處理Java程序不確定性問題的技術研究和綜述
2018-08-15 08:02:30季曉楓宋昶衡
計算機應用與軟件 2018年8期
季曉楓 宋昶衡 李 弋
(復旦大學軟件學院 上海 201203) (上海市數據科學重點實驗室(復旦大學) 上海 201203)
0 引 言
隨著硬件的發展,小到個人計算機大到數百上千核的超級計算機,多核處理器已經十分普遍。為了能夠充分利用多核處理器性能,并行程序變得越來越流行,并開始占據了主流的地位。
然而,與單線程程序不同,并行程序并不能保證每一次的執行與之前的執行從結果和性能上都完全相同。在多核處理器上執行并行程序的過程中,搶占式的線程切換使得程序在不同的運行過程中,線程的調度過程都是不確定的行為。而在多核處理器上,對共享變量的訪問更是加劇了程序的不確定性。在不同的執行循環過程中,共享變量訪問的讀寫依賴關系也是無法確定的。由于每次執行時共享變量的放回值都可能變化,這導致程序的運行路徑在多次的執行之間也可能是不同的。
而在Java虛擬機上,這一不確定性變得更為顯著。Java語言在過去的十數年中一直是最受歡迎的語言之一。Java受歡迎的一個非常重要的原因就是Java可運行在虛擬機上,保證了Java程序的可移植性,獨立性以及安全性。然而,在Java虛擬機中的使用的許多機制都會給Java程序的執行帶來不確定性,這其中包括了即時編譯器、垃圾收集等。即時編譯器通過對程序的采樣分析決定對哪些方法進行優化,垃圾收集機制的觸發也是在運行時決定的,這些機制在Java虛擬機中都由額外的線程來完成。這使得即使是單線程的Java程序,其不確定性也會比C或者C++程序來的更為顯著。圖1展示了Java的多線程程序測試集DaCapo的性能結果不確定性。圖中黑色方塊代表了變異系數的區間。其中,變異系數最大的sunflow達到了12.12%,平均變異系數達到了6.87%。由此可見,不確定性在多線程Java程序中表現得非常明顯。
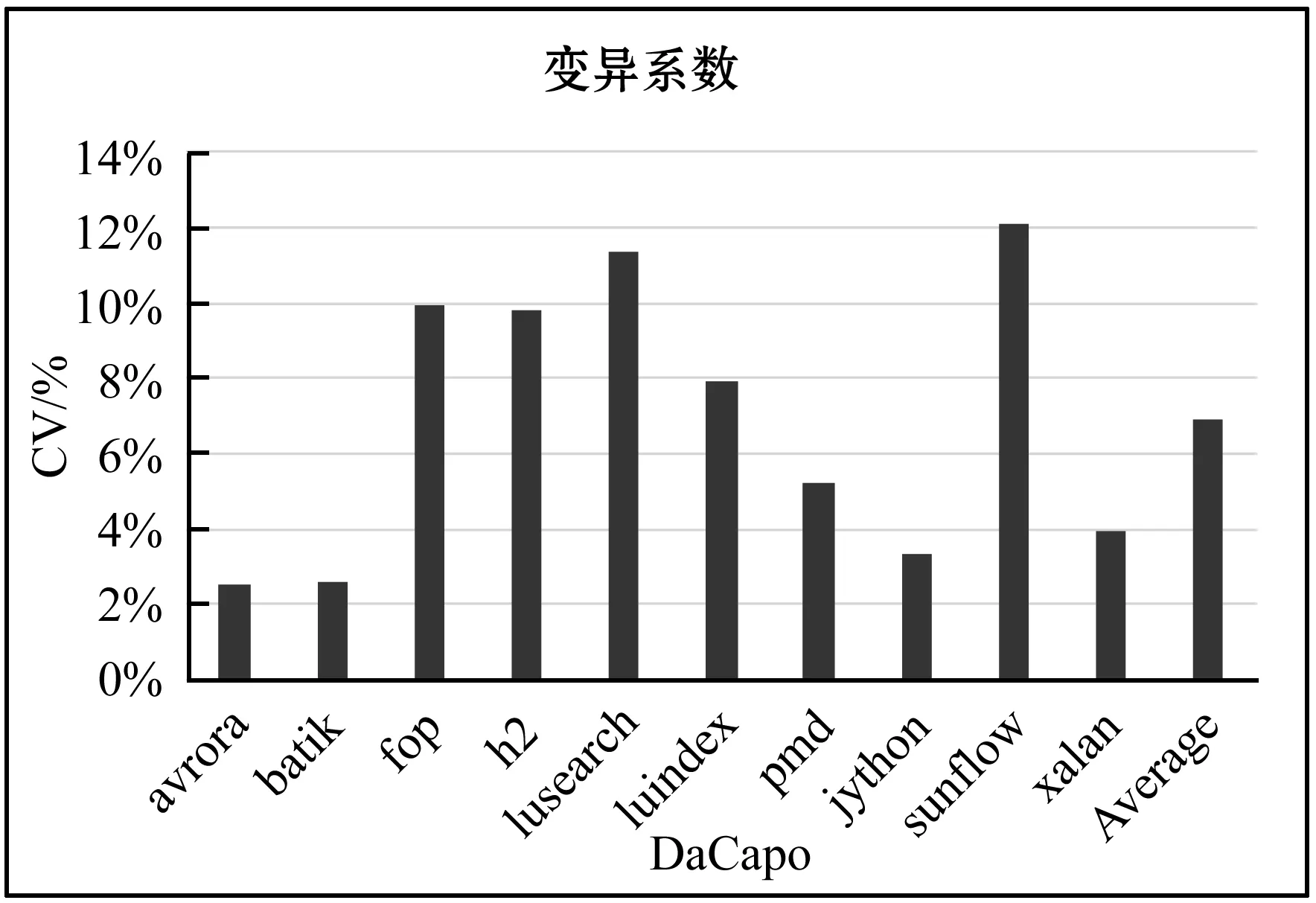
圖1 DaCapo測試集的不確定性
程序的不確定性會給許多原本看似簡單工作帶來新的問題。并行程序的不確定性主要是由于其本身的路徑不確定性所產生的,而路徑的不確定性會給許多相關工作帶來問題。首先,這會很大程度上影響性能評估的工作,路徑的不確定性會導致性能的不穩定。當研究人員要評估性能結果的優劣時,受到程序不確定性的影響,簡單地取均值的方法就不再適用,簡單的方法難以總結和描述程序的性能表現。其次,路徑的不確定性會給錯誤調試帶來很大的挑戰。在進行循環調試的時候,如果不能每次都重現錯誤發生的過程,就會使得調試變得非常困難。
本文首先分析了Java虛擬機內部會給程序帶來不確定性的原因,并對于不確定性在性能評估和錯誤調試方面造成的問題進行了分析。在此基礎上,本文從處理帶有不確定性的性能數據以及控制程序不確定性的技術兩個方面對處理Java虛擬機性能不確定性的方法進行了總結。此外,在不確定性程序的錯誤調試方面,本文對解決這一問題的常見確定性重放技術進行了分析和總結。最后,本文對適用于這兩個問題的常見的框架的技術思路進行了分析和比較,對于處理Java虛擬機不確定性的技術發展的未來可能的發展方向進行了展望。
1 Java程序不確定性造成的問題
Java程序的不確定性問題所帶來的影響主要包含兩個方面:(1) 性能結果的不確定性對于性能分析的影響;(2) 路徑不確定性對于對錯誤調試的影響。本節首先將對產生不確定性的因素進行總結,然后將分別對這兩個方面影響進行分析。
1.1 多線程程序的不確定性
