一種針對大規(guī)模社交網(wǎng)絡的用戶信任度預測算法
2018-08-17 00:26:48,
計算機工程 2018年8期
,
(江西財經(jīng)大學 軟件與物聯(lián)網(wǎng)工程學院,南昌 330013)
0 概述
隨著計算機網(wǎng)絡的快速發(fā)展,網(wǎng)絡社交已經(jīng)成為人們進行交流的主要方式之一[1]。近年來,社交網(wǎng)絡中的用戶量越來越龐大,網(wǎng)絡結構也越來越復雜。如何快速準確地預測大規(guī)模社交網(wǎng)絡中的用戶信任度顯得尤為重要。
通常情況下,信任是人們進行一切社交活動的基礎[2]。同時,在實際中,信任被認為是社交網(wǎng)絡中的一種特殊信息,其具有可傳播性、弱傳遞性和不確定性等性質[3]。這些性質為研究預測社交網(wǎng)絡中2個用戶間的信任度提供了思路。例如:社交網(wǎng)絡中的用戶A與用戶B素不相識,而在某個特定的環(huán)境下,A想要知道B是否可以信任。雖然A與B之前沒有任何聯(lián)系,但此時A可以通過咨詢他的朋友來搜集關于B的信任信息,并結合相關的信任推理方法最后對B做出信任度預測。
目前,社交網(wǎng)絡信任預測和個性化評估已被廣泛研究[4],且被應用于多種領域,如網(wǎng)絡安全、社交服務推薦[5]、P2P網(wǎng)絡[6]、電子商務[7-8]、云計算[9]等。這些研究的主要思路為:首先,從社交網(wǎng)絡中提取出相應的信任路徑(信任圖);然后,在該信任路徑上采用一些典型的信任整合策略計算出用戶的預測信任值,其中,基于圖簡化的信任度預測模型是研究較多的方式之一,較為典型的有Tidal Trust[10]、Mole Trust[11]和GFTrust[12]等算法。但是,這些算法通常只適用于小規(guī)模網(wǎng)絡或在大規(guī)模網(wǎng)絡中效率低下,且要求該網(wǎng)絡中每條邊都具有完整的信任關系。為解決這一問題,文獻[13]建立一種基于“小世界”網(wǎng)絡理論的信任圖生成框架SWTrust。該框架主要根據(jù)用戶活動域信息來計算用戶的信任相關度,并結合弱連接理論和社會距離來從大規(guī)模社交網(wǎng)絡中提取出一個信任圖,然后在該信任圖的基礎上利用8種基于可靠性模型的信任整合策略計算出用戶的預測信任值。但是,該方法所計算的用戶信任度依賴信任的發(fā)起者和被評價的信任者(如source和target),導致其計算效率存在局限性。
