使用混合差異性度量的分類器選擇方法*
2018-09-12 02:22:40米愛中
計算機與生活 2018年9期
米愛中,陸 瑤
河南理工大學 計算機科學與技術學院,河南 焦作 454000
1 引言
多分類器集成的目的是為了獲得更好的識別性能,在該項技術的研究過程中,可以很輕松地獲取大量分類器集合并通過某種手段進行融合。但是這種做法存在一些弊端:首先隨著分類器數(shù)量的增加勢必會加大存儲空間與運行時間的消耗;其次是經(jīng)過研究發(fā)現(xiàn),當分類器數(shù)量過大時,反而會由于分類器間差異度的減小而降低識別率[1]。因此分類器的選擇成為集成學習的重要研究方向之一,即從大量的分類器集合中挑選出具有一定差異度與準確率的分類器參與集成。
通常研究人員認為集成若干完全一致的分類器是無意義的,所選擇的分類器需要具有一定的差異性、獨立性與互補性[2]。目前比較流行的集成學習算法Bagging采用Bootstrap方法擾動訓練集,導致生成的分類器集合具有一定的差異。而另一種適用較為廣泛的集成學習算法Adaboost則采用一種權重分配機制串行生成具有一定差異度的分類器集合。諸多理論與實驗證明集成算法相較于單分類器能夠體現(xiàn)出更優(yōu)的分類性能,這是由于基分類器的差異導致在目標判別時可進行互補,進而提升識別率[3]。然而缺點是隨著分類器數(shù)量的增多,Adaboost會產(chǎn)生更大的時間開銷,而Bagging則會產(chǎn)生部分冗余的分類器導致不必要的空間開銷。因此一些學者開始進行基于差異性度量的分類器選擇研究,即在保障分類精度的基礎上去除冗余分類器,節(jié)約存儲空間。目前基于差異性度量的分類器選擇研究主要有兩個方向:
(1)以一種成對差異性度量方法作為標準的分類器選擇,如Li等人[4]提出的DREP(diversity regularized ensemble pruning)算法是根據(jù)分類器兩兩之間的差異度進行排序后選擇差異度較大的若干個分類器參與集成。該方法雖然在一些數(shù)據(jù)集上得到了證明并且有效地降低了集成規(guī)模,但是仍有一些不足的地方:首先是僅考慮一種差異性度量方法,并且該方法的選擇會影響排序結果;其次是排序時起始分類器的選擇問題,不同的起始分類器會產(chǎn)生不同的排序;最后是該算法需要人為指定選擇分類器的個數(shù)。
(2)以一類的差異性度量方法作為選擇標準,如Cavalcanti等人[5]提出的DivP方法是將5種成對差異性度量方法加權組合后作為分類器選擇標準,依據(jù)該標準將分類器集合分為若干組,并從中選擇準確率最高的一組參與集成。該算法雖然有效度量了分類器的差異度,但是仍然局限于一類的差異性度量方法,并且將分類器分組后僅以準確率作為各組分類器的篩選標準,并未考慮各組的整體差異度,因此可能會導致所選擇的分類器集合并不是最佳的一組。
