一種改進的點云局部幾何特征匹配方法
2018-04-24 07:58:48史魁洋
現代計算機 2018年8期
關鍵詞:特征
史魁洋
(1.四川大學計算機學院,成都 610065;2.四川大學視覺合成圖形圖像技術國防重點學科實驗室,成都 610065)
0 引言
三維幾何匹配是計算機視覺與模式識別中的一個重要研究方向。近年來,廉價便攜式點云獲取設備的發展,極大地帶動了點云數據處理技術的研究;三維幾何匹配因其在姿態估計和場景重建中的重要性等需要更高性能的方法。
傳統手工構造的低級幾何特征描述子,如Spin Im?ages[2]、Geometry Histograms[3]、Feature Histograms[4]、FP?FH[5](Fast Point Feature Histogram)等。它們大多數都是基于靜態幾何屬性的直方圖信息,在具有完整曲面的三維模型上可以取得很好的效果,但在面對只有部分曲面信息的三維數據時就會出現表現不穩定,這類算法對雜亂和遮擋的抗干擾力不強,在新場景下的應用缺乏魯棒性。
Guo Y等提出了一種叫ROPS(Rotational Projec?tion Statistics)描述子[6],在關鍵點處建立局部坐標系,通過旋轉關鍵點的鄰域并投影到xy,xz,yz三個2D平面上,并在三個平面上劃分“盒子”,根據落到每個盒子的數量,來計算每個投影平面上的一系列分布數據(熵值、低階中心矩等)從而進行描述。K.Simonyan[1]等提出了一種使用凸優化的方法把局部圖像塊非線性映射為一種二維局部特征描述子,該描述子主要是用于圖片的二維對應關系上,當多視點立體圖像缺少紋理時容易造成對應關系缺失。Samuele[7]等提出了SHOT描述子,在特征點處建立局部坐標系,將鄰域點的空間位置信息和幾何特征統計信息結合起來描述特征點,Cirujeda P[9]等提出一種綜合顏色信息和幾何信息的協方差描述子,在三維場景的匹配中達到了很好的效果,這兩種描述方法都存在著描述子維數過大,計算速度慢等問題。
近年來,隨著深度學習在計算機視覺與模式識別領域的廣泛應用,深度學習也被引入到三維幾何匹配上。3D Shape Nets[8]把三維深度學習引入到三維形狀建模上面,通過計算三維數據的深層特征來實現物體的檢索與分類,它們是從整個三維物體提取出一個全局特征,這些工作具有啟發意義,但全局特征容易受到點云數據分辨率低,噪聲、遮擋等影響,難以發揮很好的效果。Guo[10]等使用一個2D卷積神經網絡學習到的描述子來進行局部幾何特征匹配,但是他們的只是把圖像塊特征向量連接起來作為網絡的輸入數據因而缺少空間關聯性,故只適用在合成的且具有完整曲面的三維模型上。Andy Zeng[11]等人提出一種叫做3DMatch的自監督特征學習方法,通過一個3D卷積神經網絡對訓練樣本的學習,得到一種局部體積塊描述子,該描述子在關鍵點匹配上達到很好的效果且在新場景下具有很好的魯棒性。本文在其基礎上通過對其使用的3D卷積神經網絡的修改,訓練得到的新的描述子在相同測試集下準確率達到一定的提升。
1 3DMatch方法介紹
1.1 局部幾何特征學習
3DMatch方法的核心是創建一個函數ψ,可以把點云數據表面的一個興趣點及局部區域映射成一個描述子(向量表示),即給定任意兩個點,函數ψ把它們的局部三維體積塊轉換成兩個描述子表示。再計算這兩個描述子向量的L2范數,通過L2范數的距離來判斷兩個描述子的相似度,L2距離越小表示兩者的相似度越高。為得到該函數,3DMatch使用一個3D卷積神經網絡,通過訓練集學習把三維立體圖像中某一個興趣點及其局部區域映射成一個512維的特征表示向量,此特征表示向量即是該局部區域的特征描述子。訓練時通過使訓練樣本中對應的兩個匹配點的局部幾何描述子的L2距離最小以及兩個不匹配點的L2距離最大來優化卷積神經網絡的權值參數從而得到該函數模型。
1.2 三維數據表示
3DMatch使用的卷積神經網絡的輸入數據為大小為 30×30×30 的 TDF(Truncated Distance Function)值的體素網格(Voxel Grid)。
TSDF(Truncated Distance Function)[12]值等于此體素到物體表面的最小距離值,其值范圍-1~1之間。TS?DF將整個三維空間劃分成立體網格,每個網格中存放的是其到物體表面的距離。TSDF值的正負分別代表被遮擋區域與可見區域,當TSDF值大于零,表示該體素在物體表面之前,屬于可見區域;當TSDF小于零時,表示該體素在物體表面后,屬于遮擋區域;當TSDF值越接近于零,表示該體素越貼近于物體的真實表面。如圖1所示的是重建的一個人的臉(網格模型中值為0的部分,紅線表示重建的表面),重建好的表面到相機一側都是正值,另一側都是負值,在網格模型中從正到負的穿越點表示重建好的場景的表面。其大致原理如圖1所示。
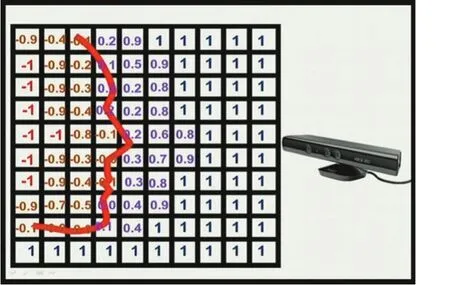
