基于多粒度特征和混合算法的文檔推薦系統(tǒng)①
2018-04-20 01:16:28鄔登峰許舒人
計(jì)算機(jī)系統(tǒng)應(yīng)用 2018年3期
鄔登峰, 白 琳, 王 濤, 李 慧, 許舒人
1(中國(guó)科學(xué)院大學(xué),北京 100049)
2(中國(guó)科學(xué)院 軟件研究所 軟件工程技術(shù)研究開(kāi)發(fā)中心,北京 100190)
3(北京智識(shí)企業(yè)管理咨詢(xún)有限公司,北京 100101)
針對(duì)文庫(kù)系統(tǒng)中文檔數(shù)據(jù)量較大,且數(shù)據(jù)量日趨增多,會(huì)導(dǎo)致大量文檔無(wú)法有效展現(xiàn),用戶難以精準(zhǔn)地獲取到所需文檔,引發(fā)數(shù)據(jù)利用率降低的問(wèn)題. 因此迫切地需要一種機(jī)器輔助功能幫助用戶做一些信息篩選的工作. 傳統(tǒng)的基于文檔分類(lèi)、基于用戶搜索的方法,在文檔數(shù)據(jù)量達(dá)到較大規(guī)模時(shí),篩選能力有限,且無(wú)法為用戶發(fā)掘潛在的可能感興趣的內(nèi)容,可以考慮引入推薦系統(tǒng). 文庫(kù)系統(tǒng)中的推薦,本質(zhì)即是文本內(nèi)容的推薦,因此可以參考新聞推薦領(lǐng)域的方法,如文獻(xiàn)[1]中的協(xié)同過(guò)濾的推薦方法,通過(guò)計(jì)算用戶行為的相似度,為目標(biāo)用戶生成推薦列表,但是協(xié)同過(guò)濾方法的冷啟動(dòng)問(wèn)題較為嚴(yán)重. 文獻(xiàn)[2]中的基于內(nèi)容的推薦方法,通過(guò)匹配用戶興趣與文本特征的相似度從而產(chǎn)生推薦結(jié)果,但是這種方法只能為用戶推薦與其歷史興趣相似的內(nèi)容,因此在新穎度上存在不足,無(wú)法發(fā)掘用戶潛在興趣.此外,文檔推薦系統(tǒng)的一個(gè)重要基礎(chǔ)是精準(zhǔn)的用戶興趣及文檔特征模型,業(yè)界一般基于文本內(nèi)容抽取特征詞語(yǔ)后采用空間向量模型來(lái)表示,但是直接采用詞語(yǔ)特征向量模型來(lái)計(jì)算,存在著向量維度過(guò)高、數(shù)據(jù)稀疏的問(wèn)題.
針對(duì)上述問(wèn)題,本文提出了一種基于多粒度特征和混合算法的文檔推薦系統(tǒng),系統(tǒng)綜合了用戶的顯式反饋和隱式反饋為用戶興趣建模,且在用戶興趣模型和文檔特征模型中分別設(shè)計(jì)了詞語(yǔ)和短語(yǔ)兩個(gè)粒度,這種建模方法既保證了模型的精準(zhǔn)度,也避免了模型的過(guò)擬合問(wèn)題. 系統(tǒng)還綜合了時(shí)間窗口法和遺忘函數(shù)法動(dòng)態(tài)更新用戶興趣模型,確保模型的精準(zhǔn)可靠. 在推薦方法上,系統(tǒng)采用了基于內(nèi)容推薦和協(xié)同過(guò)濾推薦相結(jié)合的混合推薦方法,彌補(bǔ)了單一算法的不足.
1 相關(guān)技術(shù)
1.1 用戶興趣建模
推薦系統(tǒng)為用戶提供個(gè)性化服務(wù)的過(guò)程中,服務(wù)質(zhì)量高度依賴(lài)于系統(tǒng)掌握的用戶興趣的準(zhǔn)確程度,因此確定用戶興趣模型并針對(duì)用戶興趣的變化及時(shí)更新模型也是提高推薦系統(tǒng)服務(wù)質(zhì)量的一個(gè)重要方面.
基于向量空間模型的方法是業(yè)界常用的方法,該方法通過(guò)抽取所采集用戶興趣數(shù)據(jù)的特征項(xiàng)并計(jì)算相應(yīng)權(quán)值構(gòu)成表示用戶興趣模型的向量[3]. 這種方法在一定程度上能夠準(zhǔn)確刻畫(huà)用戶興趣,且簡(jiǎn)單易實(shí)現(xiàn),但也存在著一些問(wèn)題,如某些標(biāo)簽缺乏語(yǔ)義明確性,無(wú)法體現(xiàn)用戶個(gè)性化的興趣偏好,且此方法中興趣標(biāo)簽是離散的,在大型應(yīng)用系統(tǒng)中可能存在著數(shù)據(jù)稀疏的問(wèn)題.
此外,區(qū)別于文檔特征模型一次建立始終有效的特點(diǎn),用戶興趣模型還面臨著動(dòng)態(tài)漂移的問(wèn)題,針對(duì)該問(wèn)題的主流解決方案有時(shí)間窗口法和遺忘函數(shù)法. 時(shí)間窗口法[4]認(rèn)為用戶只對(duì)最近訪問(wèn)的概念感興趣,利用滑動(dòng)時(shí)間窗濾除過(guò)時(shí)的興趣,時(shí)間窗口法簡(jiǎn)單易實(shí)現(xiàn),且能兼顧用戶興趣的累計(jì)計(jì)算以及歷史興趣的淘汰策略,但是其應(yīng)用效果非常依賴(lài)于時(shí)間窗口大小的取值,而且存在用戶興趣突變的問(wèn)題. 遺忘函數(shù)法[5]假設(shè)用戶興趣的變遷是一種漸進(jìn)的過(guò)程,即用戶興趣隨著時(shí)間的流逝逐漸減弱,遺忘的速度是先快后慢,對(duì)于用戶長(zhǎng)時(shí)間沒(méi)有更新的特征,認(rèn)為其不能再代表用戶的當(dāng)前興趣,可以通過(guò)遺忘函數(shù)讓其不斷“衰老”來(lái)達(dá)到過(guò)濾的目的[6],如Maloof和Michalski等采用了一種遺忘函數(shù)處理用戶興趣特征[7]. 遺忘函數(shù)法符合人類(lèi)記憶衰減特性,但是該方法需要輔助設(shè)計(jì)淘汰策略,用以淘汰無(wú)效特征,避免大量無(wú)效特征積累影響系統(tǒng)效果.
1.2 推薦算法
推薦系統(tǒng)[8,9]是一種重要的信息過(guò)濾機(jī)制,可以有效地解決信息過(guò)載的問(wèn)題. 通過(guò)挖掘用戶和信息之間的關(guān)聯(lián)關(guān)系,從而幫助用戶從大量的信息中獲取到他們可能會(huì)感興趣的內(nèi)容.
推薦算法是整個(gè)推薦系統(tǒng)最核心的部分,在很大程度上決定了推薦效果. 業(yè)界主流算法主要有基于內(nèi)容的推薦(Content-Based Recommendation)、協(xié)同過(guò)濾(Collaborative Filtering)和混合推薦方法(Hybrid Approach)[10]等.
基于內(nèi)容的方法是信息檢索領(lǐng)域的重要研究?jī)?nèi)容,是指通過(guò)比較資源和用戶興趣模型的相似程度向用戶推薦信息的方式,該方法較多的應(yīng)用在可計(jì)算的文本領(lǐng)域,如瀏覽頁(yè)面的推薦、新聞推薦等[11-14],這種推薦方式簡(jiǎn)單有效,不需要領(lǐng)域知識(shí),也有著比較成熟的分類(lèi)學(xué)習(xí)方法能夠?yàn)槠涮峁┲С?如數(shù)據(jù)挖掘、聚類(lèi)分析等,但是也存在著一些缺點(diǎn),如很難推薦較為新穎的結(jié)果,對(duì)新用戶的推薦處理較為困難等. 業(yè)界常用的用于比對(duì)內(nèi)容相似度的算法有: 余弦相似度算法,Jaccard系數(shù)值計(jì)算法等.