針對以上問題,本文將成對與非成對差異性度量方法結合考慮,提出一種新的分類器選擇方法。本文方法主要由兩部分組成:(1)基于成對差異性度量的分類器分組。首先基于成對差異性度量公式計算得差異度矩陣,將差異度矩陣以一定方式轉換為鄰接矩陣后通過圖的形式表示分類器的關系,即將分類器分組問題轉換為圖著色問題,然后運用基于遺傳算法的圖著色方法將圖的頂點(分類器)進行動態(tài)著色分組。(2)以5種非成對差異性度量方法作為評價指標,建立基于信息熵[6]的評價體系。計算各組分類器集合的權值,并選擇最佳的一組分類器集合參與最終的集成。通過實驗分析本文方法與差異性度量、分類器規(guī)模的關系,并與目前流行的分類器集成方法進行對比。
本文組織結構如下:第2章介紹成對差異性度量的相關知識,并給出一種基于遺傳算法的分類器分組方法;第3章建立一個基于信息熵的評價體系;第4章進行算法的收斂性分析;第5章給出實驗結果與性能分析;第6章總結全文并展望未來的工作。
2 基于成對差異度的分類器分組
2.1 成對差異性度量
本文采用同質類型的(homogeneous)[7]基分類器,基于Bagging技術,通過Bootstrap方法擾動訓練集,生成規(guī)模為L的分類器集合。為了度量L個分類器間的差異性采用成對差異性度量方法,并通過整體取均值得到分類器集合的差異度。
目前常用的成對差異性度量方法有Q統(tǒng)計法(Q-statistic)、相關系數(shù)法(correlation coefficient)、雙錯法(double-fault)、不一致度量(disagreement)等[8]。
(1)Q統(tǒng)計法

(2)相關系數(shù)法
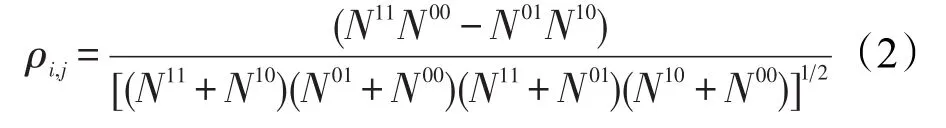
(3)雙錯法
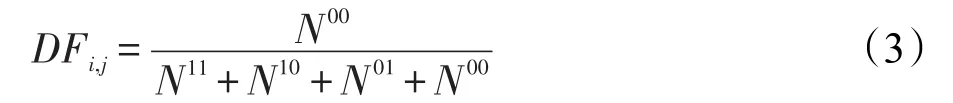
(4)不一致度量
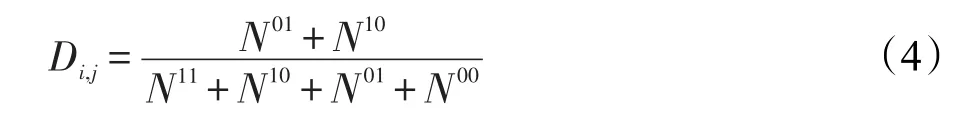
其中,Nij表示第i個分類器與第j個分類器的共同分類結果;N11與N00表示分類器ij均分類正確或錯誤;N10表示分類器i正確,分類器j錯誤;N01表示分類器i錯誤,分類器j正確。
結合成對差異性度量公式進行基分類器兩兩之間的差異度計算,生成L×L的成對差異度矩陣,如式(5)所示:
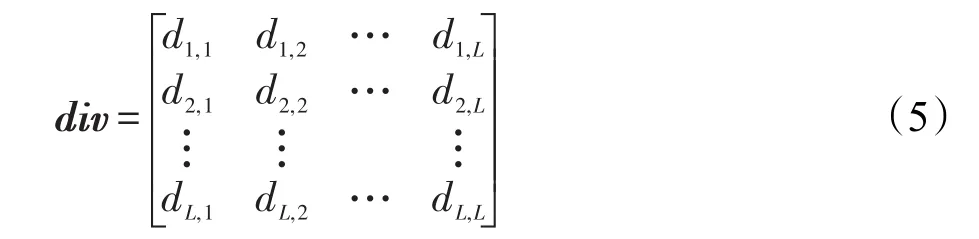
其中,div是對稱矩陣,主對角線di,j(i=j)表示分類器與自身的差異度,由于分類器與自身的差異度最小,因此在計算分類器集合整體差異度時并不將此考慮在內。
