基于PISA的學習素養評價模式設計與實證研究
2018-05-14 17:57:26齊宇歆
中國電化教育 2018年4期
齊宇歆
摘要:當前國際上,一種以場耦合、整體論和自然生成為旨趣的自然人文主義教育思潮漸成主流。在學習評價領域,OECD的PISA模式可謂個中翹楚。為此,該文首先從詞源學視角解讀了PISA中“Literacy”的社會文化功能,接著從認知與進化層面探討了學習的發生與本質,對“學習素養”給出了一個描述性定義,提出了形成模型,最后,構建了評價指標體系,運用基于計算機的項目反應理論測試方法在鄭州E中學開展了實證研究。結論如下:(1)學習素養有三個公因子,它們分別是顯著影響學習素養形成的素養因子、反映考試成績高低的成績因子和能否積極利用身邊各種學習資源的資源利用因子,其中素養因子對學習素養的影響最為顯著;(2)就總體而言,學生表現最出色的是交流合作和記憶策略,最差的是信息資源利用情況;(3)成績優異的學生和絕大部分學生主要采用記憶策略,而成績中上者則常用精致策略;(4)在所有指標中,學科成績的標準差最大;(5)精致策略等四個指標都會顯著影響知識遷移水平。在當前背景下,學生的學習參與度普遍偏低,活學活用能力明顯欠缺,兩極分化現象嚴重,這些問題不能不引起業界關注。
關鍵詞:PISA;Literacy;學習素養模型;評價指標體系;項目反應理論;實證研究
中圖分類號:G434 文獻標識碼:A
PISA(Program for International Students Assessment)是美、英等國在知識經濟背景下針對自身基礎教育質量連續下滑而進行反思后的產物。自上海2009年作為我國第一個大陸地區參加OECD的PISA評估項目并兩次同時在閱讀、數學和科學三個領域獲得第一之后,PISA得到了全社會有識之士的共同關注,在我國教育界也涌起了一股PISA研究熱。如何借鑒PISA的精髓來扎實推進我國處于瓶頸狀態的素質教育改革是擺在業界同仁面前一項嶄新的課題。從宏觀層面來看,要將PISA移植于素質教育評價必須考慮三個因素。首先,PISA的研究對象是即將結束義務教育的十五歲初中生,它屬于一種基于常模參照測試的相對性評價。這種評測方式主要是通過各樣本在常模中的相對位置來判斷樣本間的差異,看重的是對樣本的區分能力,這對于從宏觀層面依據總體分布特征來制定教育政策、預測各參與國的創新型人才儲備和經濟、社會發展后勁的相對優劣狀況無疑是合適的,但是,對于通過一系列教學活動后,重在判定被試是否掌握了該目標領域中最重要的概念群、基本命題和基本技能,被試是否存在結構性缺陷以及怎樣有針對性地進行補救的絕對性評價,即基于某一標準、理念的學業水平達成度評價則是不合適的。其次,我國于2001年頒布了基礎教育各學科的課程標準。這些課程標準在課程性質、目標和知識點上都做出了詳細規定,而且具有強制性,因此,在進行具體實踐時有必要將二者結合起來。最后,雖說有必要借鑒PISA評價模式來進行全國性或跨地區的專業調查,但考慮到我國地域廣闊,東、西部地區之間經濟、文化差異較大,在現階段,以學生個體、班級、學校甚至較小地區進行學習狀況的自我監測和自我評價,更能有的放矢地改進自身教學過程中的不足以實現內涵式提升。概言之,我們不能簡單地因襲PISA評價模式,必須充分考慮評價目標上的差異、國情制約和學校、學生個體的自身實際需要,才能在實踐中逐步探索出一種真正意義上的本土化學習評價模式。六年來,筆者以我國現階段的課程標準為基本依據,借鑒PISA評價的基本思想,增設部分能充分反映被試現實表現的真實性評價指標,突出個體和小規模團隊的學習狀態自診斷,并先后在鄭州、廈門的多所初、高中進行了實證研究,現將研究結果進行整理論述。
一、“Literacy”的功能分析
