基于GPU數據庫系統的并發查詢性能優化
2018-08-15 08:02:30李逸龍何震瀛王曉陽1
計算機應用與軟件 2018年8期
李逸龍 張 凱 何震瀛 王曉陽1,,4
1(復旦大學軟件學院 上海 201203)2(復旦大學計算機科學技術學院 上海 201203)3(上海市數據科學重點實驗室 上海 200433)4(上海智能電子與系統研究院 上海 201203)
0 引 言
由于物理工藝的限制,近年來CPU的性能已經難以得到大幅提升。然而,在大數據時代數據量快速增長,這使得CPU越來越難以應對日益增長的數據處理需求。與此同時,利用通用計算圖形處理器(GPGPU)的并行處理能力來加速計算任務成為研究熱點。由于GPU極大地提升了計算性能,數據庫研究領域也出現了大量用GPU對查詢計算任務進行加速的研究。跟傳統的CPU數據庫相比,GPU數據庫在查詢任務執行中展現出非常顯著的加速效果。
利用GPU加速SQL運算符的執行速度,YDB系統[1]實現了一個基于GPU的數據庫系統,跟CPU版本的實現相比,能夠達到大約2~6倍的查詢速度提升。為了進一步提高GPU的資源利用率,出現了以支持并發查詢為目標的研究成果,其中突出的系統有MultiQx-GPU[2]和Ocelot[3]。以MultiQx-GPU系統為例,該系統實現了并發查詢之間分時共享GPU資源的機制,提升了GPU的資源利用率和系統性能。
然而MultiQx-GPU系統的架構設計仍然導致了一些問題和缺陷。首先,MultiQx-GPU在每個查詢任務進程中都需要創建CUDAContext以發起后續GPU調用,耗時較大。其次,該系統雖然能夠讓并發的查詢任務之間分時共享GPU資源,但是在不同查詢任務中重復傳輸了數據庫中相同的列存儲數據,不但浪費了PCIe總線帶寬,還大量占用了GPU資源。以上兩點不足會造成系統對GPU整體的資源利用率較低。
針對以上不足,本文將基于MultiQx-GPU系統,提出一種改進架構的HyperQx-GPU系統的設計與實現。該系統能夠統一管理GPU硬件資源,減少了每個查詢任務單獨管理GPU的開銷,提升了單個查詢的執行效率。同時,該系統能夠根據系統中實時的查詢任務運行情況,實現跨并發查詢任務的數據庫列存儲數據共享,減少系統整體的PCIe數據傳輸量,進一步提升了系統性能。
系統架構方面,該系統采用C/S的架構設計,將數據庫系統分為查詢處理客戶端和數據庫服務端,兩端用IPC機制進行通信,使得兩個部分的優化可以互不影響地進行。跟MultiQx-GPU系統的函數庫實現方式相比,降低了系統組件之間的耦合性,增強了系統功能的可擴展性。
實驗結果證明,本文實現的HyperQx-GPU系統能夠大大提升GPU的整體資源利用率。對比MultiQx-GPU系統,HyperQx-GPU系統在執行并發SQL查詢的情況下能達到平均12倍的性能提升。
1 背景和相關工作