Java多線程程序本身的多線程執行就會給程序帶來不確定性。首先,線程的調度不能保證在每一次的執行中,每個線程的調度順序都完全一致。其次,在有些多線程程序中,工作并不會均勻地分配到每一個線程中去,比如,在多個線程競爭訪問任務隊列的時候,每次程序的執行,各個線程所完成的工作都是隨機的。最后,線程遷移和訪問共享資源的競爭都會增加多線程程序在執行過程中的不確定性。
1.2 Java程序的不確定性
除了多線程執行本身的不確定性之外,在Java虛擬機中,也有許多部分會對于程序性能產生影響,大致包括以下幾個部分:即時編譯器、線程調度、垃圾收集機制以及其他的一些系統因素。
(1) 即時編譯器 Java程序在運行前被保存為字節碼的形式,Java虛擬機可以解釋執行字節碼狀態的程序,但是這樣做的效率非常低。于是Java引入了即時編譯器。即時編譯器通常會對程序進行采樣分析,尋找程序中的熱點,當程序中的某個方法成為了熱點之后,即時編譯器會對該方法進行優化編譯。由于并行程序本身的不確定性,在多次執行中,觸發即時編譯器的方法的順序并不會是固定的,這就會導致程序在不同執行循環中的性能變化。此外,即時編譯器本身作為Java虛擬機中的一個或多個線程進行工作,同樣會增加程序的不確定性。
(2) 線程調度 和其他并行程序一樣,Java并行程序的線程調度也是程序不確定性的來源之一。Java虛擬機會直接對線程進行調度,或者對線程進行封裝之后交由系統來進行調度。在不同的執行循環中,程序可能經過了完全不同的調度,導致線程之間不同的交互,最終對性能產生影響。
(3) 垃圾收集 垃圾收集機制在Java虛擬機中同樣由額外的線程實現,大部分垃圾收集器在執行過程中還會將Java程序暫停。此外,垃圾收集的過程也會對程序的不確定性造成影響,這取決于使用的垃圾收集機制是確定性的或者是非確定性的。
此外,其他的一些系統因素,比如系統中斷,外部IO也會增加程序的不確定性。
1.3 不確定性對于性能評估的影響
傳統的性能評估方法大致包含了取平均、取中位數、取最好值、次好值以及最差值等幾種[1]。當研究需要獲得性能測試的平均結果時,取平均數和中位數是比較好的選擇。取最佳值和最差值是兩種比較特殊的方法。取最佳值法通常用于尋找類加載和即時編譯器等虛擬機系統行為對Java程序影響最大的情況下的性能,而與之相對應的,取最差值法是用于尋找類加載和即時編譯器對程序運行影響最小的情況下的性能。
以上這些性能評估方法給出的結果都是單一的數值表示。但是,由于Java程序的不確定性,多次運行的Java程序的性能結果會有不同幅度的波動。僅僅用一個數字來代表程序的性能沒有辦法完整的描述Java程序的性能。比如Java程序性能的波動范圍以及在相應范圍上的分布都是一個數字所無法描述的。這時,就可以使用置信區間來進行描述。置信區間可以表示出Java程序性能的波動范圍,給出程序性能落在某個區間上的概率。假如程序結果的分布是正態分布的話,置信區間配合變異系數可以很好地描述Java程序的不確定性。然而如果Java程序不是正態分布的話就需要配合其他的方法來對程序結果進行描述。
對于程序的性能評估來說,如何在更少的測試時間內得到更精確的結果是這個問題的主要研究方向。
此外,對于Java程序的性能評估來說,不同的階段會有不同的不確定性影響因素。如果在一次啟動Java虛擬機的過程中多次循環運行一個程序,那么前幾次循環的性能會受到動態類裝載和即時編譯器非常大的影響。而在之后的循環中,程序性能的波動幅度,也就是變異系數會逐漸穩定,在評估Java程序的性能是要將這兩種狀態下的性能區分開來評估,分為啟動狀態和穩定狀態[2-3]。
1.4 路徑不確定性對錯誤調試的影響