2.2 差異度矩陣的轉換
本文方法給出的差異度矩陣的轉換方式分兩步進行,其中轉換閾值設置為集合的整體差異度:
(1)根據(jù)L個分類器的差異度矩陣div,計算得L個分類器集合的整體差異度為:
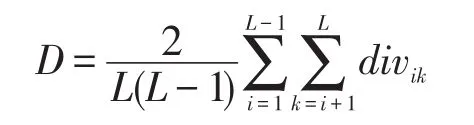
(2)根據(jù)整體差異度D,構造一個L×L的鄰接矩陣H,其中:
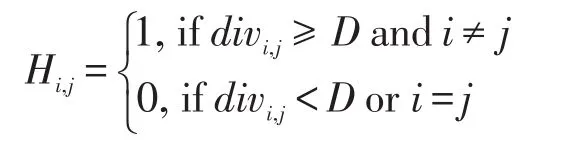
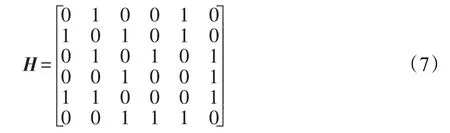
以6個分類器為例,假設式(6)為根據(jù)Q統(tǒng)計法計算得到的6個分類器集合的成對差異度矩陣,差異度的范圍是[0,1],差異度值越接近0代表差異度越大。通過計算得到該集合整體差異度為D=0.5。

將該成對差異度矩陣轉換為鄰接矩陣后如式(7)所示,需要注意的是主對角線元素為0,因為分類器自身不能與自身相連接。
根據(jù)該鄰接矩陣H可以畫出如圖1所示的無向圖G。
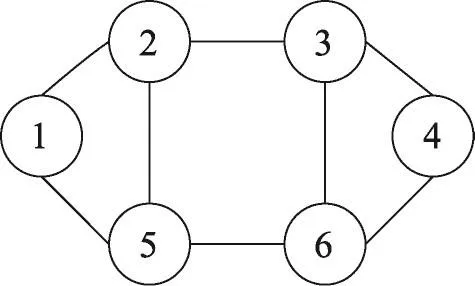
Fig.1 Undirected graph G created from adjacency matrix圖1 鄰接矩陣轉換為無向圖G
圖1中圓圈內標號表示1~6號分類器,由此將分類器以無向圖中的一個節(jié)點表示,通過邊連接的分類器差異度較小。為了盡可能多地選擇出差異度較大的分類器集合,并比較其各自的集成性能,引入了圖論中的著色算法。
2.3 遺傳算法求解圖的著色問題
圖的著色問題(graph coloring problem,GCP)[9-10]是圖論研究中的經(jīng)典問題之一。圖G=(V,E)的一個v頂點著色是指用v種顏色對圖G進行著色的一種分配方案,若該方案使相鄰頂點顏色不同,則稱著色正常,滿足此方案的最小顏色數(shù)稱為圖G的色數(shù)。如圖2所示,即為圖1中無向圖G的一種著色方案,該無向圖的色數(shù)為3。
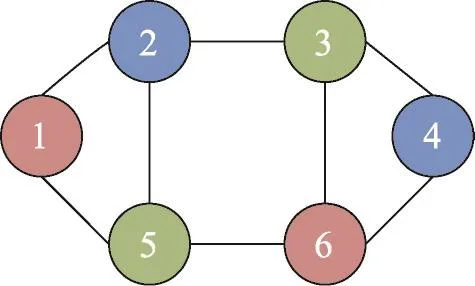
Fig.2 One coloring scheme for graph G圖2 圖G的一種著色方案
但是顯然圖2并不是唯一的著色方案,假設依舊以 Red、Blue、Green 3種顏色進行著色,Red(1,3)、Blue(2,6)、Green(4,5)同樣也滿足著色條件,即分類器1、3一組著紅色,分類器2、6一組著藍色,分類器4、5一組著綠色。為了得到滿足要求的不同的著色方案(即得到不同的分類器分組方式),本文基于遺傳算法給出了解決方式,之所以選擇遺傳算法是由于該算法具有良好的魯棒性、并行性,并且隨著該算法理論的不斷完善,利用遺傳算法解決圖著色問題是當前的一個熱點[11-12]。