協(xié)同過(guò)濾的方法是推薦系統(tǒng)中常用的算法之一,其基本思想是計(jì)算用戶間或項(xiàng)目間的相似度,然后根據(jù)該相似度,預(yù)測(cè)目標(biāo)用戶對(duì)目標(biāo)項(xiàng)目的偏好程度而產(chǎn)生推薦結(jié)果[15,16]. 協(xié)同過(guò)濾算法不需要考慮被推薦項(xiàng)目的具體內(nèi)容[17],可以為用戶提供較為新穎的推薦結(jié)果. 目前,主流的協(xié)同過(guò)濾算法分為兩類(lèi): 基于用戶的協(xié)同過(guò)濾算法[18]和基于項(xiàng)目的協(xié)同過(guò)濾算法[19]. 基于用戶的協(xié)同過(guò)濾算法根據(jù)用戶對(duì)項(xiàng)目的偏好,計(jì)算用戶之間的相似度,找出目標(biāo)用戶的最近鄰居集合,基于近鄰用戶的偏好為目標(biāo)用戶生成推薦集[20,21],該算法能夠有效地利用相似用戶的反饋信息,為目標(biāo)用戶產(chǎn)生推薦集,但是當(dāng)用戶和項(xiàng)目間的關(guān)聯(lián)數(shù)據(jù)較少時(shí),無(wú)法精準(zhǔn)計(jì)算出目標(biāo)用戶的相似用戶群體,此時(shí)的冷啟動(dòng)問(wèn)題較為嚴(yán)重[22,23]. 基于項(xiàng)目的協(xié)同過(guò)濾算法根據(jù)用戶操作過(guò)的項(xiàng)目,對(duì)項(xiàng)目之間的相似度進(jìn)行預(yù)測(cè),這在一定程度上減少了冷啟動(dòng)問(wèn)題對(duì)推薦系統(tǒng)質(zhì)量的影響,但是這種方法生成的推薦集覆蓋率低,且無(wú)法為用戶提供較為新穎的推薦[24].
2 系統(tǒng)關(guān)鍵技術(shù)
2.1 多粒度用戶興趣及文檔特征
針對(duì)傳統(tǒng)方法中用戶興趣及文檔特征建模時(shí)存在的問(wèn)題. 本系統(tǒng)中,基于空間向量模型做了進(jìn)一步的優(yōu)化,精細(xì)劃分特征模型,將用戶興趣及文檔特征模型分為短語(yǔ)和詞語(yǔ)兩個(gè)粒度. 短語(yǔ)粒度上采用了空間向量模型來(lái)刻畫(huà)用戶及文檔的特征,計(jì)算用戶興趣或文檔中涉及到某特征標(biāo)簽的次數(shù)來(lái)刻畫(huà)模型,次數(shù)越多則表明該用戶或文檔與該主題的相關(guān)度越高,最終以帶有權(quán)重值的特征標(biāo)簽向量對(duì)用戶興趣及文檔特征建模,這種方法簡(jiǎn)便易實(shí)現(xiàn),但在應(yīng)用到文檔推薦系統(tǒng)中時(shí),也存在一些缺點(diǎn),由于特征短語(yǔ)來(lái)源于海量文檔內(nèi)容,短語(yǔ)分布離散,過(guò)于稀疏,無(wú)法有效地進(jìn)行相似度匹配計(jì)算,因此,在本系統(tǒng)中設(shè)計(jì)了詞語(yǔ)粒度上的特征,相較于短語(yǔ)粒度的空間向量模型而言,改善了特征標(biāo)簽稀疏的問(wèn)題,也提高了系統(tǒng)的覆蓋率. 為建立上述兩個(gè)粒度的特征模型,在實(shí)現(xiàn)中,需要首先從文本數(shù)據(jù)中提取出能夠代表文本特征的關(guān)鍵短語(yǔ)以及關(guān)鍵詞語(yǔ),本文基于開(kāi)源中文處理項(xiàng)目HanLP提供的API (Application Programming Interface)來(lái)實(shí)現(xiàn),HanLP提供了標(biāo)準(zhǔn)分詞、NLP分詞、索引分詞、最短路徑分詞、詞典分詞等多種分詞方式,在關(guān)鍵短語(yǔ)提取方面提供了基于互信息和左右信息熵的短語(yǔ)提取識(shí)別解決方案,在工程實(shí)現(xiàn)時(shí),直接調(diào)用相關(guān)接口即可,簡(jiǎn)單易實(shí)現(xiàn).
對(duì)用戶興趣建模時(shí),為確保用戶興趣模型的精準(zhǔn)可靠,系統(tǒng)綜合了多項(xiàng)數(shù)據(jù)來(lái)源分析用戶的興趣特征,包括用戶的顯式反饋和隱式反饋,本文中用戶顯式反饋指用戶在瀏覽文檔時(shí)點(diǎn)擊“喜歡”或“不喜歡”按鈕,顯式表達(dá)偏好的行為,這種通過(guò)顯式反饋得到的用戶興趣是比較準(zhǔn)確客觀的,但是也存在靈活性差,對(duì)用戶工作侵入性強(qiáng)等缺點(diǎn). 用戶隱式反饋是指用戶使用文庫(kù)系統(tǒng)時(shí),系統(tǒng)后臺(tái)記錄的用戶日志,這種隱式反饋對(duì)用戶是透明的,不會(huì)干擾用戶的正常工作,但是基于隱式反饋得到的用戶興趣準(zhǔn)確性不夠高,存在一定的偏差.因此,本文中將用戶顯式反饋與隱式反饋相結(jié)合,以達(dá)到更好的用戶興趣建模效果.
系統(tǒng)基于用戶的每條顯式反饋日志、搜索日志、瀏覽日志及下載日志,分析該操作關(guān)聯(lián)的文檔標(biāo)題,從中提取出關(guān)鍵短語(yǔ)、關(guān)鍵詞語(yǔ),得到刻畫(huà)用戶興趣的特征短語(yǔ)空間向量及特征詞語(yǔ)列表[25],綜合所有日志數(shù)據(jù),做累加操作,得到最終的用戶興趣模型及其評(píng)分值. 系統(tǒng)在累加的時(shí)候?qū)Σ煌瑏?lái)源設(shè)置了不同的權(quán)重值,權(quán)重值是基于對(duì)業(yè)務(wù)系統(tǒng)的分析及實(shí)際使用中數(shù)據(jù)的統(tǒng)計(jì)學(xué)習(xí)得到的. 用戶興趣特征短語(yǔ)權(quán)重評(píng)分計(jì)算公式如下:
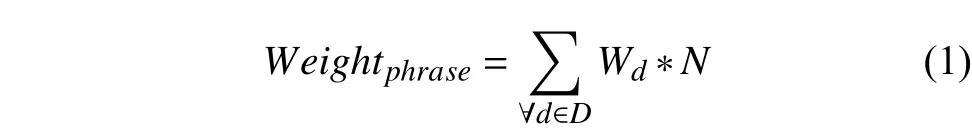
式中,D表示所有不同來(lái)源的集合,Wd表示各個(gè)不同來(lái)源預(yù)設(shè)的權(quán)重值,N表示該短語(yǔ)出現(xiàn)的頻次.
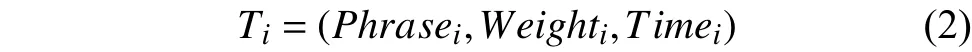
最終,由這些特征短語(yǔ)及其權(quán)重評(píng)分值、操作日期構(gòu)成用戶興趣特征Ti,公式如下:式中,Phrasei表示特征短語(yǔ),Weighti表示權(quán)重評(píng)分值,Timei表示操作日期.
用戶的興趣模型由若干個(gè)獨(dú)立的興趣特征組成,公式如下:
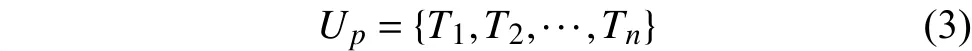
此即為短語(yǔ)粒度上的用戶興趣特征空間向量.
最后,系統(tǒng)將短語(yǔ)粒度上的用戶興趣特征空間向量作為中間結(jié)果保存到數(shù)據(jù)庫(kù)中,以備后續(xù)計(jì)算使用.