由于并行程序在執行過程中的存在路徑不確定性,這對錯誤調試帶來很大的麻煩。路徑不確定性對于錯誤的影響主要在于線程切換和同步,以及對共享變量訪問的依賴關系。在不同的執行循環中,搶占式的線程切換以及線程同步都會導致不同的線程調度結果。這兩個因素,同共享變量的不同訪問順序一起,造成了程序執行路徑的不同。而在并行錯誤調試的過程中,對于內存訪問順序的重現在解決死鎖、數據競爭等問題時又是至關重要的。如果對一個共享變量的訪問順序發生了變化的話,很可能程序就不會再進入死鎖狀態。
確定性重放技術分為兩個階段:(1) 記錄階段,在記錄階段,確定性重放的工具會記錄程序一次運行中的信息,并存放到文件中;(2) 重放階段,工具會讀取記錄到文件中的信息,并按照記錄的運行軌跡重現之前程序的運行路徑。
一般而言,記錄階段需要記錄程序中所有的不確定因素,這樣才能確保在重放階段時的執行路徑和記錄的那次運行一模一樣。然而,隨著多線程程序的規模變得越來越龐大,其中用到的共享變量訪問越來越多,完全記錄所有的不確定性信息變得越來越不現實。所以,現今對于確定性重放的研究主要目標就是降低記錄階段的開銷,減小記錄階段用到的日志文件大小。
此外,對于Java程序而言,錯誤也可能發生在虛擬機內部,比如即時編譯器或者垃圾收集階段,所以也有研究針對Java程序的機制做了確定性重放的工具,比如Ogata[21]等的工作。
2 處理性能不確定性
在對Java程序進行評估的過程中,Java程序的不確定性會帶來很多問題。
首先,在JVM的一次生命周期中運行多次Java程序循環時,即時編譯器、類裝載等因素會使得初始的多次運行的行為表現與之后的運行截然不同。如何對這兩種狀態進行劃分并且分別進行性能評估是進行Java程序評估時非常重要的一點。
其次,由于Java多線程程序的不確定性比一般的多線程程序更為復雜,如何使用更少的運行遍數進行性能評估也是亟待解決的課題。
1.2.1 細胞培養及分組 將SK-N-SH人神經母細胞瘤細胞接種于含10%胎牛血清、100 U/mL青霉素、100 mg/L鏈霉素的RPMI1640培養液中,于37℃、5%CO2的常規培養箱培養。2~3 d換液,0.25%胰酶消化傳代,觀察細胞生長情況,取對數生長期細胞用于實驗。實驗分為不同濃度螺內酯組和對照組,螺內酯組加入配置好的螺內酯溶液,終濃度分別為5、10及20 μmol/L,不加藥的為對照組。
2.1 利用統計學處理性能不確定性
由于即時編譯器以及類加載機制的存在,在利用統計學處理Java程序的不確定性時首先需要劃分出啟動狀態下和穩定狀態下的Java程序結果。其后,可以對這兩種狀態下的結果使用統計學的方法進行相應的處理。
Java程序的不確定性會使得程序的結果分布在一個區間上。當這些結果在區間上的分布呈現正態的時候,可以簡單地使用置信區間來描述程序的性能,并使用參數檢驗來比較兩組數據的性能。但是,當程序的性能結果分布呈現非正態的時候就需要使用非參數檢驗來判斷兩組數據的性能優劣。
(1) 對正態分布數據的處理 正態分布,又稱高斯分布,以平均數為中心左右對稱,向兩邊逐漸均勻下降。正態分布是最常見的分布之一,而且使用很簡單的參數就能夠對該分布進行描述。此外,最重要的是,根據中心極限定理,即使是非正態分布,大量獨立同分布的隨機變量的平均數是正態分布的。這給了研究者使用正態分布來對多線程程序性能進行描述的機會。
Georges等[1]綜合了一系列的統計學方法,提出了一種嚴格的統計學測試框架,用來評估Java程序性能。這種框架針對啟動狀態和穩定狀態分別做了處理。
首先是啟動狀態,啟動狀態的性能會受到類加載,即時編譯器等因素的影響。針對啟動狀態,Georges等提出的方法如下:測量啟動狀態的Java程序性能需要多次啟動虛擬機,每次只運行程序一遍,記錄其運行時間。然后根據指定的置信度計算其置信區間。對于啟動狀態性能的比較,可以使用z檢驗或者t檢驗來實現。
