論學術界對開源社區GitHub的貢獻
2018-04-26 01:46:56劉琪琪
現代計算機 2018年5期
劉琪琪
(四川大學計算機學院,成都 610065)
0 引言
在今天的數字世界中,開源軟件幾乎是現代社會和經濟的全部賦能。任何對于開源社區項目的貢獻都是至關重要的,尤其是依賴于開源社區所提供的關鍵服務以及技術支持的用戶群體。
GitHub是一個面向開源及私有軟件項目的托管平臺,因為僅支持Git作為唯一的版本庫格式進行托管,故名GitHub。其作為全球最大的代碼托管平臺,平均每小時都有成千上萬個項目產生,它為開源社區做出了不可磨滅的貢獻。已經有研究人員開始嘗試挖掘GitHub上龐大的數據信息,試圖理解GitHub用戶群體如何使用GitHub開發開源軟件。GitHub引入了一個“fork&pull”模型,開發人員可以通過fork創建自己的拷貝存儲庫,當他們想要在項目修改后可以并入主分支時,便可以通過pull提交一個請求。除了代碼托管、協作代碼審查和集成問題跟蹤之外,GitHub還集成了社交功能。用戶可以關注某個用戶,隨時關注其關注用戶的項目,及時將用戶感興趣的信息推送給用戶。用戶還可以擁有自己的站點,通過自動識別可以顯示出他們最近的活動。GitHub已經變得越來越受歡迎,目前已經有超過3500萬的項目。如此受歡迎程度、社會和協作功能以及其源數據的可用性使得數據挖掘領域的研究人員把GitHub作為一個完美的數據挖掘對象。
