一種基于濾波的社交網絡隱私保護強度評估方法
2018-04-19 05:09:01吳振強
信息安全研究 2018年4期
溫 閣 顏 軍 胡 靜 吳振強
(陜西師范大學計算機科學學院 西安 710119)
(wenge32@snnu.edu.cn)
社交網絡是現實生活中人與人關系的一種體現.在社交網絡中,用戶可以隨時隨地分享自己的心情狀態、生活照片以及日常活動等信息來增強朋友之間的友誼.但當其發布數據時,用戶的個人身份、朋友關系、習慣、愛好等會被泄露.而現在出現的一系列網絡攻擊事件主要利用的是用戶發布的某些社交網絡數據來挖掘用戶的隱私信息.比如,2017年10月,南非發生史上規模最大的數據泄露事件,共有3160萬份用戶的個人資料被公之于眾,連總統祖馬和多位部長都未能幸免.此次被黑客公布的數據來源于Dracore Data Sciences企業的GoVault平臺,其公司客戶包括南非最大的金融信貸機構——TransUnion.2017年11月22日,美國國防部100 GB的頂級機密在AWS上曝光,據外媒報道稱,美國五角大樓意外暴露了美國國防部的分類數據庫,其中包含美國當局在全球社交媒體平臺中收集到的18億用戶的個人信息[1].因此,如何在大家享受社交網絡便利的同時,保護個人的敏感信息不被泄露成了急需解決的問題.
社交網絡涉及多種角色,并且每個角色之間的關系也相當復雜.為了能夠更加詳細地描述社交網絡中個體之間的關系,可以將社交網絡抽象成圖結構,用節點表示個體,用邊來表示節點之間的關系.因此,通過對圖結構進行研究使我們對社交網絡的了解能夠更加深入.
由于社交網絡中包括許多個人隱私,將其抽象為圖結構后,圖中相應的節點和邊也會涉及到個人敏感信息,因此針對社交圖隱私保護,目前研究者提出了很多種隱私保護的方式,主要分為3類:標識符替換法、差分隱私法、圖結構隱私法.1)標識符替換法.2007年,BackStrom等人[2]提出可以將真實圖數據匿名化,使用一些無意義的標識符來代替保護用戶的身份信息.2)差分隱私法.2009年,Hay等人[3]提出可以利用差分隱私來實現對社交圖中的節點和邊進行保護.3)圖結構隱私法.針對圖結構隱私保護,又分為以下3種.①圖聚類方法.2007年,Zheleva和Getoor[4]針對在圖數據中出現的鏈接關系重識別現象,提出了一種基于邊的圖聚類隱私保護方法.②圖修改技術.Hay等人[5]研究了一個評估共享數據隱私風險的框架并與圖論聯系起來,提出了一種基于擾動的社交圖匿名技術,從而減少了隱私風險.③不確定圖.2012年Boldi等人[6]首次提出一種不確定圖的隱私保護算法,該方法在抗頂點身份攻擊的同時保證了圖結構數據的最小化失真.
目前對隱私保護方法的評價都是從隱私的位置、關系等方面進行評價的.本文中我們借鑒隱私攻擊的方法,從隱私挖掘的角度對隱私保護的強度進行評估.2017年,武漢大學徐正全等人[7]提出了基于濾波原理的時間序列差分隱私保護強度評估,根據信號處理中濾波的原理,設計一個攻擊模型來濾除部分噪聲,并取得了很好的攻擊效果.
現有的社交網絡隱私保護方法大都是使用加噪的方式,借鑒信號處理中濾波的原理,我們在不考慮背景知識的前提下,選擇能夠自動抑制噪聲的維納濾波對鄰近圖進行去噪來提取有用的信息.另外,我們還提出了一種基于濾波的社交圖隱私保護強度評估模型,并在該模型下設計了隱私保護強度評估算法PPIE(privacy preserving intensity evaluation).實驗表明,我們的方法能夠濾除鄰近圖中的部分噪聲,達到了隱私保護強度評價的目的,也為社交網絡隱私保護的理論研究提供了指導.