詞語(yǔ)粒度上,用戶興趣模型由關(guān)鍵詞語(yǔ)列表組成,公式如下:
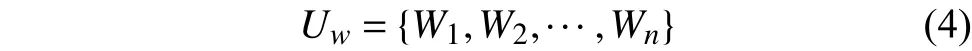
式中,Wi表示用戶興趣特征詞列表中的單個(gè)關(guān)鍵詞語(yǔ).
詞語(yǔ)粒度的用戶興趣特征,是基于短語(yǔ)興趣特征計(jì)算而來(lái)的,對(duì)短語(yǔ)特征取出全部的Phrase數(shù)據(jù),進(jìn)行分詞處理,去重后得到一個(gè)詞語(yǔ)列表,即為詞語(yǔ)粒度的用戶興趣特征,本文中調(diào)用了HanLP提供的標(biāo)準(zhǔn)分詞接口實(shí)現(xiàn).
文檔特征的建模,類(lèi)似于用戶興趣建模,分別處理文檔路徑、文檔標(biāo)題、文檔摘要以及附件內(nèi)容,結(jié)合不同來(lái)源的權(quán)重值對(duì)多個(gè)關(guān)鍵短語(yǔ)列表進(jìn)行累加合并,得到短語(yǔ)粒度的文檔特征模型,其中文檔路徑為目標(biāo)文檔的分級(jí)路徑,包含了其分類(lèi)信息. 對(duì)合并后的特征短語(yǔ)空間向量做進(jìn)一步的分詞、去重處理,即得到詞語(yǔ)粒度的文檔特征.
針對(duì)用戶興趣動(dòng)態(tài)漂移的問(wèn)題,系統(tǒng)中綜合滑動(dòng)窗口法和遺忘函數(shù)法更新用戶興趣模型,既能將用戶無(wú)效興趣特征淘汰,也能動(dòng)態(tài)更新用戶有效興趣特征的權(quán)重值,這是符合自然狀態(tài)下人類(lèi)興趣漂移狀態(tài)的.
時(shí)間窗口法,基于對(duì)實(shí)際業(yè)務(wù)系統(tǒng)運(yùn)行數(shù)據(jù)的統(tǒng)計(jì)分析,設(shè)置時(shí)間窗口大小K=15,單位是: 日. 即對(duì)最近K日內(nèi)用戶興趣進(jìn)行累積計(jì)算. 具體計(jì)算過(guò)程如下:系統(tǒng)初始化時(shí),分析近K日內(nèi)所有日志數(shù)據(jù),得到用戶的初始興趣模型. 后續(xù)每日更新的時(shí)候,則分析當(dāng)日活躍用戶日志數(shù)據(jù),進(jìn)行如下操作:
(1) 將新出現(xiàn)的特征短語(yǔ)加入用戶興趣特征池中;
(2) 將當(dāng)日涉及到的,而用戶興趣特征池中已有的興趣特征短語(yǔ)的時(shí)間戳更新為當(dāng)前日期,權(quán)重值更新為舊權(quán)重值與當(dāng)日權(quán)重值之和;
(3) 將時(shí)間戳超出K日窗口大小的興趣特征淘汰,這樣即可保證用戶興趣特征池中所有興趣特征都是在K日窗口內(nèi)的數(shù)據(jù).
遺忘函數(shù)法,對(duì)時(shí)間窗口法維護(hù)的特征池中每個(gè)特征短語(yǔ)的權(quán)重值進(jìn)行衰減,計(jì)算公式如下:
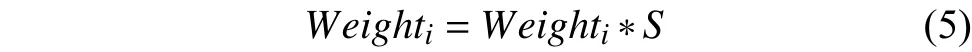
其中S為遺忘因子,由參考文獻(xiàn)[6]中提到的方法確定.
2.2 混合推薦算法
通過(guò)相關(guān)技術(shù)一節(jié)的分析可以發(fā)現(xiàn),基于內(nèi)容推薦算法和協(xié)同過(guò)濾算法分別有擅長(zhǎng)的領(lǐng)域及適用性較差的領(lǐng)域,因此,在本系統(tǒng)中,綜合了兩種算法形成一個(gè)混合的推薦系統(tǒng),這樣既可以發(fā)揮各自的優(yōu)點(diǎn),也能彌補(bǔ)單一算法的不足[26].
由于協(xié)同過(guò)濾算法分為基于用戶的協(xié)同過(guò)濾和基于項(xiàng)目的協(xié)同過(guò)濾兩種,考慮本系統(tǒng)的應(yīng)用場(chǎng)景中與用戶對(duì)個(gè)人興趣傳承的需求相比,更需要關(guān)注相同興趣群體中的熱點(diǎn)事件,因此,采用了基于用戶的協(xié)同過(guò)濾算法,且從計(jì)算量和存儲(chǔ)需求考慮,本系統(tǒng)中用戶數(shù)量遠(yuǎn)遠(yuǎn)少于文檔數(shù)量,采用基于用戶的協(xié)同過(guò)濾算法也是較為合適的.
系統(tǒng)中的基于協(xié)同過(guò)濾算法,首先計(jì)算目標(biāo)用戶的相似用戶群,將相似用戶群中用戶感興趣的文檔推薦給目標(biāo)用戶,在這個(gè)過(guò)程中需要和目標(biāo)用戶的歷史數(shù)據(jù)比對(duì),過(guò)濾已操作過(guò)的文檔,避免重復(fù)推薦,算法的流程圖如圖1所示.
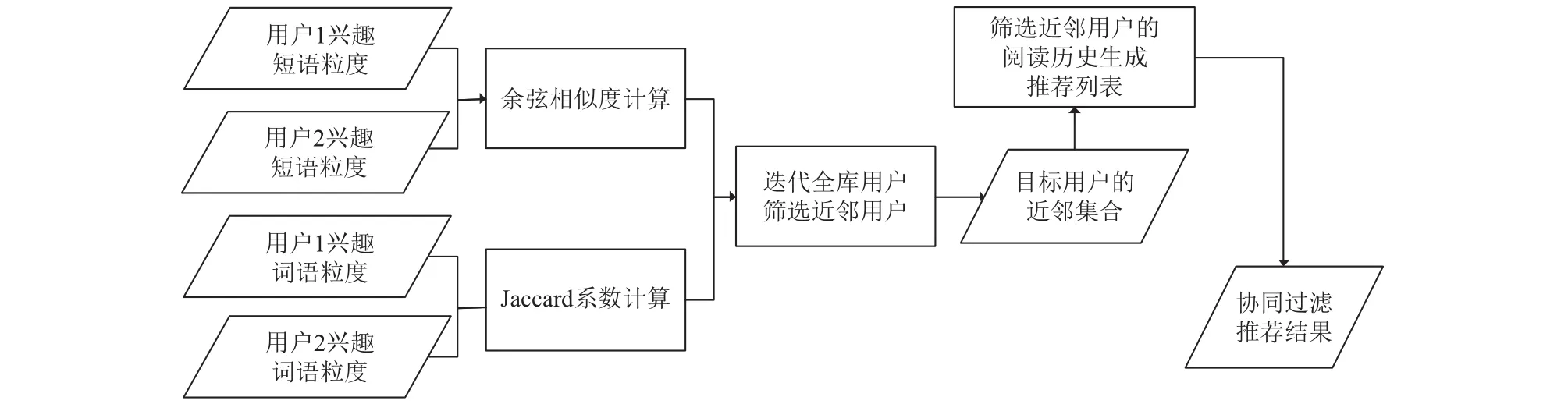
圖1 協(xié)同過(guò)濾推薦模塊流程圖
首先,基于用戶興趣模型計(jì)算用戶之間的相似度,確定目標(biāo)用戶的相似用戶群,這里分別處理短語(yǔ)和詞語(yǔ)兩個(gè)粒度上的特征.