其次,是穩定狀態的性能評估。穩定狀態時由于程序已經運行過一段時間,受到即時編譯器的影響比較少,也幾乎不會收到類加載的影響。為了測量穩定狀態的性能,首先要確定程序的運行在什么時候進入了穩定狀態。Georges等[1]使用在一次虛擬機的生命周期中多次運行一個比較短的Java程序的方法來模擬長期運行的Java程序。他們提出的方法如下:假設整個測試同樣要運行p次虛擬機周期。在每個虛擬機的生命周期中,循環運行Java程序q次。在程序循環運行了k次之后,計算最后k次運行的變異系數,當變異系數小于預設的閾值時,則認為該k次運行都達到了穩定狀態,記錄其結果。計算每次虛擬機生命周期中的k次穩定狀態運行結果的平均值,那么這q個平均值就構造了一個新的性能結果分布。計算這個新的分布在指定置信水平上的置信區間,用該置信區間來評價程序在穩定狀態中的性能。
在評估穩定狀態性能的過程中,之所以需要記錄多次虛擬機運行中的數據,而不是在虛擬機的一次運行中就多次循環把所有數據都跑完,是為了保證最終結果的正態分布性。在虛擬機每一次的運行中,多次循環后的k個結果之間并不是獨立的,但是多次虛擬機的運行之間是互相獨立的,所以基于中心極限定理,取每次虛擬機運行的k個結果的平均值就能夠得到一個獨立的結果分布。
隨后Kalibera等[4]為了提高性能評估的效率,針對性能評估的各個階段提出了一系列的建議,用以減少性能評估中的重復次數,并在合理的時間內完成性能評估。他們提出了一種新的識別穩定狀態的方法。這種方法通過識別程序的運行是否進入“獨立”狀態來判斷循環是否已經穩定。“獨立”狀態意味著程序這次的運行與之前的循環無關。該方法利用了Lag圖、ACF圖和運行序列圖,幫助研究人員根據這三種圖來進行人工判斷。通過這種方法,可以快速地判斷一個程序是否進入了“獨立”的狀態。Kalibera等[4]認為,對于沒有在較短的時間內進入“獨立”狀態的程序,建議選取多次虛擬機生命周期中初始化狀態之后的第一次循環作為性能評估的對象。而對于每次虛擬機運行中的初始化狀態,同樣用人工識別的方法,對運行序列圖進行觀察并選取,這個工作也能在數秒內完成。
除此之外,Kalibera等[4]還評估了Java程序在虛擬機運行內部循環時和多次虛擬機運行間的性能波動幅度,并且發現有一些程序在虛擬機運行間的波動性遠大于內部循環時的波動性。由此提出,對于類似的程序可以減少內部循環的重復次數,增加虛擬機的運行次數,而對于特性相反的程序就可以減少虛擬機運行的次數,增加內部循環數,減少由于虛擬機重新啟動所需的熱身時間。
與文獻[1]之前的方法進行比較,之前的方法對于達不到“獨立”狀態的程序并不適用,而文獻[4]通過對于性能評估中的多個重復周期加以區分,在不確定性較小的層次中減少重復次數,并且引入了人工的階段識別,提升的性能評估的整體效率。
(2) 對非正態分布數據的處理 多線程程序的運行時間分布大多不符合正態分布。為了能夠使用置信區間來表征程序的性能,前文提到的方法利用了中心極限定理使得收集到的數據能夠呈現正態分布,但是中心極限定理要求上百個運行結果,才能足夠構成正態的平均值分布[5]。
Chen等[5]提出了一種利用非參數統計方法的框架,用于利用更少的程序運行遍數來獲取準確的性能比較數據。這種方法利用了Wilcoxon秩和檢驗,使用Wilcoxon秩和檢驗可以在給定的置信水平上判斷兩組運行數據的性能差距是否顯著。在判定加速比的時候,將一邊的數據乘以預計的加速比,再使用非參數檢驗的方法就能判斷這個加速比是否成立,最后通過緩慢調整加速比得到最好的結論。這種方法既可以用于評估單個程序在兩種架構上的性能,也能應用于用整個測試程序集評估架構的性能。
