基于決策樹推薦克隆重構的方法
2018-08-27 10:59:12折蓉蓉張麗萍
計算機應用 2018年7期
折蓉蓉,張麗萍,侯 敏,閆 盛
(內蒙古師范大學 計算機與信息工程學院,呼和浩特 010022)(*通信作者電子郵箱cieczlp@imnu.edu.cn)
0 引言
近年來軟件開發環境、操作系統及軟件相關領域的不斷發展,導致軟件復用的規模越來越大,軟件開發的成果被越來越多的人們直接復用。為了提高軟件的開發效率,開發人員會復用大量的代碼,被復用的代碼稱為克隆代碼[1],據統計一個軟件系統中的克隆代碼達到9%~17%,有的甚至達到50%以上[2]。
克隆代碼的大量使用導致了軟件復雜性的增加,僅僅檢測出克隆代碼并不能降低軟件維護成本。現有研究表明,重構與軟件的質量(如可維護性和穩定性)有著密切的聯系,經過重構的克隆代碼往往比未經過重構的克隆代碼具有更高的質量,所以重構對于軟件的進化具有積極的意義。
重構軟件系統中克隆所有代碼是不切實際的,也不是所有克隆代碼都需要重構,雖然預測克隆重構代碼的方法相繼提出,然而國內外針對機器學習預測出需要重構的克隆代碼的方法極少,因此本文將重構作為一個機器學習問題,預測需要重構的克隆代碼,以降低軟件的復雜性和維護成本。
1 相關工作
1.1 克隆代碼定義及分類
當前,人們廣泛采用的克隆代碼的概念是將具有相似語法及語義特征的代碼段稱為克隆代碼[3]。基于對代碼質量造成重要影響的是克隆代碼的大量使用,近年來代碼分析領域中比較活躍的分支為克隆代碼的相關研究。克隆代碼的類型從不同的角度進行劃分,當前進行分類的角度主要分為兩種。一種角度是根據代碼相似度,將其分成Type- 1、Type- 2、Type- 3及Type- 4四類[4](定義如表1);另一種角度是根據檢測粒度,將其分成文件克隆、類克隆、函數克隆、塊克隆以及語句克隆等五種類型[5]。

表1 克隆類型的定義
1.2 克隆檢測
克隆檢測是指查找源代碼中的克隆代碼,并以克隆對(Clone Pair)或克隆群(Clone Group)的形式反饋。其中,克隆對是指相互之間存在克隆關系的代碼段;克隆群是一些克隆代碼段的集合,其中任意兩個代碼段都是克隆對。目前,克隆檢測領域的研究已較為成熟,許多檢測方法及技術被提出,主要包括:基于文本的克隆檢測方法[6]、基于Token的克隆檢測方法[7]、基于抽象語法樹(Abstract Syntax Tree, AST)的檢測方法[8]、程序依賴圖(Program Dependence Graph, PDG)[9]、基于低級語言[10]的檢測方法、基于Metrics[11]的檢測方法等。
本團隊在克隆檢測方面也進行了大量研究:史慶慶等[12]使用優化后綴數組的方法進行克隆代碼檢測,并實現了一款檢測軟件源代碼中克隆群的工具——FCD(Function Clone Detector)。FCD能夠把軟件系統中的Type- 1和Type- 2函數克隆高效地檢測出來;張久杰等[13]實現了基于Token編輯距離的檢測方法,能有效檢測Type- 3克隆代碼,解決了克隆檢測中Type- 3類型克隆檢測的難題,解決了以往對克隆代碼分析的研究對象大多局限于Type- 1和Type- 2類型的問題,并為后續研究克隆代碼的演化、克隆代碼性能分析提供更加全面、準確的數據來源。
1.3 克隆重構
重構的概念由Opdyke[14]提出,重構就是通過改變程序代碼的內部結構而不改變程序代碼的外部行為來提高代碼的質量,尤其是代碼的可擴展性與可維護性。多年來軟件重構作為提高代碼質量的有效途徑,已成為軟件工程領域的熱點問題。出現了許多針對不同類型的克隆代碼的重構方法和技術,主要包括:Bakota[15]采用進化分析方法提取可重構的克隆代碼;Rahman等[16]用度量提取可重構的克隆代碼。Fowler[17]提出兩種重構方法:提煉函數(Extract Method)和函數上移(Pull Up Method),這兩種方法是重構克隆代碼常用的技術,通常重構克隆代碼需要結合使用這兩種方法,首先執行“提煉函數”,然后執行“函數上移”。克隆代碼重構可以提高代碼的可維護性。
以Apache Ant中的一小段代碼為例來理解克隆重構。Apache Ant的r436724中的克隆代碼重構細節如圖1所示,開發人員在維護日志提交內容中有如下表述:“重構DirectoryScanner來減少重復的代碼,測試全部通過”。源代碼的更改確認了重構DirectoryScanner中的克隆兄弟姐妹:分散在兩個方法中的克隆兄弟姐妹被提取到一個名為processIncluded的新方法中,并且這兩個方法調用新的方法來保存程序的外部行為。這就是重構克隆代碼的一個實例。

