基于圖覆蓋的大數(shù)據(jù)全比較數(shù)據(jù)分配算法
2018-04-19 07:37:00高燕軍
計算機工程 2018年4期
關鍵詞:分配
高燕軍,,,,2
(1.太原理工大學 信息工程學院,山西 晉中 030600;2.昆士蘭科技大學 電機工程及計算機科學學院,澳大利亞 布里斯班4001)
0 概述
全比較是一類特殊的計算問題,廣泛存在于生物信息學、生物測定學和數(shù)據(jù)挖掘等領域[1]。在生物信息學中,通過比較不同物種的基因序列對譜系關系進行推斷[2]。在生物測定學的研究中,一個典型的全比較問題是通過對生物測定學數(shù)據(jù)庫中的大量數(shù)據(jù)進行成對比較來識別人的生理特征的,如面部識別、指形判斷、手掌掃描[3]。在數(shù)據(jù)挖掘中,相似矩陣的計算是分類和聚類分析中的一個關鍵步驟,它表示被考慮對象之間的相似度[4-5]。序列比對、聚類分析[6]以及當前的研究熱點全局網(wǎng)絡比對均屬于計算生物學和生物信息學中典型的全比較計算問題[7]。
全比較計算代表了一種典型的計算模式,即數(shù)據(jù)集中的每個數(shù)據(jù)都要和該數(shù)據(jù)集中的其他所有的數(shù)據(jù)做一次比較計算[8-9]。當數(shù)據(jù)集中的文件個數(shù)或者文件所包含的數(shù)據(jù)變大時,全比較計算的規(guī)模隨之變大[10]。當前,針對一些特定領域的全比較問題已有解決方法被提出,如著名的BLAST[11]和ClustalW[12]。然而,這些方法要求在系統(tǒng)中的每個節(jié)點上存儲所有的數(shù)據(jù)文件,增加了時間開銷和通信成本,而且需要巨大的存儲空間。此外,分布式系統(tǒng)(如開源的分布式處理框架Hadoop[13])被廣泛地用于解決大規(guī)模的數(shù)據(jù)密集型的計算問題,包括全比較計算[14]。然而,由于沒有考慮比較任務和數(shù)據(jù)之間的依賴關系,基于Hadoop的數(shù)據(jù)分配策略對于全比較計算是低效的[15]。由此可以得出,數(shù)據(jù)分配的結果將直接影響全比較計算的整體性能。文獻[10]將全比較計算的數(shù)據(jù)分配問題抽象為帶約束條件的組合優(yōu)化問題,并利用啟發(fā)式算法求最優(yōu)解。與Hadoop相比,該方法提高了整體的計算性能,但是隨著數(shù)據(jù)量的增大,解空間變大,問題規(guī)模呈指數(shù)級增長[16]。此外,啟發(fā)式算法也無法保證解的全局最優(yōu)性[17]。
針對上述問題,本文提出基于圖覆蓋的數(shù)據(jù)分配算法(Data Allocation Algorithm Based on Graph Covering,DAABGC)。首先對全比較計算問題進行理論分析,將其歸納為圖覆蓋問題,然后構造最優(yōu)圖覆蓋的解,根據(jù)特解設計相應的數(shù)據(jù)分配算法,以確保所有比較任務都包含本地數(shù)據(jù),使節(jié)點之間達到負載均衡,從而在保證存儲節(jié)約率的前提下,提高計算性能。
1 全比較與圖覆蓋
1.1 全比較計算
一個典型的全比較計算步驟如下:1)通過主節(jié)點管理和分配數(shù)據(jù)到各節(jié)點上;2)通過任務調度器生成計算任務,然后把任務分配到各節(jié)點上;3)各節(jié)點執(zhí)行全比較計算,處理和任務相關的數(shù)據(jù)。各階段示意圖如圖1所示。從中可以看出,數(shù)據(jù)分配和任務執(zhí)行是大數(shù)據(jù)全比較計算的2個關鍵階段。
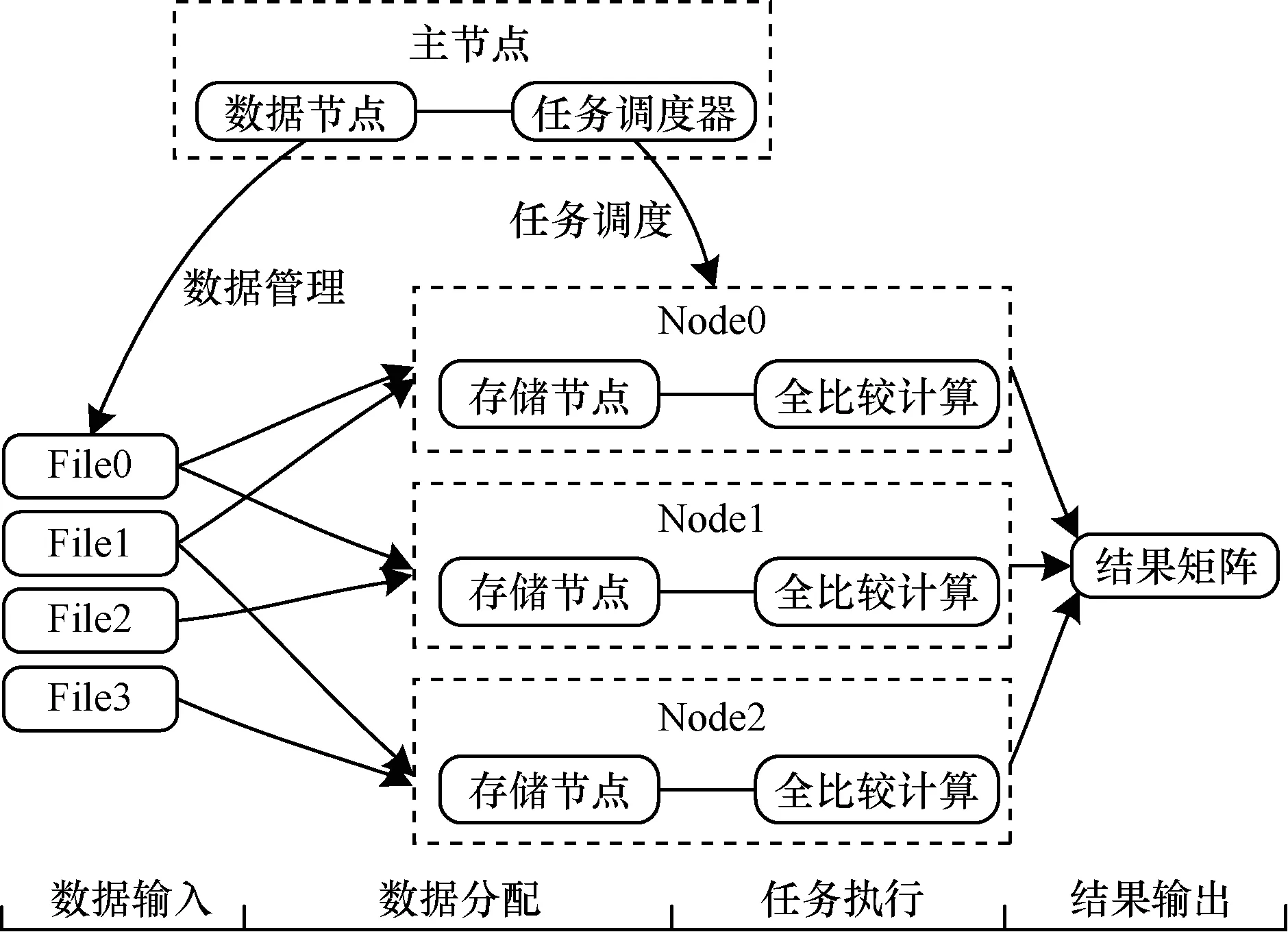