這種方法的好處是在實驗數據有限的情況下也能夠得到一個可能比較保守但是正確的結論,與簡單的計算平均值相比置信水平和加速比的準確性都有大幅度的提高。
2.2 控制不確定性變量
為了控制Java程序的不確定性在性能評估時的影響,除了利用統計學方法對性能測試結果進行處理之外,還有另一種思路,即對程序的運行過程中的變量進行控制。
Charlie等提出了Stabilizer[6]。程序在運行時,堆棧和代碼的分布等因素都會受到架構的影響,這些不確定因素使得程序的性能結果未必會呈現正態分布。
Stabiilizer對于多個層面的不確定因素都進行了包裝,并且主動進行與結構層面的無關的隨機化。在堆中,Stabilizer會根據隨機函數,給新的動態內存請求分配指定的位置。代碼塊同樣會被隨機地存儲在堆上。在每個函數內部Stabilizer都會插入一個trap指令,在運行到這個指令的時候就會根據隨機函數將代碼塊在堆上進行分配。對于棧的隨機化,Stabilizer在每個棧幀之間都會插入一個隨機大小的空白塊,最大不超過4 096比特,用來保證每個函數的棧都是隨機的。
此外,程序每運行過一段時間,都會對所有層面重新進行一次隨機化。這樣,根據中心極限定理就能確保這些因素對于程序的影響是符合正態分布的。在確保了程序結果的正態性之后,就可以用方差分析等方法對程序的性能結果進行分析。
Chen等[7]利用符號執行建立了一個Java程序性能分布的概率模型,并將這個模型上的性能結果分布進行了可視化。
在符號執行的過程中,根據輸入集中的權值以及相應的輸入,計算程序執行某一分支路徑的概率。之后通過對這些輸入進行測試執行,得到的加權平均值就是該路徑的性能。在完成符號執行的搜索之后,就能獲得該程序的性能分布模型。
這一方法的能夠獲得比較完整的程序性能分布,但是所受的限制也比較多。首先,暫時還不支持不確定性多線程程序,Luckow等[8]正在嘗試實現多線程的版本。其次,該方法的性能模型仍然不夠完備,沒能把太多的體系結構因素考慮進去。
3 處理路徑不確定性
正如前文所提到的,Java程序的不確定性多除了對性能的評估造成了影響之外,對于錯誤調試也會造成很大的干擾。
程序的錯誤調試經常需要多次循環執行程序并重現錯誤來解決問題。但是多線程程序的不確定性使得程序即使多次循環也未必能夠重現錯誤執行的路徑并將錯誤重現。在JVM虛擬機上執行時,不確定性的問題也顯得更為嚴重。本節將針對Java程序的確定性重放技術進行總結和綜述。
早期Java程序的重現方法著重于確保相同的線程切換順序以及相同的程序狀態。比如DejaVu[9]、JaRec[10]和ReVirt[11]等,這些框架適合用于單核機器上的確定性重現。
DejaVu會記錄并重現每次線程切換,包括同步操作和搶占式的切換。DejaVu確保在重放時能夠切換到正確的線程,并且在切換后程序的狀態與記錄階段的狀態相同。此外,為了處理插樁對于程序性能的影響,DejaVu還會記錄框架本身所有對于Java程序有影響的操作,并在重放過程中復現這些操作,確保重放與記錄的一致性。
JaRec同樣只記錄Java程序中的同步操作,它利用了Lamport邏輯時鐘來記錄每一次線程同步的邏輯順序,在重放的時候只需要讀取記錄文件中的邏輯時鐘就能實現同樣的線程切換和同步的順序。JaRec使用JVMPI實現插樁。重放的程序所需時間是與原程序的1.5倍到39倍不等,這一比率取決于同步操作的數目。與DejaVu相比,JaRec可以在多核平臺上使用。
