基于鐵路安全管理信息報告的文本挖掘技術研究
2018-09-11 02:18:24張磊,王喆
鐵路計算機應用 2018年8期
張 磊,王 喆
(1.中國鐵路廣州局集團有限公司,廣州 510088;2.中國鐵道科學研究院集團有限公司 鐵路大數據研究與應用創新中心,北京 100081)
近年來,中國鐵路快速發展,鐵路運營里程不斷增加,行車速度大幅提高,為整個社會的快速發展以及國民經濟的高速增長做出了巨大貢獻[1]。為確保鐵路運輸生產安全持續穩定,鐵路運輸部門不斷創新安全管理思路及方法,如將風險管控與干部履職考核掛鉤,促進風險管控措施落實[2]。但此過程中產生了大量安全管理信息報告,這些信息對于開展鐵路安全大數據研究、查找事故發生規律有著重要的價值。
高速鐵路運營和科研單位已經就鐵路文檔報告數據開展了很多探索和分析。如文獻[3]采用主題模型對高鐵車載設備故障追蹤表進行分析和特征提取,并根據車載設備的特點與領域專家知識對車載設備故障進行診斷。文獻[4]對地鐵施工事故報告進行分詞處理、特征項選擇、規律識別,并利用詞云和網絡結構圖等方法可視化文本挖掘結果。文獻[5]采用TF-IDF模型實現鐵路信號設備故障文本的特征提取,并基于Voting的方式實現故障的智能分類。文獻[6]采用基于層疊隱馬爾科夫的分詞算法對鐵路基礎設施設備質量問題數據進行分詞處理并統計詞頻,利用詞云圖展示結果。現階段的各項研究中,對鐵路安全管理報告型文檔的分析挖掘研究尚不成熟,尤其是對安全風險庫、干部履職、安監報和鐵路交通事故故障等信息的特征詞提取研究不多,導致難以查找各安全管理信息報告之間的相關性。因此,如何分析和利用此類報告文檔豐富安全管理專業詞庫,并結合事故致因論查找事故發生規律有著重要意義。
文章采用卡方檢驗提取文本特征詞,并用樸素貝葉斯算法對文本進行分類,提取鐵路安全管理信息報告文檔的特征詞,為豐富鐵路安全專業分詞庫提供一種思路。
1 思路及步驟
文本挖掘技術本身涉及統計學、自然語言學、機器學習等多個領域的知識,為研究各類事物及現象提供了新的可能。具體的文本挖掘任務則包括將文本集分成幾個主題領域(分類或有監督學習),依據樣本間相似度將文本集分成幾組(聚類或無監督學習),依照一些搜索準則搜索合適的文本(文本檢索)[7]。
文本挖掘步驟:(1)從文本集中提取特征,以便研究人員使用統計方法來計算文本。(2)構建公式化度量文本間的距離以便顯示文本間的相似度。(3)可使用分類、聚類及多公式化等方法降低編碼特征的維數。在低維數空間中可重新考慮聚類等問題。
2 常用文本挖掘算法
2.1 卡方檢驗
卡方檢驗的最基本思想是通過觀察實際值與理論值之間的偏差來確定理論的正確與否[8]。通常假設這兩個變量確實是獨立的,觀察實際值A與理論值E之間的偏差程度X2(理論值是“假如兩者獨立”時應有的值)。若偏差X2足夠小,則認為誤差是自然的樣本誤差,此時就接受原假設;如果偏差足夠大,則認為這兩者實際上是相關的,此時就接受備擇假設。卡方檢驗的基本公式為:

