異構非易失性內存卷模式實現與應用
2018-08-15 08:02:32吳毅堅趙文耘
計算機應用與軟件 2018年8期
錢 璐 李 弋 吳毅堅 趙文耘
(復旦大學軟件學院 上海 201203) (上海市數據科學重點實驗室(復旦大學) 上海 200433)
0 引 言
非易失性內存設備NVM(Non-volatile memory)是指在系統掉電時仍能保持數據不丟失的存儲設備。從發展歷程看,主要分為塊尋址和字節尋址兩種。塊尋址設備性能比動態隨機存儲器DRAM(Dynamic Random Access Memory)低得多,而字節尋址設備性能接近DRAM。針對NVM建立訪問模式的研究主要集中在兩個方面。一方面將NVM當作存儲設備,在NVM上建立文件系統進行持久內存管理[1]。另一方面,對于按字節尋址的NVM,將其替代傳統DRAM,提供應用程序load/store訪問方式[2]。前者并沒充分挖掘NVM優秀特性,沒有最大限度降低軟件系統開銷。后者直接訪問NVM,繞過很多軟件層包括系統調用、文件系統等,大大降低了訪問延遲。本文設計的非易失性內存卷模式通過將多塊不同種類NVM組織成地址連續的持久內存卷,簡稱PM卷(Persistent Memory Volume),并將卷映射到用戶空間。既提供處理器load/store訪問方式,也對異構NVM設備實現有效管理。
1 相關工作
主要從為NVM設備建立文件系統、以load/store方式直接訪問NVM設備、內存通道劃分、熱數據劃分四方面闡述相關工作。
BPFS[3]文件系統以字節尋址方式管理NVM,通過在文件系統構建樹狀數據結構,省去文件系統緩存與映像間的數據拷貝,從而減少對NVM的寫入。SCMFS文件系統[4]與BPFS一樣在持久性內存中不需要數據拷貝,并且盡可能為每一個文件分配連續空間從而提供優越的性能。PMFS文件系統[5]繞開了文件系統緩存直接訪問NVM,避免了系統中數據的拷貝。NOVA[6]文件系統通過為每個文件inode維持一個日志來提高系統并發性,并在日志之外存儲文件數據來減少垃圾回收的開銷,最終在混合NVM內存結構中最大化性能。
在NVM單層存儲模型中,內存中可以存儲持久化數據結構,所以Haris Volos等[7]提出Mnemosyne,Joel Coburn等[8]提出NV-Heaps,提供了新的NVM編程接口。Mnemosyne和NV-Heaps通過提供用戶態的編程接口,使應用程序能夠在用戶態訪問非易失內存設備,避免了通過文件系統訪問NVM的系統開銷,包括系統調用、文件系統接口、設備驅動程序等。
Muralidhara等[9]提出一種應用感知的內存通道隔離方法來減少多核環境下的訪存干擾,該方法映射相互之間可能產生嚴重訪存沖突的應用的數據到不同的內存通道并優先調度非訪存密集型應用的訪存請求。Jeong等[10]提出一種通過在多核之間隔離內存Bank以隔離訪存請求從而減少局部性沖突的方法。為了彌補因此而損失的bank級并行性,該方法采用Memory Subranking技術來增加獨立的Bank數。