假設集合中的分類器個數(shù)為L,每個分類器代表無向圖G的一個頂點,對于每種著色方案x,對應一條染色體x1,x2,…,xL,其中xi(xi=1,2,…,k)代表所著的顏色,k為最小的著色個數(shù)。
2.3.1 適應度函數(shù)
由于k種顏色且長度為L的染色體子空間規(guī)模為kL,當集合中分類器個數(shù)較多時會使得算法效率較低,因此本文將隨機產(chǎn)生染色體的編碼方案。根據(jù)圖G中節(jié)點的排列給出一種著色方案,并更新節(jié)點排序,更新規(guī)則是同顏色的節(jié)點按顏色編號依次排列。更新后序列的著色數(shù)小于等于原序列,從而找到該節(jié)點序列中的局部極小的次優(yōu)解。最終根據(jù)遺傳算法在次優(yōu)解空間中尋找最優(yōu)解。
本文方法不指定顏色數(shù)k,希望分類器集合動態(tài)分組,即自適應地找到最小顏色數(shù)k。若k種顏色下有M種著色方案,則將分類器分為kM組。因此適應度函數(shù)的設計為:
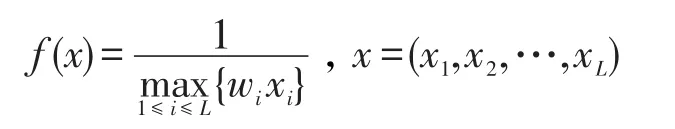
其中,wi為每個節(jié)點的權值,沒有特殊情況均設為是著色序列的最大顏色數(shù),采用該適應度函數(shù)得出的就是無向圖G的顏色數(shù)k。
2.3.2 交叉算子
本文交叉算子采用部分匹配交叉法[13],假設染色體x=(x1,x2,…,xL)與y=(y1,y2,…,yL)是參與雜交的父代個體。隨機產(chǎn)生交叉區(qū)域[m,n],使其變成x=(x1…ym…yn…xL)與y=(y1…xm…xn…yL)。然后確定xm~xn與ym~yn之間的映射關系xm→xm′,xm→xn′,ym→ym′,yn→yn′。利用映射得到新的合法染色體x=(x1′…ym…yn…xL′)與y=(y1′…xm…xn…yL′),即包括圖中所有頂點且不重復。如父代染色體(1,2,3,4,5,6)與(5,3,6,1,2,4)的交叉過程如圖3所示。
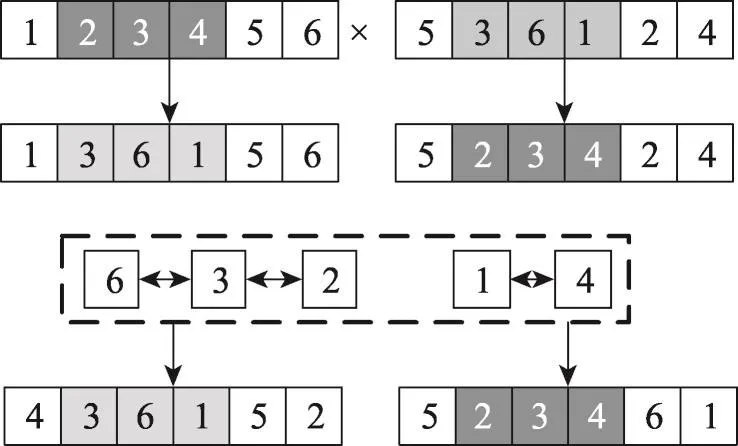
Fig.3 Process of chromosome crossing圖3 染色體交叉流程
2.3.3 變異算子
x=(x1…xm…xn…xL)以等概率隨機選取兩個基因位m和n,然后交換該位置的基因值,交換后的染色體記為x′=(x1…xn…xm…xL)。如染色體(1,2,4,3,5,6)選取兩個變異位2和5,變異結果為(1,5,4,3,2,6)。
通過該手段避免算法陷入局部最優(yōu)解,并且這種換位變異執(zhí)行簡單,有利于種群多樣性。
3 基于信息熵的分類器選擇
