基于Bi-LSTM和分布式表示的網(wǎng)頁主題相關(guān)度計算
2018-07-25 11:21:40蔡東風(fēng)王鐵錚
計算機應(yīng)用與軟件 2018年7期
王 鋒 白 宇 蔡東風(fēng) 王鐵錚
(沈陽航空航天大學(xué)計算機學(xué)院 遼寧 沈陽 110136) (遼寧省知識工程與人機交互工程技術(shù)研究中心 遼寧 沈陽 110136)
0 引 言
計算網(wǎng)頁主題和特定主題的相關(guān)度能輔助技術(shù)人員在海量的互聯(lián)網(wǎng)數(shù)據(jù)中發(fā)現(xiàn)與特定主題相關(guān)的網(wǎng)頁。目前最普遍的相關(guān)度計算的模型是向量空間模型[1](VSM),而最典型的向量空間模型是Bag-of-Words,因為它具備簡單性、有效性和經(jīng)常令人驚奇的準確性。該方法以文本中的詞作為特征項形成向量表示,并且特征權(quán)重以詞的TF-IDF值的形式表示。盡管Bag-of-Words經(jīng)常被使用,但它有兩個主要缺點:一是失去了詞的順序,二是忽略了詞的語義。當(dāng)詞的順序丟失時,不同的句子可以具有完全相同的表示,只要使用相同的詞即可。即使n-grams在短時間內(nèi)考慮了單詞順序,它也受到數(shù)據(jù)稀疏和高維度的影響。Bag-of-Words和Bag-of-n-Gram對于這些詞的語義或單詞之間的距離幾乎沒有意義。這意味著“高鐵”、“動車”和“沈陽”同樣遙遠,盡管語義上“高鐵”應(yīng)該比“沈陽”更接近“動車”。
本文綜合現(xiàn)有方法的優(yōu)缺點,提出一種基于雙向LSTM[2]和分布式表示的網(wǎng)頁主題相關(guān)度計算方法。首先將查詢關(guān)鍵詞通過分布式表示和雙向LSTM表示成向量形式,然后在詞向量空間中找出與其語義上相近的詞,并將其添加到查詢關(guān)鍵詞中,再將搜索到的網(wǎng)頁通過基于文檔的分布式表示方法形成網(wǎng)頁向量與主題關(guān)鍵詞進行相關(guān)度計算。本文將上述方法實現(xiàn)并在搜狗實驗室公開的測試數(shù)據(jù)集上進行了測試。
1 相關(guān)研究
1.1 詞的向量表示