圖1 大數(shù)據(jù)全比較計算各階段示意圖
為更高效地解決大數(shù)據(jù)全比較問題,首先提出2個假設:1)數(shù)據(jù)文件的大小相同或近似相同;2)比較任務的執(zhí)行時間相同或近似相同。在真實的場景中,很多應用滿足這2個特性,如協(xié)方差矩陣的計算、聚類分析中相似矩陣的計算等。本文研究的正是這類應用。其次,本文將從存儲的使用和計算性能2個方面對該問題進行深入剖析。
1)減少存儲使用
對于存儲的使用,需要考慮2個問題:(1)每個節(jié)點的存儲使用必須在其范圍之內;(2)分配數(shù)據(jù)到各個節(jié)點上所花費的時間應該在可接受的程度之內。令|Di|為節(jié)點i上存儲的文件數(shù),則在考慮到上述2個條件的情況下,數(shù)據(jù)分配算法需要滿足:
Minimize max{|D1|,|D2|,…,|Dk|}
(1)
最小化節(jié)點中最大的文件數(shù)可以使每個節(jié)點存儲相似數(shù)量的文件并包含相似數(shù)量的可執(zhí)行比較任務,原因是可執(zhí)行任務的數(shù)量和節(jié)點上的文件數(shù)是成比例增長的。
2)提高計算性能
在全比較問題的分布式計算中,任務執(zhí)行的總時間是由最后一個完成任務的節(jié)點決定的。為了完成每個比較任務,對應的節(jié)點必須訪問和處理所需的數(shù)據(jù)。令K、tcom(k)和tacc(k)分別代表分配給最后一個完成任務的節(jié)點的任務數(shù)、任務k的計算時間和訪問任務k所需數(shù)據(jù)的時間。那么,執(zhí)行任務的總時間可以表示為:
(2)
為了減少式(2)中總的執(zhí)行時間,數(shù)據(jù)分配算法需要滿足2個條件:(1)任務分配均衡;(2)所有的比較任務都具有好的數(shù)據(jù)本地性。
令Ti為節(jié)點i執(zhí)行的比較任務數(shù),則對于N個節(jié)點、M個文件的全比較問題,共有M(M-1)/2個比較任務需要分配,那么任務分配均衡可以表示為:

(3)
好的數(shù)據(jù)本地性也可以公式化。如果一個比較任務所需的數(shù)據(jù)都存儲在本地,那么該任務不需要通過網(wǎng)絡來遠程訪問數(shù)據(jù),因此,好的數(shù)據(jù)本地性意味著tacc(k)的最小值可以為0。令(x,y)、T、Ti、Di分別代表數(shù)據(jù)x和y之間的比較任務、所有比較任務的集合、由節(jié)點i執(zhí)行的任務集合以及節(jié)點i上存儲的數(shù)據(jù)集合,則好的數(shù)據(jù)本地性可以表示為:
?(x,y)∈T,?i∈{1,2,…,N}
x∈Di∧y∈Di∧(x,y)∈Ti
(4)
經(jīng)上述討論,將式(1)、式(3)、式(4)作為本文數(shù)據(jù)分配算法的優(yōu)化目標。
1.2 圖覆蓋問題
1.2.1 圖覆蓋的基本概念
定義1完全圖是每對頂點之間都恰好連有一條邊的簡單圖,n個頂點的完全圖有n(n-1)/2條邊,記為Gn。
定義2假設G(V,E)代表一個圖,其中,V表示頂點集合,E表示邊集合。從集合V取若干個頂點組成集合V′,構成一個誘導子圖,用G[V′]表示。
定義32個圖G1(V1,E1)和G2(V2,E2)的聯(lián)合為分別對頂點和邊求并集,即G=(V1∪V2,E1∪E2)。如果存在n個誘導子圖G(V1),G(V2),…,G(Vn)的聯(lián)合G覆蓋圖G′,當且僅當G′的任何一條邊存在于某個子圖G(Vi)。