自OECD設立PISA評估項目以來,我國為什么會有如此多的人群聚焦該項目呢?在筆者看來,除了人們的求新求異心理,這一現象更多地是承載了人們對徘徊在十字路口的素質教育評價能否得到根本性突破的一種期待。客觀地說,PISA一改過去評價的鑒定性質,轉而以促進發展為己任,具有其獨特的社會文化功能。在宏觀層面,PISA以即將完成義務教育的初中畢業生為觀察對象,以各參與國學習質量的橫向比較為手段,以學習有效內化和學習持續性為紐帶,其初衷是教育質量的持續改善,創新型人才與合格公民的培養是其雙重任務,最終目標則是實現經濟、社會的可持續性發展和培養能有效溝通、合作的社會公民。在微觀層面,PISA制定了嚴格而詳盡的技術標準以確保流程的規范性,采用項目反應理論(Item Response Theory,IRT)以確保測試具有更好的效度;利用分層隨機抽樣和問卷調查法從學生、學校、家庭等方面全方位地收集原始信息。另外一個最為突出的原因就在于其別具一格的學習評價理念——“Literacy”。
從詞源學的角度考察,“Literacy”由詞根“Liter”和后綴“-acy”兩個詞素構成。其中,“Liter”來源于拉丁語“Littera”,構成了該詞的核心義,意為“字母”“文字”;后綴“-acy”是一個表示“過程”“狀態”的抽象名詞后綴。因此,“Literacy”也就表示“能識字”“有文化”的狀態。時至今日,“Literacy”的文化功能又有了新的拓展。如圖1所示,PISA中的“Literacy”由六部分構成。它以個體生存為基點,沿著兩條線索發展:一條是認知→情境問題解決→批判性反思;另一條是人際交流、合作→哈格公民,可分別稱為認知主線和社會化主線。該外延整合了知識、能力和態度,打破了原有的“學科中心”桎梏,突出知識必須面向生活、回歸社會。該理念的提出有利于突出基本活動經驗中的真切感受和在此基礎上通過歸納、概括、轉換、推衍、抽象而習得的概念框架和詮釋體系,使學習者將凝固的知識和經驗升華到開放、動態的智慧層次。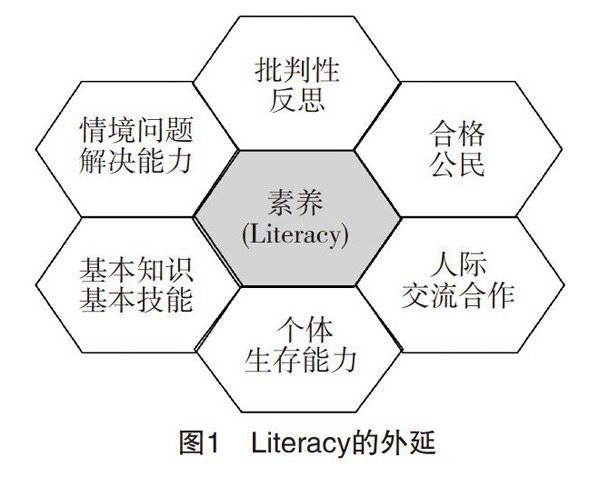
二、學習素養形成探微
學習與學習素養形成的動因是什么呢?進化心理學認為:(1)在漫長的進化過程中,人類自身逐步形成了一套獨特的環境適應系統;(2)大腦與心理是上述系統的兩個不同層次,前者主要受物理、化學定律支配,而后者則按照一定的邏輯序列負責進行信息加工,彼此以互補方式來協同工作;(3)人類并不能意識到自己的全部活動,大多數適應問題仍然依靠潛意識甚至本能來解決。
按照上述理論,在這一復雜的自適應系統中,大腦大致相當于電腦硬件,而心理則可視作軟件。事實上,兩個神經元之間是通過突觸(Synapse)并依賴于神經遞質、神經調質來實現連接的。由于一個突觸后神經元有上千條樹突同時在接收信息,因此,每一神經元都是一個多路輸入系統。面對不同的環境刺激,每一個突觸后神經元都能依據信號強弱來靈活地選擇并傳遞來自不同軸突上的神經沖動。不過,信號能被選擇并傳遞的前提是該信號疊加后的強度必須達到某一閾值,因此,編碼上只有“全”或者“無”。假如某一個體長期接受同一或類似環境的刺激,突觸上將合成新的蛋白質,在某些神經回路中形成某種相對固定的行為模式,這種類似本能的模式化行為就是反射(Reflex)的前身。長時間以來,這些既準確又快速的反射機能進化成了自身不可或缺的生理性適應機能,而且可通過基因形式遺傳給后代。其中,那些直接而具體的刺激物就是巴甫洛夫所說的“第一信號系統”,它為人類和動物所共有。然而,學習是一種特殊的反射,它具有目標性,并且是以語言、文字這種“信號的信號”即概念化符號為媒介來進行的,其最大特點間接性與抽象性,也就是說人類能將各感覺器官所收集到的環境信息依據時間接近律在大腦的不同功能中樞中加以分析與整合,形成了以特征為基礎的框架性記憶和表象,再依據相似原則將同類刺激物加以總括,形成字、詞并賦予一定的意義。