基于Spark的時間序列并行分解模型*
2018-07-13 08:54:26黃齊川李天瑞
計算機與生活 2018年7期
李 勇,滕 飛,2+,黃齊川,李天瑞
1.西南交通大學 信息科學與技術學院,成都 611756
2.軌道交通工程信息化國家重點實驗室(中鐵第一勘察設計院),西安 710043
1 引言
時間序列是指在生產和科學研究等過程中,按照時間順序記錄得到的一系列觀測值,反映了現象的發展變化規律。隨著信息技術的快速發展,各個行業應用系統產生的時間序列呈爆炸式增長,已遠遠超出了現有傳統的信息系統的處理能力[1-2]。尋求有效的大數據處理技術成為現實世界的迫切需求。
現實中的時間序列一般是比較復雜的、廣義平穩或者非平穩的,由多種因素共同作用的結果,不容易直接對其進行觀察分析,而需要首先對其分解。本文根據時間序列分解算法每個處理過程輸入數據的獨立性,將時間序列分解算法分為兩種操作類型:(1)局部相關。這種操作類型的時間序列算法具有良好的并行性,因為切分得到的時間子序列具有一定的獨立性,處理節點之間進行少量的通信、數據交換就可以達到較好的處理效果,例如STL(seasonaltrend decomposition using LOESS)[3]、EMD(empirical mode decomposition)[4]、X-12-ARIMA(autoregressive integrated moving average model)[5]等。STL算法可將時間序列分解為低頻率的趨勢項、高頻率的季節項及不規則變化的殘差項[3]。因為STL使用LOESS[6](locally weighted regression and smoothing)作為平滑器,所以具有良好的數據并行特性。(2)全局相關。時間序列的每個時間點的處理過程都有很強的相關性,這種類型的時間序列分析算法難以取得較好的并行效果,例如 SSA(singular spectrum analysis)[7]、WD(wavelet decomposition)[8]等。SSA是一種時間序列分解算法,具有插值、去噪、識別趨勢和周期信號以及建立預報模型的功能[9-10]。SSA算法分解過程為:首先將時間序列轉換成軌跡矩陣,然后對軌跡矩陣進行奇異值分解,分解之后再對每個分量進行分組和重構,從而得到分解結果[7]。SSA分解過程中各時間點之間具有很強的相關性,序列分段計算會造成信息損失,數據并行性較差。
現如今成熟的數據挖掘平臺主要有SAS、SPSS、Matlab、R等,它們當中包含豐富的時間序列分析軟件包,不過這些都不是分布式的,無法高效處理大規模時間序列數據。Spark是目前最活躍的開源分布式計算框架之一,其基于內存計算的特點,提高了大數據環境下處理數據的實時性,同時也保證了高容錯性和高可伸縮性,并且允許用戶將Spark部署在大量廉價的硬件上,形成集群[11]。研究人員相繼提出了基于Spark平臺的并行算法。文獻[12]設計了基于Spark平臺的DNA基因序列拼接算法,在保證拼接準確性的前提下提升了拼接效率。文獻[13]借助Spark平臺對道路交通管理分析平臺的海量系統日志進行查詢、分析,相比傳統的分析方法更加高效。文獻[14]提出了基于Spark的序列模式挖掘算法,打破了傳統串行算法不能處理大規模數據集的局限,并在真實數據集上驗證了算法效率。文獻[15]提出了基于Spark平臺的隨機并行森林算法,算法從數據和任務兩個角度設計并行方案,在分類準確性、擴展性等方面都優于現有的隨機森林并行算法。對于分布式算法的研究雖然包括了豐富的機器學習算法,但是對于時間序列分解算法鮮有涉及。
