IPI:靈活高效的對象代理數據庫索引結構*
2018-08-15 08:24:08李宇珺彭智勇彭煜瑋
計算機與生活 2018年8期
關鍵詞:數據庫
李宇珺,彭智勇,吳 瑕,蘭 海,彭煜瑋
武漢大學 計算機學院,武漢 430072
1 引言
面向對象模型解決了傳統關系模型難以建模復雜數據的問題,但對象的封裝性使得其對象難以分割和重組,從而不具有關系模型的柔軟性。針對上述問題,對象代理模型(object deputy model,ODM)應運而生[1],它兼具關系模型的柔軟性和面向對象模型的建模能力。近年來,ODM被廣泛應用于數據倉庫[2]、生物數據管理[3]、地理信息系統[4]、科學工作流[5]和不確定數據管理[6]等領域。對象代理數據庫(object deputy database,ODDB)管理系統圖騰[7](Totem)已基于ODM開發完成。它在繼承了面向對象數據庫諸多優點(如直接建模復雜對象等)的基礎上,使用代理對象增強了對象的柔軟性,允許對已有對象進行分解、組合和擴充,比面向對象數據庫具有更柔軟的建模能力。
ODDB中的每個對象和其每一個源對象或代理對象都被一個雙向指針鏈接在一起,這類指針稱為雙向指針。跨類查詢作為ODDB的主要查詢功能之一,是指基于對象間的雙向指針鏈接,從某個類的對象出發,沿著類路徑到達另一個與其存在直接或間接代理關系的類,并對該類中關聯對象進行的查詢。跨類查詢是由路徑表達式(path expression,PE)實現的[8],因此優化PE的計算效率對提升ODDB的性能有重大影響。
本文針對ODDB的PE計算提出了一種索引結構——倒排路徑索引(inverted path index,IPI),并基于IPI設計實現了計算PE的方法。IPI的核心思想是物化對象間的代理關系,并允許在謂詞條件上建立索引以過濾不滿足條件的對象。基于IPI的PE計算方法,能靈活用于任意PE,同時避免計算中冗余的對象遍歷,有效地減少PE的計算開銷。總體來說,本文的主要貢獻如下:(1)提出一種新的針對ODDB的索引結構(IPI),支持任意路徑/帶謂詞條件的PE計算,以極小的效率代價為跨類查詢提供更多的靈活性。(2)提出使用IPI計算PE的IPI索引方法以及維護IPI的方法。(3)通過實驗證明了所提出的IPI索引方法的有效性。
本文組織結構如下:第2章介紹相關工作;第3章給出ODDB中PE的基礎知識;第4章介紹倒排路徑索引IPI,并提出使用IPI計算PE的IPI索引方法以及維護IPI的方法;第5章討論IPI的靈活性;第6章通過實驗證明提出的IPI索引方法的有效性;第7章進行總結和展望。
2 相關工作
ODDB中由對象間的代理關系構成的網狀結構可以比作一個圖。圖數據庫具有管理超大規模圖的能力[9],故其可達性問題為PE計算提供了一種解決方案。文獻[10]提出Tree-Based索引來解決帶標簽圖的可達性問題。文獻[11]提出Top-Chain來解決時序圖的可達性問題。然而,PE計算和圖數據庫的可達性問題之間存在一個本質的區別:前者是在一個非常大的圖中確定兩個結點之間是否存在由邊組成的路徑;后者則意味著在許多由對象構成的小圖中迭代解決可達性問題。因此,解決圖數據庫可達性問題的方法并不適用于ODDB的PE計算。