然而,這種符號化的作用是雙重的:一方面,它拓展了人類進行條件反射、認識的廣度和深度;另一方面,由于個體的經歷存在差異,其觀察、統合、類比、概括化的程度常常不一致,而且人們可以在明確指稱某一具體事物的“指示義”或帶有自身情感寄托、影射的“引申義”上進行選擇性使用,這樣就容易造成“能指”(形式)和“所指”(內容)的脫節。解決這一問題的辦法是運用“思維場”,即聯系上下文或情境進行邏輯推斷。如果把“學習”看作為個體因“思維場”所引起的某種行為或行為潛能相對穩定的改變,那么,學習的本質是改變,而改變的目的是適應。當然,這種改變的結果有兩種:一種是同一層次上的水平增長,另一種是從較低層次到較高層次的縱向躍遷。從這個意義上來說,學習素養是一種高階思維能力,是“互聯網+”時代的“五大核心素養”之一。
上述命題只是對學習素養的一種初步判斷,內涵尚不清晰,筆者通過“描述性定義”法為其下一個初步定義,即:學習素養是學習者在長期的學習活動中,以生活中的靈活運用為目標,以深度探索和透徹理解為途徑,將前后學習活動進行內容、方法和意義上的整合之后所形成的一種個性化認知習慣與品質。其主要特點是認知情境化、內化深刻性、學用一致性和個體獨特性。
在系統論看來,事物的結構及其所處環境共同決定了系統的功能,一切事物皆可從環境、功能、結構、層次、運行機制等方面加以考察,因此,學習素養也是由許多功能模塊和要素構成的有序存在,其子系統均具備一定的子功能。它們在相互激勵、相互補充、相互制約的耦合關系中形成了一種動態的心理機制與行為模式,并呈現出具有一定結構的“分布式認知”格局,共同完成了學習素養所預設的全部功能。在如圖2所示的模型中,動力部分是統括了學習動機、學習興趣、學習態度在內的“學習參與度”。內容部分是“知識技能”,它通過課程以“概念”“命題”為基本形式,服務于特定培養目標,內容經過精選,各知識點之間具有嚴密邏輯性。方法部分是“學習策略”,它是指學習者對具體學習內容的加工方法選擇、加工路線安排與所需資源的調配使用情況,因此,它包括了認知和調控兩部分。其中,“認知策略”又包括“記憶策略”和“精致策略”。“學習調控策略”主要涉及學習對象選擇、時間分配與調整、環境選擇、自我激勵、尋求他人支持等資源組織能力。考慮到互聯網資源的日益豐富和當代協同創新活動的日趨頻繁,健全人格在未來社會中的作用日益重要,筆者提出了“信息資源運用”能力和“人際交流合作”能力兩個概念模塊。調節部分是個體運用自身所學知識和技能去解決情境化問題的反饋情況,這種反饋有正向和負向之分。“知識遷移”是一種將所學知識技能予以靈活運用的能力,注重在記憶中針對原型(Prototype)的多側面、多層次信息進行模型、概念、原理等的最大相似性(Similarity)概括及其類比推理能力。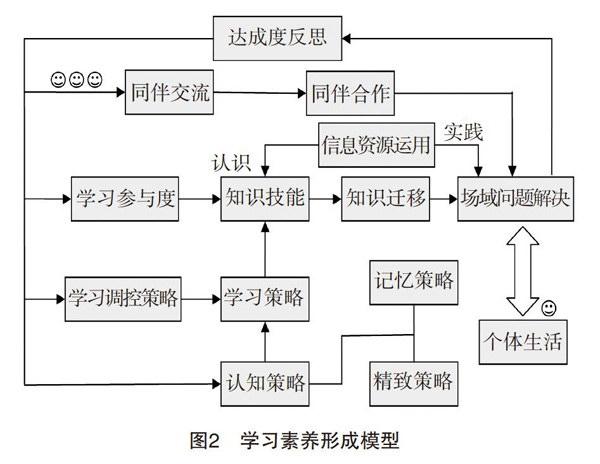
三、評價指標體系的構建
通過評價,人們可發現當前或過去的活動能在多大程度上能滿足自身需要,并對未來情況進行預測,將不利因素予以控制或排除,或者從眾多方案中找出最有價值的一種,進行有效決策。如果說評價就是一種基于行為方式層面的質的描述或量的測量之上的價值判斷活,那么,每一評價指標都必須清晰而典型地從某一側面或環節反映出該系統的某一狀態或過程。此外,指標體系除了層次清晰、同一層次的指標在外延上不能有交叉重疊現象之外,還要使每一層次、側面或環節都有恰當數量的指標作為代表,也就是說,只有在符合完備性原則時,整個評價指標體系才能在既相互獨立標識,又相互補充、相互制衡的動態關系中立體化、多層次地反映出被評價對象的總體特征與功能狀態。當然,指標體系的最后一級指標還必須是外顯化行為或狀態,這樣才有可能依據某種規則對終極指標進行賦值并做數據處理。總之,評價指標體系建立必須遵守典型性原則、完備性原則、終極指標外顯化原則。在實際操作中有三個關鍵問題也需引起注意。