1.1 GPU硬件結構及編程框架
CPU和GPU的硬件架構具有很大差異,具體情況如圖1所示。相比于CPU大量邏輯控制單元和緩存單元的硬件架構,GPU包含更多計算核心和高性能內存單元,因而更適合被用于處理批量數據的密集型并行計算。以NVIDIAGTX TITAN X型號GPU為例,該GPU擁有3 584個計算核心,并行計算能力非常強。其還擁有具有5 005 MHz時鐘頻率和384 bit傳輸位寬的高性能內存單元,相比于通常CPU搭配的DDR4內存,前者能夠達到更高的內存數據訪問速度。
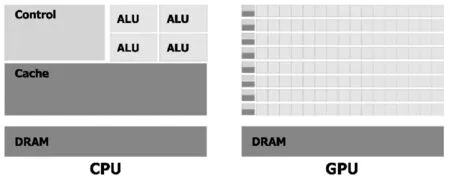
圖1 GPU內存數據庫系統架構
在目前的GPGPU領域中,最常用的編程框架為OpenCL和CUDA[4]。基于跟MultiQx-GPU對比的目的,本文設計的系統實現過程中采用了CUDA編程框架,因此此處以CUDA為例進行介紹。在CUDA編程模型中,程序代碼會被編譯為CPU運行的宿主程序和GPU運行的程序,其中GPU中運行的函數被稱為kernel。GPU作為協處理器,執行計算任務時需要CPU上運行的宿主程序通過CUDA提供的API進行驅動,因此其整體上是一個異構的編程模型。
CUDA程序運行時,其宿主程序調用的所有CUDAAPI會被放到一個stream內。CUDA編程中的一個stream代表一串連續的CUDA API調用命令,同一個stream內的CUDAAPI調用會被GPU串行地調度執行。宿主程序可以創建多個stream,在不同的stream里發起的命令在沒有數據依賴的情況下,會被GPU調度器并發執行,從而提升GPU的資源利用率。在CUDA編程中,一個常用的優化手段為利用多個stream同時發起互相不存在依賴關系的PCIe數據傳輸和kernel調用,使兩者可以同時執行,從而有效利用GPU的數據帶寬和計算資源。
1.2 GPU數據庫系統
基于GPU的高性能計算能力,大量研究開始利用GPU加速數據庫的join和sort等SQL操作符[5-8]以及事務的執行[9]。此后,不少研究考慮將GPU作為數據庫查詢執行的主要硬件[10-11],如前所述的YDB是典型的設計與實現。相比于CPU數據庫系統,YDB系統能顯著地提升查詢任務執行效率。然而其缺點也很明顯,即串行執行查詢任務時,每個任務獨占GPU硬件資源,無法充分利用GPU計算和PCIe數據傳輸帶寬等資源。
為了提升GPU的資源利用率,需要支持并發的查詢請求。目前支持并發查詢請求的GPU數據庫系統主要有MultiQx-GPU和Ocelot。以MultiQx-GPU為例,該系統通過動態鏈接庫攔截的機制,在執行SQL查詢任務前通過LD_PRELOAD環境變量預加載系統提供的動態鏈接庫,攔截了查詢任務發起的CUDARuntimeAPI調用,實現了并發的查詢任務間協同管理GPU資源的機制,使得不同任務進程之間可以共享GPU資源。與YDB相比,MultiQx-GPU在執行并發查詢任務時能夠達到平均55%的系統吞吐量提升。MultiQx-GPU的系統架構如圖2所示,虛線上方為系統實現部分,下方為CUDA提供的運行時環境。