根據(jù)著色結果得到了不同的分類器分組方式,為了從中選出最佳的一組作為最終參與集成的分類器集合,針對基分類器子集建立了一個基于信息熵的評價體系,并將非成對差異性度量作為本次評價的重要指標。
常用的非成對差異性度量方法有KW方差(M1)、Kappa度量(M2)、熵度量(M3)、難度度量(M4)、廣義多樣性度量(M5)[14]。將其作為評價的5項指標,分別針對不同子集進行度量計算,并建立一個非成對度量矩陣Ndiv。基分類器子集w1,w2,…,wk的非成對度量矩陣如式(8)所示。
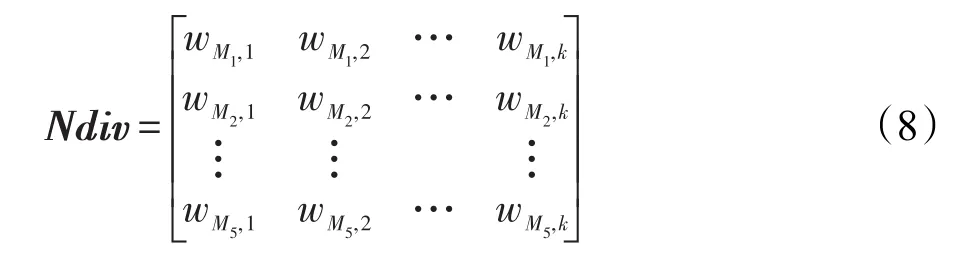
由于不同差異性度量方法的計算不同并且正負值的含義不同,因此接下來要對該矩陣進行標準化處理,即Ndiv=|Ndiv|,將差異性度量計算的絕對值轉換為相對值。并對正負指標分別進行標準化處理:
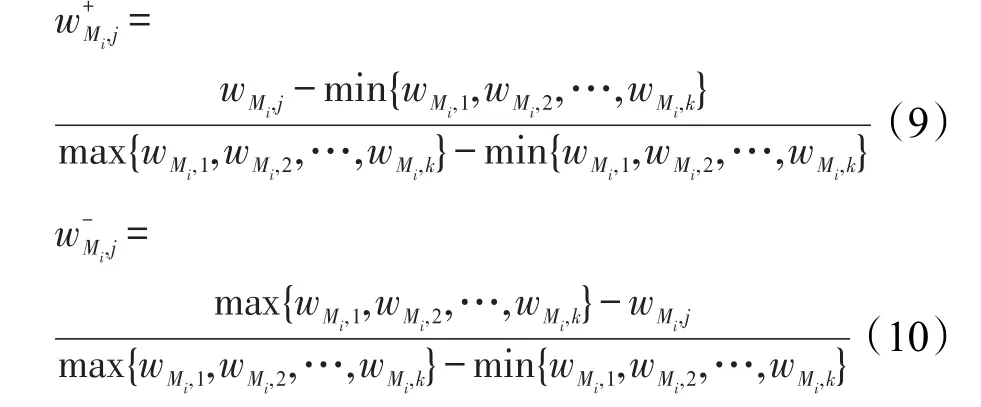
然后根據(jù)標準化后的差異度矩陣,計算各指標下第j個子集所占的比重:

其中,i=1,2,…,5,j=1,2,…,k。
接下來計算各非成對差異性度量方法的熵值:
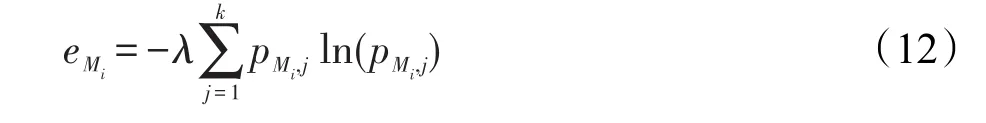
其中λ=1/ln(k)>0,滿足

最終根據(jù)權重計算各分類器子集的綜合得分:

根據(jù)最終評分選出最佳的一組分類器子集作為最終的集成對象。
4 算法收斂性分析
由于本文方法是基于遺傳算法的著色分組,因此需要進行收斂性分析。
定義1若任意兩個個體x和y,并且其關系為P{M°C(x)=y}>0,其中M°C(x)表示染色體x經(jīng)過交叉和變異產(chǎn)生的個體,則稱x和y是可達的。
引理1當遺傳算法的可行域中任意兩個個體是相互可達時,且種群序列P(0),P(1),…,P(t)單調,則遺傳算法以概率1收斂到全局最優(yōu)解。
證明假設染色體x參與雜交的概率Pa,染色體a是x雜交變異產(chǎn)生的任一后代,b是a局部搜索得到的新后代,b被選上參與變異的概率為Pc。
則由x雜交變異得到y(tǒng)的概率為P{M°C(x)=是從xi產(chǎn)生yi的概率,因此得到y(tǒng)由x變異可達,因此該算法是收斂的。 □
5 實驗
5.1 實驗方法與數(shù)據(jù)
本次實驗從UCI數(shù)據(jù)庫中選取了樣本數(shù)范圍為32~6 435的8組數(shù)據(jù)集,如表1所示。分類器的學習算法選用了不穩(wěn)定的決策樹(decision tree)15],該算法會由于訓練集的微小變化而改變。然后基于Bagging技術擾動訓練集生成50~150個分類器集合。并且實驗采用5重交叉驗證,以3∶1∶1的比例分為訓練集、驗證集和測試集,驗證集的存在是為了分析基于信息熵的評價體系。最后本次所選用的集成規(guī)則為投票法,其主要原因是這一規(guī)則無需訓練,并且也是目前多數(shù)文獻研究中所采用的方法[16]。
