基于LDA主題模型的格調(diào)挖掘
2018-07-25 06:13:32李江宇宋添樹張沁哲
電腦與電信 2018年5期
關鍵詞:模型
李江宇 宋添樹 張沁哲
1 引言
近年來,微博、微信朋友圈等社交平臺快速崛起,由于使用方便、操作簡單等優(yōu)點被廣大用戶所使用。用戶不僅可以在社交平臺上發(fā)表自己的看法,還可以通過點贊、評論以及轉(zhuǎn)發(fā)的方式參與別人討論的話題。過去關于社交平臺的研究多為人格以及情感研究,本文首次提出發(fā)布者格調(diào)的概念,旨在通過微博用戶的龐大數(shù)據(jù)量分析刻畫出發(fā)布者的格調(diào)極性分布。格調(diào)是指發(fā)布者的風格、品味,往往由其文藝作品中導出,而發(fā)布者的微博文本就是他們的文藝作品。挖掘得到發(fā)布者的格調(diào)極性對微博的定向推薦有重要的意義。
2 相關工作
本文采用的主要研究方法是引入LDA主題模型,通過主題分布來反映發(fā)布者的格調(diào)極性。徐戈等人[1]對主題模型的發(fā)展以及各階段主題模型的推導進行了詳細的闡述,并對改進的主題模型進行了展望。歐陽繼紅等人[2]提出了一種多粒度情感混合模型,該研究對LDA主題模型進行了改進,考慮兩個粒度上,即整體以及局部的情感分布來刻畫發(fā)布者的情感。王永貴等人[3]提出了基于用戶層的四層貝葉斯主題模型,解決了LDA挖掘短文本效果不佳的問題。Daniel Preotiuc等人[4]則從性別、年齡、職業(yè)三個方面使用社交文本釋義的方式刻畫不同發(fā)布者的風格。
3 格調(diào)刻畫模型
3.1 傳統(tǒng)的LDA主題模型
2003年Blei等人[5]提出了LDA(Latent Dirichlet Allocation)主題模型,LDA主題模型主要是通過無監(jiān)督學習的方式來抽取文檔集的潛在語義信息,這個語義信息就表現(xiàn)為文檔集的主題,把文檔集的高維度表示方式降到主題的低維度表示方式。LDA主題模型一般認為“每篇文檔都是按照一定的概率選擇了某個主題,而每個主題又是按照一定的概率選擇了某個詞項”,其中“文檔-主題”分布及“主題-詞項”分布都是服從一定參數(shù)的多項式分布。如果要生成一篇文檔,每個詞出現(xiàn)的概率如式1所示:
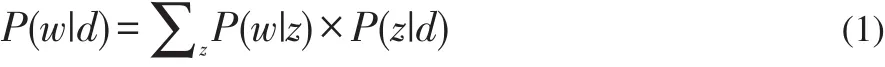
圖1表示為LDA主題模型的三層貝葉斯表示圖,其中wm,n為可觀測值,在語料庫中,我們唯一可以觀測到的變量就是詞項,而其他的元素均為無法觀測的隱含變量。K表示訓練語料庫后生成主題的數(shù)量,M表示生成文檔的數(shù)量,Nm表示第m篇文檔涵蓋詞項的數(shù)量。
3.2 SLDA主題模型
傳統(tǒng)的LDA主題模型多被應用于長文本主題挖掘,長文本包含較多的文字信息,表達語義更加明確,已有的多項研究已經(jīng)證明傳統(tǒng)的LDA主題模型對長文本主題挖掘效果比較顯著。而社交平臺的文本均屬于短文本,發(fā)布者發(fā)布的短文本被限制在140個字符以內(nèi),通過傳統(tǒng)的LDA主題模型對發(fā)布者的短文本進行主題挖掘效果并不理想。
本文借鑒AT(Author Topic)模型[3],對傳統(tǒng)LDA主題模型進行了改進,在“文檔-主題-詞”的三層貝葉斯模型的基礎上,引入了發(fā)布者層,通過加入發(fā)布者的格調(diào)參數(shù)來挖掘出發(fā)布者的格調(diào)主題分布,最終得到刻畫發(fā)布者格調(diào)極性的SLDA主題模型。
相比于傳統(tǒng)的LDA主題模型,SLDA模型的可觀測值為詞項wm,n以及發(fā)布者am,n,而其他的元素均為無法觀測的隱含變量。對于一個完整的發(fā)布者社交文本文檔,某個詞wm,n按照一定的概率選擇發(fā)布者am,n,然后根據(jù)選擇的發(fā)布者am,n的格調(diào)極性π是高的(π=s1)還是低的(π=s2)又以一定的概率選擇其對應格調(diào)的主題zm,n,主題zm,n在詞分布上服從Multinomial的多項式分布,并按一定概率產(chǎn)生一個詞。反復上述的迭代過程,最終生成一篇完整的文檔。
SLDA主題模型的四層貝葉斯網(wǎng)絡圖如圖2所示:

圖2 SLDA主題模型的四層貝葉斯網(wǎng)絡圖
主題模型參數(shù)含義如表1所示:

表1 參數(shù)及含義說明

參數(shù)wm,n am,n α β ξd π含義第m篇文檔的第n個詞第m篇文檔的第n個詞對應的發(fā)布者關于文檔-主題多項式分布的參數(shù)θm的Dirichlet分布參數(shù)關于主題-詞多項式分布的參數(shù)φk的Dirichlet分布參數(shù)發(fā)布者am,n服從參數(shù)為ξd的均勻分布發(fā)布者的格調(diào)極性,s1為格調(diào)極性高,s2為格調(diào)極性低
4 吉布斯抽樣
本文采用吉布斯采樣的方法對SLDA模型進行推導。根據(jù)式2,通過吉布斯采樣對每位發(fā)布者博文的每個詞項進行采樣,反復迭代使結果趨于穩(wěn)定。

其中zi=k,am,n=π表示在一篇文檔中的第i個詞項分配到的主題為k以及發(fā)布者am,n的格調(diào)極性為π。z-i表示除了第i個詞項的主題分布。Nw,k,π表示詞項w在主題k和格調(diào)極性π中出現(xiàn)的次數(shù),Nk,π,d表示文檔d中主題k和格調(diào)極性π中出現(xiàn)的次數(shù),Nk,d表示文檔d中k中出現(xiàn)的次數(shù),Nk,π表示主題k和格調(diào)極性π出現(xiàn)的次數(shù),Nd表示文檔d中詞項總數(shù)。
SLDA模型參數(shù)估計的吉布斯采樣迭代方式為:
(1) 設定發(fā)布者am,n博文文檔的格調(diào)極性為π;
(2) 更新格調(diào)分布的先驗ζd;
(3) 更新詞項的主題分布z和情感極性π。
經(jīng)過吉布斯采樣后,SLDA主題模型對φk、θm和π估計如式3、式4和式5所示:

根據(jù)上述吉布斯采樣公式可以得到發(fā)布者文檔d的詞項分布φk、主題分布θm以及情感極性π,通過概率計算,對發(fā)布者的整個博文文檔進行分析,就可以挖掘出每位發(fā)布者的格調(diào)極性是高的(π=s1)還是低的(π=s2)。
5 實驗分析
5.1 實驗準備
本文以新浪微博作為數(shù)據(jù)來源,利用網(wǎng)絡爬蟲爬取100位截止2017年7月的微博數(shù)據(jù)。由于采樣數(shù)據(jù)中常常包含不完整以及冗余的數(shù)據(jù),因此在獲取數(shù)據(jù)之后必須對數(shù)據(jù)進行預處理,提高數(shù)據(jù)的質(zhì)量,從而更好地完成挖掘任務。
5.2 困惑度分析
困惑度(Perplexity)[6]作為一種概率圖模型的性能評價指標,因其計算簡單、易于實現(xiàn)等優(yōu)點被廣泛應用于不同概率圖模型的比較分析中。在不同模型中輸入相同參數(shù)的情況下,困惑度越低表明模型的性能越高,主題模型困惑度的計算公式如式6所示:

其中,W表示關于發(fā)布者完整的文檔集,Nm表示第m篇文檔詞項的數(shù)量,p(wm)表示產(chǎn)生第m篇文檔的概率。p(wm)的計算公式如式7所示:
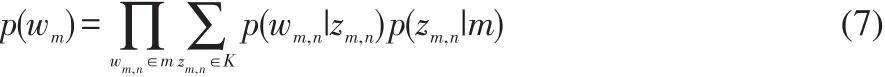
在LDA主題模型及SLDA主題模型輸入不同的迭代次數(shù)訓練文檔集,得到的困惑度對比如圖3所示:

圖3 LDA主題模型與SLDA主題模型困惑度對比
由圖3可以看出,在設定固定參數(shù)α=50/K,β=0.01以及輸入確定主題數(shù)K=10的情況下,隨著迭代次數(shù)的增加,LDA主題模型以及SLDA主題模型的困惑度均在逐漸減小。當?shù)螖?shù)小于200時,兩種主題模型的困惑減小幅度較大,當?shù)螖?shù)達到200后,困惑度減小的幅度平緩,困惑度曲線開始收斂,趨于一個較穩(wěn)定的范圍。SLDA主題模型在不同的迭代次數(shù)情況下,困惑度均小于LDA主題模型,可以發(fā)現(xiàn)SLDA主題模型對微博文本的主題提取效果更佳,性能也更高。
5.3 主題提取效果分析
在上一節(jié)的困惑度分析中,當?shù)螖?shù)達到200時,模型困惑度趨于平穩(wěn),所以在本實驗中設定迭代次數(shù)為200。選取10位發(fā)布者,把10位發(fā)布者的博文文檔輸入到改進前后的LDA主題模型中,提取10位發(fā)布者的主題,得到分主題詞分布情況如表2及表3所示:

表2 LDA主題模型挖掘發(fā)布者博文主題結果

表3 改進LDA主題模型挖掘發(fā)布者博文主題結果
表2和表3分別反映了改進前后的LDA主題模型對發(fā)布者的主題提取情況,可以發(fā)現(xiàn)經(jīng)過不同主題模型的訓練后,每位發(fā)布者的主題分布存在差異。在表3中ID為“母其彌雅”的用戶主題詞為“演員”、“健康”、“養(yǎng)生”、“瑜伽”、“健身”等,從這些詞中很容易可以發(fā)現(xiàn)發(fā)布者的主要興趣愛好為健身或者演藝類。而在表2中的主題詞出現(xiàn)了“沒有”、“共享”、“國家”等無法讀出興趣愛好的主題詞,對發(fā)布者的興趣愛好分析造成了一定的影響。對其他的發(fā)布者主題詞提取結果同“母其彌雅”類似,LDA主題模型提取得到的主題詞存在較多的無關主題詞,影響了主題的可讀性,對挖掘發(fā)布者的興趣愛好加大了難度。相反SLDA主題模型的挖掘效果要優(yōu)于LDA主題模型,減小了主題的區(qū)分難度。
5.4 格調(diào)提取分析
本實驗主要對發(fā)布者的格調(diào)主題詞進行了分類提取,通過LDA主題模型和SLDA主題模型抽取出格調(diào)相關詞項,總體來看,SLDA主題模型提取的格調(diào)詞項更加豐富。提取結果如表4所示:

表4 LDA主題模型與SLDA主題模型格調(diào)抽樣結果
從表4可以看出,LDA主題模型和SLDA主題模型提取的格調(diào)詞項存在一定的差異,而SLDA主題模型提取到的主題詞更能表達出發(fā)布者的主題。另一方面,兩種不同的主題模型都可以提取到格調(diào)極性不同的主題詞。
6 結束語
通過微博用戶的行為狀態(tài)等數(shù)據(jù)對發(fā)布者的格調(diào)進行分析和預測,對于推薦系統(tǒng)及個性化廣告等方面都有著巨大的價值。本文通過困惑度分析、主題提取效果以及對用戶的格調(diào)詞匯提取實驗證明了SLDA主題模型合理有效。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