(一)指標的層次與數量問題
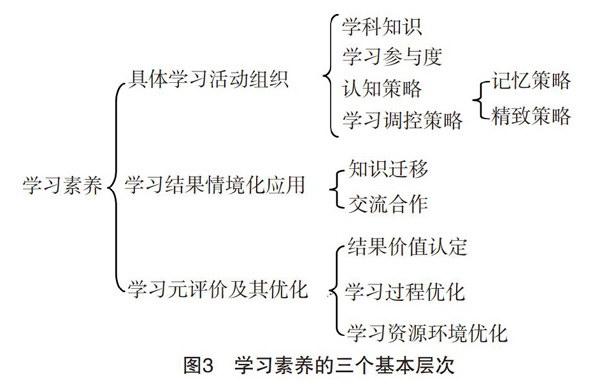
有學者認為:在對影響評價目標的因素進行篩選與歸并時,除了要遵守層次性與典型性原則,同時也要遵守簡約性原則,評價體系通常以不超過三層為宜,這樣,評價指標體系更便于操作。圖2的形成模型提出了學習素養的評價要素集,它屬于一個多目標系統,而評價指標體系則是它們與評價要素集之間的一種映射,二者之間存在一對一、一對多,多對一和多對多四種可能映射關系。其中,一對一關系最為理想,但不具備普遍現實性;其次是一對多關系,它們不存在交叉與重疊;多對一和多對多情況下存在交叉與重疊,應該盡量避免。因此,筆者將學習素養分解為學習活動組織、學習結果情境化應用、學習過程的元評價及其優化三個遞進層次。在學習活動組織方面,保留了PISA中的學習參與度和學習調控策略,將認知策略細化為記憶策略和精致策略,同時將模型中的“知識技能”明確為教材上的“學科知識”,以便今后在評價中用課程的考試分數來進行具體表征;在學習結果的情境化應用層次,依然保持了PISA中的知識遷移和(人際)交流合作;在元評價及其優化層次,重點描述學生的反思與創新能力、將信息化資源運用于學習過程和具體問題解決的能力。指標的層次體系如圖3所示。
(二)各評價指標的權重問題
指標權重,又稱權系數,它表征了該指標在整個指標體系中的相對重要性,它通常用一個[0,1]之間的小數來表示。目前,確定權重最有效的辦法仍是依賴于專業判斷。因此,筆者采用了較為常見的Delphi法,即專家調查法。在確定權重的過程中,首先由研究人員提供專家調查表,在調查表上簡要描述指標內容和可以備選的相對重要性等級;然后交由一組互不見面的專家憑借自己的專業經驗進行判斷,勾選一個他認為最切合的數值;經回收與統計后再將平均數、眾數等趨同性數值、持有異議的少數專家態度及其理由反饋給各個專家,再次征詢專家們的意見;經過數輪咨詢后,專家結果會趨向于穩定與收斂,最終獲得了具有統計意義的專家小組意見。專家代表的遴選與無預設導向性評判意見是Delphi法成功的關鍵。在兩輪的調查研究中,筆者選擇了來自9所高校、分布在8個不同省份的31名長期研究學習理論或學習評價的專家,他們長期從事一線教學、科研工作,均具有博士學位或副教授以上職稱。專家的專業權威性、地域代表性和人數規模都符合Delphi法的要求,鑒于筆者已另外撰文介紹了這一研究的詳細過程,故在此從略。各指標內容及經歸一化等計算后所得到的各指標權重如表1所示。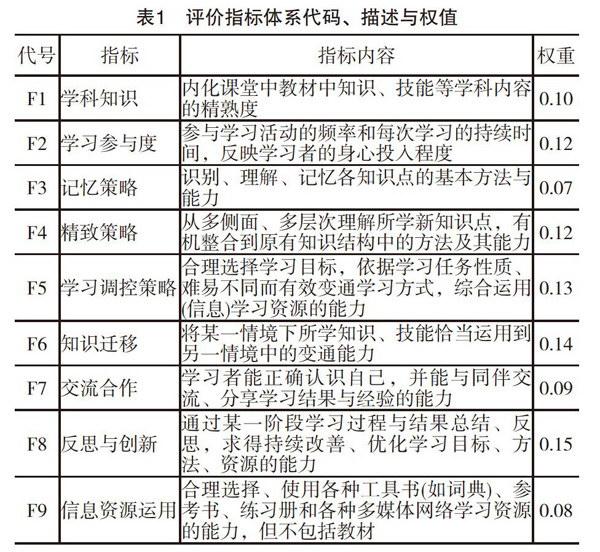
(三)各指標的量表設計
前述的指標體系只是解決了具體評價什么的問題,接下來就要確定評價標準,即如何圍繞評價指標來精準地選擇并度量各指標,它實質上是一組行為樣本的合理選擇與規范化賦值。通常,它要解決三個基本問題:(1)究竟該從評價對象上選擇哪些最為典型而又便于測量的行為或狀態作為各指標的行為樣本;(2)行為樣本的可能取值范圍如何以及根據什么標準在上述取值范圍內劃分等級;(3)各個指標行為樣本的不同等級、程度該如何分派一組合適的數字或代號。對于第一個問題,行為樣本的選擇必須符合完備性原則,即這組行為樣本的集合最好能包含該指標全部內容,最起碼也能包含該指標的全部重要特征。在實際操作中,根據評價對象性質的不同,可選擇使用某些時空條件下的行為頻率去定量描述,無法進行定量描述時一般選擇能典型代表內心感受的某些強度指標去作定性描述。至于第二、第三個問題,必須結合行為樣本的特征、性質并依據量化水平就高不就低的原則分別從類別量表、等級量表、等距量表、比率量表中加以選擇。學習素養評價各指標的量化和賦值情況如表2所示。
