基于遺傳K均值算法的軍事裝備試驗數據分組模型
2018-05-08 04:58:50馬晨光劉慶國李亞雄
兵器裝備工程學報 2018年4期
馬晨光,劉慶國,李亞雄
(火箭軍工程大學, 西安 710025)
裝備試驗與評價是按照規定的程序、條件和方法獲取裝備的特性數據,并通過數據處理分析,考核驗證裝備的特性是否滿足要求的活動[1]。隨著信息化進程的不斷深入,現代戰爭對于軍事裝備維修保養的要求也不斷提高[2]。現有的軍事裝備維修保養引入了一些高科技手段,但如何在軍事裝備數量繁多,標準要求高的軍事裝備維修保養中,科學合理地安排維修保養計劃仍是各級指揮員的當務之急。
K均值算法是一種無監督的聚類分析方法,但其分組數目需要事先指定,容易陷入局部最優,不具有客觀性,而采用具有全局搜索能力的遺傳算法則能夠實現分組數目的自動學習。本研究以軍事裝備為研究對象,建立了基于遺傳K均值算法的聚類分組模型,將不同的軍事裝備劃分到不同的組。基于此,指揮員可以按照不同組別指定不同的維修保養計劃,使得軍事裝備的維修保養更加科學化,更有利于長期戰斗力生成。
1 相似性度量
相似性度量是進行聚類分組的依據,本文將不同軍事裝備試驗數據進行歸一化處理,采用歐氏距離作為相似性度量。在此之前需要進行數據清理、數據集成、數據裝換和數據消減的數據預處理,詳見文獻[3]。由于各項軍事裝備試驗數據采取的分制不同,需歸一化后才能進行聚類分組。假設m=[ma,mb,…,mNN]和n=[na,nb,…,nNN]為兩個軍事裝備,其中NN為軍事裝備試驗數據項目的總數。歸一化處理公式為
(1)
其中amax和amin為軍事裝備試驗數據a項的最大最小值,在歸一化處理后,采用加權系數的歐式距離作為相似性度量
(2)
其中ωkk為權系數。
2 K均值算法
K均值算法是一種使用最廣泛的聚類算法[4-5]。算法以K為參數,把軍事裝備分為K個簇,使組內具有較高的相似度,而組間相似度較低。算法首先隨機選擇K個軍事裝備,每個軍事裝備初始代表了一個簇的平均值或中心,對剩余的每個軍事裝備根據其與各個簇中心的距離,將它賦給最近的簇,然后重新計算每個簇的平均值,不斷重復該過程,直到準則函數收斂。準則函數為
(3)
式中:p表示軍事裝備試驗數據;Ci表示第i個分組;mi表示組Ci的聚類中心。
K均值算法的描述如下:
1) 任意選擇K個軍事裝備的試驗數據作為初始的聚類中心。