短語(yǔ)粒度上,采用余弦相似度的算法來(lái)計(jì)算兩個(gè)不同用戶之間的相似度,即取出兩個(gè)用戶的短語(yǔ)特征向量,計(jì)算兩者的余弦?jiàn)A角值,公式如下:
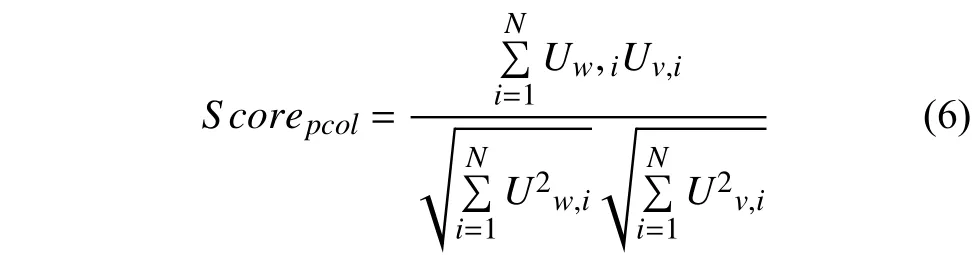
式中Uw,Uv分別表示兩個(gè)不同用戶的短語(yǔ)粒度上的興趣特征向量.
詞語(yǔ)粒度上,采用Jaccard系數(shù)值來(lái)計(jì)算用戶間的相似度,Jaccard系數(shù)是兩個(gè)集合交集與并集的元素?cái)?shù)目之比,用于測(cè)量?jī)蓚€(gè)集合在共同項(xiàng)目上的重疊度. 其匹配兩個(gè)對(duì)象之間的相似度時(shí),僅關(guān)注特征是否存在,而不關(guān)注該特征的權(quán)重值. 此處,在兩個(gè)不同用戶的特征詞語(yǔ)集合之間進(jìn)行計(jì)算,公式如下:式中N(w),N(v)分別表示兩個(gè)不同用戶的特征詞語(yǔ)集合.

經(jīng)過(guò)短語(yǔ)、詞語(yǔ)兩個(gè)粒度上的相似度計(jì)算,系統(tǒng)分別得到了Scorepcol,Scorewcol兩個(gè)值,將二者相加作為最終的用戶間相似度,公式如下:
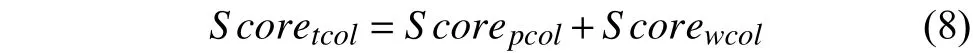
算法中將目標(biāo)用戶興趣模型分別與其他用戶的興趣模型進(jìn)行匹配計(jì)算,按照相似度數(shù)值排序,取前M個(gè)用戶作為最近鄰居集合. 這里M值可以結(jié)合業(yè)務(wù)系統(tǒng)實(shí)驗(yàn)確定. 最后,從這M個(gè)近鄰用戶的歷史記錄中取若干篇文檔作為協(xié)同過(guò)濾算法的推薦結(jié)果,選取算法如下.
以選取T篇文檔為例,系統(tǒng)在配置文件中設(shè)置近鄰個(gè)數(shù)為M個(gè),因此我們從每個(gè)近鄰用戶的閱讀歷史中取篇文檔進(jìn)行推送,此處我們按照時(shí)間順序由最近操作的文檔開(kāi)始向前取,同時(shí)在取文檔的時(shí)候需要與目標(biāo)用戶的閱讀歷史列表進(jìn)行比對(duì),過(guò)濾掉目標(biāo)用戶已經(jīng)操作過(guò)的文檔,避免重復(fù)推薦.
基于內(nèi)容的推薦算法,直接匹配用戶興趣模型和文檔特征模型的相似度,為目標(biāo)用戶生成推薦列表,計(jì)算內(nèi)容相似度的算法流程圖如圖2所示.
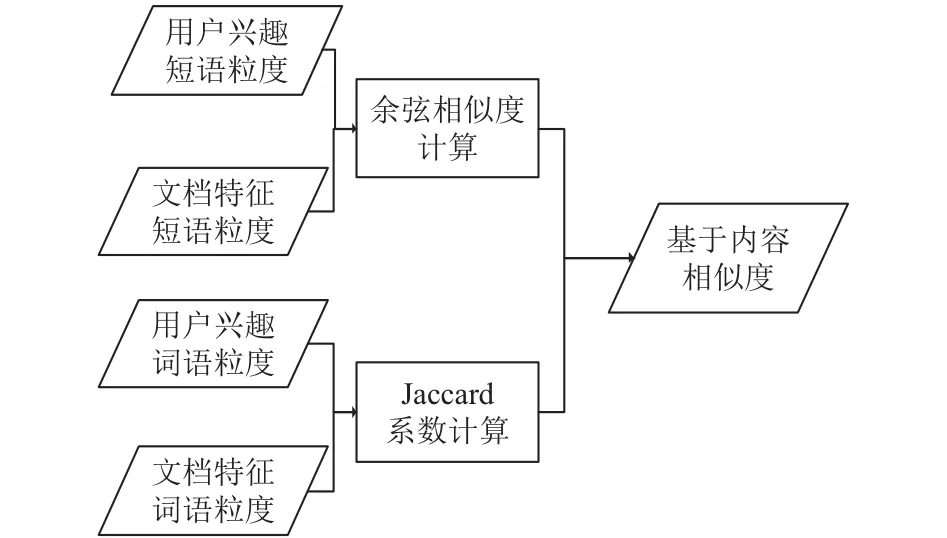
圖2 基于內(nèi)容推薦模塊流程圖
與協(xié)同過(guò)濾部分類(lèi)似,這里分別處理短語(yǔ)和詞語(yǔ)兩個(gè)粒度上的特征.
短語(yǔ)粒度上,基于余弦相似度算法,計(jì)算短語(yǔ)粒度上用戶興趣和文檔特征兩個(gè)特征向量之間的余弦?jiàn)A角值作為二者相似度的度量,公式如下:
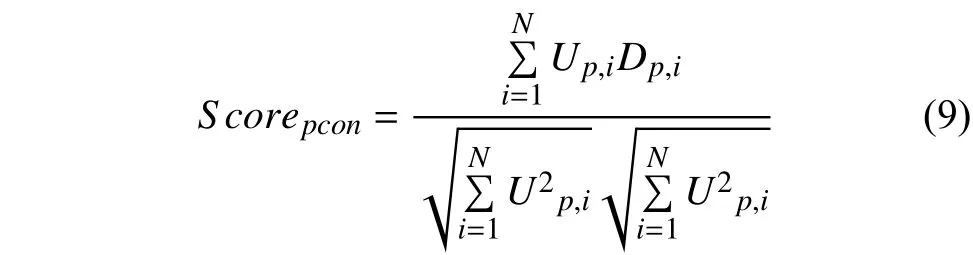
式中,Up表示短語(yǔ)粒度上的用戶興趣特征向量,Dp表示短語(yǔ)粒度上的文檔特征向量.
詞語(yǔ)粒度上,基于Jaccard系數(shù)值計(jì)算用戶與文檔的相似度,公式如下:

式中,N(U)表示用戶特征詞語(yǔ)集合,N(D)表示文檔特征詞語(yǔ)集合.
經(jīng)過(guò)短語(yǔ)、詞語(yǔ)兩個(gè)粒度上用戶和文檔的相似度計(jì)算,系統(tǒng)分別得到了Scorepcon和Scorewcon,將二者相加作為最終的基于內(nèi)容相似度匹配值,公式如下:
算法中將目標(biāo)用戶的興趣模型分別與推薦庫(kù)中的每一篇文檔特征進(jìn)行匹配計(jì)算,基于相似度值Scoretcon排序,取前Z篇文檔作為基于內(nèi)容推薦的結(jié)果. 這里的Z值可以結(jié)合業(yè)務(wù)系統(tǒng)進(jìn)行實(shí)驗(yàn)確定.
由于最終給用戶展示的推薦列表只有一個(gè),因此需要對(duì)基于內(nèi)容推薦和協(xié)同過(guò)濾推薦的結(jié)果融合,系統(tǒng)中采用了預(yù)留推薦位的方法,設(shè)最終的推薦列表中包含A篇文檔,融合策略中,將前B個(gè)推薦位預(yù)留給基于內(nèi)容推薦,后(A-B)個(gè)推薦位預(yù)留給協(xié)同過(guò)濾推薦,這里A、B值在系統(tǒng)實(shí)現(xiàn)時(shí)均設(shè)在配置文件中,可根據(jù)系統(tǒng)運(yùn)行數(shù)據(jù)修改A、B值,調(diào)整兩種推薦算法的權(quán)重,優(yōu)化系統(tǒng)推薦效果. 此外,對(duì)新注冊(cè)用戶處理時(shí),由于缺乏基礎(chǔ)數(shù)據(jù),無(wú)法確定該用戶的興趣模型,因此無(wú)法使用基于內(nèi)容推薦和協(xié)同過(guò)濾算法為該用戶生成推薦列表,針對(duì)這樣的冷啟動(dòng)問(wèn)題,系統(tǒng)中設(shè)置了獨(dú)立的冷啟動(dòng)策略,基于同部門(mén)用戶的下載熱度給新用戶推送其可能感興趣的文檔,即將該用戶的同部門(mén)用戶下載過(guò)的文檔按照下載頻度排序,推薦前列的A篇文檔.
