基于頭頸部輪廓擬合直線斜率特征的奶牛跛行檢測方法
2018-08-21 06:51:08宋懷波何東健
農(nóng)業(yè)工程學(xué)報(bào) 2018年15期
宋懷波,姜 波,吳 倩,李 通,何東健
(1. 西北農(nóng)林科技大學(xué) 機(jī)械與電子工程學(xué)院,楊凌712100 2. 農(nóng)業(yè)農(nóng)村部農(nóng)業(yè)物聯(lián)網(wǎng)重點(diǎn)實(shí)驗(yàn)室,楊凌 712100 3. 陜西省農(nóng)業(yè)信息感知與智能服務(wù)重點(diǎn)實(shí)驗(yàn)室,楊凌 712100)
0 引 言
跛行是導(dǎo)致奶牛高淘汰率與低產(chǎn)奶率的重要原因,預(yù)防跛行的發(fā)生對于奶牛業(yè)的健康發(fā)展尤為重要。奶牛跛行疾病會(huì)導(dǎo)致牛奶產(chǎn)量和生殖的損失[1]。隨著奶牛養(yǎng)殖規(guī)模的不斷擴(kuò)大,人工檢測奶牛跛行的難度也越來越大。因此,為了減少治療成本,開展奶牛跛行的早期檢測是目前最佳的解決方式,對于提升奶牛養(yǎng)殖業(yè)的現(xiàn)代化水平具有重要的研究意義。
在奶牛跛行檢測研究方面,眾多學(xué)者進(jìn)行了研究并取得了一批研究成果。針對奶牛跛行對其身體負(fù)重程度不一樣的現(xiàn)狀,Pastell等[2]提出了一種利用測量奶牛質(zhì)量分布來檢測奶牛跛行的方法,當(dāng)2個(gè)閾值LWR (ratio of weight to legs, LWR)和NRS(numerical rating scores, NRS)分別大于3與3.5時(shí)可用于檢測奶牛跛行,該方法避免了環(huán)境因素對奶牛跛行檢測的影響,但該方法粗略地評估了奶牛質(zhì)量與奶牛跛行之間的關(guān)系,在奶牛質(zhì)量與奶牛跛行對應(yīng)關(guān)系之間會(huì)存在較大的誤差。
為減少上述誤差對奶牛跛行檢測的影響,Chapinal等[3]提出了奶牛腿部質(zhì)量檢測與步態(tài)評估的方法來檢測奶牛是否跛行。上述方法均是以測量單個(gè)奶牛質(zhì)量或者測量奶牛蹄肢質(zhì)量為前提的奶牛跛行檢測方法,一般情況下,在測量過程中可能會(huì)引起被測奶牛的應(yīng)激反應(yīng),導(dǎo)致數(shù)據(jù)誤差增大。由于現(xiàn)代奶牛業(yè)的規(guī)模化養(yǎng)殖多為室外開放環(huán)境,奶牛數(shù)量較多,上述檢測方法可能會(huì)引起檢測成本的增加。在養(yǎng)殖場中,監(jiān)控?cái)z像頭每天可捕獲大量的奶牛視頻數(shù)據(jù),Magee等[4]提出了重采樣冷凝與多流循環(huán)隱馬爾可夫模型相結(jié)合的奶牛跛行檢測方法,通過對奶牛目標(biāo)跟蹤與時(shí)間建模,取得了較好的跟蹤結(jié)果,但該方法在環(huán)境魯棒性方面較弱,長時(shí)間檢測效果差。Zhao等[5]采用局部背景拼接的方法在復(fù)雜環(huán)境下建立了背景模型,分離、提取效果較好,但該方法對環(huán)境、視頻畫質(zhì)敏感,不利于推廣應(yīng)用。Poursaberi等[6]提出了利用測量奶牛后背曲率來檢測奶牛跛行的方法,檢測跛行的平均正確率達(dá)到了96.55%。
重度跛行奶牛因其癥狀比較明顯,通過飼養(yǎng)員進(jìn)行觀察即可發(fā)現(xiàn)。早期輕、中度跛行的檢測更為重要。但不難發(fā)現(xiàn),在奶牛養(yǎng)殖場規(guī)模較大的情況下,對于突發(fā)的重度跛行奶牛,受到奶牛數(shù)量的影響,可能難以及時(shí)發(fā)現(xiàn),導(dǎo)致預(yù)防與治療不及時(shí),會(huì)引起養(yǎng)殖場不必要的經(jīng)濟(jì)損失。更重要的,為了解決奶牛早期輕、中度跛行的及時(shí)檢測,本研究中將樣本分為正常、輕度跛行與中重度跛行 3類,以期為現(xiàn)代大規(guī)模奶牛養(yǎng)殖提供跛行奶牛的在線實(shí)時(shí)檢測問題,尤其是為輕度跛行檢測提供一種可靠方案。