圖1 克隆重構實例
1.4 決策樹
決策樹又稱判定樹,是一種運用于分類的樹形結構,構造決策樹采用的是一種自上而下的遞歸方法。將一組帶有類別標記的訓練數據作為決策樹的輸入,一棵二叉樹或者多叉樹作為輸出,以下兩步主要是決策樹的分類過程。
第1步 構建決策樹模型,此過程就是進行機器學習的過程。從數據中獲取知識,使用訓練集建立模型同時優化。
第2步 進行分類,使用生成的決策樹對輸入數據進行分類。對輸入的記錄,從根節點依次測試記錄的屬性值,直到到達某個葉節點,從而找到該記錄所在的類。
尤為關鍵的是構造一棵決策樹,構造決策樹的過程分為三步:1)特征選擇;2)生成決策樹;3)剪枝。
具體原理如下:
InfoGain(D,A)=H(D)-H(D|A)
(1)
(2)

(3)
其中:D代表整個訓練樣本;訓練樣本有k類;A代表特征,A將訓練樣本分為n類;Pi為數據集中第i個類別占樣本總數的比例,Pji為j個剪枝數目中第i個類別所占比例。
決策樹相對于其他分類器而言有如下優點。
1)速度快:不僅計算量小,而且分類規則轉化較容易。
2)準確性高:挖掘出的內容不僅可以清晰地反映出哪些字段比較重要,而且分類規則精準性較高、便于理解。
2 基于決策樹推薦克隆重構的方法
本文提出的基于分類器推薦克隆代碼重構的方法共分為5個步驟,如圖2所示。

圖2 整體工作流程
2.1 克隆檢測
如果不知道哪些代碼片段是克隆代碼、克隆代碼所在的位置,也無法識別重構代碼,解決克隆代碼引起的問題,克隆代碼檢測是研究克隆重構的基礎,因此本研究使用目前比較成熟的克隆檢測工具——NiCad進行克隆檢測。NiCad檢測工具是由加拿大皇后大學Roy等[6]開發的克隆檢測工具,當前最新版本為NiCad 4.0,適用于C、Java、Python等主流開發語言,能夠檢測Type- 1、Type- 2、Type- 3的克隆代碼。由于它能有效檢測Type- 3克隆代碼,解決了以往對克隆代碼分析的研究對象大多局限于Type- 1和Type- 2類型的難題,并為后續研究克隆代碼的重構、克隆代碼性能分析提供更加全面、準確的數據來源。
本研究使用subversion從版本管理器中獲取某次提交之后的結果作為一個版本的源碼,然后使用NiCad進行克隆檢測,該工具可以檢測Java語言的Type- 1、Type- 2與Type- 3函數克隆,并具有很高的精度值和召回率。檢測結果以克隆對、克隆群和克隆函數的形式反饋出來,本研究只用克隆函數、克隆群形式的檢測結果,檢測結果存儲到XML文件中。下面以Tomcat軟件為例,介紹克隆檢測結果。圖3呈現了以克隆函數形式反饋出來的部分內容檢測結果,它顯示的是一個代碼片段的文件,提供每一個代碼片段的文件路徑、起始行號、結束行號、片段源碼等信息。圖4呈現了以克隆群形式反饋出來的部分檢測結果,它是克隆群文件,克隆群包含的克隆片段、檢測出來的克隆群信息都包含在里面。
2.2 識別重構的克隆代碼
近年來隨著克隆代碼檢測技術日益成熟,克隆代碼的重構也逐漸成為了熱門,在對軟件系統中克隆代碼重構之前,識別出需要重構的集合是非常重要的。本文識別克隆代碼重構實例具體過程分為如下3個步驟。

圖3 部分檢測結果(克隆函數)