此外,Ronnse[12]等和Choi等[13]也實現了利用邏輯時鐘的重放框架。隨著多線程程序變得越來越龐大,僅僅記錄線程的切換行為并不足以完成并行程序的重放,性能也越來越差。如何將對共享內存的訪問記錄下來并重現成為了確定性重放技術的新難題。為了解決這一問題,研究人員提出了許多技術來對記錄階段進行優化,工作主要集中于如何減少記錄的事件數,這樣既能降低記錄階段的開銷,也能減少記錄文件的大小。
3.1 對記錄階段的優化
傳統的確定性重放技術會記錄程序所有不確定性操作,并記錄下他們的全局順序以便之后的重放。但這會導致在記錄階段需要許多同步操作來確定事件的順序。
Leap[14]對這一現象進行了優化。Leap記錄每個共享變量的線程訪問順序,而不是記錄共享內存的全局訪問順序。通過這個方法,降低在記錄階段的開銷。Leap首先通過Java程序的靜態分析框架Soot找出在運行中會產生多個線程訪問的共享變量,然后在運行時記錄每一個共享變量的線程訪問序列。在重放時,重放引擎會強制程序按照記錄的線程訪問隊列執行。Leap通過Soot實現,經過測試,其記錄階段的性能比傳統的邏輯序列,全局序列要快5~10倍。
其后的Order[15]、CARE[16]、Ditto[17]都對記錄階段的局部性做了優化,提升記錄階段的性能。
Order框架同樣記錄了共享變量的線程訪問序列。Order框架的記錄以Java中的對象為單位,將訪問記錄放在對象的頭部,這樣能減少垃圾收集時產生的依賴關系對記錄的影響。此外,將對共享內存的訪問信息存放在對象的頭部,能夠提高記錄階段的局部性。最后,Order還會記錄一些Java獨有的導致不確定性的因素,其中包括了垃圾收集,動態編譯以及類的初始化等操作的時間點,從而能夠重現Java虛擬機內部產生的錯誤。相對于正常運行的程序,基于Apache Harmony實現的Order記錄階段的平均額外開銷為8%,比Leap快1.4~3.2倍。
CARE提出了一種減小記錄階段所需的日志文件大小的技術。CARE為每個線程都添加了一個的共享變量的軟件緩存,只有當讀操作返回的值與緩存中的值不同時,CARE才會記錄下這次讀操作的讀寫依賴關系,通過這種方法能減少需要記錄的條目。CARE基于JVMTI進行插樁。相比于LEAP、CARE的記錄開銷是LEAP的38.47%,日志文件是LEAP的20.41%。
此外,Ditto也是一種記錄對共享變量的線程訪問順序的框架,Ditto利用邏輯時鐘來保存不同線程上內存訪問的順序,同時利用偏序關系的傳遞性減少需要記錄時的日志文件大小。Ditto也同樣利用了Soot靜態分析框架來區分局部變量和全局變量,對記錄過程進行優化。
除了記錄足夠的讀寫順序之外,還有一些方法減少了記錄的信息,并在重放階段對程序的執行路徑進行推斷,如ODR[18]、CLAP[19]和 PRES[20]等。這些方法通常只能保證重放階段的部分精度。
Stride[21]將兩種方法進行了融合,這一框架在記錄所有讀寫關系順序的方法和對程序路徑進行搜索的方法之間進行了權衡,使用Java Soot實現。Stride不會記錄所有確切的讀寫關系。對于每次讀操作,它會記錄對于這個變量最近版本的寫操作,這個寫操作在之后確定具體讀寫聯系的時候就是搜索時的上界。相比傳統的記錄順序的方法,Stride在記錄時能夠減少許多同步操作。與Leap相比,Stride在記錄階段快2.5倍,記錄文件小,是LEAP的25.77%。
3.2 在特殊虛擬機環境下進行確定性重放
為了一些特殊的目的,比如安全性的要求,或者為了降低確定性重放的難度,一些確定性重放技術通過定制的虛擬機環境進行實現,比如ReVirt[11]、SMP-ReVirt[22]和TDR[23]。
