Testing and Analysis. 2015: 71-82.
[39] 王浩宇, 王仲禹, 郭耀, 等. 基于代碼克隆檢測技術的Android應用重打包檢測[J]. 中國科學:信息科學, 2014, 44: 142-157. WANG H Y, WANG Z Y, GUO Y, et al. Detecting repackaged Android applications based on code clone detection technique[J]. Science China Information Sciences, 2014, 44(1): 142-157.
[40] ZHANG F, HUANG H, ZHU S, et al. ViewDroid: towards obfuscation-resilient mobile application repackaging detection[C]//The 2014 ACM conference on Security and Privacy in Wireless & Mobile Networks. 2014: 25-36.
[41] SUN M, LI M, LUI J. Droideagle: seamless detection of visually similar Android apps[C]//The 8th ACM Conference on Security & Privacy in Wireless and Mobile Networks. 2015: 1-9.
[42] SHAO Y, LUO X, QIAN C, et al. Towards a scalable resource-driven approach for detecting repackaged Android applications[C]//The 30th Annual Computer Security Applications Conference. 2014: 56-65.
[43] SOH C, TAN H B K, ARNATOVICH Y L, et al. Detecting clones in Android applications through analyzing user interfaces[C]//The 2015 IEEE 23rd International Conference on Program Comprehension. 2015: 163-173.
[44] ZHANG M, DUAN Y, YIN H, et al. Semantics-aware Android malware classification using weighted contextual API dependency graphs[C]//The 2014 ACM SIGSAC Conference on Computer and Communications Security. 2014: 1105-1116.
[45] AAFER Y, DU W, YIN H. Droidapiminer: mining api-level features for robust malware detection in Android[C]//International Conference on Security and Privacy in Communication Systems. 2013: 86-103.
[46] VALLEE-RAI R, HENDREN L J. Jimple: simplifying Java bytecode for analyses and transformations[R]. Technical Report, Sable Group, McGill University, Montreal, Canada, 1998.
[47] MUELLER J, THYAGARAJAN A. Siamese recurrent architectures for learning sentence similarity[C]//AAAI. 2016: 2786-2792.
[48] BROMLEY J, GUYON I, LECUN Y, et al. Signature verification using a “siamese” time delay neural network[C]//Advances in Neural Information Processing Systems. 1994: 737-744.
[49] LI L, BISSYANDé T F, KLEIN J, et al. An investigation into the use of common libraries in Android apps[C]//The 23rd International Conference on Software Analysis, Evolution, and Reengineering (SANER). 2016: 403-414.
[50] 汪潤, 王麗娜, 唐奔宵, 等. SPRD:基于應用UI和程序依賴圖的Android重打包應用快速檢測方法[J]. 通信學報, 2018, 39(3): 159-171. WANG R, WANG L N, TANG B X, et al. SPRD: fast application repackaging detection approach in Android based on application’s UI and program dependency graph[J]. Journal on Communications, 2018, 39(3): 159-171.
DeepRD: LSTM-based Siamese network for Android repackaged applications detection
WANG Run1,2, TANG Benxiao1,2, WANG Li’na1,2
1. Key Laboratory of Aerospace Information Security and Trusted Computing Ministry of Education, Wuhan University, Wuhan 430072, China 2. School of Cyber Science and Engineering, Wuhan University, Wuhan 430072, China
The state-of-art techniques in Android repackaging detection relied on experts to define features, however, these techniques were not only labor-intensive and time-consuming, but also the features were easily guessed by attackers. Moreover, the feature representation of applications which defined by experts cannot perform well to the common types of repackaging detection, which caused a high false negative rate in the real detection scenario. A deep learning-based repackaged applications detection approach was proposed to learn the program semantic features automatically for addressing the above two issues. Firstly, control and data flow analysis were taken for applications to form a sequence feature representation. Secondly, the sequence features were transformed into vectors based on word embedding model to train a Siamese LSTM network for automatically program feature learning. Finally, repackaged applications were detected based on the similarity measurement of learned program features. Experimental results show that the proposed approach achieves a precision of 95.7% and false negative rate of 6.2% in an open sourced dataset AndroZoo.
repackaging, deep learning, Siamese network, LSTM, security and privacy
TP309.1
A
10.11959/j.issn.1000?436x.2018148
汪潤(1991?),男,安徽安慶人,武漢大學博士生,主要研究方向為Android安全與隱私、AI安全等。

唐奔宵(1991?),男,湖北黃石人,武漢大學博士生,主要研究方向為移動安全與隱私、系統安全等。
王麗娜(1964?),女,遼寧營口人,博士,武漢大學教授、博士生導師,主要研究方向為網絡安全、信息隱藏、AI安全等。

2018?04?03;
2018?06?28
王麗娜,lnwang@whu.edu.cn
國家自然科學基金資助項目(No.U1536204);中央高校基本科研業務費專項資金資助項目(No.2042018kf1028);國家高技術研究發展計劃(“863”計劃)基金資助項目(No.2015AA016004)
The National Natural Science Foundation of China (No.U1536204), The Central University Basic Business Expenses Special Funding for Scientific Research Project (No.2042018kf1028), The National High Technology Research and Development Program of China (863 Program) (No.2015AA016004)
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
