面向LDA主題模型的文本分類研究進展與趨勢①
2018-08-17 12:06:14張興旺
計算機系統應用 2018年8期
趙 樂,張興旺
1(桂林理工大學 信息科學與工程學院,桂林 541004)
2(桂林理工大學 圖書館,桂林 541004)
1 引言
隨著互聯網的發(fā)展和迅速普及,面對著網絡中呈爆炸式增長且雜亂無章的數據,文本挖掘的工作就顯得愈發(fā)重要,人們希望能夠從海量的信息文本中準確的獲取想要的信息[1].那么,如何有效的獲取有價值的信息,如何對浩如煙海的文本數據進行自動分類、組織和管理就變得愈發(fā)困難[2].因此,面對這些問題和需求,利用計算機進行智能信息處理便得到了廣泛的研究.文本自動分類技術作為自然語言處理領域的研究熱點,得到了快速發(fā)展和廣泛應用.
文本自動分類技術作為文本數據挖掘的重要組成部分,在信息抽取、信息檢索、搜索引擎、個性化推薦等多個領域得到發(fā)展和應用,是自然語言處理的熱點和關鍵技術之一[3].其中,文本分類在處理大規(guī)模數據時,如何提高分類速度和準確性,如何進行特征方法選擇實現更好的降維操作,是當前的重要研究方向.LDA主題模型具有良好的降維性能,因此把它作為特征模型,再結合分類器設計能夠達到很好的分類效果.
LDA主題模型是符合文本生成規(guī)律的全概率生成模型,具有很好的文本表示能力,提取具有語義信息的主題.為了解決傳統意義上文本分類在語義相似性度量和文檔主題分布問題的不足,應用LDA主題模型方法[3].LDA主題模型的應用有助于降低特征向量空間維度,有助于提高文本分類性能.因此本文主要針對基于LDA主題模型的文本分類進行分析.
本文首先介紹了文本分類和LDA主題模型的相關理論;其次,從技術、方法和應用三個方面分析了面向LDA主題模型的文本分類的研究現狀;然后,分析了目前研究中存在的一些問題和研究策略;最后,分析并討論了文本分類未來的一些發(fā)展趨勢.
2 研究現狀分析
近些年來,信息資源呈現指數增長,大數據時代已經來臨,關于文本信息分類處理的研究和應用得到快速發(fā)展,成為自然語言處理領域重要的研究方向.
對于文本分類的研究現狀分析可從理論、技術和方法三個角度.理論分析了當前國內外關于文本自動分類技術和LDA主題模型的發(fā)展概述;相關技術對當前在文本分類中應用較為廣泛的分類器做了簡單介紹,并指出不足之處;最后是近幾年一些研究者在傳統方法的基礎上進行改進而提出的方法.
2.1 理論分析
2.1.1 文本分類分析
文本分類(text categorization),是在預先劃定好的文本類別集合中,根據文本的主題內容,把文本劃分為不同類別的過程.因為一個文本可能有一個或多個主題,所以一個文本也就可能對應一個或多個類別.一個文本分類系統不僅是一個自然語言處理系統,也是一個典型的模式識別系統,因此可以把一個文本分類系統看成是簡單的輸入輸出問題,系統輸入的是文本,輸出是文本對應的類別,如圖1所示[4].

圖1 文本分類系統示意
國外關于文本分類技術的研究起步較早,發(fā)展歷程如表1所示[5],當前已得到廣泛發(fā)展,應用于信息檢索、數據挖掘、模式識別等多種領域.由于在準確率和穩(wěn)定性方面具有明顯的優(yōu)勢,基于統計機器學習的文本分類方法日益受到重視.

表1 文本分類的發(fā)展
在過去的幾十年里,國內外學者提出及改進了一系列經典的機器學習算法,如樸素貝葉斯(Na?ve Bayes,NB)、支持向量機(Support Vector Machine,SVM)、K-最近鄰法(K-Nearest Neighbors,KNN)和神經網絡(Neural Networks,NNet)等.
這些方法具有很好的可移植性,將其成功應用于文本分類領域,取得了良好的效果.后來提出的LDA主題模型,以及在此基礎上改進的半監(jiān)督和弱監(jiān)督文本分類算法都取得了較好的分類效果,文本分類技術也有了很大的進步.