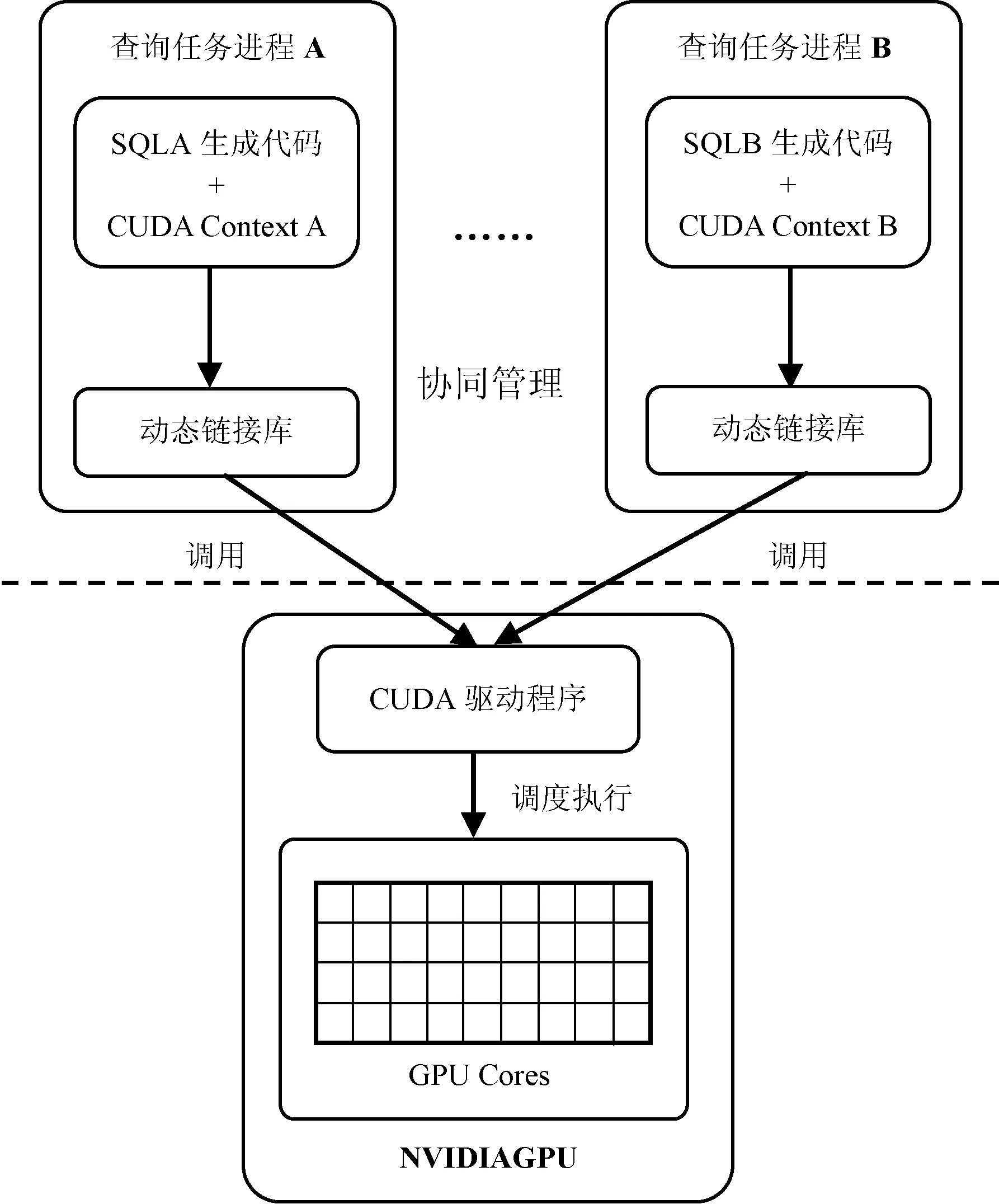
圖2 MultiQx-GPU系統架構
盡管MultiQx-GPU系統的設計和實現得到了實驗結果的驗證,但是該系統所達到的GPU資源利用率仍然還有很大的提升空間。具體而言,其待改進之處主要有以下兩點:(1) 在不同查詢任務中重復傳輸可共享的只讀的數據庫列存儲數據,造成PCIe總線的帶寬資源浪費。圖3展示了HyperQx-GPU系統中(關閉列存儲數據共享功能)一次查詢任務的執行時間線。從圖中可看出,在334 ms的查詢任務執行時間中(不包括創建CUDA Context的時間),CPU內存到GPU內存的PCIe數據傳輸操作占據了超過75%的時間(262 ms)。因為數據庫中的計算任務通常涉及大量的列數據掃描和表之間的連接等操作,在執行實際的SQL操作之前需要傳輸大量的列存儲數據到GPU內存,計算結束之后還需要把結果數據從GPU內存傳輸回CPU內存。大量的PCIe數據傳輸使得本來就稀缺的PCIe總線帶寬成為了該系統執行查詢任務時的性能瓶頸。(2)MultiQx-GPU系統中的每個查詢任務進程獨立調用CUDARuntimeAPI來使用GPU資源,使得每個進程均需要創建獨立的CUDAContext,增加查詢任務的執行時間,進而影響系統的整體性能。

圖3 MultiQx-GPU系統PCIe數據傳輸時間線
為了支持高性能的分析型查詢任務,數據庫系統通常采用列存儲的數據格式,以減少掃描等查詢操作在單條記錄上的執行時間[11]。比如SQL語句中的where語句,通常會解析后生成進行列掃描的SQL操作,其特點是在某一列的所有數據上做同樣的操作,符合向量計算模型。如果利用GPU的高性能并行計算能力來執行此掃描操作,其執行效率能夠得到數量級的提升。
2 系統設計與實現
2.1 系統架構
HyperQx-GPU系統整體上采用C/S架構的設計。在查詢任務端,利用動態鏈接庫的設計達到系統對查詢任務進程透明的效果,不會侵入查詢任務的代碼邏輯。查詢進程通過動態鏈接庫與數據庫服務進程直接通過IPC機制通信,保證了具體查詢任務進程和數據庫服務進程之間的低耦合性,使得系統具有良好的可擴展性。HyperQx-GPU的系統架構如圖4所示。
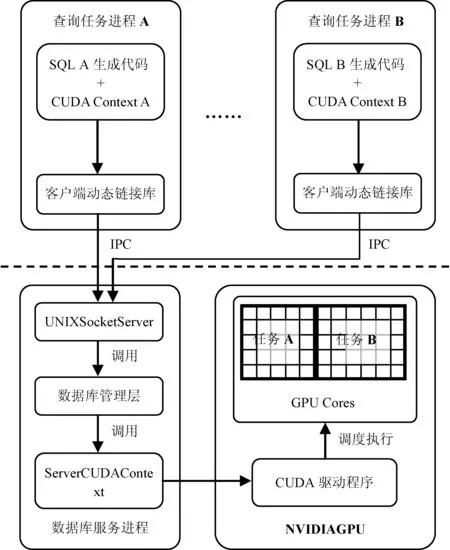
圖4 HyperQx-GPU系統架構
由于CUDA編程框架的異構性,HyperQx-GPU系統架構從總體上也分為CPU和GPU運行的兩部分。其中CPU部分進一步分為查詢進程和數據庫服務進程;GPU部分主要包括SQL操作符的kernel實現,由數據庫服務進程進行加載和調用。
