基于不完全信息隨機博弈與Q-learning的防御決策方法
2018-09-12 02:18:20張紅旗楊峻楠張傳富
通信學報 2018年8期
張紅旗,楊峻楠,張傳富
?
基于不完全信息隨機博弈與Q-learning的防御決策方法
張紅旗1,2,楊峻楠1,2,張傳富1,2
(1. 信息工程大學三院,河南 鄭州 450001;2. 河南省信息安全重點實驗室,河南 鄭州 450001)
針對現(xiàn)有隨機博弈大多以完全信息假設(shè)為前提,且與網(wǎng)絡(luò)攻防實際不符的問題,將防御者對攻擊者收益的不確定性轉(zhuǎn)化為對攻擊者類型的不確定性,構(gòu)建不完全信息隨機博弈模型。針對網(wǎng)絡(luò)狀態(tài)轉(zhuǎn)移概率難以確定,導致無法確定求解均衡所需參數(shù)的問題,將Q-learning引入隨機博弈中,使防御者在攻防對抗中通過學習得到的相關(guān)參數(shù)求解貝葉斯納什均衡。在此基礎(chǔ)上,設(shè)計了能夠在線學習的防御決策算法。仿真實驗驗證了所提方法的有效性。
網(wǎng)絡(luò)攻防;隨機博弈;Q-learning;貝葉斯納什均衡;防御決策
1 引言
近年來,信息安全事件日趨頻繁,給網(wǎng)絡(luò)安全帶來了巨大的損失[1]。由于資源和能力的限制,防御者無法保證絕對的安全,因此亟需一種能夠?qū)シ佬袨檫M行分析和防御策略選取的技術(shù),使防御者在風險與投入之間達成一種均衡。博弈論與網(wǎng)絡(luò)攻防所具有的目標對立性、關(guān)系非合作性和策略依存性高度契合[2],通過建立網(wǎng)絡(luò)攻防的博弈模型及對模型的均衡求解來研究攻擊行為和指導防御決策逐漸成為一個研究熱點[3]。
針對網(wǎng)絡(luò)防御決策問題,本文首先對網(wǎng)絡(luò)攻防進行分析。將攻防對抗進行離散化處理,整個過程看作一系列時間片,每個時間片都包含且只包含一個網(wǎng)絡(luò)狀態(tài)。網(wǎng)絡(luò)攻防過程可以用圖1(a)進行描述。每個時間片中攻防雙方檢測當前網(wǎng)絡(luò)狀態(tài),依據(jù)狀態(tài)選擇執(zhí)行攻防動作。網(wǎng)絡(luò)系統(tǒng)在攻防雙方的聯(lián)合行為作用下由一個狀態(tài)轉(zhuǎn)移到另一個狀態(tài)。時間片中的網(wǎng)絡(luò)狀態(tài)轉(zhuǎn)移關(guān)系如圖1(b)所示,網(wǎng)絡(luò)狀態(tài)之間的轉(zhuǎn)移不僅受到攻防動作的影響,還受到網(wǎng)絡(luò)中其他一些復雜因素的影響,這導致網(wǎng)絡(luò)狀態(tài)的轉(zhuǎn)移存在隨機性。由于網(wǎng)絡(luò)攻防的非合作性,攻防雙方無法完全掌握對手信息,且只能通過檢測網(wǎng)絡(luò)來了解對手的行動,這會比動作的執(zhí)行時間至少延遲一個時間片,并導致每個時間片中雙方不知道對手當前時間片的行動,因此每個時間片是一個不完全信息靜態(tài)博弈。但從整個攻防過程來看,當前時間片的攻防動作會影響后續(xù)時間片的網(wǎng)絡(luò)狀態(tài),進而影響攻防雙方的決策,這又是一個動態(tài)變化的過程。
本文采用不完全信息靜態(tài)博弈與馬爾可夫決策結(jié)合的隨機博弈[4]來對網(wǎng)絡(luò)攻防進行建模分析,其博弈系統(tǒng)在參與人的聯(lián)合行動下由一個狀態(tài)轉(zhuǎn)移到另一個狀態(tài),符合上述分析的網(wǎng)絡(luò)攻防對抗過程。
