基于高性能IO技術的Memcached優化研究
2018-04-16 12:02:24安仲奇霍志剛
計算機研究與發展 2018年4期
安仲奇 杜 昊,2 李 強 霍志剛 馬 捷
1(中國科學院計算技術研究所高性能計算機研究中心 北京 100190) 2 (中國科學院大學計算機與控制工程學院 北京 100049) (anzhongqi@ncic.ac.cn)
內存對象緩存系統是互聯網服務架構的重要組成部分,對服務性能及體驗有著至關重要的影響.隨著互聯網的飛速發展,為應對用戶量與數據量的爆炸式增長,互聯網服務架構普遍采用內存對象緩存系統來降低請求響應延遲、提高服務吞吐率.在典型的互聯網服務系統中,由于傳統數據庫提供的結構化查詢機制開銷較大,難以承載大量的訪問請求.利用內存對象緩存系統緩沖查詢結果,在以讀操作為主的場景中,能夠將大量昂貴的數據庫查詢轉換為簡單高效的內存鍵值訪問,從而降低訪問延遲、改善用戶體驗.Memcached[1]是應用最為廣泛的內存對象緩存系統之一,已于諸多互聯網服務中大規模部署,其使用者中不乏Facebook[2]、Twitter[3]、阿里巴巴[4]等知名互聯網服務提供商.
目前的內存對象緩存系統,在通信方面受制于傳統以太網的高延遲,在存儲方面受限于服務器內可部署的內存規模,其性能與容量難以應對未來海量數據下用戶體驗的挑戰.一方面,互聯網服務的競爭在很大程度上是用戶體驗的競爭,在單網頁數據量快速增加的背景下,為了保持良好的用戶體驗,內存對象緩存系統必須提升響應速度,否則將給互聯網服務商帶來嚴重的損失.相關統計結果表明,網頁加載時間超過2 s,3 s,8 s以后,分別會有47%,57%,99%的用戶選擇離開.網頁加載時間每增加1 s,就會造成網站流量轉化率下降7%,頁面訪問量下降11%,以及用戶好評率下降16%[5].另一方面,由于互聯網數據總量的快速攀升,內存對象緩存系統在存儲空間方面的不足將更加凸顯.據思科系統公司估計,從2014—2019年,全球互聯網流量的年均增長率為23%[6].隨著互聯網服務系統處理的數據規模越來越大,內存對象緩存系統所需緩存的數據量必然水漲船高.在數據爆炸的時代,現有內存對象緩存系統受服務器內存容量限制的弊端將愈發明顯.
本文以Memcached為例,聚焦數據通路,研究基于高性能IO的內存對象緩存系統的通信加速和存儲擴展問題.本文的主要貢獻有3個方面:
1) 提出了一種基于RDMA語義的Memcached通信協議,支持應用廣泛的Java客戶端并面向Java虛擬機(Java virtual machine,JVM)內存管理機制進行了優化.
2) 設計了一種基于NVMe SSD的Memcached服務端存儲擴展機制,采用日志結構管理內存與外存2級存儲,并通過用戶級驅動實現對SSD的直接數據訪問以最大限度地降低軟件開銷.
3) 實現了高效緩存系統U2cache,通過改造、優化Memcached數據通路,旁路操作系統內核與Java虛擬機運行時,數據訪問與傳輸均于用戶態本地環境中完成,并針對不同的數據訪問場景設計了不同的優化策略.相比標準版的Memcached,U2cache能夠顯著降低通信延遲并高效擴展存儲容量.
1 U2cache設計與實現
U2cache緩存系統基于高性能網絡與存儲硬件,采取直通式數據IO的架構.圖1給出了U2cache內部架構與傳統Memcached的比較.U2cache服務端與Java客戶端之間采用高性能RDMA通信取代傳統的BSD sockets機制,基于RDMA語義重新設計了Java感知的通信協議,并針對不同操作及消息大小采取不同的優化策略,大幅降低了Memcached操作延遲.服務端使用高性能NVMe SSD作為內存的擴展,采用2級日志式數據管理結構以提高存儲效率;同時于用戶空間直接訪問SSD,旁路操作系統并進一步降低軟件開銷.通過IO與通信的聯合優化,U2cache能夠顯著改善高性能并提高容量.其他方面,U2cache則是沿用了Memcached原有的架構與機制,包括客戶端一致性Hash算法、slab內存管理機制、LRU(least recently used)淘汰算法等[7].
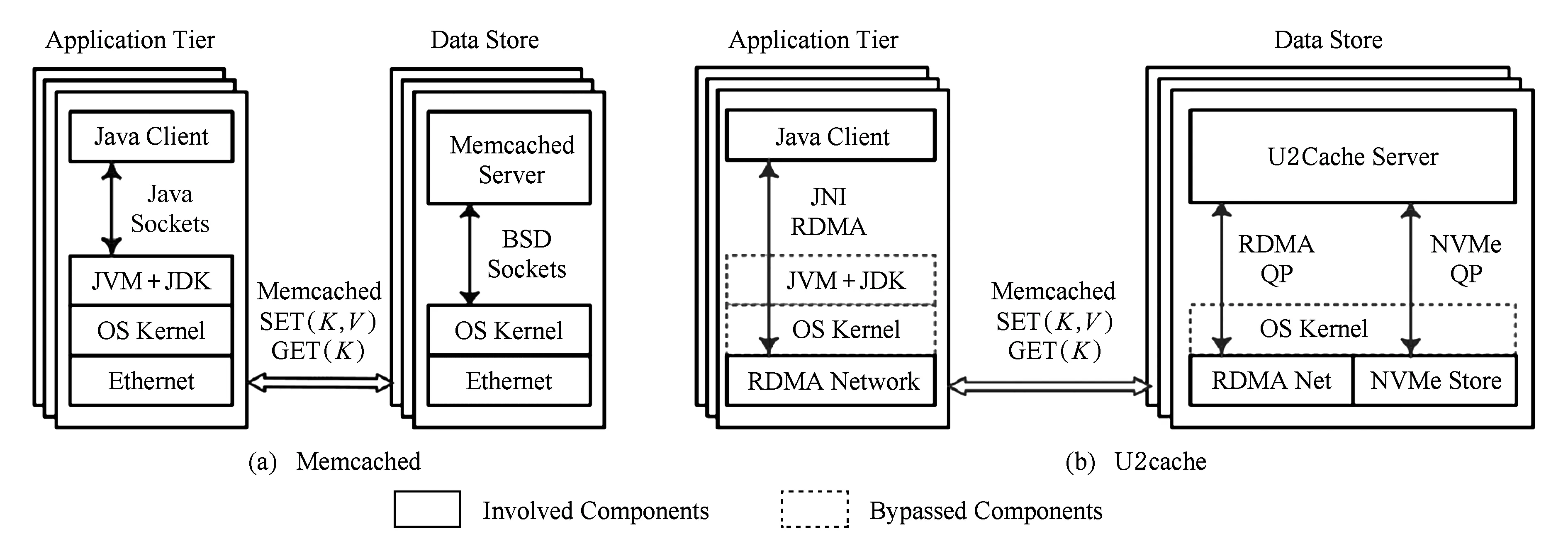
Fig. 1 Comparison of the internal architectures of Memcached and U2cache圖1 Memcached與U2cache架構比較
1.1 基于RDMA的通信協議
現有開源Memcached實現大都基于傳統的BSD sockets接口以及TCPIP協議棧.在傳統網絡機制下,操作系統復用對網絡的訪問;用戶程序進行網絡通信時,數據需在用戶空間與內核空間之間拷貝,并進行用戶態與內核態的上下文切換,加之TCPIP協議棧的處理需占用較多的處理器資源,導致傳統通信方式下軟件開銷較大.相較而言,RDMA由網卡直接讀寫數據而無額外的數據拷貝,InfiniBand網絡傳輸層亦由硬件實現而無需軟件處理;用戶程序通過“虛接口”(即queue pair)直接訪問網絡硬件,操作系統僅參與通信連接的初始化與建立,不干涉數據傳輸.
