基于Hadoop的衛生陶瓷缺陷檢測研究
2018-09-04 16:36:08
制造業自動化 2018年8期
(唐山學院,唐山 063000)
0 引言
隨著人民群眾生活水平的日益提高,近20年來,我國建筑衛生陶瓷行業得到飛速發展,從20世紀90年代初開始,其產量一直處于世界第一的位置。并且還創造了中國世界紀錄協會世界建筑衛生陶瓷產生產量最多的國家新的世界紀錄。特別是2010年,隨著大規模的工業化生產,我國建筑陶瓷行業已經出現了廣東、福建、四川、江西等幾大陶瓷產區,我國也成為世界上建筑陶瓷生產和出口大國。衛生陶瓷作為一種有釉的陶瓷制品,在燒制上釉的過程中,也會出現開裂、缺釉、色差等缺陷[1]。在機器視覺的檢測過程中,常用高清工業相機進行拍攝,然后利用相應算法進行檢測[2,3]。
這些機器視覺的檢測方法大多采用的是單處理器的方式,對應于數量龐大的待測高清圖像集來說,存在處理數據量大,處理速度較慢的問題,且無法并行運算處理。在大數據時代,工業產品機器視覺檢測領域,待測圖像的數量不計其數。隨著云計算、大數據技術的發展,使得高效、快速進行工業產品檢測成為可能。
Hadoop是目前采用的一種并行、分布式的數據處理平臺[4]。在圖像處理相關領域有著廣泛的應用前景。例如趙進超[5]等在Hadoop平臺實現了圖像紋理特征的提取;余征等[6]利用Hadoop平臺進行了人臉識別算法的應用,運行速度及效率較高;白靈[7]在Hadoop平臺下進行SVM圖像識別,進而實現了對圖像進行快速分類;夏曉云等[8]使用Hadoop里的MapReduce技術結合圖像檢測算法對液晶屏幕缺陷進行檢測,提高了檢測效率。
1 相關技術
Hadoop是Apache基金會所開發的一種分布式基礎架構,具有高可靠性、高拓展性、高效性、高容錯性、低成本等一系列特性,用戶可以輕松地在Hadoop上開發和運行處理海量數據的應用程序。Hadoop框架最核心的設計HDFS與MapReduce分別可以實現海量數據存儲與海量數據計算[9]。作為大數據時代的衍生物,Hadoop云計算平臺在海量數據并行處理方面效果顯著。Hadoop云計算平臺的核心技術為HDFS(Hadoop Distributed File System)和MapReduce(映射-歸一),分別表示分布式存儲技術和并行分布式計算技術。Hadoop最初是由Nutch項目的開發團隊,在Google的GFS技術和MapReduce的基礎上,研發出了NDFS系統,這個系統是個開源系統。并逐漸被谷歌、微軟、阿里等大廠商認可,后來更名為HDFS。Hadoop的底層是由Java編寫,也就是說可以直接使用Java語言進行編程,也可以用其他語言編寫相關函數封裝使用。
HDFS負責海量數據的分布存儲,由一個主節點和若干從節點的典型主從結構組成。其中主節點為主控服務器,用于管理協調從節點的分布作業調度。Hadoop在運行過程中主要有兩個運行階段,每個階段都使用鍵值作為作業處理的輸入和輸出。并且采用了標準的函數編程的模式,分別對應了mapper( )和reducer( )兩個Hadoop自帶的函數。mapper( )函數對應著輸入數據的分片映射處理,而reducer( )函數實現了mapper( )處理后數據的統計重構。從而實現了數據分布式并行處理的過程。
