面向SaaS應用基于多寬表模式的多租戶索引研究
2018-07-25 11:21:44張雅文劉春霞黨偉超白尚旺
計算機應用與軟件 2018年7期
關鍵詞:數據庫
張雅文 劉春霞 黨偉超 白尚旺
(太原科技大學計算機科學與技術學院 山西 太原030024)
0 引 言
在SaaS應用中,一個應用實例為多個租戶服務,即雖然多租戶數據同屬于一個應用,但是被不同的租戶進行了不同的定制[1-2]。多寬表模式是一種有效存儲多租戶數據的解決方法,通過元數據驅動實現租戶定制需求[3]。傳統數據庫索引是在關系的某個特定屬性列上建立索引,多寬表存儲模式是將所有租戶不同數據模式的數據共享存儲,所以傳統的數據庫索引技術無法適用于多寬表模式[4]。因此本文給出元數據驅動下改進的Indexes Pivot Table IIPT(Improved Indexes Pivot Table)索引模型,該模型充當多寬表模式下的租戶邏輯索引,以此提高數據訪問速度。
1 SaaS應用下的索引模型
在現階段,面向SaaS應用的多租戶數據管理是國內外研究的重要內容,由于多租戶數據庫在滿足租戶數據隔離和按需定制要求的同時,在性能上也需使用戶有較好的體驗,因此這對數據的存儲機制和索引機制提出了挑戰[5]。多租戶數據存儲已經成為熱點,但是在索引方面的研究還比較少[6]。
SaaS應用采用單個數據節點對多租戶數據進行共享存儲,但是由于單個數據節點的能力有限,無法滿足租戶數量日益增長的要求,因此采用多數據節點進行存儲是必然的[7]。為解決多數據節點大規模數據索引的問題,采用租戶節點索引、租戶邏輯索引和關系數據庫物理索引三級索引相結合的索引模型[8]。租戶節點索引根據當前訪問的租戶,定位到存儲該租戶數據的數據節點。租戶邏輯索引在單節點上為租戶數據提供支持定制、共享的索引技術,保證租戶快速訪問數據。關系數據庫索引是一個單獨的、物理的數據庫結構,在底層數據庫基礎上提供索引技術支持[9]。
本文主要針對單數據節點的索引技術進行研究。單數據節點下的數據存儲為共享模式,如果一個租戶在某個屬性上建立索引,其他租戶也會被動地在該屬性建立索引,所以在創建索引時租戶間會相互干擾[10]。為了解決該問題,M-Store提出了單獨建立租戶索引,不僅優化了索引結構,而且提高了查詢效率,但是索引數據隨著租戶數量的增加也會越來越多,給數據庫造成很大的負擔[11]。Salesforce采用建立Indexes Pivot Table來存儲租戶索引數據,該方法有效地提高了租戶訪問數據的速度,但隨著租戶數量的增加,Indexes Pivot Table會產生大量的空值,其占用的存儲空間也會暴漲[12-13]。為了解決傳統數據庫索引不能適用多寬表共享存儲模式的問題,以及現有的索引模型導致數據庫存儲空間增長的問題,給出了一種元數據驅動的IIPT索引模型,不僅存儲空間不會隨租戶數量急速增長,而且有效提高了租戶訪問數據的速度。