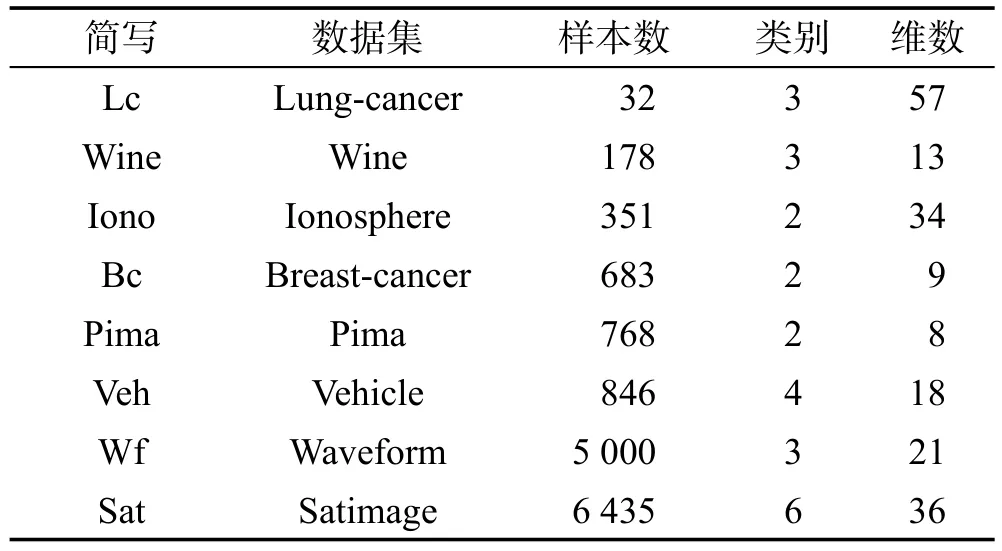
Table 1 Experimental data information表1 實驗數(shù)據(jù)信息
本次實驗平臺為Matlab R2014a,所用的基分類器均來自PRTools(http://www.prtools.org)工具箱。
5.2 實驗結果與分析
本次實驗結合控制變量法分4步進行。首先分別分析影響集成效果的因素,然后給出合理化建議,最后與當前流行的集成方法進行對比。
5.2.1 分析成對差異性度量方法
當使用不同成對差異性度量方法時得到不同的差異度矩陣,因此轉換的鄰接矩陣有所區(qū)別,再利用遺傳算法進行圖著色時可能會得到不同的結果。
本次實驗以目前流行的4種成對差異性度量方法(Q統(tǒng)計法、相關系數(shù)法、雙錯法、不一致度量)為標準,結果如表2所示,準確率最高的數(shù)值用加粗標記。
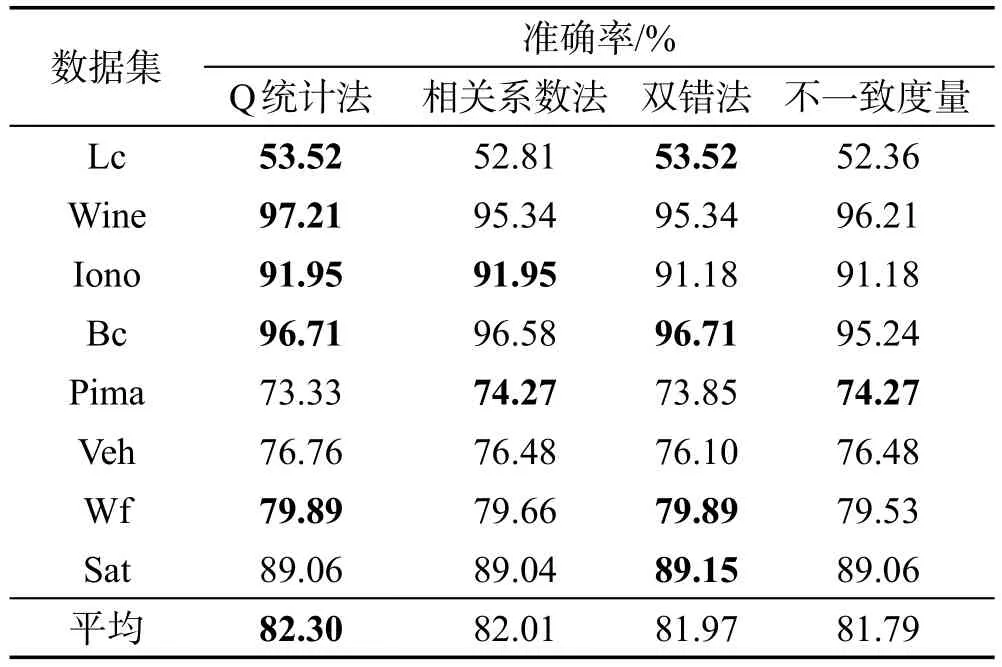
Table 2 Ensemble results of different diversity measures表2 不同差異性度量方法的集成結果
本次實驗的參數(shù):初始基分類器規(guī)模為100。
從表2可以看出,本文方法雖然在不同差異性度量標準下均可以獲得較好的分類效果,但是在大多數(shù)數(shù)據(jù)集下,以Q統(tǒng)計法作為度量標準時可以獲得相對更好的集成準確率。其次是雙錯法、相關系數(shù)法與不一致度量。
為了更好地比較這幾種度量方法,分別計算不同度量方法選擇出的分類器個數(shù),以10次實驗的平均值為最終結果,如圖4所示。
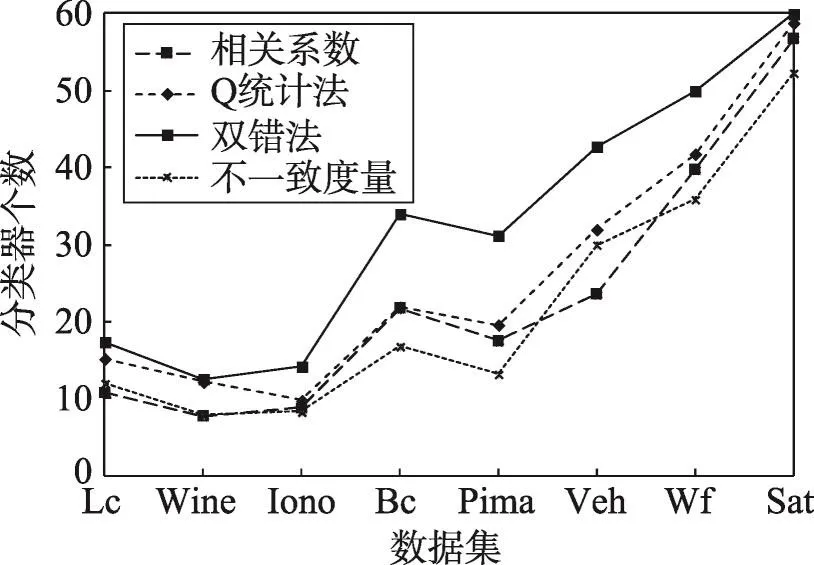
Fig.4 Number of classifiers in different datasets圖4 數(shù)據(jù)集的分類器個數(shù)
由圖4可以看出,無論使用哪種差異性度量方法,選擇出分類器的個數(shù)都隨著數(shù)據(jù)集樣本數(shù)的增加而增加。通過縱向對比可以看出,這4種度量方法中雙錯法相較于其他方法選擇出的分類器個數(shù)較多,其次是Q統(tǒng)計法、相關系數(shù)法、不一致度量。結合表2的集成準確率可以看出,Q統(tǒng)計法能在保障集成精度的同時,盡可能地相對減小集成規(guī)模,因此可以優(yōu)先以Q統(tǒng)計法作為成對差異性度量標準。
5.2.2 分析集成規(guī)模與結果