自然語言處理中,將詞的向量表示的最簡單方法是One-hot 表示方法。其主要思想是將詞形成一個與詞表長度一致的稀疏向量,除詞所在維度為1,其余維度都為0。比如:“動車”和“高鐵”,“動車”表示為[0,0,1,0,0,…,0,…],“高鐵”表示為[0,0,0,0,1,0,…,0,…]。如果采用稀疏方式存儲,會非常簡單。但“動車”和“高鐵”是語義上近似的詞,而這種方法表示出的向量卻無法反映這點[3]。這種方法存在兩個缺點,一方面是向量的維度會隨著文本中詞匯數(shù)目的增加而增加;另一方面是任意兩個詞語都是獨立存在,沒有語義層面的表示[4]。
1.2 相關(guān)度計算
早在20世紀70年代,Salton等就提出來VSM算法來計算文檔間的相似度。VSM是一種簡單有效的計算文檔相似度的方法,VSM常采用TF-IDF算法計算文檔特征詞的權(quán)重,然后將文檔表示成向量形式就可以用余弦公式[5]來計算文檔相似度了。但是這種方法丟失了詞序且沒有考慮詞語背后的語義信息,忽視了詞與詞之間的相似度。人們?yōu)榱烁珳实赜嬎阄谋鞠嗨贫龋岢隽艘恍┗谡Z義的相似度計算方法,如文獻[6]利用WordNet語義詞典研究局部相關(guān)性信息以此來確定文本之間的相似性。上述方法采用領(lǐng)域知識庫來構(gòu)建詞語間的語義關(guān)系,與基于統(tǒng)計學(xué)的方法相比準確率有提高,但是知識庫的建立是一項復(fù)雜而繁瑣的工程,需要耗費大量人力。
網(wǎng)頁主題相關(guān)度計算的研究是為了提高特定主題相關(guān)網(wǎng)頁的發(fā)現(xiàn),隨著研究的深入,研究者們提出來許多網(wǎng)頁主題相關(guān)度計算方法。文獻[7]提出了基于VSM的計算方法,根據(jù)向量空間模型思想,結(jié)合網(wǎng)頁結(jié)構(gòu)和概念層次關(guān)系,優(yōu)化網(wǎng)頁特征和權(quán)重,以提高網(wǎng)頁主題相關(guān)度計算的準確性。綜合上述的網(wǎng)頁主題相關(guān)度計算方法的優(yōu)缺點,本文提出一種基于雙向LSTM和分布式表示的網(wǎng)頁主題相關(guān)度計算方法,通過將詞的分布式表示應(yīng)用到查詢關(guān)鍵詞擴展中,同時將文檔的分布式表示應(yīng)用到網(wǎng)頁主題相關(guān)度計算上,提升了相關(guān)網(wǎng)頁識別的精度。
2 基于雙向LSTM和分布式表示的網(wǎng)頁主題相關(guān)度計算
本文在傳統(tǒng)的VSM的基礎(chǔ)上,在進行主題關(guān)鍵擴展時采用了基于雙向LSTM和詞的分布式向量表示的查詢擴展方法,在進行網(wǎng)頁主題相關(guān)度計算時采用了基于文檔的分布式向量表示的網(wǎng)頁相關(guān)度計算方法。