而漢語不同于其他語言,研究起來比較困難,所以國內的研究借鑒了國外的一些研究成果,是在侯漢清[6]關于自動文本分類技術方面的概述性報告之后才逐漸興起的.之后,一些專家學者開始熱衷于文本分類技術的研究,并提出了一些切實可行,具有很好分類性能的方法.
2.1.2 LDA主題模型概述
在2003年Blei等人在LSA和pLSA基礎上提出了LDA(Latent Dirichlet Allocation)主題生成模型[7].該模型是全概率生成模型,內部結構清晰,即文檔-主題-特征詞三層結構,可以利用高效的概率推斷算法進行計算,并且參數空間的規(guī)模與訓練文本數量無關,因此可以處理大規(guī)模語料.它的基本思想是:語料庫中的每個文本可以看成是若干潛在主題構成的一個概率分布,每個主題是由若干個特定詞匯組成的,并且以一定的概率出現.它解決了LSA的性能受損和計算復雜性的問題以及pLSA模型參數隨著文檔數量增加出現的過擬合問題,因此得到了廣泛應用.
2.2 相關技術分析
文本分類系統一般包括文本表示、特征選擇、權重計算、分類器設計和性能評測等五大功能模塊,而系統中的關鍵問題就是文本表示和分類器設計.
2.2.1 文本表示
文本是有文字和符號組成的非結構化信息表示方式,要使計算機能夠高效的處理真實文本,就必須找到一種理想的形式化表示方法,把非結構化的文本轉換為結構化的數學模型.常用的文本表示模型有布爾邏輯模型、向量空間模型、概率模型等.目前通常采用應用較多且效果較好的向量空間模型(Vector Space Model,VSM);另外,由Blei等人[7]提出的LDA主題模型,因其能夠利用隱含主題表示文本,不僅合理降低了特征詞矩陣的維度,還能保持元數據集的全面性,不影響分類性能,也備受人們關注.
1)向量空間模型(VSM)
VSM是由Salton等人提出的,最初用于SMART信息檢索.VSM模型將文檔用向量(t1,w1;t2,w2;···;tn,wn)表示,tk是特征項,一個文檔可以看成是它含有的所有的特征項的集合,wk是特征項的權重,表示它們在文檔中的重要程度.把特征項看作是n維坐標系,權重就是相應的坐標值,那么一個文本就表示為n維空間的一個向量.因此就將非結構化的文本信息轉化到向量空間來表示.
2)LDA主題模型
即潛在狄利克雷分布模型,是一種文檔主題生成模型,也是一種包含詞、主題和文檔三層結構的三層貝葉斯概率模型.LDA是一種非監(jiān)督機器學習技術,主要是針對離散數據集進行建模,通過對語料庫建模可以用來識別大規(guī)模文檔集(document collection)或語料庫(corpus)中潛在的主題信息.它運用詞袋(bag of words)將每一篇文檔視為一個詞頻向量,忽略了詞與詞之間的順序和文檔在語料庫中的順序,這簡化了問題的復雜性,同時也為模型的改進提供了契機.
2.2.2 分類器設計
分類器實際上就是一個映射函數,完成從需要映射的文本到預定義的類別集合的映射關系.常用的分類方法有:樸素的貝葉斯分類法(na?ve Bayesian classifier)、基于支持向量機(Support Vector Machines,SVM)的分類器、K-最近鄰法(K-Nearest Neighbor,KNN)、神經網絡法(Neural Network,NNet)、決策樹(decision tree)分類法等.
(1)樸素貝葉斯分類器
樸素貝葉斯分類器是基于貝葉斯定理與特征條件獨立假設的分類方法[8],是利用特征項和類別的聯合概率來估計給定文檔的類別概率的方法.它假定詞與詞之間是獨立的,這在實際情況中很難保證,因此當假設條件不滿足時,會嚴重影響分類的準確率和性能.根據貝葉斯公式,文檔Doc屬于Ci類的概率如公式(1).