定義4給定一個圖G=(V,E)和一個正整數(shù)k,把G劃分為k個誘導子圖G(V1),G(V2),…,G(Vk),如果滿足2個條件:1)該k個子圖的聯(lián)合覆蓋G;2)各子圖中最大的頂點數(shù)最小,即minmax{|V1|,|V2|,…,|Vk|},其中|Vi|代表第i個子圖中的頂點數(shù),則稱其為圖覆蓋問題。
定義5若某一個Gn的一些子圖Gp、Gp之間無公共邊,且Gn中的任意一邊必定在某個Gp中,則稱這些圖Gp的聯(lián)合為Gn的最優(yōu)圖覆蓋,若不滿足則稱這些Gp不是Gn的最優(yōu)圖覆蓋。
1.2.2 全比較問題到圖覆蓋問題的轉化
把全比較計算映射為一個完全圖,圖中的頂點代表數(shù)據(jù)文件,邊代表比較任務,如圖2所示,其中,8個頂點代表8個數(shù)據(jù)文件,28條邊代表28個比較任務,如C(3,8)、C(4,8)、C(4,7)分別表示3個不同的比較任務。因此,M個文件、N個節(jié)點全比較數(shù)據(jù)分配問題可以類比為把一個完全圖GM劃分為N個子圖,且該N個子圖的聯(lián)合能夠覆蓋圖GM。考慮到1.1節(jié)提出的優(yōu)化目標,式(1)數(shù)據(jù)均衡意味著每個子圖有相似數(shù)量的頂點,式(2)任務均衡意味著每個子圖有相似數(shù)量的邊,而式(3)數(shù)據(jù)本地性,按照最優(yōu)圖覆蓋的子圖劃分方式,任意2個子圖之間沒有公共邊,每個子圖都自成一個完全圖,所有的邊都連著2個頂點,因此,可以確保比較任務具有100%的數(shù)據(jù)本地性。由此可以得出,全比較問題可以轉化為最優(yōu)圖覆蓋的求解問題。文獻[18]證明最優(yōu)圖覆蓋問題是NP完全問題。NP完全問題是非確定性問題,無法直接通過計算得到解,解決NP完全問題的一般方法是采用啟發(fā)式算法。然而,隨著M和N的增大,解的空間呈指數(shù)級增長。
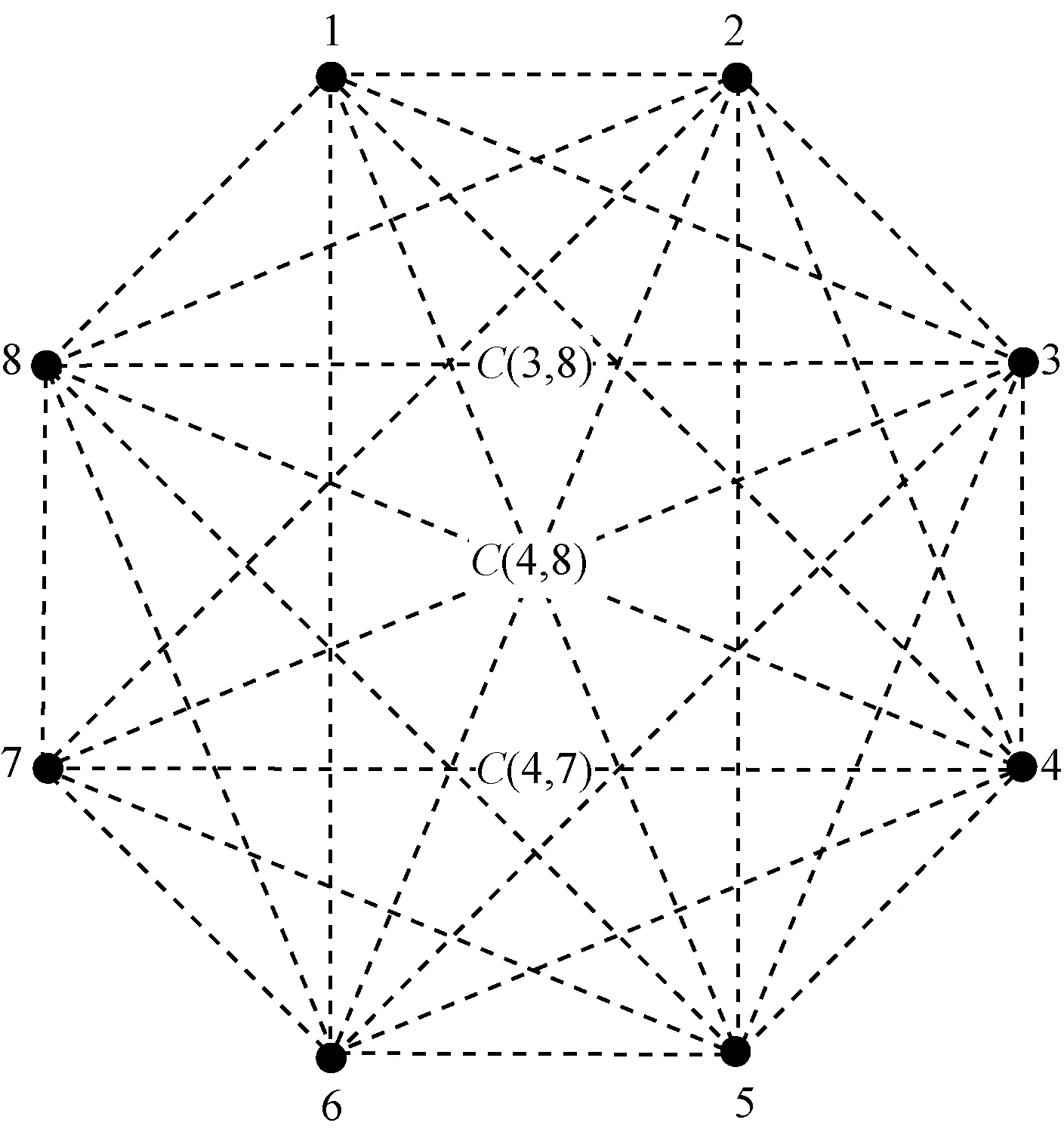
圖2 8個文件的全比較計算示意圖
通過研究可以發(fā)現(xiàn),相同頂點數(shù)的子圖Gp覆蓋Gn的必要條件是n-1≥p(p-1)。
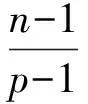
2 圖覆蓋最優(yōu)解的構造方法
M=N=p(p-1)+1,p>2,其中M為文件數(shù),N為節(jié)點數(shù),當p=2,3時,問題相對簡單,通過枚舉法構造出最優(yōu)解,如表1、表2所示,最優(yōu)解可以表示為集合S={Ni(Vi1,Vi2,…,Vip)|i=1,2,…,n},其中n為節(jié)點數(shù),Ni為節(jié)點i的編號,Vip為頂點p(即數(shù)據(jù)文件p)的編號。
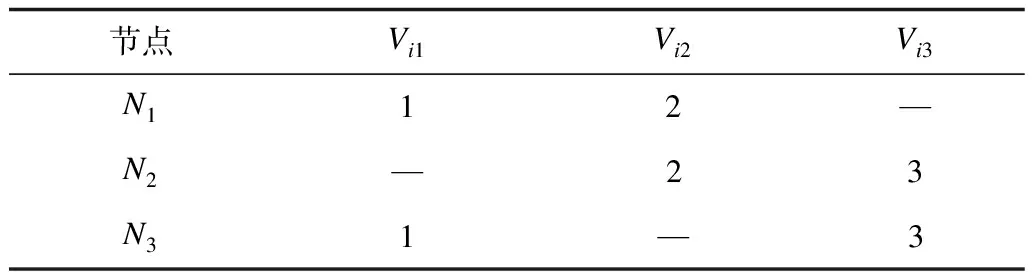
表1 p=2時圖覆蓋最優(yōu)解
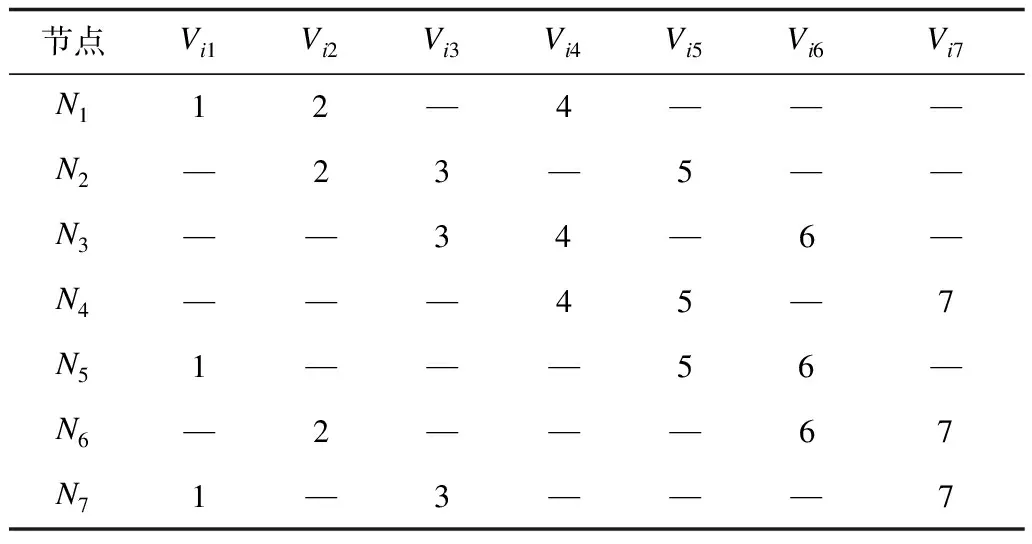
表2 p=3時圖覆蓋最優(yōu)解
由表1、表2可以歸納出以下規(guī)律:
1)如果存在最優(yōu)解,則每個節(jié)點上的文件個數(shù)為p。
2)相鄰節(jié)點之間的解組合差1,如表2的N1(1,2,4),然后對組合中的各元素遞增1,即為下一個節(jié)點上的頂點組合。當Vip遞增為N+1時,將Vip置為1,然后對這p個點從小到大重新排列,繼續(xù)遞增,結果發(fā)現(xiàn)是一個循環(huán)。
3)在這p個點中,1和2是可以首先確定的2個點,在確定1和2的情況下,3是可以排除的,例如(1,2,3)遞增1,則為(2,3,4),顯然(2,3)為公共邊,不滿足最優(yōu)圖覆蓋的條件。因此,第3個點從4開始。