2.1 分布式表示
2.1.1 詞的分布式表示
詞的分布式表示[8]是指將詞表中的詞映射為一個稠密的、低維的實值向量,深度學(xué)習(xí)中一般用到的詞向量就是用分布式表示的一種低維實數(shù)向量。詞的分布式向量表示可以通過上下文中給出的其他單詞來預(yù)測下一個詞。在分布式表示中,每個詞被映射到由矩陣W中的列表示的唯一向量,該列通過詞在詞匯表中的位置進行索引。然后將向量的連接或平均值作為特征來預(yù)測句子中的下一個詞。如圖1所示,使用三個詞(“小明”,“提交”和“一篇”)的上下文來預(yù)測第四個單詞(“論文”)。將輸入詞映射到矩陣W的列以預(yù)測輸出詞。
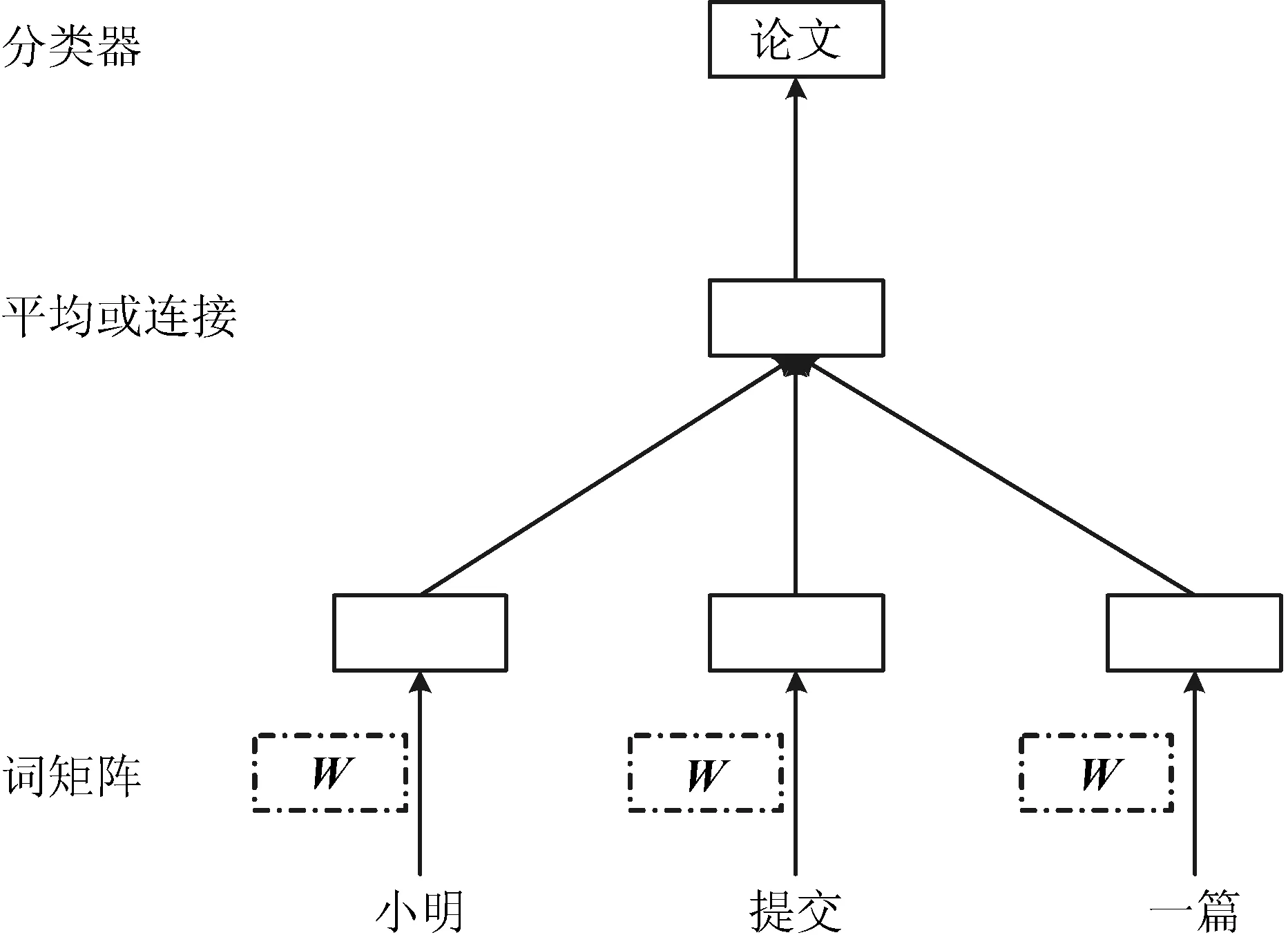
圖1 詞的分布式向量表示的學(xué)習(xí)框架
訓(xùn)練時,詞向量模型的目的是使平均對數(shù)概率L如式(1)最大化(分類器是Softmax),其中p(wt|wt-k,…,wt+k)如式(2),y如式(3)所示:
(1)
(2)
y=b+Uh(wt-k,…,wt+k;W)
(3)
詞分布式表示的訓(xùn)練方法有很多,Bengio等[9]提出FFNNLM模型(Feed-Forward Neural Net Language Model)可以訓(xùn)練出詞的向量表示形式,不過FFNNLM并非是專門用來訓(xùn)練詞向量的。相比較FFNNLM模型,Word2Vec運行速度更快。Word2vec作為一種高效地將詞表示為低維實數(shù)向量的詞向量工具,使用神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)分布式向量表示,每個單詞由在上下文中與其他單詞向量連接或平均的向量表示,并且所得到的向量用于預(yù)測上下文中的其他單詞[10]。例如“動車”的分布式向量表示為[0.452,-2.194,1.095,2.094,…],“高鐵”的分布式向量表示為[2.831,-1.369,-0.350,-1.202,…]。
2.1.2 文檔的分布式表示
文檔的分布式向量表示可以從可變長度的文本片段(如句子、段落和文檔)中學(xué)習(xí)固定長度的特征表示,通過密集的向量表示每個文檔,該向量被訓(xùn)練來預(yù)測文檔中的單詞[11]。文檔的分布式向量表示無監(jiān)督為文本片段學(xué)習(xí)連續(xù)的分布式向量表示。文本可以是可變長度,從句子到文檔。即該方法可以應(yīng)用于可變長度的文本段,從短語或句子到大型文檔的任何內(nèi)容。