針對以上方法的不足,本文提出一種針對大規(guī)模社交網(wǎng)絡的用戶信任度預測算法TTDTrust。綜合考慮網(wǎng)絡中節(jié)點的拓撲特征和用戶信任率信息,并設計一種用戶拓撲信任度指標來衡量用戶信任信息。此外,該算法所計算的用戶拓撲信任度獨立于被評價的用戶對,即計算網(wǎng)絡中用戶拓撲信任度的過程可在線下進行。最后,本文在真實的社交網(wǎng)絡分析數(shù)據(jù)集上進行多次實驗來驗證該算法的有效性。
1 算法設計
1.1 相關定義
定義1(信任) 信任在不同領域有不同定義。本文主要采用文獻[10]對信任的定義,即信任為“一個用戶的行為將帶來好的結果”。此外,信任分為推薦信任和功能信任[4]。推薦信任是指一個用戶為某個用戶推薦另一個用戶的信任值,功能信任是一個用戶對另一個用戶的直接信任值。
通常情況下,2個用戶間的信任有2種表示方式:1)二進制表示,即“1”表示信任,“0”表示不信任;2)將信任表示為[0,1]內的某一個數(shù)值[14],數(shù)值越大表示越信任。本文采用后者作為信任表示方法。
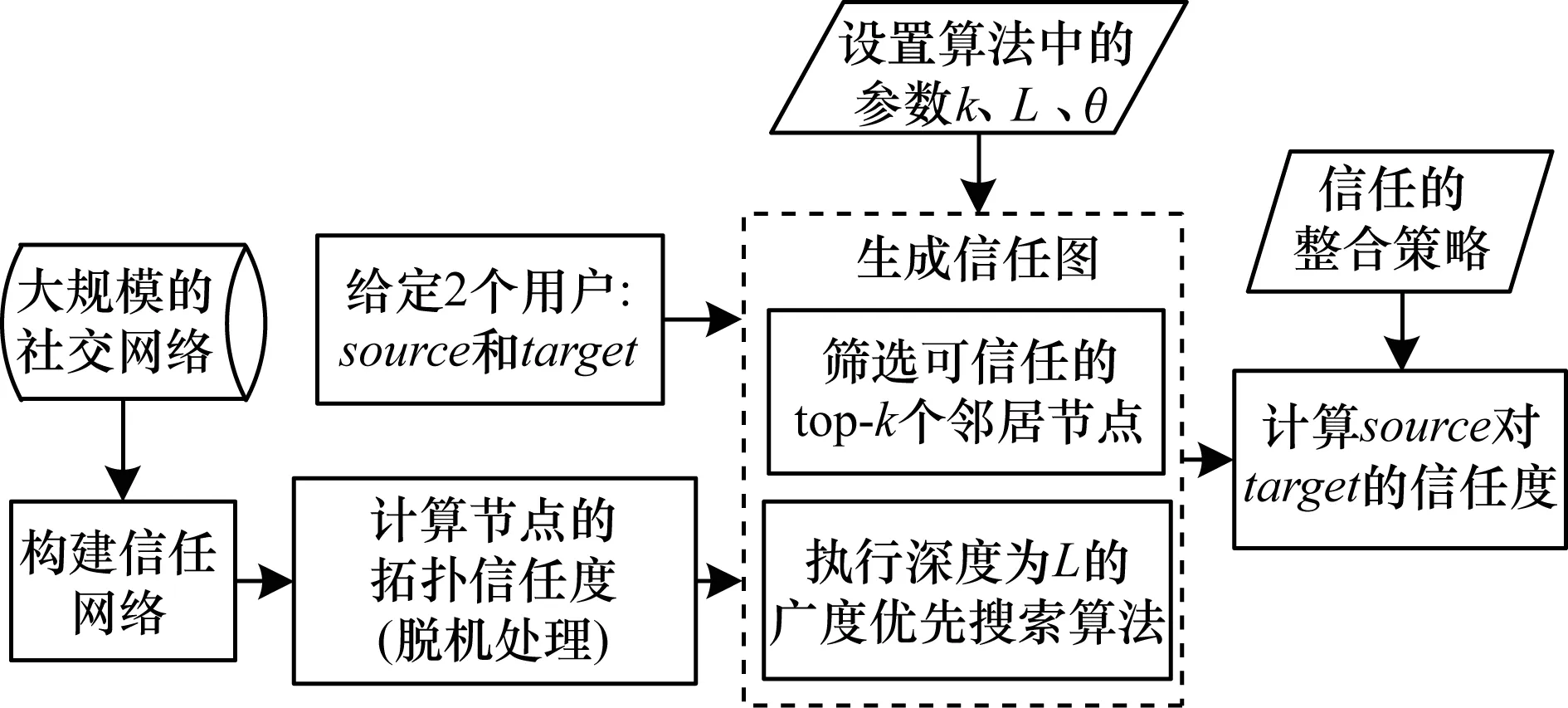
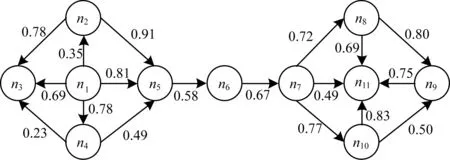
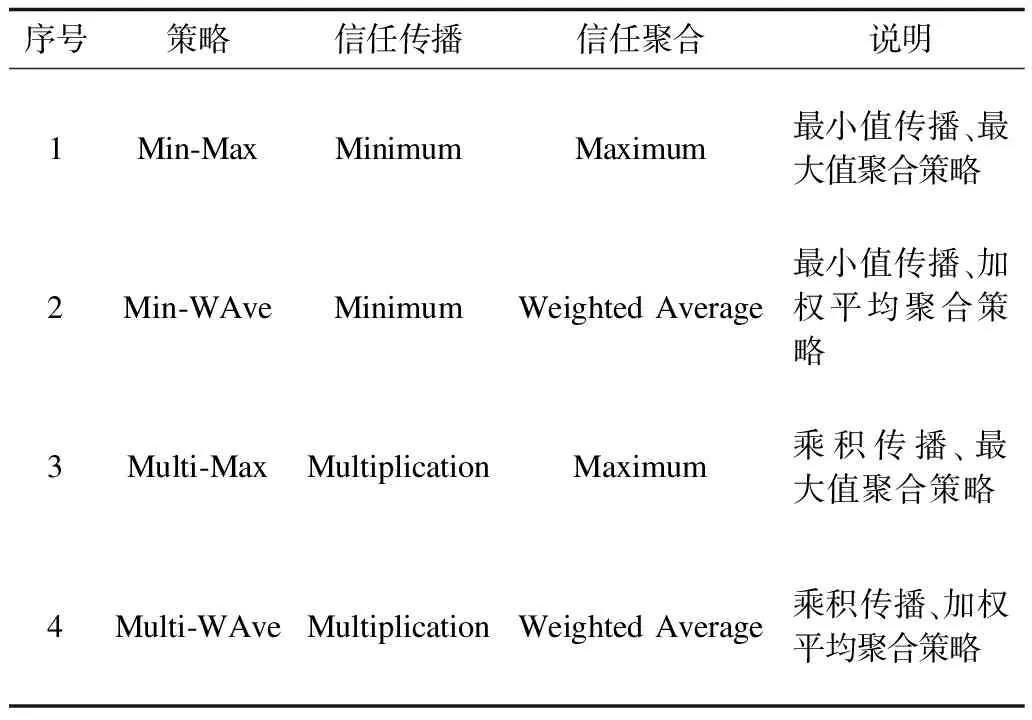
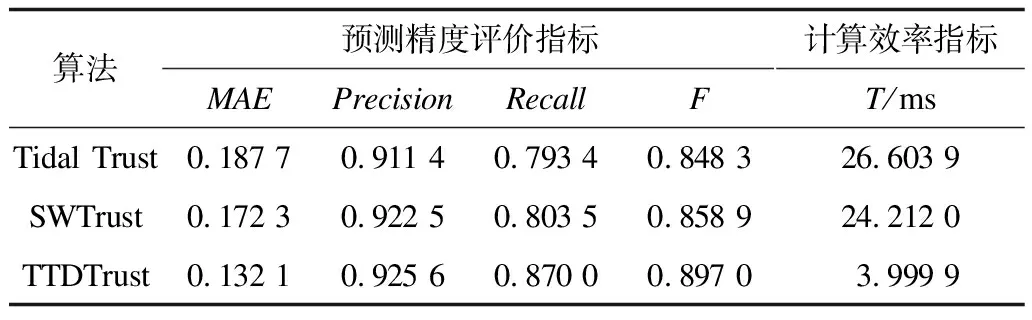
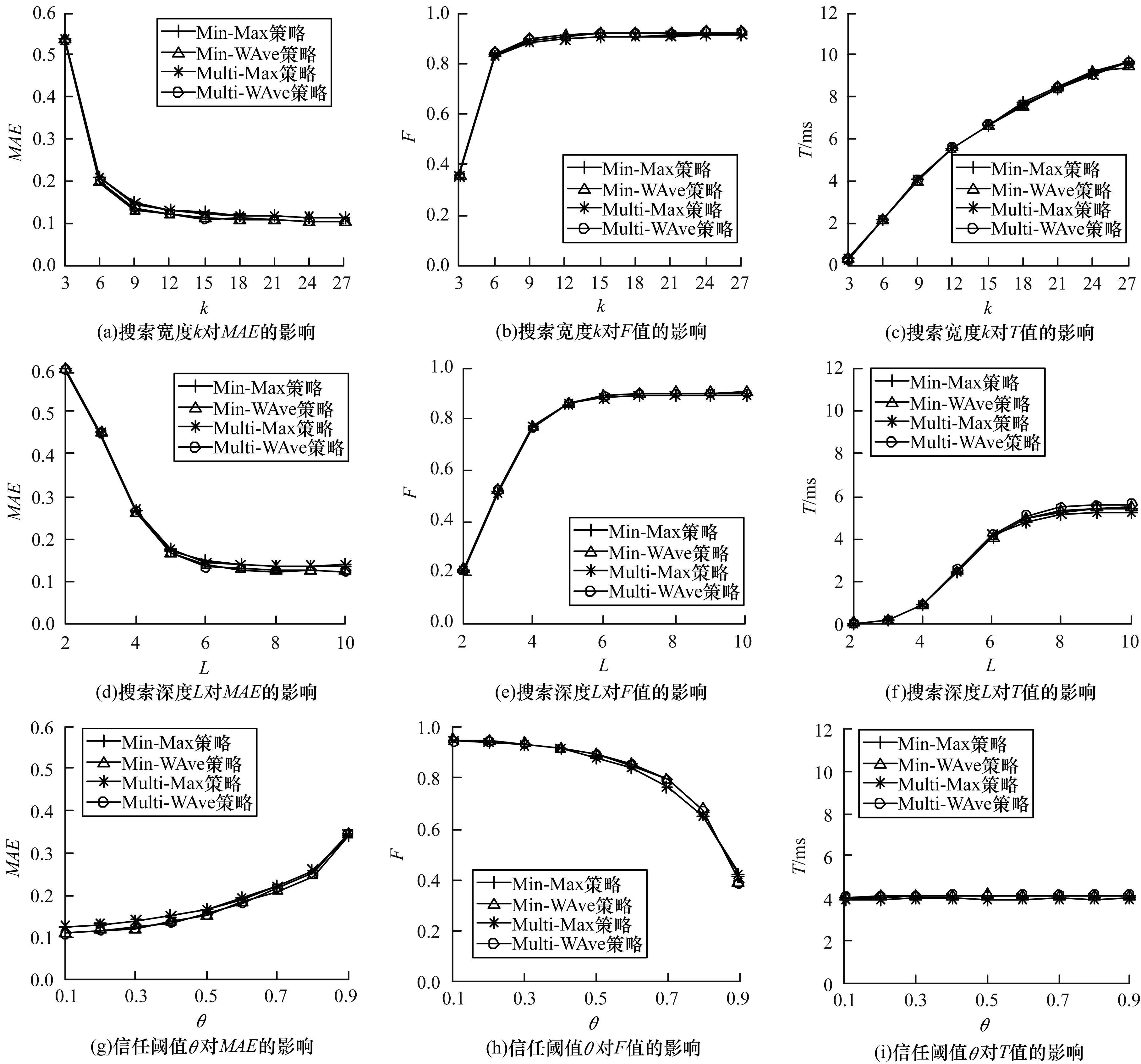
定義2(信任網(wǎng)絡) 對于一個給定的社交網(wǎng)絡,將其建模表示為對應的信任網(wǎng)絡G=(N,E,W)。其中,N代表社交網(wǎng)絡中的所有用戶,E代表信任網(wǎng)絡中的有向邊集合,每一條有向邊e(ni,nj)表示用戶ni(ni∈N,0 定義3(信任路徑) 對于給定的信任網(wǎng)絡G=(N,E,W),如果該網(wǎng)絡中的一個源節(jié)點source到另一個目標節(jié)點target之間存在一條可達的路徑p=(source,…,ni,nj,…,target),且p中任意邊e(ni,nj)上的權值tij大于信任閾值θ,則定義該路徑p為信任路徑。 