4)由于這p個點是循環(huán)遞增的,因此任意2個點之間的差值不能相同。如p=4,M=N=13,取4個點為(1,2,4,7),當遞增到(4,5,7,10)時,將出現(xiàn)一條公共邊,直到第4個數(shù)遞增到13都會有公共邊存在。
5)在滿足規(guī)律1)和規(guī)律2)之后,在(Vi1,Vi2,…,Vip)的第p個點Vip遞增到N+1之前都不會有公共邊存在。當Vip=N+1時,將其置為1,此時,節(jié)點i上的解為(1,Vi2,Vi3,…,Vip),重新計算1和其他各點之間的差,且不能和之前的差相同。
3 數(shù)據(jù)分配算法
從第2節(jié)的分析中可以得到以下結論:
1)假設M=N=p(p-1)+1,p>2時存在圖覆蓋的最優(yōu)解,則可以通過上文5條規(guī)律來構造該解。
2)在構造出最優(yōu)解之后,數(shù)據(jù)和任務的分配可以根據(jù)最優(yōu)解來進行。
3)由于之前所討論的構造特殊解的前提是M=N,因此本文討論M>N的情況。當M>N時,可以將文件均勻分成N個Block,每個Block中的文件個數(shù)差別不大于1,然后按照M=N的情況來構造解,并進行相應的數(shù)據(jù)分配和任務調度。如表3所示,N=7,M=9時可以構造7個Block。
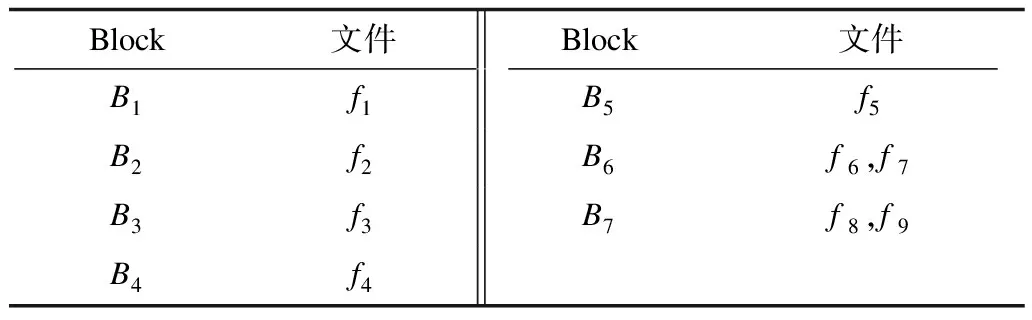
表3 N=7,M=9時Block的構造
根據(jù)上述內容,本文提出基于圖覆蓋的數(shù)據(jù)分配算法(DAABGC)。該算法分為2個步驟:
步驟1構造最優(yōu)解。首先定義5個集合變量:L1用于存放已經(jīng)找到的特解元素;L2存放特解中任意兩點之間的差;L3存放L1和L2中元素的和;L4存放新找到的頂點和已有頂點的差;L5存放當Vi遞增到N+1時,Vj,j=1,2,…,i-1和1的差,其中Vi表示第i個頂點,然后進行特解的構造。
步驟2分配數(shù)據(jù)和調度任務。當M=N時,根據(jù)步驟1得到特解進行數(shù)據(jù)分配;當M>N時,將數(shù)據(jù)文件均勻打包為N個Block,然后根據(jù)特解進行數(shù)據(jù)分配。
通過DAABGC算法,構造出當M=N=13,21,31時的最優(yōu)解,加上手動構造p=2,3時的解,M=N=3,7,13,21,31時的特解如表4所示。

表4 M=N=3,7,13,21,31時的特解
DAABGC算法描述如下:
//構造最優(yōu)解
定義變量:L1、L2、L3、L4、L5為5個集合變量
構造最優(yōu)解S中組合N1(V1,V2,…,Vp)
V1=1,V2=2,V3從4開始
把V1、V2、V3存到L1,把V1、V2、V3之間任意2個元素之間的差無重復地存到L2
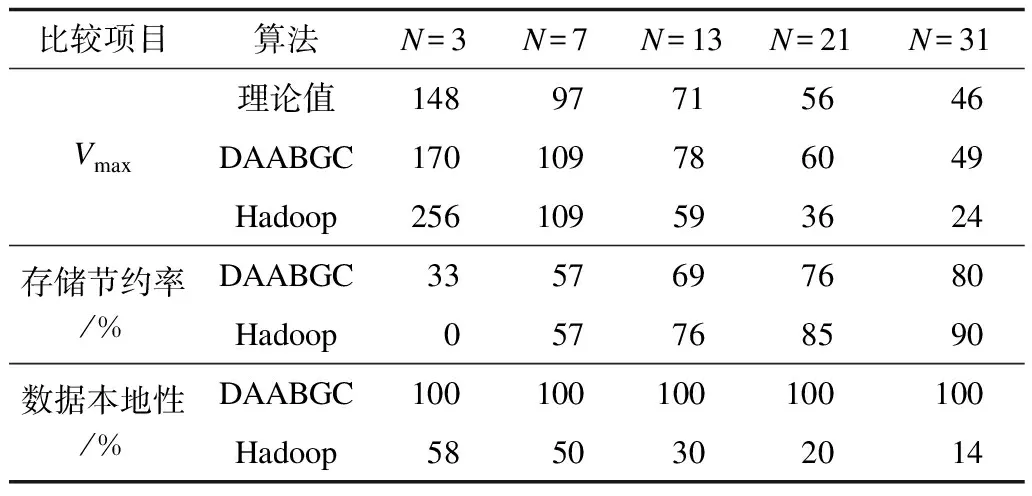
while V3 for i=4 to p do for x in L1do for y in L2do 把x+y無重復地放入L3 end for end for 對L3進行升序排序,在L3中搜索第一個在Vi-1和L3[last]之間沒有的自然數(shù),如果存在將其賦給Vi,否則把L3[last]++賦給Vi while Vi for z in L1do L4.add(Vi-z); end for 計算當Vi遞增到N+1時,Vj,j=1,2…,i-1和1的差,并放入L5 if L2或L4包含的L5任意一個元素then Vi++; if Vi是Vi-1和L3[last]之間某個元素then L3[last]賦給Vi Continue end if else 把Vi放入L1,把L4,L5的元素拷貝到L2,清空L4、L5 break; end if end while if最優(yōu)解的所有元素Vi全部找到then 保存最優(yōu)解,并退出循環(huán) else V3++; end for end while //根據(jù)最優(yōu)解分配數(shù)據(jù)和任務調度 當M=N時,按特解來分配數(shù)據(jù);當M>N時,將文件均勻地打包為N個Block,然后按照特解分配數(shù)據(jù),最后根據(jù)數(shù)據(jù)分配的結果來調度任務 本節(jié)將通過實驗來驗證算法的有效性。