在文本分類的特征選擇階段,主要關注單詞t(隨機變量)和類別c(另一個隨機變量)是否相互獨立。公式中A表示單詞t屬于類別c的文檔頻數,E表示假設單詞t與類別c無關情況下的文檔頻數。用該方法可以得出單詞同文檔之間的相關性排序,計算值越大相關性越高。
2.2 樸素貝葉斯
樸素貝葉斯分類屬于一種簡單的分類算法,其思路是對于給出的待分類項,求解在此項出現的條件下各個類別出現的概率,概率最大的就認為此待分類屬于哪個類別[9]。正式定義如下:
(1)設x={a1, a2,…,am}為一個待分類項,而每個a為x的一個特征屬性;有類別集合C={y1, y2,…,yn}。
(2)計算 P(y1|x),P(y2|x)…, P(yn|x)。
(3)如果 P(yk|x) =max{P(y1|x), P(y2|x),…, P(yn|x)},則 x∈ yk。
條件概率計算可以按照如下步驟進行:
(1)找到一個已知分類的待分類項集合,即訓練樣本集。
(2)統計獲得在各類別下各個特征屬性的條件概率估計,即:
P(a1|y1), P(a2|y1),…, P(am|y1), P(a1|y2), P(a2|y2),…,P(am|y2),…, P(a1|yn), P(a2|yn),…, P(am|yn),…。
(3)如果每個特征屬性都是條件獨立的,則貝葉斯定理具有以下推導:

由于分母對于所有類別都是不變的,因此只需要最大化分子。 又因為各特征屬性是獨立的,所以有:
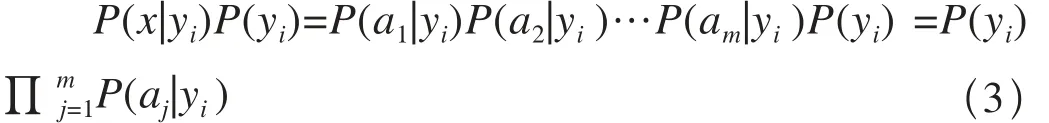
樸素貝葉斯可以分為形成訓練樣本集合、生成分類器和使用分類器3個階段。在處理文本分類問題時,x是待分類文檔,ai是文檔的特征詞,C是文檔類別集合。樸素貝葉斯通過計算文檔中每個特征詞屬于不同分類的概率,從而得到整篇文檔的分類結果。
3 文本挖掘技術方案
3.1 文檔預處理
目前,安全管理信息報告多以Word、Excel格式存儲,Word格式文檔又具體分為doc后綴和docx后綴兩種,Excel格式文檔又具體分為xls后綴和xlsx后綴。為便于后續分詞操作,需要先將兩種文檔轉換成TXT文本,字符集編碼采用UTF-8格式。另外,還需要對轉換后的文本進行無效詞去除,比如特殊字符、原文檔中頁眉頁腳等內容。
3.2 分詞
對鐵路專業的文檔分詞關鍵是構建能夠理解鐵路專業術語的鐵路專業分詞庫。目前,社會上公開發布的專業分詞庫多為通用領域的,鐵路行業本身并沒有發布滿足鐵路文本挖掘需求的分詞庫。基于現狀,本文采用基于搜狗提供的交通專業詞庫結合鐵路領域專家確認后得到的鐵路專業詞庫,綜合常用詞庫作為分詞的依據。
文章采用分詞工具ICTCLAS對文檔進行預處理,獲得文本資料。分詞后得到的詞組中包含了許多對分析挖掘無效的詞匯,比如標點符號、“但是”、“可以”等。本研究選取了較常見的1 893個詞匯和符號構成的停用詞表作為去除無效詞的依據。