定義4(信任圖) 對于給定的信任網(wǎng)絡G=(N,E,W),信任圖由source到target間的所有信任路徑構成。 基于第1.1節(jié)的定義,本節(jié)進一步描述如何預測網(wǎng)絡中源節(jié)點source對目標節(jié)點target的信任度。本文TTDTrust算法整體框架如圖1所示。該算法旨在預測大規(guī)模社交網(wǎng)絡中沒有直接社交的2個用戶之間的信任度,算法輸入為原始大規(guī)模社交網(wǎng)絡與2個待預測的用戶source和target。 圖1 TTDTrust算法整體框架 TTDTrust算法步驟為:1)將大規(guī)模社交網(wǎng)絡建模表示為信任網(wǎng)絡;2)計算信任網(wǎng)絡中節(jié)點的拓撲信任度(在線下進行計算);3)根據(jù)節(jié)點的拓撲信任度篩選該節(jié)點可信任的top-k個鄰居;4)執(zhí)行深度為L的廣度優(yōu)先搜索算法,生成source到target的信任圖;5)在該信任圖上采用信任整合策略計算source對target的信任度。 在社交網(wǎng)絡分析中,通常利用節(jié)點度[15]、緊密度[16]和介數(shù)中心性[17]等度量來評估節(jié)點的信息傳播能力。其中,節(jié)點度因設計簡單而被廣泛運用,但其難以充分度量節(jié)點的信息傳播能力。相比之下,緊密度和介數(shù)中心性因考慮到節(jié)點與節(jié)點之間的信息,可以較好地體現(xiàn)節(jié)點的信息傳播能力,但是其計算復雜度較高。因此,這3種度量方法均難以直接應用于社交網(wǎng)絡信任度預測中。文獻[18]通過考慮節(jié)點鄰居度信息,提出用一種局部中心性指標來評估節(jié)點的信息傳播能力。通常,在該指標考慮節(jié)點三步內鄰居的入出度情況時,就可以達到較好的效果,且其計算過程只需在一步節(jié)點度的基礎上進行即可。因此,該指標不僅具有較好的信息傳播能力,而且具備節(jié)點度計算簡單的特點。基于此,本文提出一種新的度量節(jié)點信任能力的指標:拓撲信任度,該指標綜合考慮網(wǎng)絡節(jié)點的拓撲特征和用戶的信任率信息。節(jié)點拓撲信任度如圖2所示。 