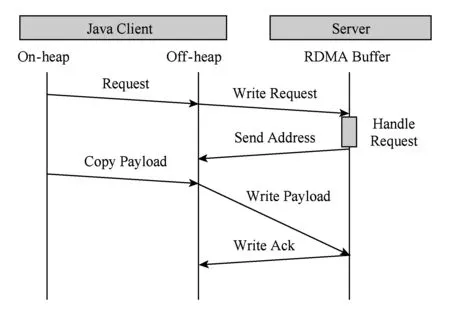
Fig. 2 Rendevzous-based SET protocol圖2 基于rendevzous協議的SET操作
U2cache基于RDMA提供的直接內存讀寫語義,重新設計了服務端與客戶端之間的通信協議,并使用底層InfiniBand Verbs API[11]實現.基于RDMA的數據通信根據消息大小采取了不同的優化策略.在U2cache中,服務端與客戶端之間的通信過程不只是單向的數據載荷的傳輸,還包括附加消息頭、狀態標識等的控制信息的傳輸.MPI(message passing interface)是高性能計算領域消息通信的事實標準,本文借鑒基于RDMA的MPI實現方法[12]并結合Memcached操作的特點,將SET小消息傳輸采取有拷貝的eager協議[13]進行通信,而SET大消息操作則采用無拷貝的rendevzous協議[13],如圖2所示.受限于JVM內存訪問的限制,GET操作采取類似eager的有拷貝傳輸方式,如圖3所示.為獲得最佳延遲,數據載荷的傳輸均采用基于可靠連接的RDMA Write操作;部分控制信息的傳輸則采用了SENDRECV原語.
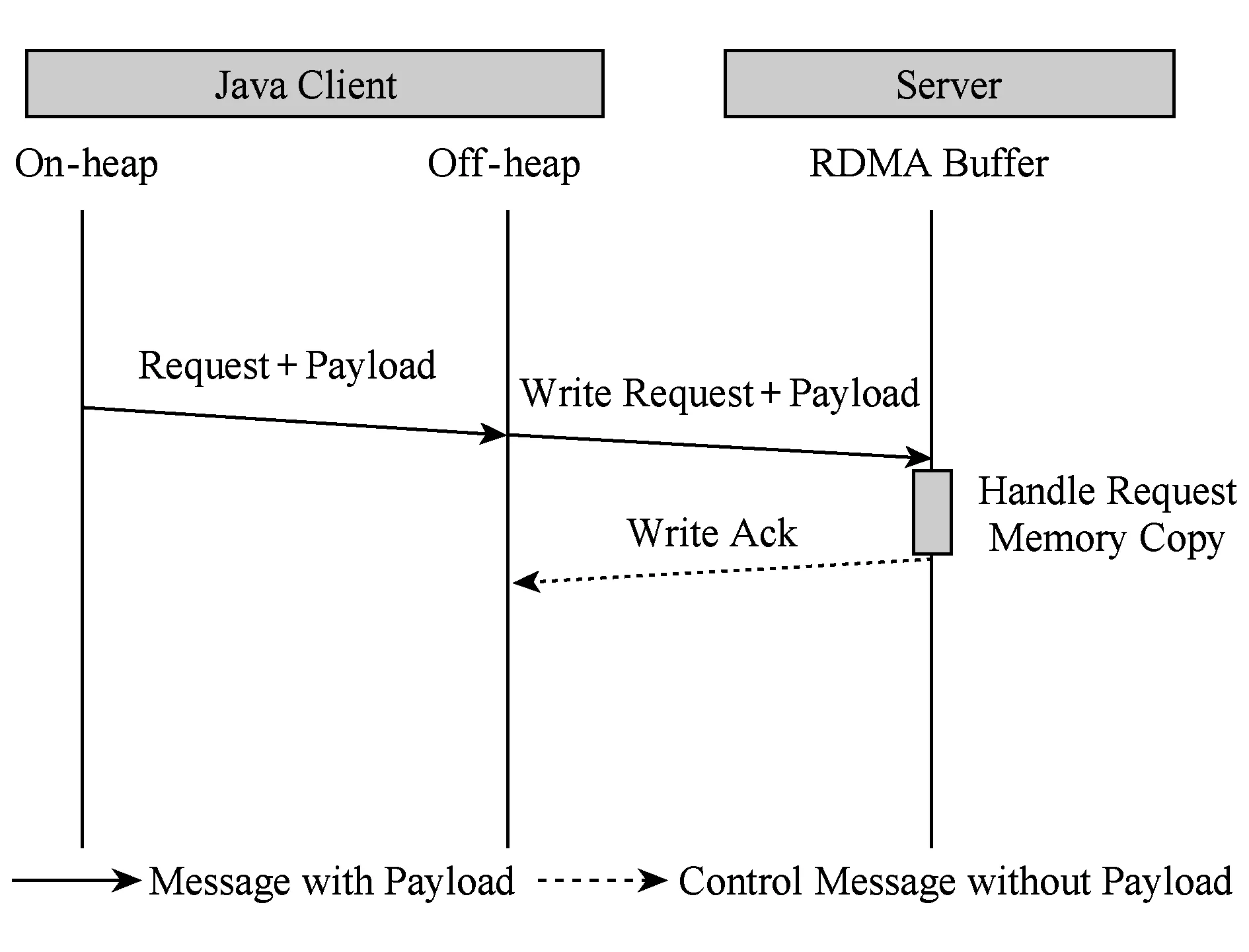
Fig. 3 Eager-like GET protocol圖3 有拷貝的類eager協議的GET操作
1.2 Java RDMA通信支持
U2cache選取了應用更為廣泛的Memcached Java客戶端進行改造與優化.Java本身是一種受限的運行時環境,Java字節碼于JVM中執行以提供可控性與安全性,但引入了額外的軟件開銷.JVM堆采取了垃圾回收的內存管理機制,堆內(on-heap)內存無法直接參與RDMA通信,目前主流的JDK實現亦未提供對RDMA網絡的支持.
U2cache設計開發了高性能的Java RDMA通信庫[14],通過Java本地接口(Java native interface, JNI)[15]接口實現旁路JVM以直接訪問InfiniBand Verbs API;另外,Java的直接字節緩沖位于堆外(off-heap),可由操作系統鎖定(pin)并注冊,進而實現RDMA通信.但是,絕大多數情況下,Java代碼并不使用堆外內存;將數據需拷貝至堆內或反序列化為堆內的對象更加適用Java的應用場景.因而,考慮JVM堆內內存與堆外內存之間的數據拷貝開銷更具實際意義.相比RDMA網絡的性能,堆內-堆外數據傳輸開銷不可忽略.U2cache針對不同的操作類型和不同的消息大小,通過服務端與客戶端的協作以及內存拷貝與RDMA通信的交疊流水化,最大限度地掩藏數據拷貝的開銷,大幅降低了JVM環境下Memcached操作的通信延遲.
1.3 基于NVMe的存儲擴展
與傳統硬盤機械運動及磁極翻轉的機制不同,SSD本質是由高速閃存顆粒組成的陣列,其并行度高、訪問延遲低.基于PCIe的高性能SSD接口規范NVMe采用了與RDMA類似的隊列機制接口[16],與傳統SATASAS接口相比,其協議棧大幅簡化,進而釋放了SSD架構與NVM介質的性能潛力,縮短了2級存儲與內存之間的性能差距.
U2cache基于NVMe SSD對Memcached的存儲空間進行了擴展.U2cache沿用了Memcached的slab內存管理機制,內存與SSD均被視作slab對象存儲.具體來說,slab分為內存slab與磁盤slab,分別由先進先出的日志維護.在內存存儲用盡時,內存slab隊列的隊頭數據被寫入SSD以得到可用slab;當SSD容量用盡時,磁盤slab隊列的隊頭數據將被驅逐.slab的大小取為MB的整數倍,這樣可將隨機寫于內存中聚合,再以順序寫的方式寫入SSD,避免了大量小數據隨機寫對SSD性能與壽命的影響.U2cache于內存中維護全部的數據索引,SSD中僅存儲數據;這樣在緩存未命中時不會訪問SSD、命中時最多只發生1次IO訪問.U2cache采用了只追加的寫方式,SSD中的數據不會被原地更新,故存儲的slab沒有固定的地址;另外,刪除slab時僅刪除索引而不刪除數據,SSD中沒有被索引的slab對象將在容量寫滿時被自動回收,進一步避免了隨機寫.