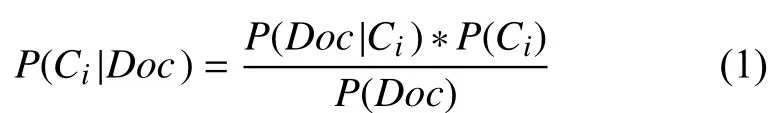
(2)基于支持向量機的分類器
支持向量機在解決小樣本、非線性及高緯模式識別中有許多優(yōu)勢,基于支持向量機的分類方法主要用于解決二元模式分類問題,基本思想是在向量空間中找到一個最優(yōu)超平面,即決策平面(decision surface),而這個平面能夠很好的分割不同類別的數據點,從而達到分類的目的.但是在處理具體分類問題時無法選取正確有效的核函數是它的不足之處,另外,訓練時間與數據集規(guī)模大小有關,訓練時計算量通常比較大,這也會影響分類器的效率.
(3)K-最近鄰法
K-最近鄰法的基本思想是:給定測試文檔和數據類別,系統在訓練集中查找與目標文本相似度最高的k個文本,并根據這些文本來給其候選類別評分.K-最近鄰算法簡單直接,但計算量大,時間復雜度較高,而且訓練樣本質量對分類器性能有著很大影響.
(4)基于神經網絡的分類器
神經網絡(NNet)是目前比較成熟的技術之一,是一種應用類似于大腦神經突觸聯接的結構進行分布式并行信息處理的數學模型.其基本思想是:給每一類文檔建立一個神經網絡,輸入單詞或是特征向量,通過機器學習獲得從輸入到分類的非線性映射.神經網絡分類效果比KNN和SVM較差,而且時間復雜度比較大,實際應用很少.
2.2.3 方法
文本分類技術興起之后,大批專家學者對此進行了研究,提出了一些具有良好效果的分類方法.如Yang等人[9]提出的基于聚類的決策樹方法,用于解決在線文本分類問題;Animashree等人[10]在LDA的基礎上利用統計中的三元或四元模型,通過兩個奇異值分解來訓練文檔中的主題模型,進而實現對文本的分類.Chakraborti等人[11]通過引入關鍵詞,提出了基于LDA和關鍵詞的弱監(jiān)督文本分類算法,也取得了較好的效果.
雖然國內起步較晚,但也取得了不少成果.繼侯漢清教授之后,李榮陸等人[12]提出了基于最大熵模型的文本分類算法,來構建分類器對文本進行分類;尚文倩等人[13]提出了基于基尼指數的新的文本特征算法.這些算法的提出在一定程度上提高了分類性能,推動了文本分類的發(fā)展.
LDA主題模型是一種可以挖掘大型文檔數據集合中潛在主題信息和實現文本信息的分類的概率模型,自從提出以來得到了廣泛的應用,并取得良好效果.應用至今,已有不少專家學者對其進一步的改進,其分類效果得到進一步提升.因此,把LDA主題模型和其他方法相結合得到了廣泛研究,并取得不錯效果.
基于Labeled-LDA(附加類別標簽的LDA)模型的文本分類[2],將類別信息融入傳統LDA模型,進而支持文檔在全部類別的隱含主題上的協同分配,解決了傳統LDA模型用于分類時強制分配隱含主題的缺陷;基于mRMR和LDA主題模型的文本分類[14],預先使用mRMR特征選擇算法將輸入空間映射到低維空間,去除較大不相關信息和重疊信息,使得LDA能夠在更簡潔的文本上建模,從而得到更精確的主題分布;基于詞向量與 LDA 相融合的短文本分類方法[15],能有效克服短文本的主題聚焦性差及特征稀疏性問題,提高短文本分類性能.基于LDA的微博生成模型MRT-LDA[16],利用微博之間的轉發(fā)、對話、支持(贊)和評論等關系來計算微博之間的相關性,綜合考慮微博之間的相關性和同一用戶微博信息間的關系,來輔助對微博的主題進行挖掘.Fu等人[17]針對開放類別文本(文檔類別未知)進行分類,提出了新的基于多重潛在狄利克雷分配模型的分類系統和方法,聚類主題并提取關鍵字幫助分類注釋,最后應用到綜合預測類別.Pavlinek等人[18]提出基于主題模型表示的自訓練半監(jiān)督式文本分類方法,有助于改進文本分類任務,這在許多高級專家和智能系統中是必不可少的.