1 相關工作
在針對社交圖隱私攻擊的研究中,現有的攻擊方式大概有以下幾類:1)節點重識別攻擊.Narayanan等人[8-9]提出利用種子節點來實現對鄰居節點的識別.Abawajy等人[10]提出使用節點對屬性進行節點重識別攻擊,此攻擊利用2個相連頂點的局部區域的信息來識別目標個體.2)屬性重識別攻擊.Zheleva等人[11]研究發現,參與同一小組的用戶傾向于具有相似的屬性,并可利用用戶的群組標簽對用戶可能具有的屬性進行預測.Mislove等人[12]研究發現,用戶可能與其好友具有類似的屬性.可以通過好友公開的信息對用戶未公開的信息進行推測.3)連接關系重識別攻擊.Zhou等人[13]利用朋友間的關系作為弱連接,而將親戚之間的關系作為強鏈接,最后發現兩者有弱連接關系的人更容易形成朋友關系.4)位置社交關系攻擊.Huo等人[14]提出一種以用戶的簽到歷史軌跡、地理位置及各用戶間的關系作為背景的簽到框架,該系統為了檢驗用戶是否真實簽到,將用戶可能去過的所有位置進行預測,并將預測到的位置反饋給用戶.孟小峰等人[15]介紹了位置大數據的概念以及位置大數據的隱私威脅,總結了針對位置大數據隱私統一的基于度量的攻擊模型,對目前位置大數據隱私保護領域已有的研究成果進行了歸納.
為了評價隱私保護的強度,現有的方法是從隱私的位置、關系等方面進行評價.然而,這些方法缺乏具體的評價模型和算法來驗證其有效性,隱私保護強度也無法進行統一性的評價.因此,本文給出一種針對加噪型的社交網絡隱私保護強度評估模型和算法以解決上述問題.
2 相關知識和理論
本文我們將社交網絡抽象成一個無向無權圖G(V,E),其中V表示網絡中所有節點的集合,E表示網絡中所有邊的集合.
2.1 高斯噪聲
高斯噪聲是指它的概率密度函數服從高斯分布的一類噪聲.
高斯分布即正態分布,若隨機變量X服從一個數學期望為μ、方差為σ2的正態分布,記為N(μ,σ2).其概率密度函數為正態分布的期望值μ決定了其位置,其標準差σ決定了分布的幅度.當μ=0,σ=1時的正態分布是標準正態分布.
2.2 維納濾波
1)濾波
從連續的(或離散的)輸入數據中濾除噪聲和干擾,以提取有用信息的過程稱為濾波,這是信號處理中經常采用的主要方法之一,具有十分重要的應用價值.
2)維納濾波
維納濾波是一種基于最小均方誤差準則、對平穩過程的最優估計器.這種濾波器的輸出與期望輸出之間的均方誤差為最小,因此,它是一個最佳濾波系統,它可用于提取被平穩噪聲所污染的信號.
2.3 平均度
一個圖(或網絡)由一些頂點和連接它們的邊構成.每個頂點連出的所有邊的數量就是這個頂點的度,即指此節點的鄰邊數量.對網絡中所有節點的度求平均可得到網絡的平均度[16].
2.4 平均聚集系數
復雜網絡中的聚集系數是用來衡量網絡集團化程度的重要參數,例如在人際關系網絡中你朋友的朋友很可能也是你的朋友,你的2個朋友彼此也可能是朋友,聚集系數就是用來度量網絡的這種性質的參數[16].
1)聚集系數
聚集系數是表示一個圖形中節點聚集程度的系數.在現實世界的網絡,這種可能性往往比2個節點之間隨機設立一個連接的平均概率更大.
在無向網絡中,可以用聚集系數Ci來表示節點v i的聚集系數,如式(1)[16]:
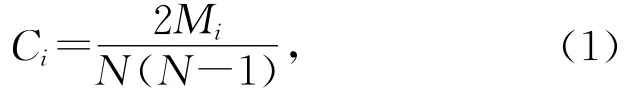
其中,N表示節點個數;Mi表示實際存在的邊數.
2)平均聚集系數
將聚集系數對整個網絡作平均,可得到網絡的平均聚集系數C,如式(2)[16]:
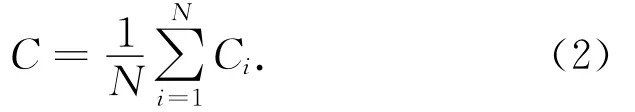
2.5 介數中心性
在一些大型的實際網絡中,每個節點的地位是不同的.要衡量一個節點的重要性其度值可以作為一個衡量指標,但有的節點度雖然小,但它可能是2個集團的中間聯絡人,如果去掉該節點,會導致2個社團的聯系中斷,因此該節點在網絡中起到極其重要的作用.因此引入介數,反映節點或邊在整個網絡中的作用和影響力.
