CoCache:基于文件關聯性的協同緩存策略
2018-07-25 11:21:38孟子瀟
計算機應用與軟件 2018年7期
孟 子 瀟
(復旦大學計算機科學技術學院,上海市智能信息處理重點實驗室 上海 200433)
0 引 言
在大數據時代,對數據進行存儲及處理所需要的資源往往會遠遠超出單臺機器的存儲容量和處理能力,因而采用分布式平臺對數據進行存儲和處理成為人們不二的選擇。分布式環境中數據會被分散到多臺機器存儲,對數據的處理也會由多臺機器并發地進行,但是出于對數據存儲持久性以及經濟性的考慮,通常將數據存儲分散到不同機器的磁盤中,并在對數據進行處理的時候從磁盤中讀取數據,這樣就導致了數據讀取與處理之間的性能鴻溝。隨著內存技術的發展,購置單位內存資源所需要花費的成本大幅降低,機器所配置的內存容量也隨之大幅提升,人們也逐步通過對數據進行緩存的方式來提高對大數據集的處理效率,因而人們逐漸開展了針對大數據集在分布式環境中的緩存問題的研究。
然而,人們往往需要同時對多個數據集進行處理才能完成某一項任務,也就是說數據集與數據集之間是存在關聯性的。但是現有的緩存框架及算法都較少地考慮數據集之間關聯性,而是把每個數據集當作獨立的緩存單元進行考慮,這樣就會導致多個相互關聯的數據集只有一部分被緩存,使對多個關聯數據集進行處理的一個計算任務在處理數據的時候仍然需要從磁盤讀取沒有被緩存的數據集,從而引起數據緩存效果的下降,導致數據讀取與處理之間的性能鴻溝依然存在,使得對數據進行緩存的意義大大降低。因此,分布式環境對數據進行緩存的時候需要把數據的關聯性考慮在內,而不能只把每個數據集作為單獨的緩存對象進行考慮。