圖2 節(jié)點拓撲信任度示意圖 定義5(節(jié)點拓撲信任度) 圖2中的一個信任網(wǎng)絡G=(N,E,W)共有11個節(jié)點,邊上權值為2個用戶的信任率,則定義節(jié)點n1的拓撲信任度Tdegree(n1)的計算公式如下: 綜上,對于一個給定的信任網(wǎng)絡G=(N,E,W)和2個用戶source、target,通過式(1)可以事先(脫機處理)計算出所有節(jié)點的拓撲信任度。 通常情況下,信任整合包括2個步驟: 步驟1針對信任圖中的每條路徑整合出一個信任值。 步驟2聚合多條路徑的信任值,即將步驟1中的所有信任值聚合成一個整體的信任度。 本文在實驗過程中實現(xiàn)了基于可靠性模型[19]的4種信任整合策略,具體信息如表1所示。 表1 信任整合策略信息 TTDTrust算法主要針對一個給定的大規(guī)模社交網(wǎng)絡和用戶source、target,預測source對target的信任度。其偽代碼如算法1所示。 算法1TTDTrust 輸入信任網(wǎng)絡G,源節(jié)點source,目標節(jié)點target,搜索廣度上界k,搜索深度上界L,信任閾值θ 輸出source對target的信任度t(source,target) 1.Queue={source},tempQ={}//初始化隊列Queue為 //source,tempQ為空 2.depth=0//初始化搜索深度為0 3.Spath={}//初始化信任路徑集為空 4.while (Queue非空,且depth小于等于L)do 5.從Queue中取出最前面的元素,并賦給v節(jié)點 6.從v所有鄰居中篩選出拓撲信任度最高的前top-k個鄰居 7.for (v節(jié)點的top-k鄰居中每一個節(jié)點u)do 8.查詢獲取u的拓撲信任度Tdegree(u)//事先通過式(1) //線下計算并存儲Tdegree(u) 9.if(u未訪問,且Tdegree(u)大于θ)then 10.if(u是target節(jié)點)then 11.從target回溯source得到一條信任路徑p 12.將p加入到Spath中 13.else 14.將u加入到tempQ中 15.標記u已經(jīng)被訪問 16.end if 17.end if 18.end for 19.if (Queue為空)then 20.將tempQ中的元素賦給Queue 21.depth增加1 22.清空tempQ 23.end if 24.end while 25.