但是隨著網絡的發(fā)展,文本數量龐大,內容更為復雜,因此上述方法中不可避免會存在一些問題.pLSA模型[19]對文檔中主題的混合權重沒有做任何假設,可能會出現過擬合的現象.sLDA模型[20]為每篇文檔關聯一個代表著該文檔類別標識的變量,然后用EM算法進行最大似然估計,但是該模型只能處理單一類別標識文檔.Labeled-LDA模型[2]在訓練主題模型之前沒有去處停用詞,沒有考慮到詞與其他各類別的關聯問題,并且使用此模型獲得的主題分布傾向于高頻詞,降低了主題的表達能力等;使用最大熵模型進行中文文本分類的研究發(fā)現,基于最大熵模型的分類器穩(wěn)定性比KNN方法要差,使用不同的訓練文檔測試結果相差較大,另外實驗規(guī)模有待擴大;MRT-LDA模型[16]對于微博中的圖片、表情等非文本信息利用不足,微博信息挖掘有待提高.
2.3 應用現狀分析
2.3.1 文本分類
文本分類(text classification)是利用計算機系統對文本按照預定義類別進行劃分的技術.文本分類問題的關鍵技術之一就是文本表示,目前在文本分類應用中較為流行、分類效果較好的就是VSM向量空間模型和LDA主題模型.LDA主題模型是一種無監(jiān)督的全概率生成模型,它本身不能直接判斷文本類別,因此它可以把文檔表示為一系列潛在主題的概率分布,然后選擇一種合適的分類算法構造分類器.LDA主題模型實現了對大規(guī)模文本數據的降維操作,能夠挖掘文本中潛藏的主題信息、分析語義信息.傳統的LDA主題模型在分類過程中可能會存在強制主題分配問題,因此李文波等人[2]提出了Labled-LDA模型,通過引入類別標簽信息,協同計算新文本在各類別隱含主題的分配量,從而克服了傳統LDA主題模型的強制分配問題.另外傳統LDA主題模型沒有考慮詞順序問題,可能會造成詞信息的損失,因此田寶明等人[21]提出了一種基于隨機森林的多視角文本分類方法,利用改進的隨機森林方法結合基于詞的和基于LDA主題的兩種文本表示方法,有效的提高了文本分類性能.吳建軍等人[22]提出的基于互信息的特征項加權樸素貝葉斯算法,部分消除了特征項獨立性和特征項重要性相等假設,提高了樸素貝葉斯算法的分類效果;針對短文本信息,劉澤錦等人[23]提出快速雙詞主題模型,用于解決大規(guī)模短文本語料庫主題模型參數大導致求解慢的問題.
2.3.2 文本聚類
文本聚類(text clustering)是依據相同類別的文檔相似度較大,不同類別的文檔相似度較小的這一聚類假設提出的非監(jiān)督的機器學習方法.文本聚類因為不需要對文本進行訓練和分類標注,所以具有一定的靈活性和自動化處理能力,應用廣泛.針對熱點新聞,對搜索引擎返回的結果,對用戶感興趣的文檔進行聚類處理,并且文本聚類還可以用于改善文本分類結果.對搜索引擎返回的結果進行聚類,有助于用戶快速瀏覽返回的信息,找到滿足自己需要的信息.阮光冊等人[24]將LDA主題模型和k-means算法相結合開展了基于主題模型的檢索結果應用研究,利用LDA模型實現文本潛在語義的識別,用于幫助用戶快速瀏覽系統返回的檢索結果.車蕾等人[25]融合新聞命名實體、新聞標題、新聞重要段落、文本語義等多特征影響,提出基于多特征融合文本聚類的新聞話題發(fā)現模型,并將三種相似度算法最優(yōu)融合,改進了用于新聞話題發(fā)現的Single-Pass算法,有效提高了算法效率,并且具有一定的自適應能力.對于熱點話題,可以先進行聚類分析,然后利用LDA進行建模,把文檔支持率作為話題熱度用于區(qū)分熱點話題和一般話題,方小飛等人[26]依據這些方法提出了基于LDA模型的移動投訴文本熱點話題識別等.