筆者課題組研究發(fā)現(xiàn),當(dāng)奶牛跛行時(shí),奶牛頭部、頸部及背部連接處也有明顯的特征變化,故將其特征用于奶牛跛行檢測,并進(jìn)行驗(yàn)證。視頻分析技術(shù)成本低,省時(shí)省力,并有快速響應(yīng)的優(yōu)勢,同時(shí)避免了與奶牛直接接觸所帶來的一些問題。近來,視頻對象跟蹤[7-14]和數(shù)據(jù)分類[15-19]引起了越來越多研究學(xué)者的興趣。因此,利用視頻分析技術(shù)對目標(biāo)區(qū)域或感興趣區(qū)域進(jìn)行跟蹤并對其有效特征數(shù)據(jù)連續(xù)獲取,這對檢測奶牛跛行具有重要的意義。但目前來看還存在 3個(gè)問題:1) 奶牛連貫性運(yùn)動(dòng)參量獲取方式可靠性不足;2) 現(xiàn)有奶牛視頻處理方法尚未涉及奶牛連貫性運(yùn)動(dòng)參量與奶牛跛行之間的關(guān)系;3) 因輕度跛行奶牛特征不明顯,尚難以實(shí)現(xiàn)奶牛輕度跛行的檢測。本研究擬提出一種基于NBSM-LCCCT-DSKNN(normal background statistical modellocal circulation center compensation track-distilling data of KNN)的奶牛跛行檢測算法,通過對視頻中奶牛進(jìn)行跟蹤并提取目標(biāo)奶牛的頭部、頸部以及與頸連接的背部輪廓線擬合直線斜率數(shù)據(jù),提取出大量的斜率數(shù)據(jù)經(jīng)過數(shù)據(jù)清洗之后,將其放入KNN分類器中實(shí)現(xiàn)奶牛輕度跛行與中重度的跛行的檢測,以期為診斷與預(yù)測奶牛跛行提供一種新方法。
1 材料與方法
1.1 試驗(yàn)視頻材料
試驗(yàn)視頻于2013年 7月至8月采集自陜西楊凌科元克隆股份有限公司的奶牛養(yǎng)殖場,試驗(yàn)對象為處于泌乳中期的美國荷斯坦奶牛。本研究共獲取30頭奶牛的視頻片段。每頭奶牛得到12段視頻,共計(jì)360段視頻,每段視頻持續(xù)時(shí)長約為10 ~40 s,從中隨機(jī)挑取6段中重度跛行奶牛行走視頻,6段輕度跛行奶牛行走視頻,6段正常奶牛行走視頻(采集信息見表 1),本文將奶牛跛行檢測任務(wù)視為分類任務(wù),在分類任務(wù)中,類別不平衡會(huì)導(dǎo)致分類結(jié)果向樣本多的一類傾斜[20-24],為避免類別不平衡問題,本文采用樣本類別比例為 1∶1∶1。采集視頻為PAL(phase alteration line)制式并保存在攝像機(jī)本地存儲(chǔ)卡內(nèi),幀率/碼率為25 fps/2000 kbps,分辨率為704 ×576像素。
視頻處理平臺處理器為 Inter Core i5-7200M,主頻為3.40 GHz,8 GB 內(nèi)存,500 GB 硬盤,算法開發(fā)平臺為MATLAB 2016b。
奶牛視頻信息,包含飛鳥、工人、夜間飛蟲、不同天氣等干擾因素,進(jìn)一步加劇了奶牛跛行檢測的難度。
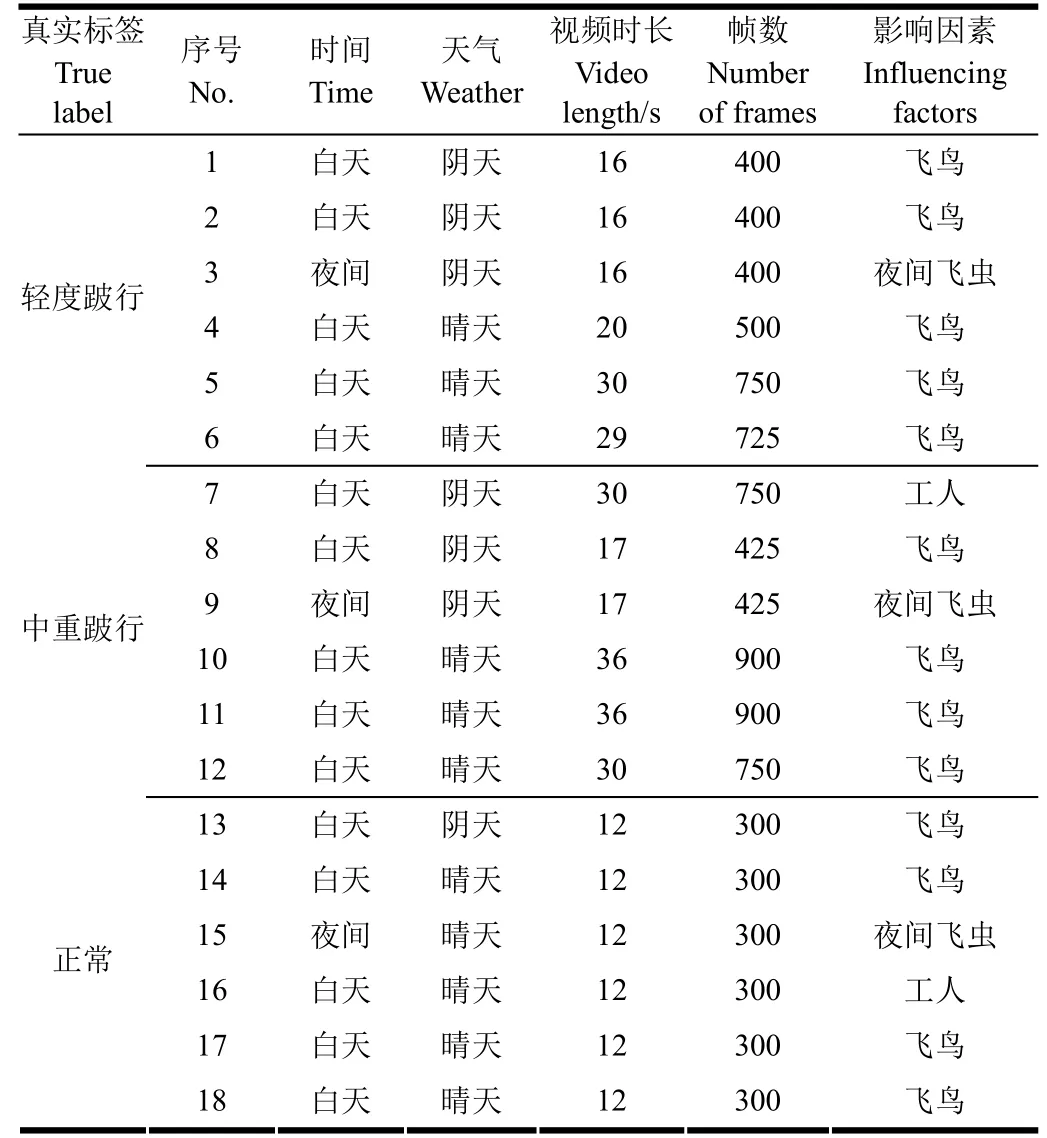
表1 奶牛視頻集包含的信息Table 1 Video information of cow video set
1.2 奶牛跛行檢測方法
本研究擬采用的技術(shù)路線如圖 1所示。算法主要包括3部分,第一部分為NBSM模型,主要用于將目標(biāo)奶牛與背景分離,獲取目標(biāo)奶牛像素區(qū)域;第二部分為LCCCT模型,主要用于獲取奶牛感興趣區(qū)域(region of interest, ROI),并進(jìn)行局部像素點(diǎn)中心進(jìn)行補(bǔ)償,獲得補(bǔ)償后的感興趣區(qū)域(compensation- region of interest,C-ROI)計(jì)算其質(zhì)心并進(jìn)行跟蹤;第三部分用于獲得跟蹤區(qū)域奶牛身體上輪廓的擬合直線斜率數(shù)據(jù),進(jìn)而訓(xùn)練DSKNN分類器。
1.2.1 NBSM模型
在分析奶牛視頻中每幀圖像的像素分布特性時(shí),發(fā)現(xiàn)在奶牛目標(biāo)像素與背景像素大致滿足雙峰分布,如圖2所示是視頻中某一幀圖像及其對應(yīng)的灰度直方圖,在圖像的灰度值擬合曲線中有明顯區(qū)域峰值,故本研究采用正態(tài)分布的目標(biāo)奶牛與背景檢測方法來描述像素分布的過程。