Kyu Ho Park等[11]提出了一種簡單的基于頁面訪問頻度的冷熱頁面劃分策略。通過設置一個訪問位來統計頁面的訪問頻繁程度來劃分冷頁面和熱頁面。Dong-Jae Shin等[12]提出了一種更為準確反映頁面熱度的頁面劃分策略。通過擴展頁表的條目,增加了4個記錄位,越是靠左的位權重更小:8、4、2、1,每當頁面被訪問的時候標記就會左移一位,最后劃分的時候計算頁面的總權重,根據設定的冷熱頁面的閾值來劃分冷熱頁面。Luiz Ramos等[13]提出了一種考慮頁面訪問頻度和時間的RaPP策略。策略利用一個M級的LRU隊列來記錄頁面的訪問信息,頁面在生存時間內隨著被訪問的程度不斷地提高隊列等級。當超過生存時間后降低隊列等級,全面地考慮頁面在很長時間和最近時間段的訪問情況。
2 動 機
隨著大數據技術的發展傳統以計算為中心的系統架構逐漸轉向以數據為中心。然而磁盤訪問性能的提升遠落后于CPU計算能力的提升,無法滿足大數據處理應用的需求。字節尋址NVM具有訪問性能高、容量大等特性,對數據密集型應用性能的提升帶來了希望。傳統存儲架構不利于發揮NVM的性能優勢。本文研究如何針對NVM設計更加高效的訪存方式,從而替代DRAM。針對字節尋址NVM特性,設計相應的文件系統在很大程度上提升了系統性能,如SCMFS、BPFS文件系統等。但始終將NVM當作存儲使用,并沒充分挖掘NVM的優秀特性,沒有最大限度的降低軟件系統的開銷。Mnemosyne在內核中創建并虛擬化一個持久區域,通過內存映射方式將持久區域映射到用戶空間,提供應用程序load/store方式訪問,從而直接替代DRAM。直接訪問NVM繞過了很多軟件層包括系統調用、文件系統以及設備驅動等,大大降低了訪問延遲。但Mnemosyne對于NVM設備的不同種類,在內核中如何管理并沒有研究。本文設計并實現的非易失性內存卷模式將NVM設備直接替代DRAM,通過將多塊不同種類NVM組織成地址連續的持久內存卷,并將卷映射到用戶空間。既提供了處理器load/store訪問方式,也很好地對異構NVM設備實現管理。
3 非易失性內存卷模式設計
Linux通過虛擬內存實現內存管理,應用程序中進程使用虛擬地址訪問內存。虛擬地址也即邏輯地址,是系統中分段機制產生的段內偏移地址部分。實際數據需要物理地址直接訪問。物理地址是前端總線上尋址物理內存的地址信號。虛擬地址加上相應的段基地址就生成了線性地址,最后通過分頁機制將線性地址翻譯成物理地址。Linux操作系統中虛擬地址等于線性地址,所以在Linux中只需要分頁機制便能將虛擬地址轉換成物理地址。
如圖1所示,PM卷是在NVM硬件層之上建立地址連續的軟件層。在內核中表現為一段地址連續的內存空間,并和傳統內存物理地址空間統一尋址。在系統中擁有一段物理地址空間,并提供內核組件調用的接口。PM卷和異構NVM之間通過映射算法實現地址翻譯,對PM卷的訪問實際被映射到NVM設備上。最后通過內存映射方式將PM卷映射到用戶空間,使得應用程序能夠以load/store方式訪問PM卷。
