基于卷積神經網絡的跨領域語義信息檢索研究
2018-08-15 08:14:20謝先章王兆凱李亞星馮旭鵬劉利軍黃青松
計算機應用與軟件 2018年8期
謝先章 王兆凱 李亞星 馮旭鵬 劉利軍 黃青松,2*
1(昆明理工大學信息工程與自動化學院 云南 昆明 650500)2(云南省計算機技術應用重點實驗室 云南 昆明 650500)3(昆明理工大學教育技術與網絡中心 云南 昆明 650500)
0 引 言
信息檢索是自然語言處理研究中用來解決信息合理推送的問題,例如在自動問答中的應用[1]。當用戶進行信息搜索時,搜索表述方式決定著其獲取信息的質量,現有基于關鍵詞檢索方式已被廣泛認可和接受,但這是以大量語料信息作為檢索基礎,而許多場景下,如小規模或中等規模的語料僅用關鍵詞匹配很難達到理想的效果。同時關鍵詞匹配計算方法將詞語作為孤立的元素,這種詞語相互之間沒有聯系的假設是不合理的[2]。為了應對此類情況,研究者從語句相似度入手,句子的相似度研究方法可以歸結為:(1) 基于詞特征的句子相似度計算[3];(2) 基于詞義特征的句子相似度計算;(3) 基于句法分析特征的句子相似度計算[4]。詞特征的方法進行句相似度計算一般依靠構建向量空間,但這類方法的明顯缺陷是特征稀疏,用在稍大點的語料上效果不理想。為了解決特征稀疏問題,Wang等[5]提出了基于詞匯分解與組合的句子相似度計算,其將對比的句子進行向量化,對形成的句子特征矩陣進行分解,最后進行近似語句計算,但是此方法對環境的實時計算能力要求較高。詞義特征的方法主要依賴外源語義詞典,如游彬等[6]提出的基于HowNet的信息量計算語義相似度算法,但是這類方法局限性太強,外源語義詞典的完整性直接影響著模型的準確率。句法分析特征計算句子相似度的方法,如李茹等[7]提出的基于框架語義分析的漢語句子相似度計算,其主要利用依存關系提取核心詞構建相似矩陣進行相似度計算,這類方法其實還是停留在淺層詞義的分析上,進行相似度計算時忽略了句子中詞與詞之間的關系,在短文本分析中效果較不理想。
目前卷積神經網絡多用于圖像處理領域,但隨著對卷積網絡的深入研究,其逐漸被用于自然語言處理[2]。何炎祥等[8]提出了一個情感語義增強的深度學習模型EMCNN進行中文微博的多情感分類,取得了較好的分類效果。Wang[9]進一步提出了用語義簇和卷積神經網絡對短文本進行分類,分類效果相比其他短文本分類方式有更高的準確率。
針對當前相似度計算方法存在的問題,本文結合卷積神經網絡的特性提出了基于卷積神經網絡的語義信息檢索模型。此模型首先將語料進行分類,然后根據分類結果選擇不同類別的卷積神經網絡檢索模型,這樣使得縮小無效檢索域的同時避免不同領域的相同詞具有不同語義特征的情況。然后將訓練語料轉化成向量矩陣特征和聚類特征,通過卷積神經網絡模型對兩種特征進行映射訓練,訓練過程是一種無監督的訓練方式。本模型用詞向量作為特征克服了特征稀疏的問題,同時卷積神經網絡的使用能使模型提取詞與詞之間的潛在語義關系。為了驗證本模型的有效性,從問答網站上爬取不同類別的提問語料用于模型訓練。實驗結果表明,相比傳統關鍵字匹配檢索,本文提出的基于卷積神經網絡檢索模型有更高的查準率和召回率。