3 系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
本系統(tǒng)為服務(wù)端程序,以文庫(kù)系統(tǒng)中的文檔作為推薦庫(kù). 首先計(jì)算出文檔特征、用戶興趣模型,再基于混合推薦算法,生成推薦結(jié)果,返回給文庫(kù)系統(tǒng),由文庫(kù)系統(tǒng)向用戶展現(xiàn). 本著高效、低耦合、分層、模塊化的原則,將系統(tǒng)劃分為5個(gè)模塊,包括: 用戶興趣特征提取模塊、文檔特征提取模塊、基于內(nèi)容推薦模塊、協(xié)同過(guò)濾推薦模塊和推薦結(jié)果融合模塊. 組織結(jié)構(gòu)如圖3所示.

圖3 基于多粒度特征和混合算法的文檔推薦系統(tǒng)結(jié)構(gòu)圖
系統(tǒng)通過(guò)調(diào)用文庫(kù)系統(tǒng)提供的API獲得文檔數(shù)據(jù)、用戶數(shù)據(jù)、日志數(shù)據(jù)等,這些數(shù)據(jù)都由文庫(kù)系統(tǒng)維護(hù),文庫(kù)系統(tǒng)通過(guò)瀏覽器與用戶交互. 基于HanLP提供的API進(jìn)行分詞、關(guān)鍵短語(yǔ)提取、關(guān)鍵詞語(yǔ)提取.綜合對(duì)文檔數(shù)據(jù)、用戶數(shù)據(jù)、日志數(shù)據(jù)的分析,為文檔特征、用戶興趣建模. 從而進(jìn)行基于內(nèi)容的推薦、協(xié)同過(guò)濾推薦并將推薦結(jié)果融合. 推薦結(jié)果會(huì)再次通過(guò)文庫(kù)系統(tǒng)提供的API存回?cái)?shù)據(jù)庫(kù)中,供文庫(kù)系統(tǒng)使用. 本系統(tǒng)也提供若干API供文庫(kù)系統(tǒng)二次開(kāi)發(fā)使用.
3.1 文檔特征提取模塊
本模塊中實(shí)現(xiàn)了文檔特征建模的算法,分析文檔的主要信息,包括文檔路徑、文檔標(biāo)題、文檔摘要、附件內(nèi)容等,基于HanLP提供的API進(jìn)行分詞,提取關(guān)鍵短語(yǔ)、關(guān)鍵詞語(yǔ),建立文檔的特征模型,模塊的類(lèi)圖如圖4所示.
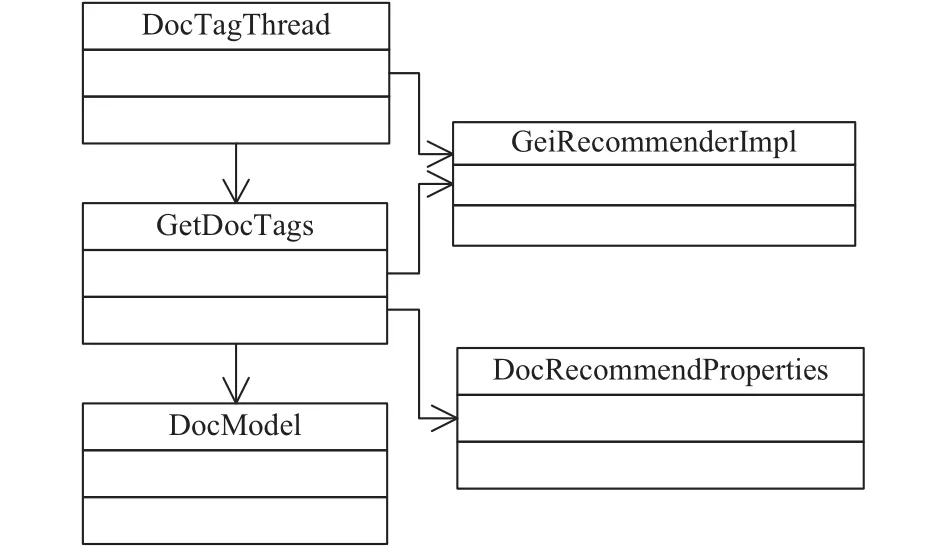
圖4 文檔特征提取模塊類(lèi)圖
為提升計(jì)算效率,模塊實(shí)現(xiàn)時(shí)采用了多線程的解決方案. 其中,DocTagThread為文檔特征提取的線程,通過(guò)調(diào)用GetDocTags類(lèi)中提供的方法,分別從文檔路徑、文檔標(biāo)題、文檔摘要、附件內(nèi)容中獲取到文檔特征,這些文檔數(shù)據(jù)則通過(guò)GeiRecommendImpl類(lèi)中提供的API從文庫(kù)系統(tǒng)中獲取. 系統(tǒng)計(jì)算得到的文檔特征也會(huì)通過(guò)GeiRecommendImpl類(lèi)中提供的API存回?cái)?shù)據(jù)庫(kù)中. DocModel類(lèi)中定義了文檔特征模型的數(shù)據(jù)結(jié)構(gòu). DocRecommendProperties為加載配置文件的類(lèi).
3.2 用戶興趣特征提取模塊
本模塊中實(shí)現(xiàn)了用戶興趣建模的算法,分析用戶操作日志數(shù)據(jù),經(jīng)過(guò)分類(lèi)計(jì)算后,融合得到用戶的興趣模型. 由于用戶興趣漂移現(xiàn)象的存在,在系統(tǒng)日常運(yùn)營(yíng)時(shí),此模塊還負(fù)責(zé)對(duì)用戶興趣模型進(jìn)行更新,模塊的類(lèi)圖如圖5所示.
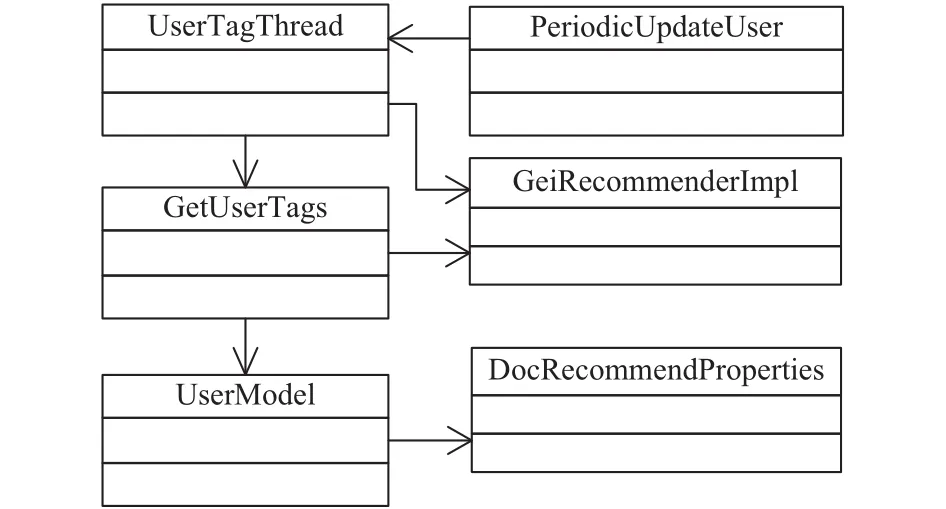
圖5 用戶興趣特征提取模塊類(lèi)圖
為提升計(jì)算效率,模塊實(shí)現(xiàn)時(shí)采用了多線程的解決方案. 其中,UserTagThread為用戶特征提取的線程,通過(guò)調(diào)用GetUserTags類(lèi)中提供的方法,分別從用戶顯式反饋、用戶搜索日志、下載日志、瀏覽日志中提取用戶的興趣特征,這些日志數(shù)據(jù)則通過(guò)GeiRecommendImpl類(lèi)中提供的API從文庫(kù)系統(tǒng)中獲取. 系統(tǒng)計(jì)算得到的用戶興趣特征也會(huì)通過(guò)GeiRecommendImpl類(lèi)中提供的API存回?cái)?shù)據(jù)庫(kù)中. PeriodicUpdateUser類(lèi)中提供了創(chuàng)建線程定時(shí)更新用戶興趣模型及推薦列表的方法.UserModel類(lèi)中的屬性及方法定義了用戶興趣模型的數(shù)據(jù)結(jié)構(gòu).
