用于重復充電運營記錄的基于塊采樣的高效聚集查詢算法
2018-08-28 08:52:24潘鳴宇龍國標李香龍馬冬雪
計算機應用 2018年6期
潘鳴宇,張 祿,龍國標,李香龍,馬冬雪,徐 亮
(1.國網北京市電力公司,北京100075; 2.南瑞集團,北京102299)
(*通信作者電子郵箱bjdky123@163.com)
0 引言
近年來,大數據已廣為人知,各行各業每天積累大量的數據并進行分析,以支持重要的商業決策。大數據的數據量以難以想象的速度增長,給數據處理帶來了極大的挑戰,一些應用對查詢響應時間提出了很高的要求。例如,日志分析通過不停地分析系統日志可以找到系統性能瓶頸或潛在的風險,如果分析時間較長而未能及時規避風險,可能造成不可估量的損失。
另外,數據分析專家或用戶通常希望可以整合多個數據源的數據進行聯合分析決策。例如,一個好的銷售經理會經常上網搜集對比不同商家的定價,從而確定適合自己的定價。然而,從多數據源整合數據經常引發數據質量問題,如同一個實體可能存在多種不同的表示,即實體識別問題,也稱去重復問題。
實體識別旨在識別出所有表示相同實體的重復元組。文獻[1-2]概述了近年來實體識別問題的研究現狀及成果,文獻[3]研究如何提升實體識別的效率,文獻[4-6]研究了復雜數據上的實體識別技術,文獻[7-8]致力于提升實體識別準確性。這些方法將實體識別作為線下預處理過程用來清洗整個數據集,找出全部的同一實體。然而,隨著數據規模的不斷增大,這種高計算復雜性的線下清洗模式已經很難滿足實時性分析應用的需求。文獻[9-17]研究了多種漸進式實體識別方法,旨在通過部分清洗過的數據給出較好的查詢結果,然而,這些工作都針對于選擇投影連接查詢,還沒有聚集查詢相關的研究工作。眾所周知,聚集查詢是數據分析的基礎,快速準確的聚集查詢處理為深入的大數據分析挖掘提供保障。
基于采樣的近似查詢處理是處理大數據聚集查詢的有利工具,這方面的研究可以追述到20世紀90年代末,為了保證交互式查詢的響應時間,文獻[18-27]提出了多種近似查詢方法。最近,隨著大數據研究的興起,Agarwal等[21]提出了以BlinkDB為代表的新型近似查詢處理系統,用于處理TB級數據分析。然而在重復數據上的近似查詢處理的相關工作仍處于起步階段。
本文研究有重復數據的情況下的高效聚集查詢處理問題,將聚集查詢處理與實體識別有效地結合,快速返回滿足用戶需求的聚集結果。本文采用基于塊的采樣策略,在采集到的樣本上進行實體識別,并根據實體識別的結果重構得到聚集結果的無偏估計。
具體地,在Spark/MapReduce等云計算平臺中,數據以塊的形式存儲在分布式文件系統中,塊是數據在節點和磁盤間傳輸的基本單位,傳統的元組級的簡單采樣不再高效。例如,在元組級采樣過程中,想要從分布式文件系統中隨機采集b個元組構成樣本,若這b個元組在不同的塊內,則會引發b塊數據的傳輸,網絡傳輸代價增大從而降低采樣的效率。另外,在有重復元組出現的情況下,經典的概率學定理不能直接應用,為此,本文提出了適用于塊采樣的聚集結果估計量,并證明該估計量可以保證給出無偏的結果估計。
總的來說,本文主要工作如下:
1)研究了有重復數據的情況下如何高效處理聚集查詢問題,該問題相關的研究工作仍處于起步階段。
2)提出了基于塊的采樣策略,高效地適用于分布式云計算環境。
3)提出了一種基于塊采樣的聚集查詢結果無偏估計量,并證明該估計量是無偏的。
1 實體識別
實體識別是數據質量中的一個重要問題[17],在聯合分析和數據聚合中應用很多。實體識別旨在識別出表示同一實體的不同元組,典型的實體識別方法包含兩個階段:劃分階段和去重階段。
1.1 劃分階段
劃分是實體識別中提高效率的重要技術,它通過將元組集合劃分為小塊,使得不同塊內的元組不可能指向相同的實體。劃分的目的是將原本需要應用在全部元組上的實體識別算法降低到只需要應用在一個塊內的元組。劃分階段通過劃分函數作用在一個或多個屬性值上,得到劃分鍵,相同劃分鍵的元組會分到相同的塊內。