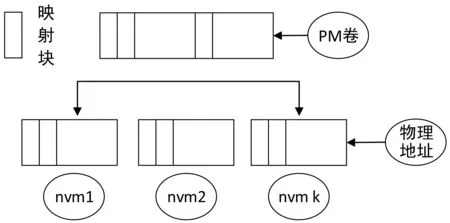
圖1 非易失性內存卷模式結構圖
非易失性內存卷模式設計提供程序員一個持久內存卷模式的抽象。應用程序以load/store方式訪問PM卷,內核負責將多個NVM設備組織成一個地址連續的PM卷。PM卷主要實現了三個方面的目標。
1) 用戶態直接訪問持久內存,繞過了包括系統調用,文件系統以及設備驅動等軟件層降低訪問延遲。
2) 設計卷到非易失性內存設備的映射關系,降低卷到非易失性內存的地址翻譯開銷。
3) 一個靈活方便的卷模式管理機制,實現用戶態創建、初始化、刪除卷等。
4 非易失性內存卷模式應用
4.1 一對多地址映射設計動機
現在的內存系統都是多通道架構,不同通道的內存可以被并行訪問。一個典型的DRAM內存模塊,通常有16個banks,而不同的bank之間也可以并行訪問。假設系統中有四個內核,且每個內核只有一個訪存請求。最好的情況下,四個訪問請求的數據分別位于四個不同的內存bank中,那么四個訪問請求可以并行執行。最壞的情況下,來自于四個內核的訪存請求都指向同一個內存bank,此時只能執行其中一個請求,其他請求需要等待并按順序執行,無法并行執行。因而訪存延遲會成倍增加。大數據時代背景下,數據規模越來越大,而對數據的訪問更多集中在對數據的讀取上。由于緩存容量有限,大量的數據訪問是以內存為主。在多核環境中熱數據的頻繁訪問會導致同一時刻不在同一cache line但位于同一內存bank中的數據被多個訪存用戶同時請求訪問,這些訪存請求無法并行訪問,因此導致嚴重訪存沖突,極大地增加了系統訪問延遲。
針對熱數據頻繁訪問導致的嚴重訪存沖突,考慮將頻繁訪問的熱數據備份多次放置在不同內存通道或不同內存bank上。多核環境中,對于同一塊數據的多個訪問請求分配到不同的數據備份上,實現并行訪問,降低系統訪問延遲。由于數據有多個備份,對內存容量要求很高,鑒于NVM容量很大,因而使用NVM替代DRAM,將同一塊數據備份多次,每個數據備份放置在不同的非易失性內存設備上,并且使不同的NVM位于不同的內存通道上。當同一時刻對同一塊數據有多個訪問請求時,將訪問映射到存有不同數據備份的NVM上。在多核環境中,不同的處理器處理其中一個訪存請求,可以實現對同一塊數據的并行訪問。借助非易失性內存卷模式,在位于不同內存通道的NVM設備之上建立一個地址連續的PM卷層,對于PM卷中的每一頁映射到不同內存通道NVM設備的多個頁面。
4.2 一對多地址映射詳細設計
假設PM卷中頁面是熱數據頁面,在大量數據訪問時會產生嚴重訪存沖突,所以將PM卷中的頁面映射到多個不同NVM設備上。并在設計一對多映射時將每一個NVM設備的大小看作與PM卷相同。類似于傳統內存訪問的請求分頁方式,通過建立頁表機制實現一對多地址映射。頁表中頁表項按照PM卷地址由小到大依次存儲。但由于PM卷上的每一頁,可以映射到多個NVM設備,每個PM卷頁面可以對應多個頁表項,對應于同一個PM卷頁的多個頁表項按照頁表項對應NVM設備的設備號由小到大依次存儲。