在表2中,F1(學科知識)并不是嚴格意義上的等距量表,而是一種介于等級量表和等距量表之間的量化形式。和PISA一樣,它的測量是基于項目反應理論(IRT)進行的,因此,必須借助計算機和某些專門軟件來完成。與經典測試理論(CTT)只考慮隨機誤差、假定每次測量都是互不影響的做法不同,IRT一方面通過數學模型把項目得分與項目自身性質、被試的潛在特質(Latent Trait)聯系起來,從而使測試項目的難度特性與被試的能力特質處于同一張量表之上;另一方面,通過使用信息函數而非方差來估測每個項目或試卷的效度,也不存在樣本依賴性問題。此外,項目參數的估計可獨立于被試進行,便于編制試題庫。鑒于IRT的以上特點,有國內學者明確指出:除了適合于編排各種較大規模能力水平的精細量化考試外,IRT還可有效應用于學習者以學習品質的自我檢查為目的的自適應測試(CAT)中,或者與認知科學結合起來,以便開發具有認知特點、認知結構分析功能的學習品質診斷系統。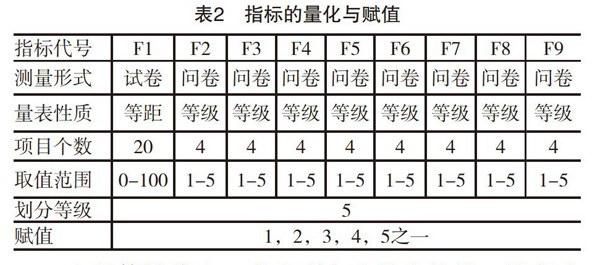
在具體操作上,考慮到方法的成熟性,筆者選擇單維性假設下雙值計分方式的邏輯斯蒂三參數模型(見式(1),式中a、b、c分別為區分度、難度和猜測度,p為正答率),測試項目庫的建設經歷了項目試測、模型四假設驗證、篩選項目、項目的等值化處理、依據雙向細目表和信息函數大小編制試卷等主要過程。其余8個指標都是采用五級計分制的總加評分式李克特(Likert)量表,每一個指標同時從四個不同側面進行提問,以便相互印證,及時淘汰不合理答案;每一個提問都力求措辭清晰、明確,而且都是采用很贊成/同意、贊成/同意、不一定/無所謂、不贊成/同意、很不贊成/同意的無導向陳述模式。對此,有學者指出:當量表中的測試項目不少于50個時,同樣能具有令人滿意的信度。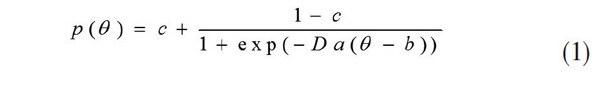
四、實證研究
根據以上設計的評價指標體系,筆者圍繞數學素養、閱讀素養先后在鄭州E中學、廈門L中學開展了多次實證研究,現將于鄭州E中學進行的研究過程進行簡要論述。
(一)研究對象的選擇
與PISA一樣,此次研究對象是初三學生。而PISA之所以選擇他們,一方面是考慮到他們中有一少部分人從此就要離開學校,獨立地走上了社會舞臺,即將成為所在參與國中的一名普通公民;而另一方面,現在的知識更新周期不足三個月,以學習興趣、學習習慣、學習結果靈活運用為基本內容的終身學習能力又是個體是否具備良好學習素養的表征。因此,通過調查他們在閱讀、數學和科學領域的學習素養水平,就能大體上判斷該參與國的創新人才儲備情況。考慮到數學領域不僅是三個基礎性領域之一,更有抽象性、嚴謹性與廣泛應用性的顯著特征,而且已有比較成熟的認知目標分類標準,故筆者在研究中選擇了初三的數學作為測試領域。
(二)基本研究過程
本實證研究過程主要從兩個方面來收集原始數據:一是圍繞“學科知識”即初三(上)數學,依據IRT測試的要點與程序對上述研究對象進行試測,然后篩選出難度、區分度等指標都合格的試題,依據雙向細目表要求再次編制一套試卷,擇機返回現場正式施測;二是在測試結束時,馬上組織對其余8個指標的問卷調查。
1.項目篩選
在基于IRT的測試中,為了確保效度,必須進行單維性驗證、特征曲線形狀檢查、模型擬合度驗證以及最后的項目難度、項目區分度、項目猜測度的具體數值計算等過程。