1 預處理
1.1 詞向量
詞向量概念是Hinton[10]于1986年提出來的一種詞表示方式。其通過訓練將語言中每個詞映射成一個固定短向量。相比于傳統稀疏的詞表示方式,利用低維固定長度的詞向量更有利于數據分析。本文利用gensim的word2vec模塊進行詞向量訓練。由于詞的向量是由詞的鄰近詞所計算出來的,所以向量里會隱含語義信息,適合用于語義的信息提取[11]。
1.2 基于語義的快速聚類
在卷積神經網絡映射訓練時需要用到句子的聚類特征,而生成句子的聚類特征需要對語料中的詞進行聚類,得到由不同詞所形成的詞簇。這里用詞向量作為詞聚類的近似依據。
搜索密度峰的快速聚類是Alex等[12]于2014年所提出來的快速聚類方法,其利用局部密度和高密度最小距離作為聚類標準。對較大數據進行聚類分析時,相比傳統聚類其速度更快且效果較好,此方法不像k-mean聚類那樣需要提前定義好聚類數目,只要定義好局部密度和高密度最小距離的閾值就能自動提取聚類中心,劃分出類別來。局部密度計算方式如下:
(1)
式中:ρi表示點i的局部密度值;dc表示截斷距離;dij表示點i到點j的距離,實際運用中用向量之間的余弦值表示。χ函數的計算公式如下:
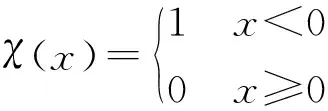
(2)
高密度最小距離計算方式如下:
(3)
計算出局部密度和高密度最小距離后,便可提取聚類中心點,在詞聚類中稱為詞類別中心。最后進行一次遍歷就可計算出其他點的最近聚類中心,最終生成所有點的類別。利用上述聚類方式對詞進行聚類,為句子構建詞聚類特征建立基礎。聚類特征的生成和運用會在3.2中詳細闡述。
1.3 改進SVM短文本分類
由于不同領域的相同詞,特征傾向有很大的不同,所以對句子進行近似計算前進行文本分類,這種處理方式會減少無效檢索域,有助于提高模型檢索的查準率。SVM是一種適用于高維空間的分類方法,傳統利用SVM對文本進行分類的方式是將文本有代表性的詞標記為一個id,即一個獨立的維度,同時設定對應詞的權重,進行SVM訓練[13]。對信息進行檢索時檢索語料一般為短文本,這就導致將詞作為獨立維度,如果選用的特征詞過少,難以表達特征少且特征空間高的短文本特征,會使分類性能降低;如果選用的特征詞過多,會造成整體維度較高,使得特征極其稀疏,最終導致短文本分類效果不盡如人意[14]。所以本文用詞向量作為SVM的訓練特征數據,特征表示如下:
(4)
式中:W為句子去掉停用詞后所包含的詞,函數V為獲取W的詞向量。分類效果在實驗部分進行對比。
通過以上方法獲得檢索語料的類別后,再將檢索語料放入對應類別的卷積神經網絡檢索模型中進行信息檢索。
2 基于卷積神經網絡的檢索模型
本文的語義檢索模型由句卷積層、池化層、隱藏層和轉換層組成,整體結構如圖1所示。
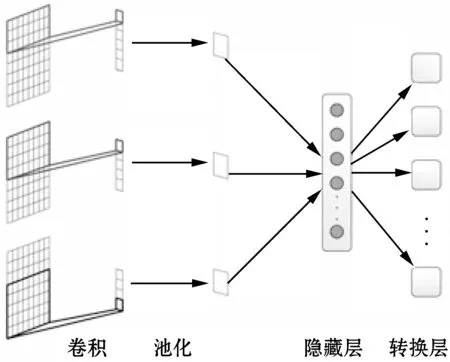
圖1 語義信息檢索模型
此模型的建立基于兩個假設:
(1) 與每句句子相似度最大的句子是句子本身。
(2) 兩句子語義相似則其句子片段必定有多處語義接近。
基于以上假設,本文提出了將相同句子的不同表達特征使用卷積神經網絡模型進行映射訓練,從而達到近似句計算的目的。
2.1 句卷積層
句卷積層將預處理后的詞向量矩陣進行卷積,為了使向量矩陣中的不同特征被盡可能地被提取,利用不同的卷積窗口卷積出不同的卷積向量。圖1中有三個卷積窗口,由于每個卷積窗口是按行卷積,所以每個窗口卷積出的特征個數為:
K=H-h+1
(5)
式中:H為特征矩陣高度,h為卷積窗口高度。每次進行卷積的卷積值為:
(6)
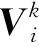
2.2 池化層
從卷積層獲得的卷積向量表示的是不同卷積窗口中的特征,為了表示向量矩陣在卷積窗口中的特征強弱,需要使用池化層來過濾,一般選用最大值的過濾方式。最終n個卷積窗口生成一個n維特征向量。對文本特征進行池化的好處在于最終特征的輸出個數不會隨輸入句子的長度變化而變化。同時池化處理在不損失顯著特征的前提下減少輸出結果的維度,減少模型計算量。
2.3 轉換層
作為模型的最后一層,也是卷積神經網絡最重要的一層。其目的是把經過池化層和隱藏層生成的句子特征進行映射,映射到新的特征空間上。轉換層的每個節點表示詞庫經過語義聚類后的類別,即轉換層神經元個數為詞聚類的類別個數。隱藏層輸出的系數作為句子中詞所在類別的修正系數,利用句子級別的特征彌補詞級別特征的不足。近似值計算方式如下:
(7)
式中:Cj表示檢索句子和被檢索句子j的近似值,Wi表示隱藏層第i個輸出系數,且0≤Wi≤1,mij表示句子j在聚類特征上的第i個系數。
生成聚類特征m的方式如下:
(8)
式中:mj表示聚類特征的第j個值,Wi表示句子中第i個詞,tj表示第j個詞類別中心的詞向量,V為詞向量函數,將詞轉換為向量。圖2為聚類特征生成示例圖,對句子進行全模式分詞。
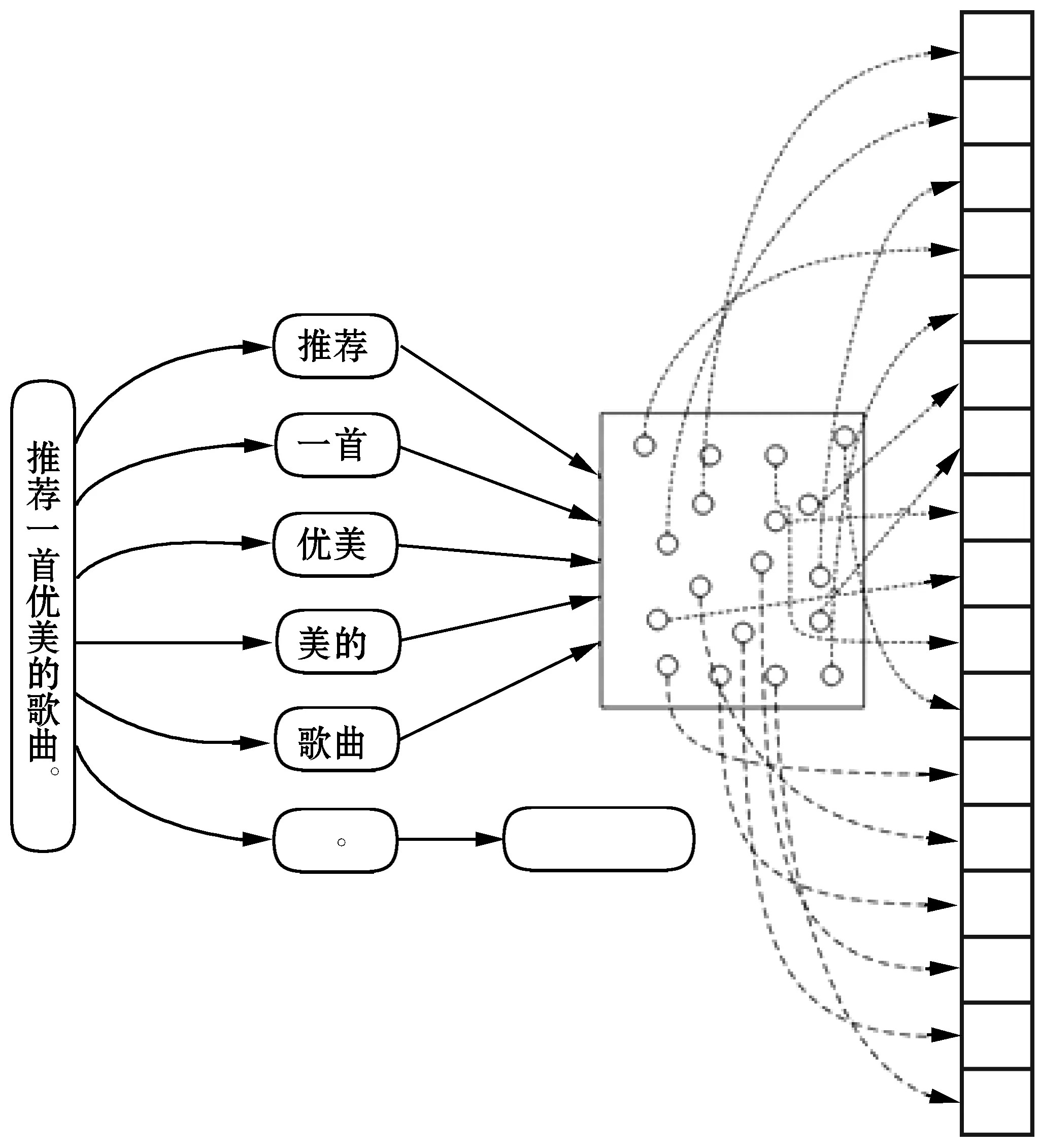
圖2 生成聚類特征
由上面的句卷積層、池化層和轉換層構成了圖1中語義信息檢索模型,通過此模型可以將卷積特征和聚類特征形成映射,最終達到信息檢索的目的。每次檢索會將檢索信息的卷積特征和所有被檢索信息的聚類特征在模型中進行計算,計算所得的數值就是最終句子的近似度。
3 結果和訓練優化
3.1 評價方法
實驗過程中,以成功率作為評價模型近似句計算的標準,以召回率和查準率作為信息檢索的評價標準。
成功率計算公式如下:
(9)
式中:PSC表示模型的成功率,sucTopN表示在sum次測試中TopN上包含最為近似的數據次數,sum表示測試集上的數據總數。
查準率計算公式如下:
(10)
召回率計算公式如下:
(11)
式中:Ppr和Pr分別表示查準率和召回率;A表示檢索到的相關數據數量;B表示檢索到的不相關數據數量;C表示未檢索到的相關數據數量。
3.2 語料片段訓練
為了解決句子對句子片段匹配不敏感的問題,即防止句子在模型訓練中過擬合,這里加入語料片段用于訓練。將句子切分成片段:
Pi={wi,wi+1,wi+2,…,wi+n-1}
則長度為L的句子可以切分出L-n+1個片段。為了使訓練片段中包含句子的關鍵信息,利用以下公式對片段進行篩選:
(12)
式中:tfd為將詞轉化為TF-IDF值的函數,如果Pdi<α則過濾掉第i個片段,反之則將其用于語料訓練。
3.3 近似計算結果優化
利用上述方法對1 000條問答句子進行100次近似計算測試,成功率如表1所示。

表1 未經模型優化TopN成功率表
從表1可知模型已發現89%測試數據的近似語句,但Top1的成功率相對較低。為了優化結果,可以從模型的兩個方面入手:
(1) 考慮向量的近似性,對前10條記錄進行重排,重排的計算依據是:
(13)
式中:S1表示用于檢索的句子,Sj表示被檢索的句子。
(2) 在相似計算階段考慮向量近似性,對結果權值進行適當調整,即式(7)改為:
(14)
式中:tj為式(10)計算結果,β為調整系數,實驗中取0.01。
優化(1)和優化(2)的區別在于優化(2)在排序時同時考慮網絡計算結果和向量相似性,而優化(1)在篩選出前10條近似句后,僅考慮向量的近似性進行重排。即優化(1)注重候選句的內部調整,優化(2)注重提高候選句的整體質量。
將優化(1)和優化(2)同時考慮后,成功率如表2所示。

表2 模型優化后的TopN成功率表
4 實 驗
本文一共進行了5個實驗,目的分別為:
(1) 分類處理對模型近似計算成功率的影響。
(2) 詞向量SVM分類和其他分類方式效果進行對比。
(3) 測試隱藏層層數和每層神經元個數對模型成功率的影響。
(4) 對基于卷積神經網絡的近似計算與其他近似計算方法進行對比。
(5) 測試本模型用于信息檢索的檢索效果。
實驗一
為了對比分類對模型近似計算的影響,拿未分類和經過四分類處理模型進行測試,測試類別為:財經、體育、娛樂和科技。將四類分別取200、500、800和1 000條作為分類后模型的訓練數據,每個類別構建獨立的CNNs模型。從四類中隨機抽取200、500、800和1 000條作為未分類處理模型的訓練數據,構建一個混合類別的CNNs模型,實驗結果如圖3所示。
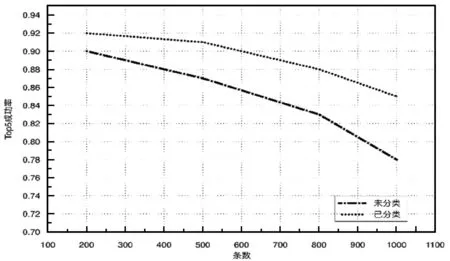
圖3 未分類-已分類模型對比
從圖3可以看出兩種模型Top5成功率都會隨著數據量的增加而下降,但經過分類處理的模型的下降速率相對更小。原因在于:(1) 對同一類別的詞進行詞向量訓練,生成的詞向量質量更好,從而使模型對語義的泛化能力更強;(2) 在未分類模型中,隨著數據量的增加,同形不同意詞造成的干擾會越來越強。
實驗二
分類的質量直接影響著模型的結果,為了對比不同模型的短文本分類效果,用財經、體育、娛樂和科技四類語料各10 000條短文本用于訓練,取100條短文本用于測試。實驗結果如圖4所示。
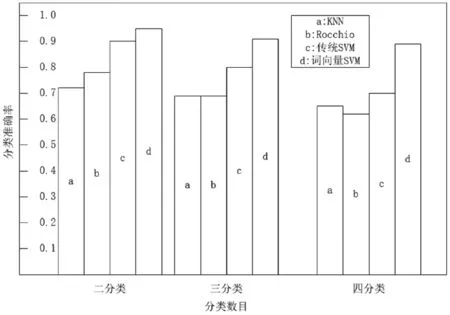
圖4 分類準確率
通過圖4可知基于詞向量的SVM方式較其他分類方式有更高的準確率,由此可以說明將詞向量作為訓練特征相比傳統以字為特征單位有更強的特征表達能力,同時克服了SVM用于文本分類時特征稀疏的問題。