節點vi的介數中心性就是節點v i的歸一化介數,設節點vi的介數為Bi,則其介數中心性CB(vi)可以定義為式(3)[16]:
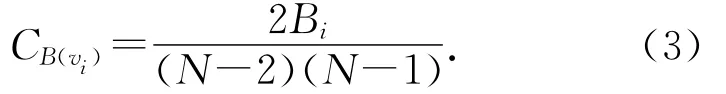
2.6 度分布
度分布是圖論和網絡理論中的概念,度為k的節點在整個網絡中所占的比例就是度分布P(k).度分布滿足式(4)[16]:

3 基于濾波的一種社交網絡隱私保護強度評估方法
由于現有的社交網絡隱私保護方法大都是基于加噪的方式提出的,而在信號處理中可以利用濾波對圖像去噪.而常用的圖像去噪方法有:平滑濾波法、中值濾波法、均值濾波法、維納濾波等.由于維納濾波器能夠自動抑制噪聲的放大,對含噪圖像的復原效果較好,可使具有噪聲干擾圖像的客觀復原性能達到全局意義上的最佳[17].因此,本文在不考慮一定的背景知識情況下,采用維納濾波方法從隱私挖掘的角度評價隱私保護的強度.
本文首先將社交網絡隱私保護強度評估抽象成一個模型,然后在該模型下提出一種基于社交網絡隱私保護強度評估算法PPIE,并對該模型進行說明;然后給出PPIE算法的偽代碼并進行分析;最后,實驗結果表明我們的方法能夠濾除鄰近圖中的部分噪聲,可以達到對隱私保護強度評價的目的.
3.1 社交網絡隱私保護強度評估模型
整體模型(如圖1所示)包括3個部分:第1部分是原圖;中間部分是鄰近圖,即隱私保護后的圖,這里加入的是高斯噪聲,研究者可以根據不同的需求加入不同的噪聲來進行隱私保護;第3部分是去噪圖,在得到鄰近圖后,對鄰近圖進行濾波得到去噪圖,研究者可以根據不同的需求提出不同的隱私保護強度評估算法,具體的隱私保護強度評估模型如圖2所示.在該模型下,我們提出了一種基于社交網絡隱私保護強度評估算法PPIE.

圖1 整體模型

圖2 隱私保護強度評估模型
3.2 PPIE算法
PPIE算法是利用維納濾波來實現社交網絡隱私保護強度的評價,實驗步驟主要由以下5步組成:
1)將圖G(V,E)轉換成鄰接矩陣Matrix;
2)改變高斯噪聲中的σ值,得到帶高斯噪聲的矩陣NoiseMatrix;
3)采用維納濾波對帶噪矩陣NoiseMatrix中的噪音進行濾除,得到矩陣Matrix′;
4)將濾除后的矩陣Matrix′轉換成稀疏矩陣S;
5)將稀疏矩陣S轉換成圖G′.
詳細算法如算法1.
算法1.PPIE算法.
輸入:G=(V,E);
輸出:G′=(V′,E′).

3.3 隱私保護強度評估
為了對隱私保護的強度進行評價,利用維納濾波的方法濾除鄰近圖中的噪聲,并且利用無向圖中的平均度、平均聚集系數、介數中心性和度分布等度量指標來評價隱私保護的強度.若度量指標相等或接近,則說明達到了隱私保護強度評估的目的.同時利用Matlab、Python語言及第三方功能包Network X對本文算法進行程序編程和仿真實驗.實驗數據分為2部分:真實數據集和合成數據集.真實數據集來自于karate和dolphin俱樂部,合成數據集分別為300和500個節點,連接概率是0.3的隨機網絡圖.為了減少實驗數據的隨機性,實驗分別進行了10次模擬取平均值.其中表1為節點個數N分別為34,61,300,500時,原圖與去噪圖的度量指標.AD(average degree)表示圖中節點的平均度,ACC(average clustering cofficient)表示圖中節點的平均聚集系數,BC(betweenness centrality)表示圖中節點的介數中心性.