文獻[1-2]使用類似HDFS[3]的管理方式來管理緩存,在底層分布式文件系統的基礎上,實現了一個額外的緩存層。文獻[4]進一步實現了一個基于內存的分布式文件系統,在HDFS和上層應用間增加一層文件緩存機制,同時為了保證數據一致性和可用性,引入Lineage和Checkpoint機制,是一個專門為大規模數據處理而設計的系統。文獻[5]提出了一種動態放置數據文件的策略,可以在HDFS實現聯合定位。文獻[6]提出可以將所有數據放在內存中提供服務,以獲得更優的效率。在文獻[7]發現了并行計算All-or-Nothing的特性,即在進行并行計算時,部分緩存對計算效率沒有幫助,要么都進行緩存,要么都不進行緩存,為本文提供了重要思路。文獻[8-11]是針對基本緩存策略LRU、LFU、FIFO等的分析和一些改進優化。
本文提出一種基于文件關聯性的協同緩存策略,稱為CoCache。主要工作包含:1) 提出數據集關聯性的量化計算方式;2) 根據數據集關聯性的元信息,提出了協同緩存策略;3) 實現CoCache的原型,并在其上進行實驗驗證方案的有效性。
1 系統框架與算法設計
在同時處理有關聯的兩個數據集時,首先需要考慮關聯性的定義,然后基于數據集之間的關聯性,CoCache實現了一種協同緩存方案,即在緩存數據集的時候,不單是考慮該數據集本身的元信息,而是結合和它相關的其他數據集。
本節將首先介紹CoCache的總體框架設計,然后提出關聯性的定義方法和在緩存替換過程中的具體算法。
1.1 系統框架設計
CoCache是一個塊式存儲系統,整體框架如圖1所示,虛線框內是核心部分,系統由一個中心的Master節點和多個位于存儲節點上的Worker節點以及底層文件系統(UFS)組成,其他部分由用戶管理。Master節點負責進行緩存控制,根據預處理模塊提供的分塊和索引的基本信息,將元數據信息存儲到自己的工作內存中,并且在計算過程中,根據任務管理器提供的查詢需求,進行緩存調度控制;Worker節點負責將數據塊返回給用戶以及從底層文件系統讀取數據,并且由Master節點調度,進行緩存控制;底層文件系統負責存儲數據集。