在Spath上分別利用4種信任整合策略計算出t(source,target) 26.return t(source,target) TTDTrust算法具體流程如下: 步驟1初始化數(shù)據(jù)結構與參數(shù)(第1行~第3行)。隊列Queue和tempQ分別用于存儲當前層訪問的節(jié)點和下一層訪問的節(jié)點,depth用于記錄每次遍歷的深度,Spath={}用于存儲最強信任路徑集。 步驟2執(zhí)行具有限制條件的廣度優(yōu)先搜索算法(第4行~第24行):1)只要隊列Queue不為空,且搜索深度depth≤L,就取出Queue中最前面的節(jié)點并賦給節(jié)點v;2)根據(jù)之前線下計算存儲的節(jié)點拓撲信任度,從v的所有鄰居中篩選出拓撲信任度最高的前top-k個鄰居;3)遍歷該top-k個鄰居中的每個節(jié)點u,查詢u的拓撲信任度Tdegree(u);4)對u進行判斷,如果u沒有被訪問且Tdegree(u)大于給定的信任閾值θ,則繼續(xù)判斷u是否為目標節(jié)點target,如果是目標節(jié)點,即從target回溯到source生成一條信任路徑p,并把p添加到信任路徑集Spath中,否則,標記u已經(jīng)被訪問,同時將u放入tempQ隊列中;5)如果Queue為空,則將tempQ隊列中的元素全部賦給Queue隊列,同時將搜索深度depth加1,并清空tempQ隊列。 步驟3分別采用表1中的4種信任整合策略計算出source對target的預測信任度t(source,target)(第25行)。 TTDTrust算法的計算時間主要包括線下計算時間和線上計算時間2個部分。 1)線下計算時間。線下計算過程主要為計算網(wǎng)絡中所有用戶的拓撲信任度。該過程遍歷每個用戶三步鄰居的邊,即需要掃描3|E|條邊,因此,該過程時間復雜度為O(|E|)。 2)線上計算時間。線上計算包括2個部分:(1)執(zhí)行搜索寬度為k、深度為L的廣度優(yōu)先搜索算法;(2)根據(jù)信任圖(信任路徑集)計算source對target的預測信任度。首先,為限制廣度優(yōu)先搜索算法的廣度,采用查找排序算法篩選每個用戶的top-k個鄰居,其時間復雜度為O(|N|·logak);然后,執(zhí)行廣度優(yōu)先搜索算法,該過程最差情況的時間復雜度為O(|V|+|E|)。