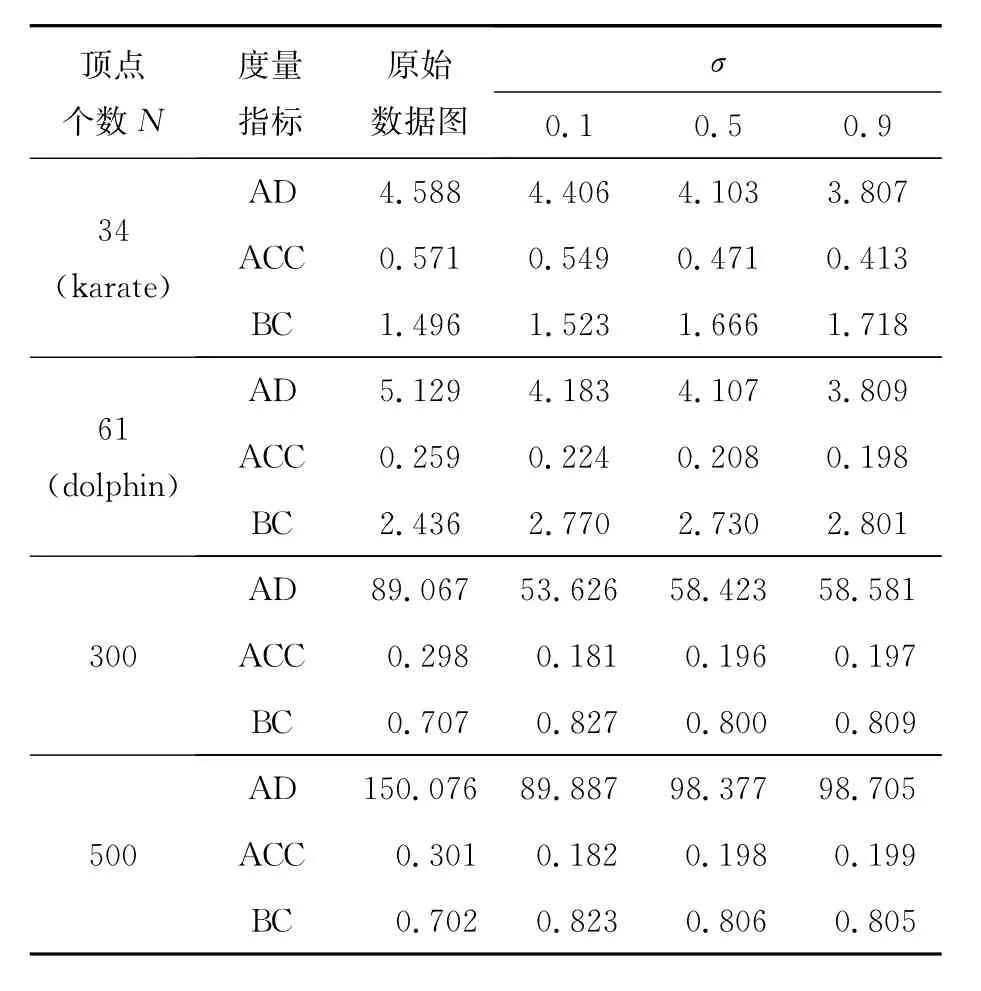
表1 原圖與去噪圖度量指標比較
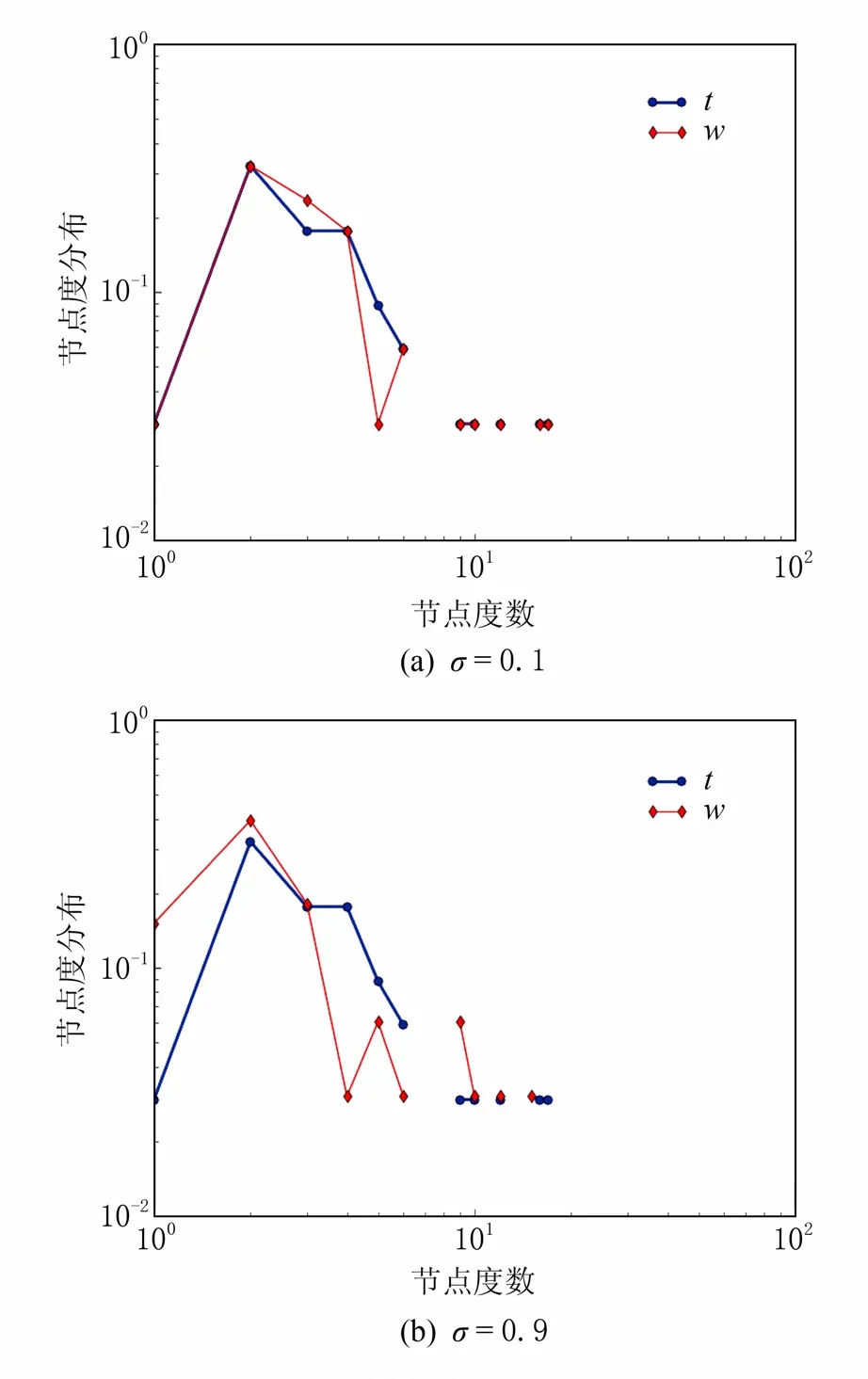
圖3 N=34,σ=0.1和0.9時度分布圖
不同的σ值下,節點個數N為34,61,300,500時對應的度分布圖如圖3~6所示;其中t代表原圖,w代表去噪圖.由于度分布圖的大體趨勢一樣,這里只列出了當σ=0.1和0.9時各節點對應的度分布圖.