圖4 部分檢測結果(克隆群)
步驟1 通過相鄰版本間定義重構實例。克隆重構簡單來說就是代碼的更改,即定義克隆類C為由兩個或更多個克隆片段組成的集合。一個克隆類C至少有兩個克隆片段被合并,并且保留原始代碼段的外部行為,超過兩個克隆片段的克隆類C,則C被認為是克隆重構,如果任何兩個克隆片段被重構,則為重構實例。
步驟2 生成重構候選集。本實驗選擇了5個著名的開源系統,Tomcat、ArgoUML、PostgreSQL、Lucene、Apache Ant,收集了這些系統的所有公開版本,要在所選目標系統中識別克隆重構實例,用Demeyer等[18]開發的度量工具Moose Metrics從源代碼中提取類、方法、屬性、計算必要的度量來生產重構候選集。
步驟3 優化重構候選集。生成重構候選集之后,依據以下3個條件對重構候選集進一步篩選和優化:
1)相鄰版本間克隆類的兩個兄妹消失;
2)對于克隆代碼片段內的方法,源代碼行數減少,并且至少一種方法被添加進此方法中;
3)一個原始克隆代碼中新的源類被創建并作為父類。
選擇這3個條件是因為它們包含了所有與克隆重構有關的重構模式。通過使用這種基于度量值的方法,手動檢查克隆克隆重構候選者,據Demeyer等[18]使用發現,這種方法可以檢測到適用于克隆重構的所有Fowler重構模式,包括“Extract Method”“Extract Superclass”“Pull-Up Method”“Replace Method with Method Object”“Template Method”等方法。
若滿足其中任意一個條件則一個克隆類C被當作候選,重構實例如表2所示。
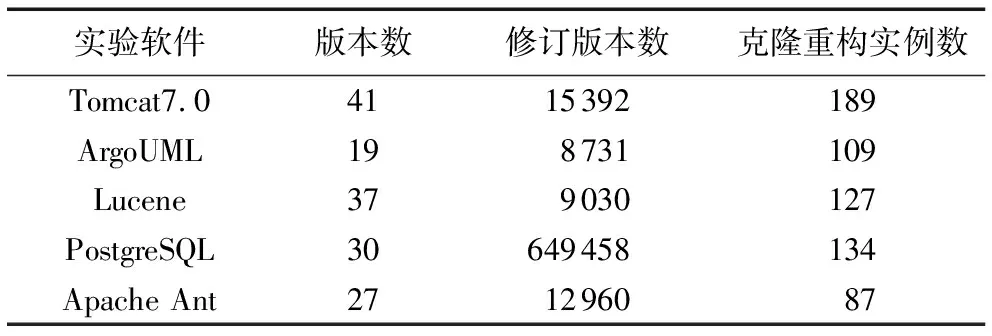
表2 識別克隆重構實例
為了構成完整的分類器訓練數據集合,還需要收集非克隆重構實例。非克隆重構實例的收集則比較簡單,只需觀察從克隆開始版本到本研究中的最后一個版本,選擇沒有任何重構的克隆代碼(包括重命名標識符),則為非克隆重構實例。
2.3 特征提取
特征提取是機器學習和模式識別領域常用的數據預處理方式,是訓練機器學習模型的必要步驟,Wang[19]提出了使用克隆代碼的危害性可能與克隆代碼段的特征以及克隆內容的特征有關,并在兩個大型工業軟件上進行了評估。Steidl等[20]用克隆代碼段、克隆關系的特征來自動識別克隆代碼的bugfixes,并進行了驗證。本團隊王歡等[21]針對克隆代碼有害性特征數量多且不容易提取、質量粗糙的情況,提出了一種有害性特征選取的組合模型。基于以上研究得出Type- 3的克隆、克隆代碼的圈復雜度、克隆代碼段的行數、分支語句的比例等特征與克隆代碼的有害性和重構相關,因此本文從克隆關系、克隆代碼段及克隆內容這3個維度中提取特征,詳細特征信息如表3所示。
特征的提取是建立在克隆代碼檢測和重構標注的基礎上,通過分析克隆檢測結果可以為本文研究基礎性的克隆代碼數據,包括克隆代碼的數量、位置等數據。克隆群是不是Type- 3的克隆、克隆代碼段的Token大小這兩個特征直接從NiCad克隆檢測結果中提取,對于其他特征本文使用代碼工具SourceMonitor提取。SourceMonitor是一款可對多種語言(C++、C、C#、VB.net、Java、Visual、Basic和HTML)編寫的代碼進行度量的工具,并且針對不同的語言,輸出不同的代碼度量值。將克隆代碼作為輸入,SourceMonitor便會輸出相應克隆代碼的靜態特征值。圖5是SourceMonitor對部分克隆代碼進行度量的結果。代碼行數是從SourceMonitor工具的
2.4 訓練決策樹分類器
決策樹方法在分類、預測等領域有著廣泛的應用,C4.5是比較成熟的決策樹算法,C4.5算法是決策樹分類問題中必不可少的挖掘工具。之所以選擇C4.5是因為它產生的預測準確性不低于其他的分類方法。哈爾濱工業大學袁悅[22]使用機器多種學習的方法來預測克隆代碼的一致性維護需求模型,經實驗發現決策樹的預測模型最佳,Wang等[23]用決策樹預測克隆代碼的質量且取得良好的效果。受此啟發本研究選用決策樹來預測需要重構的克隆代碼。

