自適應融合局部和全局稀疏表示的圖像顯著性檢測
2018-05-21 01:01:05石愛業
計算機應用 2018年3期
王 鑫,周 韻,寧 晨,石愛業
(1.河海大學 計算機與信息學院,南京 211100; 2.南京師范大學 物理科學與技術學院,南京 210000)
0 引言
隨著信息技術的不斷發展,人們擁有的數據資源越來越多。其中,圖像資源因其直觀性,出現了前所未有的增長速度,然而隨之而來的信息冗余問題也成為了圖像處理的新增難題。神經學和心理學研究專家指出,視覺顯著性是人類視覺中非常重要的一個機制,它通過過濾人眼所及之處的冗余信息,突出人們最感興趣(即顯著性)的目標,從而減小信息的冗余度。通過模仿該機制,計算機視覺專家提出了圖像顯著性檢測技術,目前該技術在圖像自動裁剪[1]、視頻壓縮[2]、圖像檢索[3]、圖像分割[4]、目標識別[5]和圖像分類[6]等領域得到了廣泛的應用。
通過對生物視覺的研究發現,人眼和大腦在處理場景信息時,有兩種模式。第一種是,當我們不帶任何目的去觀察周圍的環境,純粹只是瀏覽時,環境中與其他背景差異過大的部分會牢牢抓住我們的眼球,吸引我們的注意力,而背景則會被選擇性忽略。另一種模式是,如果我們帶有目的性的去審視周圍的環境時,那么我們更加傾向于找到與目標相關的信息,而忽略其他不相關信息。這兩種視覺模型都是大腦處理信息的有效模式,前者沒有任務驅動,大腦自動選取感興趣的區域,減少冗余信息;而后者則是帶有目的的尋找有用信息,去除不相干信息。根據大腦處理信息的這兩種模型,在計算機視覺領域,圖像顯著性檢測即可分為無任務驅動的自下而上(Down-up)模型和有任務驅動的自上而下(Top-bottom)模型。其中,前者常基于圖像的低級特征,沒有任務先驗信息,無需學習,所以處理相對較快;后者通常基于某個任務,處理過程中帶有先驗的信息、記憶和經驗等高級的圖像特征,需要對圖像庫學習,所以計算量一般較大。為了能快速有效地檢測圖像顯著性區域,本文對自下而上的方法進行重點討論。
近年來,自下而上的方法得到了顯著的發展,很多經典算法相繼被提出,如早先的IT(ITTI)算法[7]、GBVS(Graph-Based Visual Saliency)算法[8]、SR(Spectral Residual)算法[9]等,以及較新的SUN(Saliency Using Natural statistics)算法[10]、CA(Context-Aware)算法[11]等。2015 年, Cheng 等[12]提出了基于全局對比度的顯著性檢測算法,取得了良好的效果。2016年,Liu 等[13]提出了一種基于卷積神經網絡的端到端深層次顯著性網絡,用于檢測顯著性目標。2017年,葉子童等[14]提出了基于引導Boosting算法的顯著性檢測方法,它提出采用自下而上的模型生成的樣本來引導特征學習,強化顯著性檢測效果。這些算法又可以細分為基于局部思想的檢測算法和基于全局思想的檢測算法。其中,基于局部思想的檢測算法通常關注圖像的邊緣,而無法很好地檢測顯著目標內部信息;而基于全局思想的檢測算法能較為有效地檢測出顯著性目標的內部區域,但卻對背景抑制不是很理想[15-19]。
為了解決該問題,本文考慮融合局部和全局兩類檢測思想的優勢,以得到更為良好的檢測結果。由于顯著性區域相對于其他大面積的非顯著性區域往往具有非常獨特的特性,因此,它的特征在整個場景中重復的頻率通常較低,這使得顯著性區域也具有稀疏的特征,故稀疏表示理論可以有效用于視覺顯著性檢測中。具體而言,針對一幅輸入圖像,通過對其進行隨機采樣,可以得到若干個圖像塊,由于顯著性區域在整個場景中出現的頻率通常較低,隨機采樣得到的這些圖像塊將大多數為背景塊,而非顯著性塊;然后,利用這些圖像塊,構建稀疏表示過完備字典,由此學習得到的字典將包含較多的背景特征;最后,基于該字典,對原始圖像進行稀疏表示,則稀疏重構誤差較大的圖像塊為顯著性塊的可能性就較大。基于上述思想,本文提出了一種有效的融合局部和全局稀疏表示的圖像顯著性檢測方法。首先,對原始圖像進行分塊處理,利用圖像塊代替像素級操作,降低算法復雜度;其次,對分塊后的圖像進行局部稀疏表示,即:針對每一個圖像塊,選取其周圍的若干圖像塊生成過完備字典,基于該字典對圖像塊進行稀疏重構,得到原始圖像的初始局部顯著圖;接著,對分塊后的圖像進行全局稀疏表示,與局部稀疏表示過程類似,不同的是針對每一個圖像塊所生成的字典來源于圖像四周邊界處的圖像塊,這樣可以得到初始全局顯著圖;最后,將初始局部和全局顯著圖進行自適應融合,生成最終顯著圖。該方法由于融合了局部和全局的思想,能夠識別并保存顯著性區域的邊緣信息,同時準確提取出顯著性區域的內部信息。實驗結果表明,本文提出的算法大大優化了檢測效果。