鑒于傳統的單機數據挖掘平臺無法處理大規模的時間序列,對于并行的時間序列分解算法國內外研究成果較少,目前流行的分布式機器學習平臺未涉及時間序列分解算法的原因,本文提出一種基于Spark平臺的時間序列分解模型。模型的核心思想為:首先將完整的時間序列切分成一系列的子序列,通過對子序列去冗余的方式保護內部數據免受端點數據污染,然后將帶有冗余的時間子序列分發給Spark集群的計算節點,每個節點獨立進行序列分解,最后去除結果的冗余部分,再將其合并。本文針對兩種(局部和全局相關)分解特點的算法,給出模型的兩個實例,在基于內存計算的計算框架Spark上實現STL(局部相關)和SSA(全局相關)。
本文組織結構如下:第2章結合具體的時間序列分解算法STL、SSA詳細介紹模型的框架結構;第3章針對模型實例進行實驗測試,驗證模型的有效性和高效性;第4章對全文進行總結。
2 模型設計
本文模型的主要目標是在保證正確性的前提下高效地分解大規模時間序列。因此目標主要定位在以下兩方面:(1)著眼于集成兩種類型計算特點的時間序列分解算法。對于第二種類型的時間序列分析算法并行難度較大,不同的算法需要特定的并行方式才能達到較好的效果,本文旨在通過數據并行的方式得到一個近似結果,并通過冗余數據的方式提高準確性。(2)模型能夠架構在Spark的集群上。
模型構架主要包括3個模塊,如圖1所示。

Fig.1 Model framework圖1 模型架構
(1)時間序列切分冗余。考慮到將時間序列切分后的時間子序列之間的關聯操作是局部相關的,也就是說對某個時間點的計算只需要用到附近一定數量的數據點,因此考慮通過對時間子序列冗余部分數據以提高分布式處理時間序列的準確性。
(2)時間序列分解。該模塊的功能是將時間序列分解算法應用到每個Spark計算節點,得到每個帶冗余的時間子序列的分析結果。
(3)時間序列結果合并。將每個計算節點的分析結果去除冗余部分直接合并。
本文將以STL算法為例介紹模型實現過程。
2.1 模型實例
2.1.1 冗余數量選取
時間子序列之間是局部相關的,因此冗余的數據越多,序列切分處理后的結果就越接近完整序列處理的結果。為了方便理解,本文以一個周期(T)的數據為單位對時間子序列進行冗余。
STL的計算過程由內循環和外循環兩部分組成。內循環要進行3次窗口長度為 ns、nl、nt的LOESS[3]平滑和3次窗口長度為 np、np、3的移動平均,其中np為時間序列的周期。外循環是一個不斷迭代內循環的過程。
假設某個時間序列T的子序列Tn中的一個時間點為tm,想要保證在一次內部循環的過程中,獨立處理子序列Tn和完整處理時間序列T時tm時間點的計算結果相近,就必須算出3次LOESS平滑過程和3次移動平均過程計算tm時所需要前后時間點的數據量,即冗余數據量。
分析STL算法的執行過程,冗余數據量為以下兩部分冗余量的加和(np為周期長度):