由于累積K日窗口內(nèi)的興趣特征數(shù)量比較龐大,且大量特征短語(yǔ)權(quán)重評(píng)分值較低,使用這些特征進(jìn)行相似度計(jì)算對(duì)整個(gè)推薦系統(tǒng)的效果提升并不是很明顯,卻會(huì)增加系統(tǒng)的計(jì)算量,降低系統(tǒng)效率. 因此,系統(tǒng)中采用了以下優(yōu)化策略,選取其中權(quán)重值前10的特征短語(yǔ)組成用戶短語(yǔ)粒度的興趣特征向量,而詞語(yǔ)粒度的詞語(yǔ)集合則由這10個(gè)特征短語(yǔ)經(jīng)過(guò)分詞生成. 用這樣的短語(yǔ)特征向量和詞語(yǔ)列表來(lái)計(jì)算相似度,既能保證較好的推薦效果,也降低了系統(tǒng)計(jì)算量,這里的數(shù)值10設(shè)置在配置文件中,可以根據(jù)系統(tǒng)運(yùn)行效果優(yōu)化調(diào)整.
基于實(shí)際業(yè)務(wù)需求考慮,系統(tǒng)中對(duì)用戶興趣模型及推薦列表的更新都是采用的每日更新策略,即夜間系統(tǒng)低負(fù)載時(shí),對(duì)當(dāng)日活躍用戶更新興趣特征模型和推薦列表.
3.3 推薦模塊
推薦模塊基于已建立的用戶興趣模型及文檔特征模型,使用基于內(nèi)容推薦和協(xié)同過(guò)濾推薦結(jié)合的混合推薦算法為目標(biāo)用戶生成個(gè)性化文檔推薦列表. 由于最終在文庫(kù)系統(tǒng)中展現(xiàn)給用戶的推薦列表只有一個(gè),因此還需要對(duì)推薦列表進(jìn)行融合.
3.3.1 基于內(nèi)容推薦模塊
本模塊中實(shí)現(xiàn)了基于內(nèi)容推薦算法,對(duì)用戶興趣模型和文檔特征模型進(jìn)行相似度匹配,依據(jù)相似度數(shù)值從高到低進(jìn)行篩選,為目標(biāo)用戶生成推薦列表,模塊的類(lèi)圖如圖6所示.
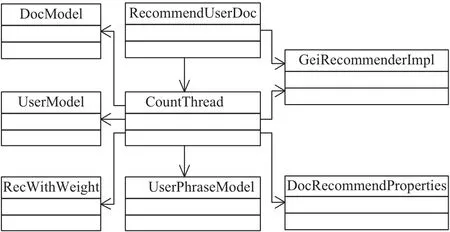
圖6 基于內(nèi)容推薦模塊類(lèi)圖
圖6中,RecommendUserDoc類(lèi)創(chuàng)建了基于內(nèi)容推薦計(jì)算線程CountThread,在該計(jì)算線程中進(jìn)行相似度計(jì)算,線程數(shù)可以由配置文件類(lèi)DocRecommend-Properties根據(jù)配置文件設(shè)定,CountThread計(jì)算線程中實(shí)現(xiàn)了余弦相似度算法與Jaccard系數(shù)算法,進(jìn)行詞語(yǔ)、短語(yǔ)兩個(gè)粒度上用戶間相似度的計(jì)算,其調(diào)用了GeiRecommenderImpl中提供的API獲取存在數(shù)據(jù)庫(kù)中的用戶興趣模型和文檔特征模型數(shù)據(jù),最終的輸出結(jié)果是包含文檔ID及相似度評(píng)分值的推薦列表. 基于內(nèi)容推薦結(jié)果會(huì)作為中間結(jié)果,通過(guò)GeiRecommenderImpl類(lèi)提供的API存回?cái)?shù)據(jù)庫(kù)中. RecWithWeight類(lèi)中定義了基于內(nèi)容推薦列表的數(shù)據(jù)結(jié)構(gòu),包括文檔ID和權(quán)重.
3.3.2 協(xié)同過(guò)濾推薦模塊
本模塊中實(shí)現(xiàn)了基于用戶的協(xié)同過(guò)濾推薦算法,對(duì)不同用戶的興趣模型進(jìn)行相似度匹配,按匹配分值從高到低順序,計(jì)算出目標(biāo)用戶的相似用戶群,根據(jù)該相似用戶群中用戶偏好的文檔為目標(biāo)用戶生成推薦列表,模塊的類(lèi)圖如圖7所示.
圖7中,CollaborativeFiltering類(lèi)關(guān)聯(lián)其他類(lèi),創(chuàng)建多線程進(jìn)行相似度計(jì)算. Evaluator類(lèi)中實(shí)現(xiàn)了余弦相似度算法以及Jaccard系數(shù)算法,進(jìn)行詞語(yǔ)、短語(yǔ)兩個(gè)粒度上用戶間相似度的計(jì)算,其調(diào)用了GeiRecommenderImpl類(lèi)提供的API獲取計(jì)算所需的基礎(chǔ)數(shù)據(jù). 協(xié)同過(guò)濾推薦模塊的計(jì)算結(jié)果會(huì)被作為中間結(jié)果通過(guò)GeiRecommenderImpl類(lèi)提供的API存回?cái)?shù)據(jù)庫(kù)中.UserPhraseModel類(lèi)中定義了短語(yǔ)粒度的用戶興趣模型數(shù)據(jù)結(jié)構(gòu).
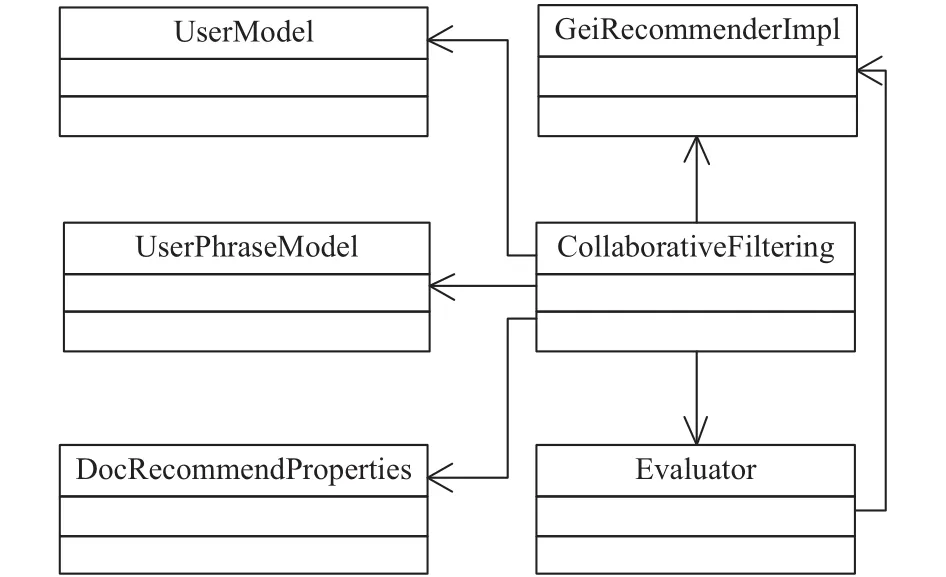
圖7 協(xié)同過(guò)濾推薦模塊類(lèi)圖
3.3.3 推薦結(jié)果融合模塊
本模塊對(duì)基于內(nèi)容推薦結(jié)果及協(xié)同過(guò)濾推薦結(jié)果進(jìn)行融合,并實(shí)現(xiàn)了面向新用戶推薦文檔的冷啟動(dòng)策略,模塊的類(lèi)圖如圖8所示.