1 稀疏表示
本文提出的算法將采用模擬人類神經細胞的標準稀疏編碼模型[20],此模型可以突出圖像中的顯著部分(該部分具有獨特性、稀少性和不可預測性)。Huang等[21]通過實驗發現,某個特征描述子用幾個基進行編碼,如果其中的某個基比其他的基和特征描述子有更相近的特征,通常這個基比其他的基具有更強的響應。通過這個發現,指出稀疏編碼等價于一種顯著性編碼機制。基于該編碼機制計算得到的輸入信號重構誤差越大,則該信號被認為越顯著。
設Y=[y1,y2,…,yN]∈Rn×N為輸入信號,D為Y的稀疏表示重構字典,則稀疏表示的目標函數[22]如下:
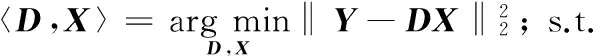
(1)

在稀疏編碼過程中,每一步的迭代字典D是固定的,可通過式(2)計算輸入信號yi的稀疏編碼系數xi:

s.t. ‖x‖0≤T
(2)
上式可通過貪婪追蹤算法中的OMP(Orthogonal Matching Pursuit)算法[23]求解,選取最匹配的原子分解信號和分解信號殘差,在每一步中都把所選擇的原子進行Gram-Schmidt正交化處理,使得字典空間展開結果最優。
基于稀疏表示理論,計算yi所對應的稀疏重構誤差:
(3)
2 自適應融合局部和全局稀疏表示方法
為了克服傳統的局部或全局顯著性檢測算法的缺陷,本文提出了一種基于自適應融合局部和全局稀疏表示的圖像顯著性檢測方法,其總體思路是分別進行基于局部或全局稀疏表示的顯著性檢測,然后將結果進行融合生成圖像顯著圖,提出算法的整體框架如圖1所示。

圖1 提出算法的框圖 Fig. 1 Block diagram of the proposed algorithm
2.1 基于局部稀疏表示的顯著性檢測
給定一幅原始圖像,為了得到其局部顯著性圖,首先對其進行分塊,針對每一個圖像塊,選取其周圍的若干圖像塊生成過完備字典,基于該字典對圖像塊進行稀疏重構,最終得到原始圖像的初始局部顯著圖。具體過程如下所示:
1)輸入原始圖像I,設其尺寸為M×N。
2)將原始圖像I分割成為若干個圖像塊bi。與大部分的局部或全局處理算法不一樣,本文沒有以像素作為最小處理單元,因為像素點數量龐大,處理起來費時費力耗資源,而采用圖像塊作為最小處理單元,雖然比像素級誤差略微大一點,但是節省了很多時間,也能取得不錯的效果。設分割成的圖像塊大小為m×n,則M×N大小的原始圖像可以被不重疊地分成(M×N)/(m×n)個圖像塊。這里需要說明的是,圖像塊的大小對后續算法的效果和復雜度有一定的影響:圖像塊越大,檢測效果下降,時間效率提高;反之,圖像塊越小,檢測效果越好,但時間效率較低。在程序實現過程中,以 320×400大小原始圖像為例,選取的圖像塊大小為4×4,這將原始圖像恰好分成8 000個圖像塊,通過實驗表明這些參數量可以在計算效率和誤差大小之間維持一個平衡。最后,將分割后的每個圖像塊按從左到右、從上到下的順序進行標記,同時將每個圖像塊進行列向量化。
3)圖像重組,得到矩陣B。這一步是為稀疏求解作準備,由于稀疏表示的實現是基于矩陣運算,所以對分割成圖像塊的圖像進行重新整合。重組后的圖像標記為B=[b1,b2,…,bK],其中,bi代表第i個列向量化后的圖像塊,K為圖像塊的總數。B可以直觀地表示為圖2所示。

圖2 矩陣B的直觀表示 Fig. 2 Visual representation of matrix B
4)構造局部稀疏字典D。對于字典的生成,本文根據顯著性檢測的實際情況,直接從圖像內選取合適的圖像塊來構造字典,這樣能更加方便、有效地重構原始信號。在局部稀疏表示中,對某一選定的圖像塊bi稀疏重構,選取的是該圖像塊周圍的圖像塊作為字典。由于在第3)步中圖像已經表示成圖像塊的行向量,因此我們選擇的是重構圖像塊前s列和后s列一共2s個圖像塊構造字典,形成的字典可以表示為D=[d1,d2,…,d2S]。
5)求解稀疏系數α。本文中稀疏系數求解算法綜合對比考慮了算法精度問題和實現復雜度問題,采用了上文提到的OMP算法求取最佳的表示系數α:
arg min‖α‖0; s.t.B=Dα