目前,國內(nèi)外基于隨機博弈的網(wǎng)絡(luò)安全研究已取得一定進展,但是應(yīng)用在網(wǎng)絡(luò)安全領(lǐng)域的隨機博弈模型大部分基于完全信息假設(shè)。文獻[5]將攻擊者的特權(quán)狀態(tài)作為網(wǎng)絡(luò)狀態(tài),構(gòu)建完全信息隨機博弈模型。文獻[6]通過完全信息隨機博弈分析攻擊者與防御者之間的策略交互,利用納什均衡指導防御決策。文獻[7]提出一種完全信息隨機博弈分析方法,保護電網(wǎng)免受協(xié)調(diào)攻擊。文獻[8]將隨機博弈應(yīng)用于物聯(lián)網(wǎng)中用于平衡網(wǎng)絡(luò)性能與安全水平,其所提方法比其實驗中的基準方法更有效。由于網(wǎng)絡(luò)攻防的競爭關(guān)系,掌握對方博弈信息非常困難,上述文獻中的完全信息假設(shè)不能滿足實際需求。因此部分學者開始采用更符合實際的不完全信息隨機博弈進行研究。文獻[9]針對移動目標防御決策問題,構(gòu)建不完全信息隨機博弈模型,并通過對比分析說明了此模型比其之前建立的完全信息隨機博弈模型[10]實用性更高。但是,上述成果均未討論隨機博弈現(xiàn)有收益函數(shù)在網(wǎng)絡(luò)攻防中的適用問題。首先,上述文獻的收益函數(shù)都以已知轉(zhuǎn)移模型為前提,但在實際中防御者往往無法確定網(wǎng)絡(luò)狀態(tài)轉(zhuǎn)移概率,導致無法利用上述文獻模型中的收益函數(shù)求解均衡。另外,網(wǎng)絡(luò)具有動態(tài)性,其狀態(tài)轉(zhuǎn)移概率也會不定期變化,但上述文獻沒有提出相應(yīng)的解決方案而是假設(shè)狀態(tài)轉(zhuǎn)移概率為定值。以上2點使上述文獻的模型實用性較低。
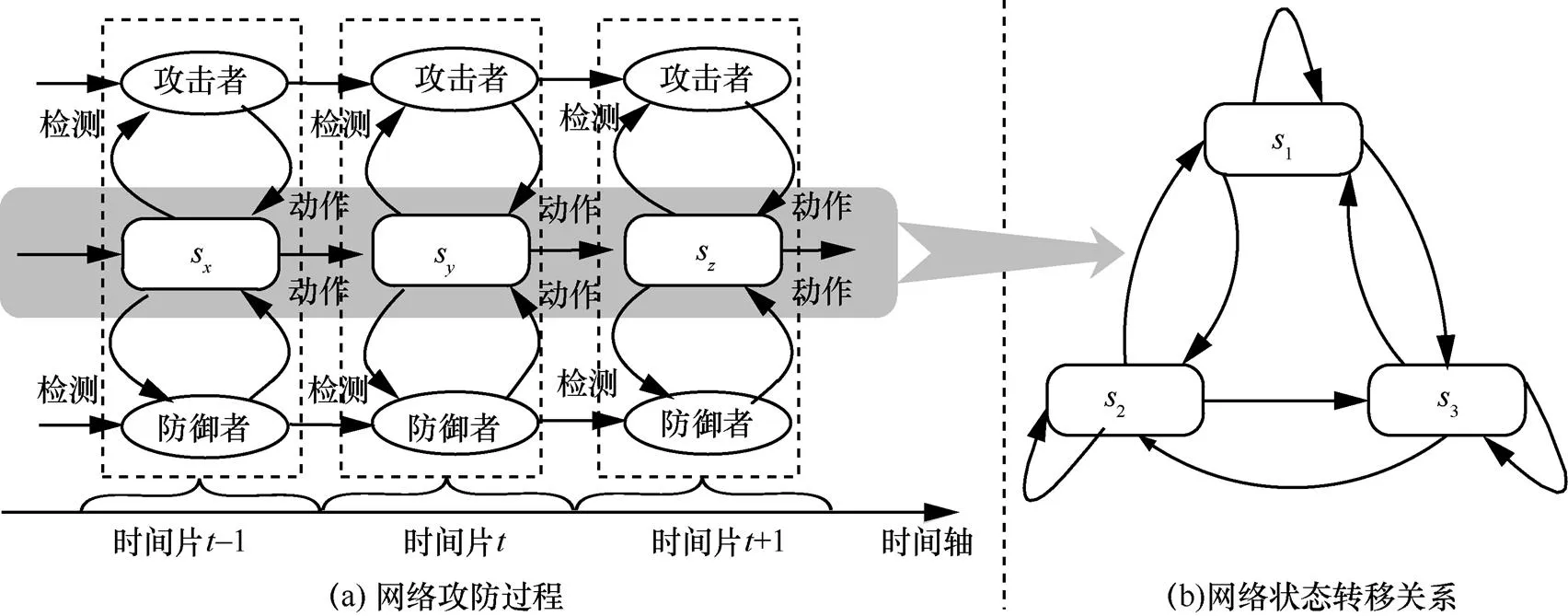
圖1 網(wǎng)絡(luò)攻防
為解決上述問題,借鑒強化學習思想,在不完全信息隨機博弈中引入Q-learning[11]算法。據(jù)統(tǒng)計,阿里云在2017年僅每天就要遭受16億次左右的攻擊,對于不同攻擊者,可能每個攻防場景只會出現(xiàn)一次,但對于以阿里云為代表的防御者來說,其每天都要面對大量相同的攻防場景。通過引入Q-learning算法并將其由一個參與者擴展為可用于博弈的2個參與者,使防御者在大量相同的攻防場景中以增量求和的方式對收益進行在線學習和更新,不需要確定轉(zhuǎn)移概率,就可以求解相應(yīng)場景的貝葉斯納什均衡,從而進行防御決策。
目前,Q-learning在攻防領(lǐng)域已得到廣泛應(yīng)用。文獻[12]提出一種基于Q-learning的LDoS攻擊實時防御機制,該方法具有較好的實時性和靈敏性。文獻[13]將Q-learning嵌入軟件中,提供一種安全機制,該方法能夠較快學會阻止惡意行為。文獻[14]基于Q-learning設(shè)計了一種有效的智能電網(wǎng)脆弱性分析方法。上述研究取得了一定進展,但其將攻擊者作為環(huán)境的一部分固定到系統(tǒng)中,不能體現(xiàn)攻防的對抗特點,也無法較好地滿足網(wǎng)絡(luò)攻防的策略依存性。
2 不完全信息隨機博弈模型