(1)單維性驗證:其目的既要保證試卷中所有項目之間具有良好的相關性,同時每次測試又只測量一個主要因素。判斷辦法是:查看因子分析中因子載荷矩陣的第一個公因子的方差貢獻率是否達到了20%。然而,進行因子分析也需符合兩個條件:一是KMO值≥0.7;二是Bartlett球形檢驗的顯著水平≤0.01。其中,第一個條件保證了皮爾遜相關系數的平方和遠大于其偏相關系數的平方和,即項目之間具有較大的關聯性;第二個條件則保證了因子載荷矩陣近似于單位矩陣,各項目之間又相對獨立。在此次測試中,通過SPSS 20.0計算發現:A、B卷的KMO值分別為0.81和0.85,Sig.值都是0.00,并且第一個公因子的方差貢獻率分別為21.69%和26.89%,因此完全符合單維性假設。
(2)特征曲線形狀檢查:每一個項目的難度應適中,不能過難或過易,這樣項目才具有一定的辨識力。這一要求反映在三參數邏輯斯蒂模型中就是項目難度一正確率的關系必須近似于一條“S”形曲線,對于那些近似于直線的題項則直接予以剔除。在此次檢查中,A、B卷各刪除了兩道題。
(3)模型擬合度驗證:在這一過程中,主要考察測試數據分布是否符合三參數邏輯斯蒂模型的理論分布。它屬于離散型非參數檢驗,主要考慮樣本實際頻數與總體理論頻數的差異大小,故一般采用卡方檢驗。考慮到即使樣本很大時X2檢驗也可能拒絕零假設,故此次模擬度檢查采用服從n-k的X2分布的楊統計量(Yen Statistic)檢驗,其最大特點是當樣本數在500-1000之間時擬合效果最佳。通過專業軟件ANOTE 1.6計算后,如果其X2檢驗的楊統計量超出了顯著水平,則將該項目予以剔除,如A卷中的第10題和B卷中的第6題。
(4)項目的參數計算:由于項目參數和能力參數均為未知,故一般采用聯合極大似然估計法,這實際是一個先給定初值,然后雙向交替迭代直至收斂的過程。在ANOTE 1.6軟件上,通過選定項目反應理論程序模塊上的“二級評分三參數項目估計”即可得到各項目的難度、區分度和猜測度參數。此外,對于項目的參數還要進行閾值檢查,即區分度、難度、猜測度分別在[0.3,2.0]、[-3.0,3.0]、[0,0.25]之間。超過閾值的項目也要予以剔除。如果要實現隨機組卷功能,還要在A、B卷中設置錨點,這樣才能進行等值化處理。
2.組卷
一份高質量的試卷不僅要涉及所學課程的全部知識與技能,還應重點突出、比例恰當。為此,筆者首先運用ISM法(Interpretive Structural Modeling Method)對教材的知識點進行結構關聯性分析,這樣便于從宏觀上依據知識點之間的相關性大小去把握教材的內容比例與難度;接著緊密結合義務教育數學課程標準中的內容——目標要求,重點考察學生對相關知識點的理解程度和進行應用時所表現出來的思維深度,具體劃分為識記、理解、應用、分析與探究五個精熟度水準,其中識記、理解題的分值約總分數的50%,而應用分析類、探究類所占分值分別是總分數的35%和15%。整個試卷由25道題組成,具體說明試卷中各章節知識點、考核目標、內容比例、難易性質的雙向細目表如表3所示。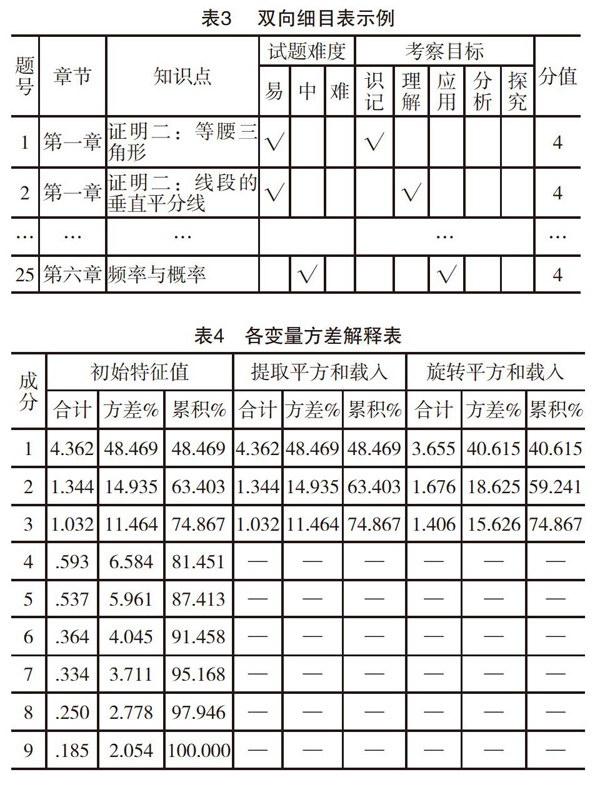
3.施測
整個測試分為試測和正式施測兩個階段。在第一輪的項目試測中,被測人數和測試項目理論上都是越多越好,故從E中學初三年段的全部10班中隨機選擇了6個班,合計332人,其中三個班用A卷測試,另外三個班用B卷測試。在第二輪的正式施測中,筆者從剩余的4個班中隨機抽取了1個學習狀況處于中間水平的班級,該班有學生57人,除去因病事假學生,實際參測人數為54人,去掉無效問卷3份,實際有效樣本為51個。
(三)主要指標分析
1.學習素養的因子分析
以表1中的F1-F9分別作為縱軸和橫軸,以彼此間的相關系數構造因子載荷矩陣,經SPSS 20.0計算后,發現其KMO=0.816≥0.7,且Sig.=0.000≤0.01,故適合進行因子分析。主成分分析后的各變量方差解釋結果如表4所示。由表4可看出:前三個公因子合計解釋了方差貢獻率的74.9%,故提取這三個公因子就可以較好地解釋原來9個變量的變化情況。