PE的概念并不是ODDB所特有,早在XML(extensible markup language)中它就已經存在,用于訪問XML的嵌套文檔結構。目前XML針對PE計算的基本索引方法有:路徑分解法[12]和樹遍歷法[13]。路徑分解法將復雜PE分解為簡單PE依次進行計算,再把計算結果連接起來,核心思想是分解再連接。由于ODDB中PE各層的連接關系包含了雙方對象實例間的所有代理關系,連接的代價過大,路徑分解法的思想并不適用于ODDB的PE計算。樹遍歷法則采用自頂向下或自底向上的方式遍歷文檔樹,該方法需要遍歷某元素通往葉子節點的所有路徑,其思想類似于ODDB的指針跟蹤算法(pointer tracker,PT)[14-15]。
PT是計算ODDB中PE的基本方法:首先沿著PE的導航路徑進行對象遍歷,檢索滿足PE各層所定義謂詞條件的路徑實例,然后獲取這些實例上的終點對象,最后由PE的目標表達式投影運算得出結果。顯然,對象遍歷是計算中最耗時的部分,它需要遍歷起點類通往終點類的所有路徑實例,頻繁的I/O操作降低了計算效率。目前針對ODDB中PE計算的優化方法還比較少。文獻[14]提出的對象代理路徑索引(object deputy path index,ODPI)針對特定的路徑建立索引,存儲滿足該路徑的所有路徑實例,減少了對象遍歷的時間,但它不適用于中間類帶謂詞條件的PE。路徑導航索引(path navigation index,PNI)[15]解決了該問題,它基于物化的路徑實例提供了關聯檢索,以支持帶謂詞條件的PE計算。然而,由于每個ODPI/PNI索引都僅服務于其對應的固定路徑,計算時缺乏靈活性。若待查詢PE所依賴的路徑上沒有建立索引,那ODPI/PNI索引對計算是無效的,此時只能用PT方法(即不使用索引)來計算該PE。
針對上述問題,本文提出的倒排路徑索引,物化了對象間的代理關系,不僅可以靈活用于任意PE,還能有效減少計算開銷。
3 基本概念
ODM的基本概念包括源類、代理類、源對象和代理對象等,首先簡單描述這些概念,其詳細定義參見文獻[1],并在此基礎上給出ODDB中PE的相關定義和符號表。
在面向對象模型中,所有真實世界的實體都被抽象為一個對象(Object),具有相同屬性的對象構成一個類(Class)。在邏輯層面,對象和類類似于關系數據模型中的元組和表,ODM同樣具有對象和類的概念。在ODM中,不存在父類的類稱為源類,其包含的對象稱為源對象;而存在父類的類則稱為代理類,它的對象實例稱為代理對象。
定義1(直接/間接代理關系)對任意兩個類Ci和Cj(i<j),若Ci是Cj的源類或代理類,則Ci和Cj之間存在直接代理關系。給定一系列類{Ci,Ci+1,…,Cj-1,Cj},若對任意k∈[i,j)都滿足Ck和Ck+1之間存在直接代理關系,則Ci和Cj之間存在間接代理關系。同理可得對象間的直接/間接代理關系。
定義2(類網/對象網)由類之間的代理關系構成的網狀結構稱為類網。其中節點表示類,邊表示兩個節點間的直接代理關系。同理,由對象之間的代理關系構成的網狀結構稱為對象網。
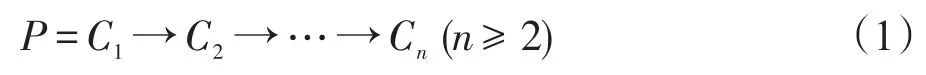
定義3(路徑)給定類網CN,式(1)中的路徑P是類網CN的一條路徑,當且僅當:(1)Ci∈CN(1≤i≤n);(2)對任意i∈[1,n)都滿足Ci和Ci+1之間存在直接代理關系。其中C1和Cn分別指起點類和終點類,路徑P中的其他類則指中間類。
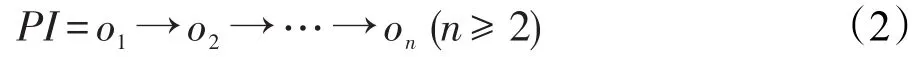
定義4(路徑實例)給定式(1)的路徑P,式(2)中的由n個對象組成的對象序列PI稱為P的一個實例,當且僅當:(1)oi是Ci的一個實例 (1≤i≤n);(2)oi與oi+1之間存在直接代理關系 (1≤i<n)。其中o1為起點對象,on為終點對象。