每個段落被映射到由矩陣D中的列表示的唯一向量,并且每個單詞也被映射到由矩陣W中的列表示的唯一向量。段落向量記住當(dāng)前上下文中丟失的內(nèi)容或段落的主題,即PV-DM模型如圖2所示。該模型的唯一變化是在式(1)中,其中h由W和D構(gòu)成。算法本身有兩個關(guān)鍵的階段:第一是訓(xùn)練以獲得已經(jīng)看到的段落的單詞向量W,Softmax權(quán)重U、b和段落向量D。第二是通過在D中添加更多的列和在D上梯度下降來獲得新段落的段落向量D,同時保持W、U、b固定。
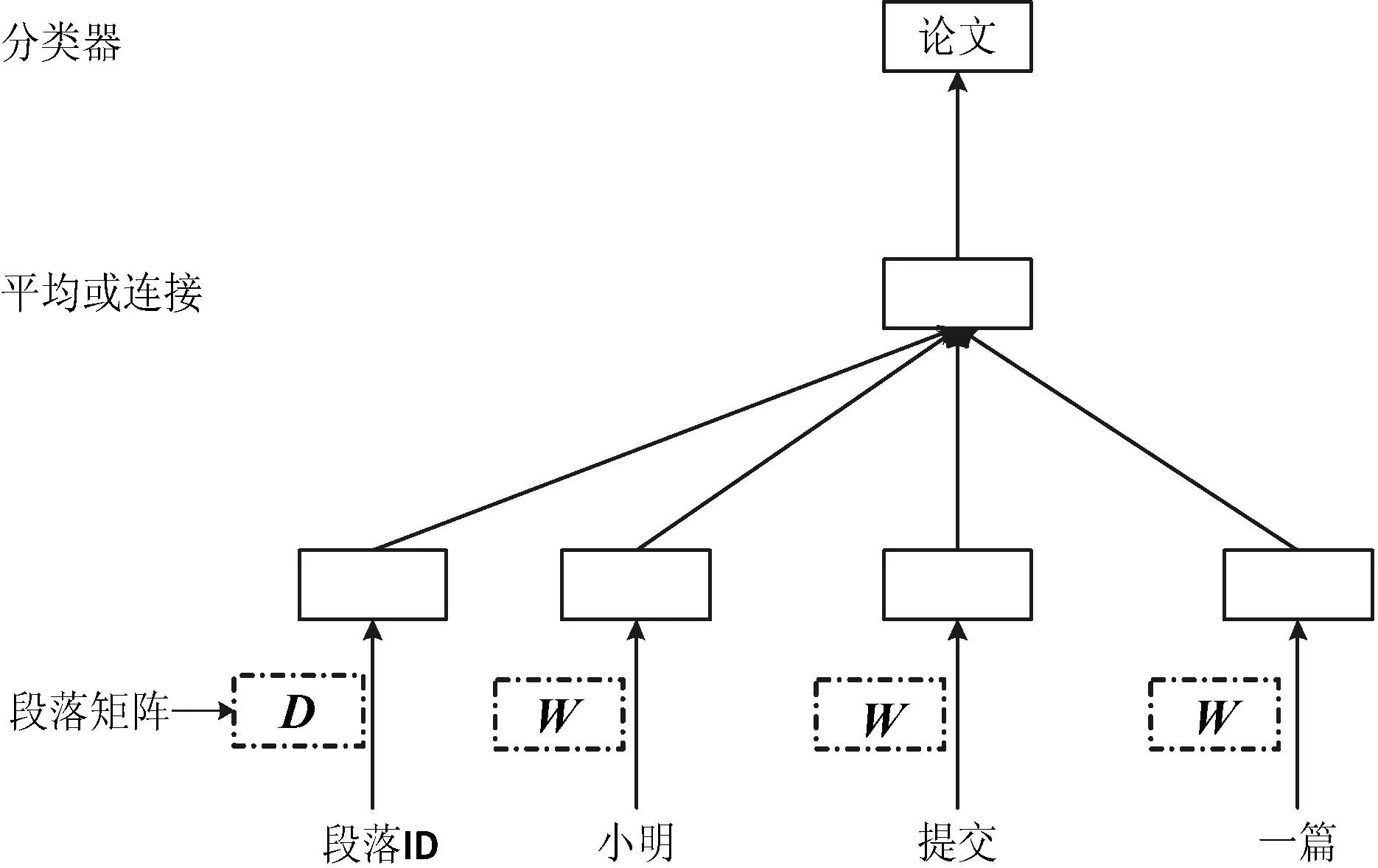
圖2 文檔的分布式向量表示的學(xué)習(xí)框架(PV-DM)
文檔的分布式向量表示的一個重要優(yōu)點是它們是從沒有標簽的數(shù)據(jù)中學(xué)習(xí)的,且包含語義信息和詞序。上述方法考慮了段落向量與詞向量的連接以預(yù)測文本窗口中的下一個詞。另一種方法是PV-DBOW模型如圖3所示,在給定段落向量的情況下形成一個分類任務(wù),而不是前面PV-DM模型,在PV-DBOW模型中段落向量被訓(xùn)練以預(yù)測小窗口中的詞。在本文中,每個段落向量是兩個向量的組合:一個向量是分布式記憶的標準段向量模型(PV- DM模型),一個向量是沒有詞序信息的分布式詞袋模型(PV-DBOW模型)。
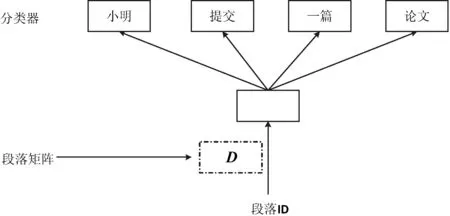
圖3 文檔的分布式向量表示學(xué)習(xí)框架(PV-DBOW)
在進行網(wǎng)頁主題相關(guān)度計算時采用文檔的分布式表示即用Doc2Vec[12]生成網(wǎng)頁的分布式向量表示和主題關(guān)鍵詞計算網(wǎng)頁主題相關(guān)度,確定其相關(guān)度閾值φ,由φ來判斷網(wǎng)頁是否相關(guān),相似度計算小于φ的網(wǎng)頁則認為不相關(guān)。
2.2 雙向LSTM
詞嵌入(詞的分布式表示)可以在緊湊低維的詞向量表示中捕獲單個詞的語義和句法信息,但是預(yù)訓(xùn)練的詞嵌入所包含的關(guān)于詞與句子語境作為一個整體的信息是有限的,多數(shù)都是對詞窗口內(nèi)的詞有所傾向性的。而雙向RNN尤其是LSTM,適用于在更大范圍的句子語境中學(xué)習(xí)內(nèi)在表示,可以有效學(xué)習(xí)長句的語境向量。將整個句子語境和目標詞嵌入到同一低維空間,進一步優(yōu)化以反映目標詞和其整個句子語境作為整體的內(nèi)部依賴關(guān)系。