雖然NVMe SSD性能取得了大幅提升,但目前仍與內存有一定的性能差距.在軟件方面,開銷主要來自傳統操作系統的存儲軟件棧.以Linux內核為例,訪問SSD的最短路徑是:用戶進程發起IO讀寫系統調用將上下文切換至內核態,經由塊IO層隊列調度與設備驅動后到達設備.如若涉及文件系統,則需首先經過更上層的虛擬文件系統(virtual file system, VFS)層,將引入更多的軟件處理開銷甚至額外的數據拷貝.過厚的存儲軟件棧限制了NVMe SSD性能的發揮,難以獲得最佳的延遲表現.Linux的塊IO層自3.13版本開始引入了多隊列機制[17],利用多核處理器來獲取最佳性能.但對較少核心數量的情況,由于中斷處理等的開銷,為獲得更好的性能,需要更高主頻的處理器.
為進一步降低軟件開銷,U2cache借助了由Intel公司開源的SPDK(storage performance development kit)[18]所提供的NVMe用戶級驅動來實現對SSD的直接訪問.SPDK支持標準NVMe設備,使用前需將設備從內核驅動“解綁”,然后將設備的PCI地址空間映射至用戶進程空間,此后設備即由用戶級驅動“接管”,內核不再干涉.SPDK采用輪詢模式取代中斷機制來處理設備的完成事件,并通過設定處理器核親和度綁定、使用物理連續的大頁內存等的方法來進一步屏蔽性能干擾.這樣,通過旁路操作系統內核并采用輪詢模式,避免了系統調用、中斷處理等的上下文切換所帶來的延遲開銷.在此種機制下,較低主頻的單一處理器即可獲得設備的最佳性能.
另外,U2cache還通過SSD訪問與RDMA通信交疊流水化、數據分散化寫以充分利用SSD多通道等的優化,進一步掩蓋了延遲.
2 U2cache數據通路優化
2.1 通信通路優化
當傳輸小消息時,RDMA通信與U2cache服務端處理的占據總延遲的絕大比例,且二者必須順序執行,缺少進一步優化的空間.
當傳輸大消息時,Memcached的SET與GET操作均存在并行優化的空間.以寫緩存SET操作為例,其具體流程如圖2所示,延遲主要包括:握手延遲、堆外與堆內之間數據拷貝延遲、RDMA通信延遲、發送狀態延遲.如圖4所示,雖然RDMA通信延遲所占比重依舊最大,但隨著消息變大,堆外與堆內之間的內存拷貝延遲越來越顯著,而且握手過程始終會帶來約3 μs的延遲.在不影響程序正確性的前提下,可盡可能讓數據拷貝與握手操作以及數據傳輸交疊并行執行以降低整體延遲.
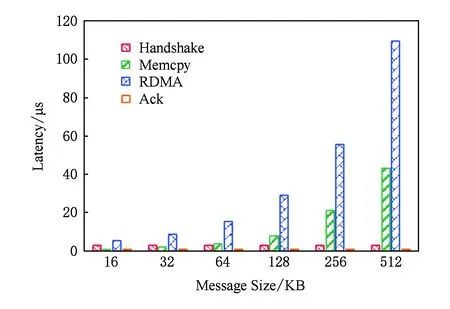
Fig. 4 Latency of each stage in the SET operation圖4 SET操作中各階段延遲
2.1.1 數據分片流水
針對大消息傳輸,本文提出了數據分片后內存拷貝與RDMA通信并行流水的優化方法.之所以能夠進行較好的交疊優化,主要是由于RDMA數據傳輸完全由硬件設備完成,CPU被旁路,RDMA通信與內存數據拷貝可以同時進行.另外,對相同大小的數據而言,RDMA通信延遲高于內存拷貝延遲,故每次拷貝能夠在RDMA通信結束前完成.經過內存拷貝與RDMA通信交疊優化后的SET與GET過程分別如圖5和圖6所示:
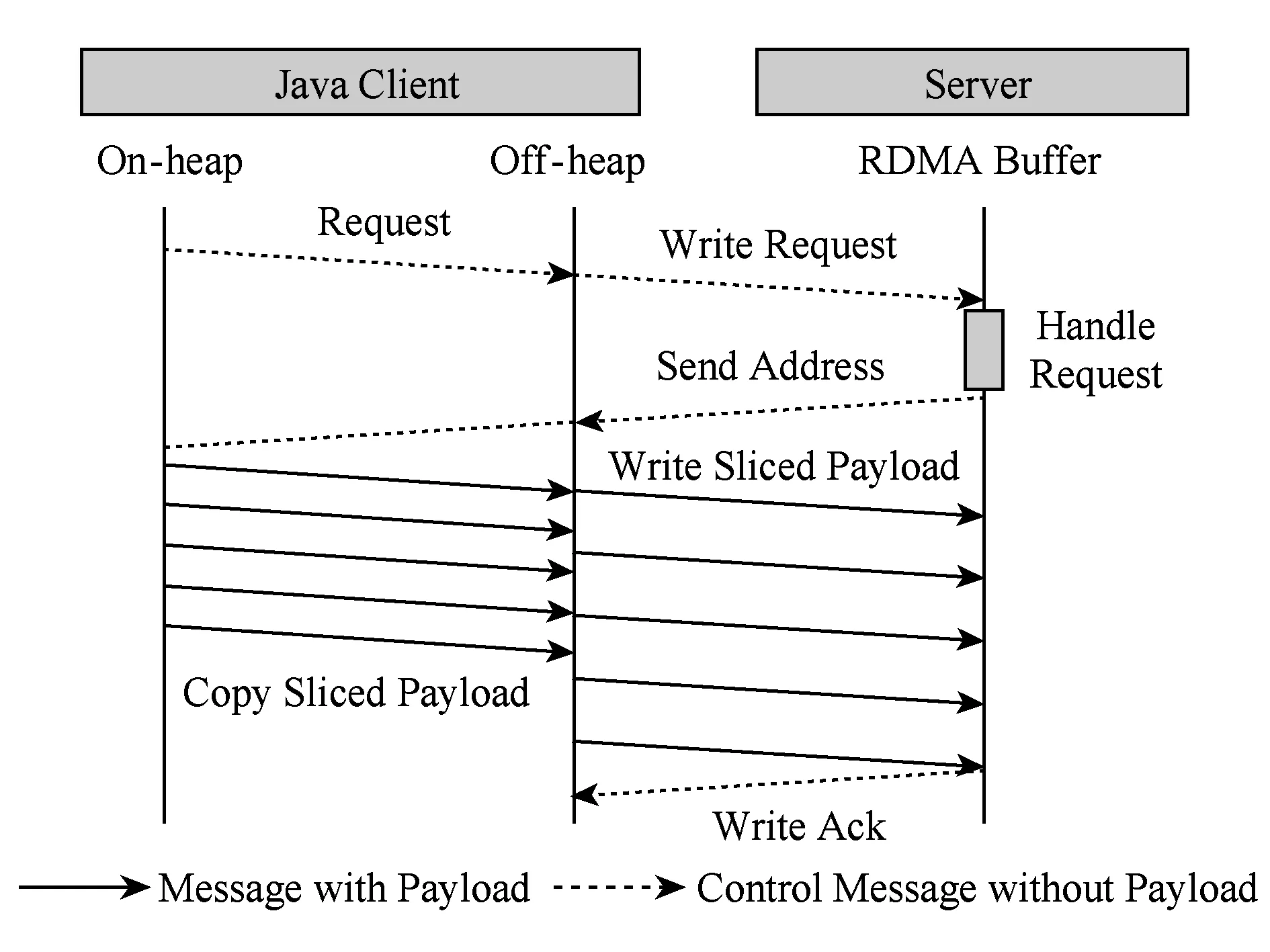
Fig. 5 Overlapping of Memcpy and RDMA transfer in SET圖5 SET操作中內存拷貝與RDMA通信交疊
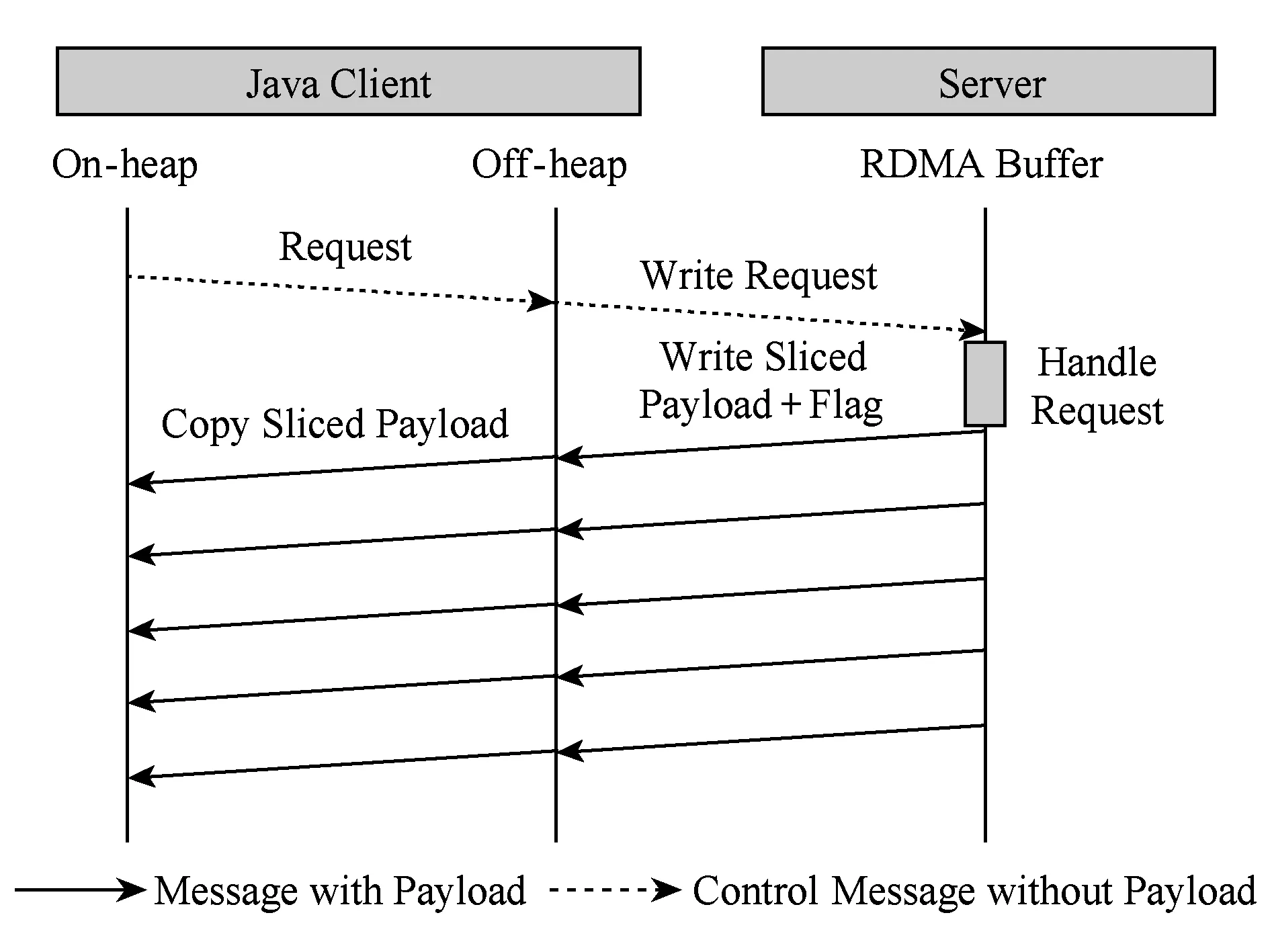
Fig. 6 Overlapping of Memcpy and RDMA transfer in GET圖6 GET操作中內存拷貝與RDMA通信交疊
在SET操作中,分片后的數據載荷由堆內逐個拷貝至堆外;每片拷貝結束后立即發起相應的RDMA傳輸,然后繼續下段分片的拷貝.GET流程采取了類似的分片流水方法,不同的是每段分片的RDMA通信結束后服務端立即發送相應標識位,以供客戶端同步通信與拷貝;這也意味著GET命令引入了額外的網絡通信,限制了延遲掩藏的效果.
2.1.2 RME通信協議
針對大消息SET操作,為進一步掩藏3 μs的握手延遲,本文提出了一種新的通信協議——RME(rendezvous mixed with eager)協議.RME通信協議規定:1)客戶端向服務端發送請求后,不等待握手響應立即開始向服務端預設緩沖區按分片流水的方式發送數據;2)服務端收到請求并解析后返回數據存放地址;3)客戶端在收到地址回復后,首先通知服務端已發送的數據大小,然后將剩余數據繼續以分片流水的方式發送到新地址;4)服務端在獲知已接收的數據大小后,將該部分數據拷貝到新地址.采用RME通信協議后的SET操作流程如圖7所示.這樣,通過服務端與客戶端之間的協作,最大限度地降低大消息的SET延遲.
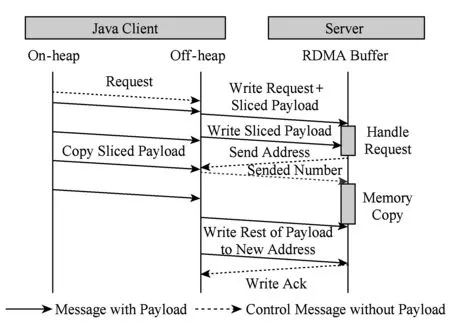
Fig. 7 RME-based SET protocol圖7 采用RME協議的SET操作過程
2.2 IO與通信聯合優化

Fig. 8 Latency of each stage in SSD GET operation圖8 SSD GET操作中各階段延遲
在傳輸大消息的GET操作中,SSD讀操作與RDMA通信存在并行流水優化的空間.對于SSD中的數據,服務端需要先將數據從SSD讀到內存,再進行RDMA通信.另外,客戶端每接收到服務器發送來的數據分片,就會將數據從RDMA緩沖區拷貝到JVM堆內存上.SSD讀操作、RDMA通信和內存拷貝這3個階段占據了GET操作的絕大部分延遲.實驗測得各類操作延遲如圖8所示:當消息較小時,SSD讀延遲遠遠大于RDMA通信延遲和拷貝延遲;隨著消息變大,受益于SSD的多通道機制,SSD讀延遲增長緩慢,而RDMA通信延遲和拷貝延遲快速增加,在總延遲中占比擴大.
當發送位于SSD數據區的較大數據時,GET操作采用SSD讀操作與RDMA通信并行流水方法,其流程如圖9所示.服務端將數據分片后按序將從SSD讀取至內存的RDMA緩沖區中;每次SSD讀操作完成后立即發起RDMA傳輸,并隨之傳輸相應標記位;客戶端每接收到1段數據分片,就將該部分數據拷貝到JVM堆內存上;該過程一直持續到客戶端完成最后1段數據分片的拷貝.