首先介紹評價指標,然后根據(jù)每個指標依次對算法進行評估。 本文提出了4個評價指標來評估算法,分別為存儲節(jié)約率、數(shù)據(jù)本地性、計算性能和可擴展性。 1)存儲節(jié)約率。存儲節(jié)約率是數(shù)據(jù)分配算法的目標之一,反映了算法對硬盤的節(jié)約情況,可有效度量存儲效率。 2)數(shù)據(jù)本地性。數(shù)據(jù)本地性能夠反映數(shù)據(jù)分配算法和計算性能的好壞。因為在本文的算法中,任務的分配是基于數(shù)據(jù)分配的結果,所以具有數(shù)據(jù)本地性的任務在數(shù)據(jù)分配完成之后可以統(tǒng)計出來。 3)計算性能。相對于存儲節(jié)約率和數(shù)據(jù)本地性,計算性能能夠更加直觀地反映算法的性能。 4)可擴展性。可擴展性對于大數(shù)據(jù)全比較問題的大規(guī)模分布式計算是非常重要的。本文將對分布式系統(tǒng)中節(jié)點上不同數(shù)量的處理進行測試。 存儲節(jié)約率的計算以每個節(jié)點上存儲所有數(shù)據(jù)文件作為基準,以節(jié)點上的最大文件數(shù)Vmax為衡量標準,即max{|V1|,|V2|,…,|VN|}。存儲節(jié)約率的計算式如下: (5) 在最理想的數(shù)據(jù)分配和任務調度情況下,Vmax存在理論下界。令M為文件數(shù),N為節(jié)點數(shù),則共有M(M-1)/2個比較任務,每個節(jié)點分配的比較任務不超過下式: (6) 為了完成比較任務所需的最少的文件,由于每個任務對應2個不同的數(shù)據(jù)文件,因此可以得到式(7)。 (7) 對式(7)進行計算得到: (8) 令M=256,對DAABGC算法和Hadoop進行對比。如表5所示,與在每個節(jié)點上存儲所有的數(shù)據(jù)文件相比,DAABGC算法和Hadoop都具有很高的存儲節(jié)約率,其中,Hadoop更高一些。當節(jié)點數(shù)為31時,DAABGC算法的存儲節(jié)約率達到了80%,而Hadoop則為90%。雖然DAABGC的存儲節(jié)約率相對較低,但是對于所有的比較任務,數(shù)據(jù)本地性都為100%,而Hadoop的高存儲節(jié)約率是以犧牲數(shù)據(jù)本地性為代價的。例如,當節(jié)點數(shù)為31時,Hadoop的數(shù)據(jù)本地性只有14%。數(shù)據(jù)本地性對于大規(guī)模的全比較計算問題十分重要,好的數(shù)據(jù)本地性能夠極大地減少任務執(zhí)行時節(jié)點間的數(shù)據(jù)移動,因此,DAABGC算法在高存儲節(jié)約率的情況下,數(shù)據(jù)本地性更好。 表5 不同數(shù)據(jù)分配策略的對比 計算性能由全比較問題總的執(zhí)行時間來表征。下文對Hadoop和DAABGC算法進行比較。實驗的設計如下: 1)實驗的軟硬件環(huán)境。如表6所示,為了測試算法在真實的集群環(huán)境下的性能,筆者搭建了Hadoop集群,操作系統(tǒng)采用Centos7,將其中一個管理節(jié)點作為主節(jié)點,另外一個管理節(jié)點作為主節(jié)點的備用節(jié)點,其他節(jié)點作為數(shù)據(jù)節(jié)點。