經坐標旋轉后的因子載荷矩陣如表5所示,表中數值是該變量與所在公因子之間的相關系數。為了清晰起見,將相關系數在0.5以上的指標在表中以方框標注。由表5可見:公因子1以精致策略為代表,還受到記憶策略、知識遷移、交流合作、學習調控策略、反思與創新、學習參與度的影響,但它們的相關系數漸次減小,而且它幾乎不受學科成績(F1)和信息資源利用(F9)兩個指標的影響。由于它對學習素養的方差貢獻率達到了近一半,能較好地代表了學習素養水平,故可以將其稱為素養因子。同理,與第一公因子相互獨立的第二公因子和第三公因子則分別反映了學生的考試得分情況和信息資源利用情況,因此,可分別命名為成績因子和資源利用因子。
2.認知策略的使用分析
如前所述,認知策略包括傳統的記憶策略和以知識點的深度理解與整合為基礎的精致策略。為了統一量綱,筆者將學生的測試成績按照[0,20],[21,40],…,[81,100]五個間隔轉換為五級計分制。不同成績水平的學生使用記憶策略與精致策略的情況如圖4所示。
從圖4可以看出:不同成績水平的學生使用記憶策略和精致策略的情況是不同的。在當前狀況下,成績優秀的學生更多使用記憶策略,而中等成績的學生反而更注意使用精致策略,由于他們的知識得到了較好的理解和整合,反而使得他們在日后的工作、生活中具有較高的情商和創新意識。這也與在當前的教育背景下成績最優秀的學生往往很難成為各行業的領軍人物這一社會現象相符合。
3.知識遷移水平
知識遷移反映了學生學習后是否獲得了觸類旁通的情境問題解決能力,這與學習后所形成的語義知識網絡的規模大小和層次有關。考慮到指標數據主要是非連續型的等級數據,故采用的是Spearman相關檢驗。在樣本數N=51時,各評價指標對知識遷移水平的影響程度如表6所示。在該表中,精致策略F4、交流合作F7、反思與創新F8和學習參與度F2都會明顯影響知識遷移水平,而學科成績F1和信息資源利用F9則對知識遷移水平幾乎沒有影響。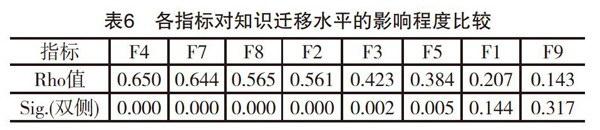
如按照對因變量貢獻最大且符合判斷條件:F≤0.05時進入,F≥0.1時予以刪除的規則逐一引進各自變量,還可得到知識遷移水平預測的回歸方程: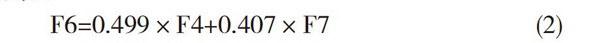
4.各指標均值與標準差比較
指標的集中量和差異量往往可以通過其均值和標準差來加以刻畫。經計算,9個指標的平均值為3.29。各指標的均值和標準差如圖5所示,均值最大的為交流合作指標F7,其次是記憶策略F3,最小的是信息資源利用F9,其數值分別為3.59、3.44和2.76。這一現象與學習是一種社會活動、具有很強的互動性這一特點有關。不過,被試的學習目的重在獲取比較理想的分數,認知方法主要是機械記憶,這不利于形成自己的立體化語義知識網絡,從而間接影響了日后創新能力和知識遷移能力的提高。此外,信息資源利用F9的均值最小,這也在一定程度上說明在當今學習背景下,學生普遍還沒有養成充分利用萬維網上的各種數字化學習資源作為學習手段有效補充的習慣。在差異量方面,學科知識(成績)F1的標準差為0.934,是9個指標中最大的一個,而標準差最小的是反思與創新F8,這說明初中生學習中的兩極分化現象比較嚴重,而反思與創新能力都在較低水平徘徊,不具有明顯差異。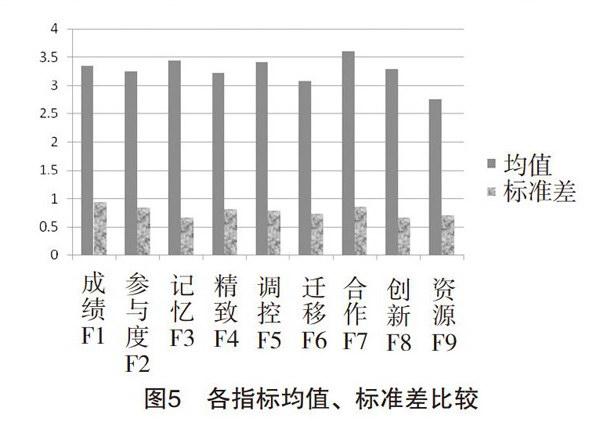
5.反思與創新等四個指標的橫向比較
