基于加權霍夫投票的多視角車輛檢測方法
2018-08-06 05:54:26李冬梅李濤向濤
現(xiàn)代電子技術 2018年15期
李冬梅 李濤 向濤


摘 要: 針對復雜場景中車輛由于視角變化引起的檢測精確度過低的問題,改進霍夫投票目標檢測模型,提出一種在統(tǒng)一框架下通過不同權重組合發(fā)現(xiàn)目標最優(yōu)視角并進行精確定位的方法。首先,利用一種無監(jiān)督方法實現(xiàn)多視角車輛的子視角劃分;其次,利用子視角劃分結果定義霍夫投票過程中各正例樣本在不同視角下的投票權重;最后,利用子視角劃分和投票權重,提出一種新的適用于多視角目標檢測的加權霍夫投票模型。在MITStreetScene Cars和PASCAL VOC2007 Cars兩個常用數據集上的實驗結果表明,所提方法在不增加模型復雜度的前提下,有效提升了多視角目標檢測精確度。
關鍵詞: 復雜場景; 霍夫投票; 最優(yōu)視角; 多視角目標檢測; 子類劃分; 局部線性嵌入(LLE)
中圖分類號: TN911.73?34; TP391.4 文獻標識碼: A 文章編號: 1004?373X(2018)15?0073?06
Multi?view vehicle detection method based on weighted Hough voting
LI Dongmei1, LI Tao1, XIANG Tao2
(1. School of Information Engineering, Henan Radio & Television University, Zhengzhou 450008, China;
2. School of Computer Science and Engineering, University of Electronic Science and Technology of China, Chengdu 611731, China)
Abstract: For the low detection accuracy of vehicles in complex scene caused by view variation, the target detection model based on Hough voting is improved to propose an accurate location method to find the object optimal view by means of different weights combination in the unified framework. An unsupervised method is used to realize the sub?view division for the multi?view vehicles. According to the sub?view division result, the voting weight of each positive example under different views is defined in the process of Hough voting. The sub?view division and voting weight are used to propose a weighted Hough voting model suitable for multi?view target detection. The experimental results are obtained by two commonly?used datasets of MITStreetScene Cars and PASCAL VOC2007 Cars. The experimental results demonstrate that the method can improve the multi?view target detection accuracy without increasing the model complexity.