奶牛視頻中每幀圖像的像素分布特性中奶牛目標(biāo)與背景像素分布規(guī)律如圖3所示。幀圖像像素點(diǎn)按照式(1)映射在極坐標(biāo)中獲得到圖 3a。本文將圖像幀中的內(nèi)容視為奶牛目標(biāo)與背景,且背景像素一定比目標(biāo)像素?cái)?shù)目多,故在極坐標(biāo)中幀圖像像素會(huì)呈現(xiàn)增-減-增-減的狀態(tài)。擬合曲線極徑總體變化狀態(tài)呈現(xiàn)增-減-增-減,表明幀圖像像素分為目標(biāo)奶牛像素與背景像素2部分。
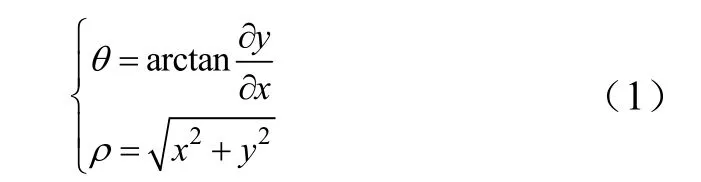
式中x為灰度值,y為灰度值所對應(yīng)的像素?cái)?shù),θ為極角,ρ為極徑。
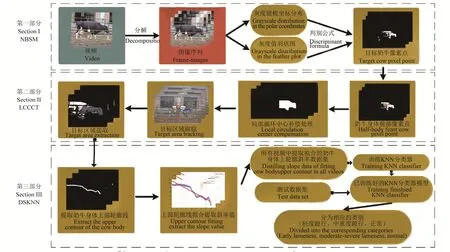
圖1 基于NBSM-LCCCT-DSKNN的奶牛跛行檢測方法流程圖Fig.1 Flowchart of lameness detection for dairy cows based on NBSM-LCCCT-DSKNN model
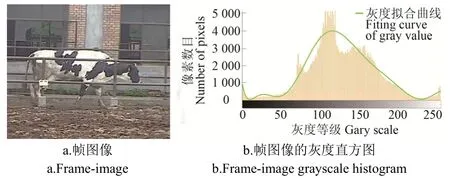
圖2 幀圖像及其灰度直方圖Fig.2 Frame-image and its grayscale histogram
圖3b是像素在羽狀圖的分布規(guī)律,折線表示灰度值所對應(yīng)的像素點(diǎn)數(shù)量,由于只將圖像內(nèi)容視為奶牛目標(biāo)與背景 2部分,且背景在圖像中所占比例遠(yuǎn)大于奶牛占圖像的比例,由圖3b中發(fā)現(xiàn)折線密集區(qū)域也由2個(gè)部分組成,折線密集區(qū)域和折線稀疏區(qū)域分別對應(yīng)目標(biāo)奶牛像素與背景像素。
將幀圖像目標(biāo)奶牛像素與背景像素分布可近似為 2個(gè)正態(tài)分布的疊加,如式(2)、式(3),其中包括背景正態(tài)分布與目標(biāo)奶牛正態(tài)分布2部分,并根據(jù)式(2)計(jì)算重率比。其中Pb是灰度直方圖中最大值與圖像中所有像素的比值。重率比是區(qū)分幀圖像像素分布當(dāng)中的背景像素和目標(biāo)奶牛像素的依據(jù),當(dāng)?shù)谝粋€(gè)正態(tài)分布所對應(yīng)的重率比小于第二個(gè)正態(tài)分布所對應(yīng)的重率比且小于1,說明第二正態(tài)分布重率比越接近1,其越可能屬于背景像素點(diǎn)的分布。
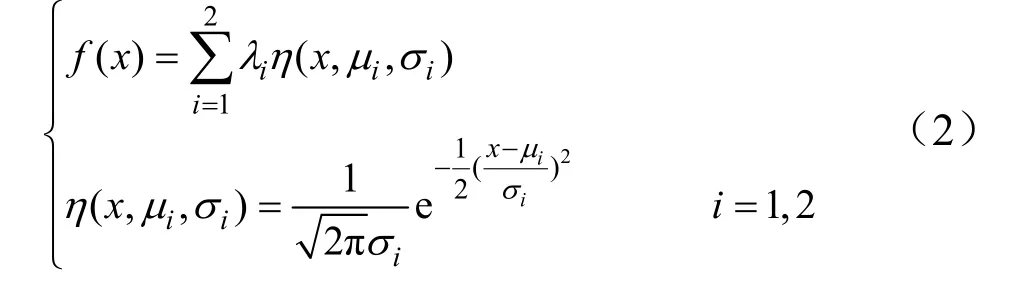
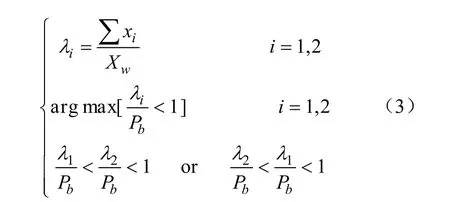
式中x為灰度圖像像素點(diǎn);μi、σi分別為正態(tài)分布的均值和方差;λi為2個(gè)正態(tài)分布分別所占比重;∑xi為對應(yīng)正態(tài)分布的像素點(diǎn)數(shù)目;Xw為圖像中像素點(diǎn)總數(shù)。
在奶牛發(fā)生跛行時(shí),奶牛頭頸部區(qū)域會(huì)發(fā)生較大幅度的變化,因此,其頭頸部區(qū)域(前半部像素區(qū)域)的完好分割有利于后期跛行行為的檢測,而奶牛軀干及臀部區(qū)域(后半部像素區(qū)域)與之無關(guān)。圖 4為模型各階段處理的結(jié)果,可以發(fā)現(xiàn),由于奶牛頭頸部的運(yùn)動(dòng)幅度大于奶牛軀干及臀部區(qū)域的運(yùn)動(dòng)幅度,且NBSM模型對運(yùn)動(dòng)幅度大的區(qū)域敏感,在利用NBSM模型進(jìn)行奶牛目標(biāo)分離時(shí),奶牛前部區(qū)域較為完整,因此可通過該特征將奶牛前半部像素區(qū)域提取出來。為了使奶牛身體前部像素區(qū)域更加完整,擬利用LCCCT模型進(jìn)行處理。
1.2.2 LCCCT模型
局部循環(huán)中心補(bǔ)償跟蹤模型LCCCT用于補(bǔ)償通過正態(tài)分布背景統(tǒng)計(jì)模型分離得到的不完整的奶牛像素區(qū)域,并進(jìn)行奶牛身體前部區(qū)域的跟蹤,該模型主要由局部循環(huán)中心補(bǔ)償算法、質(zhì)心跟蹤算法2部分構(gòu)成。
基本形式:給定二維目標(biāo)循環(huán)矩陣
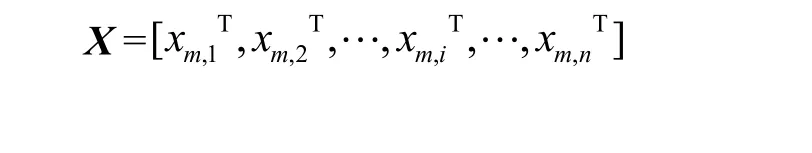
xm,iT與卷積窗口矩陣G進(jìn)行卷積運(yùn)算,卷積結(jié)果ym,iT為卷積中心所對應(yīng)的循環(huán)矩陣X中的數(shù)值進(jìn)行補(bǔ)償。