2 多寬表模式下的租戶邏輯索引
在SaaS模式下,數據庫不但要提供存儲的功能,還要支持租戶按需定制、數據隔離以及數據擴展。結合國內外研究現狀,同時比較多種存儲模式優缺點,本文選擇了多寬表模式來存儲租戶業務數據,以及給出一種適合該模式的多租戶索引模型。
2.1 多寬表模式介紹
在SaaS應用中,多租戶的特性支持單個應用實例被不同租戶進行不同定制。寬表模式作為一種有效解決多租戶數據存儲問題的方法,是將所有租戶不同數據模式的數據存儲到一張寬表中,為了解決寬表存在大量空值的問題,提出了多寬表的存儲模式。
多寬表模式提供較好的可定制性,在該模式下,租戶按需定制數據項,將其定制信息保存在元數據(MetaDataFields)中,租戶定制的數據項經過模式映射后,根據數據表的元數據信息(MetaTable)存儲在與租戶定制列數相近的寬表Data x中,多寬表的數據定義如圖1所示。
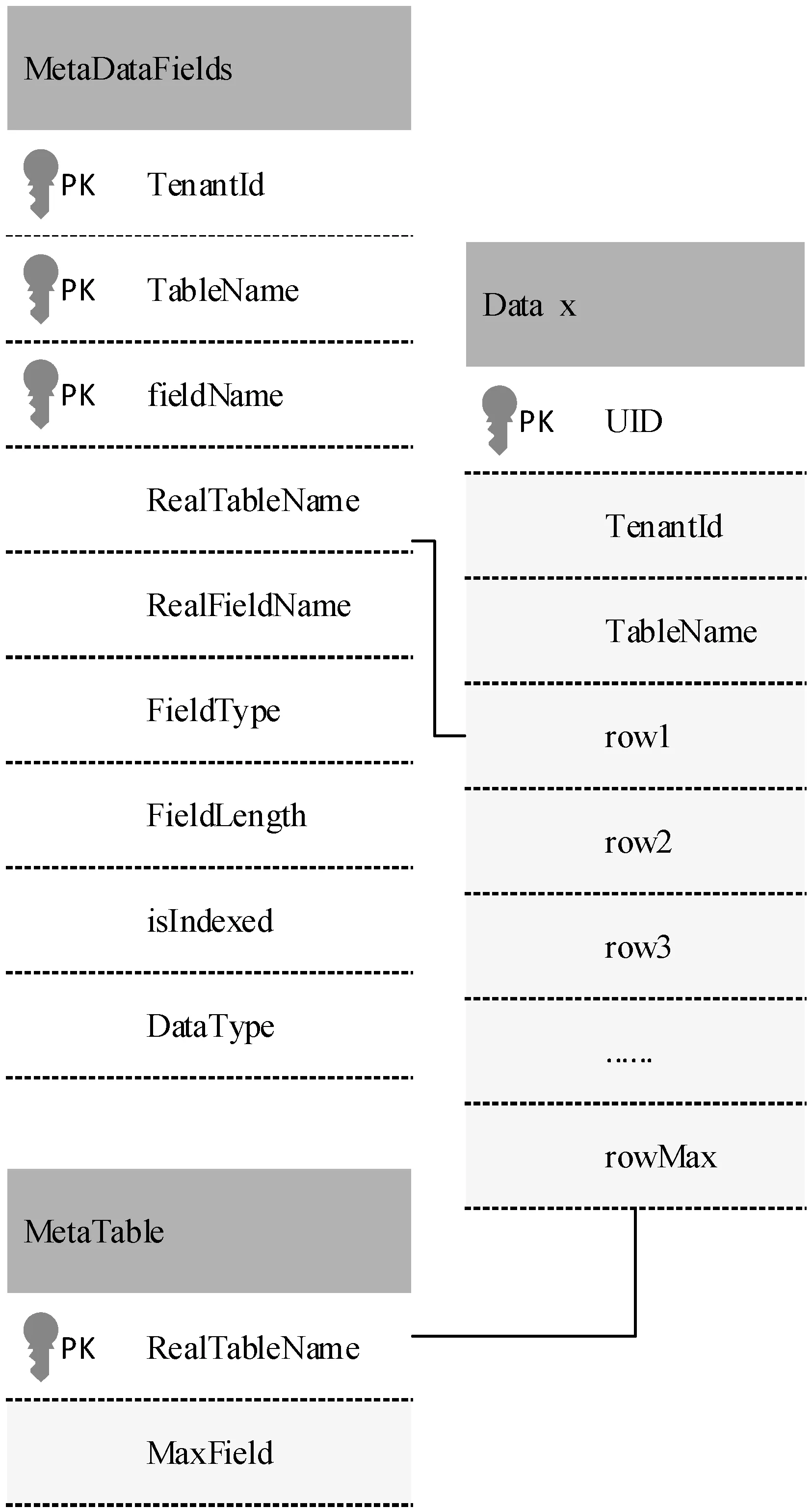
圖1 基于多寬表的多租戶數據庫
如表1所示,租戶從視圖層看到的是傳統的關系數據模式,但是在實際的多寬表存儲模式中,基于定制的元數據信息,該關系通過模式映射機制被透明的轉換到寬表(Data x)中,如表2所示。
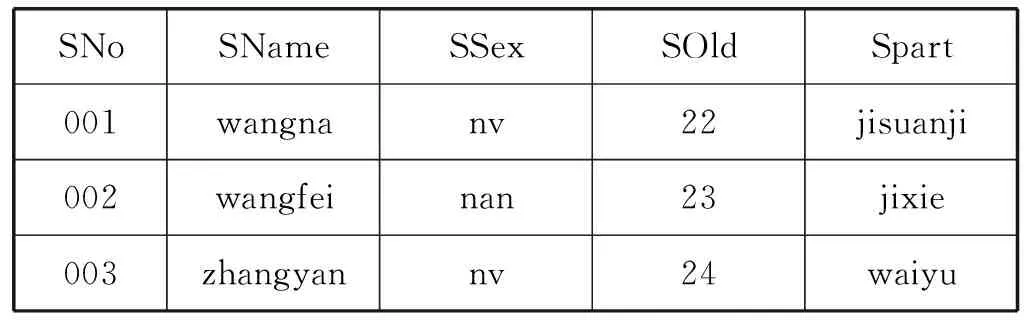
表1 租戶1從視圖層看到的關系
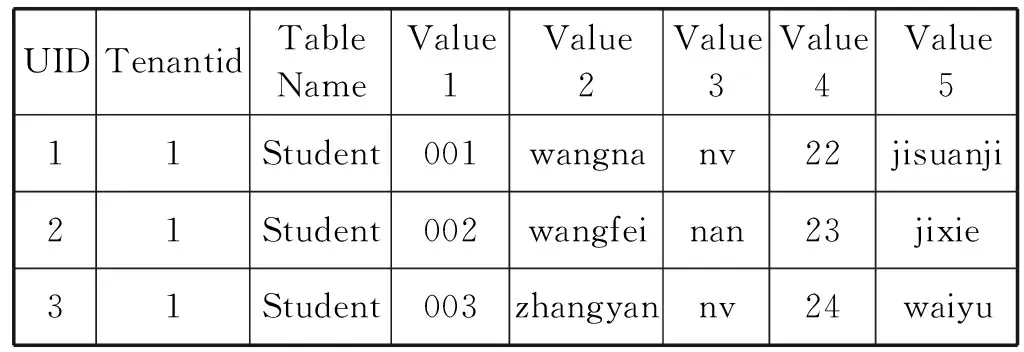
表2 租戶1存儲層的關系
多寬表共享存儲多租戶不同業務下不同的數據模式,隨著租戶數量的不斷增加,數據量也會急劇增加,訪問數據時通過順序掃描查詢勢必會影響查詢效率,因此建立多寬表數據存儲模式下的多租戶索引模型勢在必行。傳統索引是在關系的某個特定屬性列上建立索引,該屬性列下數據的數據類型、數據模式是相同的,但是多寬表存儲著多種不同的數據模式,同一屬性列數據可能是不同的數據類型或代表不同的數據含義。因此給出了一種元數據驅動改進的Indexes Pivot Table索引模型。
2.2 基于Indexes Pivot Table的多租戶索引模型
Salesforce建立Indexes Pivot Table存儲索引數據。Indexes Pivot Table中包含字段如StringValue、NumValue和DateValue等,Salesforce將索引數據按數據類型存儲在相應的字段中。例如,Salesforce會將數據表中字符串數據類型的數據復制到索引表中的StringValue字段,日期類型的數據復制到DateValue字段等。該Indexes Pivot Table在存儲索引數據時,如果其中一個數據類型字段存儲了索引數據,則其他數據類型為空值。隨著數據量的增大,空值的數量也會逐漸增大,浪費了存儲空間。針對產生大量空值的情況,對Indexes Pivot Table進行改進,將多種數據類型字段合并存儲在一列中,有效解決了空值產生的問題。