? 查詢進程 查詢進程包括兩部分。第一部分由SQL查詢語句請求生成,將解析后的SQL語法樹與數據庫schema結合起來,編譯成控制數據讀取和調用SQL操作符的CPU宿主程序。該宿主程序負責根據SQL查詢語句邏輯,調用相應的CUDARuntimeAPI控制整個查詢任務的邏輯流程。第二部分為與數據庫服務進程進行IPC通信的客戶端動態鏈接庫,利用動態鏈接庫攔截技術攔截了到CUDA動態鏈接庫libcudart的調用,將CPU宿主程序中包含的CUDARuntimeAPI調用映射為到服務進程的IPC調用。
?服務進程 數據庫服務進程通過監聽Unix Domain Socket來接收查詢任務端通過動態鏈接庫發起的IPC請求,調用數據庫管理層的函數進行實際的GPU查詢任務執行和資源調度等任務,并將結果返回給查詢任務客戶端。數據庫的核心管理層包含列存儲數據共享、GPU硬件管理和kernel調用等核心服務的邏輯,以函數庫的形式向服務進程提供數據庫管理功能。
服務進程采用多線程的架構,使用獨立的線程來服務不同查詢任務進程的請求,以降低不同任務的相互影響,同時可以方便地支持并發查詢,具有很好的可伸縮性。并且,使用多線程架構使得某一個任務的失敗不會影響到系統中正在執行的其他任務,起到了查詢任務隔離效果,同時系統的整體邏輯也更加清晰。
2.2 系統設計與實現
本節將詳細介紹HyperQx-GPU系統中兩個核心功能——共享CUDAContext和共享數據庫列存儲數據的設計與實現,并闡述該實現方式的優勢。
2.2.1 共享CUDAContext
在數據庫系統運行的所有查詢任務間共享服務進程中的CUDAContext,用于發起所有的GPU調用,是HyperQx-GPU系統的核心設計之一。該設計使得查詢任務的CUDARuntimeAPI調用能夠被數據庫服務進程統一管理,節省了每個查詢任務進程需要單獨創建CUDAContext的開銷,提高了GPU的整體資源利用率。
HyperQx-GPU服務端進程初始化時會創建一個CUDA Context,作為整個數據庫系統生命周期中,調度GPU資源的全局唯一環境。當查詢任務啟動時,由于其CUDA Runtime API調用被動態鏈接庫攔截,并不會觸發CUDA隱式創建CUDA Context的機制,而是通過數據庫服務進程使用全局唯一的CUDA Context,節省了每個查詢進程單獨創建所消耗的時間。
為了使每個查詢任務進程之間的CUDARuntime-API調用互不阻塞,服務進程在啟動每個查詢服務線程時,會在CUDAContext中創建一個單獨的stream,用于發起該查詢進程請求的GPU調用。不同stream上進行的CUDAAPI調用不會相互阻塞,會被GPU并發調度執行,因此可以同時進行不同查詢任務的PCIe數據傳輸和kernel調用,充分利用GPU資源。
2.2.2 共享列存儲數據