(4)
其中,α是所有圖像塊的系數集合。
6)生成初始局部顯著圖SL。在步驟5)的基礎上,利用求得的稀疏系數α重構每個圖像塊bi,并計算其重構誤差ei:
(5)
將該結果賦給所在的圖像塊,然后進行高斯濾波即可得到初始局部顯著圖SL。圖3給出了基于局部稀疏表示的顯著性檢測示例,其中:圖3(a)為三幅原始圖像,圖3(b)為計算得到的初始局部顯著圖,圖3(c)為對應的真值圖。由圖3可以看出,基于局部稀疏表示的顯著性檢測算法,能大致檢測出圖像的顯著區域,但是其更加關注顯著性物體的邊緣信息,對物體的內部信息有所抑制。

圖3 基于局部稀疏表示的顯著性檢測 Fig. 3 Saliency detection via local sparse representation
2.2 基于全局稀疏表示的顯著性檢測
下面對原始圖像進行全局稀疏表示顯著性檢測。與2.1節描述的基于局部稀疏表示的顯著性檢測過程類似,只是步驟4)中字典生成方式有所不同。
在傳統的稀疏表示中,全局字典的生成一般是從圖像中隨機選取圖像塊,進行字典學習。此時,對于大部分的應用領域而言,稀疏表示的重構誤差越小,說明算法越好,但是在顯著性檢測中,并非如此。我們希望屬于背景的圖像塊能得到很好的重構效果,理想誤差值為0;而屬于前景目標的圖像塊,根據字典重構,并不能得到很好的重構效果,歸一化的理想誤差值為1。這樣才能準確地檢測出顯著區域。
基于以上思想,本文沒有選用現有常見的全局字典構造法,而是直接從屬于背景的圖像塊中選擇字典。對于大部分圖像而言,圖像四周靠邊緣的圖像塊一般都屬于非顯著性區域,所以本節選擇上下左右四個邊界的圖像塊構造字典。由此即可得到基于全局稀疏表示的顯著性檢測結果。圖4給出了圖3(a)的全局稀疏表示顯著圖SG。從圖4可以看出,基于全局稀疏表示的顯著性檢測算法,檢測顯著部分的內部信息體現得要比局部全面,但非顯著性部分沒有得到很好的抑制,噪聲較多。
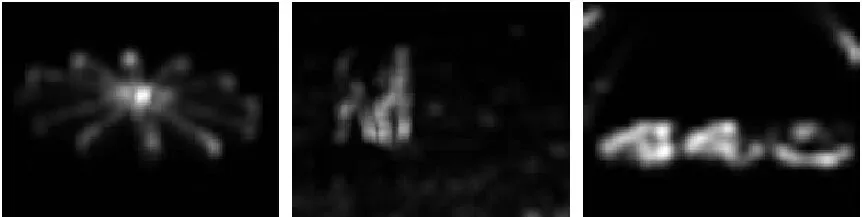
圖4 基于全局稀疏表示的顯著性檢測(初始全局顯著圖) Fig. 4 Saliency detection via global sparse representation (initial global saliency map)
2.3 局部和全局顯著性自適應融合
綜合考慮上述基于局部或全局稀疏表示的顯著性檢測效果,各有利弊:局部稀疏檢測法側重于檢測物體輪廓,容易丟失顯著物體內部信息;而全局稀疏檢測法可以很好地突出物體內部信息,但是背景噪聲得不到很好地抑制。
基于此,本節將求得的初始局部和全局顯著圖進行相互融合,取長補短,以獲得更好的檢測結果。現有的圖像顯著圖融合方法包括取乘法融合[24]、最大值融合[25]、加權融合[26]等。不同融合算法的融合結果對比如圖5所示,其中,圖5(a)為原始圖像,圖5(b)是初始局部顯著圖,圖5(c)是初始全局顯著圖,圖5(d)是乘法融合結果,圖5(e)是取最大值融合結果,圖5(f)是加權融合結果(以1:1加權為例)。通過對比發現,乘法融合只能顯示兩幅圖像共同顯著的部分,對于局部區域而言,被抑制的內部信息在經過乘法融合之后,依舊不顯著;最大值融合得到的顯著圖由于只來源于某個主要渠道,不能很好地突出顯著區域;加權融合相比前兩種方法,能取得較好的效果,此外加權融合實現也簡單,效率高。

圖5 不同融合策略對比結果 Fig. 5 Comparison of different fusion strategies
對于加權融合,如何選取兩幅顯著圖的權重之比非常重要,一般有兩種方式:固定權重值[27]和自適應權重值[28]。前者兩幅顯著圖的權重值固定,實現簡單,運行速度快,但是靈活性差,不能根據圖像的不同特點調整相應的比例。因此,為了更加合理地融合兩幅初始顯著圖,得到更好的融合效果,這里提出了一種自適應權重計算策略。
給定初始局部顯著圖SL和全局顯著圖SG,并分別進行歸一化,然后將它們自適應融合,得到最終的顯著圖S:
S(i,j)=ωL×SL(i,j)+ωG×SG(i,j)
(6)

定義SL相對于SG的相關性,相關系數用PL表示:
(7)
同理,定義SG相對于SL的相關系數PG:
(8)
在此基礎上,計算權重值ωL和ωG:
(9)
(10)