Keywords: complex scene; Hough voting; optimal view; multi?view object detection; sub?class division; local linear embedding
0 引 言
在現(xiàn)實場景中,由于目標自身移動或者拍攝位置不同,導致最終目標在圖像中以不同視角呈現(xiàn),這將引起目標的外觀特征出現(xiàn)很大差異,檢測此類目標也變得極度困難,如圖1所示。雖然多數目標都會出現(xiàn)多視角問題,但基于研究價值和實用價值,本文著重考慮復雜場景中的多視角車輛檢測(以轎車為例)。多視角特征在車輛上的體現(xiàn)最為明顯,車輛檢測又是智能交通相關應用的重要組成部分,為解決這個問題,研究者們提出了以下三類方法:
1) 利用手工方法或基于樣本長寬比(Aspect Ratio)將訓練集劃分成不同子類,每個子類包含某一范圍的視角變化,并為每個子類獨立地建立檢測模型,常見的如基于劃分的每個子集訓練一個HOG+SVM檢測器[1?2]。目標檢測領域最知名的DPM模型[3]也沒有很好地解決這個問題,它依舊是利用多個組件(Component)建立一種包含多子類的混合模型,每個組件對一種視角子類負責。文獻[4]對DPM做出改進,多組件之間可以共享局部部件,但前提是需預先劃分樣本子類。總之,此類方法成倍增加模型復雜度,并且手工劃分樣本是一個耗時、主觀性強的工作,不同人可能對樣本有不同的劃分標準,這種不確定性將最終影響檢測性能。
2) 基于自動子類劃分方法或在學習檢測器過程中嵌入無監(jiān)督聚類過程。文獻[5]利用目標輪廓和層次聚類算法對目標進行子類劃分。文獻[6]提出利用圖像HOG特征和局部線性嵌入(Locally Linear Embedding,LLE)對樣本進行聚類。文獻[7]提出一種嵌套的Adaboost算法,外層選擇某視角下有代表性的樣本原型進行視角劃分,內層選擇有區(qū)分性的特征進行目標分類。文獻[8]提出一種基于Boosting算法的樹結構分類模型,在逐層劃分樣本特征空間的同時不斷利用無監(jiān)督聚類算法對樣本進行聚類。該類檢測算法取得了較好效果,但沒有解決同類目標間視覺信息共享的問題,訓練中需要大量樣本。
3) 在模型中嵌入3D視角信息,并利用它估計目標視角。PSM(Partial Surface Models)[9]利用圖模型將多視角下的目標部件連接起來,檢測過程中通過圖推理算法驗證部件組合關系和整體視角的合理性。文獻[10]結合標定的2D視角信息和3D合成模型中的幾何信息學習多視角目標的外觀模型。文獻[11]結合3D模型和基于外觀的投票檢測模型,在投票過程中同時確定目標類別和整體視角。文獻[12]利用視角標注的目標圖像修正已有的3D模型,然后將其用于目標檢測。上述方法能有效提高多視角目標檢測性能,但3D視角信息和3D目標模型通常很難得到。
上述三類方法從不同角度解決了多視角目標檢測問題,但各自均存在明顯的缺陷或局限性,主要表現(xiàn)在:
1) 通過手工或自動聚類劃分樣本,并為每個視角子類學習分類模型,這樣做只考慮了不同視角下目標外觀特征的差異,沒有有效利用多視角目標的特征共性;
2) 基于全局特征的目標模型很難表達由于視角差異引起的類內變化,基于局部部件的目標模型才是解決多視角目標檢測的關鍵;
3) 在實際應用中,由于設備限制,3D視角信息很難采集。
針對存在的問題,本文方法以無監(jiān)督子視角聚類和霍夫投票目標檢測框架[13]為基礎,提出一種既能體現(xiàn)多視角目標外觀差異,又能解決多視角目標局部特征共享的加權霍夫目標檢測方法,所提方法的主要創(chuàng)新點包括:
1) 基于局部線性嵌入(LLE)和k?means算法的車輛視角子類自動劃分方法;
2) 在子視角劃分基礎上,定義正樣例對不同視角的投票權重;
3) 結合投票權重,提出一種能自動發(fā)現(xiàn)最優(yōu)目標視角,并進行精確定位的霍夫投票方法。
本文方法在一個統(tǒng)一的框架實現(xiàn)了多視角目標檢測,同時還有效利用了不同視角目標的共享信息。
基于本文提出的加權霍夫投票目標檢測方法,解決了單一模型下的多視角目標檢測問題,大大提高了檢測速度,并且通過有效利用不同視角子類間的共享信息,使得檢測精度也得到提升,在MITstreetscene Cars[14]和PASCAL VOC2007 Cars[15]兩個車輛檢測數據集上的實驗結果驗證了所提方法的可行性和有效性。
1 基于霍夫投票的目標檢測框架
由于所提算法建立在霍夫投票目標檢測框架上,該框架主要包括以下3部分內容:
1) 圖像塊集合生成和標注:收集目標圖像訓練集,定義局部圖像塊大小,并在每個訓練樣本中抽取若干圖像塊以構成局部圖像塊集合。注意,正樣例中抽取的局部圖像塊需定義該圖像塊中心到正樣例圖像中心的幾何偏移向量,用于構建投票單元;
2) 視覺單詞訓練和表達:根據局部圖像塊外觀特征相似和正樣例圖像塊相對目標中心幾何偏移一致的原則對局部圖像塊集進行聚類,每個子類對應一個視覺單詞,每個視覺單詞記錄了分類信息和目標中心位置信息;
3) 投票和檢測:在測試圖像中采樣同樣大小的圖像塊,并與視覺單詞集匹配,根據匹配的視覺單詞記錄的分類信息和目標中心位置信息對可能出現(xiàn)目標的位置和概率進行投票,生成關于候選目標中心位置的霍夫圖,并最終利用mean?shift[13]算法確定真正的目標中心。
視覺單詞集可通過聚類算法[13]或隨機森林[16]訓練得到,本文采用隨機森林生成視覺單詞集。由于改進算法主要針對霍夫投票檢測框架,因此需先對其通用流程做詳細描述。在視覺單詞集生成后,對于測試圖像[G],霍夫投票檢測流程為:
1) 提取預先定義大小的局部圖像塊[pt∈G],并利用[pt]與視覺單詞匹配關系生成投票單元。[pt]對一個候選目標中心位置[h]的投票分值為[V(hpt)],其中,[h]由像素坐標和尺度大小構成,投票分值[V(hpt)]可通過與[pt]匹配關聯(lián)的視覺單詞所記錄的分類信息和目標中心位置信息確定;
2) 遍歷測試圖像[G]中所有局部圖像塊[pt],候選目標中心位置[h]的最終投票分值為:
[S(h)=pt∈GV(hpt)] (1)
3) 利用mean?shift算法在由位置坐標和尺度構成的三維霍夫投票空間找到超過閾值的極值點,并在相應的測試圖像中標定目標。
由上述投票檢測流程可以看出,因為視角變化會使得目標相近位置的局部圖像塊外觀特征和相對幾何偏移向量不一致,所以該方法不能解決多視角目標檢測問題。
2 本文方法
針對霍夫投票檢測框架在解決多視角目標時遇到的問題,本文首先采用一種無監(jiān)督方法對訓練樣本集中的正樣本圖像進行視角子類劃分;然后給出基于劃分子類計算每個正樣本圖像視角貢獻權重的方法;最后利用視角子類劃分和權重矩陣改進霍夫投票檢測框架,提出適用于多視角車輛的加權霍夫投票檢測方法。
2.1 多視角劃分及權重矩陣生成
假定訓練樣本圖像集標記為[D=Ii=(fi,yi)Ni=1],其中,[fi]為圖像特征表達(本文在進行多視角劃分時采用HOG特征[1],訓練視覺單詞和霍夫投票時采用多通道像素特征[16]);[yi∈{-1,1}]為樣本標簽,[yi=-1]時,[Ii]為背景樣本,[yi=1]時,[Ii]為目標樣本;[N]為樣本集大小。收集樣本過程中,背景圖像和目標圖像大小一致,數量接近,且應盡量保證樣本的多樣性,即背景圖像應包括目標可能出現(xiàn)的各種場景,目標圖像應包括目標可能呈現(xiàn)的各種形態(tài)(重點考慮視角)。