開源軟件項目的成功很大程度上依賴于積極的團隊參與,包括計劃、開發、維護和文檔化。參與者通常使用一個或多個共享軟件存儲庫進行協作,以存儲和管理源代碼、文檔和bug報告。GitHub平臺的開源軟件項目的完成主要是來自團隊的貢獻,然而對于此類項目的軟件資源庫訪問通常是嚴格控制的,GitHub上這些項目的合作更傾向于以修復程序或者pull request的形式請求外部參與[1]。
學術界是指學術或學院式的環境。在GitHub中超過千萬的項目中,有很大一部分來自于學術界,這些項目與科研工作者的研究息息相關。而且,使用數據挖掘技術能夠從GitHub龐大的數據中挖掘并分析這類信息。將GitHub用戶群體進行分類,其中隱含著學術界、工業界以及個人用戶的數量及其所占比例。通過分析挖掘的信息,能夠知曉用戶使用這個產品的目的和習慣,從而得出開源項目的發展趨勢。
本文首次提出分析學術界對開源社區所做的貢獻,結合現在最受歡迎的開源項目平臺GitHub,通過平臺提供的API挖掘到的一定量的大數據進行整理分析,從學術界人員所占比例、人員的分布、所參與的項目以及使用語言的偏好著手,通過運用對比分析法、結構分析法等對數據進行分析,再運用杜邦分析法分析原因,實驗結果反映出了學術界對于開源平臺重視程度以及開源平臺在一定程度上對科學研究有引領作用。
1 數據收集
GitHub對外提供開放應用編程接口(API),可以使用其獲取整個平臺的數據,借助GitHubarchive和GHTorrent工具以及GoogleBigquery查詢到自己需要的數據。也可從現有各個渠道搜索查找相關數據,例如中文網站GitHuber。
1.1 GitHubarchive