為了從詞周圍可變長度的句子語境學(xué)習(xí)一個通用的嵌入函數(shù),如圖4所示,在Word2Vec的CBOW模型中,將它原來在固定窗口內(nèi)的詞嵌入取平均作為語境模型,替換成一個更有效的神經(jīng)網(wǎng)絡(luò)模型——雙向LSTM。
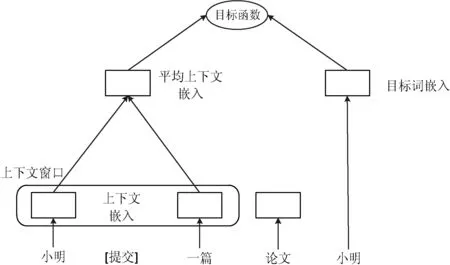
圖4 Word2vec的CBOW模型
兩個模型都同時學(xué)習(xí)語境和目標詞的分布式表示,通過一同嵌入低維向量空間,目的是用上下文語境預(yù)測目標詞,通過一個對數(shù)線性模型。不同的是,雙向LSTM更能有效地捕捉句子語境的本質(zhì)。
圖5說明了雙向LSTM是如何表示句子語境的,把句子中的詞從左到右輸入一個LSTM,從右往左輸入另一個LSTM,這兩個網(wǎng)絡(luò)的參數(shù)是完全分開的,包括兩個獨立的從左至右和從右至左的語境詞向量。
給定一個句子w1:n,我們對目標詞wi的雙向LSTM語境表示定義為以下向量連接:
biLS(w1:n,i)=lLS(l1:i-1)⊕rLS(rn:i+1)
(4)
式中:l/r表示句子中詞的從左到右和從右到左詞嵌入,和標準的雙向LSTM不同,我們并不將目標詞wi本身輸入到LSTM中。
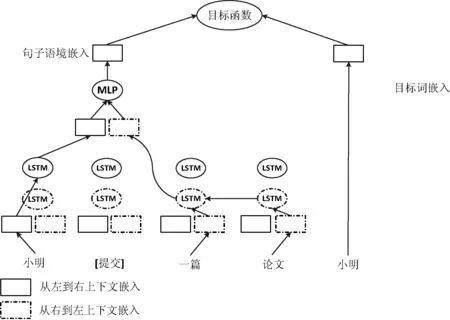
圖5 雙向LSTM
為表示句子中目標詞的語境(例如,“小明 [提交] 畢業(yè) 論文”) ,首先將LSTM輸出的從左到右語境(“小明”)的向量表示和從右到左(“畢業(yè) 論文”)的向量表示連接起來,這樣做的目的是獲得句子語境中的相關(guān)信息,即使有時它離目標詞很遠。
接下來,對左右語境表示的連接使用非線性函數(shù)。
MLP(x)=L2(ReLU(L1(x)))
(5)
式中:MLP代表多層感知機,ReLU[13]是激活函數(shù),Li(x)=Wix+bi是全連接線性操作。將連接后的向量輸入到多層感知機,就可以表示兩側(cè)文本的重要依賴。將此層的輸出作為目標詞整個連接句子語境的嵌入。雙向LSTM和Word2Vec的CBOW模型之間的唯一差別是CBOW模型是對目標詞語境表示為周圍一定窗口內(nèi)語境詞的簡單平均,雙向LSTM則使用了語境的全句神經(jīng)表示。讓c=(w1,…,wi-1,-,wi+1,…,wn)代表目標詞wi的句子語境。目標詞及其語境的向量維度相同,語境向量C:
C=MLP(biLS(w1:n,i))
(6)
式中:求和遍歷訓(xùn)練語料中的每一個詞t和它所對應(yīng)的句子語境c、σ表示sigmoid函數(shù)[14]。采用word2vec中的負采樣目標函數(shù)如式(7)來學(xué)習(xí)語境嵌入網(wǎng)絡(luò)的參數(shù)、目標詞向量和語境向量。可以根據(jù)詞向量的余弦相似度找出與其語義上相近的詞,在本文中主要是根據(jù)詞的分布式表示和雙向LSTM來做查詢擴展。
(7)
3 實驗及結(jié)果分析
3.1 查詢擴展實驗
查詢擴展分別是基于詞的分布式表示和雙向LSTM的,詞的分布式表示實驗使用Word2Vec工具,搜狗實驗室公開的搜狗全網(wǎng)新聞數(shù)據(jù)作為詞向量訓(xùn)練語料,使用Skip-gram模型訓(xùn)練且訓(xùn)練的窗口大小為5,生成200維的詞向量,基于雙向LSTM的查詢擴展實驗使用相同的訓(xùn)練語料生成詞向量。設(shè)計了三個實驗,實驗1是比較查詢擴展詞的個數(shù)對檢索性能的影響,得到擴展詞后,逐漸增加擴展次數(shù),比較檢索結(jié)果;實驗2是比較查詢擴展詞的相關(guān)度閾值對檢索性能的影響,同時和實驗1的結(jié)果作比較;實驗3是把本文方法和其他查詢擴展方法做個比較。
為了精確地判定擴展查詢結(jié)果的準確度,用平均準確率MAP和n位置的準確率Pn來評測。MAP是所有標準相關(guān)網(wǎng)頁的所有查詢的AP平均值,檢索到的相關(guān)網(wǎng)頁位置越靠前,那么MAP值便會越靠前,如公式所示:
(8)
式中:r為標準相關(guān)網(wǎng)頁數(shù);wi為第i個相關(guān)網(wǎng)頁;n(wi)為第i個相關(guān)網(wǎng)頁的排序。
Pn是指對一個排序結(jié)果,返回前n個結(jié)果的準確率。有時用戶使用搜索引擎時可能只對返回的前n個網(wǎng)頁感興趣,Pn就是從這樣的角度對檢索性能進行衡量的評價標準,如公式所示:
(9)
式中:n是返回的前n個網(wǎng)頁,Wn是前n個網(wǎng)頁的相關(guān)與否。
從圖6中可以看出,擴展詞數(shù)量在0到6之間時,隨著查詢擴展詞數(shù)的增加,檢索性能MAP和Pn都有一定幅度的提高,當(dāng)擴展詞數(shù)達到6時,檢索性能達到最優(yōu)。當(dāng)擴展詞數(shù)達到6之后。增加擴展詞個數(shù)并沒有繼續(xù)增加檢索性能,反而性能有一定的下降。由此可見,查詢擴展詞數(shù)應(yīng)該選擇6的時候檢索性能最好,太多的話會引入噪聲。