將計算的得出的權重值ωL和ωG代入式(6)中,即可得到最終的融合圖像S。圖6給出了圖3(b)初始局部顯著圖和圖4初始全局顯著圖的自適應加權融合結果,由該圖可以看出融合了局部和全局的顯著圖比單一算法顯著圖要好很多,克服了單一算法的缺點,最終顯著圖既抑制了背景信息,又突出了顯著物體內部,取得了不錯的效果。

圖6 基于自適應加權融合的最終顯著圖生成 Fig. 6 Final saliency map generation by using adaptive weighted fusion
3 實驗和分析
為了驗證提出算法的有效性,在CPU主頻為2.3 GHz,內存為4 GB,仿真軟件為Matlab R2013b的PC上對提出算法進行了實驗。實驗圖像來源于MSRA、ECSSD, NUSEF 和INRIA數據庫[29-32],這些圖像庫包含了各種各樣的自然場景原始圖像和被人工標記過的真值圖像,從這些庫中隨機挑選了400幅圖像進行實驗。
3.1 定性分析
為了評價本文提出的顯著性檢測方法,選擇了IT、GBVS、SR、SUN和CA這5種經典的顯著性檢測算法及基于稀疏重建殘差(Sparse Representation Residual, SRR)的顯著性檢測算法[33]進行對比,結果如圖7所示。圖7(a)均表示原始圖像。這里選取了一些具有代表性的原始圖像,包括:具有較大顯著性區域的原始圖像(如圖7(a)的前三幅圖)、具有較小顯著性區域的原始圖像(如圖7(a)的第4到第7幅圖)、具有多個顯著性區域的原始圖像(如圖7(a)的最后兩幅圖)。圖7 (b)~(h)分別為IT、GBVS、SR、SUN、CA、SRR和提出算法(記為Ours)得到的顯著圖,圖7 (i)為真值圖。對比不同算法的顯著圖,可以看出IT算法可以檢測出顯著性區域,但是邊緣信息模糊,且檢測目標內部信息不能很好地保留;GBVS算法略優于IT算法,但顯著性目標內部仍無法有效檢測;SR算法對邊緣信息過于敏感,忽視了顯著目標內部;SUN算法較好地檢測出顯著目標,但很多背景信息也被檢測到;CA算法也很關注背景信息,從而導致非顯著性區域不能得到很好的抑制;SRR算法更加關注顯著性物體的邊緣信息,內部區域未能有效檢測出來。相比其他算法,本文算法有很大的優勢,由于融合了局部和全局的思想,對較大顯著性對象不僅能夠識別并保存其邊緣信息,同時能夠準確提取出其內部信息(如圖7(h)的前三幅圖);此外,本文提出算法對較小顯著性對象也達到了良好的檢測效果(如圖7(h)的第4到第7幅圖);最后,針對包含多個顯著性對象的原始圖像,提出算法也能夠將相關對象區域提取出來,使得這些對象在整體上得到了提升(如圖7(h)的最后兩幅圖)。
3.2 定量分析
為了進一步驗證提出算法的性能,本文采用查準率(precision),查全率(recall)和F值(F-measure)這三個指標來定量分析[34]。這三個指標的具體計算公式如下:
(11)
(12)
(13)
其中:SB代表將檢測結果圖像進行二值分割后的結果,G為該圖像的真值圖,Num(SB)和Num(G)分別代表SB和G中像素值為1的個數,參數β2取0.3。
本文將不同算法在整個實驗數據集(共400幅圖像)上進行了實驗,針對每個算法計算得到的400幅顯著圖結果,在[0,1]區間上,以0.05為步長,選取閾值對所有顯著圖進行二值化分割,然后計算每個閾值下的查準率和查全率,最終得到該算法的平均查準率,查全率和F值,結果如表1所示。由表可見,提出算法的在查準率、查全率及F值上均有較好的表現,明顯優于其他方法的相應指標。其中,查準率反映了檢測出的并包含在真值圖中的顯著像素與檢測出的顯著像素之比,體現了檢測的有效像素在整個顯著像素中的百分比,查準率越高說明檢測的正確性越高。查全率反映的是檢測出的包含在真值圖中的顯著像素與總的真值圖像素比,體現了被檢測出的有效顯著像素與實際有效像素之比,查全率越高說明檢測出的顯著性區域越完整。F值是對查準率和查全率的綜合量化指標,總體而言更具可靠性。因此,本文提出的算法在顯著性檢測的正確性、完整性及綜合評價方面均優于其他方法。

圖7 不同算法顯著圖對比 Fig. 7 Saliency map comparison of different methods 表1 不同方法的查準率、查全率和F值比較 Tab. 1 Precision, recall and F-measure comparisons of different methods