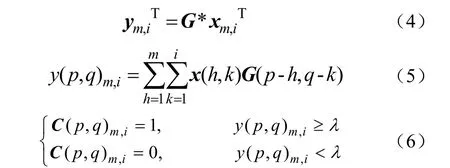
式中p,q代表像素點(diǎn)在圖像中的位置,xm,iT為二維矩陣,尺寸大小為3×3,卷積窗口G采用3×3的歸一化平均矩陣,Y=[ym,1T;ym,2T;··;ym,iT;··;ym,nT]為結(jié)果矩陣,λ為給定閾值,由于卷積矩陣G是一個(gè)二維矩陣,尺寸大小為3×3,且矩陣中每一個(gè)元素均為1/9,即進(jìn)行均勻卷積,故λ取值為卷積結(jié)果的0.5倍,C為補(bǔ)償結(jié)果矩陣。

圖3 幀圖像像素分布規(guī)律Fig. 3 Frame-image pixel distribution law
循環(huán)矩陣進(jìn)行上式(4)~(6)計(jì)算時(shí),可將補(bǔ)償區(qū)域最大化,故而需要將所提取得到的奶牛身體前部像素區(qū)域矩陣進(jìn)行循環(huán)矩陣化,如式(7)所示。

式中P、Q是排列矩陣,T是目標(biāo)奶牛身體前部像素區(qū)域矩陣。
循環(huán)矩陣與卷積窗口矩陣卷積過程如圖 5所示,圖5a中卷積窗口矩陣G與循環(huán)矩陣X中子矩陣塊xm,iT進(jìn)行卷積運(yùn)算,得到y(tǒng)m,iT結(jié)果矩陣的子矩陣塊,在圖5b中,得到的 ym,iT進(jìn)行閾值判別,若 ym,i(p,q) 大于等于給定閾值λ,則C(p,q)m,i=1;若ym,iT(p,q)小于λ,則C(p,q)m,i=0。上述過程可以達(dá)到像素區(qū)域補(bǔ)償?shù)哪康摹?/p>

圖4 模型各階段處理的效果Fig.4 Effect of each stage of model
對 NBSM 模型處理過的圖像按式(6)進(jìn)行循環(huán)矩陣化,卷積窗口矩陣G與處理過后的循環(huán)矩陣進(jìn)行滑動(dòng)卷積,得到卷積之后的結(jié)果矩陣Y,即將所有像素進(jìn)行增強(qiáng)處理,通過判別函數(shù)來判別當(dāng)前圖像中的像素是否為孤立的像素區(qū)域,若是,則進(jìn)行歸零處理,若否,則進(jìn)行保留,最終得到補(bǔ)償結(jié)果矩陣C,即圖4c。從圖4c可以發(fā)現(xiàn),LCCC算法對目標(biāo)奶牛區(qū)域保留了奶牛身體前部的形狀,補(bǔ)償了奶牛身體前部區(qū)域丟失或損失的像素區(qū)域,同時(shí),由于在算法中加入了孤立像素區(qū)域的抑制策略,對于非完整的奶牛后部像素區(qū)域,可以進(jìn)行較好地去除處理,在保證前部像素完整性的前提下起到了抑制后部像素區(qū)域的效果,為進(jìn)行奶牛身體前部區(qū)域的跟蹤奠定了基礎(chǔ)。
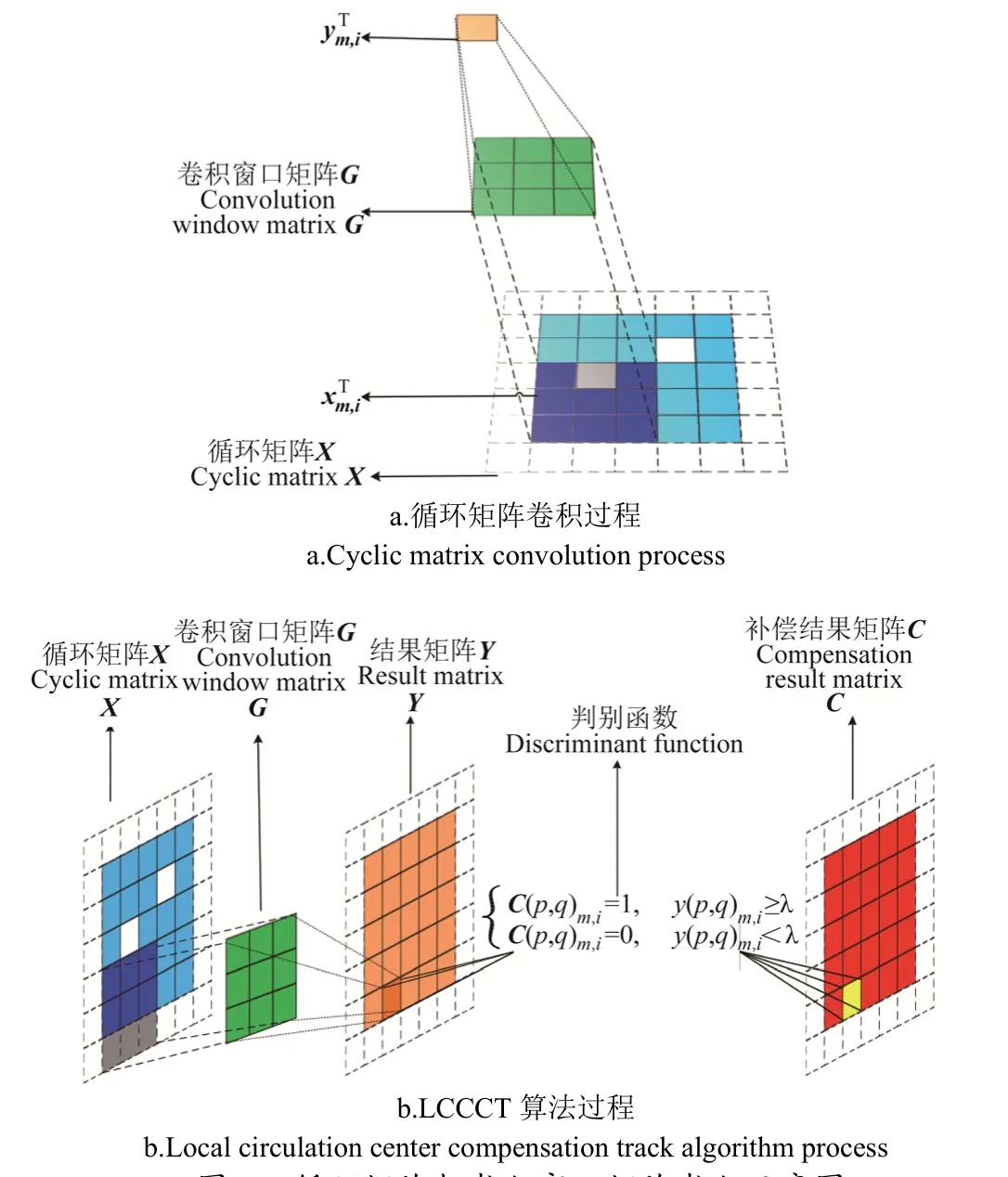
圖5 循環(huán)矩陣與卷積窗口矩陣卷積示意圖Fig.5 Cyclic matrix and convolution window matrix convolution
將局部循環(huán)中心補(bǔ)償算法處理過的圖像視為新的圖像f(x,y),由于補(bǔ)償后的新圖像中只有奶牛前部像素區(qū)域一個(gè)目標(biāo),不受每次提取目標(biāo)部分大小的影響,即可根據(jù)式(7)計(jì)算補(bǔ)償后的目標(biāo)奶牛像素區(qū)域的質(zhì)心,根據(jù)質(zhì)心的變化進(jìn)行奶牛身體前部跟蹤。
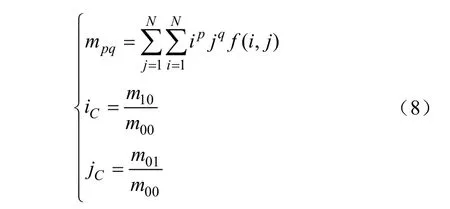
式中mpq是圖像f(x,y)的p+q階矩;m10、m01為其1階矩、m00為其0階矩;iC、jC分別為圖像f(x,y)的質(zhì)心橫坐標(biāo)和縱坐標(biāo)。
為了驗(yàn)證跟蹤效果,利用表1所述視頻進(jìn)行了測試,結(jié)果表明,視頻1-17均可以準(zhǔn)確跟蹤,僅視頻18因奶牛運(yùn)動(dòng)幅度過小而導(dǎo)致跟蹤失敗的問題,表明跟蹤算法對普通運(yùn)動(dòng)幅度奶牛的跟蹤效果具有普遍意義。
圖4d為在18段奶牛視頻中(除視頻序號為18的奶牛視頻)隨機(jī)選取一段奶牛視頻跟蹤試驗(yàn)效果可以看出,跟蹤奶牛身體前部區(qū)域均能準(zhǔn)確跟蹤其位置,為提取奶牛身體前部上輪廓線奠定了基礎(chǔ)。
1.2.3 數(shù)據(jù)清洗