表3 特征選擇
構造一棵決策樹的步驟如下。
1)數據預處理:將屬性變量處理形成決策樹的訓練集,這里只需處理連續型的屬性變量,若沒有連續型的屬性變量則忽略。
2)計算屬性的信息增益率。
3)生成決策樹:每一個根節點屬性的取值對應一個子集,對樣本子集遞歸執行步驟2),直到分類屬性上取值都相同時生成決策樹。
4)對新數據集進行分類:根據構造的決策樹,提取分類規則且進行分類。
算法描述如下。
輸入:訓練樣本samples,候選屬性的集合attributelist。
輸出:一棵決策樹。
創建節點N
ifsamples都在同一個類Cthen
returnN作為葉節點,以類C標記
ifattribute_list為空then
returnN作為葉節點,標記為samples中最普通的類
選擇attribute_list中具有最高信息增益的屬性best_attribute
標記節點N為best_attribute
for eachbest_attribute中的未知值ai
由節點N長出一個條件為best_attribute=ai的分枝
設si是samples中best_attribute=ai的樣本的集合
ifsi為空then
加入一個樹葉,標記為samples中最普通的類
else 加上一個由Generate_decision_tree返回的節點

圖5 部分克隆代碼度量結果
訓練分類器,需要一個包含克隆重構實例和非克隆重構實例的樣本數據庫,然而未經重構的克隆實例通常比重構實例多出幾倍,訓練所有克隆實例將會在構造分類器時引入對未克隆重構的偏奇。為了解決這個問題,使用隨機欠采樣來減小未重構克隆的大小。隨機欠采樣簡單來說就是從原始數據集中刪除數據,從而提供相同比例的數據。具體來說,本文隨機選擇一組Dmaj中的多數類實例,并從D中刪除這些樣本,計算過程如下:
|D|=|Dmin|+|Dmaj|-|E|
(4)
其中:D是數據集;Dmin表示少數類數據的集合,在本實驗中就是克隆重構實例;Dmaj表示多數類數據的集合,在本實驗中就是非克隆重構實例;E表示D上采樣過程中產生的任何集合。
2.5 評估分類結果
在對未知數據樣本進行預測時,部分被正確分類,部分被錯誤分類,因此,為了評價克隆代碼重構預測模型,本研究選用常用的召回率、精度值、F值來評價分類器的性能,對應的混合矩陣如表4所示。表4中:正確的正例(True Positive, TP)用TP來表示;錯誤的反例(False Negative, FN)用FN來表示;錯誤的正例(False Positive, FP)用FP來表示;正確的反例(True Negative, TN)用TN來表示。

表4 混合矩陣
精度值(Precision)的定義如式(5)所示、召回率(Recall)的定義如式(6)所示、F值的定義如式(7)所示:
Precision=TP/(TP+FP)
(5)
Recall=TP/(TP+FN)
(6)
F=(2*Precision*Recall)/(Precision+Recall)
(7)
其中:精度值是分類問題中常用的指標,它反映分類器對數據集的整體分類性能;召回率度量分類器正確預測克隆重構的比例。
3 實驗結果與分析
3.1 實驗目標軟件
本實驗選取5款開源軟件分別是:Tomcat 7.0、Apache Ant、ArgoUML、Lucene、PostgreSQL,基本信息如表5所示。本研究之所以選擇這些系統不僅僅是這些系統比較龐大,而且這幾個系統已經通過趙玉武等[24]在克隆代碼Bugs的研究中進行了實驗。