圖1 TSDF網格表示原理示例:圖中的人臉輪廓表示其物體表面
3DMatch使用TDF與TSDF的區別在于TDF舍去了TSDF的正負符號,把值截斷并歸一化為0~1之間,TDF值越接近1,表示該體素越貼近物體的真實表面,越接近0,表示該體素距表面越遠。之所以選擇使用TSDF是因為TDF相比TSDF有幾項優點:TDF去掉正負號使可見區域與遮擋區域的不再加以區分,使得體素值的最大梯度值從相機視景的可見區域與遮擋區域的陰影邊界處集中到物體表面附近,從而使得描述子即使在不完整的數據上也具有魯棒性;此外當拍攝物體的相機視角不可知時,TDF可以減少物體遮擋空間的不確定性。
實驗的局部三維圖像塊空間跨度為0.3m3,體素大小為0.01m3,體素網格相對于相機視角坐標對齊,如果相機位置信息不可知,則體素網格通過物體坐標對齊。
1.3 訓練數據集
3DMatch通過RGB-D重建數據集生成對應點的訓練樣本。該訓練樣本由3D圖像塊以及表示它們是否匹配的對應關系標簽組成。生成訓練樣本的方法如下:首先,在從重建場景中隨機選取興趣點并提取興趣點周圍不同掃描視角的局部3D圖像塊,再把興趣點在重建場景的3D位置投影到相機視景內的所有RGB-D幀上,要確保該興趣點沒有被遮擋,此外這些RGB-D幀的相機位置要相距1m以外,再分別從這兩個RGBD幀選取該興趣點的兩個局部圖像塊,這兩個局部圖像塊就作為一對匹配對;從重建物體表面隨機采樣兩個興趣點(至少相距0.1m),并從隨機挑選的兩個深度幀上選取這兩個興趣點對應的局部3D圖像塊,這兩個局部圖像塊用來作為不匹配對。最后把這些匹配與不匹配的圖像塊轉換成TDF體素網格表示。訓練集樣本總共為16,000,000個,其中正負樣本各為8,000,000。部分RGB-D重建數據集場景如圖2所示。


圖3 網絡結構示意圖
2 改進的網絡結構
根據Lan Goodfellow[15]等,使用池化是一個無限強的先驗,即每一個單元都具有少量平移不變性,與任何其他先驗類似,卷積和池化只有當先驗的假設合理且正確時才有用,如果一項任務依賴于保存精確的空間信息,那么在所有特征上使用池化將會增大訓練誤差,受到Szegedy[16]等的卷積網絡結構啟發,為了保證當平移不變性不合理時不會導致欠擬合的特征,而且由于初始輸入的TDF體素網格維度比較小,為了防止子采樣造成關鍵信息損失,本文對3DMatch的網絡結構進行修改,設計成在通道上不使用池化;此外受到微軟ResNet[13]具有152層網絡的的啟發,在訓練集樣本足夠多的情況下,更深的卷積網絡結構往往能取得更好的訓練效果,因此本文也適當的加深了網絡結構的深度,由原來的8個卷積層(每一個都有線性修正單元激活函數進行非線性化)增加到12個卷積層,在最后的卷積層輸出一個512維的特征表示向量,該特征表示向量作為一個特征描述子。其中網絡結構如圖3所示,卷積層表示為(kernel size,number of filters)。
網絡的訓練參數設置如下:
3 實驗結果與分析
3.1 關鍵點匹配測試
通過測試三維局部描述子在區分關鍵點的局部三維圖像塊匹配與不匹配的能力可以衡量三維局部描述子的性能。測試采用了3DMatch使用的基準,該測試基準包含30,000個3D圖像塊,其中匹配與不匹配的正負樣本數量比為1:1。評估結果是在95%召回率的條件下的錯誤率,結果越低說明效果越好。實驗主要與 Spin-Images、FPFH、2D ConvNet on Depth、3DMatch描述子在基準上進行比較。其中Spin-Images、FPFH描述子使用PCL[14](Point Cloud Library)提供的代碼實現進行測試。比較結果如表1所示。


表1 關鍵點匹配測試錯誤率(在95%召回率的情況下)
3.2 實驗分析
本文通過對3DMatch卷積網絡結構的優化與改進,獲得了更好的訓練效果。通過訓練可以的到一個優秀的局部體積塊描述子,該描述子對噪聲、新場景的變化具有魯棒性,可以獲得了良好的關鍵點匹配效果。此外實驗也存在著許多不足之處,如在顯卡上進行訓練時占用顯存大,訓練速度比較慢等,這些都有待進一步對實驗進行優化改進,如采用新的數據表示方法以及新型網絡結構等。
4 結語
深度學習是一種有效且方便的新方法,而且效果會隨著更多的數據集樣本、新型的更深的神經網絡結構出現獲得進一步的提升。在大數據的支持下,相信深度學習以后將在場景重建、形狀匹配等領域得到廣泛的使用。
參考文獻:
[1]Simonyan K,Vedaldi A,Zisserman A.Learning Local Feature Descriptors Using Convex Optimisation[M].IEEE Computer Society,2014.