算法查準率查全率F值IT0.540.210.3963GBVS0.600.390.5337SR0.450.370.4286SUN0.610.390.5397CA0.670.580.6468SRR0.580.360.5083Ours0.770.740.7629
此外,除了上述量化評價之外,為了分析提出算法的時間效率,在Matlab 2013(b)的平臺上進行了實驗。不同算法的運行時間結果如表2所示,結果保留到小數點后三位,時間單位是“秒”。由于本文提出的算法基于稀疏表示理論進行顯著性檢測,所以在時間效率上,本文提出的算法不如前4種經典算法。為了提高算法的效率,后續將采用具備并行計算能力的計算機以及更高效的軟件實現平臺(如C++)對算法進行實現。
總之,通過實驗結果分析及量化指標評價,本文提出的方法相對現有算法在顯著性檢測效果及性能方面均有明顯提高。
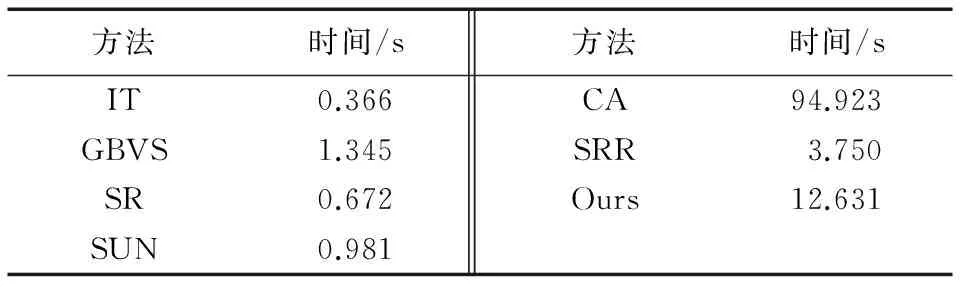
表2 不同方法的效率比較(Matlab)Tab. 2 Computation time comparison of different methods (Matlab)
4 結語
本文提出了一種基于自適應融合局部和全局稀疏表示的圖像顯著性檢測方法,通過在常用基準數據庫進行評測,與IT、GBVS、SR、SUN和CA 5種經典方法進行性能對比,結果表明,本文提出的方法能夠有效檢測顯著性目標的邊緣和內部區域,并在查準率、查全率和F值 3個指標上明顯優于比較算法。由于本文算法基于稀疏表示理論,算法效率有待進一步提高。
參考文獻(References)
[1] SANTELLA A, AGRAWALA M, DECARLO D, et al. Gaze-based interaction for semi-automatic photo cropping [C]// CHI ’06: Proceedings of the 2006 SIGCHI Conference on Human Factors in Computing Systems. New York: ACM, 2006: 771-780.
[2] BRADLEY A P, STENTIFORD F. Visual attention for region of interest coding in JPEG 2000 [J]. Journal of Visual Communication & Image Representation, 2003, 14(3): 232-250.
[3] CHEN T, CHENG M M, TAN P, et al. Sketch2Photo: Internet image montage [C]// Proceedings of the 2009 ACM SIGGRAPH Asia. New York: ACM, 2009: Article No. 124.
[4] WANG L, XUE J, ZHENG N, et al. Automatic salient object extraction with contextual cue [C]// ICCV ’11: Proceedings of the 2011 International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2011: 105-112.
[5] NAVALPAKKAM V, ITTI L. An integrated model of top-down and bottom-up attention for optimizing detection speed [C]// Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2006: 2049-2056.
[6] KANAN C, COTTRELL G. Robust classification of objects, faces, and flowers using natural image statistics [C]// Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2010: 2472-2479.