實際的網(wǎng)絡(luò)攻防對抗是一個復雜的過程,針對防御策略選取問題,對其進行一些必要的假設(shè)和簡化。
對參與博弈的攻防雙方做出如下假設(shè)。
1) 攻防雙方都是理性的,追求最大的收益。
2) 防御者對攻擊者收益函數(shù)的不確定性視為對攻擊者類型的不確定性,且防御者對攻擊者類型的概率分布有一個判斷[11]。
對每個時間片中博弈所需的“信息”和“行動順序”這2個基本要素做進一步假設(shè)。設(shè)當前博弈處于時間片中,則在中攻擊者類型為其私有信息,雙方的共同知識為:①時間片中的狀態(tài)和對應(yīng)狀態(tài)攻防雙方可采取的動作;②攻擊者在采取的動作,在+1會被防御者觀察到,防御者在采取的動作,在+1會被攻擊者觀察到;③防御者對攻擊者類型分布的概率判斷。行動順序:在每個時間片,攻防雙方是同時行動的。這里的“同時”是一個信息概念,非時間概念,即盡管從時間概念上攻防雙方的選擇可能不在同一時刻,但只要攻防雙方在行動時不知道對手的選擇就認為是同時行動。
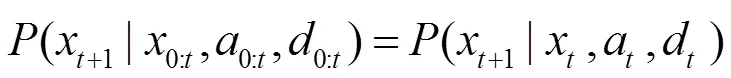
常用變量及其含義如表1所示。
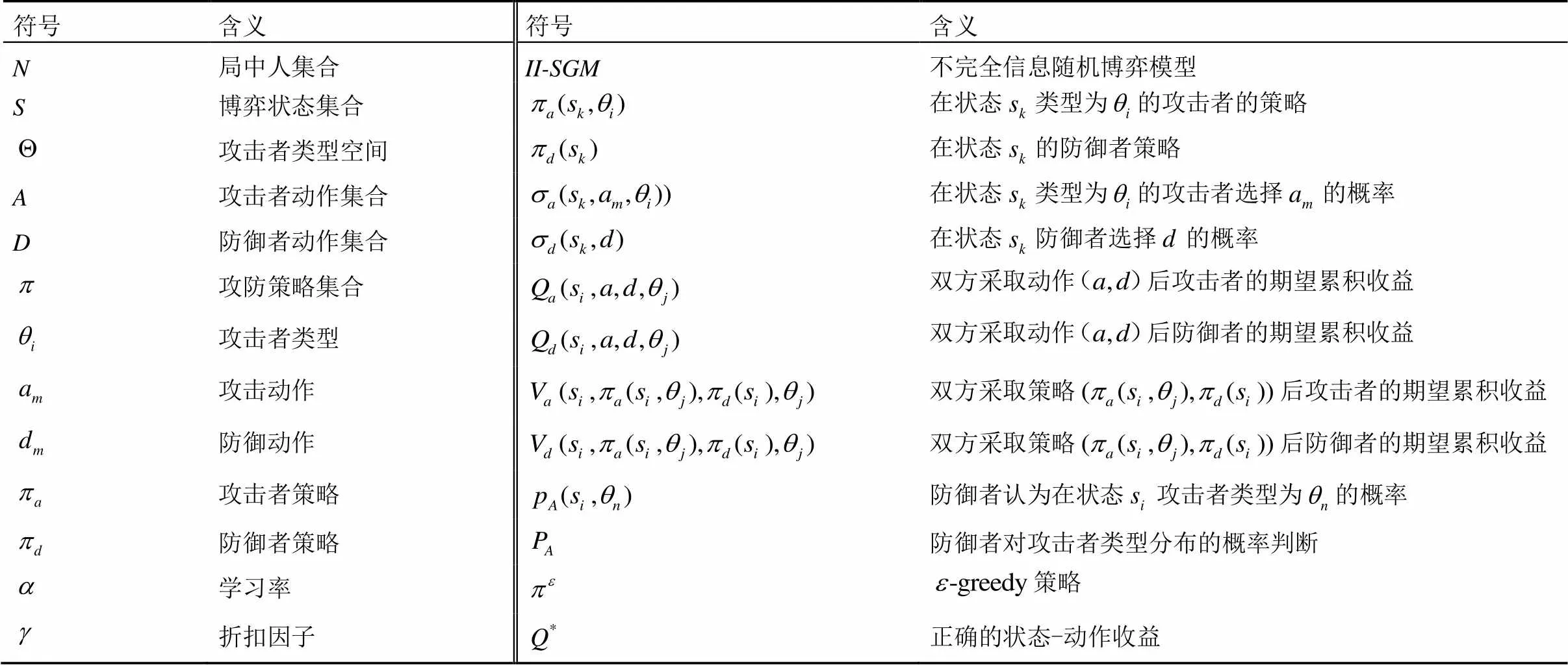
表1 主要符號及其含義
在上述基礎(chǔ)上構(gòu)建博弈模型。
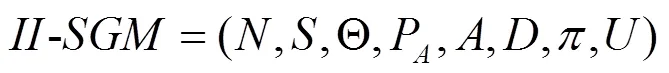
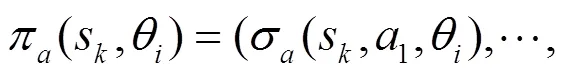
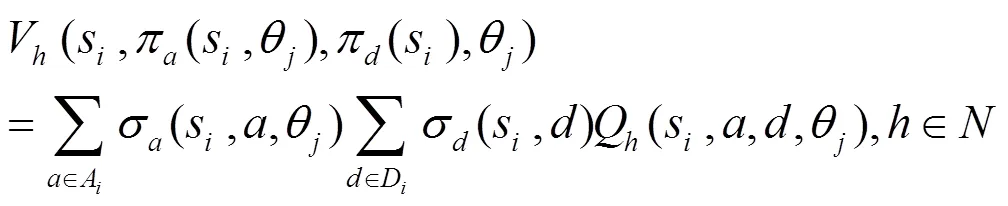
采用海薩尼轉(zhuǎn)換[15]來處理不完全信息博弈,引入虛擬參與人“自然”按照相應(yīng)概率選擇轉(zhuǎn)移的狀態(tài)和攻擊者類型,使攻防雙方對狀態(tài)轉(zhuǎn)移的不完全信息和防御者對攻擊收益的不完全信息轉(zhuǎn)換成對“自然”行動的不完美信息。在此基礎(chǔ)上,依據(jù)博弈模型構(gòu)建一個時間片的攻防博弈樹,如圖2所示。其中,N為虛擬參與人“自然”,A為攻擊者,D為防御者。博弈由上一個時間片轉(zhuǎn)移到當前時間片后,“自然”N按照轉(zhuǎn)移概率先選擇當前時間片的網(wǎng)絡(luò)狀態(tài),再按防御者對攻擊者類型分布的概率判斷選擇攻擊者的類型,攻擊者A和防御者D都能觀察N對狀態(tài)的選擇,但只有攻擊者能觀察到N對攻擊者類型的選擇。A和D觀察后依據(jù)策略選擇自己的動作并獲得回報。當前時間片的博弈結(jié)束后,博弈轉(zhuǎn)移到下一個時間片。
3 Q-learning與貝葉斯納什均衡求解
貝葉斯納什均衡是攻防雙方的最優(yōu)策略,雙方無法再通過單方面改變自己的策略來提高收益。本節(jié)主要對隨機博弈在網(wǎng)絡(luò)攻防中求解均衡存在的問題進行研究。
3.1 網(wǎng)絡(luò)攻防中的均衡求解參數(shù)問題
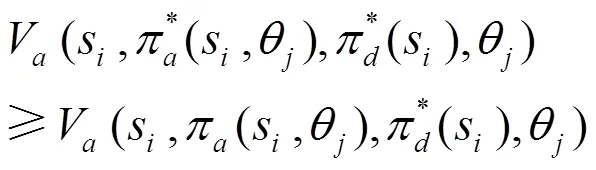
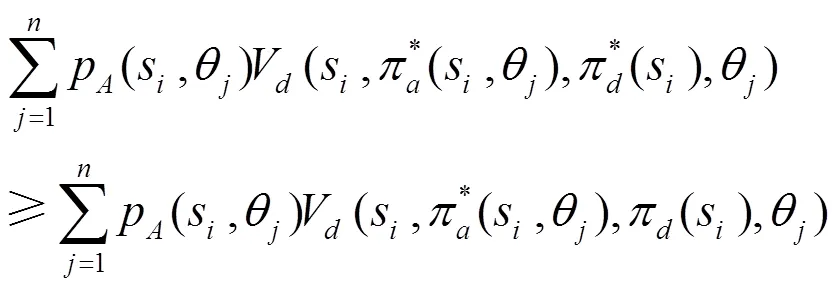
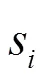
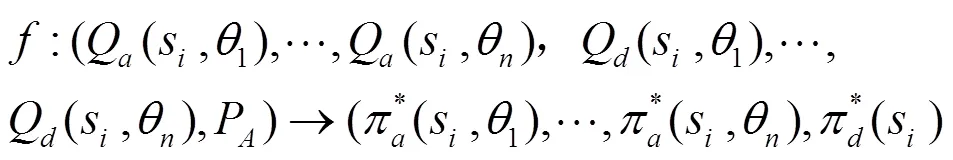
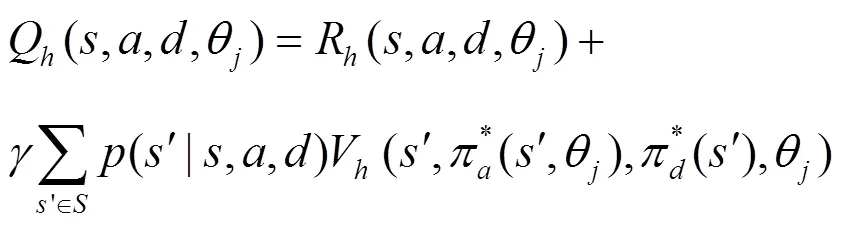
3.2 基于Q-learning的均衡求解參數(shù)確定方法