數(shù)據(jù)清洗(data cleaning)是對數(shù)據(jù)進(jìn)行重新審查和校驗(yàn)的過程,用于刪除重復(fù)信息、糾正錯(cuò)誤數(shù)據(jù)并提供數(shù)據(jù)一致性[25-28]。數(shù)據(jù)清洗按功能主要分為4類:1)解決不完整數(shù)據(jù)的方法;2)錯(cuò)誤值的檢測及解決方法;3)重復(fù)記錄的檢測及消除方法;4)不一致性的檢測及解決方法。
本文采取數(shù)據(jù)清洗方法是異常值檢測混合模型[29]。將對所有未清洗的數(shù)據(jù)集中的每一個(gè)數(shù)據(jù)計(jì)算其評價(jià)函數(shù)的值(本研究采用馬氏距離函數(shù)[30]),根據(jù)評價(jià)函數(shù)值來判斷當(dāng)前數(shù)據(jù)是否為異常點(diǎn)值。具體過程為:1)初始化:在時(shí)刻t=0,令Gt包含所有對象,而Bt為空;令?(Gt, Bt)為好壞觀測點(diǎn)劃分的評價(jià)函數(shù)(馬氏距離);2)對屬于Gt的每個(gè)點(diǎn) xt,將 xt從 Gt移動(dòng)到 Bt,產(chǎn)生新的數(shù)據(jù)集合Gt+1和Bt+1,計(jì)算?的新的評價(jià)函數(shù)的值;3)計(jì)算差值:△=?(Gt+1, Bt+1)-F(Gt, Bt);4)若△<c,將觀測xt分類為異常,其中c是給定閾值。
閾值c的取值采用的是3σ準(zhǔn)則[31],經(jīng)過上述數(shù)據(jù)清洗算法,可將大部分異常點(diǎn)或強(qiáng)影響點(diǎn)剔除,為提高分類器的分類精度奠定基礎(chǔ)。
1.2.4 線性斜率K最近鄰分類器模型
對提取出來的目標(biāo)奶牛身體前部像素區(qū)域,進(jìn)行Sobel算子輪廓邊緣提取,并利用傅里葉描述子進(jìn)行邊緣平滑[32],然后將奶牛身體前部像素區(qū)域中線以下設(shè)為0,該過程可以提取目標(biāo)奶牛身體上部輪廓線,并進(jìn)行線性擬合,得到擬合直線斜率。
本文對身體上部輪廓線定義為:奶牛身體上部輪廓線是從奶牛頭部的鼻尖起始,超過頸部線結(jié)束。若提取的輪廓線屬于定義的區(qū)域范圍,則認(rèn)為是有效的輪廓線,超出此范圍區(qū)域則認(rèn)為提取的是異常或具有強(qiáng)影響的輪廓線。奶牛低頭、抬頭以及左右轉(zhuǎn)頭等動(dòng)作會(huì)影響頭頸部擬合直線的斜率。但每一類奶牛的擬合直線斜率都存在不同的斜率范圍,故而對檢測結(jié)果沒有影響。
如圖6為所示獲取輪廓擬合直線處理過程及效果。
每一段視頻中都有大量的目標(biāo)奶牛頭、頸及背部連接處的輪廓線的擬合直線斜率數(shù)據(jù),可將其作為分類特征值進(jìn)行奶牛跛行的識別及檢測。
對18段奶牛視頻進(jìn)行處理,獲得頭部、頸部及背部連接處的擬合直線斜率數(shù)據(jù)集。試驗(yàn)采用加噪法,增加樣本的多樣性,從而可以檢測算法對環(huán)境魯棒性的強(qiáng)弱。對于 3類(正常奶牛、輕度跛行奶牛、中重奶牛跛行)18個(gè)樣本數(shù)據(jù)集按Bootstrap抽樣法[33-37]隨機(jī)分3層抽取3次,將抽取到不重復(fù)的樣本作為訓(xùn)練樣本,剩下樣本作為測試樣本,所得到的訓(xùn)練樣本集約占總數(shù)據(jù)集的63.2%。
本研究采用 K最近鄰分類器(K-nearest neighbor,KNN)進(jìn)行數(shù)據(jù)分類[38]。KNN 算法的思路是:如果一個(gè)樣本在特征空間中的 K個(gè)最相似(即特征空間中最鄰近)的樣本中的大多數(shù)屬于某一個(gè)類別,則該樣本也屬于這個(gè)類別。
該方法在定類決策上只依據(jù)最鄰近的一個(gè)或者幾個(gè)樣本類別來決定待分樣本所屬的類別。由于KNN方法主要靠周圍有限的鄰近樣本,而不是靠判別類域的方法來確定所屬類別的,因此對于類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合。本研究在利用KNN算法時(shí)采用的距離度量方式是標(biāo)準(zhǔn)歐幾里得距離[39],無距離加權(quán)函數(shù),K值為3,即輕度跛行奶牛、中重度跛行奶牛、正常奶牛3類。
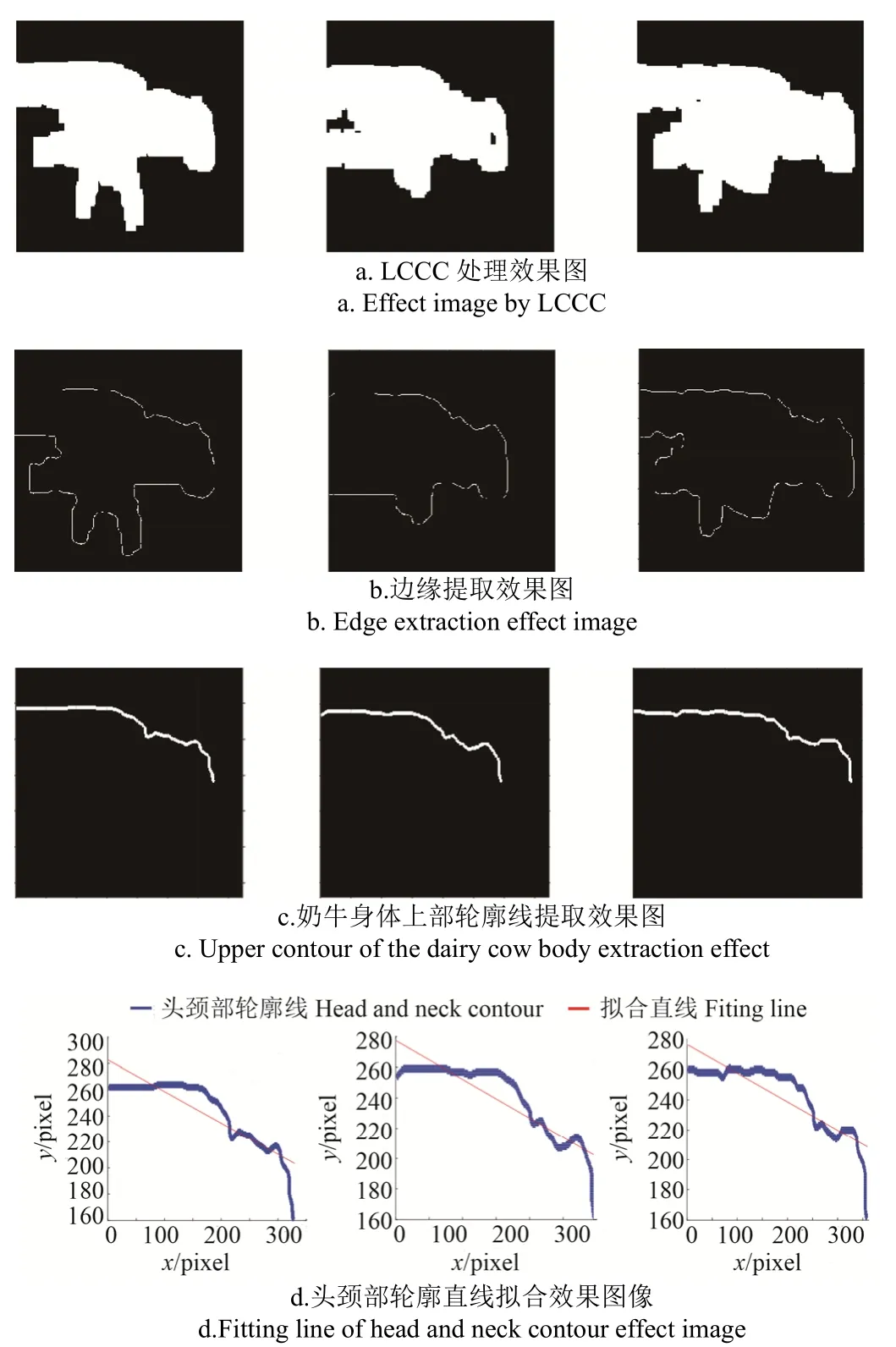
