基于語義網(wǎng)絡的英語機器翻譯模型設計與改進
2018-07-27 06:50:48盧蓉
現(xiàn)代電子技術 2018年14期
盧蓉


摘 要: 針對傳統(tǒng)基于規(guī)則的機器翻譯模型存在英語翻譯結(jié)果不夠精確、難以準確描述詞語間關系的弊端,設計并改進基于語義網(wǎng)絡的英語機器翻譯模型。該模型采用基于向量混合的短語合成語義統(tǒng)計英語機器翻譯方法,在翻譯相似度模型中,采用余弦相似度的方法獲取兩個向量的語義相似度,經(jīng)過帶權向量加法的計算極易辨別兩個相似向量的不同之處,獲取精準的英語翻譯結(jié)果,對句子實施權值訓練獲取構成句子的主要短語,保證翻譯結(jié)果歸納出句子的中心思想。改進基于語義網(wǎng)絡的英語機器翻譯模型,針對用戶需求引入大數(shù)據(jù)的同時讓語言學家參與到機器翻譯的過程中,使得英語翻譯結(jié)果既能獨立進行語義表達,又能準確描述詞語間關系。實驗結(jié)果表明,所設計的模型能夠精準高效地進行英語翻譯。
關鍵詞: 語義網(wǎng)絡; 機器翻譯; 模型設計; 語義相似度; 語料庫; 權重訓練
中圖分類號: TN912.3?34; TP391.2 文獻標識碼: A 文章編號: 1004?373X(2018)14?0126?04
Design and improvement of English machine translation model
based on semantic network
LU Rong
(Hainan University, Haikou 570028, China)
Abstract: In allusion to the deficiencies existing in the traditional rule?based machine translation model for its inaccurate English translation results and difficulty to accurately describe the relationship between words, an English machine translation model based on semantic network is designed and improved. In the model, the phrase semantic synthesis statistical English machine translation method based on vector hybrid is adopted. In the translation similarity degree model, the cosine similarity degree method is adopted to obtain the semantic similarity degree of two vectors. The differences between two similar vectors are very easy to be discriminated after addition calculation of weighted vectors, so as to obtain accurate English translation results. The weight training is conducted for sentences to obtain the main phrases that constitute sentences, so as to ensure that the central idea of the sentence is summarized in translation results. In the improved English machine translation model based on semantic network, big data is introduced to meet users′ needs and linguists are invited to participate in the machine translation process, so that not only can semantic expressions be independently conducted, but also the relationship between words can be accurately described in English translation results. The experimental results show that the designed model can conduct an accurate and efficient English translation.