2) 計算每個軍事裝備的試驗數據與K個聚類中心的距離,并將距離聚類中心最近的其他軍事裝備試驗數據劃分到一組。
3) 計算每個組的質心(聚集點的均值)并重新計算每個軍事裝備的試驗數據到質心的距離,并根據最小距離重新對相應的對象進行劃分。重復該步驟,直到式1)不再明顯發生變化。
3 基于遺傳K均值算法的聚類分組模型
由于K均值算法對初始聚類中心比較敏感,容易陷入局部最優,加入具有全局搜索能力的遺傳算法[6-7]則能夠有效地解決該問題。
1) 染色體編碼
本研究采用實數編碼方式進行編碼。圖1中G1,G2,…,Gk為初始聚類中心點。

G1G2…Gk
圖1 編碼示意圖
2) 初始種群的生成
為了獲得全局最優解,初始種群完全隨機生成。先將每個樣本隨機指派為某一類作為最初的聚類劃分,并計算各類的聚類中心作為初始個體的染色體編碼,共生成K個初始種群個體,由此產生第一代種群。
3) 適應度函數計算
本文的適應度函數計算式為
(4)
其中:a和b為正的常系數;E為準則函數,描述分組的緊密性;Gb描述的是組間的離散性,式(4)的含義為組間距離越大,組內距離越小,適應度函數值越大
(5)
式(5)中ci,cj分別為第i,j個聚類中心。
4) 遺傳算子
選擇:采用適應度比例法,根據各個體的適應度計算個體被選中的概率,用輪盤賭方法進行個體的選擇。
交叉:本研究采用單點交叉:在兩條需要交叉的染色體上,隨機選取交叉點,然后交換交叉點右側的基因,得到兩個新的染色體。
變異:其具體操作過程是:對于每個變異點,從對應基因位的取值范圍內取一隨機數代替原有基因值。
結合K均值算法和遺傳算法,得到遺傳K均值算法流程(見圖2):
① 設置參數,包括初始分組數目K,種群的規模Mt,遺傳終止代數hf,交叉概率Pc和變異概率Pm;
② 隨機產生初始種群;
③ 以種群個體為聚類中心,采用K均值算法進行聚類分組,計算個體的適應度值;
④ 按照上文的遺傳算子設計方法,得到新的后代;
⑤ 反復執行③到④,直到算法收斂或達到遺傳終止代數,將得到適度值最優的個體作為結果。
4 實驗結果及分析
本文以假設的200臺某型軍事裝備的訓練數據作為研究對象,數據結構包含:編號(S1-S400),機動能力(A,100分制)、抗干擾能力(B,100分制),打擊能力(C,20分制)、打擊精度(D,20分制)、運載能力(E,20分制)和生存能力(F,20分制)等各項軍事裝備試驗數據(見表1)。設定初始K值為3,終止迭代次數為60,Pc和Pm分別為0.7和0.1。本文設置A,B,F 3個項目的權重為0.25,0.25,0.2,其他3項分別為0.1。