(1)3次LOESS平滑。對于某個時間點tm的LOESS平滑使用到前后時間點的數量為窗口長度的一半。周期子序列平滑中的LOESS平滑是在周期層面的平滑,需要窗口長度一半數量的周期數據,低通濾波、趨勢平滑過程中的LOESS平滑是在時間點層面上的平滑,只需要窗口長度一半數量的時間點數據。例如,對于一個以年為周期的月度時間序列,假設分別對某個時間點進行窗口長度為5的周期層面和時間點層面上的平滑需要時間點前后的數據量為24個月(2個周期)和2個月(2/12個周期)。因此,周期子序列平滑中LOESS平滑過程需要冗余的數據量為ns/2,低通濾波平滑過程需要冗余的數據量為nl/2×np,趨勢平滑過程中LOESS平滑需要冗余的數據量為nt/2×np。
(2)3次移動平均。移動平均為在時間點層面上的操作,3次窗口長度為np、np、3的移動平均過程中需要的數據冗余量分別為 (np-1)/np、(np-1)/np、2/np。
STL算法是一個迭代的過程,由多次內循環和多次外循環組成,因此序列切分處理即使冗余數據也不可能和完整時間序列處理的結果完全一致,冗余數據的作用是在一定程度上保護內部的數據不受端點數據的污染,從而使得序列分塊處理的結果盡可能地接近完整序列處理的結果。
綜合以上分析,本文使用如下公式(兩部分冗余數量的加和)來計算冗余量:

例如當 ns=7,nl=np,nt=1.5np時 R=7,即冗余數據量為7個周期。
對于STL算法切分后的時間子序列之間是局部相關的,因此可以分析算法執行過程得到合適的冗余數量。而SSA算法是全局相關的,因此本文通過實驗確定冗余數量來達到較優的分解效果。
2.1.2 時間序列切分
主要包括對時間序列切分時的幾種特殊情況的處理:(1)對于STL算法為了達到較好的分解效果,周期子序列平滑窗口必須大于等于7,因此當時間子序列的長度小于7個周期時,默認其為7個周期。(2)時間子序列長度大于完整序列長度時,將時間序列劃分成一個子序列,即處理完整時間序列。(3)時間序列不一定能等分,最后一個子序列應包含剩下所有時間點。
2.2 模型實現
圖2展示了Spark實現并行分解算法的狀態轉移圖。結合并行狀態轉移圖可以將并行過程描述如下:首先從HDFS(Hadoop distributed file system)上讀取數據,并將數據重新分區(分區數為參數slice)生成RDD1。然后調用Spark中的mapPartitions算子獲取每個分區的迭代器,調用切分冗余函數rdSplit()將每個分區中的時間序列切分和冗余生成一系列時間子序列,結果返回格式為ArrayBuffer(ArrayBuffer(object))的RDD:RDD2。隨后再利用RDD2.map算子將stl()、ssa()分解算法應用到每個時間子序列,每個時間子序列分解后直接刪除冗余,結果返回格式為ArrayBuffer(ArrayBuffer(T,S,R))的三元組集合(一個時間子序列分解結果)組成的集合(一個分區中所有時間子序列分解結果),再調用flatMap算子將RDD中每個分區每個集合中的元素合并成一個集合,即RDD3的格式為ArrayBuffer((T,S,R))。最后利用Spark提供的saveAsTextFile算子將RDD3持久化存儲到HDFS的指定目錄。

Fig.2 Parallel state transition diagram圖2 并行狀態轉移圖
3 實驗設計與結果分析
本文設計了兩部分實驗來驗證模型實例的結果:設計了并行一致性驗證實驗來證明時間序列切分、冗余的并行方式的有效性;設計了性能驗證實驗來證明基于Spark平臺實現的性能優勢。
3.1 一致性驗證
3.1.1 數據集描述