ReVirt框架在一個自己實現的虛擬機上進行記錄和重放,這樣能夠移除程序對于外部操作系統的依賴。ReVirt的重放機制與前文所述的框架類似,只適用于單核上的多線程程序。
SMP-ReVirt基于Xen實現了多核模擬器上的確定性重放。SMP-ReVirt利用了并發讀、單獨寫(CREW)的協議來控制虛擬機對于共享變量的訪問,然后通過硬件頁保護來確定讀寫的順序。
TDR為了能夠在進行確定性重放之外,還能確保程序的執行時間與原來的運行相同,在虛擬機上實現了確定性重放功能。為了使得記錄和重放的環境不受干擾,TDR重新實現了一個Java虛擬機,在這個虛擬機上盡可能地排除了系統因素對程序的影響,達到干凈狀態。除了虛擬機之外,TDR還需要另一個核心來幫助虛擬機執行IO和中斷等操作。由于這個虛擬機暫時只支持單核執行,TDR所使用的重放方法是傳統的記錄線程切換的方法。在同樣配置的兩臺機器上進行記錄和重放,TDR能夠讓運行時間的誤差保持在1.85%之內。TDR的虛擬機并沒有垃圾收集和動態編譯的功能。
3.3 針對Java具體機制的確定性重放
Java虛擬機中,即時編譯器在每次運行時的行為都是不確定的。為此,Ogata等[24]實現了動態編譯的重放。這一框架由兩個即時編譯器組成,記錄階段用的編譯器會在每次進行動態編譯的時候將編譯器收到的所有輸入,包括系統配置、虛擬機狀態和分析數據存儲到日志文件中。這些記錄信息會在系統轉儲時寫入其中,重放編譯器工作時會將系統轉儲文件載入地址空間,然后讀取日志文件作為編譯器的輸入,進行動態編譯的重放。這一框架在記錄階段的開銷只有1%,日志文件非常小。
3.4 根據路徑特征信息進行不確定性分析
VarCatcher[25]通過記錄程序的路徑特征,對齊并進行處理之后得到并行特征向量(PCV)。通過對多次運行的并行特征向量進行聚類處理,可以得到路徑類似的運行結果。得到運行路徑相似的運行結果之后可以實現和確定性重放類似的效果。此外,通過對于并行特征向量的處理,可以對程序在不同路徑下的性能結果進行更深入的分析。利用Intel Processor Trace機制,該框架在記錄階段只有3%的額外開銷。
4 分析與展望
本節我們將對上文提到的各類不確定性處理機制進行比較和分析,并對未來可能的發展方向進行了展望。
4.1 分析總結
(1) 對處理性能不確定性研究的分析 針對性能不確定性的研究主要分為兩大類,一類從性能測試和統計學的角度出發,對測試方法和性能分析的方法進行優化;另一類,從程序本身出發,控制運行過程中的不確定性變量,使得對性能不確定的分析更加簡便。
文獻[1]提出的嚴格的統計學處理方法,也就是表1中的Rigorous,為Java并行程序的性能測試提出了一種完備的框架。文獻[4]的工作,也就是表中的Reasonable,對前者的工作進行了優化,將測試的過程分層,在不必要的層上減少重復次數。隨后文獻[5]的工作,也就是表中的HPT,使用了一種非參數檢驗的方法,能夠提升從已知的數據從歸納出更精確的結果。
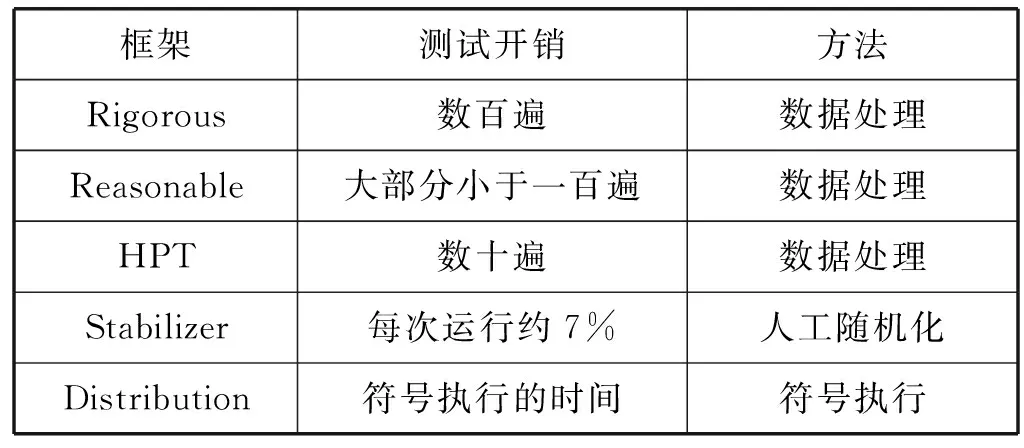
表1 處理性能不確定性研究的比較
Stabilizer和Distribution,也就是文獻[7]的工作,則將減少性能不確定性的努力放在了程序本身上。Stabilizer能夠使程序運行的結果呈正態分布;而Distribution則希望通過符號執行建立程序的性能分布模型。值得注意的是,這項技術還并不完全成熟,并不足以模擬多線程不確定性和系統對程序的影響。