2.3.3 情感挖掘
情感挖掘也是文本分類的研究內容,它是對民眾關于社會中一些現象或是問題的態(tài)度、觀點等的分析,以此可以了解民眾觀點,預測事件走向.例如銷售公司可以利用該技術了解用戶對產品的評價、反饋等,政府部門利用該技術可以分析民眾對政府做出的決策或是管理辦法的評論,可以實時的了解大眾的態(tài)度.因此,這需要情感分析作為支撐.因為人在這過程中并不能完全客觀的進行分析,所以情感分析已經成為情感挖掘的基本技術.此外,該技術還涉及文本挖掘、觀點挖掘等各方面問題.對于網絡中出現的短文本的情感挖掘,以微博為代表,黃發(fā)良等人[27,28]提出了基于社交關系的微博主題情感挖掘和基于多特征融合的微博主題情感挖掘,這兩種方法都用LDA主題模型進行建模,更好的挖掘出用戶性格情緒特征,用于分析微博短文本主題情感特征,把握用戶情感動向.基于在線評論文本,王偉等人[29]構建較完整的情感詞典,依據情感單元搭配模式,構建情感單元,提出了基于LDA評論文本情感分類方法,取得了較好的效果,但缺乏對更復雜句子語境的討論.
另外隨著網絡購物的發(fā)展,用戶對商品評價也越來越多,要從這些評價信息中了解用戶對產品的態(tài)度,就要用到情感挖掘,彭云等人[30]提出了一種基于語義關系約束的主題模型SRC-LDA,用于提取商品特征和從用戶評價中挖掘出用戶情感詞,網絡購物平臺可以以此來很好的改進自己的商品和服務.黃章樹等人[31]對某通信公司投訴文本進行實驗,提出了改進的卡方統計方法,并將其運用到特征選擇,通過降低負相關低頻詞在特征選擇算法中的權重,減小其對模型的影響,實驗表明該方法能更準確的對業(yè)務投訴工單進行分類,進而為通信公司后續(xù)改進服務提供數據支持.
2.3.4 個性化推薦
個性化推薦(personalized recommender)是根據用戶的興趣愛好或是購買特點,推薦用戶感興趣的話題信息或是商品.隨著網絡中信息和商品的大量增加,用戶在瀏覽信息或是選擇商品時往往需要大量的時間和精力.為了使用戶更便捷的使用社交網絡或是購物平臺,個性化推薦系統應運而生.對于一段文本中可能涉及多個主題,而LDA主題模型主要是挖掘文本中潛在主題,得到廣泛應用.高明等人[32]基于LDA主題模型推斷微博的主題分布和用戶的興趣去向,提出了微博系統上用戶感興趣微博的實時推薦方法;但是未考慮用戶興趣隨時間的變化,因此陳杰等人[33]提出了一種基于用戶動態(tài)興趣和社交網絡的微博推薦方法;對于文獻推薦,杜永萍等人[34]提出了一種基于主題效能的學術文獻推薦算法,利用LDA主題模型對候選文獻和用戶發(fā)表的文獻進行建模,挖掘出具有高效能的主題集合,并根據主題分布計算與用戶興趣間的相似度,最后向用戶推薦有價值的文獻.王日芬等人[35]通過全局和學科視角的對比來探究基于LDA主題模型的科學文獻主題識別.
個性化推薦在網絡購物平臺上應用,電商可以根據用戶的瀏覽和購買記錄推薦一些相關的產品,省去了用戶進行大量瀏覽的時間;對于社交平臺,微博、論壇等,可以向用戶推薦一些當前的熱點話題,或是根據用戶平時的瀏覽記錄來推薦用戶可能感興趣的話題.因此崔金棟等人[36]從演化發(fā)展角度對LDA運行機理進行解析,分析研究了微博用戶信息個性化推薦的主題模型LDA演化方向.