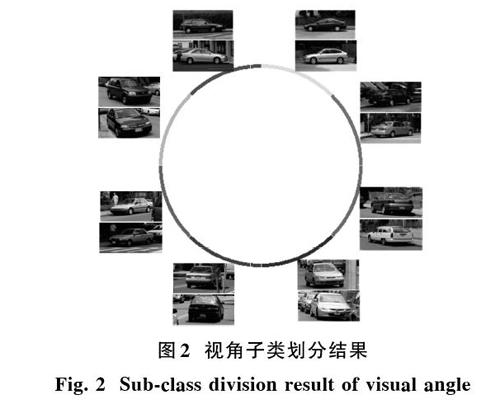
為了實現(xiàn)多視角車輛檢測,首先需要解決車輛視角劃分問題,即對樣本集[D]中正樣本集合[D+=][Γj=(fj,yj)N+j=1]進行視角子類劃分,[N+]表示正樣本個數。常用的手工方法費時耗力,且主觀性強,本文提出一種局部線性嵌入(LLE)[6]和k?means算法相結合的方式對多視角車輛進行視角劃分,其核心思想是先利用LLE算法將圖像的高維HOG特征嵌入到低維空間,然后在低維空間依據相對角度對樣本進行投影和聚類,具體做法是:
1) 利用LLE算法將樣本集[D+]中HOG特征表達的正樣本圖像(車輛)嵌入到二維空間。結果表明,HOG特征表達的多視角車輛被嵌入到二維空間后,樣本點分布形成環(huán)狀,沿著該環(huán),車輛視角平穩(wěn)變化;
2) 根據嵌入樣本分布,在二維空間選擇一個中心點,基于樣本點到該中心點的相對角度,將所有樣本規(guī)則化到一個圓形上,圓上相近區(qū)域樣本有接近的視角;
3) 利用k?means算法對圓上樣本進行聚類,最終視角相近的樣本被劃分到圓的同一段弧上,如圖2所示,圓上每段弧代表有相近視角的一個子類。結合具體問題,本文將視角子類數K設置為8。
相比直接利用HOG特征在高維空間進行無監(jiān)督聚類的做法,所提方法有兩點好處:高維特征聚類困難,缺乏穩(wěn)定性;聚類生成的子類不能保證視角上的一致性。通過將LLE和k?means算法相結合,既保證了生成子類中樣本外觀特征上的相似,也保證了它們視角的相近。
當正樣本圖像集的K個視角子類劃分確定后,便可計算每個正樣本對每個視角子類的貢獻權重,以體現(xiàn)出各視角子類間信息的共享性和差異性。在LLE嵌入空間中,假定已劃分的第[k∈{1,2,…,K}]個視角子類樣本集的聚類中心為[ok],[D+]中正樣本[Γj]在該空間的表達式為[f′j],則[Γj]對視角[k]的貢獻權重[wjk]定義為:
[wjk=1d(f′j,ok)] (2)
式中[d(f′j,ok)]為LLE嵌入空間中[f′j]與[ok]間的距離。為了保證計算的正確性,需要對正樣本[Γj]在各視角子類下的貢獻權重[wjk]進行歸一化,以確保:
[k=1Kwjk=1] (3)
可以看出,通過直接劃分視角子類,并為每個子類分別建模的方法中,[wjk]取值為0或1,可視為本文所提[wjk]定義的特例,這樣做最大的缺點是沒有利用樣本圖像在多個視角子類間的信息共享,提高樣本收集難度,增加處理時間。
2.2 加權霍夫投票方法
傳統(tǒng)霍夫投票方法的關鍵是如何在給定視覺單詞集的條件下,求解測試局部圖像塊[pt]在候選位置[h]的投票分值[V(hpt)]。假定與[pt]匹配的視覺單詞為[L],[L]中包含正樣例圖像塊偏移向量集合[EL],通過統(tǒng)計[L]中包含正樣例圖像塊所占比例得出分類概率[CL],則:
[V(hpt)=1ELe∈EL12πδ?exp-(h-qt)-e22δ2?CL] (4)
式中:[EL]中每個偏移向量[e]對候選位置[h]的投票是利用高斯Parzen窗來估計,[EL]表示集合大小;[qt]為圖像塊[pt]的中心位置。
根據式(4),在視覺單詞[L]生成后,其對應的分類概率[CL]已確定,局部圖像塊[pt]在候選位置[h]的投票分值主要取決于偏移向量集合[EL]中的投票單元[e],而這些投票單元是基于正樣本集[D+]中圖像定義的,故可建立局部圖像塊[pt]到[D+]中圖像的映射關系。因此,利用霍夫投票分值線性累加特性,可將[V(hpt)]的定義由累加[EL]中各投票單元對位置[h]投票分值的形式改寫為累加與[EL]中投票單元相關聯(lián)的正樣本圖像[Γj]對位置[h]投票分值的形式,即:
[V(hpt)=Γj∈D+Φ(hΓj,pt)] (5)
[Φ(hΓj,pt)= 1ELe∈EL,e⊕Γj12πδ?exp-(h-qt)-e22δ2?CL] (6)
式中[e⊕Γj]表示[EL]中的投票單元[e]來自于[D+]中圖像[Γj]。遍歷測試圖像[G]中所有局部圖像塊[pt],候選目標中心位置[h]的最終投票分值為:
[S(h)=Γj∈D+ pt∈GΦ(hΓ,pt)] (7)
在式(7)中,候選位置[h]的最終投票分值是通過累計正樣本集[D+]中每張圖像對[h]的貢獻得到的,但這種計算方法有效的前提是[D+]中樣本目標視角基本一致。對于多視角目標檢測,盡管來自樣本集[D+]中同一張圖像的所有投票單元會指向相對一致的候選位置,但由于[D+]中各樣本圖像視角差異過大,會導致最終投票生成的霍夫圖混亂,亮點不夠集中,無法準確確定目標中心位置。為了解決上述多視角霍夫投票存在的問題,本文提出在式(7)定義的投票模型中引入視角變量[k∈][{1,2,…,K}],以保證對候選位置投票的視角一致性,即:
參考2.1節(jié)定義,[K]為正例樣本被劃分視角子類數(本文中[K=8])。通過式(8)可知,對某一候選位置的投票都被限定在相同的視角下,解決了霍夫圖混亂、亮點不夠集中的問題。
求解式(8)最直觀的思路是對[D+]中樣本進行子視角劃分,并利用每個子視角類樣本分別進行投票,最大投票分值視角子類下的候選位置為最終目標中心位置。這種做法不但沒有有效利用不同視角樣本間的共享信息,還成倍增加計算開銷。本文結合2.1節(jié)給出的[D+]中樣本視角子類劃分算法和視角權重定義方法,給出式(8)的計算流程如下:首先利用視角子類劃分方法為[D+]中每張圖像標記一個視角子類[k∈{1,2,…,K}];然后利用式(2)和式(3)計算每張圖像的視角貢獻權重[wjk,j∈{1,2,…,N+}];最終通過標定視角和視角貢獻權重的樣本集[D+],式(8)被重新定義為:
[S(h,W)=maxk∈KΓj∈D+wjkpt∈GΦ(hΓj,pt)] (9)
式中[W]為[wjk]構成的大小為[N+×K]的權重矩陣。
式(9)給出了適合于多視角目標檢測的候選目標中心位置分值計算模型,基于此模型,在測試圖像中確定最終目標檢測框的步驟為:
1) 對于一張測試圖像,首先將圖像進行尺度分解,假定圖像尺度空間定義為[Λ=λmMm=1],[M]為離散尺度的個數;
2) 在尺度為[λm]的測試圖像中密集抽樣同大小的局部圖像塊,找到與每個局部圖像塊匹配的視覺單詞,然后利用式(9)計算并生成該尺度上的霍夫投票圖;
3) 在[(h,λm)]構成的三維霍夫空間([h=(hx,hy)],包含圖像橫、縱坐標位置)中,利用mean?shift算法和判定閾值確定最終目標中心位置[(h,λ′m)],并在原測試圖的[h′xλ′m,h′yλ′m]位置標記大小為[Widthλ′m?Heightλ′m]的檢測框。
3 實 驗
為了驗證方案的可行性和有效性,在MITStreetScene Cars[15]和PASCAL VOC2007 Cars[15]兩個包含現(xiàn)實場景中多視角車輛的數據庫上進行相關實驗,計算相應性能統(tǒng)計指標并與相關算法(ACF[17],DPM[3],Xiang[18],HF[16],HC[19])進行比較。實驗結果表明,對于多視角車輛檢測問題,相比其他方法,本文方法能取得更好的結果,特別地,所提算法改進了傳統(tǒng)投票檢測框架中投票計算量大、生成的霍夫圖能量過于分散等問題。
本文算法用到的樣本圖像大小都標準化為128×64,視角子類數定義為8。為了生成圖像塊集,在訓練集中每個樣本圖像上隨機抽取50個大小為16×16的圖像塊,并為每個圖像塊標定類別標簽和相對目標中心的偏移向量(只對正樣本)。利用隨機森林生成視覺單詞時,森林中樹的棵數為20,森林的最大深度為15。在樹節(jié)點分裂終止條件中,分裂節(jié)點中最少圖像塊個數為20,最大類純度為99.5%,節(jié)點中正樣例圖像塊偏移向量的偏離平方差最小為30。對于多尺度問題,每張測試圖的尺度空間設定在0.1~0.8的20個尺度上。本文實驗平臺為:Intel CoreTM i5 3.2 GHz CPU,16 GB RAM,Matlab 2012,Window 64?bit OS。