通過觀察表1中的度量指標發現,當節點個數較少時,原圖與去噪圖AD的絕對誤差值較小;而無論節點多少,原圖與去噪圖的ACC,BC的絕對誤差值都較小.由此可以看出,經過維納濾波之后得到的去噪圖與原圖的AD,ACC,BC的值與原始圖比較接近;另外,由分布圖可以看出,當σ在(0,1)的范圍內,比較原圖t和去噪圖w,發現兩者
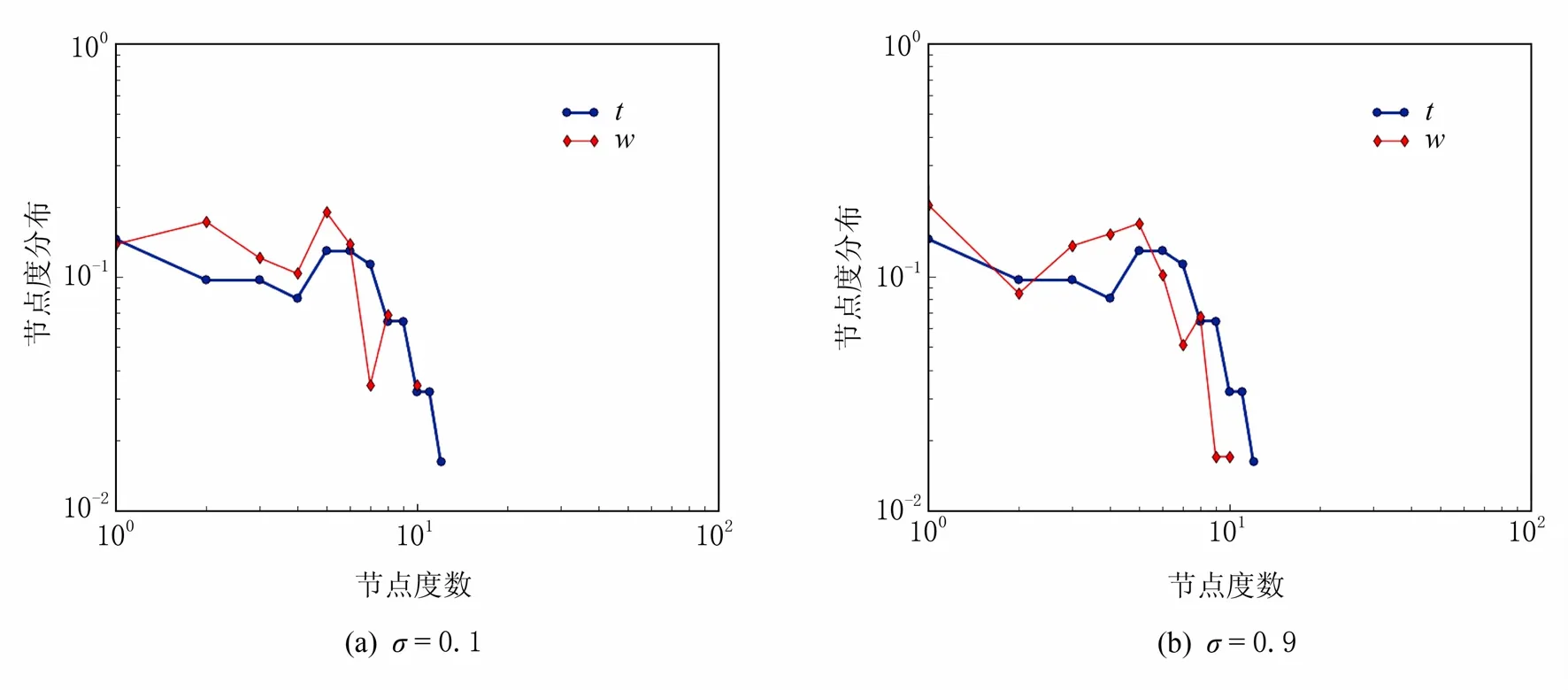
圖4 N=61,σ=0.1和0.9時度分布圖
在變化趨勢上非常接近.當N=34時,隨著節點度數的變化,節點度分布趨勢都是先升后降;當N=61時,隨著節點度數的變化,節點度分布總體趨勢在降;當N=300時,隨著節點度數的變化,節點度分布趨勢都是先升后降,但升到最高點后開始下降,不再上升;當N=500時,隨著節點度數的變化,節點度分布趨勢都是先升后降,與N=300的變化趨勢很接近;通過比較4個數據集的原圖與去噪圖的度量指標發現,經過維納濾波時之后得到的去噪圖與原圖的平均度、平均聚集系數、介數中心性和度分布與原始圖比較接近,達到了隱私保護強度評估的目的.