2.3.5 網絡安全
隨著網絡的迅速發(fā)展和普及,網絡中信息量太過于龐大,需要對網絡中信息進行內容管理、監(jiān)控和垃圾信息過濾.這時的文本分類已不再是傳統的客觀分類了,這需要分析文本內容的主觀因素,分析作者表達的目的意圖,因此應用到主觀傾向性分類.如何準確的把郵件進行很好的分類,進而處理掉垃圾郵件是文本分類技術的又一應用熱點.張紹成等人[37]利用LDA主題模型對郵件內容進行主題提取,實現郵件分類,提出了代價敏感多主題學習的郵件過濾算法,實現了垃圾郵件過濾.廖曉鋒等人[38]LDA主題模型和SVM支持向量機結合的方法,在主題向量空間構造一個漏洞分類器,以國家信息安全漏洞庫數據進行測試,實驗表明分類準確度比詞匯向量構建的分類器有所提高.
對于網絡安全方面,一般用戶的應用主要是過濾垃圾郵件.對于企業(yè),公司或是軍事領域不僅是要過濾掉垃圾信息,更重要的是要防止病毒的入侵,保障機密文件的安全.
3 存在問題和研究策略
通過對文本分類研究現狀的分析,可以發(fā)現,對于文本分類的研究和分析,有利于對網絡中數量龐大的信息進行有效的管理和分類,方便用戶檢索和瀏覽;有利于分析文本情感傾向,把握用戶情感特征;有利于分析數據安全特性,過濾垃圾信息和監(jiān)管不安全因素.然而,已有的研究在理論和方法層面雖然已經取得了一定的成就,但是目前還存在一些不足,還需進一步完善和提高.
文本分類存在問題和研究策略分析主要圍繞理論體系和方法兩個方面進行.通過對已有的研究進行分析,總結出文本分類目前存在的一些問題和相應的研究策略.
(1)理論層面
自然語言處理涉及詞法、語法、語義、和語用學等多個層次,實際上關鍵問題就是歧義消解和未知語言現象的處理問題.文本分類的理論研究在國外已經取得重大突破,趨于完善,但是我國中文文本分類涉及內容較多,分類比較困難.在漢語中,存在同義詞,一詞多義的問題,而且一個詞可有不同詞性,理解詞義還需結合上下文語境,因此給文本分類帶來很大困難.另外,還存在一些數學模型不夠奏效和算法復雜度過高等理論問題.例如,文本分類需要處理的數據一般是成千上萬的稀疏矩陣,矩陣維數過于巨大,因此需要有效的降維操作;文本的特征詞中存在多義詞、同義詞現象,還包含大量的噪音,因此要形成有效的特征矢量;文本分類在小量數據中應用較好,但實際應用中數據量是非常巨大的,因此需要研究大規(guī)模文本.另外在知識資源方面也存在一些問題,例如,數據資源匱乏、覆蓋率低、知識表示困難等.
近幾年來,中文文本分類研究發(fā)展迅速,一大批專家學者進行了分析研究,并且提出了很多切實可行的改善理論和方法.基于統計機器學習的文本分類方法在準確率和穩(wěn)定性方面具有明顯優(yōu)勢,日益受到重用.目前文本表示、特征選擇和分類方法眾多,性能評測指標也愈發(fā)成熟.文本分類的應用也更加廣闊,深入到人們的日常生活,例如社交網絡評價,輿情分析,情感挖掘,個性化推薦等.
(2)方法層面
常用的文本表示方法詞向量空間模型,存在向量空間維度過高,詞項之間缺乏語義關系等問題.因此有國外學者提出語義向量空間模型,嘗試利用潛在語義索引技術或本體的概念語義關系挖掘詞項之間的語義關系,構建低維的語義向量空間模型.
通過對面向LDA主題模型的文本分類研究進展與趨勢的分析,可以發(fā)現,應用LDA主題模型于文本分類,有利于處理大規(guī)模文本,不僅合理地降低了特征詞矩陣的維度,還能保持原數據集的全面性,不影響分類器性能,解決了傳統文本分類中相似性度量和主題單一性問題.然而,盡管LDA主題模型得到進一步改進和完善,但還尚有一定缺陷和不足.LDA是非監(jiān)督學習模型,不能直接用于文本分類,因此必須嵌入到合適的分類算法中.傳統的LDA主題模型存在分類過程中將文檔強制在單個類別上分配隱含主題的缺陷;并且由于實際情況中大規(guī)模的數據,可能會出現主題范圍過大,不能對主題單詞的潛在語義進行準確定位,限制了模型的魯棒性和有效性;沒有考慮詞序問題,是典型的詞袋模型等.