以PM卷和非易失性內存的地址都用32 bit表示,并且建立的頁表中的每一個頁表項都是32 bit,而系統是以4 KB為一頁大小,給出頁表項的格式如圖2所示。地址中12-31位表示物理頁號,指向NVM中某一頁的基地址,要求物理頁4 KB對齊。由于頁表項前20位是頁幀號,后12位并沒有實際意義,取其中一位標記此頁是否已經被映射,就是V字段,當為1的時候表示已經映射。創建PM卷的時候初始化頁表項,將所有的頁表項初始化為0。建立的頁表映射都是固定的,一旦某個進程訪問了PM卷的某一頁,通過一對多映射將地址映射到某個NVM設備某頁之后,在此進程結束之前,該映射的頁表項保持不變。

圖2 一級頁表結構的頁表項含義圖
建立了頁表機制,并初始化頁表項為0。當有進程首次對PM卷某頁寫入數據時,將數據寫入構成卷的第一個NVM設備上(由于構成卷的NVM設備是用鏈表鏈接,鏈表是按照NVM設備號的大小鏈接,第一個設備指的是鏈表中第一個結點),之后將數據拷貝到其他k個設備上。通過寫入的PM卷地址計算得到對應的頁表項的位置,然后將每個數據備份的物理頁幀號根據設備號寫入正確的頁表項中。有了映射頁表,在大規模數據讀取時,需要設計地址翻譯策略,來實現并行的訪問。一對多地址映射算法見表1。

表1 一對多地址映射算法偽代碼
因為不同平臺的頁面大小不盡相同,偽代碼中的PAGE_SHIFT是地址中頁面偏移量的位數。Nums指的是PM卷的一頁究竟映射到多少個NVM設備上。1~4行代碼通過頁表基址加上PFN*Nums的方式找到頁表項。函數isValidEntry通過檢查V標記位是否為1來判斷頁表項是否有效,如果是1則表示該頁表項無效。searchValidEntry函數尋找下一個有效的頁表項,函數setEntryNotValid將V標記位設置為1。pfn_to_page函數將NVM設備的pfn轉化成對應頁的page。算法的整體思路是:通過PM卷中待映射的頁幀號相對于PM卷初始地址頁幀號的偏移量乘以構成PM卷的NVM設備總數,再加上頁表基地址得到待映射頁對應頁表項集的初始地址,然后判斷該頁表項是否已經被分配給某進程,最后找到沒有被分配的頁表項,將該頁表項設置為已分配,同時通過頁表項前20位頁面物理地址得到頁幀號。
由于頁表的大小會隨著PM卷地址空間大小的增加成倍增加,因而增加缺頁開銷,所以考慮將頁表設計成多級結構。若設計成二級頁表,對應PM卷地址結構如圖3所示。以一對四映射為例,頁表項中是4個頁表項指向同一個PM卷地址頁框,那么在一頁中(4 KB)可放入256個(一個頁表項占4 B,4 KB/(4 B×4))映射到不同PM卷地址的頁表項,所以需要8位來標記,也即是圖3中的PPN2(physical page number),一級頁表用12位,也即是圖3中的PPN1來標記,需要存儲在4頁中。