2.3 基于多寬表的多租戶索引模型
本文對多寬表模式的多租戶數據庫進行擴展,增加了基于元數據驅動改進的Indexes Pivot Table。圖2描述了IIPT多租戶數據庫模型,模型中的表分為兩種。一種為元數據表,另一種為數據表。元數據表包括字段元數據MetaDataFields、多寬表的元數據MetaTable以及索引元數據IndexDataTable。數據表包括一系列的寬表Data。
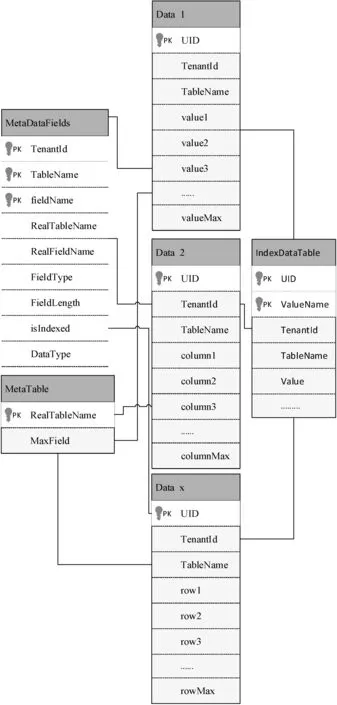
圖2 IIPT多租戶數據庫模型
下面給出本模型的表結構定義。
定義1MetaDataFields
表示字段元數據,用于存儲Data寬表的信息以及其中屬性的各種信息。租戶標識TenantId、租戶邏輯私有表標識TableName,以及寬表所屬列名fieldName聯合作為主鍵,通過RealTableName可以映射出租戶業務數據fieldName實際物理存儲位置,而RealFieldName可以映射Data寬表中fieldName的真正含義。fieldType、fieldLength、isIndexed、DataType分別表示fieldName的屬性:類型、長度、是否為索引、真正的數據類型。
定義2MetaTable
表示多寬表的元數據,用于存儲所有Data寬表的基本信息,包括寬表的表名和列數等信息,該信息作為租戶選擇寬表進行存儲的依據。
定義3IndexDataTable
表示索引元數據,用于共享存儲多寬表的索引。Indexes Pivot Table存儲多種數據類型的索引數據,造成索引表中空值的增多。本文對Indexes Pivot Table進行改進,將多種數據類型共同存儲在一列中。通過訪問字段元數據表,對于需要建立索引的數據,將其從寬表復制到索引表中,無需關注數據類型。
定義4Data1, Data2, Data x
表示數據表,寬表的列數呈遞增趨勢分布。租戶根據數據模式具有的屬性列數選擇合適的寬表存儲業務數據。UID是全局唯一標識作為寬表的主鍵,與租戶標識TenantId和租戶邏輯私有表標識TableName一起對租戶的業務數據進行共享存儲,它們的最大列數分別為valueMax、columnMax、rowMax。
3 基于多寬表的多租戶索引維護策略