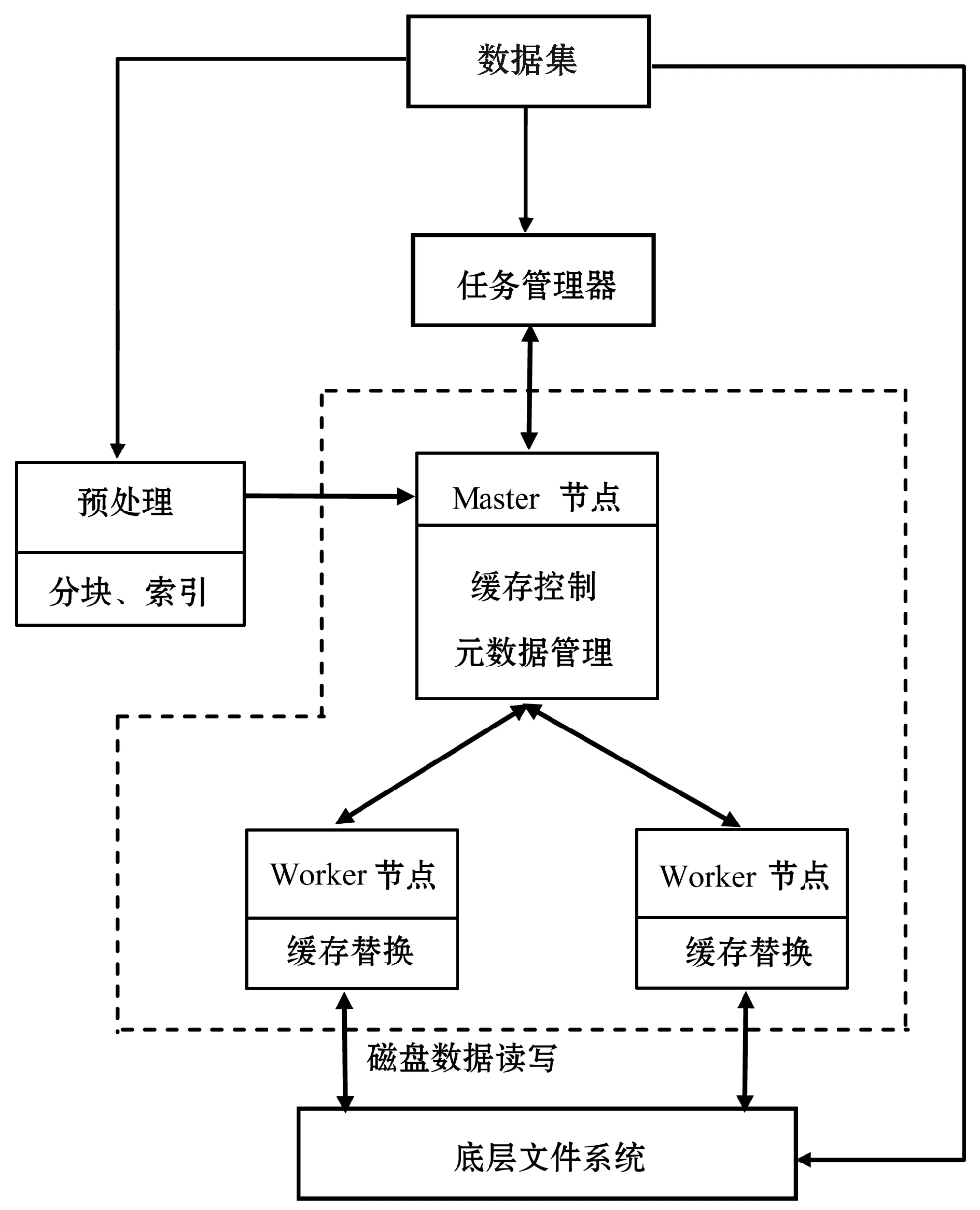
圖1 系統架構圖
整個工作流程分為以下幾個部分:1) 底層文件系統獲取到數據集,并且由預處理模塊進行分塊,建立索引,并將預處理結果通知Master節點。2) 任務管理器發起查詢,Master節點接收到查詢請求,在索引中查找對應的數據塊,并向Worker節點請求該數據塊,與此同時,告知Worker節點緩存調度信息。3) Worker節點接收到Master節點的元信息后,將嘗試從緩存中讀數據塊,如果讀到,則將數據塊返回任務管理器;如果緩存中不存在該數據塊,則從底層文件系統中讀取并返回給任務管理器,同時根據緩存調度信息,決定緩存內容和方式,該部分會在1.3節中詳細描述。4) 任務管理器接受到數據塊后,計算出結果。當再次執行查詢任務時,重復以上2至4步驟。
1.2 數據集的關聯性
CoCache的第一步,就是要定義數據集之間的關聯性。在這里,本文先考慮兩個數據集之間的關聯性。表1列出了在此過程中用到的參數及其定義。
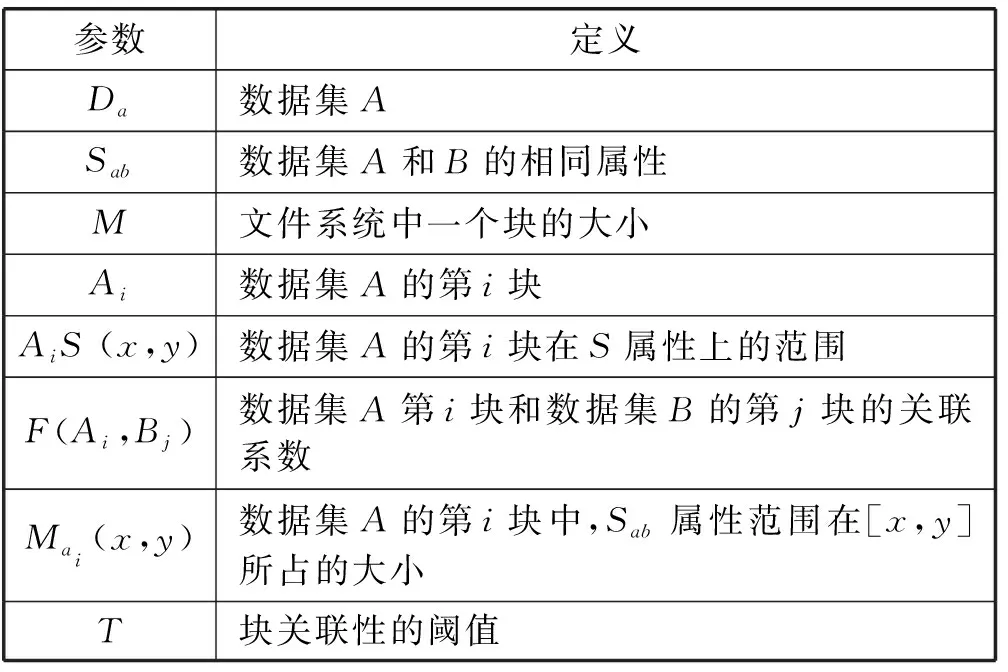
表1 參數定義
數據集Da和Db都是數據庫表,它們在某一列上有相同的屬性Sab,關聯性針對Sab定義。將Da和Db按照Sab排序后,把Da和Db按照每塊大小M分成多塊,分別是A1,A2,…,Am和B1,B2,…,Bn,對每一塊,可以得到該塊在S屬性上的范圍AiS(xai,yai)和BjS(xbj,ybj)。對此,數據集A第i塊和數據集B的第j塊的關聯系數通過如下方式計算:
1) 當[xai,yai]∩[xbj,ybj]=?時,F(Ai,Bj)=0。
2) 當[xai,yai]∩[xbj,ybj]≠?時,令[xai,yai]∩[xbj,ybj]=[x,y],可計算出Mai(x,y)和Mbj(x,y),則:
根據上述定義,由于數據集A和數據集B都要進行排序,有如下優化方式來計算出各塊之間的關聯系數。
從頭開始,對數據集A和B同時掃描,Sab字段較小的指針往下掃描,直到一個塊結束。可以計算出當前對應塊之間的關聯系數,然后標記當前位置,作為下一個迭代的起始位置,繼續掃描,直到文件結束。未計算的塊之間的關聯系數均為0。通過這種方式可以不必計算所有塊,使得尋找關聯系數的復雜度從O(n2)變為O(n)。
1.3 協同緩存策略
協同緩存策略是基于數據集關聯性的緩存策略,是在基于已有的緩存策略上,對部分有關聯性的塊進行綁定緩存,因此在協同緩存之上有一個基本的緩存策略,如LRU、FIFO等。
查詢任務的執行過程和緩存替換策略如圖2所示。任務管理器發起讀請求,Master節點根據索引,找到要讀取的塊集合I,然后查看其是否全部在緩存中,如果是,直接從緩存中讀取并返回;如果不是,則從底層文件系統中查找I以及與其相關的塊集合P,將其存在緩存中并返回。在此,本文定義一個List,用于保存即將被替換的塊的元信息。當涉及到緩存替換時,首先檢查List里的塊數量是否充足,如果不足,則通過總體緩存策略選出第一個被替換的塊,然后將該塊及與其相關的塊,也加入List中,再次檢查List的塊數量,直到滿足替換要求。
2 實驗分析
本文基于Tachyon實現CoCache的原型,使用HDFS作為底層文件系統。Master節點和Worker節點均是Amazon EC2 m4.2xlarge型號機器,其中一臺Master節點,四臺Worker節點。每個節點的配置為32 GB內存,其中工作內存占用12 GB,剩下20 GB作為緩存資源;總共分配80 GB作為緩存數據的資源。
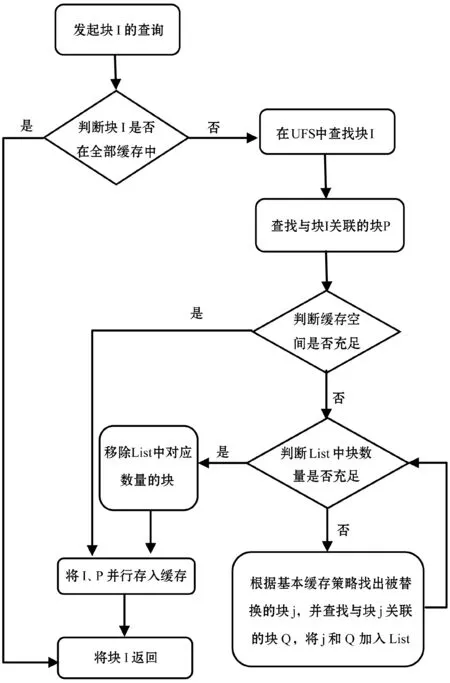
圖2 協同緩存流程圖