本文采用兩種類型的數據集:(1)蘇黎世1749—1983年太陽黑子月度數據,共2 820個觀測;(2)添加了噪聲的正弦模擬信號,y=50×sin(43×π×t)+20×sin(52×π×t),采樣頻率為1 000。
3.1.2 實驗環境
實驗中使用的計算機配置如表1所示。

Table 1 Computer environment表1 計算機配置信息
3.1.3 實驗方案
本文使用相似度函數來衡量序列分布式處理和完整序列處理結果的相似程度。相似度函數[16]定義如下:設xn和yn是兩個能量有限的確定性信號,并假定它們是因果的,則定義xn和yn的相關系數為:

由公式可知,當xn=yn時,ρxy=1,表明兩個信號完全相關(相等);當它們完全無關時,ρxy=0。
本實驗在單機上進行,使用R語言中提供的STL、SSA算法包。實驗方案是對兩個類型不同的時間序列,分別采用不同的處理方式:(1)單機處理方法,完整時間序列直接分解;(2)分布式處理方法,時間序列切分、冗余后分解、合并,然后對實驗結果進行對比。其中合并時間子序列分解結果時,冗余處理方式有兩種:冗余部分取平均和冗余直接去除。實驗選取了不同長度的時間子序列,不同的長度反映了時間序列切分帶來的端點對內部數據的污染程度。
3.1.3.1 局部相關分解算法一致性驗證(STL)
主要包括3組對比實驗:(1)對于分布式處理方式,冗余取平均和冗余直接去除的效果對比;(2)對于分布式處理方式,采取不同時間子序列長度的效果對比;(3)對于前兩組對比實驗使用不同類型時間序列處理結果對比。兩種處理方式結果對比評價指標為式(2)。
分布式處理方式將時間序列分成多個時間子序列,由式(1)計算冗余估計量(ns=7,nl=np,nt=1.5np,參數選擇參考文獻[3]),R=7。實驗中選取了6個長度不同的冗余量:0T(不冗余),1T,3T(R/2),7T(R),10T(3R/2),14T(2R),T表示一個周期采樣點數量。
表2給出了完整時間序列數據分解結果和分布式時間序列分解結果的相似度,分解結果主要包括季節項(S),趨勢項(T),季節項和趨勢項的和(S+T)。太陽黑子1、2數據集中時間子序列的長度分別是3T、78T。分解結果的冗余處理方式為直接去除。太陽黑子3數據集中時間子序列長度為78T,冗余處理方式為冗余部分取平均。正弦模擬信號序列長度為3T,冗余處理方式為直接去除。(3T,78,冗余去除)表示每個子序列長度為3周期,共78個序列,冗余直接去除。
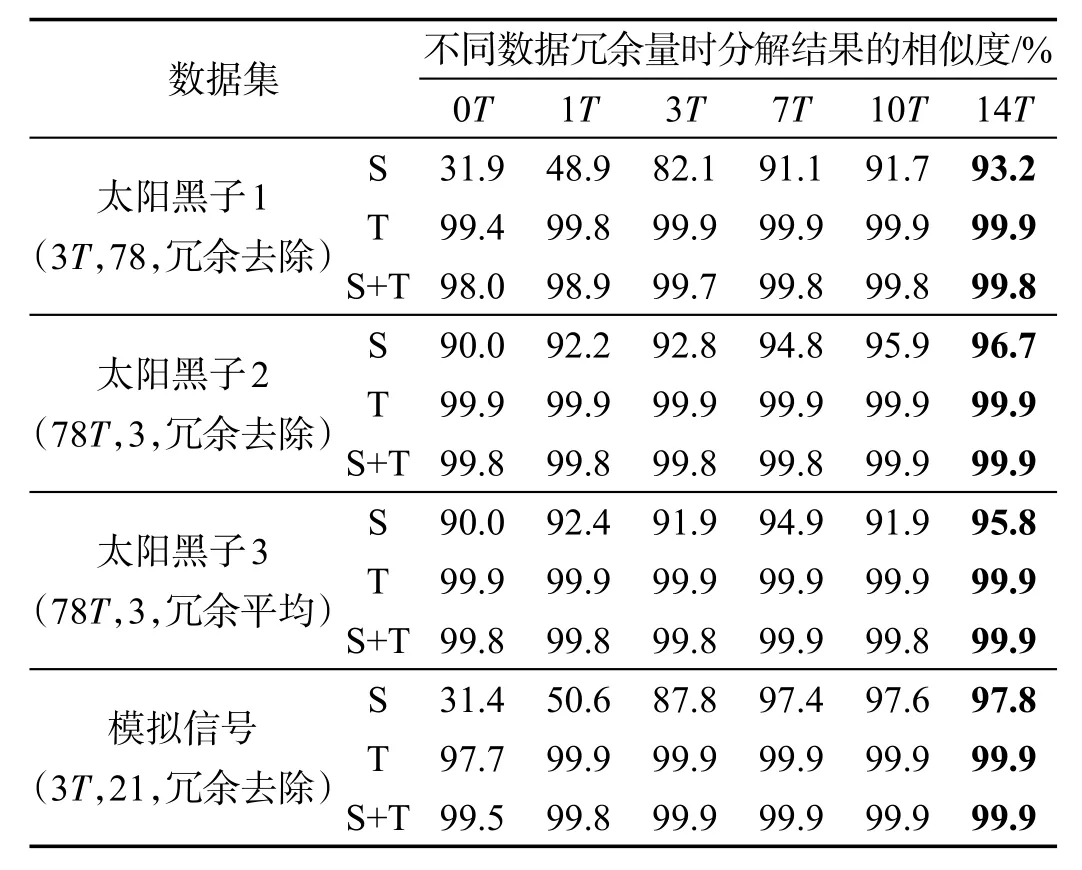
Table 2 Consistency test result for local correlation based decomposition algorithm表2 局部相關分解算法一致性驗證結果(STL)
對于兩種不同類型的時間序列數據,分析表2中的數據可以得到如下結論:
(1)時間子序列冗余數量越多,與完整序列處理的結果相似程度越高,太陽黑子1和模擬信號中時間子序列的長度為3個周期,這是一種極端情況即端點數據最大程度地污染內部數據,當冗余量達到7個周期的數據時,季節項和趨勢項的相似度都達到了91%,說明了本文時間序列分布式處理方法和傳統的單機處理結果對比具有較高的一致性。
(2)對比太陽黑子和模擬信號分解結果,可以說明對于不同類型的時間序列,通過冗余的方式,分布式處理都能達到較好的處理效果。