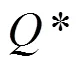
Q-learning是一種被廣泛應(yīng)用的典型免模型強化學習算法,能夠求解馬爾可夫決策的最大回報和最優(yōu)策略問題。雖然Q-learning和隨機博弈的基礎(chǔ)理論都是馬爾可夫決策,但是Q-learning中只有一個參與人,其決策只受環(huán)境的影響,每個狀態(tài)下參與人最大收益的動作是固定的,而隨機博弈中有2個參與人,其決策不僅受環(huán)境的影響,還要依賴于對手的決策,每個狀態(tài)下對手采取不同策略,自己的最大收益策略也不同,將Q-learning應(yīng)用在隨機博弈中還需要對其進行改進。
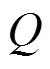
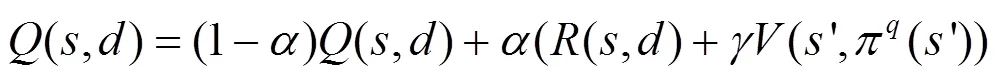
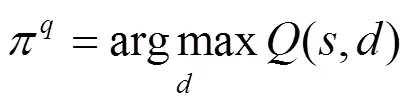
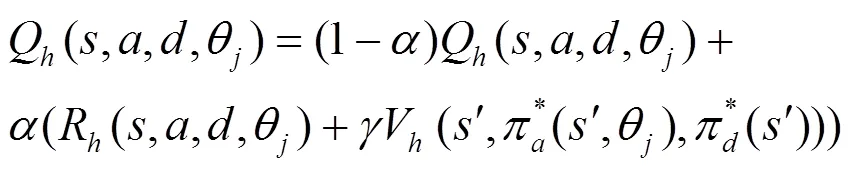
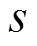
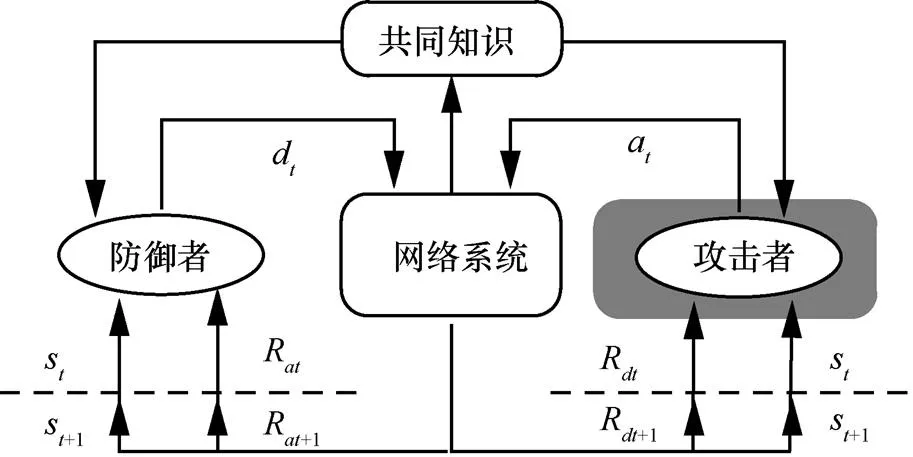
圖3 防御者學習機制
Q-learning中的環(huán)境采用本文II-SGM中的博弈狀態(tài)進行建模,參與者的行為采用II-SGM中的攻防動作集合來定義。


4 網(wǎng)絡(luò)防御策略選取
本節(jié)首先對將貝葉斯納什均衡作為攻防策略的合理性以及均衡的存在性進行分析,然后提出結(jié)合II-SGM與改進Q-learning的防御策略選取算法并從理論上對算法的收斂性進行分析。
4.1 貝葉斯納什均衡策略分析
網(wǎng)絡(luò)攻防具有策略依存性:①防御者在考慮策略時,會對攻擊者做出預(yù)測并根據(jù)預(yù)測結(jié)果選擇收益最高的策略;②攻擊者會預(yù)測到防御者對自己的預(yù)測進而調(diào)整自己的策略;③作為理性的防御者,還應(yīng)該進一步考慮到攻擊者會因預(yù)測到自己對攻擊者的預(yù)測而做出調(diào)整,此時防御者會進一步優(yōu)化防御策略;④作為理性的攻擊者,也應(yīng)該考慮到防御者會因預(yù)測到自己對防御者的預(yù)測而重新調(diào)整策略。這是一個螺旋上升的過程,最終攻防雙方的最優(yōu)策略會達到一種穩(wěn)定狀態(tài),此時雙方的策略都是對方策略的最優(yōu)響應(yīng),沒有人有積極性再去偏離這個結(jié)果。根據(jù)第3節(jié)貝葉斯納什均衡的定義,均衡中每一個參與人的策略,都是在其他參與人策略下使自己獲得最高收益的策略,是針對其他人做出的最優(yōu)響應(yīng),所以貝葉斯納什均衡是攻防對抗穩(wěn)定狀態(tài)的最優(yōu)策略,防御者選擇均衡作為防御策略可以獲得最高的期望收益,是合理的。
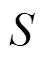
4.2 防御策略選取算法
算法1 自適應(yīng)防御策略選取算法
begin
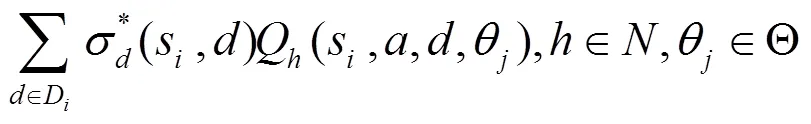
9)repeat:
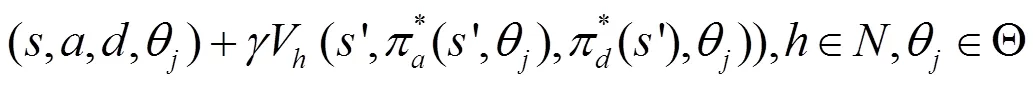
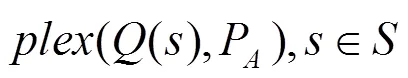
//對貝葉斯納什均衡進行更新