分類器的規(guī)模是影響集成效果的因素之一。為了分析當分類器規(guī)模發(fā)生變化時,本文方法對集成結果產(chǎn)生的影響,本次實驗首先基于Bagging生成了3種規(guī)模(50,100,150)大小的基分類器集合,并使用本文方法進行選擇性集成,將最終集成結果與Bagging(Bag)直接集成進行對比,如表3所示。
本次實驗參數(shù):成對差異性度量方法為Q統(tǒng)計法。
由表3可以看出,當分類器規(guī)模為50、100、150的情況下,在8組數(shù)據(jù)集中本文方法相較于Bagging的集成準確率平均提升1.57%、1.98%、1.62%,其中分類器規(guī)模為100時的提升效果最高。
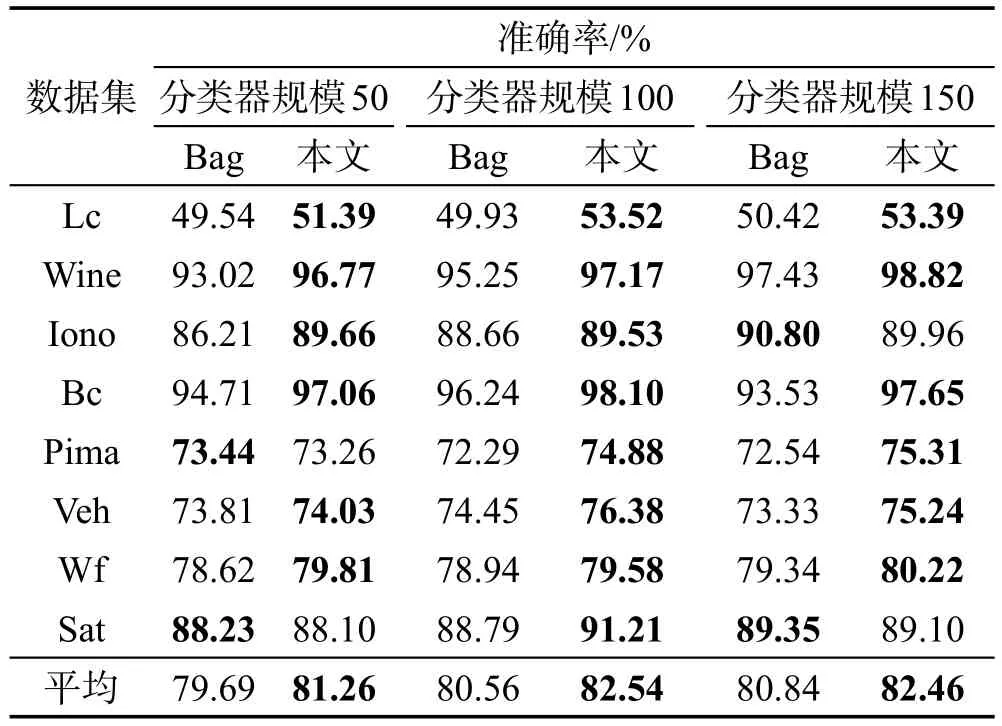
Table 3 Ensemble results on different scales表3 不同規(guī)模時的集成結果
5.2.3 分析基于信息熵的評價體系
本文提出的基于信息熵的評價體系是將5種非成對差異性度量方法動態(tài)加權,計算各組分類器綜合得分,并根據(jù)評分情況進行挑選。為詳細分析該評價體系,首先分別以每種非成對差異性度量方法為標準進行分類器集合的選擇,結果如表4所示。
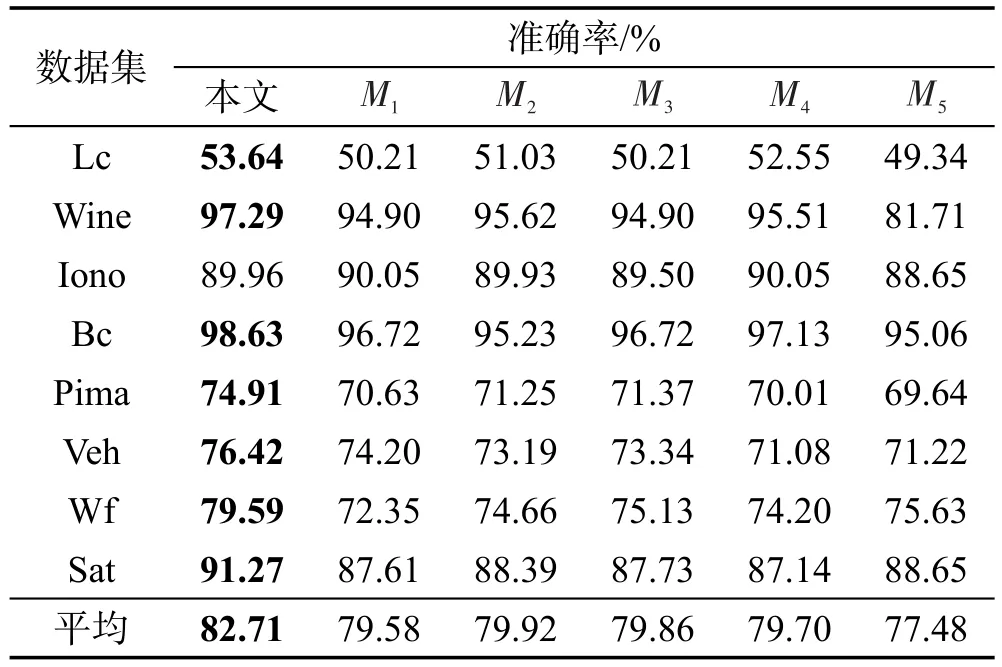
Table 4 Ensemble results of different non-pairwise diversity measures表4 不同非成對差異性度量方法的集成結果
本次實驗參數(shù):集成規(guī)模為100,成對差異性度量方法為Q統(tǒng)計法。
由表4可以看出,除Ionosphere數(shù)據(jù)集,由本文方法所選出的分類器集合的集成效果均好于以單個非成對差異性度量方法為標準進行挑選的分類器集合。
但是目前僅是從分類器差異性的角度進行考慮,接下來要從準確率的角度進行實驗。首先將著色分組后的各集合分別對驗證集進行識別,將準確率最高的一組分類器集合與通過評價體系選出的分類器集合針對測試集進行識別。實驗結果如圖5所示。

Fig.5 Accuracy and evaluation system圖5 準確率與評價體系
由圖5可以看出,兩種分類器集合的選擇方法均擁有較高的識別精度,這是由于本文方法中的基于遺傳算法的著色分組合理地將差異性較大的分類器挑選出來。通過評價體系選出的集合與直接選出針對驗證集準確率最高的集合在最終集成效果上非常相似,這是由于在實驗過程中,兩種選擇方法有時選出的分類器集合是相同的。但是通過評價體系選出的分類器集成效果仍有一定的提升,因此也證明了針對驗證集分類效果良好的分類器集合不一定對測試集分類效果最好。通過差異性與準確率兩個角度進行的實驗均證明本文提出的基于信息熵的評價體系具有一定可行性。