圖3 二級頁表結構的PM卷地址含義圖
4.3 一對多地址映射對系統影響
一對多地址映射由于在多塊NVM上建立了PM卷層,并且PM卷層到NVM設備之間通過頁表形式進行地址翻譯,相比于傳統內存架構,多了一層地址翻譯過程。傳統內存架構中應用程序虛擬地址在MMU作用下最多只需要一次訪存操作便可以得到物理地址,而非易失性內存卷模式下的一對多地址映射中。應用程序虛擬地址首先需要類似于傳統內存架構中地址翻譯過程得到PM卷對應的地址,然后仍需要進行PM卷到NVM地址映射得到最終存儲數據的NVM設備上地址,至少需要兩次訪存操作。這會導致缺頁處理開銷加大。
5 多路并行訪存實現
多路并行訪存是將數據備份放置在不同內存通道的NVM上,在多核環境中通過一對多映射算法,將同一塊數據不同訪存請求分配到不同數據備份上,實現并行訪問。首先實現非易失性內存卷模式,然后實現PM卷到NVM之間一對多地址映射。
5.1 非易失性內存卷模式實現
為了對PM卷進行管理,在內核中創建結構體struct pm_volume保存PM卷的卷大小、卷號、卷的開始地址以及組成卷的NVM設備等信息。同時PM卷是取自不同NVM設備的中的一部分內存空間組成,因此創建結構體struct pm_device保存組成PM卷的NVM設備開始頁號、大小、設備號等信息。實現非易失性內存卷模式分兩步進行,首先將PM卷加入內存系統中,提供內核中組件訪問接口。然后通過內存映射方式將PM卷映射到用戶地址空間,提供應用程序load/stroe訪問方式。
(1) 將PM卷加入內存系統分兩步實現,首先將PM卷加入伙伴系統,然后修改內核中alloc_pages函數使內核組件能夠訪問PM卷。
傳統內存系統中,內核將內存空間劃分成結點,每個結點劃分成管理區(zone),每個管理區由各自的伙伴系統負責所有頁面的申請和釋放。管理區中的每個頁幀對應一個struct page結構。我們自定義了PM_ZONE管理區,讓PM卷和PM_ZONE管理區的頁面一一對應,然后將PM_ZONE管理區中的頁面加入伙伴系統。通過修改管理區和伙伴系統初始化方法,加入對自定義PM_ZONE的管理。為了方便區分PM_ZONE和系統其他管理區,在struct zone結構體中增加了char*name字段表示管理區的名字。完成管理區和伙伴系統初始化之后,PM_ZONE管理區上并沒有實際頁面,所以內核中申請PM_ZONE大小的連續內存頁,將其每頁初始化為屬于PM_ZONE管理區。由于申請和釋放頁面時系統通過page_zone(page)函數獲取頁所在的管理區,但該函數用到很多系統預定義標記符,而PM_ZONE并沒有添加到系統中維護,因此無法通過此方法獲取頁所在的管理區,故在struct page中添加了一個struct zone*zone字段來表示該頁所在的管理區。在內核申請PM_ZONE大小頁面并設置成所屬管理區時,通過page->zone->name=″PM_ZONE″實現。