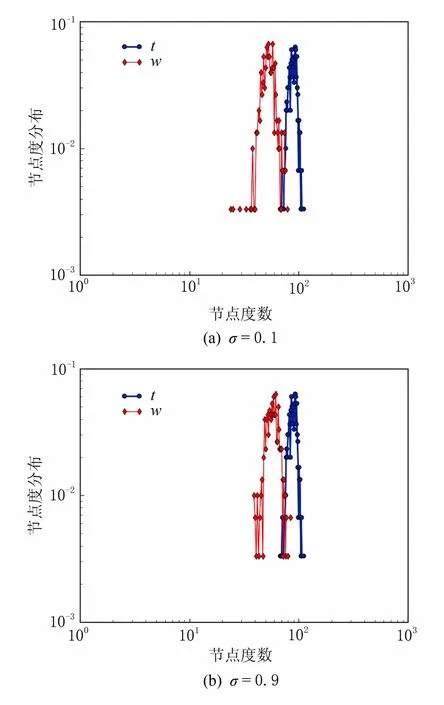
圖5 N=300,σ=0.1和0.9時度分布圖
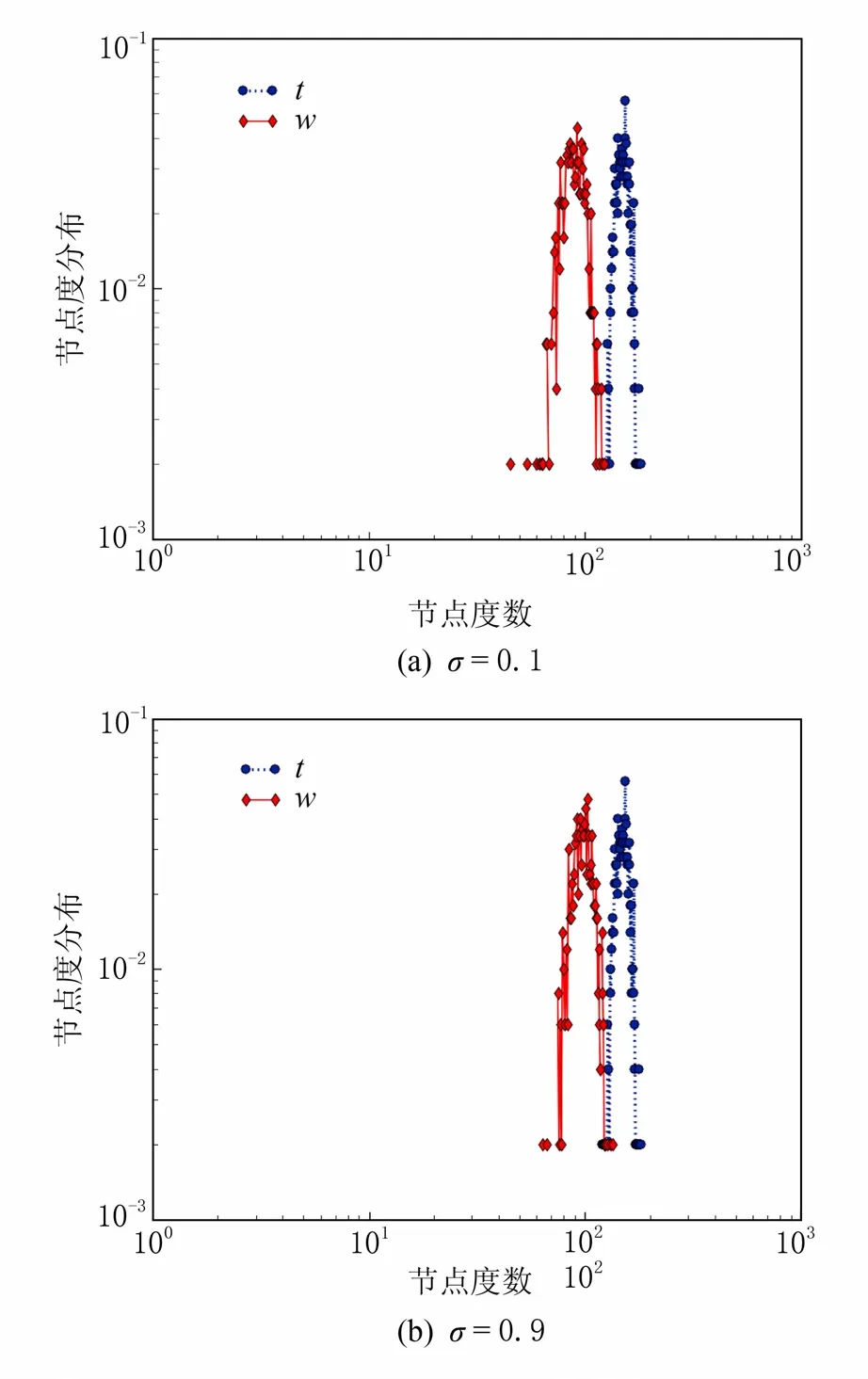
圖6 N=500,σ=0.1和0.9時度分布圖
4 結束語
本文針對加噪型的社交網絡隱私保護方法缺乏統一性評價的問題,在不考慮一定背景知識的前提下,從隱私挖掘的角度,借鑒信號處理中能夠自動抑制噪聲的維納濾波,提出了一種基于濾波的社交網絡隱私保護強度評估模型,并且在該模型下設計了隱私保護強度評估(PPIE)算法.為了驗證該算法的可行性,將算法應用到2個合成數據集和2個真實的數據集中,并比較原圖和經過維納濾波后的去噪圖的度量指標.Matlab和Python仿真實驗結果表明,濾波后的去噪圖和原圖的度量指標基本相似,說明我們的方法達到了評價隱私保護強度的目的,為社交網絡隱私保護的理論研究提供了指導.在接下來的工作中,我們將對濾波的方法再進一步地改進,必要時可以加入相應的背景知識來提高隱私挖掘的效果,從而更好地評價隱私保護的強度.