GitHub Archive網站是通過GitHub的API,定期抓取GitHub的事件數據,并上傳到Google Big Query進行分析。GitHubarchive中根據時間線存儲著從GitHub上獲取的數據,數據分為 yeardataset,monthdataset,daydataset。通過查詢GitHub的API文檔,我們了解到用戶star一個項目時會觸發一個WatchEvent。因此,程序可以遍歷去年所有的WatchEvent事件,按repo_name進行分組,計算每組的數目。最終截取前7000條數據,用來分析去年最受關注的項目。
SELECT COUNT(*)AS star,repo.name
FROM[GitHubarchive:year.2016]
WHERE type='WatchEvent'
GROUP BY repo.name ORDER BY star DESC LIMIT 7000
由此可挑選出去年最受歡迎的100個項目,從而篩選出這些項目中的參與用戶,有多少來自學術界,評比學術界在這些項目中的貢獻。
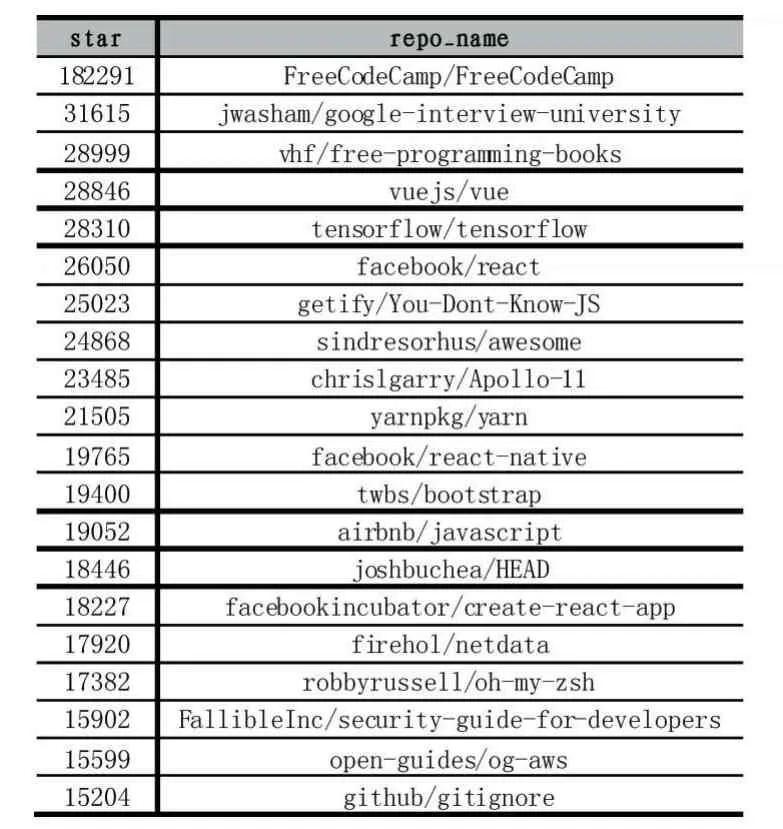
表1 按star值排名靠前的部分項目
2.2 GHTorrent
GHTorrent中的數據也是源于GitHub API獲取的JSON數據,數據以bson的形式保存在MongoDB里,在解析后得到Schema不僅可以將其保存在MySQL里還可以導出SQL[3]。使用GoogleBigQuery即可進行SQL查詢。