(3)對比太陽黑子2和3數據集得出結論,時間子序列分解結果合并時,冗余部分直接去除具有更好的效果,這是因為冗余部分取平均值會把邊緣的誤差傳遞到內部。
(4)分布式處理時間序列的方式,冗余的數據造成了額外的計算開銷,但是極大地提升了計算結果的精確度。假設時間子序列長度為s,冗余數據長度為r,則分布式處理方式增加的計算量為a=r/s(%)。對于同一個時間子序列來說,子序列長度越大造成的額外開銷就越小。例如,表2中當時間序列的長度為78T時端點數據對內部污染很小,即使不冗余數據也可以達到90%的相似度,冗余數據為7T時增加了17.9%計算量,相似度提高了4.8%。表4中當時間子序列的長度為3T時,冗余7T的數據時增加了466%計算量,相似度提高了59.2%。
3.1.3.2 全局相關分解算法一致性驗證(SSA)
首先將太陽黑子數據和模擬信號時間序列分為不同段長,然后采取不同冗余長度進行分解,最后對實驗結果進行對比,結果對比評價指標為式(2)。算法參數:SSA算法的窗口長度為序列一半,SSA算法分組參數參考文獻[13]。實驗使用SSA將兩個序列都分解成兩個分量F1和F2,太陽黑子數據分解后得到趨勢項和周期項,模擬信號中不包含趨勢,因此分解后得到兩個正弦分量。
表3給出了分解結果的相似度,可以發現:(1)隨著冗余數量增多,結果的相似度不斷提升,對于太陽黑子數據段長為3周期這種極端情況,F2分量的分解效果很不理想,這是因為SSA分解過程中各時間點的操作是全局相關的,時間序列切分得太短,導致損失信息太多,信號周期信息不全,所以分解結果很不理想。因為F1分量能量較強,即使段長很短,也能取得較好的效果。模擬信號比較平穩,在這種極端情況下表現良好。(2)對于太陽黑子2和模擬信號數據,當冗余數量為2個周期采樣點時相似度達到了91%以上,說明本文方法與單機處理方式具有較高的一致性,當冗余數據超過2個周期采樣點,效果提升不明顯。

Table 3 Consistency test result for global correlation based decomposition algorithm表3 全局相關分解算法一致性驗證結果(SSA)
3.2 性能提升驗證
3.2.1 數據集描述
本實驗采用的數據是高鐵軌檢車采集的軌道狀態真實數據。軌檢車是一列裝有專用檢測設備,對軌道、供電、信號、周邊環境等影響列車安全運行和舒適性的技術指標和相關信息進行實時檢測。軌檢車每0.25 m采集一個數據點,本實驗只驗證算法效率,因此設置高鐵軌檢數據周期T為500 m的采樣點數,每個塊的大小為10個周期數據。STL實驗使用6個數據集32 MB(約500萬采樣點)、64 MB、128 MB、256 MB、512 MB、1 024 MB。由于SSA計算時間較長,使用5個較小的數據集8 MB、16 MB、32 MB、64 MB、128 MB。
3.2.2 實驗方案
為了方便分析實驗結果,將本文模型的實例基于Spark的STL、SSA算法標記為STL-Spark、SSASpark。為證明STL-Spark的效率提升和串行單機算法的局限性,本實驗同R語言軟件包中的STL、SSA算法進行比較,該算法標記為STL-R、SSA-R,Scala語言實現的串行STL算法記為STL-S。為了公平起見,Spark實現的參數都參照R的設置。