end
4.3 算法分析
4.3.1 收斂性分析
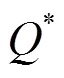
在滿足上述假設(shè)的基礎(chǔ)上對算法的收斂性進行分析。
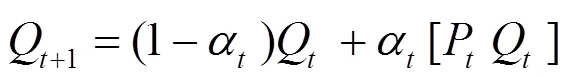
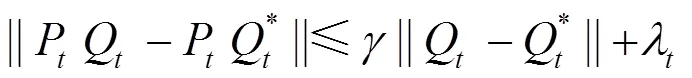
下面,對本文算法是否滿足上述3個條件進行分析。
本文算法算子為
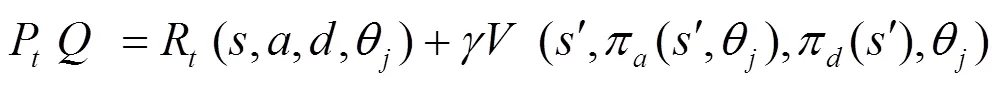
條件1)
由于本算法滿足假設(shè)2,因此條件1)成立。
條件2)
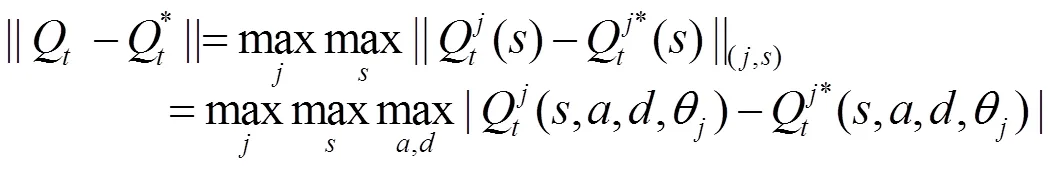
在上述基礎(chǔ)上證明如下引理。
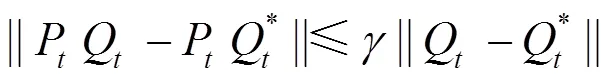
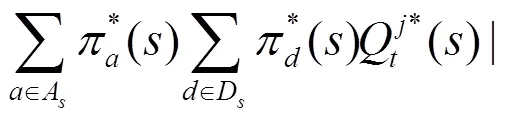
聯(lián)立式(10)和式(12)可知,欲證引理1,只需證明
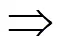
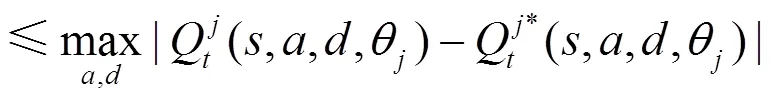
即可。
當為攻擊者時,分2種情況進行證明。
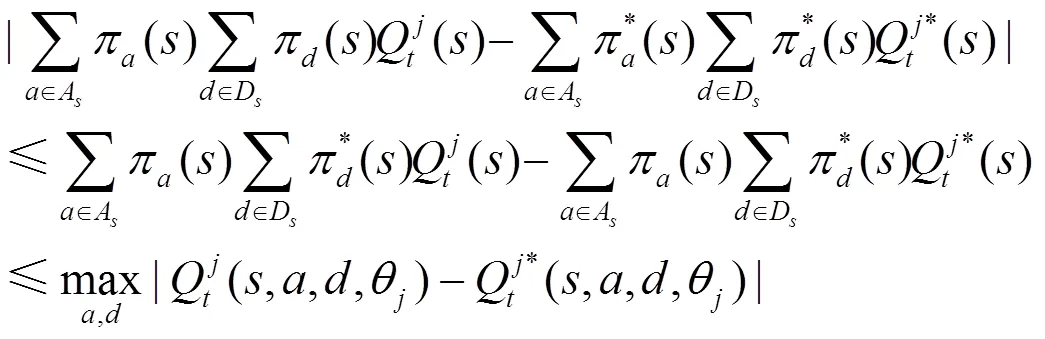
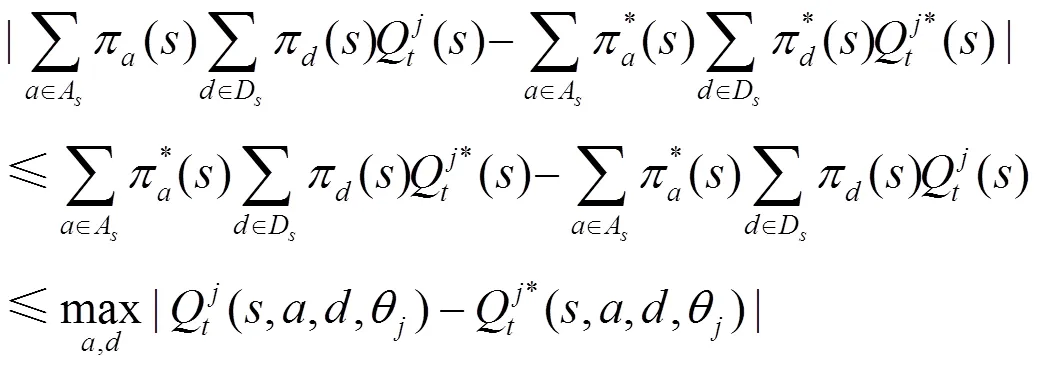
由式(14)和式(15)可知,式(13)成立。
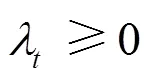
條件3)
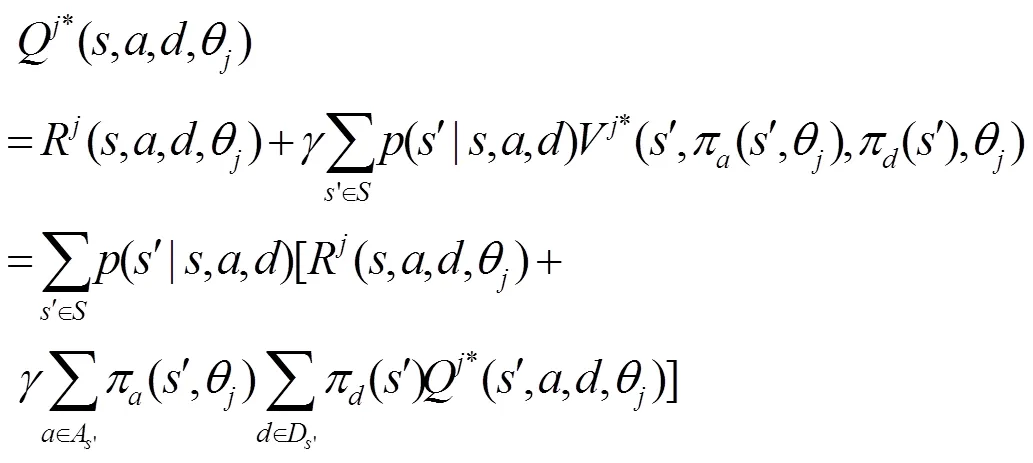

由式(16)可知,本文算法滿足條件3)。
綜上可知,本文算法滿足3個條件,所以本文算法收斂。
4.3.2 復雜性分析
5 仿真實驗與分析
5.1 仿真實驗場景
采用圖4所示的典型網(wǎng)絡(luò)信息系統(tǒng)場景進行仿真實驗。Web服務(wù)器和堡壘主機部署在非隔離區(qū)(DMZ, demilitarized zone),內(nèi)網(wǎng)由文件服務(wù)器和數(shù)據(jù)庫服務(wù)器組成。防火墻的安全策略為外部用戶僅允許訪問Web服務(wù)器的FTP、HTTP服務(wù)和堡壘主機上的SMTP服務(wù),其他網(wǎng)絡(luò)節(jié)點和端口均進行阻斷。所有的攻擊均來自外網(wǎng)。參考NVD數(shù)據(jù)庫給出目標網(wǎng)絡(luò)脆弱性信息,如表2所示。參考美國麻省理工大學的攻防行為數(shù)據(jù)庫[20]給出防御動作,如表3所示。
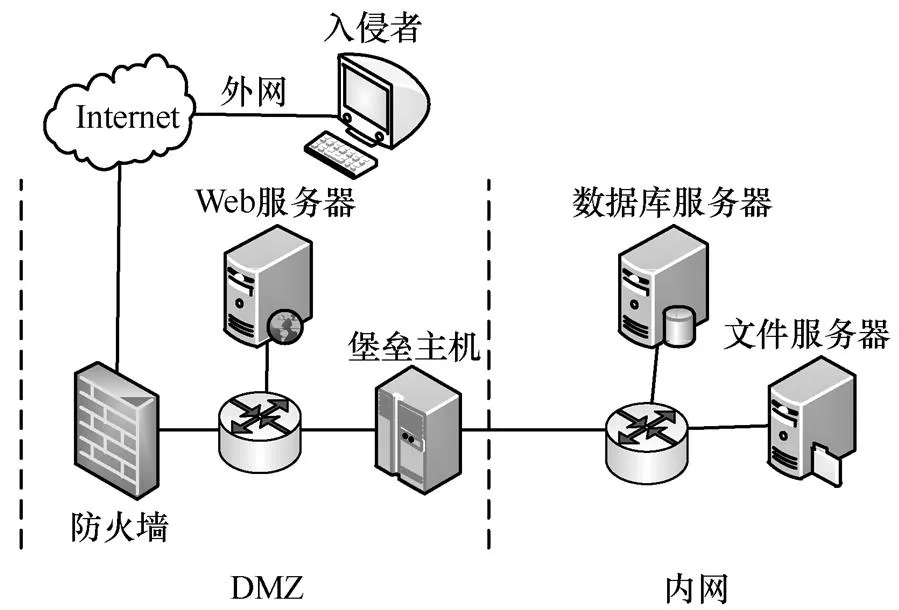
圖4 仿真網(wǎng)絡(luò)信息系統(tǒng)場景
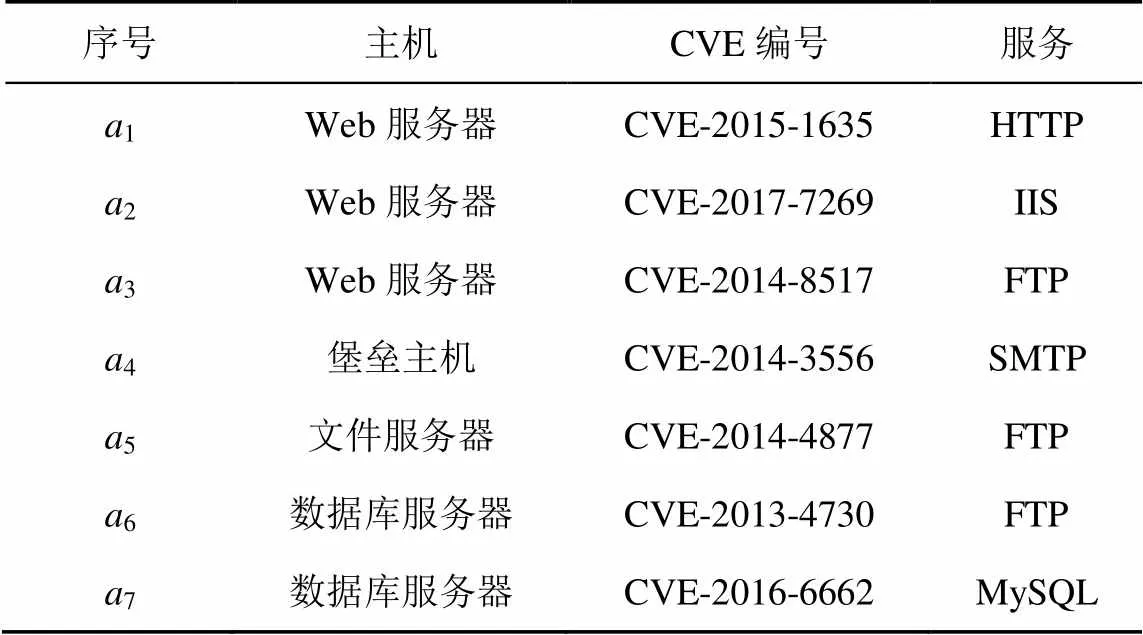
表2 網(wǎng)絡(luò)脆弱性信息

表3 防御動作描述
5.2 構(gòu)建仿真場景的攻防隨機博弈模型

表4 網(wǎng)絡(luò)狀態(tài)
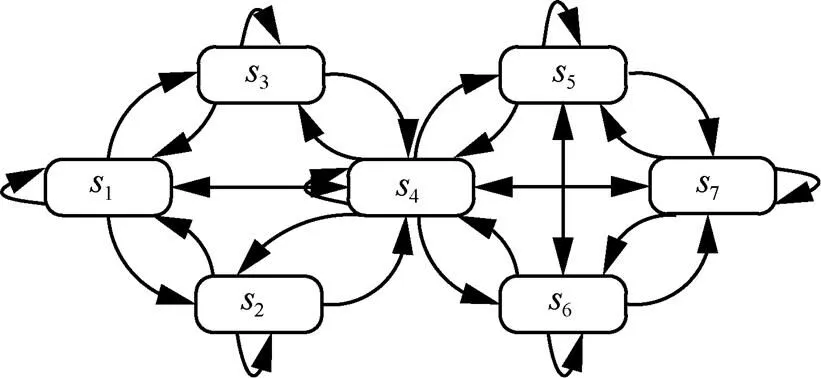
圖5 網(wǎng)絡(luò)狀態(tài)轉(zhuǎn)移關(guān)系
攻擊者類型分布的先驗概率為
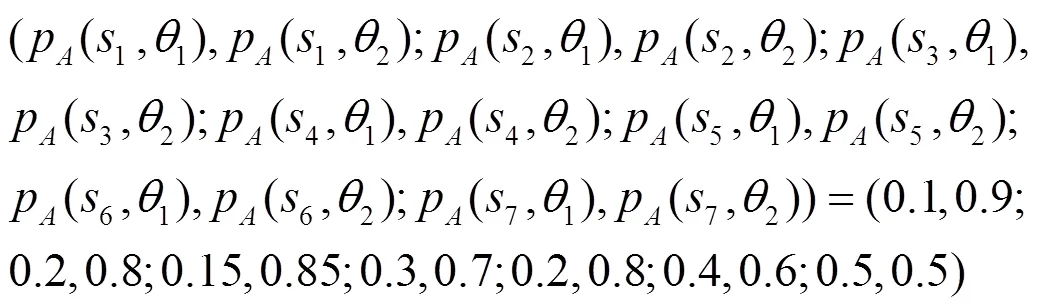