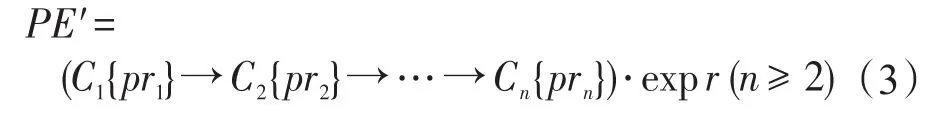
定義5(PE)給定式(1)的路徑P,式(3)中的PE′是在P上定義的PE當且僅當:(1)pri是定義在Ci上的謂詞條件(pri可為空,1≤i≤n);(2)expr是由Cn的屬性和常量通過算術或邏輯運算符組成的表達式。其中C1{pr1}→C2{pr2}→…→Cn{prn}稱為PE′的導航路徑,expr則稱為PE的目標表達式。
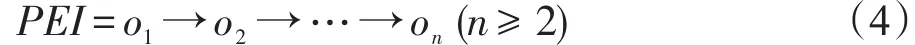
定義6(PE實例)給定式(3)的PE′,式(4)中的由n個對象組成的對象序列PEI稱為PE′的一個實例當且僅當:(1)oi是Ci的一個實例 (1≤i≤n);(2)oi與oi+1之間存在直接代理關系 (1≤i<n);(3)oi滿足定義于Ci上的pri(1≤i≤n)。
定義7(跨類查詢)給定式(3)的PE′,針對PE′的跨類查詢表示從起點類C1的對象出發,沿著PE′的導航路徑到達終點類Cn,對PE′所有PE實例的終點對象進行查詢。
圖1給出了一個教學管理數據庫的模式,由上述定義可知該數據庫模式是一個類網,而Course→Cou_Stu→Student是該類網上的一條路徑,(Course{cid=“1”}→Cou_Stu→Student).sid是定義在該路徑上的一個PE,其中Course是起點類,Student是終點類,{cid=“1”}是定義在Student類上的謂詞條件。
表1總結了幾個本文經常出現的符號和術語。
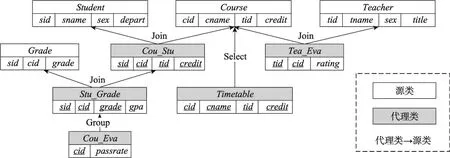
Fig.1 Schema of teaching management database圖1 教學管理數據庫模式
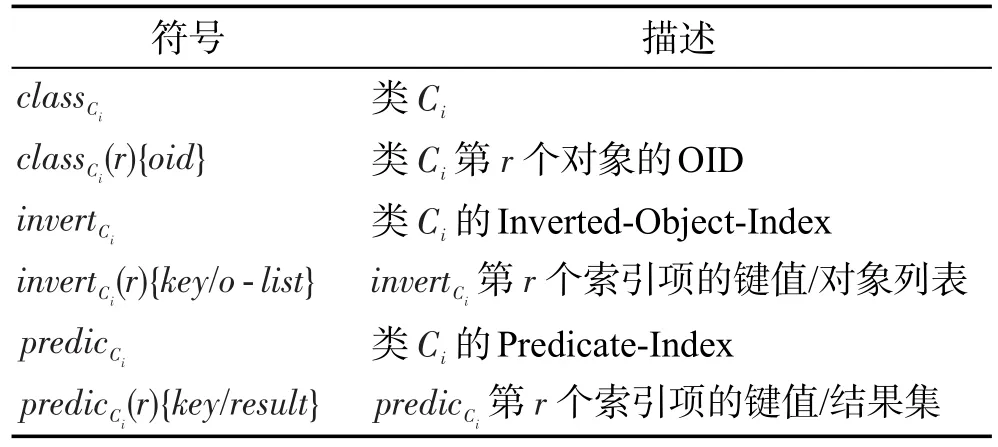
Table 1 Symbol table表1 符號表
4 倒排路徑索引IPI
本章介紹一種靈活高效的索引結構——倒排路徑索引(IPI)。IPI建立在類之上,由Inverted-Object-Index和Predicate-Index組成。前者存儲對象間的代理關系;后者則輔助它計算定義于該類的謂詞條件。IPI支持任意路徑和帶謂詞條件的PE計算,并能有效減少計算開銷。
4.1 索引的結構
對于一個類網中的每個類,Inverted-Object-Index基于對象間的雙向指針使用倒排索引來存儲與該類關聯的所有代理關系,其每個索引項對應該類的一個對象,映射所有與之存在直接或間接代理關系的對象。每個代理關系對應一個路徑實例,因為ODM中對象間的代理關系不能出現環[16],同一對象網中的任意兩個對象間有且僅有一條路徑連通。因此,Inverted-Object-Index存儲的每條路徑實例的終點對象可以唯一地標識該路徑實例。
Inverted-Object-Index是一個存儲(key,object list)對集合的索引結構,其中“key”是鍵值,由對象的唯一標識符(OID)表示,而“object list”(對象列表)是一組與“key”存在直接或間接代理關系的對象,每個對象由“所屬類的OID:對象OID”表示。如圖2所示,Inverted-Object-Index包含一個構建在“key”上的BTree索引(Key Tree),其內部節點與普通B-Tree索引一樣,而葉子節點中索引項的指針則指向“ObjectList”或“Object Tree”的根頁面。若某個“key”的與之存在代理關系的對象數目較多,則在其對象列表(即“object list”)上創建一個B-Tree結構(Object Tree)以加快查找速度。