在檢測過程中,對于超過檢測閾值的候選檢測框,遵循PASCAL協(xié)議[3],即該檢測框與目標真實區(qū)域(通過測試集的標注信息給出)交并比要超過50%,則認為是一次成功的檢測。
3.1 數據集
MITStreetScene Cars:該數據集包含3 547幅圖像,并從中標定出5 799輛車。這些圖像包含車輛可能出現(xiàn)的各種場景,同時光照條件也有變化。在標定的車輛中,基本都是常見轎車,但是形狀會有些差別,其成像視角也基本包括了可能出現(xiàn)的所有角度。數據集一半用于訓練,一半用于測試,所需負樣本圖像從PASCAL VOC2007中抽取。
PASCAL VOC2007 Cars: PASCAL VOC被公認是目標檢測領域最難的數據集,在該數據庫的2007版本中總共有10 000幅圖像,包含20種生活中常見的目標。對于車輛,該數據集中各有625個樣本用于訓練和檢測。為了使訓練樣本覆蓋更多視角范圍,將每個訓練樣本進行水平翻轉,并將翻轉得到的圖像放入訓練集中。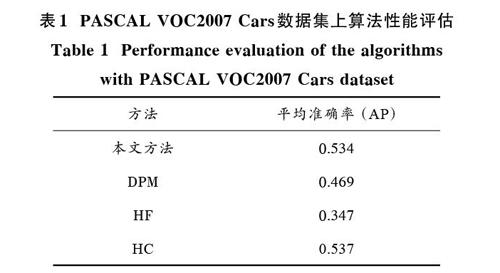
兩測試集上檢測實例如圖3所示。
3.2 實驗結果
對于MITStreetScene Cars數據集,各算法性能通過精度(Precision)?召回率(Recall)曲線描述(簡稱PR曲線)。準確率和召回率是兩個相互關聯(lián)但又相互制約的統(tǒng)計指標,單個指標無法衡量算法性能,須計算出每條PR曲線下的面積(Area Under Curve,AUC),并以此作為算法性能度量指標,曲線AUC越大,算法效果越好。圖4給出了各算法的檢測性能曲線,可以看出,所提方法達到較好的檢測性能,超過著名的DPM[3]和HF[16]算法,以及最近提出的HC[19],Xiang[18]和ACF[17]方法。DPM利用多組件來解決多視角問題,但組件劃分只是通過目標長寬比進行,相似做法還包括Xiang。HF,HC方法和所提方法都屬于霍夫投票檢測框架,但它們在模型中沒有特別加入視角因子。
PASCAL VOC2007 Cars數據集上相關算法的比較沿用已有方法通用的指標,即平均準確率(Average Precision,AP),AP通過統(tǒng)計不同Recall下,Precision的平均值(即AP)來衡量算法好壞,AP越高,算法性能越好。相關算法比較結果見表1,可以看出,所提方法檢測性能接近HC方法,相比于DPM,HF方法,所提算法檢測性能則有明顯優(yōu)勢。關于與HC之間的差距,其主要原因是PASCAL VOC2007 Cars數據集中車輛除了各種視角變化,還包含大量被遮擋、被截斷的車輛,HC方法利用上下文信息,增強了對遮擋、截斷車輛的識別能力。
4 結 論
本文在統(tǒng)一框架下,利用正例樣本對不同視角下目標的貢獻權重提出一種適用于多視角車輛的霍夫投票檢測模型。對于樣本視角劃分問題,不同于手工劃分或基于長寬比劃分的方法,所提LLE+k?means劃分方法避免了人工劃分的主觀性,有效利用了目標外觀特征和視角信息。在投票過程中,通過正樣例圖像投票加權和視角尋優(yōu),在一個框架下解決了多視角目標檢測問題,同時還有效利用了多個視角目標提供的信息。實驗結果表明,本文方法在不增加時間開銷的情況下,顯著提高了多視角車輛檢測的準確性。
參考文獻
[1] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2005: 886?893.