劃分函數需要滿足以下兩點:首先,如果兩個元組可能共同指向同一個實體,那么劃分函數應該保證這兩個元組劃分后至少同時出現在一個塊內。其次,如果兩個元組劃分后不在任何一個塊內同時出現,則它們很大概率上不會共同指向相同實體。例如,將論文按照會議名稱劃分,那么只有發表在相同會議的論文會被劃分到一起,進入下一步的去重階段。
1.2 去重階段
去重階段的目的是檢測、聚集然后合并重復元組,包含三個子過程:計算相似性、聚集候選對、合并候選對。
計算相似性 通過計算同一塊內的元組的相似性,每對元組是否可能指向同一實體。這一階段通常計算代價很高,對于一個大小為n的塊,可能需要比較O(n2)個元組對的相似性。總的來說,不同的實體識別算法在計算相似性時采取的技術各種各樣,大致可以分為兩類:一種是基于相似性函數的方法;另一種是基于學習的方法。基于相似性函數的方法需要設計一個相似性函數和一個閾值。基于學習的方法將實體識別問題建模為一個分類問題,通過訓練分類器標記每個元組對是重復的或者不重復的。
聚集候選對 根據上一階段計算的相似性或標簽,將滿足條件的相似元組對劃分到無重疊的簇中,使得同一個簇內的元組指向同一實體。
合并候選對 將每個簇中指向相同實體的元組合并為一個有代表性的實體,返回給用戶。合并函數是領域相關的,要根據元組具體形式確定,例如,對于數值型元組,合并函數可以為平均值,用均值代表簇內元組的一般取值。
2 總體框架
2.1 基于塊的采樣策略
本文研究數值型聚集查詢,如 SUM、AVG、COUNT、VAR、GEOMEAN等,對于關系表R,本文研究如下查詢:SELECT op(exp(ti))FROM R
WHERE predicate GROUP BY col
其中:op表示聚集操作(SUM,AVG,COUNT);exp表示R的屬性算術表達式;predicate是屬性上的選擇條件;col是R中一個或多個列。當op是COUNT時,exp相當于SQL中的“*”通配符,ti表示表 R中的第 i條元組。構造隨機變量 Xi=|R|*expp(ti),對于給定的分組k,若ti滿足predicate條件并屬于分組k,則expp(ti)=exp(ti);否則expp(ti)=0。如果操作op是COUNT,則expp(ti)=1或0。
本文假設數據沒有重復,由于數據在分布式文件系統以塊的形式存儲,通常一塊大小為128 MB,設R有N個塊,每個塊大小為 B,則 |R|=NB,R={B1,B2,…,BN}。和簡單隨機采樣不同,基于塊的抽樣以塊為基本抽樣單元,隨機抽取n塊組成樣本 S,不失一般性,假設 S={B1,B2,…,Bn}。為樣本中的每個塊構造一個隨機變量n。
以COUNT為例,聚集結果的估計為:
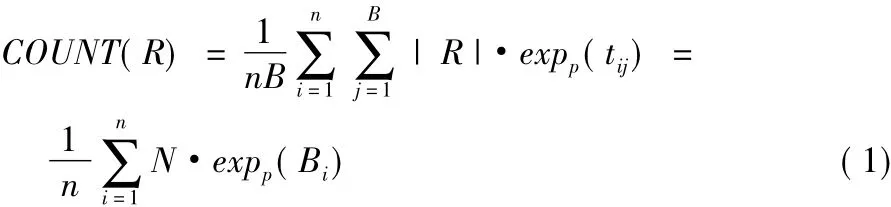
令隨機變量 Yi=N·expp(Bi),則 COUNT(R) =,即COUNT(R)是Yi的均值,又由于樣本S是從R中隨機抽取,則隨機變量Yi的觀察值獨立同分布。由中心極限定理可知,COUNT(R)服從以真實值為期望的正態分布,聚集結果的置信區間為:
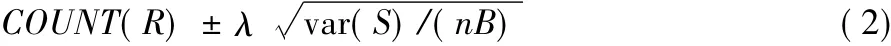
其他聚集函數的估計量可以通過類似的方式構造,且可以證明是總體聚集結果的無偏估計。上述估計量適用于總體R中沒有重復元組的情況,當有重復元組出現的時候,就不能保證樣本中每個采樣單元被抽取的概率是相等的,因為重復出現的元組被采樣的概率大于其他元組,違背了中心極限定理中隨機變量獨立同分布的前提,因此在有實體重復情況下,不能直接應用上述估計量,需要根據元組重復次數修改估計量,元組重復出現的次數將其定義為重復因子,然后利用重復因子修正估計量得到總體聚集結果的無偏估計。