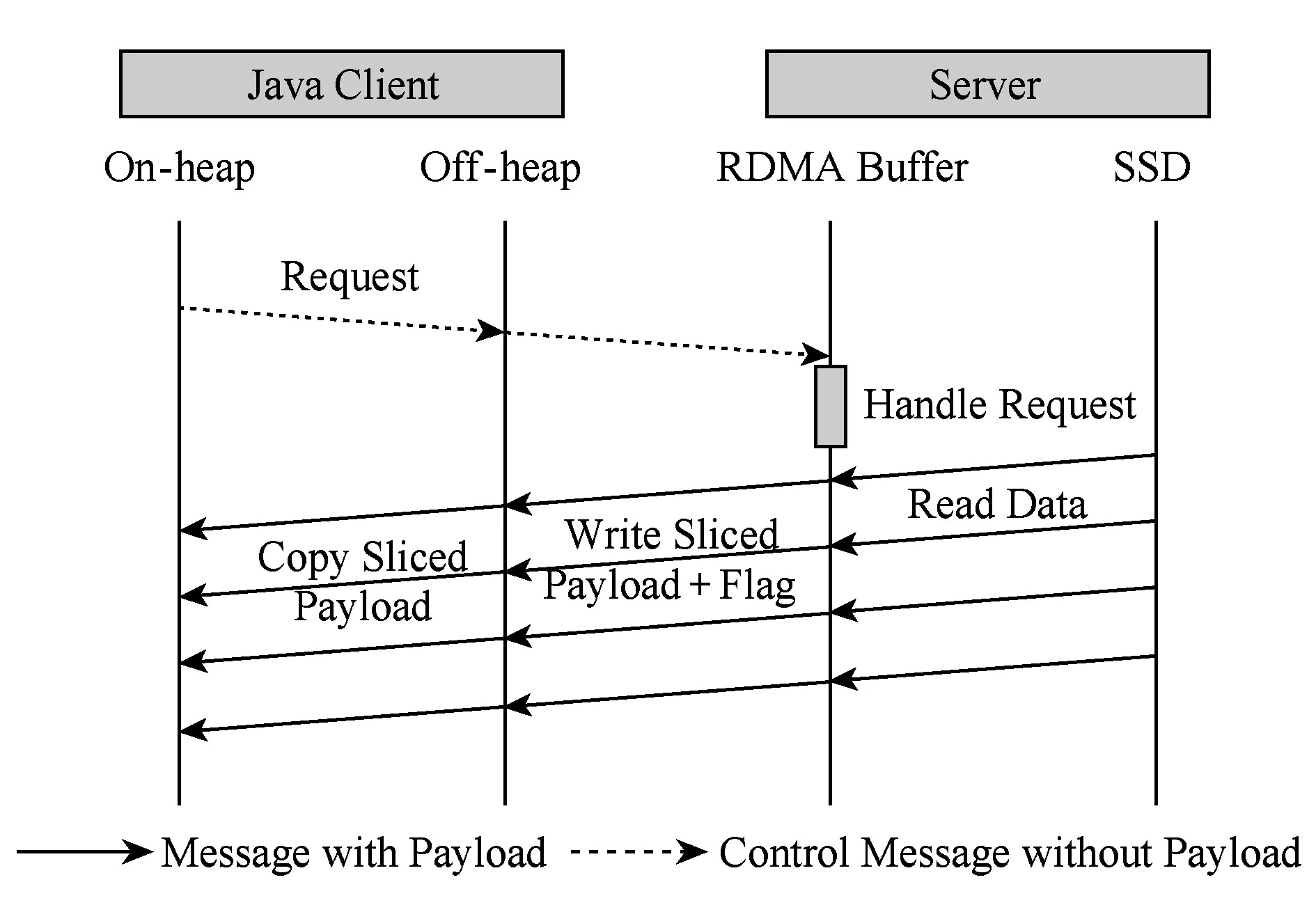
Fig. 9 Overlapping SSD read and RDMA communication in SSD GET operation圖9 SSD GET操作中SSD讀與RDMA通信交疊
3 性能評測
本節對U2cache緩存系統進行性能評測與分析.測試平臺選取3臺物理服務器節點,每個節點配有雙路Intel Sandy-Bridge Xeon E5-2650處理器,主頻為2.00 GHz,每顆處理器具備8個核心,20 MB最外層緩存.每節點配有32 GB DDR3內存.RDMA網絡采用了InfiniBand FDR網絡,每節點配有Mellanox MT27500 56 Gbps網卡.NVMe SSD選用了Intel P3700 SSD,容量為400 GB.操作系統為CentOS 6.7,內核版本為2.6.32-573,JVM版本為1.7.0_79.選取其中1個節點部署U2cache服務端,另外2個節點部署U2cache客戶端.本文將U2cache緩存系統和俄亥俄州立大學實現的基于RDMA優化的Memcached系統(下文以OSU-Memcached或OSU-MC代指)于相同平臺進行了測試對比,具體版本為0.9.4.OSU-MC基于高度優化的MVAPICHUCR重寫,其是高性能通信系統的代表.
3.1 SET延遲
當消息小于1 KB,SET操作延遲不超過5 μs.如圖10所示,在傳輸大消息時,SET操作采用RME通信協議時延遲最低.這是由于:首先,RME通信協議是在內存拷貝與RDMA通信并行流水方法的基礎上實現的,能夠隱藏數據拷貝的延遲;其次,RME通信協議還隱藏了SET操作發起時客戶端與服務端的握手延遲.如圖10所示,在傳輸的數據長度分別為64 KB,128 KB,256 KB,512 KB時,相對于采用未流水化的RDMA通信方式,SET操作采用內存拷貝與RDMA通信并行流水優化后的延遲分別降低4%,13%,22%,26%,而采用RME協議后的延遲分別降低7%,18%,26%,28%.如圖11所示,當消息長度不超過4 KB時,U2cache和OSU-Memcached的SET操作延遲相當;當消息長度超過16 KB時,U2cache比OSU-Memcached的SET操作的延遲要低,這主要得益于U2cache采用的RME協議隱藏了握手延遲.SET操作數據接收方為U2cache服務端,不受JVM限制,數據通路終點無額外路徑開銷,故而可獲得與完全本地化的OSU-Memcached相當的性能.
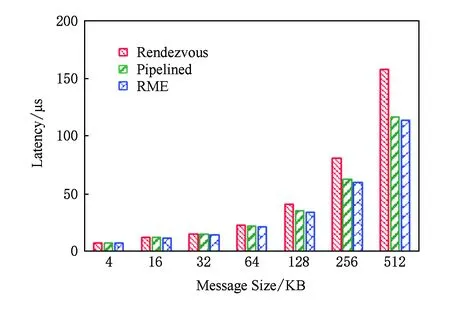