HyperQx-GPU系統的另一個核心設計是實現了跨查詢任務的列存儲數據共享機制:多個查詢任務如果使用了相同的列存儲數據,服務進程會根據當前的系統狀態決定通過PCIe總線傳輸數據到GPU內存或者復用已經存在于GPU內存的數據。下面將詳細介紹該機制的行為和實現。
服務進程在初始化時,會將數據庫的列存儲數據預加載到內存,并生成數據表中列的名稱到內存地址空間的映射表。當查詢任務進程需要訪問特定列的數據時,會通過客戶端動態鏈接庫進行IPC請求,服務進程則根據請求中的數據表名和列名,返回該列對應的內存地址作為后續操作的句柄。由于列存儲數據只存在于服務進程的內存地址空間,因此查詢任務進程無法通過該地址直接訪問或修改數據庫的列存儲數據,起到了隔離效果。
當查詢任務發起列存儲數據從CPU內存到GPU內存的傳輸請求時,服務進程會查看當前映射表中該列的使用情況。若該列尚未被使用過,則分配相應的GPU內存空間,將該列存儲數據通過PCIe總線傳輸到GPU內存,然后將映射表中該列的使用進程數設置為1,并返回GPU內存地址給查詢任務進程。若該列存儲數據已經存在于GPU內存中,這時候將映射表中該列的使用進程數加1,然后直接返回該列存儲數據的GPU地址。該查詢任務中,后續對該列的使用便可以直接使用已經存在于GPU內存的列存儲數據,達到了共享列存儲數據的目的,節省了PCIe傳輸開銷。當查詢任務結束時,服務進程會從列存儲數據映射表中將該查詢任務用到的所有列存儲數據減去1。極端情況下,當GPU內存空間不足時,若某個列存儲數據的使用進程數為0,則該列存儲數據占用GPU內存空間可以被暫時釋放,之后再次使用時再重新傳輸到GPU內存。
通過上述的列存儲數據共享機制,HyperQx-GPU系統節省了每個查詢任務需要進行的列存儲數據的PCIe傳輸,提升了系統的整體性能。
2.3 系統執行流程
本節以一個具體的SQL查詢為例,詳細描述HyperQx-GPU系統處理查詢請求的主要執行流程,從而展示系統各個功能模塊之間的關系和交互行為。如下流程描述中,編號由小到大表示時間順序。
(1) 啟動數據庫系統服務進程,該進程會創建CUDA Context,并根據啟動參數datadir,修改文件夾預加載列存儲數據到系統內存,然后監聽查詢請求。(2) 用戶向數據庫系統提交了如下的SQL查詢語句:SELECTSUM(lo_extendprice*lo_discount) AS revenue FROM lineorder,ddate WHERE lo_orderdate=d_datekey AND d_year=1993 AND lo_discount>=1 AND lo_discount<=3 AND lo_quantity<25。(3) 數據庫查詢前端模塊先將SQL字符串解析成SQL語法樹,然后結合數據庫表的schema生成包含SQL操作符對應kernel調用的CPU宿主程序代碼,代表查詢任務的實際邏輯——在本例中會生成列掃描過濾和表之間的哈希連接等kernel調用。