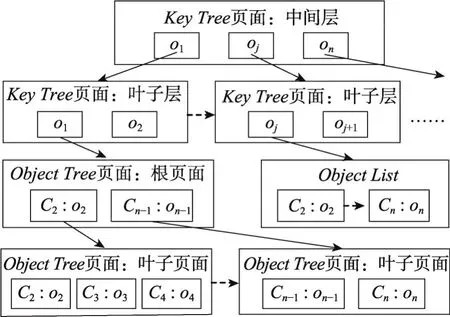
Fig.2 Index structure of Inverted-Object-Index圖2 Inverted-Object-Index的索引結構
第2章提到PT方法在對象遍歷時,對每個對象都要進行兩步操作:(1)判斷是否匹配路徑;(2)判斷是否滿足定義于該類的謂詞條件。通過Inverted-Object-Index,能快速找到該類中匹配路徑的對象實例,并獲取其所在的路徑實例上的終點對象,但無法判斷這些路徑實例是否滿足可能定義于PE的謂詞條件。Predicate-Index是針對謂詞條件計算設計的索引,它通過OID將滿足謂詞條件的對象映射到Inverted-Object-Index的“key”上,輔助Inverted-Object-Index過濾不滿足條件的對象。Predicate-Index是一個存儲(predicate,result)對集合的索引結構,其中鍵值“predi?cate”表示謂詞條件,而“result”(結果集)是一組滿足“predicate”的對象。Predicate-Index包含一個構建在“predicate”上的B-Tree索引,葉子節點的索引項指針指向對應結果集(即“result”)。
4.2 索引的創建
算法1和算法2描述了IPI創建的過程,包括Inverted-Object-Index和Predicate-Index。
算法1Inverted-Object-Index的創建

算法1描述了Inverted-Object-Index的創建過程,目標類的每個對象對應其一個索引項,包括鍵值和對象列表。需要順序掃描目標類的對象,對每個對象進行如下操作(第2到3行代碼):根據OID填充鍵值,再把所有與鍵值存在代理關系的對象以“類OID:對象OID”的形式存入對象列表。目標類掃描完畢后,其Inverted-Object-Index也創建完成。
算法2Predicate-Index的創建

算法2描述了Predicate-Index中一個索引項的創建過程,每個謂詞條件對應一個索引項,包括鍵值和結果集。第2行代碼根據謂詞條件填充鍵值。結果集包含所有滿足鍵值的對象,需要順序掃描目標類的對象把滿足條件的OID存入結果集(第3到7行代碼)。Predicate-Index沒有規定行數,可為空,按查詢需求把頻繁查詢的謂詞條件創建完畢即可。
4.3 索引的使用
創建完IPI索引,接下來介紹使用該索引計算PE的IPI索引方法。對于一個給定PE,使用IPI計算的流程按如下步驟進行:
(1)進行謂詞條件檢查和PE劃分。首先需要判斷PE是否帶謂詞條件。如果PE帶謂詞條件,就把PE按謂詞條件所在類進行劃分;否則就直接在起點類的Inverted-Object-Index中進行路徑匹配。
(2)謂詞條件計算。為了計算定義于某特定類Ci的謂詞條件pred,首先需要在predicCi中掃描pred,若找到了,就把對應的結果集保存在該類的一個臨時的謂詞條件結果集prCi();否則,需要重新掃描classCi,把滿足pred的對象OID加入prCi()。
(3)路徑匹配。若PE帶謂詞條件,就依次從prCi()中獲取OID,分別找到它們在invertCi中對應的索引項。對每個索引項,判斷其對象列表中是否包括了PE的所有類,若是則說明該索引項能夠匹配路徑,獲取對象列表中終點對象OID,加入該類的一個臨時的終點對象集resCi()。若PE不帶謂詞條件,則順序掃描起點類的Inverted-Object-Index,對其每個索引項的操作和帶謂詞條件的情況相同。