租戶索引具有可定制性,定制過程就是根據租戶需求及對關系模式中某字段適合作為索引的判斷,將字段元數據表(MetaDataFields)中的isIndexed字段設置為yes。在對實時性要求較高的SaaS應用中,如果沒有索引更新策略是不可行的。當業務數據插入、刪除、修改時,索引元數據需同時更新;當業務數據查詢時,首先根據字段元數據表判斷是否存在索引,如果存在按照索引查詢,并返回結果,如果不存在,則順序查詢,返回查詢結果。本文給出IIPT索引模型的索引插入算法IIPTIA(Improved Indexes Pivot Table Insert Algorithm),索引刪除算法IIPTDA(Improved Indexes Pivot Table Delete Algorithm),索引更新算法IIPTUA(Improved Indexes Pivot Table Update Algorithm)及查詢算法IIPTQA(Improved Indexes Pivot Table Query Algorithm)。
算法1索引插入算法(IIPTIA)
輸入:insert into R (A,B,…) values(value1,value2,value3,…)
輸出:null
1. 獲取當前租戶標識Tenantid;
2. 根據輸入語句更新數據庫中的業務數據表Data,保存全局唯一標識(UID);
3. 根據租戶標識Tenantid,for私有表R中的字段A,B,…,在字段元數據表MetaDataFields中判斷出R定制的索引列;
4. 取出索引列上更新的值;
5. 根據索引元數據表的結構對索引值進行存儲。
算法2索引刪除算法(IIPTDA)
輸入:delete from R where A=′b′;
輸出:null
1. 獲取當前租戶標識Tenantid;
2. 根據輸入語句獲得私有表名稱R與列名A,查詢字段元數據表MetaDataFields取得實際存儲表名與實際列名;
3. 根據步驟2得出實際刪除業務數據的SQL語句;
4. 根據步驟2對實際存儲的表進行查詢,保存要刪除信息的全局唯一標識UID;
5. 根據步驟4中所得UID對索引表進行刪除操作,由此當對業務數據進行刪除操作時,業務數據所對應的索引數據也同步進行刪除。
算法3索引更新算法(IIPTUA)
輸入:update A set B=′b′ where C=′c′;
輸出:null
1. 獲取當前租戶標識Tenantid;
2. 根據輸入語句獲得私有表名稱R、列名A與列名B,查詢字段元數據表MetaDataFields取得實際存儲表名與實際列名,以及set的列是否為索引列;
3. 對sql語句進行解析,獲得索引更新值b與條件值c;
4. 根據步驟2與步驟3得出實際更新業務數據的SQL語句;
5. 根據步驟2與步驟3對實際存儲的表進行查詢,保存要更新信息的全局唯一標識UID;
6. if步驟2中結果為yes
根據步驟5中得到的UID對索引數據表進行更新
else步驟2中的結果為no。
無需對索引表進行更新。
算法4數據查詢算法(IIPTQA)
輸入:select A,B,… from R where D=value1