為了確定樣本中每個元組的重復因子,需要對樣本進行實體識別,總體框架如圖1所示。系統輸入是關系R={B1,B2,…,BN},以及聚集查詢語句Q,輸出是聚集查詢結果的估計值及置信區間。首先對總體N塊數據進行隨機采樣得到n塊數據,構成樣本S;然后,對S進行實體識別,檢測所有重復元組,若S中的一條元組t經過實體識別過程,發現和m個其他元組重復,則t的重復因子為m。根據樣本中每個元組的重復因子,可以計算出聚集結果的無偏估計,詳情見第3章。樣本S上可以采用任何現有的實體識別方法,用戶可根據數據特點及需求選擇,本文采用經典的基于相似性的實體識別。
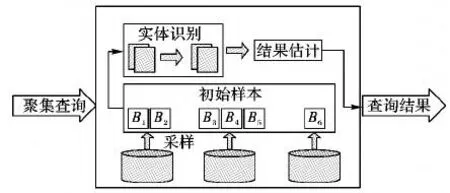
圖1 聚集查詢處理總體框架Fig.1 Overall framework of aggregation query processing
2.2 樣本實體識別
通常實體識別是針對字符型數據的排字錯誤,因此本文根據字符串的類別提供相應的相似性函數。具體地,對于短字符串使用編輯距離作為相似性度量標準,對于長字符串使用杰卡德(Jaccard)相似性函數。
短字符串比較 如果用戶指定要去重的屬性是短字符串,只有幾個單詞,那么就使用編輯距離計算候選對之間的相似性。兩個元組之間的相似性為用戶指定的去重屬性上兩個屬性值的編輯距離,也就是將其中一個屬性值轉換為另一個屬性值所需要的最少編輯操作。一共有三種編輯操作:插入、刪除和修改。舉個例子,Apple和Aplee之間的編輯距離為2,因為需要將Aplee的字符e刪掉,然后再插入p到A和p之間。
長字符串比較 如果用戶指定的去重屬性是由長字符串構成的,那么使用Jaccard相似性函數計算屬性值之間的相似性。兩個字符串集合S1、S2的Jaccard相似性值定義為:
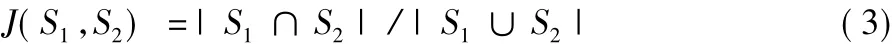
即兩個集合交集大小比兩個集合并集大小。例如,S1={A,B,C},S2={A,C},則J(S1,S2)=2/3。Jaccard 相似性函數同樣適用于元組之間相似性計算,將整條元組看作是各個屬性值組成的集合即可。
3 基于塊采樣的無偏估計
對樣本實體識別后,將得到樣本中每個元組的重復因子,接下來,研究如何利用重復因子重新構造總體聚集值的估計量,使得其適用于重復數據并保證結果的無偏性。
不難發現,有重復數據的總體大小大于實際大小,因此在其上進行均勻采樣,每個樣本被采到的概率發生改變,重復元組被采到的概率增大,沒有重復的元組被采到的概率減小。若一條元組ti的重復因子為m,即它表示的實體重復出現m次(若只出現一次沒有其他重復,則m=1)。ti被采到的概率為其他非重復元組的m倍,若ti出現在樣本S中,需要將其聚集屬性取值除以m,這樣等同于將其采樣的概率降低為1/m,從而和其他非重復元組的采樣概率相同,滿足均勻采樣的要求。
為了證明這種在樣本上降低重復元組權重的方法可以得到總體結果的無偏估計,首先證明在總體上降低重復元組權重后計算得到的聚集值和總體去重后的聚集結果一致。以SUM操作為例,其他聚集操作可以用類似的方法證明。
引理1 總體R={t11,t12,…,tNB}是由N個數據塊,共NB個元組構成,令Ru表示R去重復后的數據集合,有NB個無重復元組,N'≤N。對于R中的任意元組tij,其重復因子為mij(mij≥1),對R中每個元組按照重復因子降低權重后得到新集合,則 SUM(R')=SUM(Ru)。
接下來,證明可以通過樣本得到總體聚集值的無偏估計。和引理1類似,構造S',可以證明其上求得的SUM值乘以N/n,期望上等于總體去重后Ru上的SUM值,詳見定理1。
定理1 令S R是R上基于塊采樣得到的樣本,且|S|=nB,和引理1類似,Su為去重后的干凈樣本。對于任意Sij∈S,令mij表示Sij在總體中重復個數,對S中每個元組按照重復因子降低權重后得到集合