(4)合并結果。若PE帶謂詞條件,取所有非空resCi()(1≤i≤n)的交集為最終終點對象集;否則起點類終點對象集resC1()即最終終點對象集。
(5)根據目標表達式對最終終點對象集進行投影運算得到并返回結果對象。
4.4 索引的維護
IPI和傳統索引一樣依賴于數據庫建立。若數據庫被修改,IPI也需要被維護。數據庫可能的修改包括:創建對象和類,刪除對象和類以及修改對象的屬性值。由于創建/刪除一個類相當于插入/刪除該類包含的多個對象,本節主要介紹針對插入/刪除對象操作和修改對象屬性值操作的IPI索引維護。為方便討論維護時間的復雜度,假設invertCi的平均索引項數目為n,predicCi的平均索引項數目為m,m<<n。
(1)插入/刪除對象。當一個對象oi被插入/刪除需要維護3處:①在invertCi中添加/刪除記錄oi;②在predicCi中找到oi所滿足的謂詞條件,分別在對應結果集中添加/刪除記錄oi;③對所有與oi存在代理關系的對象(假設數目為常數k),在其各自Inverted-Object-Index對應索引項的對象列表中添加/刪除記錄oi。其中,①相當于在invertCi二叉樹中查找目標對象,平均維護時間為lbn+1;②相當于順序查找不定量的謂詞條件,平均維護時間為m+m/2;③同①,相當于在k個二叉樹中分別查找目標對象,平均維護時間為k×(lbn+1)。綜上該操作的維護時間如式(5)所示,時間復雜度為O(lbn)。
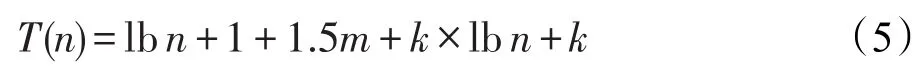
(2)修改對象的屬性值。對象屬性值的修改不改變對象間的雙向指針,因此invertCi不需要被維護。當一個對象oi的屬性值被修改可能導致兩種情況:①一個對象修改前不滿足某謂詞條件但修改后滿足;②一個對象修改前滿足某謂詞條件但修改后不滿足。它們都會影響predicCi,具體維護操作如下:首先在predicCi中掃描定義于該屬性的謂詞條件,重新判斷oi是否滿足這些謂詞條件,然后根據判斷結果在它們的結果集中添加/刪除oi的記錄。同(1)操作中的②,該操作的維護時間T(n)=1.5m,時間復雜度為O(1)。
插入/刪除對象的操作需維護同一類網中大多類的Inverted-Object-Index和被修改類的Predicate-Index;而修改對象屬性值的操作也需要維護被修改類的Predicate-Index。執行多次的單步維護操作可能導致冗余維護,降低了維護效率。因此,設計了op_update(表2)和op_maintain(表3)兩個系統表來支持批量維護操作。系統表op_update存儲對數據庫的修改操作,op_maintain存儲由修改操作轉換而成的針對各個類的維護指令。批量維護操作并不是當數據庫被修改一次就立即維護IPI,而是將修改操作存入系統表op_update中,當操作數超過一定閾值或所有修改操作都已讀入時,就根據緩存的修改操作來維護IPI,具體維護步驟如下:
首先,對系統表op_update中所有操作進行抵消和合并,該功能由記錄修改操作執行時間的time來支持:(1)若一個插入操作和一個刪除操作作用于同一對象,且前者執行時間比后者早,即插入一個對象后再將它刪除,那么這兩個操作的作用會相互抵消。在該情況下,這兩個操作會被清除。(2)若有兩個或兩個以上的屬性值修改操作對同一對象的同一屬性先后進行修改,那么執行時間最晚的一個修改操作就會覆蓋先前的。在該情況下,這些修改操作會被合并為時間最新的一條屬性值修改操作。