篩選數據庫中表users里的company,可以得到包 含 有“university”,“institute”,“college”,“school”,“academy”,“學院”,“大學”,“學校”,“研究所”,“研究院”,“中科院”的用戶。意味著這些用戶隸屬于學術界。通過projects表,可查出相關用戶所做的項目情況。
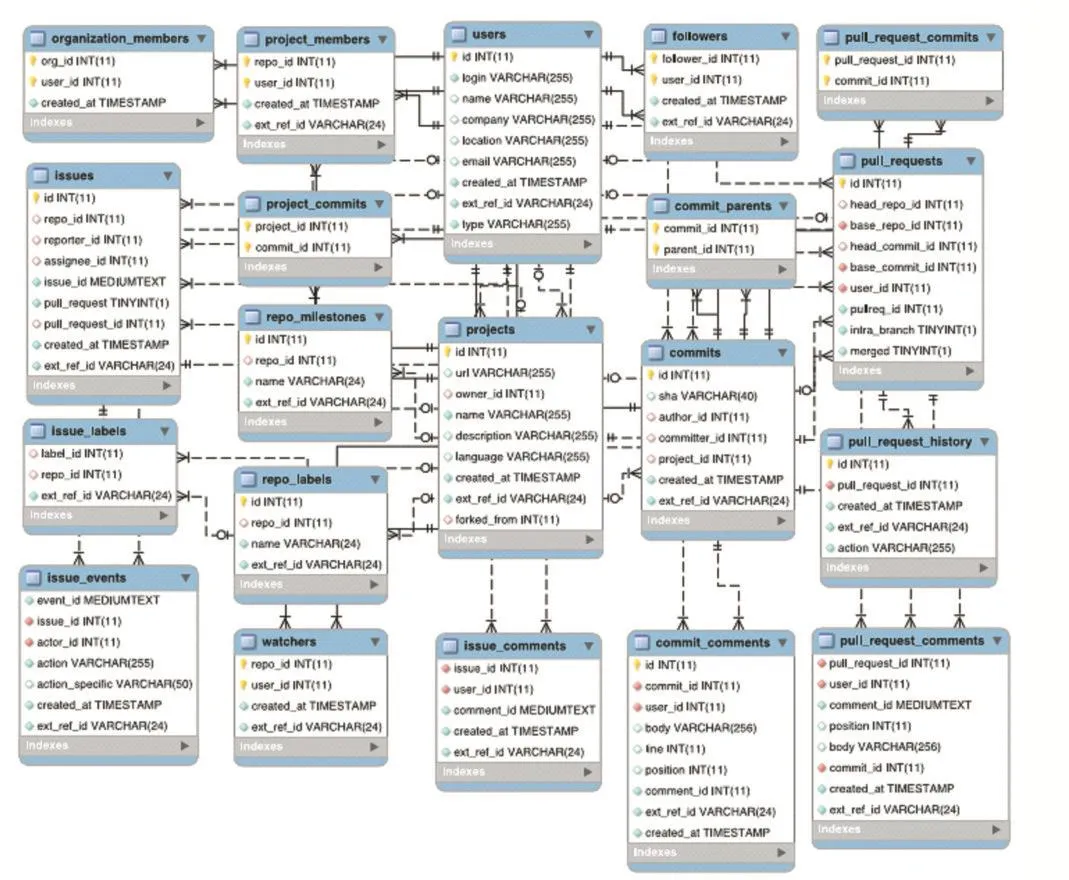
圖1 GHTorrent數據庫表
對所得數據進行預處理整合,去除重復項,共3543人的company來自于學術界。經過學術界的用戶匹配項目后,可以得到一共4983個項目。
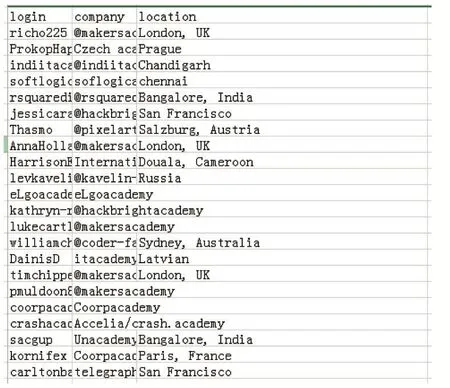
圖2 部分學術界用戶的公司和地理位置

圖3 部分學術界用戶的項目和項目描述
1.3 GitHuber
GitHuber是基于GitHub數據平臺的一個中文網站,可直接通過關鍵字搜索相關機構的用戶,選擇關鍵字“學院”,即可查出所有中國的學術界用戶。部分數據如下:
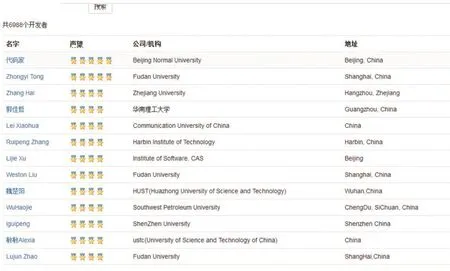
圖4 中國學術界按聲望排行榜
1.4 其他
通過調用 GitHub的 API,抓取 followers排名前1000的用戶,再使用如下公式計算Score值。本文提出的計算公式是受到了業界對followers的排名認可度的啟發。業界普遍認為followers在前期的增長含金量比較高,而之后的增加主要是影響力因素。

通過計算,分別找到了中國地區和世界地區排名前1000的人。部分排名如下:
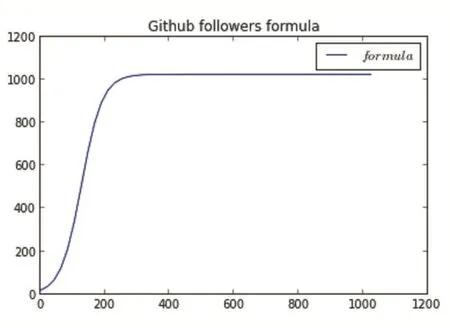