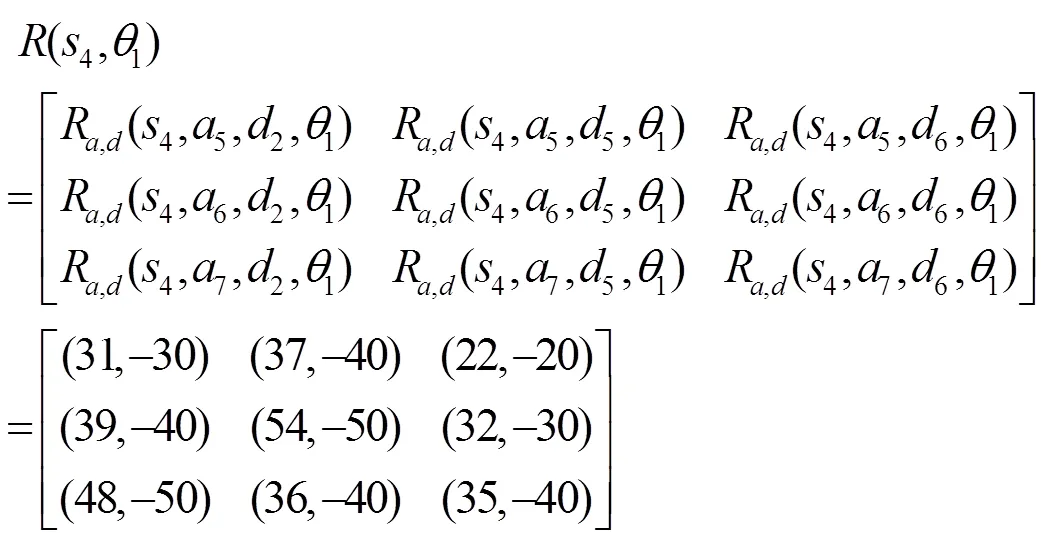
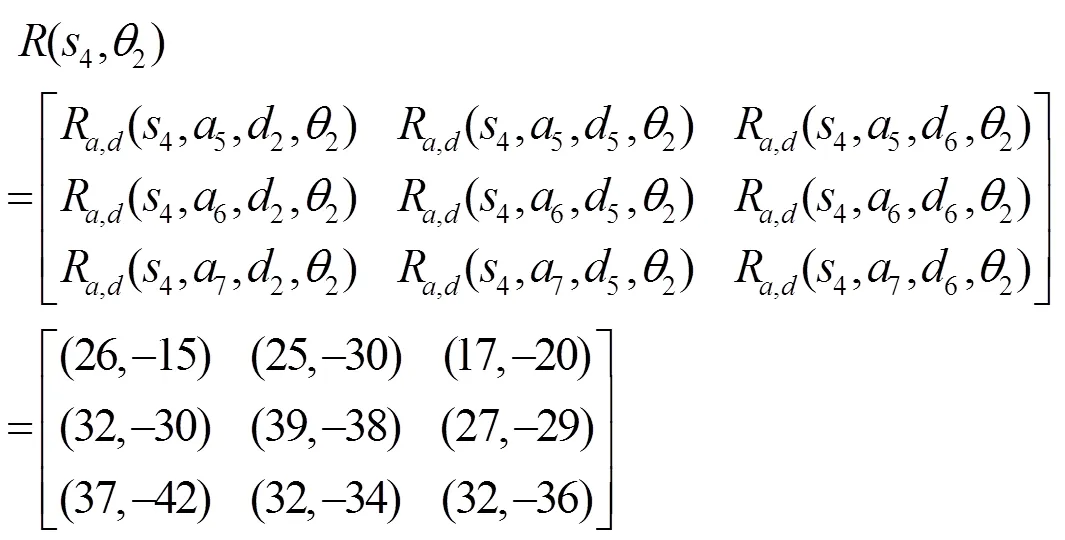
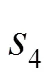
接下來,在防御者不知道轉(zhuǎn)移概率的前提下,對本文算法的有效性進行測試,仿真實驗使用Python2.7實現(xiàn)了本文的防御策略選取算法。
5.3 測試與結(jié)果分析
5.3.1 收斂性測試與分析
1)不同參數(shù)設(shè)置對算法收斂性的影響
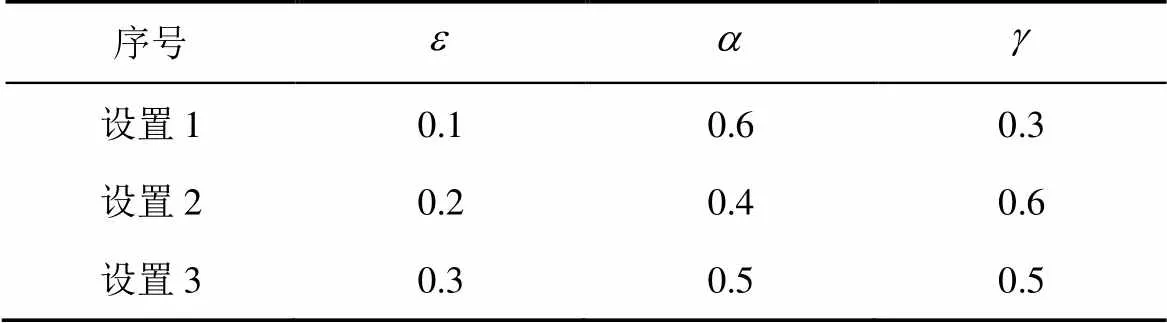
表5 實驗參數(shù)設(shè)置
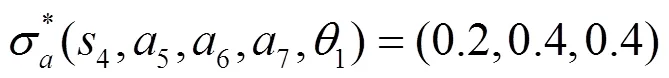
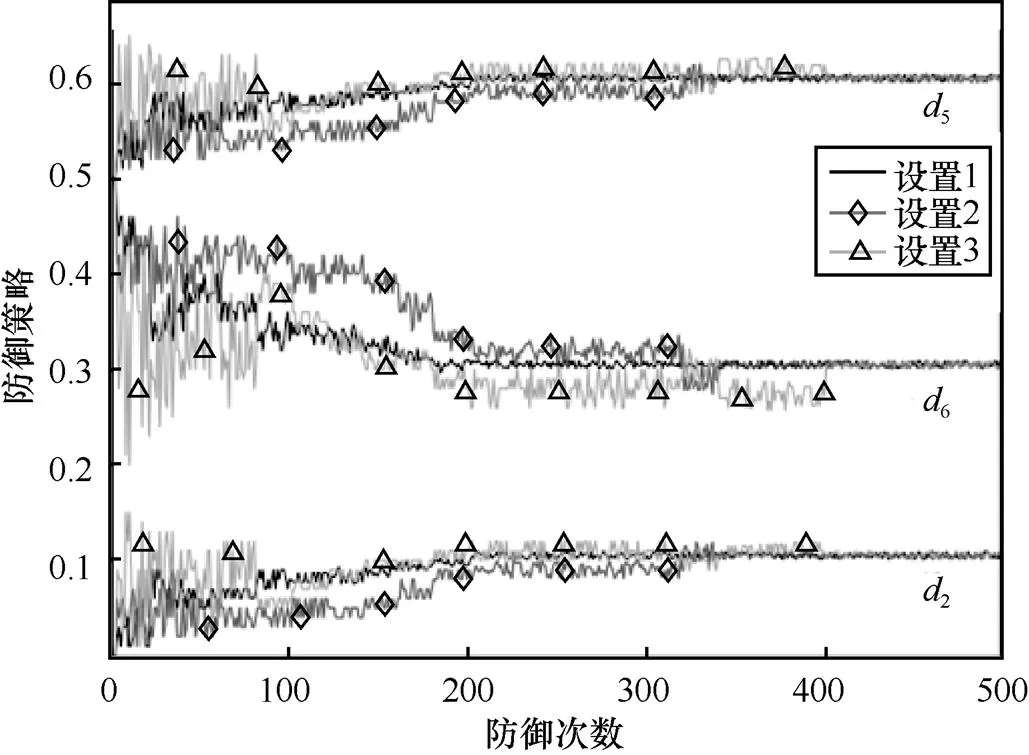
圖6 不同參數(shù)設(shè)置下狀態(tài)s4的防御策略變化
從圖6可以看到,3組參數(shù)設(shè)置都能夠收斂,通過與已知轉(zhuǎn)移概率計算的貝葉斯納什均衡結(jié)果對比可以發(fā)現(xiàn),3組參數(shù)設(shè)置都能夠收斂到正確的貝葉斯納什均衡,即
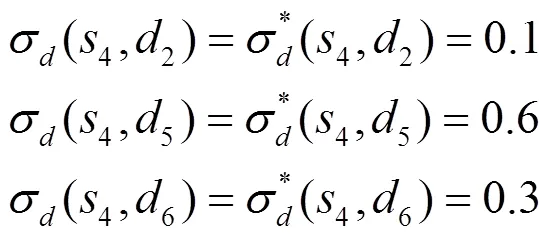
不同參數(shù)設(shè)置的收斂速度不同,設(shè)置1在防御200次左右達到貝葉斯納什均衡,而設(shè)置2和設(shè)置3在防御350~400次左右達才達到收斂,且設(shè)置1在學習過程中的振蕩幅度也明顯小于設(shè)置2和設(shè)置3,由此可知,設(shè)置1比設(shè)置2和設(shè)置3更適用于本場景。
2) 不同攻擊策略對算法收斂性的影響
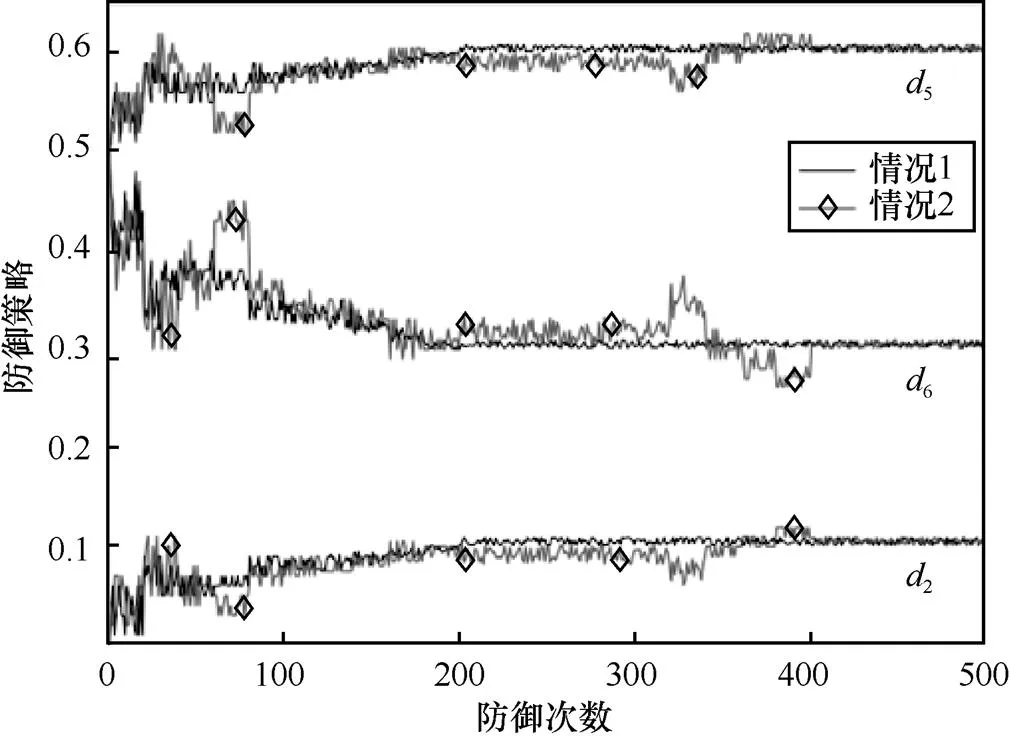
圖7 不同攻擊策略下狀態(tài)s4的防御策略變化
從圖7可以看到,當面對理性攻擊者時,本文方法能夠在200次左右的學習后快速收斂到貝葉斯納什均衡策略;當面對非理性攻擊者時,防御者仍能夠在與攻擊者對抗中進行學習,雖然學習過程中振蕩幅度比情況1稍大且收斂速度比情況1稍慢,但在400次左右的學習后也能夠達到收斂。綜上可知,攻擊者的策略會對本文方法的學習速度和振蕩程度有一定影響,但不會影響最終的學習結(jié)果,這說明算法在實際的復雜環(huán)境中也能進行有效的防御決策。
5.3.2 適應(yīng)性測試與分析

算法第16)步中狀態(tài)s=的防御策略變化如圖8所示。
從圖8可以看到,初始狀態(tài)下算法進行了第一次學習并達到收斂,當網(wǎng)絡(luò)狀態(tài)轉(zhuǎn)移概率發(fā)生變化后,算法能夠及時做出反應(yīng),進行第二次學習并再次達到收斂。第一次收斂經(jīng)歷了200次左右的學習,而第二次收斂只經(jīng)歷了100次左右的學習,這是因為初始狀態(tài)只引入了較少的先驗知識,所以需要較長的學習過程,而第二次由于網(wǎng)絡(luò)的動態(tài)變化一般比較平穩(wěn),通常不會突然發(fā)生劇烈改變,由此轉(zhuǎn)移概率的變化幅度較小,利用前一階段的學習成果相當于引入了較多的先驗知識,因此收斂速度較快。綜上可知,算法能夠在網(wǎng)絡(luò)動態(tài)變化時及時做出調(diào)整,適應(yīng)新的環(huán)境。
5.3.3 對比測試與分析