另外在分類器設計方面,樸素的貝葉斯分類法假定詞與詞之間是獨立的,這在實際情況中很難保證,因此當假設條件不滿足時,會嚴重影響分類的準確率和性能.基于支持向量機的分類器在處理具體分類問題時無法選取正確有效的核函數,另外,訓練時間與數據集規(guī)模大小有關,訓練時計算量通常比較大,這也會影響分類器的效率.k-最近鄰法計算量大,時間復雜度較高,而且訓練樣本質量對分類器性能有著很大影響.神經網絡法分類效果比kNN和SVM較差,而且時間復雜度比較大.
針對這些問題,多種方法的融合、改進可以改善分類效果.特征選擇和特征重構是降維操作的關鍵技術,二者融合有助于改善降維效果.例如把互信息和聚類融合,通過互信息最大化從原始特征空間中選擇次優(yōu)特征子集,借助特征空間的聚類來剔除冗余特征,從而實現特征空間的再次降維.把多種分類算法相融合,利用它們的優(yōu)點,剔除缺點,從而可以改善分類性能.例如LDA分別與卡方統計、互信息和信息增益進行結合,利用改進后的特征提取方法提取特征詞,實驗表明結合后的方法比原來的方法分類效果好;另外隨著特征詞個數的增多,每一種方法的分類性能也有提高.
4 發(fā)展趨勢
根據目前國內外已有的研究成果和存在問題來看,文本分類已經成為自然語言處理領域的研究熱點和重點,雖然在理論體系和技術層面還不夠完善,但其重要性已經逐步展現出來,引起了研究者的重視.基于此,本文總結歸納出了文本分類未來的一些研究方向,供讀者參考.
(1)文本分類在對話系統中的應用
人機對話系統有智能聊天、知識問答、任務執(zhí)行和信息推薦等四個方面的內容.當前的主要任務就是研究如何能夠讓對話系統更自然,具備人一樣的情感,如何能夠在場景化任務執(zhí)行中做到高效的場景切換.
聊天機器人不僅要理解人類語言,而且還要感知用戶情緒變化,分析用戶情感特征,實現和用戶的交流.通過對大規(guī)模聊天語料的標注,訓練和對上下文語境信息的分析,從而進行分類,得到對話模型,計算機可以生成表達不同情緒類別的內容來與人進行對話.如微軟的小冰.以后聊天機器人不僅要能夠通過文字、語音、表情、動作等識別情感情緒信息,還要進化到道德、精神層面的高級情感,進行更深層次的自主學習.
對話系統中個性化推薦在很多領域都有廣泛的應用,如電商購物、社交網絡、新聞資訊等.在以后的發(fā)展中旨在提高推薦的精準度和更加個性化,提高用戶的滿意度.
(2)文本分類在人工智能知識服務體系中的應用
人工智能知識服務體系就是把分散于個人的知識技能集中起來,實現知識共享,把人工智能涉及的技術和領域知識組織起來,讓計算機能夠像專家一樣,輔助決策,成為綜合知識集合,結合人工智能的體系框架、技術方法,以及涉及到的眾多知識學科和應用領域,將各種顯性和隱性知識按照需求進行提煉,從而解決用戶需求的過程.那么如何獲取如此龐大的知識,并且進行分析整合,最后反饋給用戶呢?可以使用機器學習,包括文本分析、自然語言理解、計算機視覺和數據挖掘等技術,向用戶智能推送.這需要持續(xù)累積大量的訓練樣本和數據,讓機器學習系統不斷地學習,改善和進化.
在信息流的場景中,人們可以更便捷的獲得更多的標注數據和顆粒度更細的標注,用于幫助自然語言理解和自然語言生成等.語義化的進一步研究,使得人工智能能夠處理、分析、挖掘和理解信息流里的每一個環(huán)節(jié),可以利用這一技術進行知識的獲取、分析和整合,然后把內容反饋給用戶.以此讓人工智能更多元,更智慧的為人們服務,例如幫助用戶進行內容的創(chuàng)作,幫助消費,以及機器閱讀等.