圖6 獲取頭頸部輪廓擬合直線處理過程及效果Fig.6 Process and effect of fitting line of head and neck contour
2 試驗(yàn)與結(jié)果分析
2.1 試驗(yàn)設(shè)計(jì)
為了驗(yàn)證該方法的有效性,分別使用了SVM[40]、樸素貝葉斯(naive bayes, NB)[41]分類器以及KNN的分類器對奶牛頭部、頸部及背部連接處的斜率數(shù)據(jù)清洗前后進(jìn)行效果對比試驗(yàn),本研究用10折交叉的方法在數(shù)據(jù)集上做分類測試。
2.2 使用分類算法對奶牛跛行檢測的結(jié)果
2.2.1 3種分類器性能結(jié)果分析
表2為SVM、Naive Bayes及KNN在未清洗的測試數(shù)據(jù)集的試驗(yàn)結(jié)果比較。可以看出,SVM和Naive Bayes的平均值均達(dá)到了82.78%,但比 KNN的平均分類精確度81.67%高1.11個(gè)百分點(diǎn)。由于未清洗的數(shù)據(jù)集呈現(xiàn)復(fù)雜度高、特征值分布雜等特點(diǎn),SVM和Naive Bayes這類統(tǒng)計(jì)性分類算法,比只將訓(xùn)練數(shù)據(jù)與測試數(shù)據(jù)進(jìn)行距離度量來實(shí)現(xiàn)分類的KNN算法更加合適在未清洗的數(shù)據(jù)集上進(jìn)行分類。從結(jié)果上來看,在未清洗的數(shù)據(jù)集上,3種分類器的準(zhǔn)確率均不高,但選取奶牛頭部、頸部及背部連接處特征能夠進(jìn)行奶牛跛行的檢測。
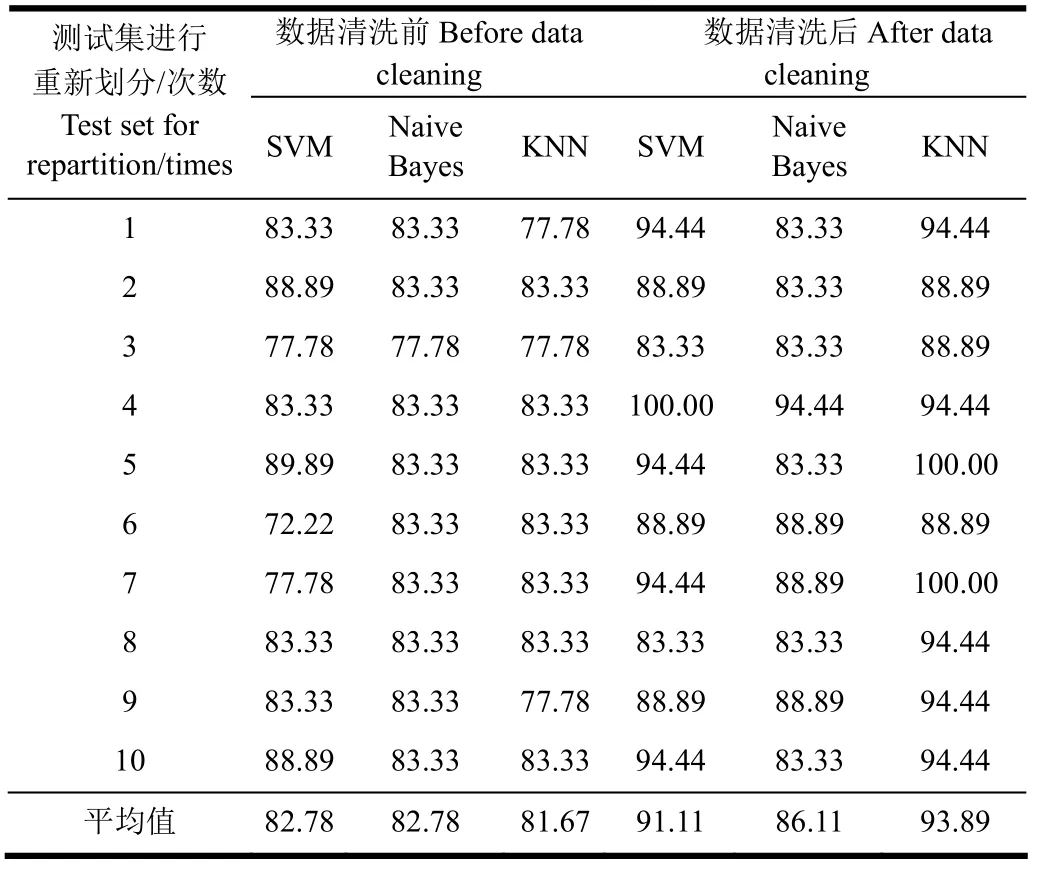
表2 SVM、Naive Bayes及KNN在數(shù)據(jù)清洗前后對測試數(shù)據(jù)集的分類正確率比較Table 2 Comparison of classification accuracy by SVM, Naive Bayes, and KNN algorithm on test data sets before and after data cleaning %
3種算法在未清洗的數(shù)據(jù)集上的訓(xùn)練所需時(shí)間及正確率比較如圖7所示。從圖7a可以看到,SVM和Naive Bayes訓(xùn)練所需時(shí)間很接近,SVM花費(fèi)的時(shí)間要比Naive Bayes略高,主要原因是SVM算法要對未清洗的數(shù)據(jù)集作分類超平面的統(tǒng)計(jì),而KNN所用時(shí)間相對較短,主要原因是KNN不需要進(jìn)行模型訓(xùn)練而只需要進(jìn)行距離度量的計(jì)算。從圖7b可以看到,在未清洗的數(shù)據(jù)集上,SVM和Naive Bayes的正確率略高于KNN;試驗(yàn)結(jié)果說明使用SVM與Naive Bayes分類器在未清洗的數(shù)據(jù)集上將正常奶牛、輕度跛行奶牛、中重度跛行奶牛錯(cuò)誤分類的可能性很小。
2.2.2 數(shù)據(jù)清洗后3種分類器性能結(jié)果分析
如圖 8所示為正常、輕度跛行、中重跛行奶牛斜率未清洗的數(shù)據(jù)集箱圖,由于奶牛行進(jìn)方向不一致,得到的斜率有正有負(fù)。當(dāng)奶牛由左往右行進(jìn),得到的斜率數(shù)據(jù)為負(fù),反之為正。為了數(shù)據(jù)保持一致性及規(guī)律性,將為負(fù)的斜率數(shù)據(jù)按式(8)進(jìn)行轉(zhuǎn)換成正斜率數(shù)據(jù)。在圖8中,每一個(gè)箱體代表一段視頻中的斜率數(shù)據(jù)集,箱體中的線段為該段視頻里斜率數(shù)據(jù)的中位數(shù)(中位線),奶牛低頭、抬頭以及轉(zhuǎn)頭等動(dòng)作會(huì)影響頭頸部擬合直線的斜率,在奶牛視頻中若突然出現(xiàn)上述動(dòng)作,則斜率會(huì)發(fā)生突變,即與其他幀圖像所獲得的斜率差異較大,這些突變的斜率視為異常點(diǎn),即箱體外的點(diǎn)標(biāo)記代表異常點(diǎn)。其中,第 1、2、5組中重度跛行奶牛、輕度跛行奶牛以及正常奶牛的箱圖雖然有交疊區(qū)域,但中重度跛行奶牛的箱體中位線均在其箱體圖的 50%以下,輕度跛行奶牛的中位線基本保持在同一水平線,正常奶牛的中位線均處于上述2者中位線之上,具有明顯的區(qū)分度。