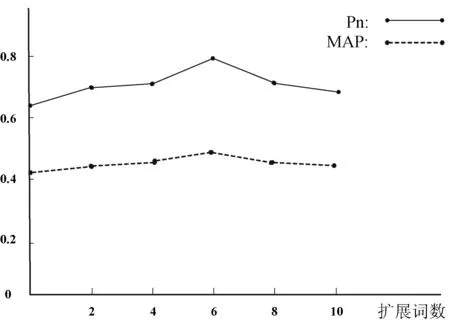
圖6 不同擴展詞個數(shù)的實驗結(jié)果
為了進一步驗證實驗1,對查詢擴展的相關(guān)度閾值設(shè)置進行實驗,如圖7所示,當(dāng)查詢擴展的相關(guān)度閾值大于0.6時,MAP和Pn的檢索性能達到最優(yōu),平均閾值為0.6時,檢索性能最優(yōu),這時的擴展詞數(shù)也是接近6,驗證了實驗1的查詢擴展詞數(shù)。
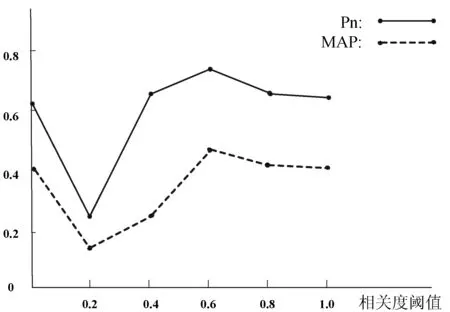
圖7 不同相關(guān)度閾值的實驗結(jié)果
實驗3是把本文擴展方法和其他查詢擴展方法做了比較,相同實驗參數(shù)下,查詢擴展詞數(shù)為6個時,基于HowNet[15]語義詞典的查詢擴展方法為W1,基于本體和局部共現(xiàn)的查詢擴展方法[16]為W2,本文基于雙向LSTM和詞的分布式表示方法為W3,實驗3的平均準確率和n位置的準確率如圖8所示。
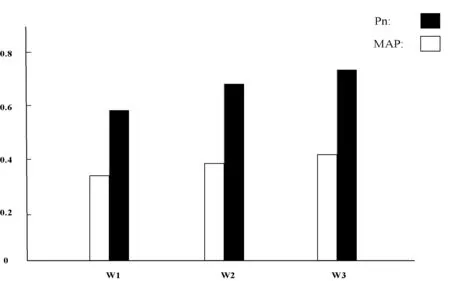
圖8 不同擴展方法的實驗結(jié)果
從圖8中可以看出,本文的方法和其他查詢擴展方法相比較平均準確率和n位置的準確率都有一定的提高。這主要是因為詞的分布式表示和雙向LSTM生成的詞向量都包含了語義相關(guān)的信息,同時也包含了上下文及詞序信息,這使得查詢擴展方法的效果有所提升。
3.2 網(wǎng)頁主題相關(guān)度計算實驗
查詢擴展在基于詞分布式表示和雙向LSTM的關(guān)鍵詞擴展后得到最終的主題關(guān)鍵詞集合,再做進一步的實驗。本文提出的基于分布式表示的網(wǎng)頁主題相關(guān)度計算方法在Sogou實驗室的評測數(shù)據(jù)中的國際類、體育類、社會類和娛樂類語料上進行測試。文檔的分布式表示實驗采用DBOW模型,訓(xùn)練的窗口大小為8,迭代200次生成200維的文檔向量。
文檔的分布式表示實驗使用Doc2Vec生成文檔向量計算網(wǎng)頁主題相關(guān)度,與查詢擴展后基于VSM和LDA[17]的網(wǎng)頁主題相關(guān)度計算形成對比。
根據(jù)實驗設(shè)定網(wǎng)頁主題相關(guān)度閾值φ=0.28,計算查詢關(guān)鍵詞和網(wǎng)頁的余弦相似度大于φ時,則網(wǎng)頁與查詢關(guān)鍵詞主題相關(guān),否則不相關(guān)。