證明 由于采用均勻隨機采樣,因此sij和mij可視為獨立同分布的隨機變量,并且=MEAN(R'),根據期望線性可知,有=MEAN(R')代入上式可得如下關系:E(SUM(S'))=(nB·MEAN(R'))=NB·MEAN(R')=SUM(R')。由引理 1可知,SUM(R') =SUM(R),因此,E(SUM(S'))=SUM(R)。uu
由定理1可知,可以對樣本進行去重后計算聚集值,通過一定的變換可以得到總體的無偏估計,這樣可以大大減少清洗全部數據所需代價,既滿足了用戶精度要求,又可以快速返回計算結果。接下來,通過一個例子說明總體框架流程。
例1 假設塊大小為2,表R有6個元組,分布在3個塊內,R={(t11,t12),(t21,t22),(t31,t32)},查詢Q要計算 R上所有元組的SUM值。隨機選取一塊入樣本S,假設S={(t11,t12)},通過實體識別得出(t11,t12)指向同一實體,(t12,t32) 指向同一實體,因此,m11=m12=2,總體SUM值的估計值為
4 實驗與結果分析
本文在真實數據集和合成數據集上進行實驗,測試本文提出的算法的準確性和效率。實驗在10個節點的集群上進行,包含1個主節點和9個從節點,每個節點有2個 Intel Xeon處理器,六核,16 GB的隨機存取存儲器(Random Access Memory,RAM),1 TB 的硬盤。
4.1 實驗設置和數據集
通過以下兩個指標衡量本文提出的方法的性能:1)樣本大小,單位為塊,表示采樣和去重的塊個數。2)錯誤率,q%的錯誤率表示估計值以95%概率位于真實值±q%范圍內。
本文和當前最好算法文獻[28]中提出的SampleClean(Sample and Clean framework)進行比較,SampleClean采用的是基于元組的采樣策略,和基于塊采樣不同,另外,SampleClean是在Hive上實現的,通過調用Hive操作數據庫實現采樣,本文直接在數據集上進行采樣,避免了中間層的開銷。為了方便對比,將本文提出的基于塊的采樣算法記為BlockSample(Block-based Sample)。
實驗中采用的數據集包括合成數據集TPC-H(Transaction Processing performance Council-H)和真實數據集微軟學術檢索數據集(Microsoft Academic Search,MAS)。
TPC-H數據集:生成1 GB的TPC-H標準數據集(lineitem表中有6001199個元組),lineitem的關系模式模擬工業購買記錄。隨機注入d%的重復數據:80%一次重復,15%二次重復,5%三次重復。
微軟學術檢索數據集:該公開數據集包含學術論文發表信息,該數據集合中主要的錯誤來源于重復數據,選取Jeffrey Ullman10位研究人員發表的論文進行研究(記為publish)。原始數據集顯示Jeffrey Ullman這10位研究人員共發表了4605733篇文章,通過手動去重,得到真實值為2554892篇。
對以上兩個關系表設計兩組聚集查詢,對lineitem表進行SUM查詢,對publish表進行COUNT查詢,如下所示:
SELECT SUM(quantity) FROM lineitem WHERE returnflag='A'AND linestatus='F'
SELECT COUNT(paper)FROM publish
4.2 準確性