此外,在計算source對target預測信任度的過程中,需要掃描信任圖中的每條路徑和路徑上的邊權(信任率),又因為信任圖中只有|Spath|條信任路徑,每條路徑的邊數(shù)最多不超過L,且|Spath|和L通常是一個較小的常數(shù),所以該過程的時間復雜度為O(1)。因此,線上計算過程的時間復雜度為O(|N|·logak)。 綜上,TTDTrust算法的總時間復雜度為O(|E|+|n|·logak),線上計算的時間復雜度為O(|N|·logak),遠小于傳統(tǒng)的全遍歷信任度預測算法的復雜度O(|V|·|E|),尤其是在大型網(wǎng)絡中,TTDTrust算法的時間復雜度優(yōu)勢更明顯。 本文采用真實的社交網(wǎng)絡數(shù)據(jù)集Epinions[20]進行實驗,實驗中舍棄不存在信任關系的用戶和邊,最后得到7 375個用戶節(jié)點和111 781條邊。考慮到數(shù)據(jù)集中的信任表示為二進制類型,在實驗過程中,本文采用文獻[14]方法,將用戶二值信任關系轉換為[0,1]范圍內的信任表示。具體方法為:首先,為每個用戶節(jié)點賦一個質量qi∈[0,1],且qi~N(μ,σ2);然后,從[max(qj-δij,0),min(qj+δij,1)]范圍內均勻地選取用戶ni對nj的信任值t(ni,nj)。其中,δij=(1-qi)/2表示噪音系數(shù),t(ni,nj)的范圍為[0,1],其值越大表示ni對nj越信任。 本次實驗使用的個人計算機配置為64位win7操作系統(tǒng),處理器為Intel(R) Core(TM) i5-2400 CPU@3.10 GHz RAM 8 G。實驗參數(shù)如表2所示。 表2 實驗參數(shù)設置 實驗過程采用留一法進行測試。實驗次數(shù)τ=10 000,每次實驗隨機地抽取一條邊進行測試,將第i次實驗中2個用戶之間的實際信任度值記為treal(i),預測信任度值記為tpred(i)。相應的信任度評估指標為平均絕對誤差(MAE)、準確度(Precision)、召回率(Recall)和F值。各值計算公式為: Precision=|SA∩SB|/SB (3) Recall=|SA∩SB|/SA (4) F=2×Precision×Recall/(Precision+Recall) (5) 其中,SA、SB分別為實驗隨機抽取的邊中treal(i)大于θ和tpred(i)大于θ的邊集合。 