主節(jié)點和備用節(jié)點,以及數(shù)據(jù)節(jié)點之間通過2個交換機冗余連接。 表6 集群的硬件配置 2)實驗應用。作為生物信息學中典型的全比較問題,CVTree被選為測試計算性能的應用。CVTree在單機平臺的計算已經(jīng)實現(xiàn)[19],本文將在分布式的環(huán)境下來測試CVTree。 3)實驗數(shù)據(jù)。本文選擇國家技術生物中心的一組dsDNA文件作為實驗數(shù)據(jù),其中,每個文件的大小約為150 MB,總的數(shù)據(jù)量為20 GB。 本文對節(jié)點數(shù)為7時不同的數(shù)據(jù)文件做了測試。如圖3所示,當M分別為93、109、124時,DAABGC的總運行時間都低于Hadoop,說明DAABGC算法對于解決CVTree來說具有更好的性能。 圖3 2種算法的計算效率對比 為了更好地驗證DAABGC算法的性能,對不同數(shù)量的文件,在節(jié)點數(shù)為7的情況下計算總的運行時間。如圖4所示,對于相同的文件個數(shù)M,每個節(jié)點的運行時間是非常相似的,很好地滿足了式(3)所表達的負載均衡。每個節(jié)點上的比較任務在執(zhí)行時都訪問了本地數(shù)據(jù),因為節(jié)點之間不存在數(shù)據(jù)移動。 圖4 7個節(jié)點的任務均衡性 可擴展性對于大數(shù)據(jù)集全比較問題的處理很重要。可擴展性的評估指標為加速比。 如圖5所示,實驗對處理器個數(shù)從1~7的情況進行測試。從中可知DAABGC算法獲得了約6.335/7=90.5%的理想性能,由此可得,和Hadoop相比,DAABGC算法雖然占用了更多的存儲空間,但是也獲得了更好的性能,隨著處理器數(shù)量的增加,獲得了較好的加速比,因此,DAABGC算法具有良好的可擴展性,能夠適應大數(shù)據(jù)全比較問題的大規(guī)模分布式計算的要求。 圖5 本文算法獲得的加速比 本文從存儲使用和計算性能2個方面探討如何高效解決大數(shù)據(jù)全比較問題,并基于圖覆蓋理論提出DAABGC算法。實驗結果表明,該算法可構造出最優(yōu)解,得到比Hadoop更好的性能。下一步將深入研究圖覆蓋問題最優(yōu)解產(chǎn)生的理論依據(jù),并針對更多領域的大數(shù)據(jù)全比較問題對DAABGC算法進行實驗驗證。 [1] ZHANG Y F,TIAN Y C,KELLY W,et al.Application of simulated annealing to data distribution for all-to-all comparison problems in homogeneous systems[C]//Proceedings of ICONIP’15.Berlin,Germany:Springer,2015:683-691. [2] HAO B,QI J,WANG B.Prokaryotic phylogeny based on complete genomes without sequence alignment[J].Modern Physics Letters B,2011,17(3):91-94. [3] PHILLIPS P J,FLYNN P J,SCRUGGS T,et al.Overview of the face recognition grand challenge[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Computer Society,2005:947-954. [4] SKABAR A,ABDALGADER K.Clustering sentence-level text using a novel fuzzy relational clustering algorithm[J].IEEE Transactions on Knowledge and Data Engineering,2013,25(1):62-75. [5] 丁三軍,薛 宇,王朝霞,等.