用正確率式(10)、召回率式(11)和F值式(12)來評測分別基于VSM和LDA的網(wǎng)頁主題相關(guān)度計算和本文方法的實驗對比結(jié)果。
(10)
(11)
(12)
如表1和表2所示為基于VSM、LDA的網(wǎng)頁主題相關(guān)度計算在Sogou評測數(shù)據(jù)上四類語料上述指標下的實驗結(jié)果,表3為本文方法在Sogou評測數(shù)據(jù)上四類語料上述指標下的實驗結(jié)果。從表中可以看出基于雙向LSTM和分布式表示的網(wǎng)頁主題相關(guān)度計算(Bi-LSTM and DP)在準確率、召回率和F值上相較基于VSM和基于LDA的網(wǎng)頁主題相關(guān)度計算都有了明顯的提高,主要是因為考慮了特征詞和文檔在語義層次上的相關(guān),同時還沒有丟失詞序的信息。
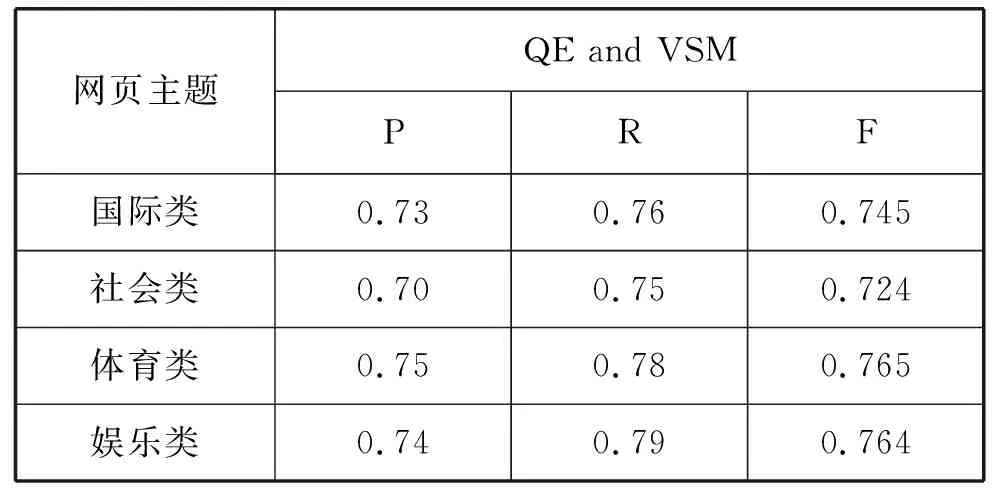
表1 基于VSM的網(wǎng)頁主題相關(guān)度計算
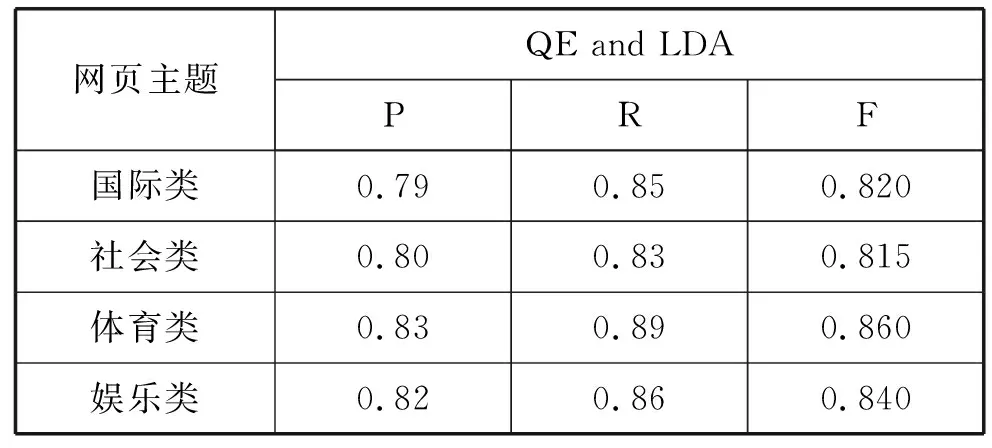
表2 基于LDA的網(wǎng)頁主題相關(guān)度計算
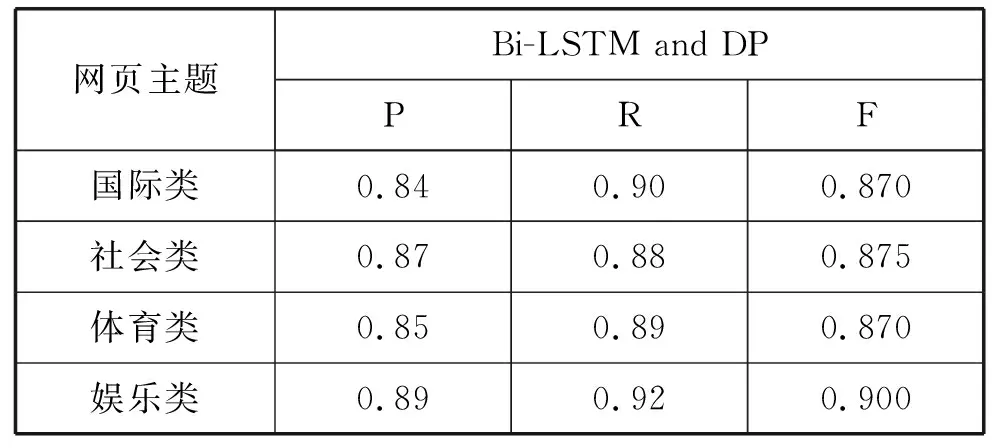
表3 基于Bi-LSTM和分布式表示的網(wǎng)頁主題相關(guān)度計算
4 結(jié) 語
用戶通過查詢關(guān)鍵詞得到相關(guān)網(wǎng)頁時,VSM僅從查詢關(guān)鍵詞的詞頻等統(tǒng)計信息與網(wǎng)頁進行余弦相似度計算,從而判斷網(wǎng)頁相關(guān)與否,沒有考慮到查詢關(guān)鍵詞的語義相關(guān)以及關(guān)鍵詞的上下文語境。本文通過雙向LSTM和詞的分布式表示來擴展查詢關(guān)鍵詞,對最終的主題關(guān)鍵詞集合與搜索網(wǎng)頁進行余弦相關(guān)度計算,得到主題相關(guān)網(wǎng)頁。本文的查詢擴展方法根據(jù)查詢詞的上下文語境可以得到其語義相關(guān)詞,同時還包含了詞的語序。進行余弦相似度計算時將文檔的分布式表示應(yīng)用到網(wǎng)頁主題相關(guān)度計算上,考慮了網(wǎng)頁中的段落信息,可以提高主題相關(guān)網(wǎng)頁計算的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