輸出:符合條件的目標結果集
1. 獲取當前租戶標識Tenantid;
2. 解析查詢語句中的私有表R和所查字段A,B,…;
3. 查詢字段元數據表(MetaDataFields)獲得私有表R實際存儲表名Data,以及所查字段(A,B,…)在Data表中的實際字段名value n(n=1,2,…,n);
4. 查詢字段元數據表(MetaDataFields)獲得where條件D是否為索引;
5. If 步驟4中結果為yes
查詢索引元數據表(IndexDataTable)獲得數據行全局唯一標識UID;
在Data表中,根據UID字段上的數據庫物理索引B-樹,直接查;
返回符合條件的目標數據集。
Else 步驟4中的結果為no
依次將A,B,…,D用查詢到的實際字段名value n替換,將R用Data表替換;
替換后拼接成可直接作用于Data表的查詢語句,進行查詢;
返回符合條件的目標數據集。
4 實驗結果與分析
本文實現了基于關系型數據庫,在多寬表共享數據存儲模式下元數據驅動的索引機制。實驗主要針對空值數量進行分析,并對本文給出的索引策略進行驗證。實驗環境如下:
數據庫版本為MySQL Server 5.5,運行環境為Eclipse 3.7.2。
4.1 空值數量的分析
在存儲單元的基礎上對空值數量進行分析,假設存儲N個索引數據。若采用Indexes Pivot Table存儲,其中表示數據類型的字段有M個,則存在(M-1)×N個空值。
若采用IIPT存儲,所有索引數據只存儲在一個字段中,沒有空值產生。
分析可得,采用改進的Indexes Pivot Table,相對于Indexes Pivot Table,解決了空值問題,節省了存儲空間。
4.2 索引策略驗證
實驗數據采用3個關系模式作為實例,分別為:學生(Student)關系模式、課程(Course)關系模式和地址(NativePlace)關系模式。定制關系模式中的一個屬性為索引屬性,分別為CNo、NNo和SOld。3個關系模式的數據經過模式映射存儲在合適的Data表中,Data表中字段UID上有主碼索引,Data表數據量為10 000條。
由租戶發起insert插入數據的更新操作,實驗算法1中的索引插入。例句如下:
insert into Course (CNo,Cname,CGrade) values (8,yuwen,2)
insert into NativePlace(NNo,Nname,NPlace) values (001,wangli,beijing)
insert into Student(SNo,Sname,SSex,SOld,Spart) values (001,wangna,nv,22,jisuanji)
分別更新數據到各自的Data表中,如表3和表4所示。