Table 2 Attributes of op_update表2 系統表op_update的屬性
接下來,把系統表op_update中的操作轉換成以類為單位的維護指令,填充到系統表op_maintain中。如表3所示,opindex決定具體要對哪部分索引進行維護。若optype為3,則opindex只能取2,因屬性值修改時不需要維護Inverted-Object-Index,此時position表示被修改屬性的列號,value表示修改后的屬性值。屬性position的另一作用是當optype為1或2,opindex為1時,表示維護操作作用的對象,分為兩種情況:(1)position等于opoid,即維護的是被修改對象本身,相當于插入/刪除對象時維護的第i點。(2)position表示所屬于classoid并且與opoid存在代理關系的對象,相當于插入/刪除對象時維護的第③點。在第(1)種情況中,構建插入對象在Inverted-Object-Index的索引項時需要對象列表的信息,由表3的value屬性給出:如果opoid有源對象,value值就是其源對象的OID與源對象的對象列表的并集;否則,value值為空。
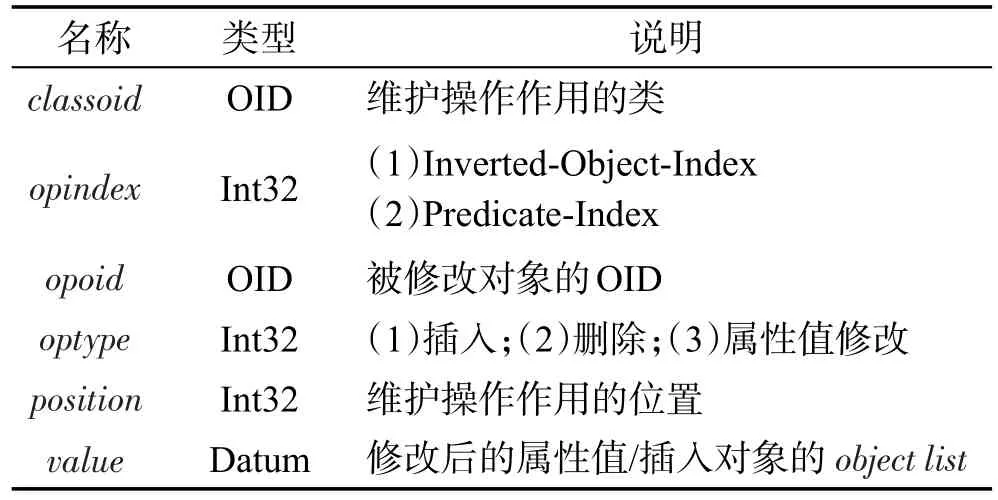
Table 3 Attributes of op_maintain表3 系統表op_maintain的屬性
最后,根據屬性classoid把系統表op_maintain中的維護指令劃分到對應類,逐個類進行索引維護。當op_maintain系統表中的所有維護指令執行完畢,一次批量維護操作也就完成了。
5 IPI的靈活性討論
第2章提到目前針對ODDB中PE的索引結構(ODPI[14]、PNI[15])都存在一個嚴重問題,即缺乏靈活性。由于ODPI的核心思想與PNI類似,且謂詞條件計算受限制,因此本文沒有把ODPI作為對比索引(下同)。本文通過對比IPI和PNI從以下兩方面來說明IPI在靈活性方面的優勢:
(1)使用IPI能以較少的索引支持更全面的路徑覆蓋。假設一個類網有n個類,就有n×(n-1)條路徑。由于正逆路徑共用同一個PNI,覆蓋全部路徑需要n×(n-1)/2個PNI;而對于IPI,覆蓋全部路徑只需要對每個類建立索引,即n個IPI。顯然,O(n)在復雜度上遠小于O(n2)。如果PNI僅建立和IPI同樣數目的索引,即只對n條路徑建立PNI,那么此時PNI的路徑覆蓋率如式(6)所示。隨著n的增加,其路徑覆蓋率會越來越小。因此,在大多情況下,需要更多的PNI才能維持和IPI同樣的需求,并且類網的數據規模越大,IPI的優勢越明顯。
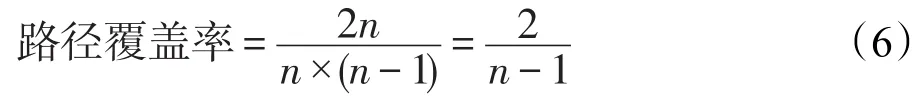
(2)使用IPI能更好地適應需求變化。以圖1的教學管理數據庫模式為例,假設使用者是學生,可能的查詢需求有:查詢課程信息,查詢自己某門課程的績點等等,分別對應如下的路徑:Student→Cou_Stu→Course,Student→Cou_Stu→Stu_Grade。要維持此時的需求,可以對每個類建立IPI或對每條頻繁查詢的路徑建立PNI。若以后該數據庫的使用者變為教師,查詢需求則可能有:查詢課程信息,查詢自己的職稱等,分別對應如下的路徑:Teacher→Tea_Eva→Course,Teacher→Tea_Eva。此時原先建立的PNI對新的查詢無效,而IPI索引方法則可以提供任意路徑的查詢。當然上述例子也許過于極端,但能說明PNI難以適應需求變化的問題。