2 海量衛生陶瓷圖像的并行檢測
圖像處理技術經過幾十年的發展,雖然有很多研究人員在算法的執行效率方面進行研究,但目前的圖像處理工作存在處理量大,算法較為復雜的特點,在處理研究上已經遇到瓶頸。因此將圖像處理算法引入到云計算平臺中是有重要意義的。因為Hadoop云平臺自身也帶了處理小文件的技術方案。Hadoop在HDFS中存儲塊的大小為64MB,小于64MB這種的文件統稱為Hadoop小文件。該方案稱為組合分片技術,在此不用考慮文件怎樣被組合分片的。通過對大量Hadoop小文件的合并大大減少了Map映射任務的啟動次數,從而提升了文件處理的速度。云計算平臺的并行集群化計算,能在時間性能上得到顯著的提升。本文提出的衛生陶瓷缺陷檢測云平臺處理步驟如下,其框架如圖1所示。
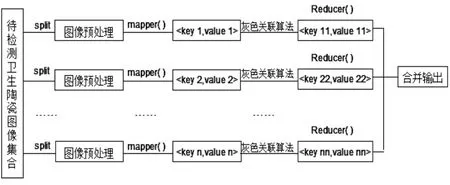
圖1 衛生陶瓷缺陷檢測云平臺的框架圖
第一步:將待測的衛生陶瓷圖像集合分成若干split,在這里每幅圖像即為一個split;
第二步:各從節點調用mapper( )函數,接收split傳入后的數據,并行提取每幅圖像的特征,生成相應的特征矩陣;
第三步:利用灰色關聯算法[6]對選取的關鍵點進行關聯處理,判斷是否有缺陷區域;
第四步:主節點調用reducer( )函數將mapper( )函數處理的結果進行合并,由RecordWriter類寫回指定的HDFS中。
3 衛生陶瓷缺陷檢測云平臺系統設計
3.1 Hadoop云平臺的搭建
1)硬件平臺
本文搭建的衛生陶瓷缺陷檢測的Hadoop云平臺由5臺普通的PC機組成。其中主節點采用的是Intel酷睿i5 4460四核心,3.2GHz主頻,6M三級緩存,內存8GB,硬盤2TB;4個從節點采用的是酷睿i3 6100四核心,3.7GHz主頻,6M三級緩存,內存4GB,硬盤1TB。
2)軟件平臺
操作系統:5臺PC機都安裝Ubuntu14.04,32位linux操作系統;
Hadoop版本:Hadoop 2.7.1;
軟件框架:Eclipse和JDK 1.8。
3)Hadoop網絡平臺的搭建
該云平臺分布并行系統中的主、從節點都通過千兆以太網進行連接,配置Java語言實現映射、歸一化。該Hadoop云平臺的各主從節點都屬于同一個局域網,具體網絡配置如表1所示。
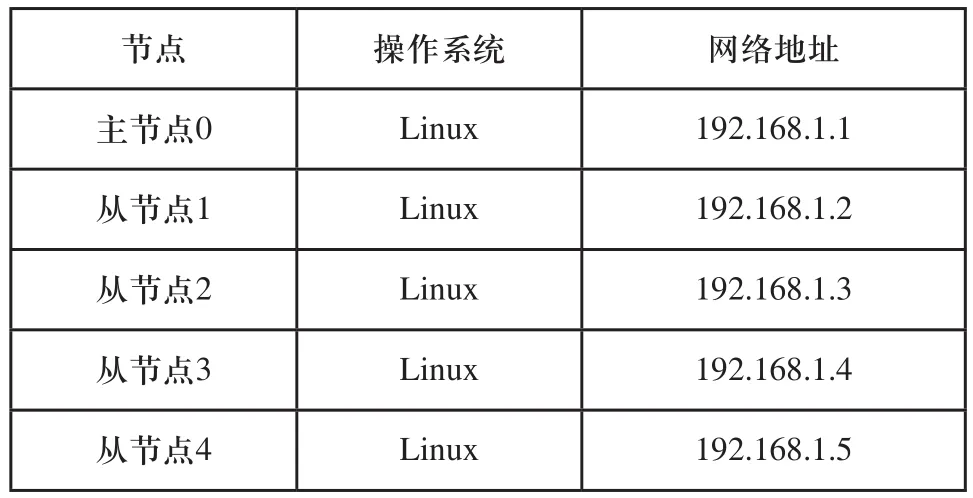
表1 Hadoop云平臺網絡配置
3.2 灰色關聯算法
灰色決策系統關聯就是利用所研究對象的“部分信息已知,部分信息未知”的“小樣本”、“貧信息”,通過一定的方式和技巧對“部分”已知信息的生成、開發,提取有價值的信息,實現對研究對象的確切描述和認識,對未來的行動作出決定[10,11]。對于所提取的具有缺陷的衛生陶瓷制品圖像來說,要么有缺陷,要么沒有缺陷,因此可以將陶瓷制品缺陷圖像轉化為本文算法的灰色系統,也就是可以使用灰色理論中非常重要的灰色關聯度算法進行缺陷區域提取[12,13]。