2.2.1 TTDTrust算法精度 為驗證TTDTust算法的有效性,分別運用4種典型信任整合策略測試TTDTust算法的信任預測精度,實驗結果如表3所示。 表3 TTDTrust算法的信任預測精度 由表3可以看出,在4種信任整合策略中,Min-WAve的MAE、Precision、Recall和F值都優(yōu)于其他3種策略,即Min-WAve預測效果最好。此外,從表3還可以看出,4種策略的綜合指標F最小值為0.883 1,最大值為0.897 0,該結果驗證了TTDTust算法具有較高的信任預測精度。 2.2.2 TTDTrust算法與典型預測算法的對比分析 在社交網(wǎng)絡信任度預測研究領域中,Tidal Trust算法[10]較典型,且其具有很強的代表性。此外,文獻[13]提出的SWTrust算法也是針對大規(guī)模社交網(wǎng)絡進行用戶信任度預測研究,且是近幾年社交網(wǎng)絡信任度預測模型中效果較好的算法之一。因此,本節(jié)實驗通過Min-WAve策略,進行TTDTrust算法與Tidal Trust算法、SWTrust算法的性能對比分析,實驗結果如表4所示。其中,T表示算法運行時間。 表4 3種算法在Min-WAve策略下的性能對比分析 由表4可以看出,與Tidal Trust、SWTrust算法相比,TTDTrust算法MAE值分別降低了29.62%和23.33%,Precision值分別提高了1.55%和0.33%,Recall值分別提高了9.65%和8.27%,F值分別提高了5.74%和4.43%。此外,在計算效率上,因為TTDTrust算法的線上計算時間較少,所以其總體計算時間大幅減少,Tidal Trust算法的計算時間是TTDTrust算法的6.65倍,SWTrust算法的計算時間是TTDTrust算法的6.05倍。這些結果均能說明TTDTrust算法針對大規(guī)模社交網(wǎng)絡用戶信任度預測時具有較好的效率。 2.2.3 參數(shù)k、L、θ對TTDTrust算法的影響 TTDTrust算法涉及3個關鍵參數(shù):k,L,θ。因此,本節(jié)實驗分別測試參數(shù)k、L、θ對TTDTrust算法的影響,算法MAE值、F值、T值3個指標的實驗結果如圖3所示。其中,圖3(a)~圖3(c)的實驗參數(shù)為k∈[3,27]、L=6、θ=0.5;圖3(d)~圖3(f)的實驗參數(shù)為k=9、L∈[2,10]、θ=0.5;圖3(g)~圖3(i)的實驗參數(shù)為k=9、L=6、θ∈[0.1,0.9]。 