從圖9可以看到,本文方法在經(jīng)過200次左右的學習后收斂到了客觀的均衡策略;文獻[5-6,9]的方法由于初始計算時無法得到準確的轉(zhuǎn)移概率導致其結(jié)果與客觀的均衡存在誤差,其中,文獻[5-6]又由于以完全信息假設(shè)為前提,導致誤差比文獻[9]要稍大一些;單純的Q-learning方法由于只能選擇純策略,而客觀均衡是一個混合策略,導致其防御策略一直在振蕩。
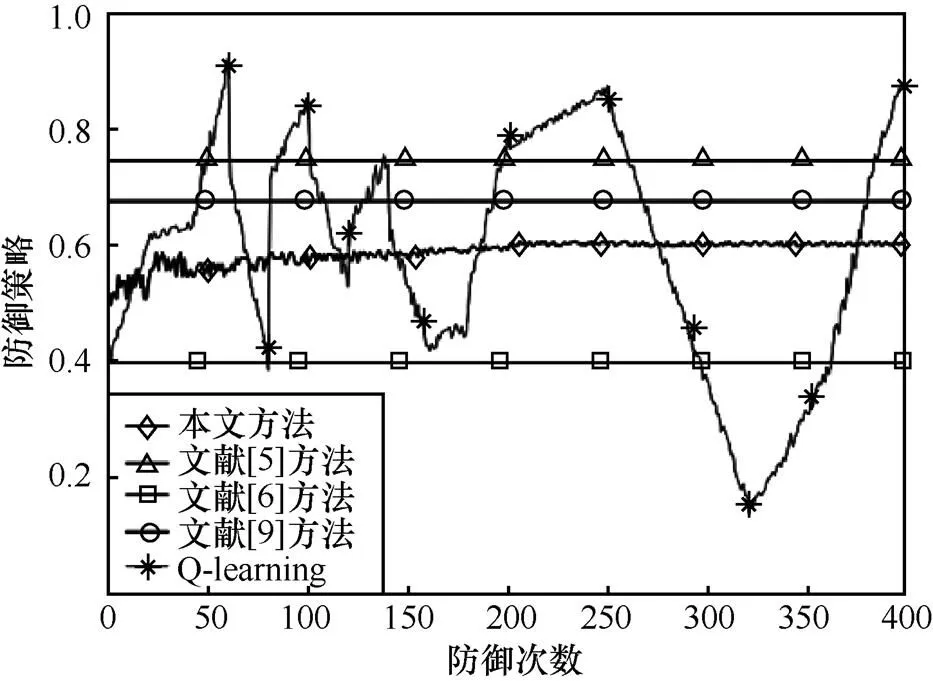
圖9 不同方法在狀態(tài)s4的防御策略變化
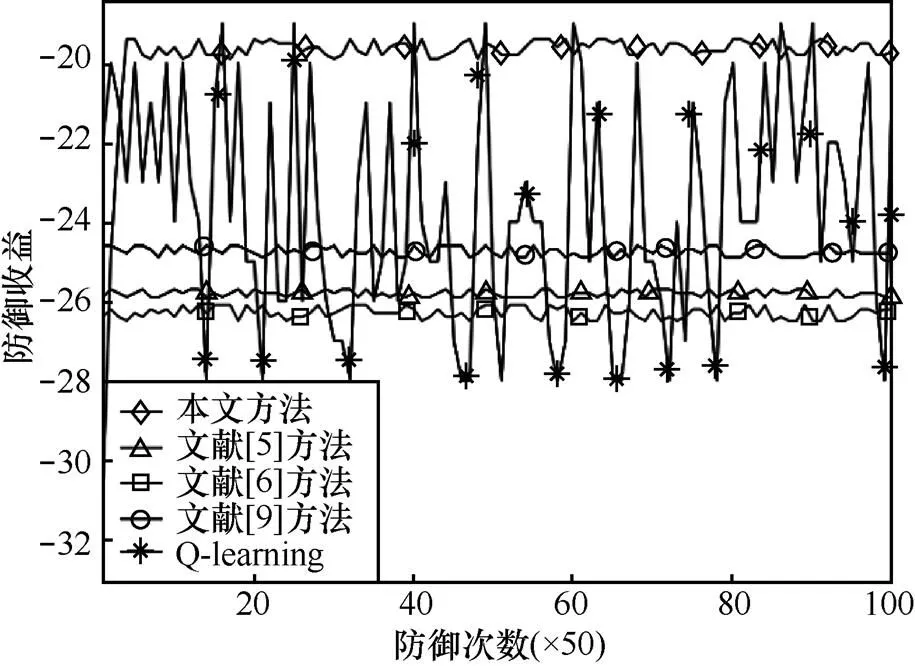
圖10 不同方法在狀態(tài)s4的防御收益變化
從圖10可以看到,本文方法在初始階段收益稍低于其他方法,但是當收斂到均衡策略以后,本文方法收益明顯高于其他4種方法,這表明本文方法的防御策略在此場景要優(yōu)于其他方法。
6 相關(guān)工作對比分析
本文方法與一些典型方法的研究對比結(jié)果如表6所示。文獻[5-6,8-9]的理論基礎(chǔ)為隨機博弈,文獻[12,14]的理論基礎(chǔ)為Q-learning,本文方法則是隨機博弈與Q-learning的結(jié)合。與文獻[5-6,8]相比,本文方法以不完全信息假設(shè)為前提,更符合攻防實際;與文獻[5-6,8-9]相比,本文方法不需要已知轉(zhuǎn)移模型,且能夠適用于轉(zhuǎn)移概率動態(tài)變化的情況;與文獻[12,14]相比,本文方法能夠充分考慮網(wǎng)絡(luò)攻防的策略依存性。

表6 本文方法與典型方法的評估比較
將本文方法擴展至實際網(wǎng)絡(luò),其攻防對抗仍然符合隨機博弈過程,防御決策原理仍然正確,但是需要針對具體網(wǎng)絡(luò)的環(huán)境做一些調(diào)整。如果實際網(wǎng)絡(luò)規(guī)模較小,則本文方案可直接使用;如果網(wǎng)絡(luò)規(guī)模較大,一些網(wǎng)絡(luò)的攻防策略集和攻擊者類型數(shù)量會增加,導致博弈求解難度加大,還有一些網(wǎng)絡(luò)采用表存儲值時可能會消耗過多內(nèi)存,同時收斂速度也會降低。文獻[21]對第一類情況進行了總結(jié)與分析,給出了相應(yīng)的解決方案。如遇到第一類情況,可參考文獻[21]中的方法對博弈求解方式進行調(diào)整。如遇到第二類情況,可利用神經(jīng)網(wǎng)絡(luò)或深度學習等函數(shù)擬合的方式存儲值。需要注意的是,并不是本文現(xiàn)有的博弈求解方式和以表存儲值的方式存在問題,而是實際中不同網(wǎng)絡(luò)對算法有不同的需求,本文現(xiàn)有的博弈求解方式和以表存儲值的方式更適用于規(guī)模較小的網(wǎng)絡(luò),而文獻[21]中提供的求解方式和神經(jīng)網(wǎng)絡(luò)(深度學習)存儲值的方式則更適用于大規(guī)模網(wǎng)絡(luò)。兩者各有優(yōu)勢,由于這不是本文的研究重點,因此沒有對其進行深入討論。
7 結(jié)束語
[1] HU H, ZHANG H, LIU Y, et al. Quantitative method for network security situation based on attack prediction[J]. Security & Communication Networks, 2017(4): 1-19.