表5 實驗軟件基本信息
3.2 實驗結果
由于位于決策樹根部附近的特征不能代表其預測能力,因此選擇不同的特征子集,并使用每個子集來訓練一個新的分類器。本實驗選擇三個子集的特征。這三個子集分別是克隆關系、克隆內容以及克隆代碼段。
實驗結果如表6所示(使用子集對克隆重構組、非重構組進行分類訓練的性能),從表6中可以得出如下結論。
1)在5個目標系統中,沒有一個特征子集的性能始終優于其他子集。
2)和所有特征訓練的分類器相比,克隆代碼片段的特征可以產生最接近的結果。如重構組ArgoUML目標系統中所有特征訓練分類器的精度值為0.813、召回率為0.785,與此最相近的是受過克隆上下文訓練分類器的精度值為0.798、召回率為0.779。其他目標系統也是如此。
3)與克隆上下文相關的特征產生的結果略低于受過所有特征訓練的分類器。如重構組ArgoUML目標系統中所有特征訓練分類器的精度值為0.813、召回率為0.785。受過克隆上下文訓練分類器的精度值為0.751、召回率為0.732,略低于所有特征訓練的分類器。其他目標系統也是如此。
4)通過學習克隆關系的特征,例如特征3(克隆類是否是一個Type- 3克隆),或者特征4(克隆片段是否在同一個文件中,或者是兄妹姐妹),分類器的性能獲得一小部分的改進。如重構組ArgoUML目標系統中所有特征訓練分類器的精度值為0.813、召回率為0.785,受過克隆關系訓練分類器的精度值為0.635、召回率為0.801,略低于所有特征訓練的分類器。其他目標系統也是如此。
基于以上結論,得出克隆代碼段的特性獨立于克隆關系及克隆內容,產生的結果可用于推薦重構的克隆代碼。

表6 使用子集對不同組進行分類訓練的性能對比
本實驗選取K折交叉驗證來評估驗證,此方法的基本思想是將輸入數據集劃分為訓練集和測試集,因為測試集和訓練集中測試集對分類器是不可見的,所以進行交叉驗證的對象是訓練集輸出的結果。
第1步 將數據集D劃分為k個大小相似的互斥子集,即D=D1∩D2∩D3∩…∩Dk,每個子集之間沒有交集。
第2步 然后每次用k-1個子集的并集作為訓練集,余下的那個作為測試集,這樣得到k組訓練/測試集。
第3步 可以進行k次訓練和測試,最終返回的是這k個結果的均值。
第4步 可以隨機使用不同的劃分次數。
本實驗選取K=10,即K折交叉驗證來評估分類器預測模型,通過利用大量數據集以及使用不同技術進行大量實驗發現10折獲得的誤差最小,因此本實驗將數據集分為10份。驗證結果如表7所示,分別顯示了重構組和非重構組的精度值、召回度、F度量。
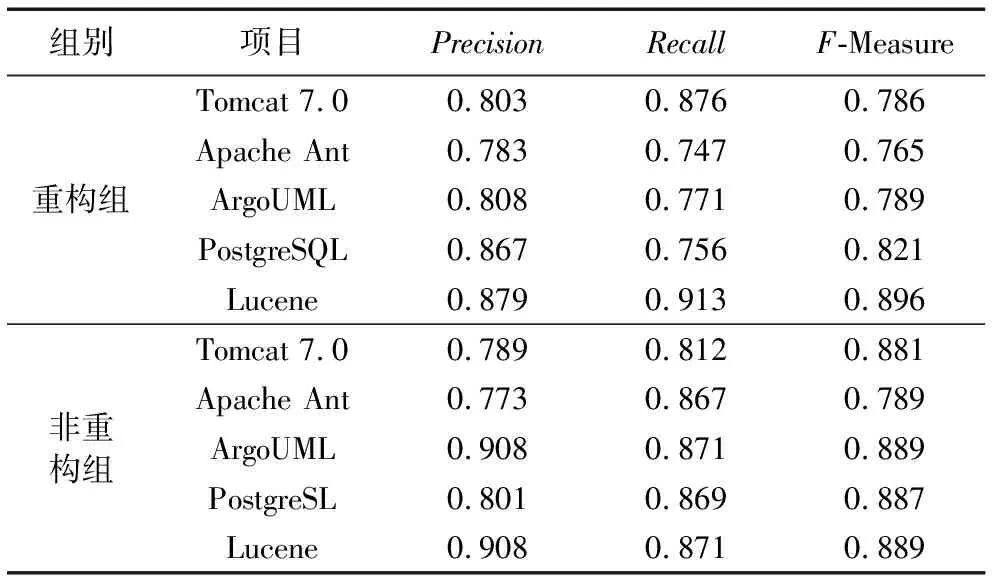
表7 對不同組的測試結果對比
從表7的重構組對比可以得出,重構組10倍交叉驗證的精度值從78.3%提高到了87.9%,提高了9.6個百分點;召回率從74.7%提高到了91.3%,提高了16.6個百分點;F值從76.5%提高到了89.6%,提高了13.1個百分點。從表7的非重構組對比中可以得出,非重構組10倍交叉驗證的精度值從77.3%提高到了90.3%,提高了13個百分點;召回率從81.2%提高到了87.1%,提高了5.9個百分點;F值從78.9%提高到了88.9%,提高了10個百分點:因此得出本文所構造的分類器比隨機選擇執行來的效果更佳。
3.3 同類實驗對比分析
當前國內外使用機器學習的方法預測出需要重構的克隆代碼方法較少,本團隊的劉冬瑞等[25]也曾使用機器學習方法預測需重構的克隆代碼,然而其度量值的選取是根據ISO軟件質量標準選取的,不能很好地體現需重構克隆代碼的特征,而本研究度量值的選取是從重構實例中提取的,相對而言,可信度更好,可行性更強。使用機器學習方法預測出需要重構的克隆代碼具有代表性的是文獻[26]所提出的方法,鑒于文獻[26]直接從公司收集的克隆代碼,而本研究使用NiCad來檢測克隆代碼,同時本研究與文獻[26]提取的特征也不完全一致,因此僅對推薦克隆重構做對比實驗。其中本文研究與文獻[26]所使用的項目均為Java項目,實驗平臺同為操作系統:Ubuntu14.04 64位、8 GB內存、2核CPU。版本信息如表8所示。
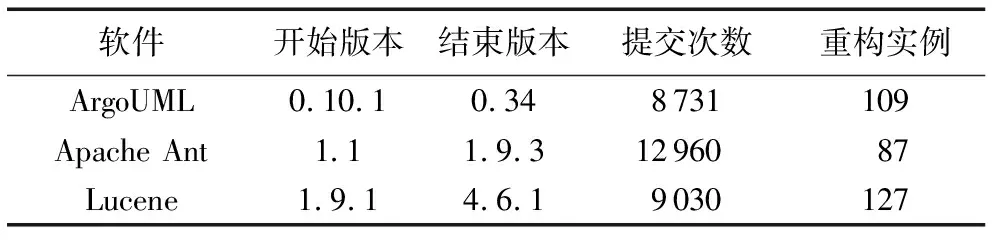
表8 推薦克隆重構對比實驗軟件信息
通過對比實驗,結果如表9所示。