圖5 GitHub用戶聲望計算方式
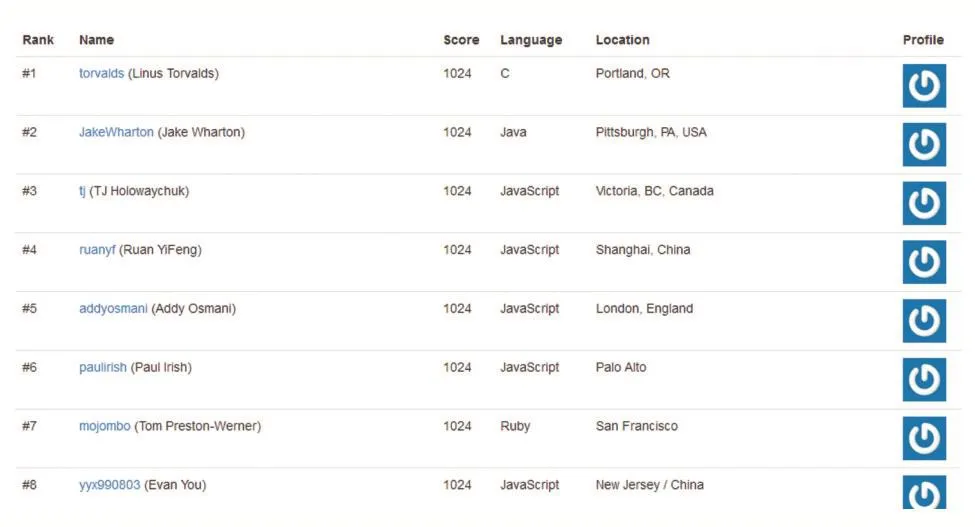
圖6 中國地區排名
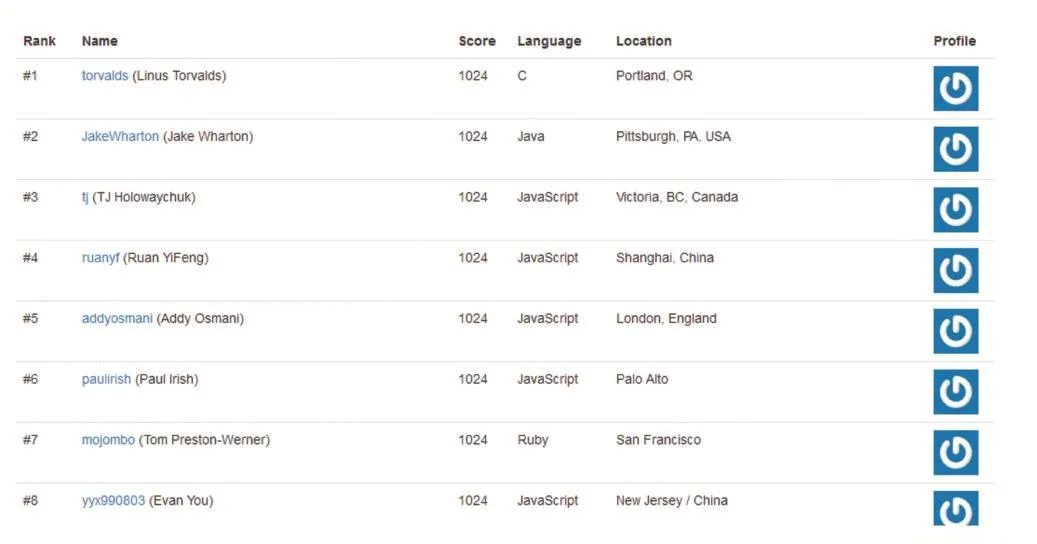
圖7 世界地區排名
2 數據處理
數據處理包含數據清洗、數據轉化、數據提取、數據計算等過程。
2.1 數據清洗
數據清洗主要包含刪除重復項,填充缺失項以及檢測邏輯錯誤項等。由于公司名字存在多個模糊匹配字段,所以在數據量足夠多的情況下,得到的總人數中必然有重復存在的數據,因此需要將重復項刪除。在3543名學術界的用戶信息中,去除location填寫為空的用戶,有2559名用戶顯示了其地理位置。而匹配的目標字段存在很多空白的缺失數據,需將其補齊。當缺失值是以錯誤標識符形式出現的時候,本文的做法是將其全部替換成0。
2.2 數據加工
當數據表現為某些數據字段不滿足我們的數據分析需求時,需要對現有字段進行抽取、計算或者轉換等處理,生成符合本文分析所需要的一系列新數據字段。如抽取的項目參與人員commit次數的數據,得到的是數字加上人名的形式,而本文只需要參與人員姓名即可,則通過檢測空格把數據進行字段分列,去除掉commit字段后,再將人名用“&”進行字段合并。
從Bigquery上直接導出的數據中文字段會存在亂碼情況,是由于CSV文件編碼引起的。因而需要進行數據轉換而得到相應的字段。
3 數據分析
3.1 學術界的用戶分布分析