1)設m×n系統一個參考序列的初值像值,如式(1)所示。
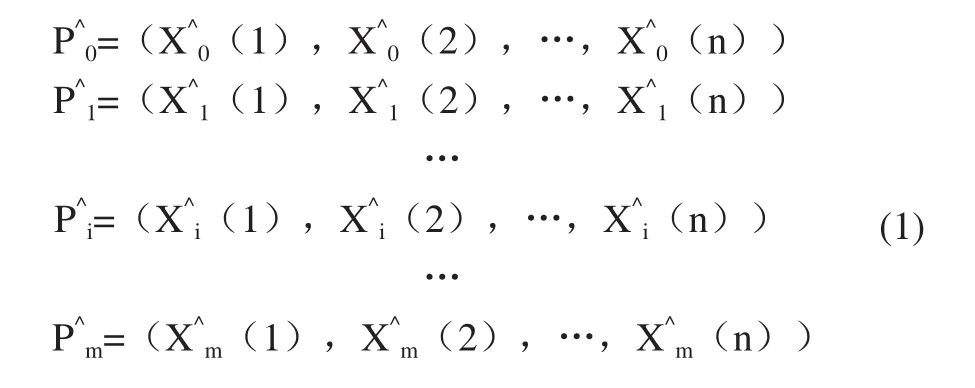
2)參考序列差,如式(2)所示。
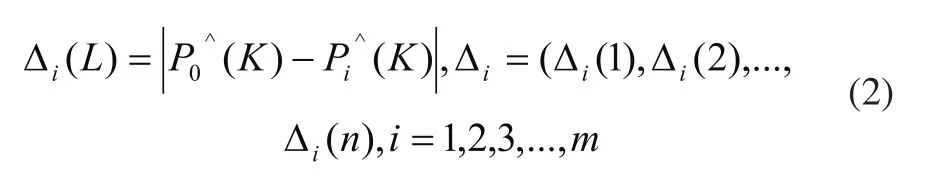
3)求解兩極端的最大差以及最小差,如式(3)所示。
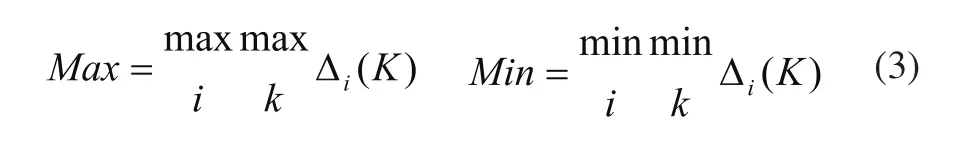
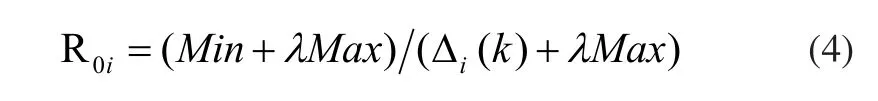
5)求解關聯度,如式(5)所示。
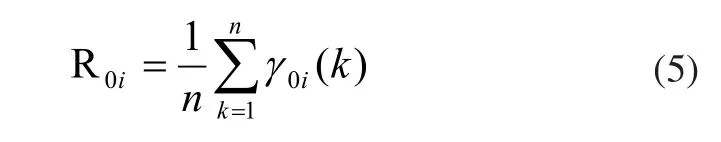
首先,對原始待測圖像按照灰色關聯理論提取出顏色特征N種,即利用上述算法簡化圖像所需計算的范圍,也就是將m×n的待測圖像,使用式(1)~式(5)分行進行關聯度R0i的計算,分成N類。然后加入確定好的缺陷特征顏色,構成N+1個參考序列,最后將圖像中的所有像素與N+1種顏色計算其灰色關聯度,取出關聯度最大者將其歸為該類,最后判斷歸為缺陷特征的顏色像素點的真偽。這樣就可以把缺陷目標區域與正常圖像進行本質分割,達到預期的效果。
3.3 缺陷檢測算法描述
本系統平臺所使用的缺陷檢測算法,是對缺陷衛生陶瓷的開裂、顏色、形狀和尺寸等參數,利用機器視覺算法進行特征提取,然后進行相應的計算識別,具體步驟如下:
舞蹈作品是由舞蹈動作組成舞句再連成舞段再由舞段銜接成一個舞蹈作品的這樣一個過程,音樂是由音符組成小節再連成一句繼續延伸到一段再銜接成一首曲子的這樣一個過程,所以音樂與舞蹈的創編過程是相似的,音樂是由單個的音符、舞蹈是由單個的動作這樣往后繼續延續形成的一個作品,而且都是具有行進與推動性的,在時間值上也都具有變化,因此音樂與舞蹈都是具有節奏的這便是它們的基礎與共性,也因此決定了音樂與舞蹈不可分割的藝術表演形式。
1)建立衛生陶瓷缺陷特征模型,主要包括顏色、形狀和尺寸等幾個方面,使用基于灰色理論的圖像處理方法,主要根據衛生陶瓷缺陷的顏色特征進行檢測,形狀和尺寸特征作為缺陷判別的輔助手段。
2)采集衛生陶瓷圖像,這里使用彩色圖像。
3)對圖像進行常規處理,這里主要是彩色圖形的濾波處理,為了提高效率濾波算法也使用基于灰色理論的圖像處理方法[14]。
4)對衛生陶瓷圖像按照像素的顏色值進行分類,為了便于處理和提高效率,這項操作選在RGB空間進行。
5)搜索與缺陷顏色特征隸屬度高的像素[15],然后通過其形狀和尺寸特征給出最終判斷。
6)為了用戶能夠對缺陷方便察看,所以對判斷出的缺陷區域,按照標定算法對缺陷區域進行標定。
3.4 基于Hadoop云平臺的衛生陶瓷缺陷圖像區分