Fig. 10 Comparison of latency of SET operations圖10 SET操作延遲對比
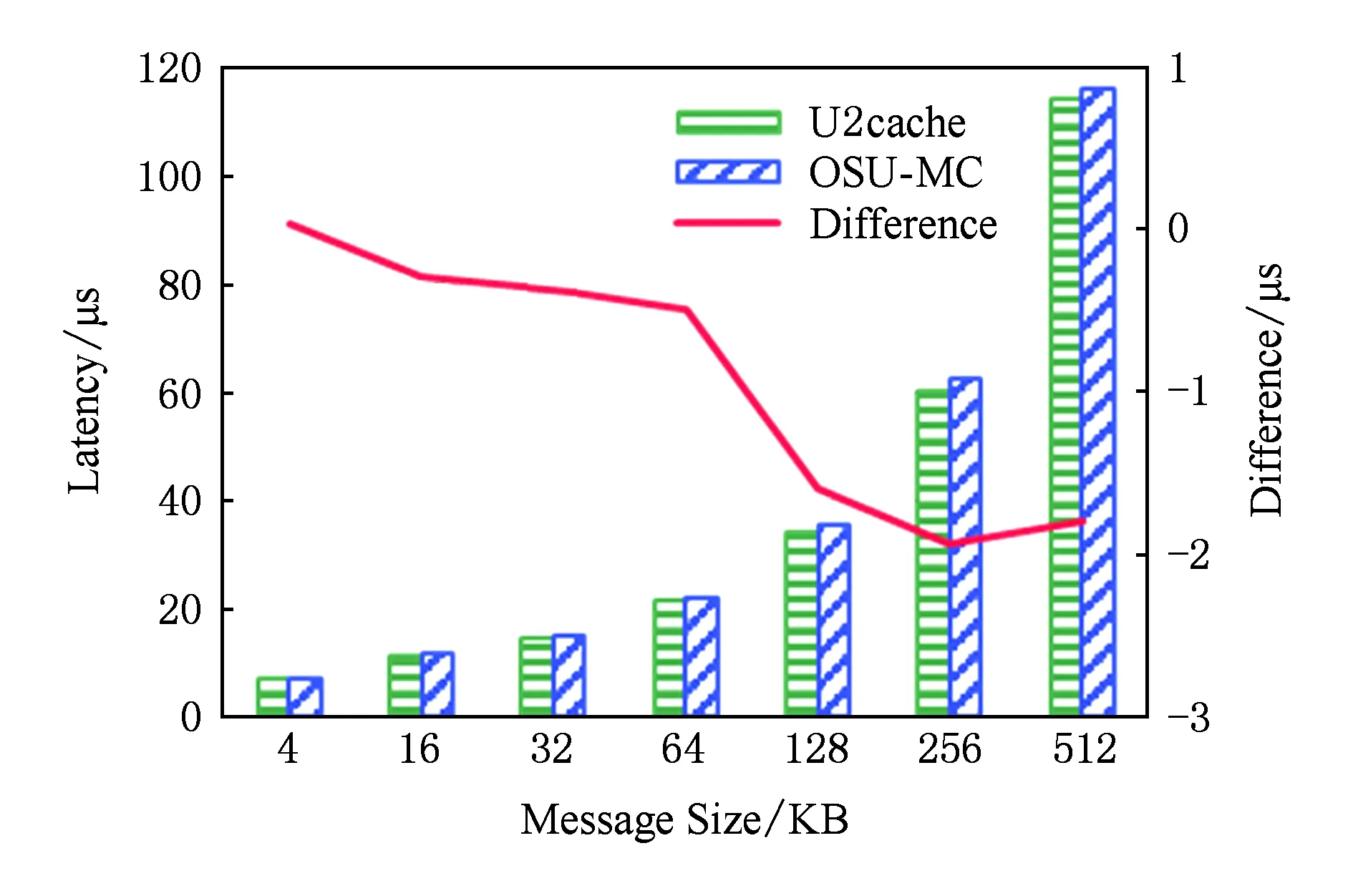
Fig. 11 Comparison of U2cache and OSU-Memcached on SET圖11 U2cache與OSU-Memcached SET延遲比較
3.2 GET延遲
低于1 KB的小消息GET操作延遲不超過6 μs.在傳輸大消息時,GET操作實現了內存拷貝與RDMA通信并行流水優化.如圖12所示,當傳輸的數據長度分別為64 KB,128 KB,256 KB,512 KB時,相對于未經優化的方式,GET操作采用內存拷貝與RDMA通信交疊優化后的延遲分別降低13%,17%,24%,27%.不過,受JVM數據拷貝開銷的影響,GET延遲始終高于OSU-Memcached.如圖13所示,在消息長度低于4 KB以及大于256 KB時,U2cache與OSU-Memcached的GET延遲差距稍大,但差距最大不超過2 μs.對小消息而言,開銷主要源自請求命令序列化與數據向堆內的拷貝;對大消息而言,開銷主要是堆內與堆外之間的數據拷貝.當消息大小為16 KB,32 KB,64 KB,128 KB時,并行流水的優化拉近了性能差距;但隨著消息大小的繼續增長,性能差距再次被拉大,這是由于伴隨每個消息分片而傳輸的控制信息造成的通信開銷累加.
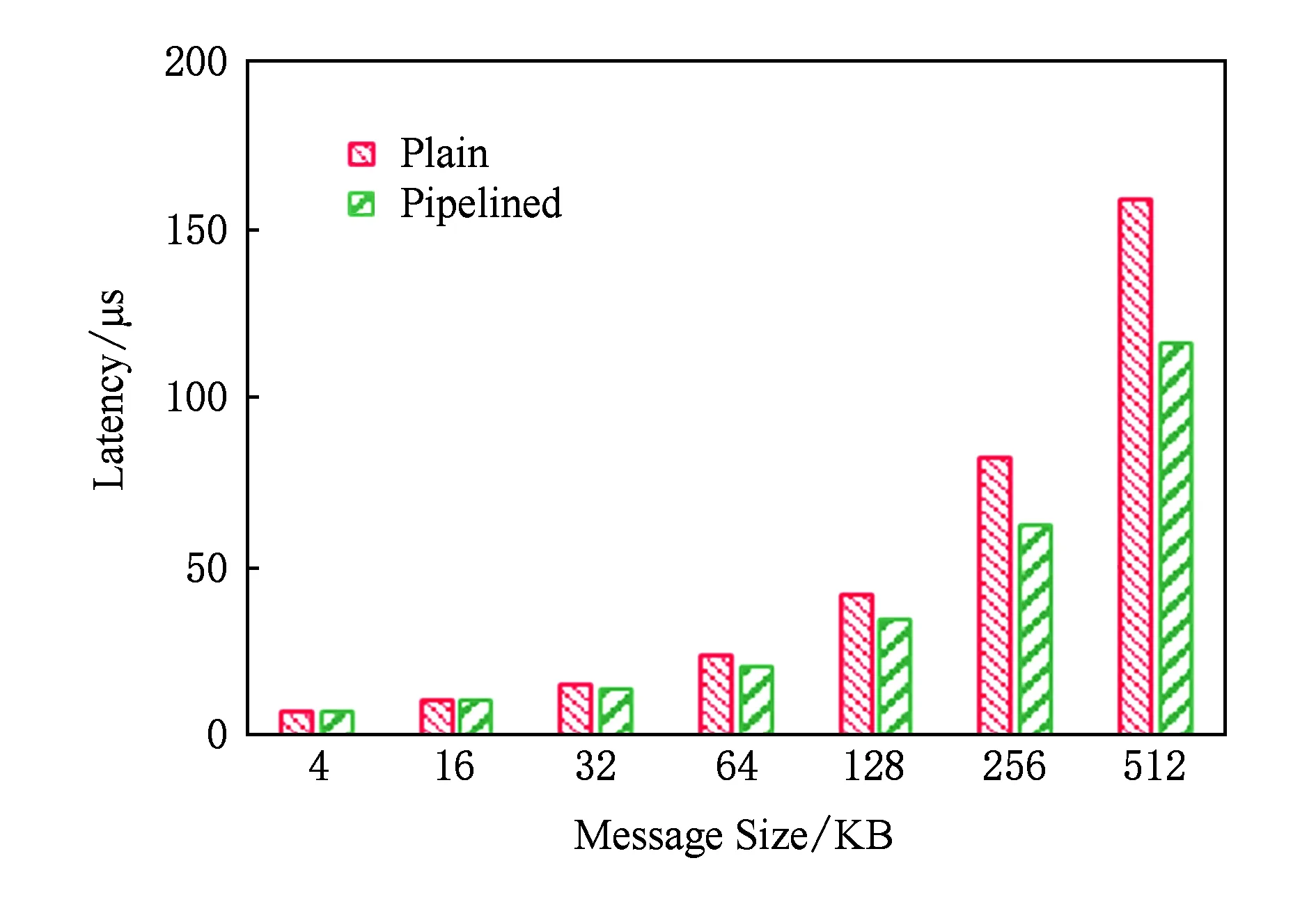
Fig. 12 Comparison of latency of GET operations圖12 GET操作延遲對比
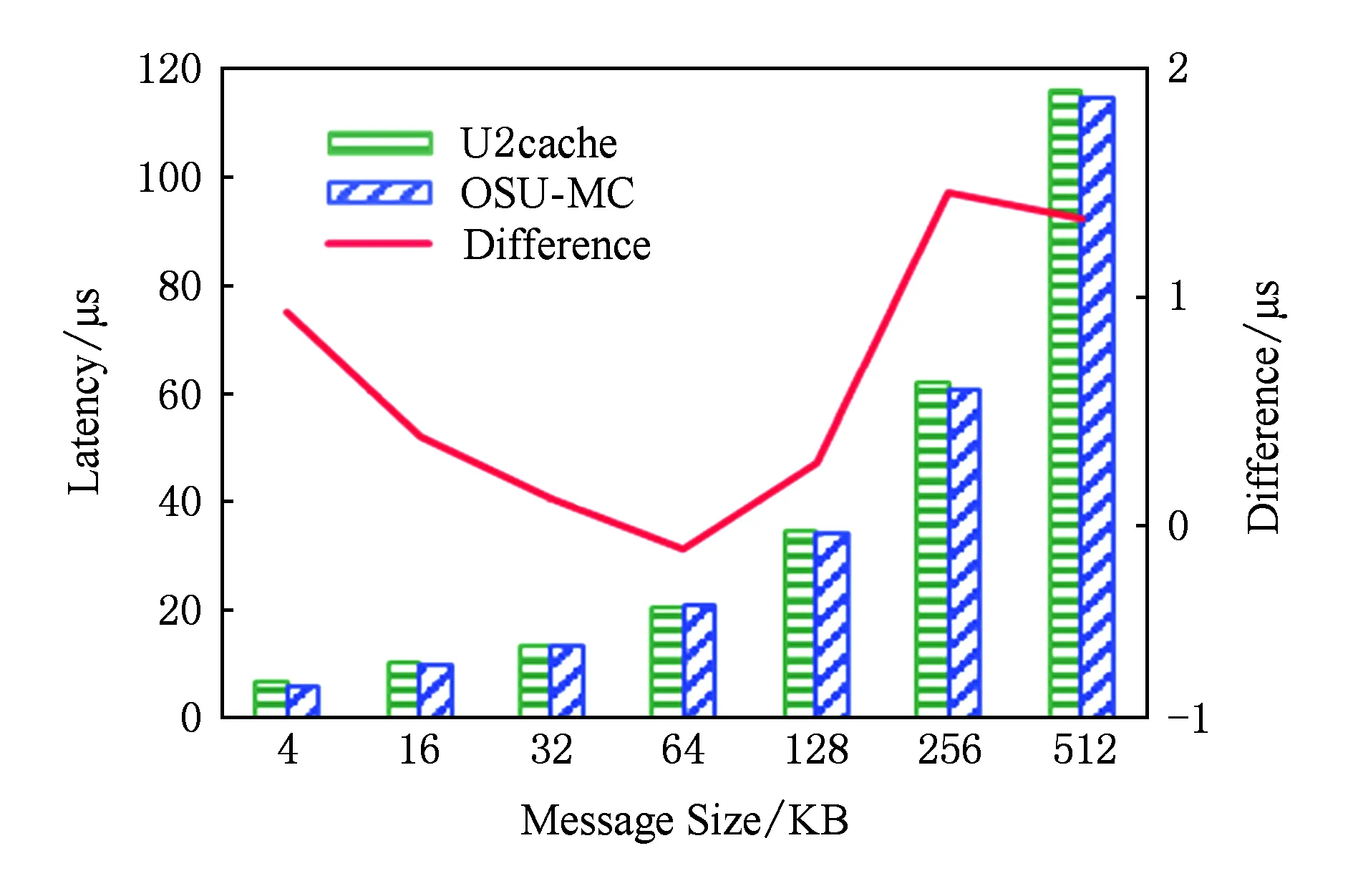
Fig. 13 Comparison of U2cache and OSU-Memcached on GET圖13 U2cache與OSU-Memcached GET延遲比較
3.3 SSD GET延遲
由于對SSD的批量寫入并非位于性能關鍵通路,本節主要分析涉及SSD的GET延遲.本文提出的基于用戶級NVMe訪問的存儲擴展方法能夠顯著降低GET操作的延遲.圖14和圖15分別給出了小消息與大消息的GET延遲對比,可以發現不同消息長度對應的GET延遲的降幅有明顯區別.當數據長度在16 KB以內時,相對于采用內核IO棧訪問SSD的方式,優化后的GET操作延遲減少了10 μs左右.隨著數據長度的增加,其延遲降幅從21%逐漸減小到12%,這同樣受益于用戶級驅動直接訪問SSD的延遲優勢.當數據長度為32 KB和64 KB時,受益于SSD數據分散化,GET操作的延遲降幅有所擴大,分別達到了19%和31%.當數據長度超過128 KB后,相比采用內核IO棧訪問SSD的方式,優化后的GET操作的延遲絕對值減小了30~70 μs,延遲降幅在7%~15%之間,這主要受益于SSD讀操作與RDMA通信并行流水優化隱藏了部分RDMA通信的延遲.