在3543名學術界的用戶信息中,去除location填寫為空的用戶,得到了帶有明確地理位置信息的2559名用戶。利用ArcGIS軟件導入位置數據,可以得到一個如下圖的學術界用戶群體分布圖。
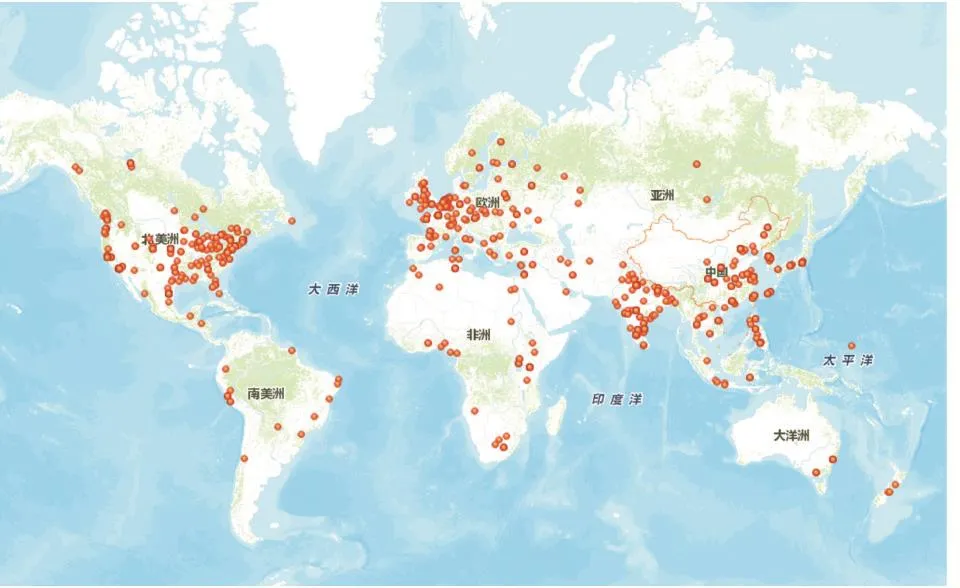
圖8 學術界地理位置分布圖
由圖可知,GitHub上的學術界用戶群體大多分布在美國、英國、中國、印度、韓國等國家,且一線城市的居多。
3.2 學術界的項目分析
通過獲取的2016年最火的前100個項目,使用基于git的后臺并配置ssh key可下載獲得這些項目的源代碼。在命令窗輸入git log--pretty='%aN'|sort|uniq-c|sort-k1-n-r,可以獲得每個項目的參與人員commit的次數。
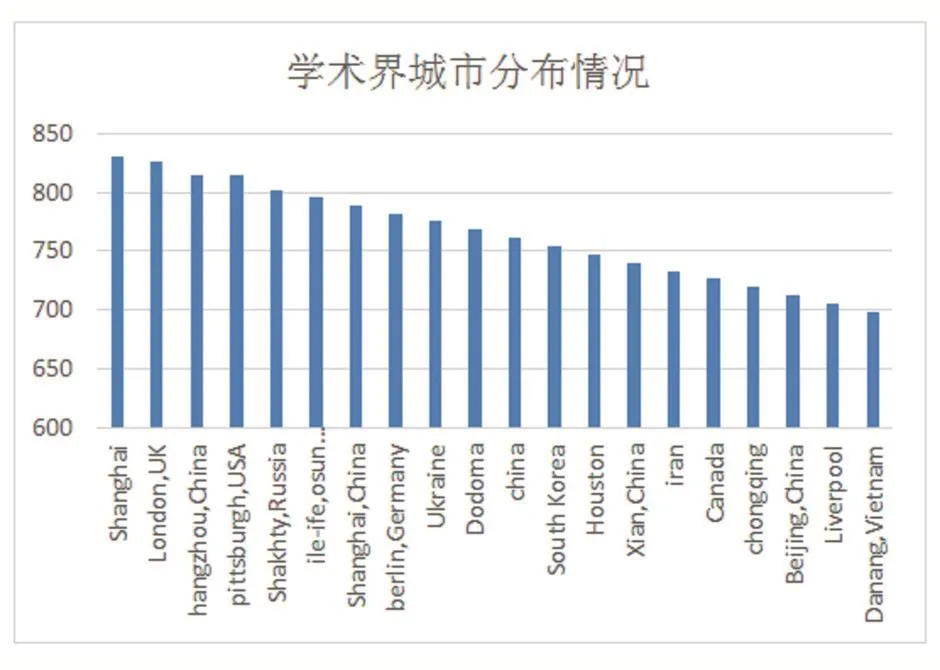
圖9 學術界所在城市排名
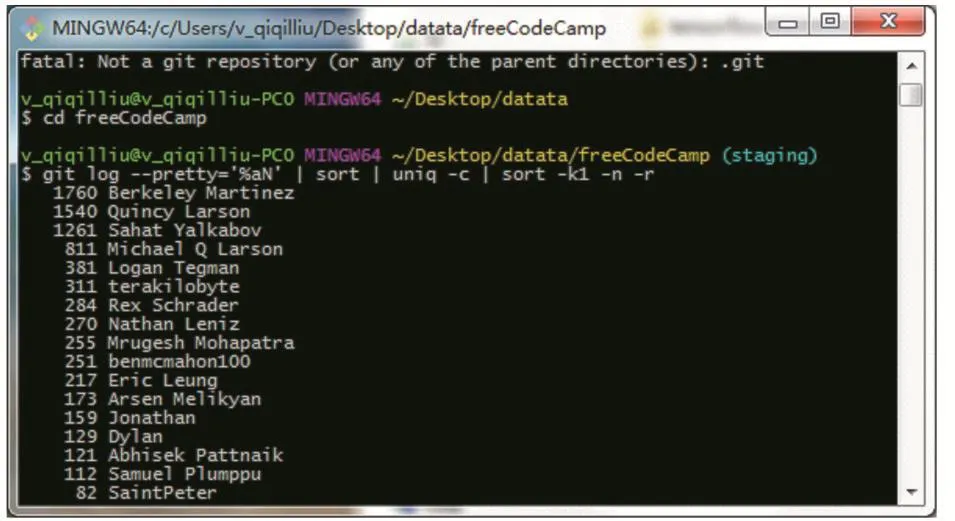
圖10 獲取參與人員commit詳情
選取學術界前10的項目一一進行研究分析后,將所有用戶匯總到同一個表格內,去重處理后可知共有3179名用戶參與,再與先前獲取的學術界用戶群體數據進行比對可知,學術界人員有15名,占總人數的0.5%。
學術界的項目類型主要分為三大類,一是龐大人群共同參與的工程類項目開發,二是個人所在科研項目的研發討論,三是個人生活學習類的小型項目。
3.3 學術界所使用的編程語言偏好分析
通過對學術界項目的抽樣調查,可得到所有項目使用的語言詳情。
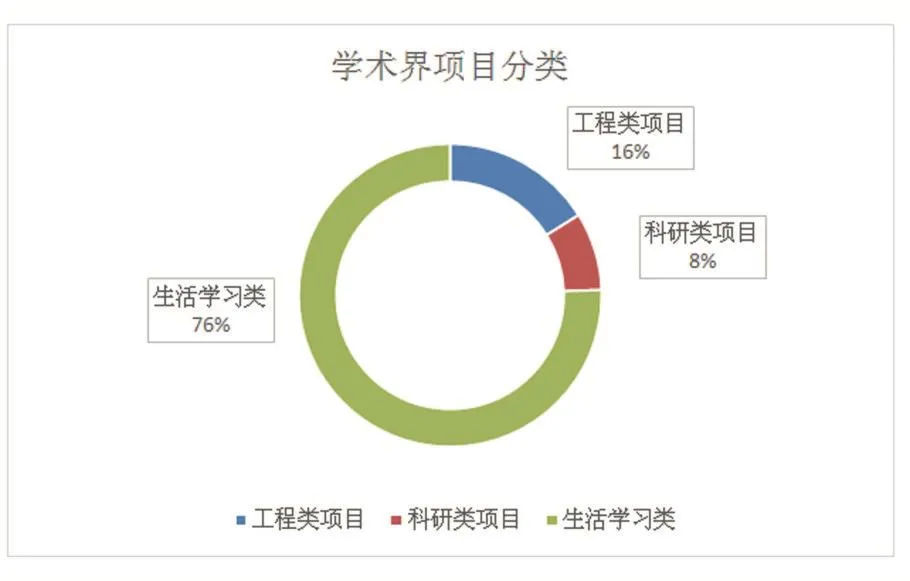
圖11 學術界所做項目分類