表9 推薦克隆重構同類實驗結果對比
從推薦克隆重構結果中分析軟件ArgoUML的精度值、召回率和F值,與文獻[26]的方法相比,本文方法的精度值提高了10個百分點、召回率提高了10個百分點、F值提高了9.8個百分點。從推薦克隆重構結果中分析軟件Apache Ant的精度值、召回率和F值,與文獻[26]的方法相比,本文方法的精度值提高了10個百分點、召回率提高了6個百分點、F值提高了3.3個百分點。從推薦克隆重構結果中分析軟件Lucene的精度值、召回率和F值,與文獻[26]的方法相比,本文方法的精度值提高了4.5個百分點、召回率提高了9.6個百分點、F值提高了2.4個百分點。綜上本文推薦克隆代碼重構方法的召回率、精度值、F值均高于文獻[26]方法。
4 結語
針對克隆代碼的大量使用會導致長期軟件維護問題甚至引入錯誤的問題,本文提出了一種基于決策樹的分類器來推薦克隆進行重構的方法,通過Nicad檢測出源代碼中的克隆代碼,使用基于度量值的方法將重構實例標注出來,同時使用SourceMonitor提取出特征并構建樣本數據集。最后對600多個克隆實例使用10折交叉來驗證,發現本文提出的基于決策樹的分類器來推薦克隆重構方法的精確度、召回率及F值都能達到80%以上,驗證了本文方法的有效性。本研究可以為克隆重構提供更好的資源分配,從而改進克隆管理。
本文的研究內容與實驗仍然存在一些不足之處,例如目前只能推薦用Java開發項目的克隆重構、推薦克隆重構精度有待提高,在后續研究中將繼續改進,嘗試使用深度學習、半監督學習來推薦克隆重構。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