(3)文本分類在文化遺產數字化與數字人文中的應用
對于種類龐雜,信息總量龐大的文化遺傳的采集,可以把多源數據融合、自動紋理映射和影像建模等技術結合將大規(guī)模、高精度文化遺產數字化,利用文本分類技術對信息進行分類、整理為不同類別,建立檔案庫.然后采用虛擬現實和數字動畫技術,建立虛擬的數字博物館,對文化遺產的現象、場景和過程進行復原或再現.以此做到更好的保證文化遺產數字化檔案質量和客觀性.
利用VR(虛擬現實)和AR(增強現實)技術對文化遺產進行保護,實現人機交互.例如,可以通過VR技術進行對非物質文化遺傳進行全方位的展現,可以通過人機交互了解文化遺傳的演變與發(fā)展等.利用AR技術將現實文化遺產增加一層虛擬維度,通過復原再現、展示傳播等賦予文化遺產鮮活的生命,具有很高的互動性和參與性.
(4)文本分類在突發(fā)事件監(jiān)測中的應用
我國每年突發(fā)事件頻發(fā),交通事故、火災等不計其數.如何對這些突發(fā)事件進行監(jiān)測,并實施有效的救援,這是一個難題.現在網絡技術發(fā)達,其實可以把網絡信息進行詳細分類,針對網絡中出現的信息進行分析、挖掘,過濾出敏感詞匯,如地震,失火,車輛相撞,追尾等,分析出可能發(fā)生的隱患事件和對已經發(fā)生的事件進行追蹤,從而實施有效的預防和救援措施,保障人們的生命財產安全.應用于公安系統可以預防犯罪發(fā)生和快速破案.也可應用于軍隊,對我國領海、領土、領空進行監(jiān)測,一旦發(fā)現事故發(fā)生或是外部入侵,可以及時采取有效措施,保障我國國民和領域安全.
(5)文本分類在智慧醫(yī)療系統中的應用
我國人口眾多,排隊看病是一個難題,病人流量太大,醫(yī)院環(huán)境嘈雜,可能會影響病人描述病情和醫(yī)生進行更有效診斷.因此,將文本分類和信息抽取應用于醫(yī)療健康系統,將用戶輸入的咨詢信息進行分類和整理,提取出用戶的病癥信息,然后根據處理后的病癥內容進行分類,診斷出可能的病癥名稱,然后推送給不同的科室醫(yī)生進行在線回復,還可以根據分析出的病情推薦合理的看病科室.將文本分類應用于醫(yī)療健康后,病人可以更方便的對自己的病情進行咨詢和就診,醫(yī)生也可以根據這些信息對病人病情進行更好、更快捷的診斷.這不僅對病人、醫(yī)生,還是醫(yī)院都提供了有利的條件,因此可以在這方面進行更深一步的研究.
5 總結
文本分類是自然語言處理的熱點研究內容之一.文本分類的研究和分析,有助于對網絡中數量龐大的信息進行有效的管理和分類,方便用戶檢索和瀏覽;有助于分析文本情感傾向,把握用戶情感特征,對于商家可以據此提高產品質量,提升服務水平;有助于分析數據安全特性,過濾垃圾信息和監(jiān)管不安全因素,政府、高校、公司等可以據此來提高部門數據安全,防止不利或是有害信息傳播,并為自然語言處理的應用提供有力的支持.然而,已有的研究在理論和方法層面雖然已經取得了一定的成就,但是文本分類研究涉及內容、領域和技術等多個方面,各學科研究錯綜復雜,因此還有很多缺陷和不足,需要進一步進行系統和深入的研究.
本文針對文本分類這一研究內容,探討了文本分類和LDA主題模型的相關理論;然后,從技術、方法和應用三個方面分析了面向LDA主題模型的文本分類的研究現狀;總結了目前研究中存在的一些問題和研究策略;最后,展望了文本分類未來的一些發(fā)展趨勢.
文本分類的最終目的還是為自然語言處理服務,因此,可以將文本分類的研究成果應用到信息檢索、信息抽取、輿情分析和個性化推薦、網絡安全等研究中,以期取得更好性能.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