圖8 推薦結(jié)果融合模塊類(lèi)圖
圖8中,RecommenderImpl類(lèi)中提供的方法getRecommendDocsByUserId()實(shí)現(xiàn)了融合算法,完成了基于內(nèi)容推薦和協(xié)同過(guò)濾推薦結(jié)果的融合,并實(shí)現(xiàn)了針對(duì)新用戶按照同部門(mén)用戶下載熱度進(jìn)行推薦的策略.GeiRecommenderImpl類(lèi)提供了與文庫(kù)系統(tǒng)交互的API.
4 實(shí)驗(yàn)與結(jié)果分析
本文采用了離線實(shí)驗(yàn)的方法評(píng)測(cè)推薦系統(tǒng)的效果,基于北京市長(zhǎng)城企業(yè)戰(zhàn)略研究所的知識(shí)管理平臺(tái)KRP系統(tǒng)進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)數(shù)據(jù)集中包含了脫密后的300活躍用戶數(shù)據(jù),17萬(wàn)篇文檔數(shù)據(jù),以及10日周期內(nèi)的系統(tǒng)運(yùn)行日志數(shù)據(jù).
實(shí)驗(yàn)中,以活躍用戶的相鄰2個(gè)活躍日為一個(gè)測(cè)試用例. 根據(jù)用戶原有興趣模型結(jié)合首個(gè)活躍日用戶操作確定用戶最新的興趣模型,以此為用戶生成推薦列表. 將用戶第二個(gè)活躍日所有操作過(guò)的且未顯式標(biāo)記為“不喜歡”的所有文檔認(rèn)定為用戶感興趣的文檔,基于此,計(jì)算系統(tǒng)的準(zhǔn)確率、召回率、覆蓋率、新穎度,并對(duì)10日實(shí)驗(yàn)周期內(nèi)所有實(shí)驗(yàn)結(jié)果取均值,作為系統(tǒng)最終評(píng)測(cè)數(shù)據(jù). 經(jīng)多次實(shí)驗(yàn)分析,系統(tǒng)相關(guān)參數(shù)設(shè)置如表1所示時(shí)推薦效果較好.
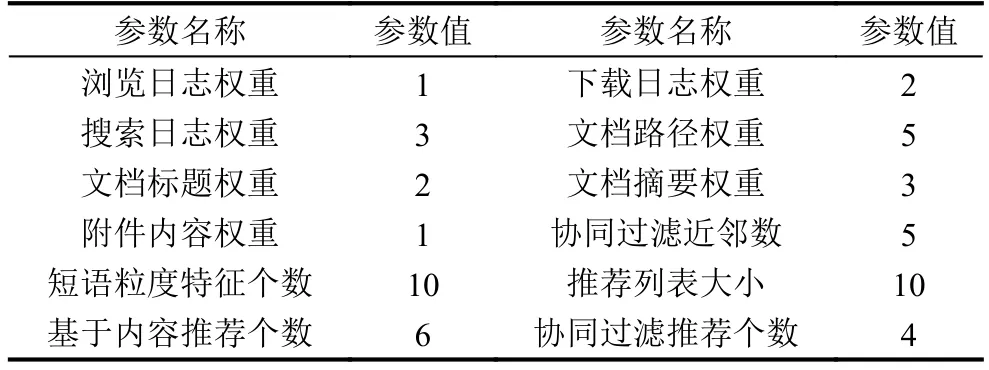
表1 實(shí)驗(yàn)配置
關(guān)于系統(tǒng)的評(píng)測(cè)指標(biāo)說(shuō)明如下[27].
(1)準(zhǔn)確率
準(zhǔn)確率描述最終的推薦列表中有多少比例是用戶實(shí)際感興趣的文檔,如下式計(jì)算:
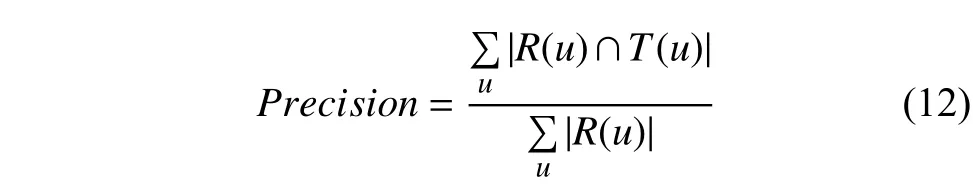
式中,R(u)表示系統(tǒng)為用戶生成的推薦列表,T(u)表示用戶行為展現(xiàn)的實(shí)際偏好列表.
(2)召回率
召回率描述的是有多少用戶實(shí)際感興趣的文檔包含在最終的推薦列表中,如下式計(jì)算:
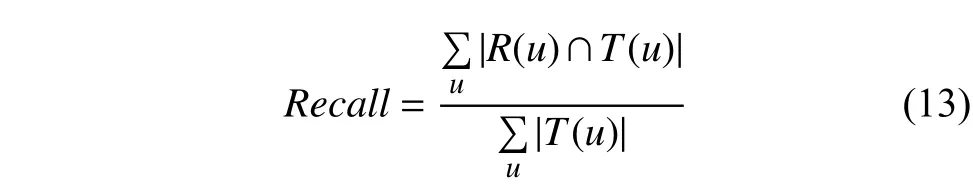
式中,R(u)表示系統(tǒng)為用戶生成的推薦列表,T(u)表示用戶行為展現(xiàn)的實(shí)際偏好列表.
(3)覆蓋率
覆蓋率反映了系統(tǒng)發(fā)掘長(zhǎng)尾的能力,覆蓋率越高說(shuō)明越能夠?qū)㈤L(zhǎng)尾中的文檔推薦給用戶,如下式計(jì)算:
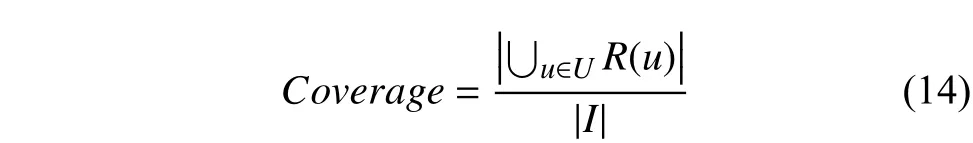
式中,R(u)表示系統(tǒng)為用戶生成的推薦列表,I表示全部文檔.
(4)新穎度
新穎度可以用被推薦的文檔的平均流行度來(lái)度量,如果推薦出的文檔都很熱門(mén),則說(shuō)明推薦的新穎度較低,否則說(shuō)明推薦結(jié)果比較新穎; 計(jì)算平均流行度的時(shí)候?qū)γ總€(gè)文檔的流行度取對(duì)數(shù),這是因?yàn)槲臋n的流行度分布滿足長(zhǎng)尾分布,在取對(duì)數(shù)后,流行度的平均值更加穩(wěn)定. 如下式計(jì)算:

式中,R(u)表示單個(gè)用戶的推薦列表,d表示單個(gè)文檔,P(d)表示文檔的流行度,即該文檔在所有用戶感興趣文檔數(shù)據(jù)集中出現(xiàn)的頻次.
實(shí)驗(yàn)中以單獨(dú)的基于內(nèi)容推薦列表、協(xié)同過(guò)濾推薦列表與混合推薦列表三者對(duì)比分析,相關(guān)實(shí)驗(yàn)數(shù)據(jù)如表2所示.
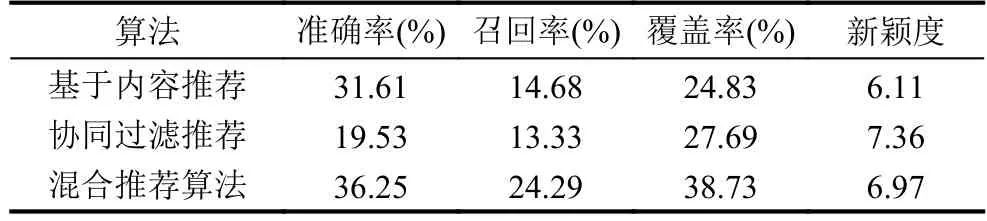
表2 不同推薦算法在實(shí)驗(yàn)數(shù)據(jù)集中的性能
由實(shí)驗(yàn)數(shù)據(jù)分析可知本系統(tǒng)建立的用戶及文檔標(biāo)簽較為精準(zhǔn)可靠,基于混合推薦算法為用戶生成的推薦列表也較為契合用戶實(shí)際需求. 系統(tǒng)的準(zhǔn)確率、召回率、覆蓋率、新穎度等指標(biāo)的實(shí)驗(yàn)數(shù)值,直接表明了本系統(tǒng)的有效性. 實(shí)際應(yīng)用時(shí),可在更長(zhǎng)周期內(nèi)監(jiān)測(cè)系統(tǒng)運(yùn)行數(shù)據(jù),并結(jié)合用戶調(diào)查和在線實(shí)驗(yàn)的測(cè)評(píng)方法,不斷優(yōu)化系統(tǒng)參數(shù),提升系統(tǒng)綜合性能.