綜上,由于一個類網中類的數目遠小于路徑數,IPI對每個類建就能覆蓋全部路徑,并能適應應用需求的變化。與PNI相比,IPI能以更少的索引數量滿足需求,對需求變化的適應性也更好。
6 實驗
本文把IPI索引方法分別與PT[14-15](即不使用索引)和PNI[15]索引方法進行對比。通過實驗證明IPI索引方法的有效性。所有實驗都在ODDB系統Totem[7]中完成。
實驗使用的測試環境是一臺PC機,其配置如下:Intel?CoreTMi5-2320 3.0 GHz CPU,4 GB內存容量,500 GB硬盤,Ubuntu 16.04操作系統,Totem 2.0數據庫系統。實驗采用一個教學管理數據庫為測試數據庫(數據庫模式如圖1所示),不同規模的數據集(DS1~DS6,表4)為測試數據集。在表4中,每個單元格的數據表示不同數據集中每個類的對象數目。
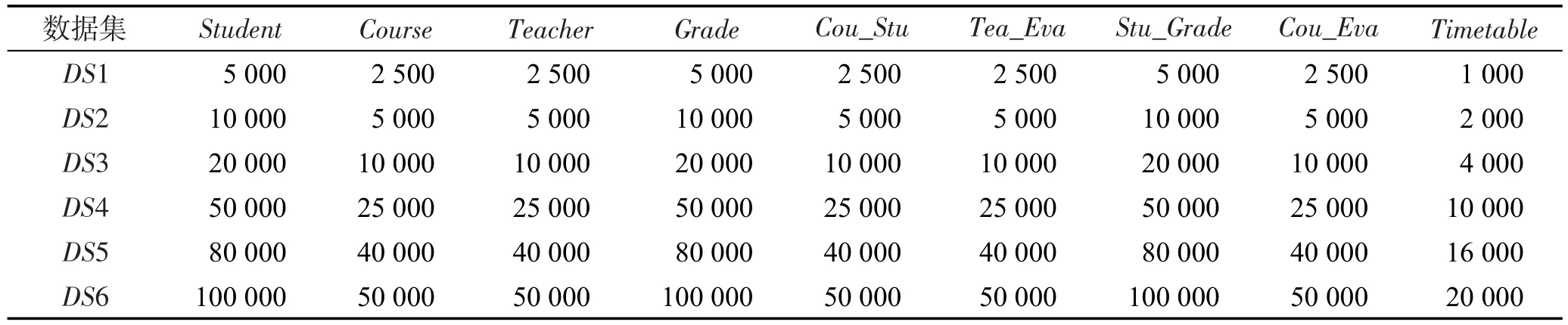
Table 4 Test data sets表4 測試數據集
實驗結果表明使用IPI得到的結果和不使用索引的完全相同,即IPI的有效性得到證明。下面實驗將分析路徑長度和謂詞條件對計算效率的影響,以及IPI創建時間和存儲空間的影響因素,并討論索引維護時間、效率以及靈活性之間的權衡。
6.1 路徑長度對PE計算的影響
第一組實驗在不考慮謂詞條件的情況下,分別以路徑長度為3和5的PE為測試用例,測試不同數據規模下各個方法的執行時間。由圖3可以看出,3種方法的執行時間都是隨著路徑長度的增加而增長。它們在計算過程中都依賴于路徑:IPI需要判斷是否匹配路徑中的所有類;PT是沿著路徑依次獲取每個類滿足條件的對象實例;PNI則是直接建立于固定的路徑上。整體實驗結果表明,3種方法中PT效率最差,這是因為它需要不斷存取中間路徑上的對象實例,頻繁的I/O操作導致總的時間開銷較大。IPI的效率比PNI略差一些,因為IPI在獲取終點對象前比PNI多一步操作,即判斷對象是否匹配路徑。但該操作消耗的時間占整個計算時間的比重很小,因此二者的效率相差無幾。
6.2 謂詞條件對PE計算的影響
第二組實驗在不考慮路徑長度的情況下,分別以帶1個和2個謂詞條件的PE為測試用例,測試不同數據規模下各方法的執行時間。由圖4可以看出,IPI和PNI的執行時間隨謂詞條件數目的增加而增長,而PT則無明顯變化。因為PT是在遍歷路徑的同時判斷謂詞條件。一旦發現對象實例不滿足謂詞條件,就會提前中止該趟計算流程,因此更多的謂詞條件對PT的執行時間影響不大,反而可能節省一些不必要的對象遍歷時間。與之相反,IPI和PNI索引方法都以謂詞條件為單位進行計算,因此謂詞條件的數目和它們的執行時間成正比。
6.3 IPI索引的創建時間
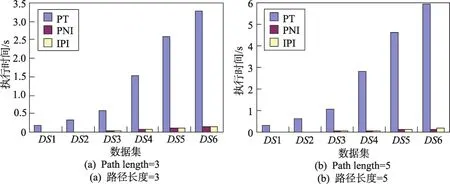
Fig.3 Influence of path length on PE evaluation圖3 路徑長度對PE計算的影響
第三組實驗以教學管理數據庫模式(圖1)的Student類為例,得到不同數據規模下Student類的IPI創建時間(Inverted-Object-Index和Predicate-Index)。由圖5可以看出,Inverted-Object-Index和Predicate-Index的創建時間隨著數據規模的增大而增長。二者在創建過程中都需要掃描其所在類的對象,數據規模越大,創建時間也越長。此外,因為Predicate-Index的每個索引項對應一個謂詞條件,所以謂詞條件的數目是Predicate-Index創建時間的另一影響因素。如圖5(b)所示,謂詞條件越多,Predicate-Index的創建時間越長。