第4組視頻箱圖里,中重度跛行奶牛箱圖分布發(fā)生異常,是由于在該段奶牛視頻里的奶牛跛行程度嚴(yán)重且發(fā)生了多次的低頭、抬頭以及轉(zhuǎn)頭等動(dòng)作,即異常點(diǎn)增多,常規(guī)斜率數(shù)據(jù)點(diǎn)減少,但在第4組視頻中箱圖仍然可以發(fā)現(xiàn),3類奶牛箱圖中位線區(qū)分明顯,不影響奶牛跛行的檢測結(jié)果。發(fā)現(xiàn)正常、輕度跛行、中重跛行奶牛斜率未清洗的數(shù)據(jù)集中均存在異常點(diǎn),這些異常點(diǎn)會(huì)影響分類器的分類準(zhǔn)確率。將異常點(diǎn)剔除,即將奶牛抬頭、低頭等行為的干擾影響消除。

式中xi為負(fù)的斜率數(shù)據(jù), xi*為新的正斜率數(shù)據(jù)
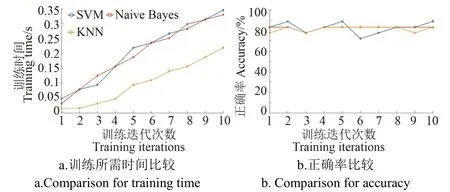
圖7 未清洗的數(shù)據(jù)集上訓(xùn)練所需時(shí)間及正確率比較Fig.7 Result of comparison for training time and accuracy on uncleaned data sets

圖8 正常、輕度跛行、中重跛行奶牛未清洗的斜率數(shù)據(jù)集箱圖Fig.8 Boxplot of uncleaned slope data set for normal, mild claudication, moderate-to-heavy lame dairy cows
針對清洗之后的新數(shù)據(jù),進(jìn)行SVM、Naive Bayes以及KNN分類算法的試驗(yàn),試驗(yàn)結(jié)果見表2。
雖然SVM和 KNN的平均值分別達(dá)到了91.11%和93.89%,但KNN的平均分類精確度高出SVM分類精確度2.78個(gè)百分點(diǎn),而Naive Bayes的分類精確度,相比未清洗的數(shù)據(jù)上進(jìn)行分類精度雖有增長,但在此次試驗(yàn)結(jié)果中是分類精度最低的分類器。由于新數(shù)據(jù)集具有較少的強(qiáng)影響點(diǎn)或者沒有異常點(diǎn),所以KNN這類只進(jìn)行距離度量來實(shí)現(xiàn)分類的算法要優(yōu)于SVM和Naive Bayes這類統(tǒng)計(jì)性分類算法,在新數(shù)據(jù)集上KNN算法更加合適進(jìn)行分類。但從分類結(jié)果上來看,在清洗之后的新數(shù)據(jù)集上,3種分類器中的SVM與KNN的準(zhǔn)確率均較高。
3種算法在清洗之后的數(shù)據(jù)集上的訓(xùn)練所需時(shí)間及準(zhǔn)確率比較如圖9所示。從圖9a可以看到,SVM訓(xùn)練所需時(shí)間很長,而Naive Bayes訓(xùn)練所需時(shí)間次之從圖9b可以看到,在新的數(shù)據(jù)集上,KNN的錯(cuò)誤分辨率明顯高于SVM和Naive Bayes,KNN的平均正確率接近94%。試驗(yàn)結(jié)果說明使用KNN分類器將在未清洗的數(shù)據(jù)集上將正常奶牛、輕度跛行奶牛、中重度跛行奶牛錯(cuò)誤分類的可能性很小,且因?yàn)闀r(shí)間是以秒計(jì)算,實(shí)際應(yīng)用中在大量數(shù)據(jù)的情況下KNN訓(xùn)練所需時(shí)間的優(yōu)勢非常明顯。
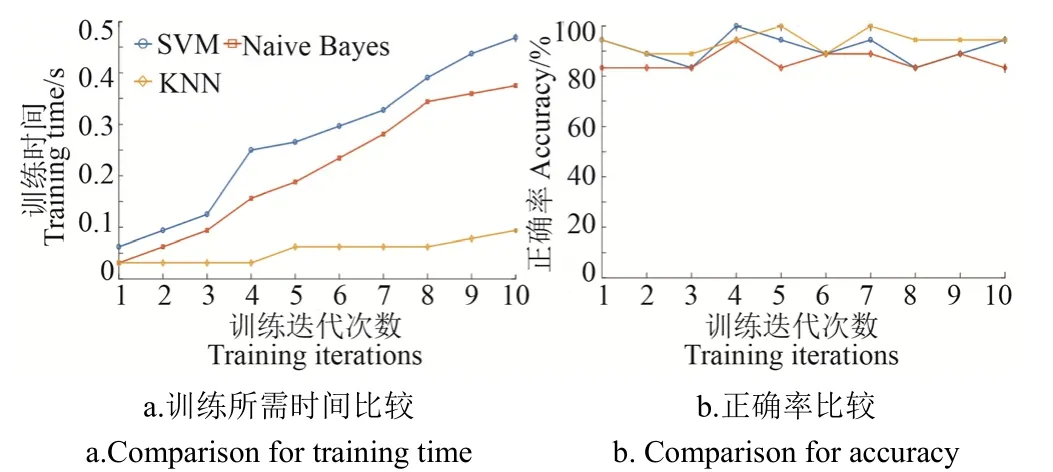
圖9 在數(shù)據(jù)清洗后數(shù)據(jù)集上訓(xùn)練所需時(shí)間及正確率比較Fig.9 Result of comparison for training time and accuracy on cleaned data sets
2.3 斜率異常點(diǎn)值或強(qiáng)影響點(diǎn)對分類結(jié)果的影響
本文提出的算法通過奶牛頭部、頸部及背部連接處的擬合直線斜率能夠檢測到奶牛跛行的種類,包括正常奶牛、輕度跛行奶牛、中重度奶牛 3類,在不同環(huán)境影響下通過本文提出的算法進(jìn)行了環(huán)境魯棒性的試驗(yàn),結(jié)果如圖10所示。