學生通過學習活動汲取知識,但其根本目的還是要解決自身所面臨的問題。能否在應用中收獲創新與效率是判斷教育成敗的關鍵指標之一。從研究結果看,學科成績F1、學習參與度F2、知識遷移F6和反思與創新F8這四個指標的均值依次是3.35、3.24、3.39和3.28,只有學科知識F1在平均值3.29之上,而學習參與度F2和反思與創新F8均沒有達到平均水平。上述四個指標在不同成績水準學生的頻數分布如圖6所示。從該圖可以看出,四條曲線都呈準正態分布,但它們的峰度和偏度明顯不同,眾數所在區間也不同。反思與創新F8和學科成績F1較為同步,知識遷移水平最高的那部分學生成績表現為中等和中等偏上,學習參與度F2則呈現明顯的負偏態。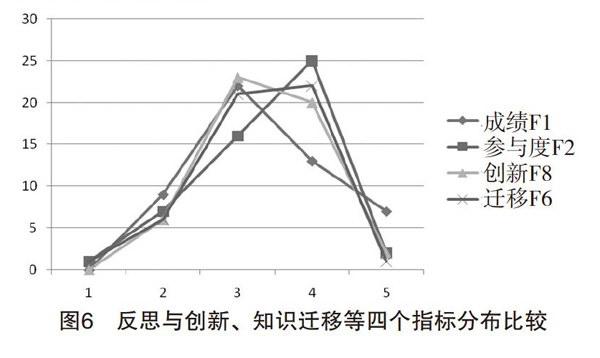
(四)研究的效度
本研究通過雙向細目表來保證了內容效度,但在此次測試與調查中,學生能力是否得到了穩定發揮尚不得而知。為此,本研究將此次測試成績分別與該班期中考試和上一次月考的平均成績進行了t檢驗,按式(3)進行計算并查表得知:在顯著性水平α=0.05、自由度df=51條件下均接納了測試樣本總體的平均分μ與假設總體平均分μ0之間沒有區別的零假設。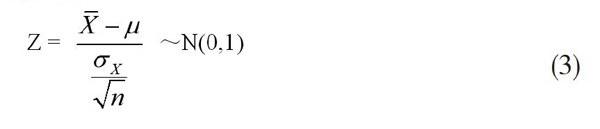
五、反思與展望
概括地說,價值是活動對象的客體屬性、功能與主體需要的一種關系表征。學習評價是一種對學習活動能在多大程度上滿足主體需要的價值判斷活動。因此,評價研究中特別注重三個基本問題,即為什么而評、評什么、怎么評、從本質上來說,學習評價歸根結底是一個認識問題,更確切地說,是一個由點及面、由淺入深、由現象到本質的認識過程。
首先是取樣規模問題。模型驗證的樣本來源越廣,項目參數的適應范圍也就越廣。如果考慮到數據處理的工作量大小,也可嚴格按比例進行隨機抽樣。在類別差異較為顯著時還可采用分層隨機抽樣的方式。受時間、精力所限,本研究的樣本都來自于同一所學校,同一年級的學生規模不超過1000人,因此,研究結論屬于個案性質。當然,從鄭州E中學所處的地理位置和生源結構來看,其結論也有較強的普適性。
其次是擬合模型的選擇問題。對于IRT來說,不同性質的測試會有不同的最佳適應模型,因此,在模型擬合階段可以嘗試使用不同的數學模型。由于數學和科學領域往往具有客觀性和精確計量的特點,可選擇二值計分模型。但是,對于重在捕捉信息和意義的閱讀領域來說,答案往往是基于情感和意義的選擇,具有一定的主觀性,此時選擇多級計分模型更為合適。因此,筆者在對廈門L中學高一學生閱讀策略的評價研究中改用了五級計分的等級反應模型(Graded Response Model)。
再次是信息函數的使用問題。信息函數I(θ)反映了某一項目對某被試能力的分辨程度。因此,只有在測試中找出那些難度與被試能力最為接近的項目(此時項目的信息函數值最大),才能保證測量誤差最小。具體來說,在組卷時,如果一套試卷的信息量達到25,其標準誤差將小于0.2。在進行自適應測試時,如何圍繞最大信息量設計一種快速而有效的算法也是一個值得研究的問題。對于CAT,筆者嘗試將所有項目按照難度大小分成數層,然后依據信息量不斷增大的原則進行試測,直到前后兩次信息量之差小于某一可接受的誤差之后才停止。為充分利用第一手項目測試數據和減少調試工作量,整個選題流程在經過蒙特卡羅(Monte Carlo)模擬實驗予以證實并且取得滿意效果后才正式形成算法,編寫代碼。
最后是該評價模式的應用前景問題。歷經六年多的探索驗證,該評價模式已相對成熟。預計在未來一段時間內,研究將從目前以初中生為研究主體,逐步擴展到小學五、六年級和高中一、二年級學生,內容涉及閱讀、數學和科學三個領域,建設一個中等規模的多媒體試題庫,在學習素養評估專題網站中采用實時問卷調查和基于IRT測試相結合的辦法,以本研究中的指標權重為基礎,轉換成一個百分制數值,將結果解釋和未來完善建議一并即時反饋給該網站用戶。這些用戶可能是廣大學習愛好者或學校教師和教育研究人員,甚至可以是家長。