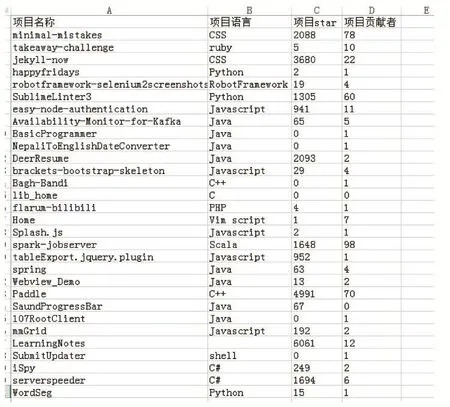
圖12 項目語言詳情
由此可得偏好語言的排序:
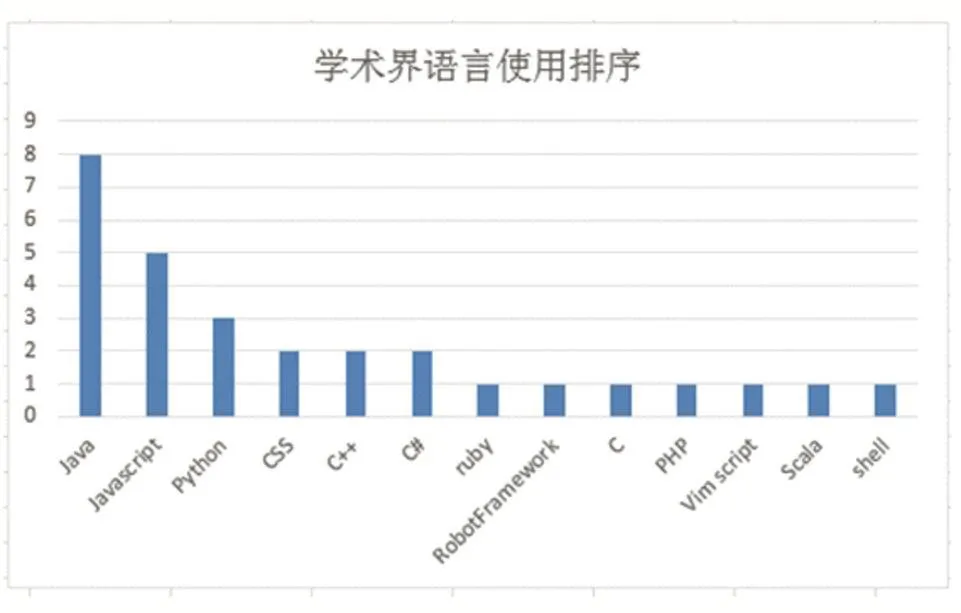
圖13 項目語言排行
4 結語
開源社區有近一半的貢獻者表示,他們關于開源社區所做的一些工作對于他們當前所從事的工作有或多或少的幫助,甚至有一些具有重大意義的工作也放在開源社區的平臺上。開源工作有助于開發者建立自己的專業信譽。
從參與的總人數和總項目來看,學術界的用戶在開源平臺的用戶群體中所占的比例不大。通過分析排名靠前的用戶信息所知,這些用戶幾乎都是國內外頂尖的互聯網公司人才。但是通過學術界所做的項目數據信息進行分析可知,大部分學者在開源平臺的項目大都和自己研究方向相關。
參考文獻:
[1]Padhye R,Mani S,Sinha V S.A Study of External Community Contribution to Open-Source Projects on GitHub[C].Proceedings of the 11th Working Conference on Mining Software Repositories.ACM,2014:332-335.
[2]Gousios G,Pinzger M,Deursen A.An Exploratory Study of the Pull-Based Software Development Model[C].Proceedings of the 36th International Conference on Software Engineering.ACM,2014:345-355.
[3]Gousios G.The GHTorent Dataset and Tool Suite[C].Proceedings of the 10th Working Conference on Mining Software Repositories.IEEE Press,2013:233-236.
[4]Cosentino V,Izquierdo J L C,Cabot J.Findings from GitHub:Methods,Datasets and Limitations[C].Mining Software Repositories(MSR),2016 IEEE/ACM 13th Working Conference on.IEEE,2016:137-141.
[5]Dyer R,Nguyen H A,Rajan H,et al.Boa:A Language and Infrastructure for Analyzing Ultra-Large-Scale Software Repositories[C].Proceedings of the 2013 International Conference on Software Engineering.IEEE Press,2013:422-431.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