基于模糊數(shù)據(jù)挖掘的虛擬環(huán)境主機故障預測[J].計算機工程,2015,41(11):202-206. [6] WONG A K,LEE E S.Aligning and clustering patterns to reveal the protein functionality of sequences[J].IEEE/ACM Transactions on Computational Biology and Bioinformatics,2014,11(3):548-560. [7] FAISAL F E,ZHAO H,MILENKOVIC T,et al.Global network alignment in the context of aging[J].IEEE/ACM Transations on Computational Biology and Bioinformatics,2015,12(1):40-52. [8] KRISHNAJITH A P D,KELLY W,HAYWARD R,et al.Managing memory and reducing I/O cost for correlation matrix calculation in bioinformatics[C]//Proceedings of IEEE Symposium on Computational Intelligence in Bioinfor-matics and Computational Biology.Washington D.C.,USA:IEEE Press,2013:36-43. [9] ANATHTHA P D K,KELLY W,TIAN Y C.Optimizing I/O cost and managing memory for composition vector method based on correlation matrix calculation in bioinformatics[J].Current Bioinformatics,2014,9(3):234-245. [10] ZHANG Y F,TIAN Y C,KELLY W,et al.A distributed com-puting framework for all-to-all comparison problems[C]//Proceedings of IECON’14.Washington D.C.,USA:IEEE Press,2014:2499-2505. [11] ALTSCHUL S F,GISH W,MILLER W,et al.Basic local alignment search tool[J].Journal of Molecular Biology,1990,215(3):403-410. [12] THOMPSON J D,GIBSON T J,HIGGINS D G.Multiple sequence alignment using ClustalW and ClustalX[EB/J].Current Protocols in Bioinformatics,2002,2(3). [13] 欒亞建,黃翀民,龔高晟,等.Hadoop平臺的性能優(yōu)化研究[J].