數(shù)據(jù)清洗將未清洗的斜率數(shù)據(jù)中的異常突變值進(jìn)行了剔除,通過減少異常突變值的方式,得到的奶牛跛行類型概率平均提高了10.00個(gè)百分點(diǎn),可以發(fā)現(xiàn)該算法在晴天、陰天以及白天與夜間均能得到正確結(jié)果,表明該算法具有較好的環(huán)境魯棒性。
獲得頭部、頸部及背部連接處的擬合直線斜率數(shù)據(jù)的未清洗的數(shù)據(jù)集中,存在強(qiáng)影響點(diǎn)值與異常點(diǎn)值,這兩種數(shù)據(jù)會(huì)影響分類器的分類準(zhǔn)確度。產(chǎn)生這兩類點(diǎn)是由于局部循環(huán)中心補(bǔ)償算法的局限性,算法由于數(shù)學(xué)關(guān)系決定了其只適用于各像素位置間距較小的情況,而出現(xiàn)這類情況根本原因是奶牛整體運(yùn)動(dòng)幅度過小導(dǎo)致的。如圖 11a~圖 11c所示,這類像素位置間距較大的情況LCCCT算法效果不明顯。
由于這一原因,在奶牛跛行跟蹤的過程中,容易將跟蹤區(qū)域平移,將目標(biāo)區(qū)域錯(cuò)過。圖11a所示,跟蹤框偏離了目標(biāo)跟蹤區(qū)域,圖11b~圖11e提取了偏離目標(biāo)跟蹤區(qū)域的像素區(qū)域,并進(jìn)行了上輪廓線的提取,導(dǎo)致圖11f中擬合直線誤差非常明顯,無法表達(dá)此時(shí)可奶牛頭部、頸部及背部連接處真實(shí)斜率數(shù)據(jù),即所得斜率數(shù)據(jù)也是異常點(diǎn)數(shù)值或強(qiáng)影響點(diǎn)數(shù)值。這類情況所產(chǎn)生的數(shù)據(jù)會(huì)導(dǎo)致分類器的分類準(zhǔn)確率降低。
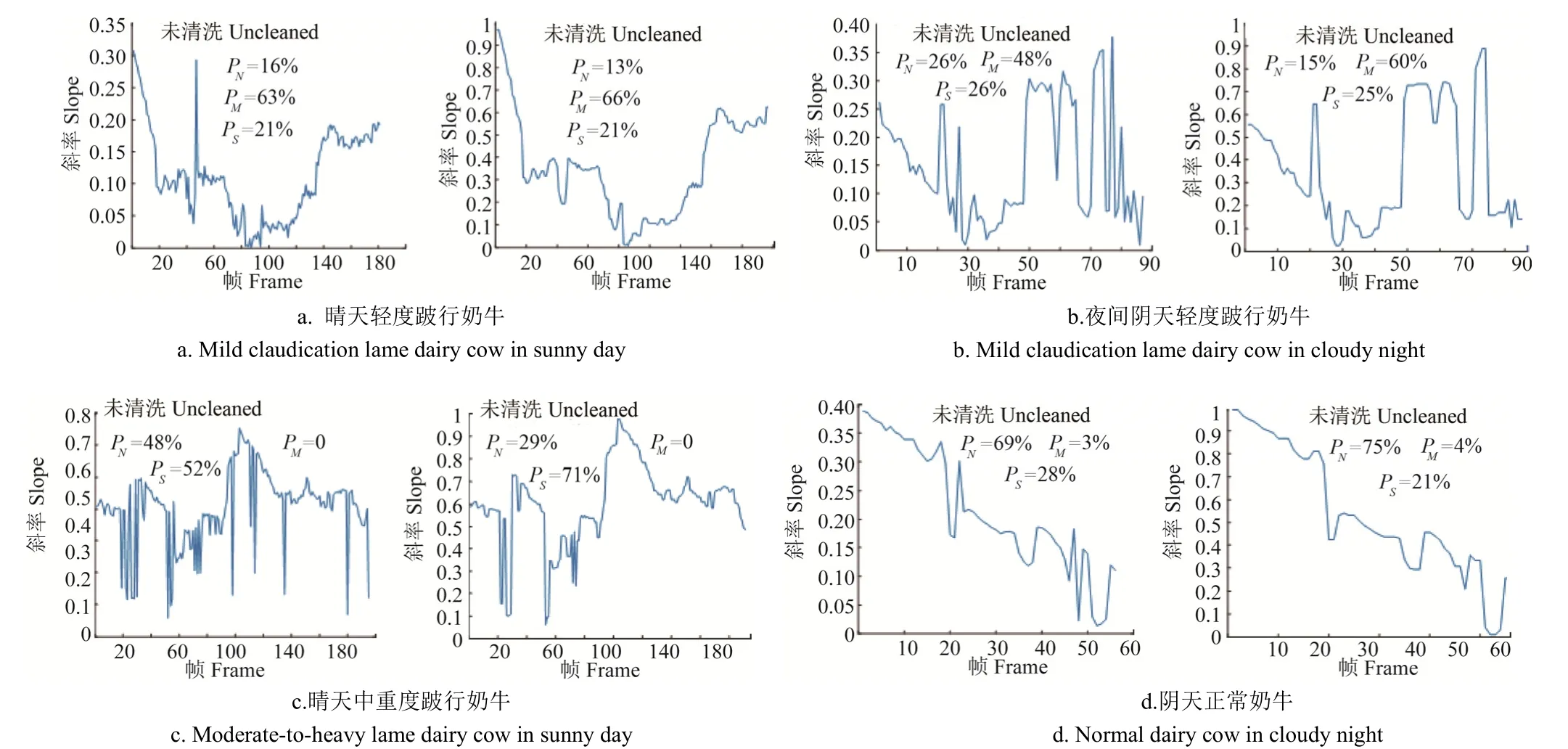
圖10 數(shù)據(jù)清洗前后算法環(huán)境魯棒性試驗(yàn)結(jié)果Fig.10 Results of algorithm environment robustness test before and after data cleaning
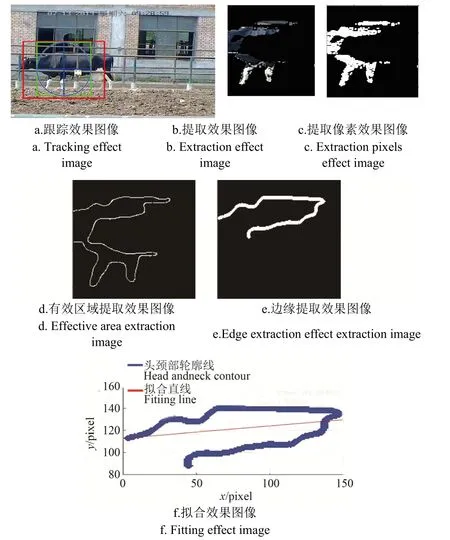
圖11 產(chǎn)生奶牛斜率異常點(diǎn)或強(qiáng)影響點(diǎn)的情況Fig.11 Produce a point of abnormal cows or strong impact point of the situation
3 結(jié) 論
為了解決現(xiàn)有人工跛行檢測存在的不夠及時(shí),難以發(fā)現(xiàn)問題,本研究基于視頻分析技術(shù),利用NBSM-LCCCT-DSKNN模型實(shí)現(xiàn)了奶牛跛行檢測,所取得的主要結(jié)論如下:
1) 利用文中算法提取出未清洗的頭頸部斜率數(shù)據(jù),在SVM、Naive Bayes以及KNN算法進(jìn)行跛行的分類檢測對比可以發(fā)現(xiàn)中,SVM與Naive Bayes分類算法準(zhǔn)確率相同且最高均為82.78%,表明選取奶牛頭部、頸部及背部連接處特征檢測奶牛跛行是有效的、可行的。
2)在清洗后數(shù)據(jù)集上進(jìn)行跛行的分類檢測,在SVM、Naive Bayes以及KNN算法進(jìn)行跛行的分類檢測對比中,SVM 與 Naive Bayes分類算法準(zhǔn)確率分別為 91.11%、86.11%,KNN算法分類準(zhǔn)確檢測率達(dá)到了94.44%,表明在數(shù)據(jù)清洗的基礎(chǔ)上進(jìn)行奶牛跛行分類有助于提升其分類精度。KNN算法訓(xùn)練時(shí)間明顯小于其他二者算法的訓(xùn)練時(shí)間,其更適合進(jìn)行奶牛跛行檢測。
3)由于在局部循環(huán)中心補(bǔ)償算法中其循環(huán)矩陣的局限性,進(jìn)行跛行的分類檢測過程時(shí),數(shù)據(jù)集中的異常點(diǎn)與強(qiáng)影響點(diǎn)均會(huì)降低奶牛跛行分類準(zhǔn)確檢測率;本文算法能夠?qū)φD膛!⑤p度跛行奶牛、中重度跛行奶牛進(jìn)行準(zhǔn)確的跛行判斷,但未能對運(yùn)動(dòng)幅度過小、存在其他異常行為的奶牛做出正確的分類檢測,尚需進(jìn)一步深入研究。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