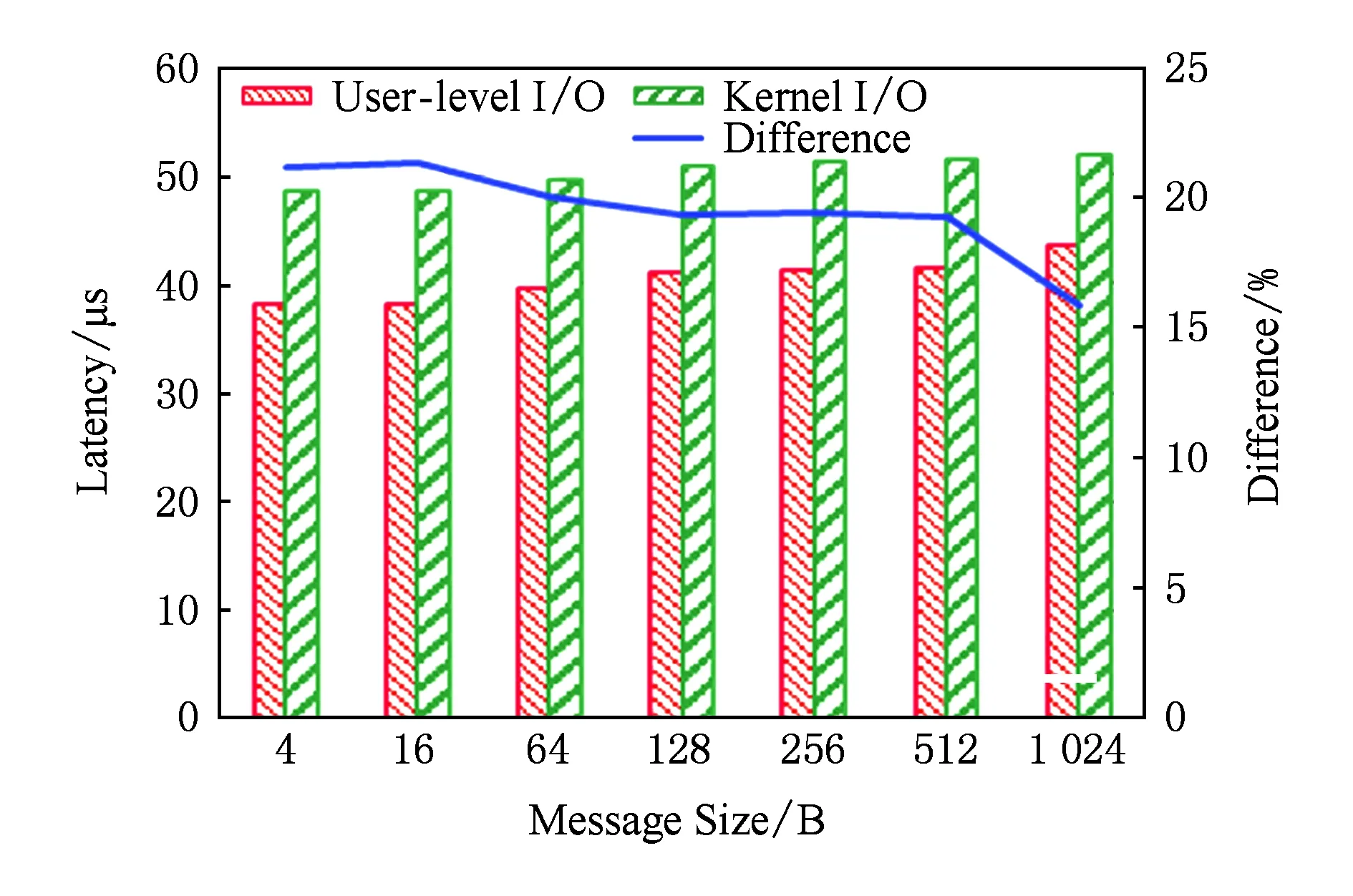
Fig. 14 Comparison of latency of GET on small messages圖14 小消息GET操作延遲對比
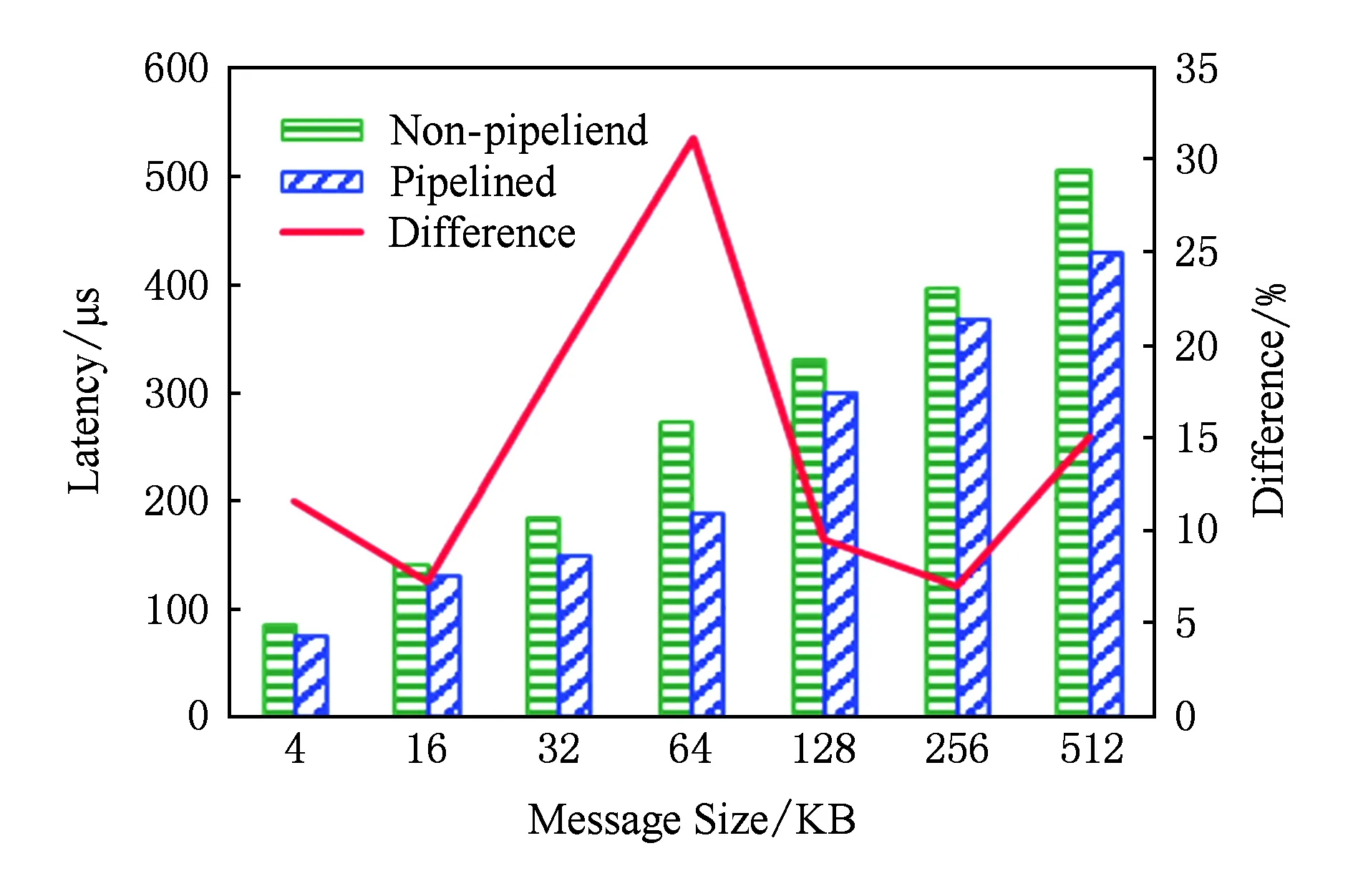
Fig. 15 Comparison of latency of GET on large messages圖15 大消息GET操作延遲對比
3.4 吞吐率和應用測試
本節同時啟用2個客戶端,分別對服務端處理SET請求和GET請求的吞吐率進行了測試.當消息長度為4 KB時,服務端SET和GET請求處理的吞吐率分別為23萬次s和20萬次s.
為了測試U2cache緩存系統在實際應用中的表現,本節還采用不同的緩存系統搭建了頁面內容完全相同的2個網站系統,并采用壓力測試工具ab[19]進行測試.2組對比系統均采用了相同的Tomcat,Servlet,MySQL的部署方案,不同之處是系統1采用了標準Memcached緩存,系統2采用了本文提出的U2cache高性能緩存系統.其中Tomcat和U2cache之間采用InfiniBand FDR網絡通信,其余組件間均采用千兆以太網進行通信.在壓力測試中,ab會發起1 000次網頁請求,每個頁面請求會產生200次查詢操作,而每次查詢的數據量為20 B,這樣數據總量約為4 MB.測試結果如圖16所示,結果表明U2cache能夠大幅降低Web服務的響應時間.

Fig. 16 Distribution of average page loading time圖16 平均網頁加載時間分布
4 相關工作
相比傳統以太網絡,RDMA網絡具備低延遲的優勢,且內存讀寫語義與Memcached的鍵值存儲方式相契合,國內外已經有一些采用RDMA技術加速Memcached通信的研究.
Jose等人[20]提出了基于RDMA over InfiniBand來加速Memcached通信的方案,該工作基于UCR(unified communication runtime)通信系統.該方案在傳輸小消息時采用有拷貝的通信方法,而傳輸大消息時采用無拷貝的通信方法,權衡了內存拷貝開銷和RDMA通信延遲的相對比重,從而降低了整體操作延遲.該工作取得了非常理想的加速效果,在QDR網絡下,與IPoIB相比,SET操作延遲改進3~6倍,GET操作延遲改進4~7倍.但是,該工作基于純本地環境,并未涉及諸如JVM等的高延遲語言運行時.