Spark RDD是被分區的,在生成RDD時,一般可以指定分區的數量,如果不指定分區數量,當RDD從集合創建時,則默認為該程序所分配到的資源的CPU核數,如果是從HDFS文件創建,默認為文件的Block數。分區的個數決定了并行計算的粒度,本實驗是從HDFS上讀取文件,HDFS上默認的Block大小為64 MB,粒度太粗,為了能夠充分利用計算資源,需要對RDD進行重新分區。Spark官方建議每一個CPU核(core)分配2~3個任務,本實驗最多使用8個節點共32個核,因此Spark讀HDFS上的時間序列數據時分區數目設置成96。STL、SSA實驗中冗余數量為1個周期數據,冗余處理方式采用的是直接去除。
表4展示的是單機處理方式(STL-R和STL-S)和基于Spark的分布式處理方式的運行時間,表中“NA”表示內存溢出程序崩潰。分析表中數據可以得到如下結論:(1)STL-S運行效率低且數據處理能力較差,最多只能處理128 MB的數據,產生這種情況的原因是當數據量增大時,JVM(Java virtual machine)垃圾回收時間較長。(2)STL-R數據處理能力較強但是受內存限制,數據量較大(1 024 MB)時程序崩潰,此時STL-Spark表現出較大優勢。
表5展示的是SSA算法單機處理方式SSA-R和基于Spark的分布式處理方式的運行時間。分析表中數據可以得出結論:R語言數據處理能力較強但是受內存限制,數據量較大(32 MB)時程序崩潰,此時Spark表現出較大優勢。對于實驗中最大的數據集128 MB,8個節點相對于1個節點效率提升了7倍,極大地提升了效率。
4 結束語
為了應對大數據時代下因時間序列規模急劇增長導致的傳統單機算法無法快速進行時間序列分解的問題,本文提出了一種基于Spark平臺的時間序列分解模型。模型對特定計算特點(局部相關和全局相關)的時間序列分析算法進行并行,使其能架構在Spark計算集群上。針對模型實例(STL、SSA)進行實驗,結果證明了局部和全局相關分解算法通過冗余數據的方式都能夠保證分布式分解的正確性,同時基于Spark平臺的實現,極大地提高了時間序列分解效率。對于段長和冗余數量參數的選取,局部相關分解算法通過分析算法的執行過程可以計算出合適的冗余數量,即使段長很短的極端情況也可以達到一個較優的效果(相似度90%以上)。全局相關分解算法分解過程中各時間點之間具有很強的相關性,序列分段計算會造成信息損失,通過冗余數據的方式難以達到局部相關分解算法的效果,但是通過實驗選擇合適的段長和冗余數量也可以得到一個較優的結果。未來的工作:(1)對于SSA這種全局相關計算特點的算法,需要做更多的探索來確定分段的長度以及冗余數據的數量;(2)可以考慮將更多的時間序列分解算法融入到模型中,以形成一個分布式的時間序列分解工具。

Table 4 Running time for different processing methods(series and distributed)with different data sizes(STL)表4 STL串行和分布式處理方式、不同大小數據集的運行時間

Table 5 Running time for different processing methods(series and distributed)with different data sizes(SSA)表5 SSA串行和分布式處理方式、不同大小數據集的運行時間
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