如圖1所示,mapper( )函數映射后的圖像數據,經過灰色關聯算法進行并行處理運算,有缺陷的使用標定算法在原圖像進行標定。然后將處理結果使用Hadoop自帶的API函數ImageRecordReader(此函數繼承于RecordReader類),把輸入的圖像split轉化為<key,value>對的形式。在這里經過Java語言編程,將有缺陷的value標為1,將沒有缺陷的value標為0。然后將處理結果交由用戶自定義的reducer方法進行處理,并將結果傳入預先指定的Hbase區域,進行數據的存儲。最后將檢測結果,匯聚到主節點上,給用戶進行反饋輸出。用戶既可以得到檢測結果,又可以根據檢測結果找到已測圖像從而進行科學分析。
4 實驗結果分析
為了驗證本文提出的方法能夠并行檢測出衛生陶瓷圖像的缺陷,筆者以4幅分辨率640×480的存在缺陷的衛生陶瓷圖像為例,進行基于Hadoop的MapReduce的分布式并行缺陷檢測實驗和單機檢測實驗,待測圖像和相應處理結果如圖2和圖3所示。

圖2 Hadoop并行處理前待測圖像
圖2(a)表示了衛生陶瓷正面開裂的缺陷,圖2(b)表示了衛生陶瓷垂直面開裂的缺陷,圖2(c)表示了衛生陶瓷側面開裂的圖像,圖2(d)表示了衛生陶瓷側面開裂的情況。通過分析可知,圖2中各圖像的亮度和對比度有所不同,是因為衛生陶瓷的立體特性,從而導致工業相機在拍攝時得到的圖像效果不同。如果用傳統的直方圖以及色差處理方法,很容易將沒有缺陷的圖像誤判為有缺陷。由圖3可知,灰色關聯算法很好的解決了這個問題。因為衛生陶瓷缺陷區域在衛生陶瓷生產過程中由于工藝的原因,占比很小,所以只需在拍攝的區域進行缺陷檢測,利用灰色關聯算法的歸類特性進行缺陷檢測。

表2 單機和Hadoop平臺檢測效率對比

圖3 Hadoop并行處理后標定的結果
采用傳統的圖像缺陷檢測大都是單機運算,也就是說一次只能處理一幅待測圖像,檢測系統的吞吐率很低。而采用Hadoop平臺的并行缺陷圖像處理系統,一次能處理多幅圖像,程序的吞吐率得到較大提升。筆者對比了單機和Hadoop平臺的系統圖像檢測的效率,如表2所示。由表2可知,單機系統處理這四幅待測圖像需要0.688秒,Hadoop平臺處理這四幅待測圖像需要0.181s。在處理單幅待測圖像時單機系統要比Hadoop平臺要快0.007s,這是因為,Hadoop平臺在MapReduce執行階段要耗費一些時間;在處理4幅待測圖像的情況下,Hadoop平臺要比單機系統快0.507s。經過大量實驗,當待測圖像數量大于4時甚至達到海量級別,基于Hadoop平臺的檢測系統就能滿負荷工作,檢測效率最高。
5 結論
本文提出了基于Hadoop平臺的衛生陶瓷缺陷檢測方案。此方案包括5臺PC機,1臺作為主節點,4臺作為從節點。并部署了Hadoop的MapReduce框架,在Mapper( )映射過程中,用Java編寫了基于灰色關聯的衛生陶瓷缺陷檢測系統。該系統能夠對衛生陶瓷缺陷圖像進行并行檢測,在滿負荷工作下,效率大大高于普通單PC機搭建的檢測系統。本文為工業產品的并行機器視覺檢測提供了相應解決方案,有一定參考價值。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