PM卷以PM_ZONE管理區的形式加入內存伙伴系統之后,需修改內核的alloc_pages函數才能使內核申請PM卷的頁面。實現中增加自定義GFP_PM標志,也就是將GFP_PM標志加入alloc_pages函數第一個參數gfp_t gfp_mask中。通過判斷gfp_mask標志是否等于GFP_PM,進而選擇是否從PM卷對應的PM_ZONE管理區中申請頁面。
(2) PM卷以PM_ZONE管理區形式加入內存系統之后,內核可以申請釋放PM卷中頁面。但應用程序對PM卷的訪問還需要提供正確的訪問接口,本文基于mmap的內存映射接口模式,將PM卷層中的頁面通過mmap函數映射到用戶空間。基于mmap的內存映射方式是指通過mmap函數將PM卷地址空間映射到用戶進程地址空間,提供用戶進程load/store方式訪問。函數接口形式是int pm_mmap(struct file*filp, struct vm_area_struct*vma),參數filp是待映射目標文件的結構體指針,vma是虛擬內存區域。
5.2 一對多地址映射實現
一對多地址映射通過頁表機制實現,本文實現了單級頁表結構。首先在PM卷結構體struct pm_volume中加入屬性unsigned long*pageTableBase表示當前PM卷對應頁表基地址。由于struct pm_volume結構體中有屬性volume_size表示PM卷大小以及num表示構成卷的NVM設備個數。volume_size和num乘積就是頁表大小。另外還需在struct page結構體中增加屬性unsigned int firstaccess,表示PM卷中每頁是否第一次被進程訪問并寫入數據。0表示首次被訪問,1表示否。
創建PM卷時根據頁表大小將所有頁表項初始化為0。當有進程首次訪問PM卷的某頁時,修改mmap函數,通過判斷PM卷的當前被寫入頁面的struct page的firstaccess屬性是否為0,決定是將數據直接寫入第一個NVM設備的對應頁還是訪問頁表得到頁表項。如果是0,表示訪問的PM卷頁面是首次寫入,因此將數據寫入第一個NVM設備對應頁。然后通過memcpy函數將該頁數據拷貝到其他NVM設備對應頁面上。Memcpy函數使用內存虛擬地址,可通過函數kmap將NVM設備物理地址轉換成內存虛擬地址。最后修改PM卷中當前頁面的頁表項集。
建立頁表后,對PM卷該頁面的大量讀取操作可以通過地址翻譯算法在多核環境中實現并行訪問。以PM卷映射到四個NVM設備為例子闡述地址翻譯的實現過程,考慮到非易失性內存總的空間大小是PM卷的4倍,在制作頁表時PM卷的每一個頁號對應四個不同NVM的頁號,PM卷每一頁對應的四個不同的NVM頁號的頁表條目連續(每個頁表條目的大小為4 B)。若PM卷的大小為4 GB,每個NVM的大小同樣也是4 GB。以PM卷地址為:0x000645b0為例,一對四地址翻譯如圖4所示。