5 結(jié)束語(yǔ)
本文介紹了基于多粒度特征和混合算法的文檔推薦系統(tǒng)架構(gòu)、功能模塊、文檔特征模型、用戶興趣模型以及推薦過(guò)程的設(shè)計(jì)與實(shí)現(xiàn). 系統(tǒng)中綜合了用戶顯式反饋和隱式反饋信息,經(jīng)過(guò)分詞、關(guān)鍵短語(yǔ)提取、關(guān)鍵詞語(yǔ)提取等操作后,在短語(yǔ)粒度和詞語(yǔ)粒度兩個(gè)層面對(duì)用戶興趣建模. 系統(tǒng)對(duì)文檔特征建模時(shí)也分別處理了短語(yǔ)粒度和詞語(yǔ)粒度兩個(gè)層面,這種方法既能較為準(zhǔn)確的刻畫(huà)用戶興趣及文檔特征也在一定程度上解決了數(shù)據(jù)稀疏問(wèn)題,提升了推薦系統(tǒng)的效果; 在此基礎(chǔ)上,系統(tǒng)使用基于內(nèi)容推薦和協(xié)同過(guò)濾推薦混合的推薦算法為用戶生成文檔推薦列表,此方法綜合了兩種推薦算法的優(yōu)點(diǎn),又互相彌補(bǔ)了單一算法的不足. 在系統(tǒng)實(shí)現(xiàn)時(shí),將推薦模型相關(guān)參數(shù)都設(shè)置在配置文件中,增強(qiáng)了系統(tǒng)的靈活性,也便于系統(tǒng)的迭代優(yōu)化. 文章最后對(duì)系統(tǒng)的實(shí)驗(yàn)效果分析,得出系統(tǒng)中所用的方法是有效可行的.
1彭菲菲,錢(qián)旭. 基于用戶關(guān)注度的個(gè)性化新聞推薦系統(tǒng). 計(jì)算機(jī)應(yīng)用研究,2012,29(3): 1005-1007.
2Li LH,Chu W,Langford J,et al. A contextual-bandit approach to personalized news article recommendation.Proceedings of the 19th International Conference on World Wide Web. Raleigh,NC,USA. 2010. 661-670.
3Vatturi PK,Geyer W,Dugan C,et al. Tag-based filtering for personalized bookmark recommendations. Proceedings of the 17th ACM Conference on Information and Knowledge Management. Napa Valley,CA,USA. 2008. 1395-1396.
4Klinkenberg R. Learning drifting concepts: Example selection vs. example weighting. Intelligent Data Analysis,2004,8(3): 281-300.
5Koychev I,Schwab I. Adaptation to drifting user’s interests.Proceedings of ECML 2000 Workshop: Machine Learning in New Information Age. Barcelona,Spain. 2000. 39-46.
6單蓉. 用戶興趣模型的更新與遺忘機(jī)制研究. 微型電腦應(yīng)用,2011,27(7): 10-11.
7Bollacker KD ,Lawrence S,Giles CL. Discovering relevant scientific literature on the Web. IEEE Intelligent Systems and Their Applications,2000,15(2): 42-47. [doi: 10.1109/5254.850826]
8Ricci F,Rokach L,Shapira B,et al. Recommender Systems Handbook. Berlin,Germany: Springer,2011: 1-842.
9王立才,孟祥武,張玉潔. 上下文感知推薦系統(tǒng). 軟件學(xué)報(bào),2012,23(1): 1-20.
10許海玲,吳瀟,李曉東,等. 互聯(lián)網(wǎng)推薦系統(tǒng)比較研究. 軟件學(xué)報(bào),2009,20(2): 350-362.
11van den Oord A,Dieleman S,Schrauwen B. Deep contentbased music recommendation. Advances in Neural Information Processing Systems 26. Lake Tahoe,NV,USA.2013. 2643-2651.
12Lops P,de Gemmis M,Semeraro G,et al. Content-based and collaborative techniques for tag recommendation: An empirical evaluation. Journal of Intelligent Information Systems,2013,40(1): 41-61. [doi: 10.1007/s10844-012-0215-6]
13Achakulvisut T,Acuna DE,Tulakan R,et al. Science concierge: A fast content-based recommendation system for scientific publications. PLoS One,2016,11(7): e0158423.[doi: 10.1371/journal.pone.0158423]
14Philip S,Shola PB,Abari OJ. Application of content-based approach in research paper recommendation system for a digital library. International Journal of Advances Computer Science and Applications,2014,5(10): 37-40.
15Jeong B,Lee J,Cho H. An iterative semi-explicit rating method for building collaborative recommender systems.Expert Systems with Applications,2009,36(3): 6181-6186.[doi: 10.1016/j.eswa.2008.07.085]
16de Campos LM,Fernández-Luna JM,Huete JF,et al.Combining content-based and collaborative recommendations:A hybrid approach based on Bayesian networks. International Journal of Approximate Reasoning,2010,51(7): 785-799.[doi: 10.1016/j.ijar.2010.04.001]
17楊家慧,劉方愛(ài). 基于巴氏系數(shù)和Jaccard系數(shù)的協(xié)同過(guò)濾算法. 計(jì)算機(jī)應(yīng)用,2016,36(7): 2006-2010.
18Konstan JA,Miller BN,Maltz D,et al. GroupLens: Applying collaborative filtering to Usenet news. Communications of the ACM,1997,40(3): 77-87. [doi: 10.1145/245108.245126]
19Zhao ZD,Shang MS. User-based collaborative-filtering recommendation algorithms on hadoop. Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining. Phuket,Thailand. 2010. 478-481.
20黃裕洋,金遠(yuǎn)平. 一種綜合用戶和項(xiàng)目因素的協(xié)同過(guò)濾推薦算法. 東南大學(xué)學(xué)報(bào)(自然科學(xué)版),2010,40(5): 917-921.
21Lee SK,Cho YH,Kim SH. Collaborative filtering with ordinal scale-based implicit ratings for mobile music recommendations. Information Sciences,2010,180(11):2142-2155. [doi: 10.1016/j.ins.2010.02.004]
22Lika B,Kolomvatsos K,Hadjiefthymiades S. Facing the cold start problem in recommender systems. Expert Systems with Applications,2014,41(4): 2065-2073. [doi: 10.1016/j.eswa.2013.09.005]
23Fernández-Tobías I,Braunhofer M,Elahi M,et al.Alleviating the new user problem in collaborative filtering by exploiting personality information. User Modeling User-Adapted Interaction,2016,26(2-3): 221-255. [doi: 10.1007/s11257-016-9172-z]
24鄧愛(ài)林,朱揚(yáng)勇,施伯樂(lè). 基于項(xiàng)目評(píng)分預(yù)測(cè)的協(xié)同過(guò)濾推薦算法. 軟件學(xué)報(bào),2003,14(9): 1621-1628.
25上海林原信息科技有限公司. HanLP: Han language processing. http://hanlp.linrunsoft.com/. [2015-04-02].
26Lu ZQ,Dou ZC,Lian JX,et al. Content-based collaborative filtering for news topic recommendation. Proceedings of the 29th AAAI Conference on Artificial Intelligence and the 27th Innovative Applications of Artificial Intelligence Conference.Austin,TX,USA. 2015. 217-223.
27項(xiàng)亮. 推薦系統(tǒng)實(shí)踐. 北京: 人民郵電出版社,2012.
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
商用汽車(chē)(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(chē)(2016年6期)2016-06-29 09:18:54
商用汽車(chē)(2016年4期)2016-05-09 01:23:12