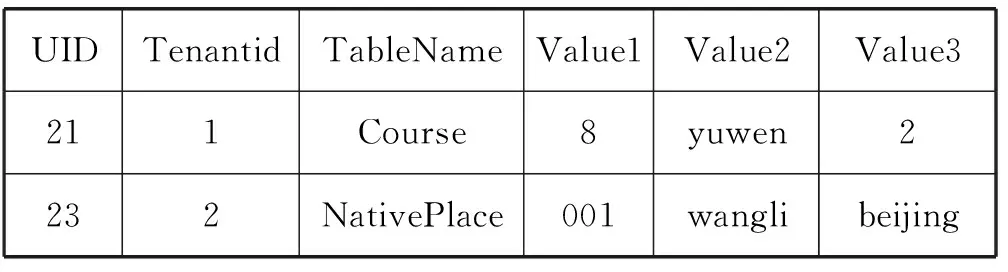
表3 Course和NativePlace所在Data表
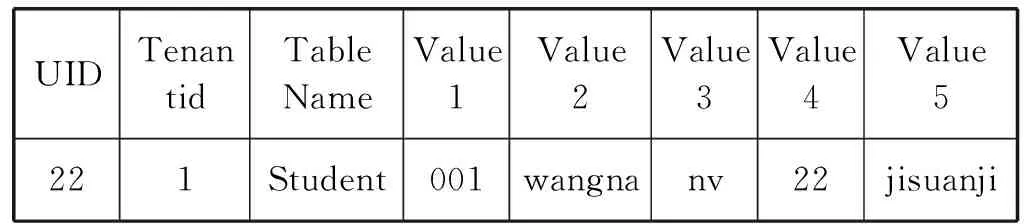
表4 Student所在Data表
根據更新的數據對索引表同步更新,如表5所示。
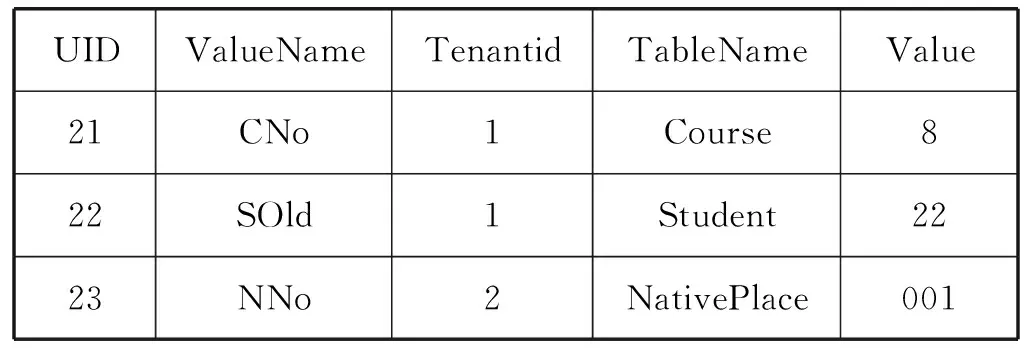
表5 改進的Indexes Pivot Table
以上實驗實現了算法1的索引插入的更新策略。
由租戶發起delete刪除數據的更新操作,實驗算法2中的索引刪除。例句如下:
delete from Student where SNo=′000′
根據算法2可成功刪除實際存儲表中Student 學號為′000′的數據,同時也刪除了索引表中該學生的所有索引信息。
由租戶發起update數據的更新操作,實驗算法3中的索引更新。例句如下:
update Student set SOld=′30′ where SNo=′000′
根據算法3,判斷得出SOld為索引列,因此在更新業務數據的同時對索引表也進行更新。
update Student set SName=′zhangli′ where SNo=′000′
根據算法3,判斷得出SName不是索引列,因此只需更新業務數據,索引表保持不變。
為了模擬多租戶環境,本實驗開啟40個線程作為40個租戶對數據進行操作。記錄有索引機制與沒有索引機制40個租戶分別對數據進行查詢的時間,實驗結果如圖3所示。
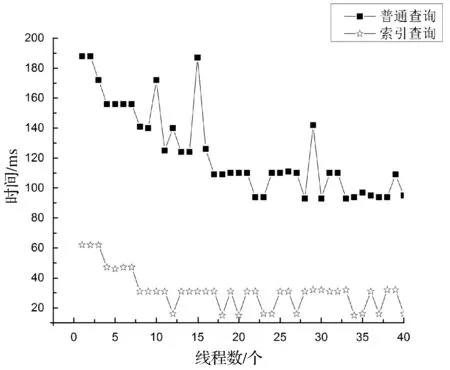
圖3 查詢時間對比
如圖3所示,圖中上方的曲線是沒有加入索引機制的查詢時間,下方是加入索引機制后的查詢時間。在無索引機制下,40個租戶的平均查詢時間為123.675 ms;在索引機制下,平均查詢時間為30.025 ms,比無索引機制的平均查詢時間低75.72%。通過實驗驗證可得,在兩級索引即租戶邏輯索引和關系數據庫物理索引的基礎上,本文給出的算法是可實現的,并且提高了多租戶數據查詢效率。
綜上所述,給出的多寬表模式下的索引模型,較好地解決了SaaS應用索引的定制問題,以及在查詢效率上實驗效果也較為理想。
5 結 論
本文基于MySQL關系型數據庫,在多寬表數據存儲模式下引入改進的Indexes Pivot Table,減少了Indexes Pivot Table作為索引表產生的空值數量。同時給出了在該模型下的索引維護策略,包含索引更新策略和在索引機制下的查詢策略,通過實驗實現了同步更新索引表以及有效提高數據查詢效率。在下一步研究中,如何對索引列更全面地進行設置是需要考慮的問題。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