Keywords: semantic network; machine translation; model design; semantic similarity; corpus; weight training
0 引 言
隨著我國綜合國力與國際競爭力的增強,與世界各國的貿(mào)易往來、文化交流日益加深,英語作為應用最為廣泛的語言成為我國與其他國家之間溝通的橋梁[1?2]。因此英語翻譯成其他語言的需求日益增強,各種英語翻譯機器應運而生。英語機器翻譯的歷史可以追溯到20世紀80年代,而近十余年來,英語機器翻譯技術發(fā)生了翻天覆地的變化。現(xiàn)有關于英語的翻譯模型設計數(shù)不勝數(shù),在某種程度可以滿足用戶的需求[3?4]。但同樣存在問題,大部分都是基于詞義排歧、語義角色標注等進行的英語機器翻譯模型,本文設計的基于語義網(wǎng)絡的英語機器翻譯模型既能具備獨立進行語義表達的能力,又能具備描述詞語間關系的能力,為各領域的用戶提供精確的翻譯服務。
1 英語機器翻譯模型的設計與改進
1.1 基于語義網(wǎng)絡的英語機器翻譯模型設計
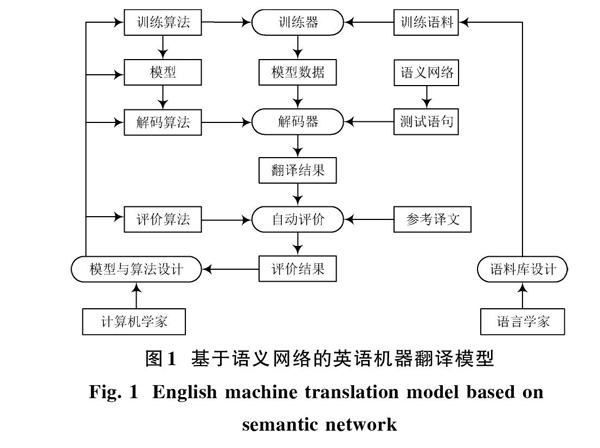
語言學家嚴格分析翻譯結(jié)果并進行知識庫更新,改善英語翻譯器的使用效果。計算機學家的功能是向機器輸入固定數(shù)值,系統(tǒng)設計成功后,對于翻譯結(jié)果的靈活度較低,不能進行調(diào)整。因此,在基于規(guī)則的英語機器翻譯研究范式中融入語義網(wǎng)絡,塑造基于語義網(wǎng)絡的英語機器翻譯模型如圖1所示。
圖1引入了語義網(wǎng)絡部分,基于語義網(wǎng)絡的統(tǒng)計機器翻譯模型的翻譯結(jié)果更加精確,使得語言學習者的學習效果更加明顯,更能在有限時間內(nèi)高效率地學習英語。知識庫變成了包含大量信息的語料庫,計算機學家對于算法的設計也更加全面系統(tǒng)。
1.2 短語合成語義統(tǒng)計英語機器翻譯方法
1.2.1 翻譯相似度模型
相同語義空間中兩個不同多維向量[u],[v]的相似程度可以通過語義相似度來描述。向量[u],[v]相似度越大其所代表的向量[u],[v]描述的語義相似程度就越大。予以相似的實際應用越來越廣泛,例如,在自然語言分析領域中也融入了語義相似度的概念。語義相似模型在統(tǒng)計機器翻譯中的具體表現(xiàn)是翻譯相似度模型[5]。在驗證分析的過程中,可以通過多種方式獲取兩個向量[u],[v]的翻譯語義相似度,本文對最常用的方法余弦相似度進行舉例說明。
1.2.2 余弦相似度
余弦相似度又稱為余弦距離,在多維空間中,用兩個向量夾角的余弦作為衡量這兩個向量間差異大小的標準。當余弦值增大的情況下,兩個語義向量間的夾角會減小,那么兩個單詞的語義就越接近[6];當余弦值減小的情況下,兩個語義向量間的夾角會變大,那么兩個單詞的語義就越不接近。雙語向量[u=a1,a2,…,an]以及[v=b1,b2,…,bn]的英語翻譯相似度為:[Simu,v=u·vu×v=i=1nai×bii=1na2i×i=1nb2i] (1)
1.2.3 帶權向量加法
通過式(2)能夠獲取相同語料庫中兩個單詞語義向量[u,v]的合成語義向量[p]:
[p=u+v=a1+b1,a2+b2,…,ai+bi]
(2)
設置單詞“機器”的語義向量為5維向量[u=2,6,8,7,1],單詞“翻譯”的語義向量為5維向量[v=1,3,4,5,6],那么根據(jù)式(2)得出合成短語“機器 翻譯”的語義向量[p=3,9,12,12,7]。
通過帶權向量加法獲取合成短語的合成語義向量的方式有效地解決前面的錯誤[7?8],具體的公式如下:
[p=αu+βv] (3)
同樣分析合成語義“機器翻譯”的步驟,通過語料庫訓練后得到的“機器翻譯”短語中“機器”的權重是[α=0.6],翻譯的權重[β=0.4],根據(jù)式(3)獲取“機器翻譯”的語義向量是[p=2.6,4.8,6.4,6.2,3.0]。
這種情況下,把短語“翻譯機器”當成是新的短語,對“翻譯”“機器”實施新的權重訓練,設置其權重分別是0.3,0.7,獲取“翻譯機器”的語義向量是[q=1.7,5.1,6.8,6.4,2.5]。再將兩者的語義向量結(jié)果進行比較發(fā)現(xiàn),這次可以簡單地辨別兩個短語的不同之處。
通過式(4)可以得到多字短語的合成語義向量:
[p=i=1nλiwi] (4)
式中:多字短語各組合單元的單詞語義向量用[wi]表示;各組合單元單詞的權重用[λi]表示。