實驗主要通過執行多次查詢操作,來對比使用和不使用CoCache時,查詢操作的總時間,緩存命中率。
每次測試的查詢操作混合了若干個單表查詢和多表join查詢。在實驗中對比了不同參數對結果的影響,包括數據集大小,關聯性閾值T,塊大小M。
2.1 數據集預處理
由于CoCache是對有關聯性的數據集進行處理,所以使用的兩個數據集為
本實驗所采用的數據集為日志信息,以時間為key,日志內容為value,且已排序。使用索引能夠快速地定位到查詢所需要的數據塊,避免過多的磁盤掃描。通過關聯系數鄰接表,可以在進行緩存的過程中,快速準確地找出與目標塊相關聯的塊。為了更好地對比緩存對實驗結果的影響,實驗預先把數據集前部分數據存入緩存中。
2.2 總體運行時間和緩存命中率的對比
實驗分別設置了幾組不同大小的數據集(數據集A和B大小相同),將閾值T設置為0.5,塊大小設置為128 MB,然后比較了使用Tachyon和使用CoCache時的總體運行時間和緩存命中率,得到的結果如圖3和圖4。可以發現當數據集大小小于緩存資源大小時,兩者并無區別,但是一旦超過這個數值,CoCache在運行時間和緩存命中率上的表現都優于Tachyon。因為CoCache能夠減少出現有關聯的塊一部分在緩存,一部分不在緩存的現象,使得下一次查詢更大幾率全部命中。
閾值和塊大小的設置對整個查詢也是有影響的,所以接下來將通過設置不同參數,來對比CoCache和Tachyon的性能。

圖3 數據集大小對運行時間的影響

圖4 數據集大小對緩存命中率的影響
2.3 閾值T對運行時間和緩存命中率的影響