對應PM卷地址的頁表項有4個(圖中只畫出3個),地址0x000645b0前20位的物理頁號是100,根據算法乘以4得到400。查看頁表400位置處對應的V標記位是1,表示此頁表項已經被映射,由searchValidEntry函數找到401處V標記位是0有效,則將該標記位設置為1,并且根據該頁表項的前二十位頁面物理基地址找到對應的NVM設備的那一頁,再由offset為1 456計算得到最終目標字節位置并找到。
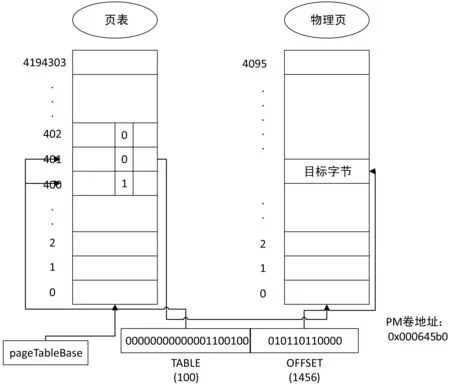
圖4 一對四單級頁表結構圖,左邊是頁表結構,右邊是找到的NVM設備的具體物理頁
一旦將某個非易失性內存的頁幀號映射給對應進程的時候,當該進程此后訪問PM卷同一頁時,一律訪問之前綁定的非易失性內存的頁,而不再進行缺頁處理,也就是缺頁處理只會在進程首次訪問PM卷地址空間某一頁的時候進行。即便缺頁訪問時,需要進行兩次的地址翻譯,當有大量的數據訪問時候,這個缺頁的開銷會被不斷稀釋掉。
6 實驗與結果分析
6.1 實驗環境
實驗中,硬件是ThinkPad x230 Intel i5雙核4 GB DDR3雙通道內存筆記本電腦,安裝了Ubuntu15.10操作系統,內核版本是4.2.8。
6.2 實驗方法
在驗證了非易失性內存卷模式實現的合理性后,驗證一對多地址映射。從內存DRAM中申請兩個連續內存塊模擬兩個NVM設備。由于一對多設計比傳統內存訪問方式多了一層地址翻譯過程,因而首先考慮缺頁中斷處理中開銷的增加對系統的影響。實驗組中測量的是實現了一對多映射的缺頁處理時間,對照組測量傳統內存請求分頁方式缺頁處理時間。實驗結果見圖5。
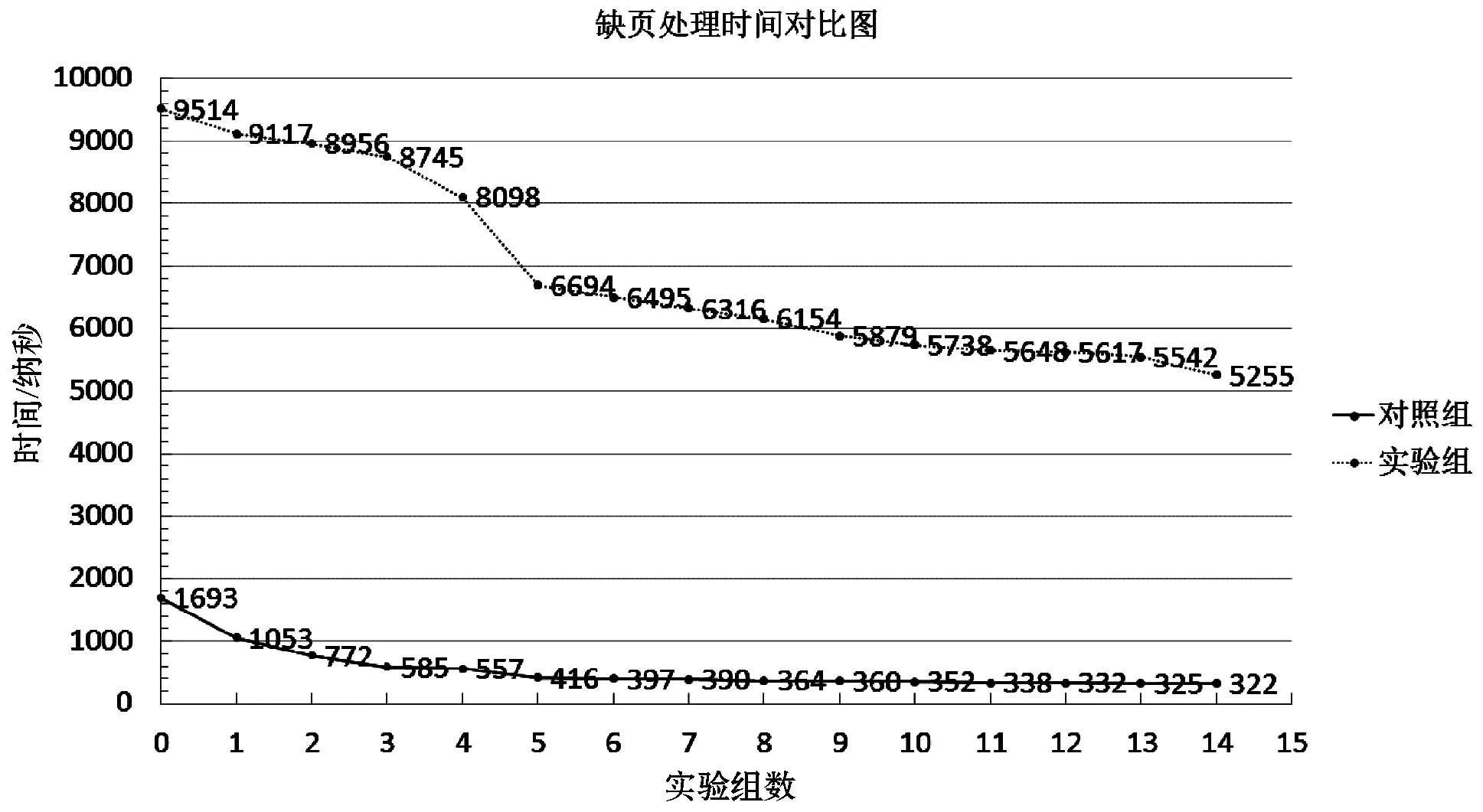
圖5 性能優化后PM卷頁面訪問缺頁處理時間和正常內存訪問缺頁處理時間對比圖
缺頁處理的開銷會增加,但由于頁表項一旦寫進頁表,在當前進程結束前頁表項不會改變,所以缺頁只在首次訪問PM卷頁面時發生。在大規模數據讀取時開銷會被不斷稀釋,因此進一步測試對PM卷大規模數據訪問時的性能提升情況。實驗主要驗證一對二地址映射時,雙通道并行訪問是否能夠提升系統性能,因而,對于映射到不同內存通道的同一塊數據的兩個備份不要求數據相同,主要保證兩個數據備份位于不同內存通道即可。
內存控制器地址映射,是將一個內存請求的物理地址翻譯并映射成DRAM模塊的物理結構:channel、rank、bank、column等。對于雙通道的內存結構中,物理地址有1 bit表示該內存請求的數據所在內存通道。實驗中使用的ThinkPad x230設備是物理地址右邊起第12 bit。