[2] WANG X, HAN T X, YAN S C. An HOG?LBP human detector with partial occlusion handling [C]// 2009 IEEE International Conference on Computer Vision. Kyoto: IEEE, 2009: 32?39.
[3] FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D, et al. Object detection with discriminatively trained part?based models [J]. IEEE transactions on pattern analysis and machine intelligence, 2010, 32(9): 1627?1645.
[4] PIRSIAVASH H, RAMANAN D. Steerable part models [C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 3226?3233.
[5] SEEMANN E, LEIBE B, SCHIELE B. Human multi?aspect detection of articulated objects [C]// 2006 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2006: 1582?1588.
[6] KUO C H, NEVATIA R. Robust multi?view car detection using unsupervised sub?categorization [C]// 2009 IEEE Workshop on Applications of Computer Vision Workshop. Snowbird: IEEE, 2009: 1?8.
[7] SHAN Y, HAN F, SAWHNEY H, et al. Learning exemplar?based categorization for the detection of multiview multi?pose objects [C]// 2006 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2006: 1431?1438.
[8] WU Bo, NEVATIA R. Cluster boosted tree classifier for multi?view, multi?pose object detection [C]// 2007 IEEE International Conference on Computer Vision. Rio de Janeiro: IEEE, 2007: 1?8.
[9] KUSHAL A, SCHMID C, PONCE J. Flexible object models for category?level 3D object recognition [C]// 2007 IEEE Confe?rence on Computer Vision and Pattern Recognition. Minneapolis: IEEE, 2007: 1?8.
[10] SHRIVASTAVA A, GUPTA A. Building part?based object detectors via 3D geometry [C]// 2013 IEEE International Confe?rence on Computer Vision. Sydney: IEEE, 2013: 1745?1752.
[11] GLASNER D, GALUN M, ALPERT S, et al. Viewpoint?aware object detection and pose estimation [C]// 2011 IEEE International Conference on Computer Vision and Pattern Re?cognition. Barcelona: IEEE, 2011: 1745?1753.
[12] HAO S, MIN S, LI F F, et al. Learning a dense multi?view representation for detection, viewpoint classification and synthesis of object categories [C]// 2009 IEEE International Conference on Computer Vision and Pattern Recognition. Kyoto: IEEE, 2009: 213?220.
[13] LEIBE B, LEONARDIS A, SCHIELE B. Robust object detection with interleaved categorization and segmentation [J]. International journal of computer vision, 2008, 77(1/3): 259?289.
[14] BILESCHI S M. StreetScenes: towards scene understanding in still images [D]. Cambridge: Massachusetts Institute of Technology, Department of Electrical Engineering and Computer Science, 2006.
[15] EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The PASCAL visual object classes challenge [DB/OL]. [2007?02?12]. http://host.robots.ox.ac.uk:8080/pascal/VOC/voc2007/index.html,2007.
[16] GALL J, LEMPITSKY V. Class?specific Hough forests for object detection [C]// 2009 IEEE International Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 1022?1029.
[17] APPEL R, PERONA P, BELONGIE S. Fast feature pyramids for object detection [J]. IEEE transactions on pattern analysis and machine intelligence, 2014, 36(8): 1532?1545.
[18] 向濤,李濤,趙雪專,等.基于隨機森林的精確目標檢測方法[J].計算機應用研究,2016,33(9):2837?2840.
XIANG T, LI T, ZHAO X Z, et al. Random forests for accurate object detection [J]. Application research of computers, 2016, 33(9): 2837?2840.
[19] LI T, YE M, DING J. Discriminative Hough context model for object [J]. Visual computer, 2014, 33(11): 59?69.