在TPC-H數據集上分別注入0.1%的重復數據和10%的重復數據,并和SampleClean進行比較。在0.1%重復數據上,BlockSample和 SampleClean中 NormalizedSC(Normalized Sample Clean)算法比較,該算法適用于重復數據較少的情況;在10%重復數據上和SampleClean中的RawSC(Raw Sample Clean)算法比較,該算法適用于重復元組較多的情況。實驗結果如圖2所示。
從TPC-H數據集上測試的結果可以看出,無論在較少重復數據或較多重復數據的情況下,BlockSample都可以和SampleClean達到幾乎相同的準確率,另外,錯誤率以1/SampleSize的速度下降。
為了更直觀地顯示計算結果,用圖3中的置信區間顯示結果的變化。圖3(a)是在0.1%重復數據的TPC-H上的實驗結果,圖3(b)是真實數據集publish上的實驗結果,可以看出,隨著樣本大小的增大,結果的置信區間逐漸縮小,估計結果最終趨近真實值(ground-truth)。
BlockSample可以達到和SampleClean幾乎相同的準確率是因為設置SampleClean采用本文中的實體識別技術,兩者又存在一些差異,是因為每次采樣都是隨機的,得到的樣本不可能完全相同。
4.3 運行時間
接下來,對BlockSample和SampleClean的運行時間進行測試,如圖4(a)所示,在重復率0.1%,大小為1 GB的TPC-H數據集上,相同樣本大小時(即準確度相同),BlockSample計算時間總是小于SampleClean,并且時間差隨著樣本增大逐漸增大,也就是說,BlockSample在數據較大的情況下性能表現更好。
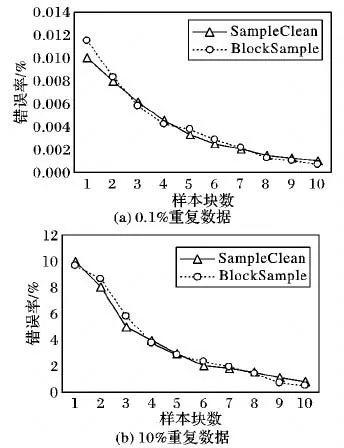
圖2 SampleClean和BlockSample準確率比較Fig.2 Accuracy comparison of SampleClean and BlockSample

圖3 不同數據集上查詢結果與置信區間比較Fig.3 Query result and confidence interval comparison on different datasets
為了證實上述猜想,在更大的數據集上進行測試,選取TPC-H數據集,生成10 GB~100 GB的數據,重復率為0.1%,設置BlockSample和SampleClean都采取樣本大小為全部數據的10%,記錄兩個算法的運行時間如圖4(b)所示。
由圖4(b)可以看出:在數據量較大時,BlockSample運行時間也少于SampleClean的運行時間;并且,當數據線性增大時,BlockSample運行時間呈線性緩慢增長,而SampleClean呈指數趨勢增長。通過這個實驗,可以看出BlockSample具有更好的可擴展性,適用于數據量較大的情況。
通過分析,共有兩點原因:首先,BlockSample采用基于塊的采樣策略,在Spark中,數據以塊作為基本單位進行存儲和傳輸,基于元組的采樣取一個樣本就可能造成一個塊的傳輸,從而增大了I/O時間和通信時間。另外,SampleClean構建在Hive數據庫上層,所有數據的操作都通過Hive層進行,無疑增大了中間層的計算代價,而BlockSample是在數據上直接進行計算,省去了中間數據管理的開銷。

圖4 不同數據集上運行時間比較Fig.4 Running time comparison on different datasets
5 結語
本文研究了將實體識別與聚集查詢高效融合問題,提出了基于塊的采樣策略,大大提高了聚集查詢效率。另外,本文提出了適用于塊采樣和重復數據的查詢結果的估計量,并證明該估計量是無偏的。實驗結果表明本文提出的算法能達到和當前最好的算法相同的精確度,并且大大提高了查詢效率,能夠更好地適用于大數據情況。未來我們將研究重復數據上的嵌套聚集查詢處理方法,當查詢嵌套時,本文提出的無偏估計量不再有效,因此,需要進一步研究如何保證查詢結果的無偏性。