一對二地址映射實驗中訪問不同內存通道便可以通過訪問物理地址channel標記位分別為0和1的兩個內存通道。也就是一對二設計中同一PM卷頁面映射的兩個實際頁面的頁幀號倒數第2 bit不相同。實驗中設計兩個并發的線程,分別讀取PM卷空間的一段頁框。由于實現了一對二的情況,當訪問同一塊數據時兩個并發線程會實現并行執行。對照組中將與一對多中PM卷大小相同的一塊連續內存通過mmap函數映射到進程虛擬地址空間,設計兩個線程執行并發訪問。實驗是在禁用cache中進行。實驗是將每一個線程對PM卷進行100萬次讀取操作,測量兩個線程執行完需要的總時間,與對照組總時間進行對比。結果如表2所示。
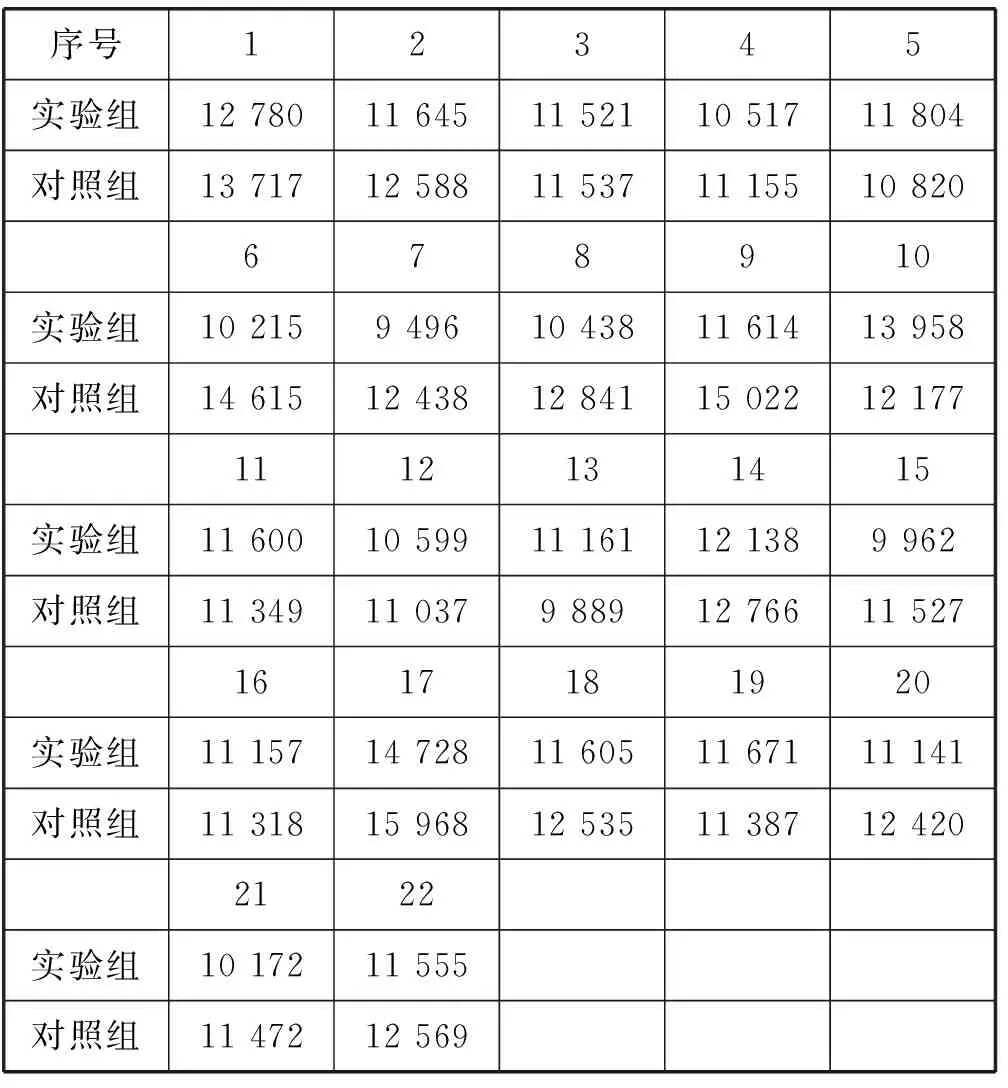
表2 實驗結果匯總表 us
6.3 實驗結果
如圖5缺頁處理實驗共進行了15組,實驗組數據的最大值、最小值和平均值分別是9 514 ns、5 255 ns和6 917.9 ns。對照組數據的最大值、最小值和平均值分別是1 693 ns、322 ns和550.4 ns。從平均值看來,實驗組所用時間是對照組的12.6倍。可以看出在缺頁處理上對性能產生了較大的影響。針對一對多地址映射進行了22組實驗得到數據,見表2。
表2中實驗組數據的平均值、最大值和最小值分別是:11 430.8 us、14 728 us、9 496 us。對照組數據平均值、最大值和最小值分別是:12 324.9 us、15 968 us、9 889 us。由平均值可計算得出實驗組比對照組性能提升7.25%。從實驗結果看來,基于一對多映射的PM卷模式增加了一層地址翻譯過程雖然在缺頁處理時間上是傳統訪存方式的12.6倍,但在大量數據讀取中,整體性能提升了7.25%。但是仍然存在些不足之處,實驗是在雙通道環境下進行的,實現了一對二映射的情況,對于更多的一對三、一對四等映射情況可進一步進行實驗。
7 結 語
本文針對新型NVM設備的優秀特性,設計實現了load/store方式訪問NVM設備,并管理異構的NVM設備的非易失性內存卷。然后基于熱數據訪存沖突在非易失性內存卷模式的基礎上提出了一對多的地址映射方案,實現了一對多地址映射策略。最后,通過在雙通道內存中,進行一對二映射實驗,得到的數據在一對二映射情況下,系統訪存性能提升了7.25%。表明這種設計確實能夠改變內存訪問方式并提升訪問性能,比較好地避免熱數據的訪存沖突。
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
中國特種設備安全(2022年6期)2022-09-20 02:52:28
保健醫苑(2022年1期)2022-08-30 08:39:14
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
電子制作(2018年11期)2018-08-04 03:26:08
工業設計(2016年12期)2016-04-16 02:52:00
設備管理與維修(2015年12期)2015-04-09 06:57:00
消費者報道(2014年7期)2014-07-31 11:23:57
電腦愛好者(2011年11期)2011-06-22 08:20:18