實驗三
神經網絡中隱藏層的層數和每層神經元的多少直接影響著網絡的功能效果。網絡每層的神經元越多,即維度越高,其逼近能力越強,但是神經元過多會降低網絡的泛化能力,造成過擬合。同時網絡維度應逐層降維,降維幅度不宜過大,否則會使降維過程降低噪聲信息的同時損失重要的信息,導致結果劇烈震蕩[15]。
由于神經元的確定目前還沒有統一的標準,所以這里通過實驗進行測試,確定一個效果較好的近似語義模型。拿1 000條短文本進行模型訓練,用100條近似句用于測試。測試模型為:一層隱藏層,節點數1 600;二層隱藏層,節點數1 600~1 200;二層隱藏層,節點數1 600~800。實驗結果如表3所示。

表3 不同模型結構Top10成功率
由表3可見二層隱藏層模型比一層隱藏層模型有更高的成功率,原因在于二層隱藏層模型泛化能力相對更強。通過對表3的1 600~1 200和1 600~800隱藏層對比,可以推測1 600~800隱藏層之所以成功率下降,主要在于第二層隱藏層的節點降幅過大,造成一定的信息損失。
實驗四
為了比較此模型與其他常用近似計算方法,這里從Top1、Top5、Top10的成功率進行對比,用1 000條短文本作為匹配目標語句,進行100次測試計算,結果如表4所示。

表4 近似計算方法的成功率
由表4可以明顯看出,Self-CNNs比n-gram overlap,同義詞擴展和編輯距離有更高的成功率,這是由于n-gram overlap和編輯距離過度依賴字面匹配,同義詞擴展則忽略了鄰近詞之間的關系,而Self-CNNs模型利用詞向量和CNNs特性彌補了這兩方面的不足。
實驗五
為了測試模型用于信息檢索的實用性,這里拿傳統關鍵字匹配檢索與本模型進行對比,分別從查準率和召回率兩方面進行比較。在1 000條被檢索信息中進行100次檢索測試。結果如表5所示。

表5 檢索模型性能對比
從表5可以發現基于卷積神經網絡的信息檢索方法比關鍵字檢索方法以及BGRU-CNN方法[16]有更高的查準率和召回率。其中基于卷積神經網絡的信息檢索方法召回率遠高于關鍵字檢索方法,這是由于中短長度文本的表達用詞呈現多樣化,基于卷積神經網絡的信息檢索方法不會受限于信息的字面匹配,從而相比關鍵字檢索有更高的召回率;而BGRU-CNN由于使用了遺忘門和更新門,丟失了句子中一些有用的信息,造成了準確率和召回率不如CNN語義信息檢索的問題。
5 結 語
本文提出一種基于卷積神經網絡的語義信息檢索模型。利用詞向量SVM進行短文本分類,降低無效檢索域從而提高近似句的成功率,再將分類后的文本拼接成向量矩陣放入卷積神經網絡,將卷積神經網絡的最后一層用轉換層進行近似句的檢索計算。實驗表明基于卷積神經網絡的近似計算模型用于信息檢索相比關鍵字檢索有更高的查準率和查全率。可是此模型面對海量數據進行句子相似度檢索還略有不足,這也是接下來要進行的工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