為了比較不同閾值下CoCache的性能,實驗從0.05到1設置7組不同的閾值(0.05、0.1、0.2、0.4、0.6、0.8、1),通過分析可以知道,當閾值為1時,幾乎沒有兩個塊是具有關聯性的,因此CoCache等同于Tachyon。在此使用兩個100 GB的數據集,設置塊大小為128 MB,在此環境下,對比了不同閾值的運行時間和緩存命中率,實驗結果如圖5。可以發現,隨著閾值增加,緩存命中率越來越小,這說明了CoCache能夠進行有效的緩存,使得更多的塊命中。但是,運行時間并不是如此樂觀,當閾值很小的時候,過多的塊具有關聯性,使得每次在替換塊時,同時有很多塊需要并行處理,造成了一定的IO阻塞,增加了運行時間。
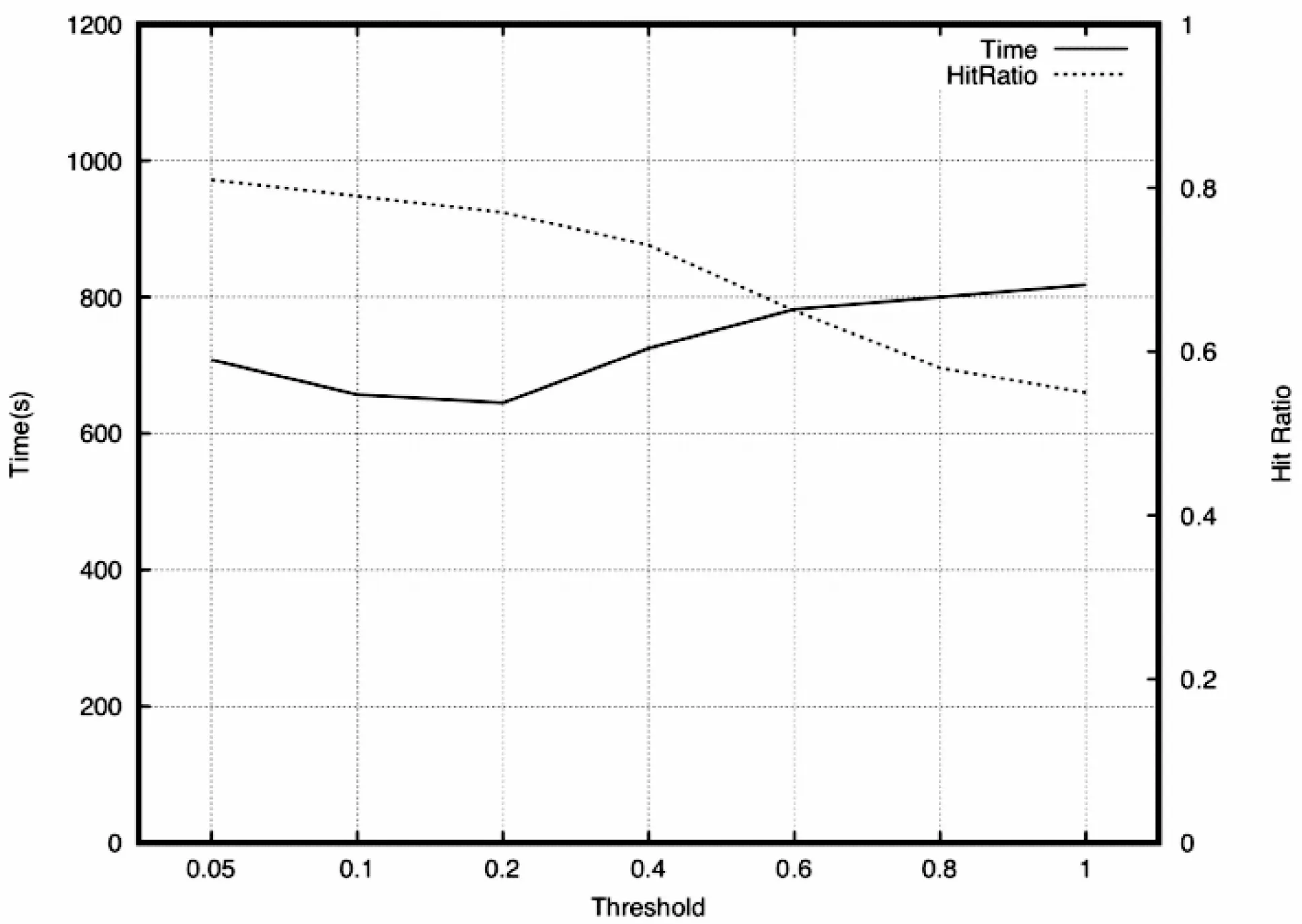
圖5 閾值T的影響
2.4 塊大小的影響
在這一部分,實驗將對比不同塊大小對CoCache和Tachyon性能的影響。由上一部分可以看出,當閾值為0.2左右時,能夠在運行時間上取得比較好的效果,所以在這一部分中,閾值設置為0.2,兩個數據集大小也為100 GB,實驗結果如圖6所示。可以發現,不管采用何種大小的塊,CoCache的運行時間都優于Tachyon。同時還發現,當每塊越小時,運行時間越快,因為每次查詢時,索引能夠更準確地找到相應的塊,以及與此同時被緩存的“無用信息”會變少。但是這一部分還是受到上層查詢的范圍的影響,如果每次查詢覆蓋的范圍是抖動的,會導致查詢讀取的塊個數也是抖動的,塊大小的影響就會逐漸消失。
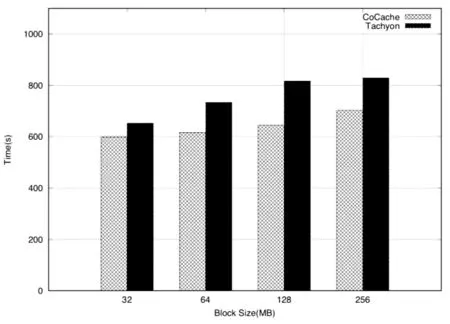
圖6 塊大小的影響
3 結 語
隨著大數據查詢應用的增加,利用分布式緩存來對運算進行加速已成為共識,而多數據集的查詢任務越來越多,為了更好地利用緩存資源,本文提出的基于文件關聯性的協同緩存策略,已經開始解決這一部分問題,并且取得了一定的成果。對比實驗表明,CoCache可以提高數據緩存效率,減少查詢時間。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