6.4 IPI索引的存儲空間開銷
第四組實驗以教學管理數據庫模式(圖1)的Stu?dent類為例,得到不同數據規模下Student類的IPI存儲開銷(Inverted-Object-Index和 Predicate-Index)。由圖6可看出,IPI的存儲空間隨數據規模的增大而增長。因Inverted-Object-Index的每個索引項對應其所在類的一個對象,顯然Inverted-Object-Index的存儲空間和數據規模成正比。對非空的Predicate-Index,每條記錄的結果集規模越大,所占用的存儲空間就越大。
6.5 IPI索引的維護時間與效率討論
由圖3和圖4可以看出,使用IPI比不使用IPI(即PT)節省的時間隨數據集的增大呈拋物線增長,其復雜度約為O(n2)。第4.4節討論到IPI單次維護時間的復雜度最多是O(lbn),維護時間代價遠小于使用IPI節省的時間。因此,IPI以較小的維護時間代價換取較大的效率提升是值得的。
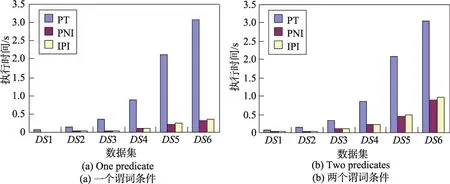
Fig.4 Influence of predicates on PE evaluation圖4 謂詞條件對PE計算的影響
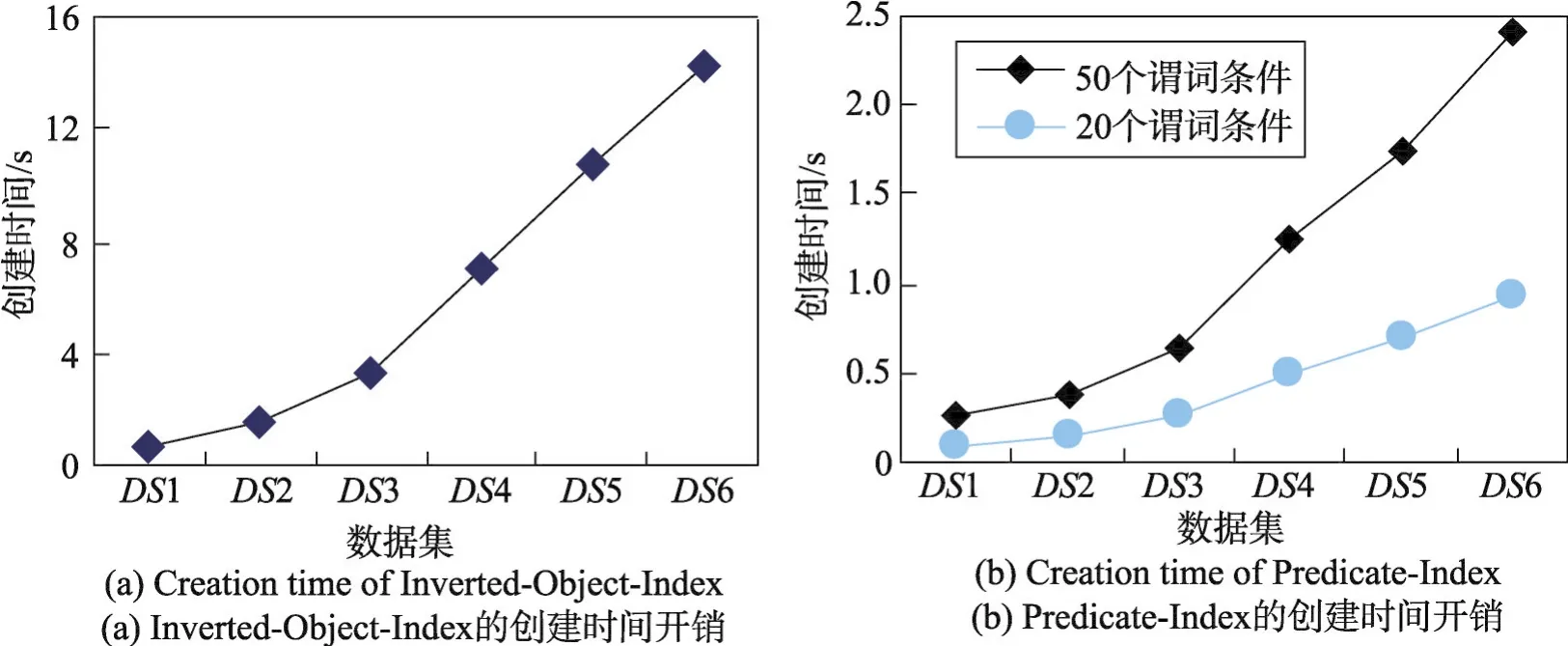
Fig.5 Creation time of IPI圖5 IPI的創建時間開銷
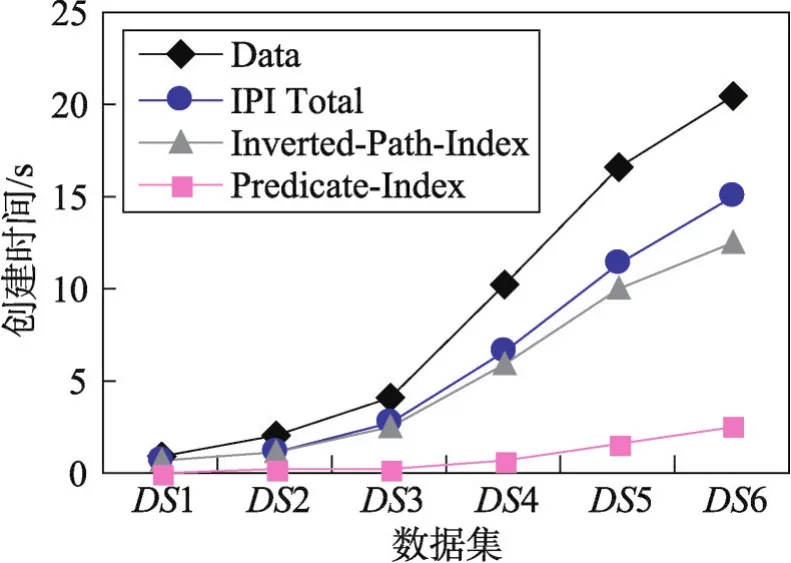
Fig.6 Storage space of IPI圖6 IPI的存儲空間開銷
6.6 IPI索引的效率與靈活性討論
由圖3和圖4可以看出,IPI整體效率比PNI略差一些,相差的時間平均約占IPI執行查詢時間的5%,數據規模越大,其所占比重越小。第5章討論到要覆蓋某類網的全部路徑,IPI需要的索引數目遠小于PNI,且數據規模越大,兩者數目相差越大。因此,對于比較大的數據規模,IPI以比較小的效率代價換取較大的靈活性是值得的。
7 結論和展望
作為ODDB的主要查詢功能之一,跨類查詢由PE實現,故PE的計算效率對ODDB的性能有顯著影響。現有的一些針對ODDB跨類查詢的索引結構(ODPI[14]、PNI[15])都局限于固定的路徑,缺乏靈活性。在此背景下,本文提出一種新的索引結構——倒排路徑索引(IPI),使ODDB跨類查詢具備靈活高效的查詢性能。IPI索引物化了對象間的代理關系,并利用對象關聯檢索技術輔助進行謂詞條件計算。物化的對象代理關系可以靈活覆蓋所有路徑實例,并減少計算中對象遍歷的開銷;對象關聯檢索能過濾不滿足條件的代理關系,以輔助計算謂詞條件。本文通過實驗對影響PE計算的各種因素進行研究,分析了路徑長度和謂詞條件對計算效率的影響。實驗結果表明IPI索引方法能以不低于現有方法的效率支持更加靈活的PE計算。
IPI索引方法仍有一些不足。與PT[14-15]相比,建立IPI需要消耗存儲空間,并且隨數據庫的變化需要頻繁地維護IPI索引。因此,如何減少IPI的存儲占用和維護時間是下一步的工作。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