[2] HU H, LIU Y, ZHANG H, et al. Optimal network defense strategy selection based on incomplete information evolutionary game[J]. IEEE Access, 2018, PP(99): 1.
[3] FALLAH M. A puzzle-based defense strategy against flooding attacks using game theory[J]. IEEE Transactions on Dependable & Secure Computing, 2010, 7(1): 5-19.
[4] FILAR J, VRIEZE K. Competitive Markov decision processes[J]. Springer Berlin, 1996, 36(4): 343-358.
[5] 姜偉, 方濱興, 田志宏, 等. 基于攻防隨機博弈模型的防御策略選取研究[J]. 計算機研究與發(fā)展, 2010, 47(10): 1714-1723.
JIANG W, FANG B X, TIAN Z H, et al. Research on defense strategies selection based on attack-defense stochastic game model[J]. Journal of Computer Research and Development, 2010, 47(10): 1714-1723.
[6] LYE K W, WING J M. Game strategies in network security[J]. International Journal of Information Security, 2005, 4(1-2): 71-86.
[7] WEI L, SARWAT A, SAAD W, et al. Stochastic games for power grid protection against coordinated cyber-physical attacks[J]. IEEE Transactions on Smart Grid, 2016, PP(99): 1.
[8] ARFAOUI A, LETAIFA A B, KRIBECHE A, et al. A stochastic game for adaptive security in constrained wireless body area networks[C]//Consumer Communications & NETWORKING Conference. 2018: 1-7.
[9] LEI C, ZHANG H Q, WAN L M, et al. Incomplete information Markov game theoretic approach to strategy generation for moving target defense[J]. Computer Communications, 2018, 116: 184-199.
[10] LEI C, MA D H, ZHANG H Q. Optimal strategy selection for moving target defense based on Markov game[J]. IEEE Access, 2017, PP(99): 1.
[11] WATKINS C J C H, DAYAN P. Technical note: Q-learning[J]. Machine Learning, 1992, 8(3-4): 279-292.
[12] 劉陶, 何炎祥, 熊琦. 一種基于Q學習的LDoS攻擊實時防御機制及其CPN實現(xiàn)[J]. 計算機研究與發(fā)展, 2011, 48(3): 432-439.
LIU T, HE Y X, XIONG Q. A Q-learning based real-time mitigating mechanism against LDoS attack and its modeling and simulation with CPN[J]. Journal of Computer Research and Development, 2011, 48(3): 432-439.
[13] RANDRIANSOLO A S, PYEATT L D. Q-learning: from computer network security to software security[C]//International Conference on Machine Learning and Applications. 2015: 257-262.
[14] YAN J, HE H, ZHONG X, et al. Q-learning-based vulnerability analysis of smart grid against sequential topology attacks[J]. IEEE Transactions on Information Forensics & Security, 2017, 12(1): 200-210.
[15] HARSANYI J C, SELTEN R. A general theory of equilibrium selection in games[M]. Boston: MIT Press, 1988.
[16] CORMEN T H, LEISERSON C E, RIVEST R L, et al. Introduction to algorithms[M]. Boston: MIT Press, 2009.
[17] 張恒巍, 李濤. 基于多階段攻防信號博弈的最優(yōu)主動防御[J]. 電子學報, 2017, 45(2): 431-439.
ZHANG H W, LI T. Optimal active defense based on multi-stage attack-defense signaling game[J]. Acta Electronica Sinica, 2017, 45(2): 431-439.
[18] HUNG S M, GIVIGI S N. A Q-learning approach to flocking with UAVs in a stochastic environment[J]. IEEE Transactions on Cybernetics, 2016, 47(1): 186-197.
[19] SZEPESVARI C, LITTMAN M. A unified analysis of value-function-based reinforcement-learning algorithms[J]. Neural Computation, 1999, 11(8): 2017-2059.
[20] GORDON L, LOEB M, LUCYSHYN W, et al. 2015 CSI/FBI computer crime and security survey[C]//The 2014 Computer Security Institute. 2015: 48-64.
[21] 王震, 袁勇, 安波, 等. 安全博弈論研究綜述[J]. 指揮與控制學報, 2015, 1(2): 121-149.
WANG Z, YUAN Y, AN B, et al. An overview of security games[J]. Journal of Command and Control, 2015, 1(2): 121-149.
Defense decision-making method based on incomplete information stochastic game and Q-learning
ZHANG Hongqi1,2, YANG Junnan1,2, ZHANG Chuanfu1,2
1. The Third Institute, Information Engineering University, Zhengzhou 450001, China 2. Henan Province Key Laboratory of Information Security, Zhengzhou 450001, China
Most of the existing stochastic games are based on the assumption of complete information, which are not consistent with the fact of network attack and defense. Aiming at this problem, the uncertainty of the attacker’s revenue was transformed to the uncertainty of the attacker type, and then a stochastic game model with incomplete information was constructed. The probability of network state transition is difficult to determine, which makes it impossible to determine the parameter needed to solve the equilibrium. Aiming at this problem, the Q-learning was introduced into stochastic game, which allowed defender to get the relevant parameter by learning in network attack and defense and to solve Bayesian Nash equilibrium. Based on the above, a defense decision algorithm that could learn online was designed. The simulation experiment proves the effectiveness of the proposed method.
network attack and defense, stochastic game, Q-learning, Bayesian Nash equilibrium, defense strategy
TP393.08
A
10.11959/j.issn.1000?436x.2018145
張紅旗(1962?),男,河北遵化人,博士,信息工程大學教授、博士生導師,主要研究方向為網(wǎng)絡(luò)安全、風險評估、等級保護和信息安全管理等。

楊峻楠(1993?),男,河北藁城人,信息工程大學碩士生,主要研究方向為網(wǎng)絡(luò)信息安全、博弈論和強化學習等。
張傳富(1973?),男,山東萊蕪人,博士后,信息工程大學副教授,主要研究方向為計算機建模與仿真技術(shù)等。

2018?04?03;
2018?07?10
楊峻楠,624519905@qq.com
國家高技術(shù)研究發(fā)展計劃(“863”計劃)基金資助項目(No.2014AA7116082, No.2015AA7116040)
The National High Technology Research and Development Program of China (863 Program) (No.2014AA7116082,No.2015AA7116040)
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數(shù)理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數(shù)學大世界(2018年1期)2018-04-12 05:39:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