計算機工程,2010,36(14):262-263. [14] CHEN Q,WANG L,SHANG Z.MRGIS:a MapReduce-enabled high performance workflow system for GIS[C]//Proceedings of the 4th IEEE International Conference on e-science.Washington D.C.,USA:IEEE Computer Society,2008:646-651. [15] 程 苗,陳華平.基于Hadoop的Web日志挖掘[J].計算機工程,2011,37(11):37-39. [16] GILLETT B E,MILLER L R.A heuristic algorithm for the vehicle-dispatch problem[J].Operations Research,1974,22(2):340-349. [17] LIN S,KERNIGHAN B W.An effective heuristic algorithm for the TSP[J].Operations Research,1973,21(2):498-516. [18] THITE S.On covering a graph optimally with induced subgraphs[J].Computing,2006,44(1):1-6. [19] KRISHNAJITH A P D,KELLY W,HAYWARD R,et al.Managing memory and reducing I/O cost for correlation matrix calculation in bioinformatics[C]//Proceedings of IEEE Symposium on Computational Intelligence in Bioinformatics and Computational Biology.Washington D.C.,USA:IEEE Press,2013:36-43.4 實驗
4.1 評價指標
4.2 存儲節(jié)約率和數(shù)據(jù)本地性
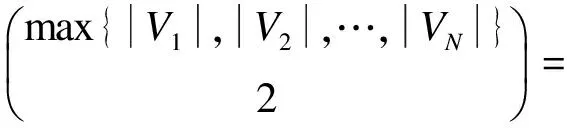
4.3 計算性能

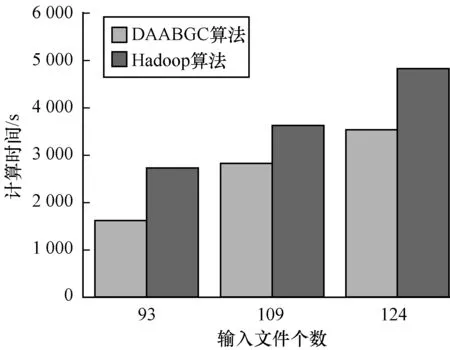
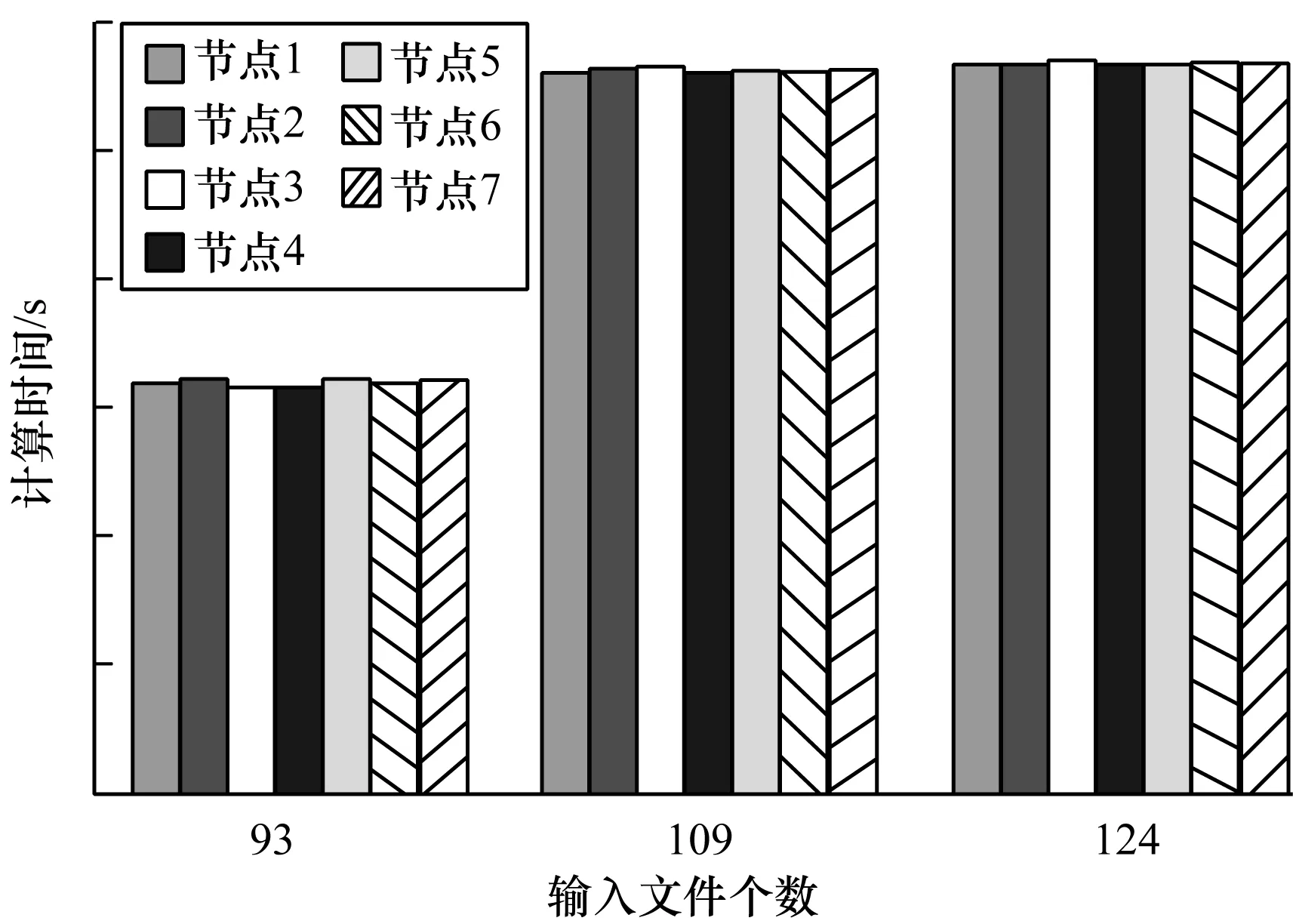
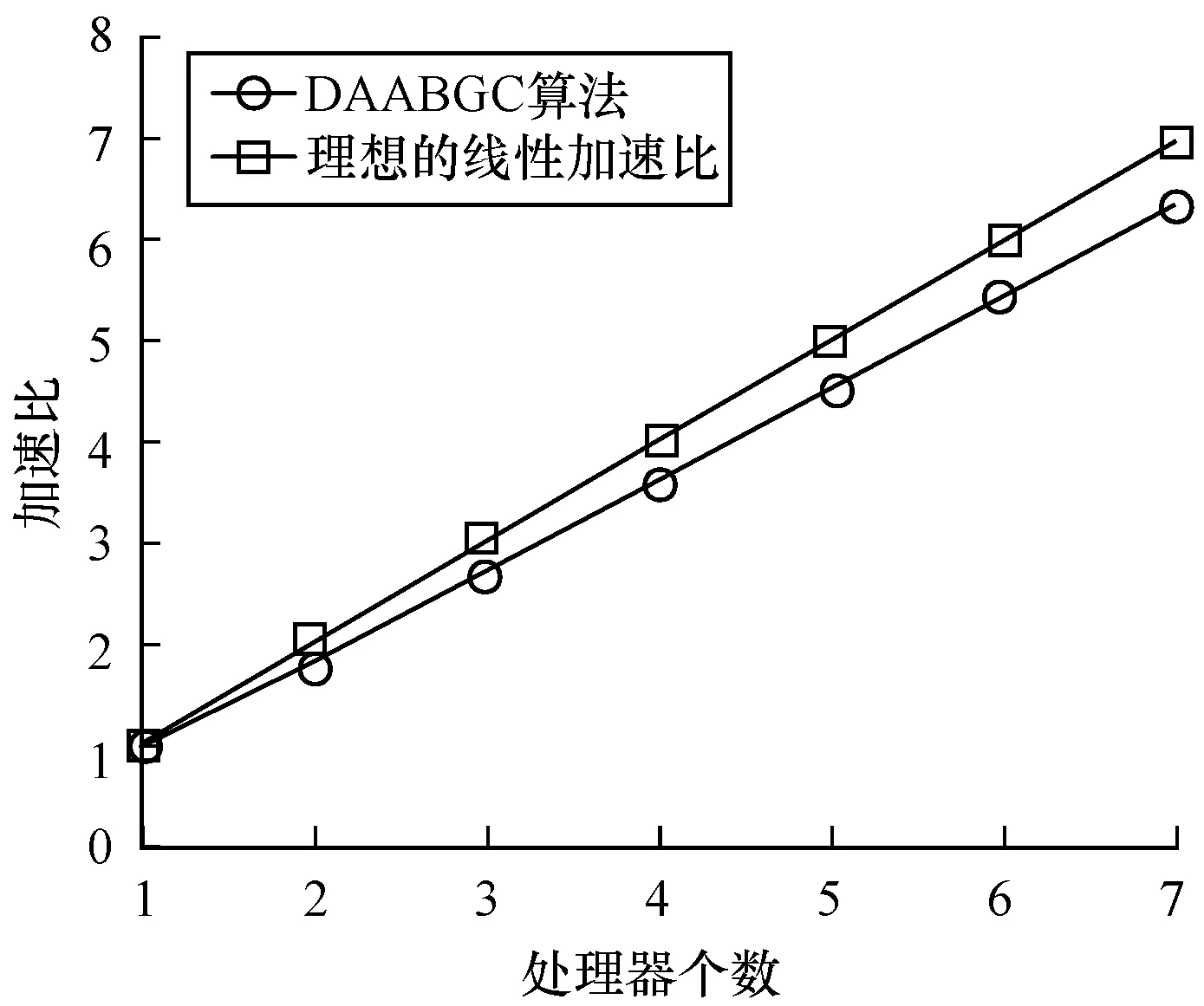
4.4 可擴展性
5 結束語
猜你喜歡
天水行政學院學報(2022年4期)2022-11-18 09:02:36艦船科學技術(2022年13期)2022-08-11 09:30:02鐵道通信信號(2020年9期)2020-02-06 09:15:22漢語世界(The World of Chinese)(2019年3期)2019-07-01 02:37:48數(shù)學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43小學科學(學生版)(2019年5期)2019-05-21 01:00:18中學生數(shù)理化·中考版(2018年10期)2018-12-07 00:44:52經(jīng)濟技術協(xié)作信息(2018年30期)2018-11-22 06:20:24中央社會主義學院學報(2017年1期)2017-04-16 05:34:07中國衛(wèi)生(2014年12期)2014-11-12 13:12:40