[1]天下數據IDC.盤點2017全球十大數據泄露事件:一件比一件重量級[EB/OL].[2018-03-20].http://www.sohu.com/a/207652321-99931348
[2]Backstrom L,Dwork C,Kleinberg J.Wherefore art thou r3579x?:Anonymized social networks,hidden patterns,and structural steganography[C]//Proc of the 16th Int Conf on World Wide Web.New York:ACM,2007:181-190
[3]Hay M,Li C,Miklau G,et al.Accurate estimation of the degree distribution of private networks[C]//Proc of IEEE Int Conf on Data Mining.Piscataway,NJ:IEEE,2009:169-178
[4]Zheleva E,Getoor L.Preserving the privacy of sensitive relationships in graph data[C]//Proc of ACM SIGKDD Int Conf on Privacy,Security,and Trust in KDD.Berlin:Springer,2007:153-171
[5]Hay M,Miklau G,Jensen D,et al.Anonymizing social networks[OL].[2018-03-15].https://www.research.gate.net/publication/49250847-Anonymizing-Social-Networks
[6]Boldi P,Bonchi F,Gionis A,et al.Injecting uncertainty in graphs for identity obfuscation[J].Proceeding of the VLDB Endowment,2012,5(11):1376-1387
[7]熊文君,徐正全,王豪.基于濾波原理的時間序列差分隱私保護強度評估[J].通信學報,2017,38(5):172-181
[8]Narayanan A,Shmatikov V.Robust de-anonymization of large sparse datasets[C]//Proc of IEEE Symp on Security and Privacy.Piscataway,NJ:IEEE,2008:111-125
[9]Narayanan A,Shmatikov V.De-anonymizing social networks[C]//Proc of IEEE Symp on Security and Privacy.Piscataway,NJ:IEEE,2009:173-187
[10]Abawajy J,Ninggal M I H,Herawan T.Vertex reidentification attack using neighbourhood-pair properties[J].Concurrency and Computation:Practice and Experience,2016,28(10):2906-2919
[11]Zheleva E,Getoor L.To join or not to join:Theillusion of privacy in social networks with mixed public and private user profiles[C]//Proc of Int Conf on World Wide Web.New York:ACM,2008
[12]Mislove A,Viswanath B,Gummadi K P,et al.You are who you know:Inferring user profiles in online social networks[C]//Proc of the 3rd Int Conf on Web Search and Web Data Mining.New York:DBLP,2010:251-260
[13]Zhou Tao,LüLinyuan,Zhang Yicheng.Predicting missing links via local information[J].European Physical Journal B,2009,71(4):623-630
[14]Huo Zheng,Meng Xiaofeng,Zhang Rui.Feel free to check-in:Privacy alert against hidden location inference attacks in GeoSNs[C]//Proc of Int Conf on Database Systems for Advanced Applications.Berlin:Springer,2013:377-391
[15]王璐,孟小峰.位置大數據隱私保護研究綜述[J].軟件學報,2014,25(4):693-712
[16]郭世澤,陸哲明.復雜網絡基礎理論[M].北京:科學出版社,2012
[17]盧虹冰.醫學成像及處理技術[M].北京:高等教育出版社,2013