[7] ITTI L, KOCH C, NIEBUR E. A model of saliency-based visual attention for rapid scene analysis [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11): 1254-1259.
[8] SCH?LKOPF B, PLATT J, HOFMANN T. Graph-based visual saliency [C]// Proceedings of the 2006 20th Annual Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2007:545-552.
[9] HOU X, ZHANG L. Saliency detection: a spectral residual approach [C]// CVPR ’07: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society. 2007: 1-8.
[10] ZHANG L, TONG M H, MARKS T K, et al. SUN: a Bayesian framework for saliency using natural statistics [J]. Journal of Vision, 2008, 8(7): 1-20.
[11] GOFERMAN S, ZELNIKMANOR L, TAL A. Context-aware saliency detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(10): 1915-1926.
[12] CHENG M M, MITRA N J, HUANG X, et al. Global contrast based salient region detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3): 569-582.
[13] LIU N, HAN J. DHSNet: deep hierarchical saliency network for salient object detection [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 678-686.
[14] 葉子童,鄒煉,顏佳,等.基于引導Boosting算法的顯著性檢測[J].計算機應用, 2017,37(9):2652-2658.(YE Z T, ZOU L, YAN J, et al. Salient detection based on guided Boosting method [J]. Journal of Computer Applications, 2017, 37(9): 2652-2658.)
[15] HOU X, ZHANG L. Dynamic visual attention: searching for coding length increments [EB/OL]. [2017- 03- 03]. http://pdfs.semanticscholar.org/1432/d0c3a4b96bc3af9f83d65d77be2fb1046fb6.pdf.
[16] BORJI A. Exploiting local and global patch rarities for saliency detection [C]// CVPR ’12: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012: 478-485.
[17] 陳文兵,鞠虎,陳允杰.基于倒數函數-譜殘差的顯著對象探測和提取方法[J].計算機應用,2017,37(7):2071-2077.(CHEN W B, JU H, CHEN Y J. Salient object detection and extraction method based on reciprocal function and spectral residual [J]. Journal of Computer Applications, 2017, 37(7): 2071-2077.)