1.3 基于語義網(wǎng)絡的英語機器翻譯模型改進
上面對機器翻譯的現(xiàn)有水平進行了探討研究,接下來對其未來發(fā)展趨勢進行展望。
未來的研究中應引進更深層次的語言與知識儲備,更加精準先進的技術[9?10]。具體方法是讓語言學家參與到機器翻譯的過程中,增加新的語言信息、更新語料庫的知識儲備,以此改進基于語義網(wǎng)絡的英語機器翻譯模型流程,從科學、高效的角度調(diào)整研究范式的工作流程。獲取新的基于語義網(wǎng)絡的英語機器翻譯模型如圖2所示。
2 實驗分析
2.1 實驗數(shù)據(jù)
為了驗證本文設計的基于語義網(wǎng)絡的英語機器翻譯模型能夠獲取精確的翻譯結(jié)果進行實驗。實驗的數(shù)據(jù)采用LDC語料的部分子集,包含400萬句平行句對;其中包括中文單詞9 890萬個,英文單詞11 260萬個。實驗的開發(fā)集是NIST 05,其中包括1 082個中文句子,每個中文句子下屬4個翻譯結(jié)果,也就是總計4 328個英文句子。實驗測試集分別是NIST 06,NIST 08,測試集NIST 06包含1 664個句子,下屬4個英文句子,即6 656個英文句子;測試集NIST 06包含1 357個中文句子,下屬4個英文翻譯句子,即5 428個英文句子。
2.2 實驗設置
實驗采用層次短語解碼器的C++實現(xiàn)版本作為解碼器。詳細操作步驟如下:英漢、漢英兩個方向的詞語信息對齊是通過GIZA++工具來實現(xiàn)的,發(fā)揮grow?diag?final?and的啟發(fā)作用達到多對多的詞語對齊的狀態(tài),翻譯結(jié)果中的詞對齊的交叉連接數(shù)越小說明系統(tǒng)的翻譯性能更好一些。通過采用SRILM工具的方式在Gigaword新華部分獲取四元英語語言模型。由于MERT的不穩(wěn)定性需利用Clark等人提出的方式重復實施實驗3次,把最后的平均值當作實驗結(jié)果。
2.3 實驗結(jié)果
1) 為了驗證本文設計模型在英語翻譯方面的精確度,實驗檢測層次短語翻譯模型、加入單詞分布語義信息模型以及本文模型,對不同數(shù)據(jù)集的翻譯結(jié)果見表1。
本次實驗評價指標為BLEU值,分析表1 可得,基于測試集NIST 06,NIST 08,本文模型獲取的翻譯結(jié)果比層次短語翻譯模型的翻譯結(jié)果分別增長了0.35,0.23。同樣基于測試集NIST 06,NIST 08,本文模型獲取的翻譯結(jié)果比加入單詞分布語義信息的層次短語翻譯模型的翻譯結(jié)果分別增長了0.12,0.03。說明采用本文模型獲取的英語翻譯結(jié)果更加準確、科學。采用顯著性檢驗的方式獲取本文模型翻譯結(jié)果符合[ρ<0.05]的條件,說明其翻譯結(jié)果的性能明顯的進步。
語義信息的層次短語翻譯模型以及本文模型進行英語翻譯,獲取三種模型在英語翻譯方面的性能。實驗結(jié)果如表2所示,本次試驗給出參考譯文進行對比。
分析表2可得,在具體的翻譯過程中,三種模型對于“物價局”這一詞語均未翻譯,再分析“做出解釋”這一詞語,前兩者模型給出的翻譯結(jié)果是explained。本文模型給出的翻譯結(jié)果是gives explaination of,與參考譯文相一致,說明本文模型的英語翻譯結(jié)果更加精準、正確率較高。
3) 實驗設置提到,翻譯結(jié)果中的詞對齊的交叉連接數(shù)越小說明系統(tǒng)的翻譯性能更好。實驗分別采用三種模型對英語翻譯結(jié)果的交叉連接數(shù)進行實驗分析。
分析表3可得,采用層次短語模型翻譯結(jié)果的交叉連接數(shù)是29.2,加入單詞分布語義信息的層次短語翻譯模型翻譯結(jié)果的交叉連接數(shù)比前者減少4.7,表明其翻譯結(jié)果性能有所提高;而本文模型翻譯結(jié)果的交叉連接數(shù)是16,比前面兩者明顯大幅縮減,說明本文模型具有較高的翻譯性能。
4 結(jié) 論
本文設計的基于語義網(wǎng)絡的英語機器翻譯模型具有較高的翻譯性能,既能獨立進行語義表達,又能在排除歧義的基礎上描述詞語間關系,最終給出精確的英語翻譯結(jié)果。狹義上來說,為用戶提供了英語翻譯參考介質(zhì),廣義上來說有利于促進各國文化交流、貿(mào)易往來。在未來的發(fā)展中,英語機器翻譯會朝著大數(shù)據(jù)、多信息的方向發(fā)展。
參考文獻
[1] 劉宇鵬,馬春光,張亞楠.深度遞歸的層次化機器翻譯模型[J].計算機學報,2017,40(4):861?871.