[2]Johnson A E,Hebert M.Using Spin Images for Efficient Object Recognition in Cluttered 3D Scenes[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2002,21(5):433-449.
[3]Frome A,Huber D,Kolluri R,et al.Recognizing Objects in Range Data Using Regional Point Descriptors[J].Lecture Notes in Computer Science,2004,3023:224-237.
[4]Rusu R B,Blodow N,Marton Z C,et al.Aligning Point Cloud Views Using Persistent Feature Histograms[C].Ieee/rsj International Conference on Intelligent Robots and Systems.IEEE,2013:3384-3391.
[5]Rusu R B,Holzbach A,Blodow N,et al.Fast Geometric Point Labeling Using Conditional Random Fields[C].Ieee/rsj International Conference on Intelligent Robots and Systems.IEEE,2009:7-12.
[6]Guo Y,Sohel F,Bennamoun M,et al.Rotational Projection Statistics for 3D Local Surface Description and Object Recognition[J].International Journal of Computer Vision,2013,105(1):63-86.
[7]Salti S,Tombari F,Stefano L D.SHOT:Unique Signatures of Histograms for Surface and Texture Description☆[J].Computer Vision&Image Understanding,2014,125(8):251-264.
[8]Wu Z,Song S,Khosla A,et al.3D ShapeNets:A Deep Representation for Volumetric Shapes[J],2014:1912-1920.
[9]Cirujeda P,Cid Y D,Mateo X,et al.A 3D Scene Registration Method via Covariance Descriptors and an Evolutionary Stable Strategy Game Theory Solver[J].International Journal of Computer Vision,2015,115(3):306-329.
[10]Guo K,Zou D,Chen X.3D Mesh Labeling via Deep Convolutional Neural Networks[J].Acm Transactions on Graphics,2015,35(1):1-12.
[11]Zeng A,Song S,Niebner M,et al.3DMatch:Learning Local Geometric Descriptors from RGB-D Reconstructions[J].2017:199-208.
[12]Curless B,Levoy M.A Volumetric Method for Building Complex Models from Range Images[C].Conference on Computer Graphics and Interactive Techniques.ACM,1996:303-312.
[13]He K,Zhang X,Ren S,et al.Deep Residual Learning for Image Recognition[J],2015:770-778.
[14]http://pointclouds.org/.
[15]Lan Goodfellow等著.深度學習[M].趙申劍,黎彧君等譯.北京:人民郵電出版社,2017.8.
[16]Szegedy C,Liu W,Jia Y,et al.Going Deeper with Convolutions[C].Computer Vision and Pattern Recognition.IEEE,2015:1-9.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