5.2.4 分析集成方法
上述實驗中已經(jīng)針對影響集成效果的因素分別進行了分析,接下來將本文方法與目前比較流行的4種集成方法Bagging(Bag)、Adaboost(Ada)、DREP[3]、DivP[4]進行比較。
本次實驗的參數(shù):集成規(guī)模為100,本文方法與DREP算法的成對差異性度量方法選擇為Q統(tǒng)計法,DivP算法為默認參數(shù),集成規(guī)則均為投票法。實驗結果如圖6所示。
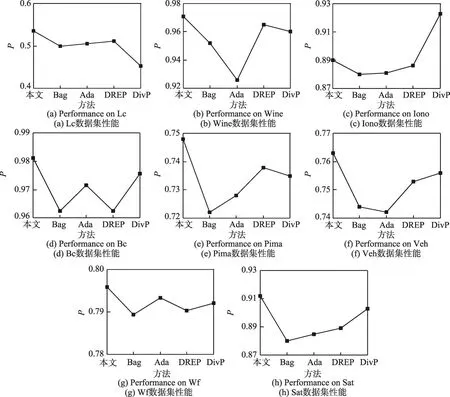
Fig.6 Performance comparison of ensemble methods圖6 集成方法的性能比較
由圖6可以看出,除Ionosphere數(shù)據(jù)集下本文方法的表現(xiàn)力略遜色于DivP算法,大多數(shù)數(shù)據(jù)集下本文方法與目前流行的集成算法相比,均接近或者超過其識別精度。本文方法與DivP算法的主要區(qū)別在于DivP算法以準確率作為各組分類器的篩選標準,而本文方法則是以準確率與差異度建立了一種評價體系作為各組分類器集合的篩選標準。事實證明大多數(shù)數(shù)據(jù)集下本文提出的方法具有一定的可行性。
6 結束語
選擇出具有一定差異度的分類器集合是獲得良好集成效果的前提之一。本文將成對與非成對差異性度量方法結合提出了一種新的分類器選擇方法,并分析該方法以不同成對差異性度量作為標準、不同分類器規(guī)模下的集成效果,將該方法與目前流行的若干種集成方法進行對比分析,最終得到了有一定指導意義的結論。
此外本文方法有待改進的地方主要有兩點:(1)分類器著色分組過程中,差異度矩陣轉換鄰接矩陣時的閾值設置可以進行改進,本文的閾值是采用整體差異度的平均值,后續(xù)研究也可嘗試其他設置方式。(2)本文的圖著色方法是基于遺傳算法提出的,后續(xù)也可以嘗試模擬退火或蟻群算法等啟發(fā)式算法。因此擬將算法根據(jù)這兩部分進行分析與改進,以提升分類器集成精度。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
音樂探索(2022年2期)2022-05-30 21:01:37
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小天使·一年級語數(shù)英綜合(2019年8期)2019-08-27 02:23:00
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