LIU Yupeng, MA Chunguang, ZHANG Yanan. Hierarchical machine translation model based on deep recursive neural network [J]. Chinese journal of computers, 2017, 40(4): 861?871.
[2] 李響,南江,楊雅婷,等.泛化語言模型在漢維機器翻譯中的應用[J].計算機應用研究,2014,31(10):2994?2997.
LI Xiang, NAN Jiang, YANG Yating, et al. Application of generalization language model in Chinese?Uyghur machine translation [J]. Application research of computers, 2014, 31(10): 2994?2997.
[3] ZHANG J, LIU S, LI M, et al. Towards machine translation in semantic vector space [J]. ACM transactions on Asian and low?resource language information processing, 2015, 14(2): 9.
[4] MUZAFFAR S, BEHERA P, NATH G. A Pāniniān framework for analyzing case marker errors in English?Urdu machine translation [J]. Procedia computer science, 2016, 96(C): 502?510.
[5] 惠浩添,李云建,錢龍華,等.一個面向信息抽取的中英文平行語料庫[J].計算機工程與科學,2015,37(12):2331?2338.
HUI Haotian, LI Yunjian, QIAN Longhua, et al. A Chinese?English parallel corpus for information extraction [J]. Computer engineering and science, 2015, 37(12): 2331?2338.
[6] 薛征山,張大鯤,王麗娜,等.改進機器翻譯中的句子切分模型[J].中文信息學報,2017,31(4):50?56.
XUE Zhengshan, ZHANG Dakun, WANG Lina, et al. An improved sentence segmentation model for machine translation [J]. Journal of Chinese information processing, 2017, 31(4): 50?56.
[7] ROMOOZI M, FATHY M, BABAEI H. A content sharing and discovery framework based on semantic and geographic partitioning for vehicular networks [J]. Wireless personal communications, 2015, 85(3): 1583?1616.
[8] 王俊華,左祥麟,左萬利.基于證據(jù)理論的單詞語義相似度度量[J].自動化學報,2015,41(6):1173?1186.
WANG Junhua, ZUO Xianglin, ZUO Wanli. Word semantic similarity measurement based on evidence theory [J]. Acta automatica sinica, 2015, 41(6): 1173?1186.
[9] MALLAT S, MOHAMED M A B, HKIRI E, et al. Semantic and contextual knowledge representation for lexical disambiguation: case of Arabic?French query translation [J]. Journal of computing & information technology, 2014, 22(3): 191?215.
[10] BOULARES M, JEMNI M. Learning sign language machine translation based on elastic net regularization and latent semantic analysis [J]. Artificial intelligence review, 2016, 46(2): 145?166.