[18] LI Y, ZHOU Y, XU L, et al. Incremental sparse saliency detection [C]// ICIP ’09: Proceedings of the 16th IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2009: 3057-3060.
[19] HAN B, ZHU H, DING Y. Bottom-up saliency based on weighted sparse coding residual [C]// MM ’11: Proceedings of the 19th ACM International Conference on Multimedia. New York: ACM, 2011: 1117-1120.
[20] OLSHAUSEN B, FIELD D J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images [J]. Nature, 1996, 381(6583): 607-609.
[21] HUANG Y, HUANG K, YU Y, et al. Salient coding for image classification [C]// CVPR ’11: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2011:1753-1760.
[22] DAMNJANOVIC I, DAVIES M E P, PLUMBLEY M D. SMALL box — an evaluation framework for sparse representations and dictionary learning algorithms [C]// LVA/ICA ’10: Proceedings of the 9th International Conference on Latent Variable Analysis and Signal Separation. Berlin: Springer, 2010: 418-425.
[23] PATI Y C, REZAIIFAR R, KRISHNAPRASAD P S. Orthogonal matching pursuit: recursive function approximation with applications to wavelet decomposition [C]// Proceedings of the 1993 Conference Record of the 27th Asilomar Conference on Signals, Systems and Computers. Piscataway, NJ: IEEE, 1993, 1: 40-44.
[24] KIM W, KIM C. Spatiotemporal saliency detection using textural contrast and its applications [J]. IEEE Transactions on Circuits & Systems for Video Technology, 2014, 24(4): 646-659.
[25] LI Y, TAN Y, YU J G, et al. Kernel regression in mixed feature spaces for spatio-temporal saliency detection [J]. Computer Vision & Image Understanding, 2015, 135: 126-140.
[26] SU Y, ZHAO Q, ZHAO L, et al. Abrupt motion tracking using a visual saliency embedded particle filter [J]. Pattern Recognition, 2014, 47(5): 1826-1834.
[27] FANG Y, WANG Z, LIN W. Video saliency incorporating spatiotemporal cues and uncertainty weighting [C]// Proceedings of the 2013 IEEE International Conference on Multimedia and Expo. Washington, DC: IEEE Computer Society, 2013: 1-6.
[28] WANG X, NING C, XU L. Saliency detection using mutual consistency-guided spatial cues combination [J]. Infrared Physics & Technology, 2015, 72:106-116.
[29] LIU T, SUN J, ZHENG N N, et al. Learning to detect a salient object [C]// CVPR ’07: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2007:1-8.
[30] YAN Q, XU L, SHI J, et al. Hierarchical saliency detection [C]// CVPR ’13: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 1155-1162.
[31] RAMANATHAN S, KATTI H, SEBE N, et al. An eye fixation database for saliency detection in images [C]// Proceedings of the 2010 European Conference on Computer Vision, LNCS 6314. Berlin: Springer, 2010: 30-43.
[32] JEGOU H, DOUZE M, SCHMID C. Hamming embedding and weak geometric consistency for large scale image search [C]// Proceedings of the 2008 European Conference on Computer Vision, LNCS 5302. Berlin: Springer, 2008: 304-317.
[33] XIA C, QI F, SHI G, et al. Nonlocal center-surround reconstruction-based bottom-up saliency estimation [J]. Pattern Recognition, 2015, 48(4): 1337-1348.
[34] WANG X, NING C, XU L. Spatiotemporal saliency model for small moving object detection in infrared videos [J]. Infrared Physics & Technology, 2015, 69: 111-117.
This work is partially supported by the National Natural Science Foundation of China (61603124), the Six Talents Peak Project of Jiangsu Province (XYDXX-007), the 333 High-Level Talent Training Program of Jiangsu Province, the Fundamental Research Funds for the Central Universities (2015B19014).
WANGXin, born in 1981, Ph. D., associate professor. Her research interests include image processing, pattern recognition, computer vision.
ZHOUYun, born in 1992, M. S. candidate. Her research interests include image processing.
NINGChen, born in 1978, M. S., lecturer. His research interests include compressed sensing.
SHIAiye, born in 1969, Ph. D., associate professor. His research interests include image processing, visual computing.
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