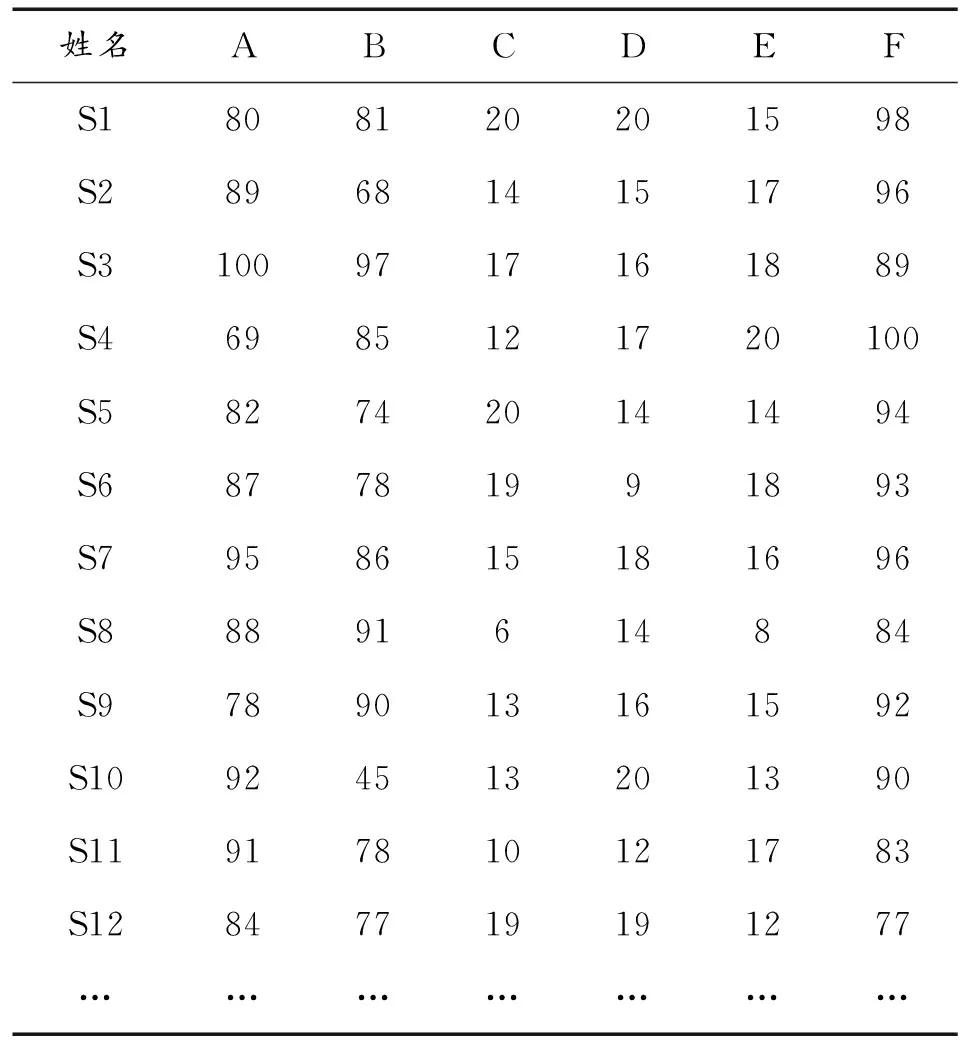
姓名ABCDEFS1808120201598S2896814151796S31009717161889S46985121720100S5827420141494S687781991893S7958615181696S88891614884S9789013161592S10924513201390S11917810121783S12847719191277…………………
經計算后,得到分組結果如表2所示。分組數目由最初的3變為5,實現了自動學習,說明遺傳算法在K均值聚類分組中發揮了作用。第1、2、3、4、5組軍事裝備的數量分別為48,24,70,28和30,為指揮員按照組別制定維修保養計劃打下了基礎。
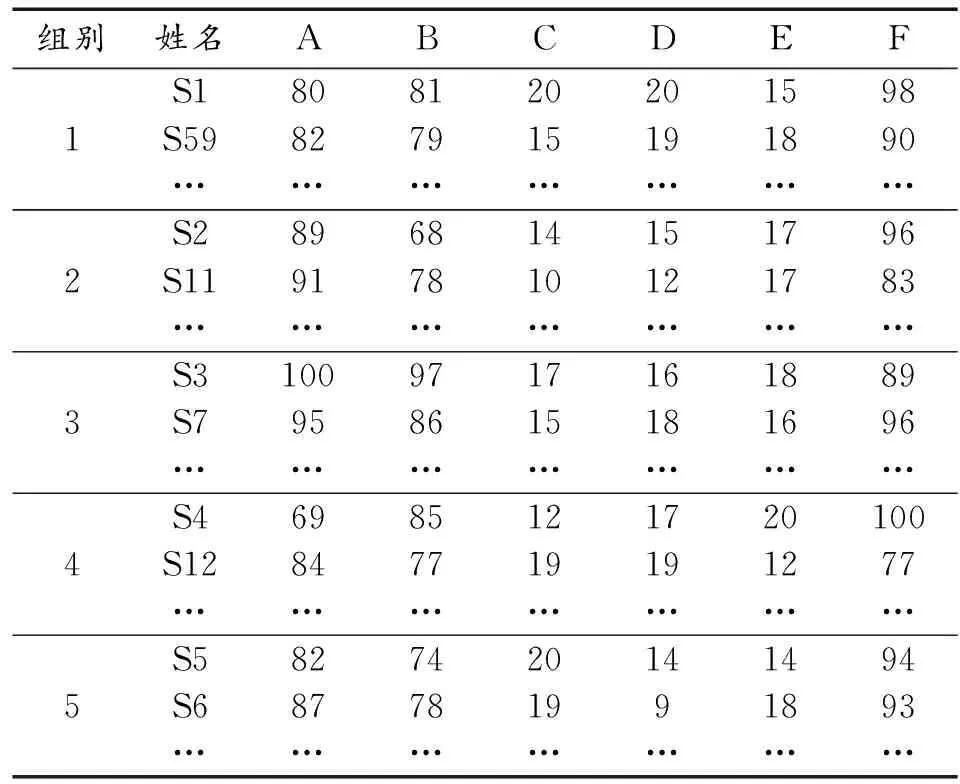
表2 分組結果
5 結論
本文給出了軍事裝備試驗數據的相似性度量,采用遺傳K均值算法對軍事裝備的試驗訓練數據進行了聚類分組,實驗結果證明該方法實現了分組數目的自動學習,為指揮員按照組別指定維修保養計劃打下了基礎。
聚類分組仍有一部分內容需要進一步討論和研究,如:聚類分組的有效性評價,依據分組結果制定科學合理的維修保養計劃等。
參考文獻:
[1] 廖興禾,白洪波,丁建琪.基于系統工程的裝備試驗與評價需求研究[J].裝備學院學報,2017,28(1):118-123.
[2] 王志航.RFID技術在軍事裝備維修保養中的應用[D].濟南:山東大學,2008.
[3] 李健平.決策樹技術在軍事訓練成績中的分析研究[D].昆明:昆明理工大學,2010.
[4] 鄧敏,劉啟亮,李光強,等.空間聚類分析及應用[M].北京:科學出版社,2011.
[5] 呂可,鄭威,趙嚴冰.雷達對抗偵察裝備作戰能力的ANP冪指數評估方法[J].火力與指揮控制,2016(12):59-63.
[6] 賴玉霞,劉建平,楊國興.基于遺傳算法的K均值聚類分析[J].計算機工程,2008,34(20):200-202.
[7] 王玉斌.數據挖掘技術在輔助決策中的應用研究[D].重慶:重慶大學,2008.