3.3 樣本訓練
分詞結束后的文檔集形成了M ? N矩陣,其中,M表示文檔集合中文檔的數量,N表示文檔中包含的詞匯數量。另外,算法還生成了詞匯編號表(對文檔中所有出現的詞匯進行順序編號,矩陣中記錄編號值)、詞匯文檔頻次表(記錄某一詞匯出現在文檔集中多少個文檔中)以及文檔分類信息表等。生成的矩陣以及信息表是后續的特征選擇算法和分類算法操作的基礎。本文使用python語言實現了卡方檢驗和樸素貝葉斯算法,采用卡方檢驗作為文本特征詞提取的算法,文本分類算法選用的是樸素貝葉斯算法。
3.4 應用模型挖掘文本
某鐵路局集團公司積累了2 480份鐵路交通安全事故故障報告以及安監報信息。我們對上述報告文檔進行了特征詞提取,并去除“構成”、“故障”、“司機”、“調度員”等卡方檢驗值較高但對安全管理信息報告文檔分析無意義的特征詞,得到了對應該文檔的特征詞及卡方檢驗結果值,示例如表1所示。
卡方檢驗值越大則表明該詞匯對當前文檔分類的效果越明顯。在此示例中,我們選取了卡方檢驗值最大的前20個詞匯作為本文檔的特征詞。
安全管理信息報告主要分為安監報、設備故障調查報告和鐵路交通事故調查報告等3類,本文選取了上述文檔中安監報信息報告70份、設備故障調查報告50份、鐵路交通事故調查報告30份,共計150份文檔進行了人工分類,可以計算得出統計表1中特征詞在各分類中出現的頻率,如表2所示。
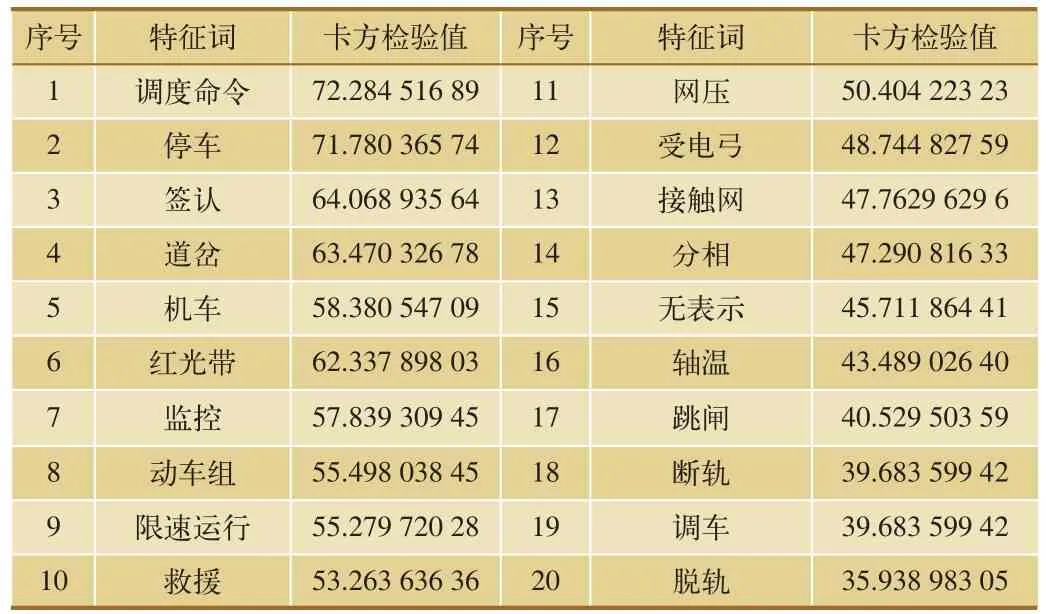
表1 卡方檢驗結果值
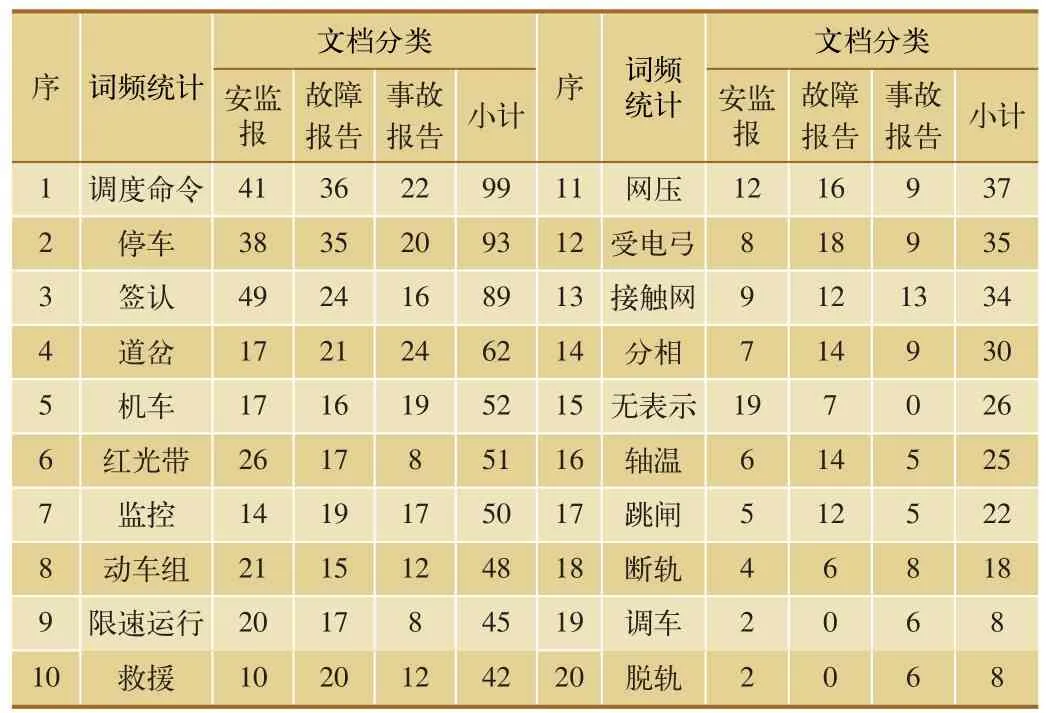
表2 文檔分類及詞頻統計
基于上述特征詞在分類中出現的詞頻及概率,可以通過樸素貝葉斯算法對剩余文檔進行分類計算。經過驗證,2 330份文檔分類正確為2 003份,準確率達到了86%。
4 結束語
本文采用卡方檢驗和樸素貝葉斯算法對鐵路安全管理信息報告文檔的特征提取,可以較為準確地獲取文檔的關鍵詞。但由于訓練樣本不足,同時文本錄入者對關鍵詞的習慣用法略有差別,準確率有待進一步提升。下一步將繼續優化鐵路安全管理信息文檔的挖掘、檢索和應用,最大限度地提取非結構化文檔中的重要信息,并充分利用系統工程、事故致因等理論開展安全大數據應用研究。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
云南畫報(2021年12期)2021-03-08 00:50:54
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
鐵道通信信號(2018年7期)2018-08-29 01:17:04
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
通信電源技術(2016年4期)2016-04-04 02:58:04
工程建設與設計(2016年3期)2016-02-27 10:50:46