由SQL生成的代碼被編譯成可執行文件后,將LD_PRELOAD環境變量設置為數據庫客戶端動態鏈接庫的路徑,然后執行該文件,啟動查詢任務進程。(4) 查詢任務進程發起的CUDARuntimeAPI調用被客戶端動態鏈接庫攔截,轉化成到服務進程的IPC請求。(5) 服務端接收到新的查詢任務進程的IPC請求后,創建新的服務線程處理來自該進程的后續請求。該服務線程會不斷解析來自同一個查詢任務進程的請求消息體,通過數據庫核心管理層模塊執行相應的資源管理和kernel調用等操作,并將結果通過IPC機制回傳給查詢任務進程。在本示例查詢中,服務進程會保證kernel執行前,lineorder表中用到的4列數據和ddate表中的2列數據已經被傳輸到了GPU內存。如果同時發起該SQL語句的兩個查詢請求實例,后到的請求會復用前一個請求已經傳輸到GPU的列存儲數據,而不進行實際的PCIe數據傳輸。(6) 查詢結果(包括查詢中產生的宿主程序需要的臨時結果)會通過IPC回傳給動態鏈接庫,進而返回給查詢任務進程。(7) 查詢進程完成查詢時,向服務進程發起退出請求,服務進程結束相應的服務線程。
3 實驗設計與測試
3.1 實驗環境
實驗所用工作站搭載開啟Hyper-threading的18核2.1 GHz Intel XeonE5-2695 CPU,和32 GB DRAM系統內存。實驗使用的GPU為NVIDIA TITAN X,包含12 GB內存,以及3 584個時鐘頻率為1 531 MHz的計算核心。該系統的SQL操作符kernel代碼和其余模塊代碼使用NVIDIACUDA Toolkit 9.0和GCC 6.1.0工具鏈進行編譯。工作站運行的操作系統為CentOS Linux release 7.4.1708,Linux內核版本為3.10.0。
3.2 實驗基準數據集與實驗設計
本實驗使用的數據集為MultiQx-GPU采用的標準測試基準數據SSB(Star Schema Benchmark)[12],其中包括13條SQL查詢語句和生成的數據庫數據。該數據集基于TPC-H測試基準并加以修改,在數據庫相關研究中被廣泛運用于測試實際查詢負荷狀態下的數據庫系統性能。實驗使用的數據庫數據由SSB的數據生成工具dbgen生成,并預處理成MultiQx-GPU中使用的列存儲格式,即每個表的每個列會被單獨存儲為一個文件。若表中包含記錄數過多,每個列存儲文件會包含多個數據塊,最終被系統分批載入GPU處理。生成數據時,使用10作為規模放大參數(scalefactor),最終生成的數據表中大約包含6千萬條記錄,占用磁盤空間為4.8 GB。實驗使用的查詢任務共由13條SQL查詢語句組成。由于實驗目的是測試系統的核心模塊性能,為了排除SQL語句的解析和編譯時間,所有SQL查詢語句均被預先編譯成可執行的查詢任務程序。實驗開始時,所有列數據均被預先加載入內存,以避免查詢過程中產生不必要的磁盤到內存的數據傳輸。同時,實驗設定所有列存儲數據和查詢任務執行時產生的中間結果均能在GPU內存中同時存在而不超出內存空間總量。