圖3 參數(shù)k、L、θ對TTDTrust算法的影響 由圖3(a)~圖3(f)可以看出,在k∈[3,9]、L∈[2,6]范圍內,隨著k、L的增大,TTDTrust算法的MAE值逐漸減小,F值、T值均逐漸增加。隨后,MAE值和F值開始收斂,T值增長放緩。此外,在圖3(c)中,T值增長曲線的趨勢與log函數(shù)基本相同。該結果與前文分析的TTDTrust算法時間復雜度為O(|N|·logak)相吻合。 由圖3(g)~圖3(i)可以看出,在θ∈[0.1,0.5]范圍內,隨著θ的增大,TTDTrust算法的MAE值、F值變化較小,而在θ=0.5后,MAE值顯著增大、F值顯著減小。這說明信任閾值θ不能設置過大,原因是信任閾值太大會導致太多的路徑被剔除,即信任閾值過大將導致source獲得過少關于target的信息,以至于降低了TTDTrust算法的精度。此外,從圖3(i)可以看出,隨著θ的增大,TTDTrust算法的運行時間變化甚微。 綜上可知,k、L和θ對TTDTrust算法均有較大影響,尤其在k∈[3,9]、L∈[2,6]、θ∈[0.5,0.9]范圍內影響較顯著。從實驗結果可以看出,在實際應用中取k=9、L=6和θ=0.5時,算法效果較好。 本文綜合考慮網(wǎng)絡中的節(jié)點拓撲結構信息和用戶信任率信息,提出一種針對大規(guī)模社交網(wǎng)絡的用戶信任度預測算法TTDTrust,并設計一種用戶拓撲信任度指標來衡量用戶信任信息。在真實的社交網(wǎng)絡分析數(shù)據(jù)集上進行多方面的實驗測試,結果表明,與典型算法Tidal Trust、SWTrust相比,TTDTrust算法具有較高的信任預測精度和計算效率。由于實際社交網(wǎng)絡往往具有較復雜的網(wǎng)絡環(huán)境,且用戶信任的影響因素較多,因此下一步將考慮多因素的信任建模并構建可應用于復雜網(wǎng)絡環(huán)境的信任模型。1.2 算法框架
1.3 拓撲信任度
1.4 信任整合策略
1.5 TTDTrust算法描述
1.6 算法復雜度分析
2 實驗結果與分析
2.1 數(shù)據(jù)集說明與實驗設置

2.2 算法性能分析
3 結束語
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