(2) 對Java程序的確定性重放技術的分析 確定性重放技術的研究方向大致分為兩種:(1) 致力于對記錄階段進行優化,降低重放技術的額外開銷;(2) 通過特定的虛擬機環境,實現額外功能的重放技術。對于前者,表2給出了本文總結的幾種確定性重放技術的性能比較。由于這幾篇文獻的性能分析都是以Leap為比較對象,表格中就以Leap為基準進行比較,其中Ditto給出了比較數據,但沒有具體的總體性能比較。可以看到,后面幾篇文獻進行各自的優化之后,都取得了比較好的結果。Order針對Java虛擬機中的編譯器,垃圾收集等做了額外的信息記錄。Ditto在記錄階段利用偏序的傳遞性,減少不必要的信息記錄。CARE通過自己實現的軟件緩存減少需要記錄的讀寫操作。Stride結合了路徑推斷的技術,減少記錄階段的同步操作。
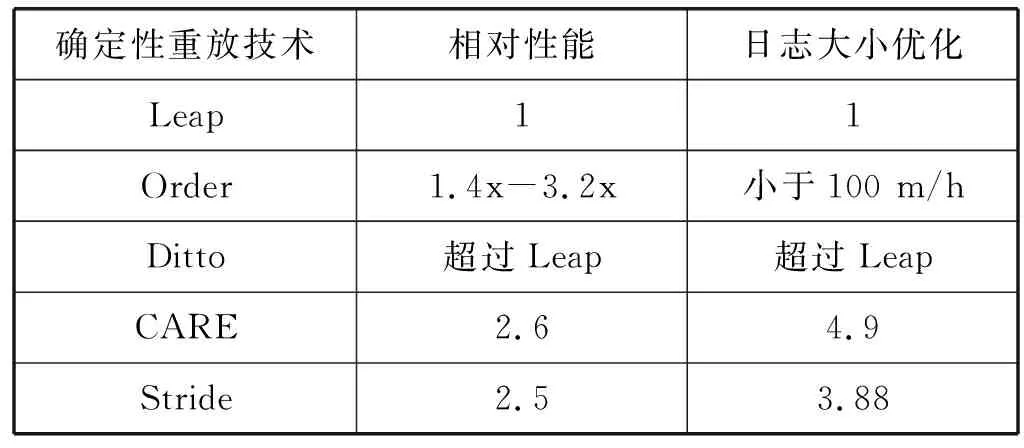
表2 各確定性重放相對于Leap框架的性能比較
4.2 展 望
4.2.1 對處理系統不確定性研究的展望
在對數據處理的研究上,前文所述的研究已經做出了十分顯著的成果,但依然有一些問題得不到解決。比如在對于Java虛擬機內部機制和并行程序不確定性之間的關系,這方面的研究仍然比較缺乏。如果能夠知道即時編譯器和垃圾收集等因素會在多大的程度上,會如何影響Java程序執行時的不確定性,對分析Java程序的性能結果會很有幫助。并行程序結果的分布形態與程序本身的關系也是可以進一步研究的方向,這也有助于將程序的結果分布正態化。
此外,通過符號執行對程序性能分布建立模型的工作也需要進一步發展,當這項工作能夠將所有的因素都考慮到模型中時,該技術才能得到更廣泛的應用。
4.2.2 對Java程序的確定性重放技術的展望
盡管前文提到的工作對確定性重放技術有了非常大的提升,但是確定性重放技術的代價仍然是比較大的,這項技術還有進一步提升的空間。
目前的大多數工作致力于減少對共享變量訪問的記錄。如果要在這一方面有所突破,可以進一步對多線程程序訪問共享變量的模式進行優化,減少不確定性的共享變量訪問。另外,更多的使用事務內存,也可以簡化對于共享變量的記錄,只在檢查點上對這些訪問記錄進行處理。
另一方面,結合前文提到的TDR技術也是一個非常有潛力的方向。隨著大數據處理和云計算變得越來越普及,在虛擬機上運行程序將是未來不可避免的趨勢。如果TDR的虛擬機能夠實現更高效的性能,那么將有潛力解決未來在云端的程序確定性重放問題。
此外,TDR的時間確定性重放對于解決并行程序的性能不確定性也是非常有幫助的。如果在兩臺配置相同的機器上能實現一模一樣的性能,那在兩臺配置不同的機器上運行,兩者之間的速度差異就可能是確切的性能差異。若能實現這個效果,將會極大地性能評估的效率,并解決性能不確定性的問題。
5 結 語
隨著多核處理器的發展,大規模并行程序已經成為了主流。然而并行程序的不確定性卻給程序的性能評估和錯誤調試帶來了許多問題。而Java虛擬機由于自身系統存在的不確定性,加劇了程序的不確定性,這使得Java并行程序的性能評估以及確定性重放的錯誤調試方法變得更加重要。本文針對解決Java并行程序的性能評估方法以及確定性重放技術分別進行了總結和分析。Java并行程序的性能評估的難點主要在于提升性能測試的效率以及對程序的性能進行總結和描述。基于Java程序的確定性重放技術的主要難點在于如何提升記錄階段的性能。最后,本文總結了這兩個方向如今還存在的問題,并對解決不確定性問題的前景進行了展望。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年3期)2015-11-19 02:53:32
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