實驗主要測試內容為驗證共享CUDAContext和共享列存儲數據機制帶來的系統性能提升。參照MultiQx-GPU,本實驗所采用的吞吐量指標為加權吞吐量,定義如下:
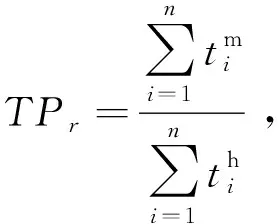
3.3 吞吐量測試
本實驗使用MultiQx-GPU系統性能作為基準,采用查詢任務兩兩并發(包括兩個相同查詢任務并發的情況)的方式,測試HyperQx-GPU系統在共91個(互不相同并發查詢組合78個,相同并發查詢組合13個)查詢任務組合并發執行情況下的相對吞吐量。由于單獨執行一個查詢所用時間較短,且啟動進程等操作會給系統帶來開銷,有可能在第一個查詢任務快結束時,第二個查詢任務才開始執行。為了保證實驗進行時每組中的兩個查詢能同時執行,本實驗實在兩個進程中重復串行地執行兩個查詢任務,以一次查詢任務執行時間內的平均相對吞吐量作為最終的實驗結果。實驗結果數據如圖5和圖6所示。
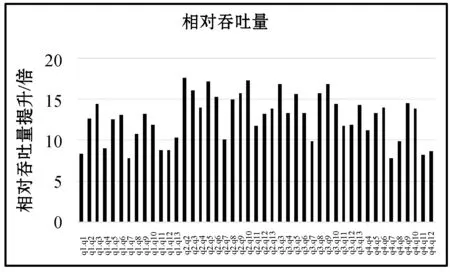
圖5 HyperQx-GPU相對吞吐量提升

圖6 HyperQx-GPU相對吞吐量提升
從圖5和圖6所示的實驗數據可以看出,在HyperQx-GPU系統的新架構下,系統在查詢任務兩兩并發執行的情況下,其查詢請求處理的相對吞吐量平均達到了MultiQx-GPU系統的12.0倍。其中最低的查詢組合為q7和q7并發執行,相對吞吐量達到4.5倍,而最高的查詢組合為q10和q10并發執行,其相對吞吐量能達到19.0倍。本相對吞吐量測量結果表明,與MultiQx-GPU系統相比,HyperQx-GPU系統的性能提升非常明顯。
為了進一步驗證導致HyperQx-GPU系統性能提升的獨立因素,下列兩組實驗將進一步驗證和分析共享CUDAContext和共享列存儲數據兩項改進技術分別帶來的系統吞吐量提升效果。
3.4 共享CUDAContext性能提升驗證
在MultiQx-GPU系統架構設計中,每個查詢任務進程使用CUDARuntimeAPI控制查詢邏輯時,會在第一次調用RuntimeAPI的時候隱式地創建CUDAContext。本實驗測試MultiQx-GPU和HyperQx-GPU系統(關閉列存儲共享功能)執行單個查詢任務的時間。實驗數據如圖7所示。
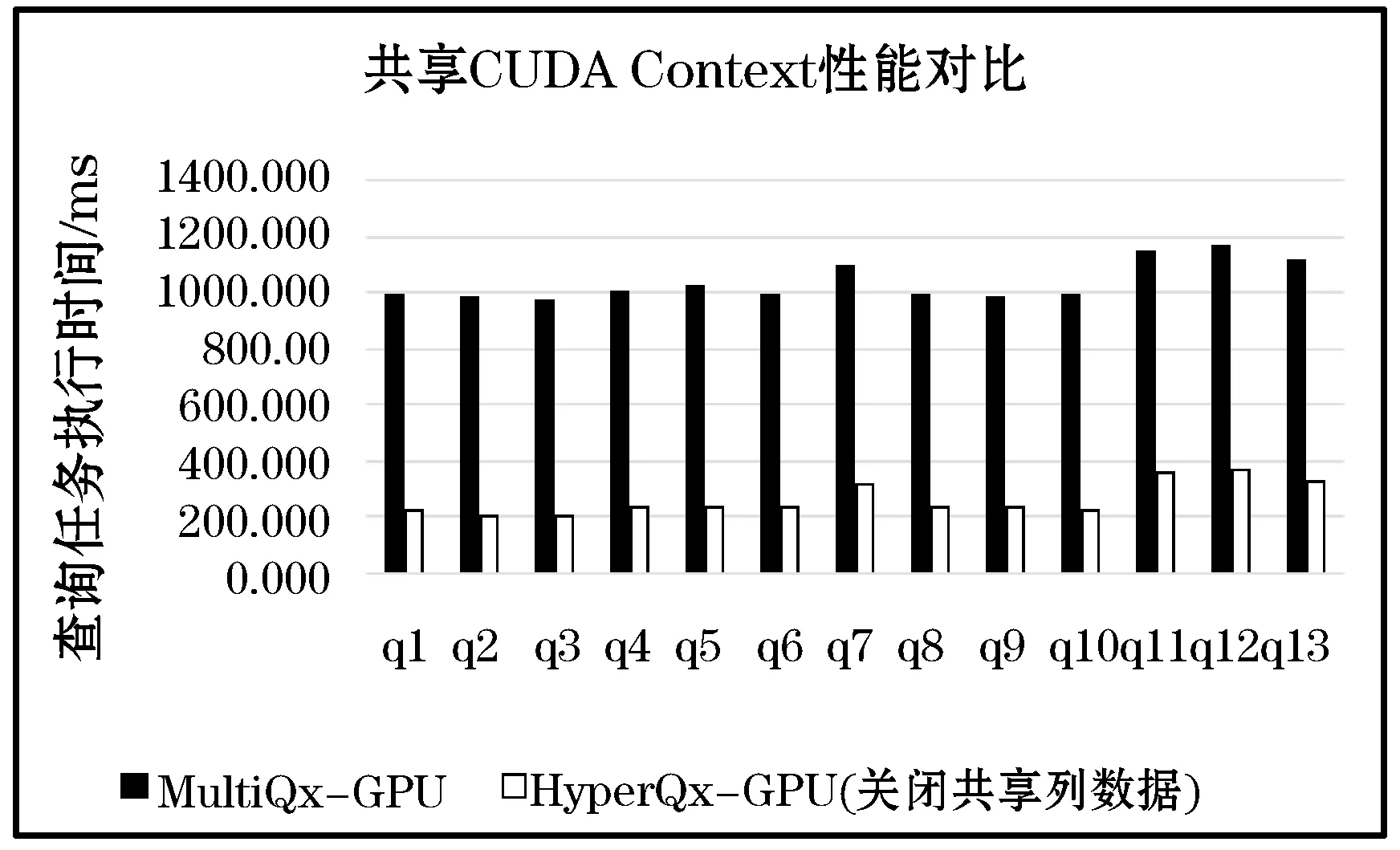
圖7 MultiQx-GPU和HyperQx-GPU關閉共享列數據對比
根據實驗數據,HyperQx-GPU利用共享CUDA Context機制,與MultiQx-GPU相比,平均性能提升(減少執行時間)為75.0%。其中提升最多的為q3查詢,減少執行時間為79.6%;最低為q11查詢,減少執行時間為68.5%。因此,在服務進程中使用全局唯一的CUDAContext進行GPU資源調度,能夠節省在每個查詢進程啟動時的CUDA Context創建開銷,使GPU更多地處于執行計算任務的狀態,從而提升系統的查詢請求響應速度和吞吐量。
3.5 共享列存儲性能提升驗證
為了驗證共享列存儲技術帶來的系統相對吞吐量的提升效果,本實驗測試了全部的13個SQL查詢語句在HyperQx-GPU系統中分別在開啟和關閉列存儲數據共享功能情況下,查詢任務在PCIe總線數據傳輸過程上花費的時間。本實驗采用串行(非并發)的查詢執行情況,以排除其他因素對系統性能的影響。實驗結果如圖8所示。
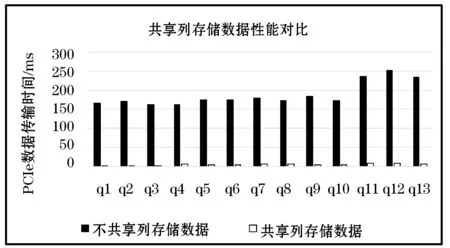
圖8 HyperQx-GPU共享與不共享列存儲數據情況下PCIe總線數據傳輸時間對比
從實驗結果數據中可以看出,支持列存儲數據共享機制的HyperQx-GPU系統能夠大幅地減少PCIe數據傳輸消耗的時間。其中減少時間最多的查詢為q2,減少了98.2%;減少時間最少的查詢為q4,減少了96.4%,平均減少的PCIe數據傳輸消耗時間為97.2%。實際執行查詢任務時,HyperQx-GPU系統能夠根據系統中實時運行的所有查詢任務的信息,重復利用已經傳輸過的數據庫列存儲數據,從而提升系統吞吐量。該實驗證明,共享列存儲數據的機制幾乎能夠消除查詢任務執行時的PCIe數據傳輸瓶頸,為進一步的系統優化提供了有力支持。
4 結 語
本文發現并分析了已有GPU數據庫系統均存在的GPU整體資源利用率低的缺陷。在此基礎上,本文提出并實現了HyperQx-GPU系統。該系統設計并實現了新的軟件架構,通過共享CUDAContext節省了查詢任務執行時間,使用共享列存儲數據方案減少了查詢任務中的PCIe數據傳輸量,優化了GPU資源利用率。本文通過實驗測試,分析了以上兩個關鍵技術分別帶來的系統性能提升。實驗結果表明,HyperQx-GPU系統在MultiQx-GPU系統的基礎上,提升GPU數據庫處理并發查詢請求的平均相對吞吐量達到了12.0倍。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中國外匯(2019年20期)2019-11-25 09:54:58
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
財經(2017年2期)2017-03-10 14:35:35
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
民主與科學(2014年3期)2014-02-28 11:23:03