Stuedi等人[21]面向普通數據中心,提出了基于RDMA over Ethernet來加速Memcached的GET操作的方法.該方案由客戶端維護數據在服務端的存放地址信息,通過單邊RDMA Read操作直接從服務端獲取數據.如若客戶端沒有相應的地址信息,則通過sockets向服務端發起請求,服務端再通過RDMA Write將數據傳輸至客戶端.該方法客戶端邏輯實現復雜,并引入了服務端與客戶端數據索引一致性的問題.
Kalia等人[22]設計了高效利用RDMA技術的內存鍵值系統Herd.Herd僅使用RDMA Write與RDMA Send原語,放棄使用延遲更高的RDMA Read操作.考慮到RDMA網絡鏈路層采用了無損的流控機制,Herd大膽使用了不可靠傳輸及降低額外開銷,而由應用層負責重傳.客戶端通過基于不可靠連接的RDMA Write操作將請求寫至服務端,服務端輪詢檢查請求并處理,服務端輪詢檢查請求并處理,完成后通過基于不可靠數據報的RDMA Send操作回復客戶端.
選擇一種性價比更高的存儲設備作為內存的備用存儲,成為擴展內存對象緩存系統存儲空間的關鍵.在眾多存儲設備中,SSD的性能與內存更加接近,單位價格低于內存,并且技術正在走向成熟.目前,國內外已經有一些基于SSD擴展Memcached存儲容量的研究.
將閃存存儲設備作為Swap分區可以輕易實現對內存的擴展,但是會面臨許多問題.Ko等人[23]對Linux Swap策略進行了改進,保留了Linux系統日志結構[24]的Swap-Out方法,同時將Swap-In過程改為按塊對齊的機制.該方案的不足之處在于系統的整體性能與閃存設備的基礎性能差距仍然較大.
相較于SSD作為系統Swap分區的方案,Ouyang等人[25]提出了一種在Memcached內部集成SSD的方法.該方法采取slab的方式管理SSD,并且采用聚合寫的辦法來減少SSD寫放大.通過這種內部集成定制的方法,Memcached獲得了較為理想的SSD讀寫性能.該方法在系統軟件層面仍需通過內核IO棧,無法獲取最佳延遲表現.
5 總 結
本文以Memcached為例,從通信加速和存儲擴展2個角度研究內存對象緩存系統的數據通路優化問題,實現了高效緩存系統U2cache.U2cache采用了日益流行的高性能RDMA通信技術,服務端針對不同的緩存操作類型及消息大小設計了不同的通信策略,客戶端則重點面向應用更加廣泛的Java客戶端,并針對JVM內存管理機制,通過服務端與客戶端的協作以及內存拷貝與RDMA通信交疊的技巧,掩蓋了多數JVM開銷,保證了整體的低延遲響應.實驗結果表明,U2cache通信延遲接近RDMA底層通信性能,并且針對大消息,相較無優化版本,其性能提升比例超過20%;在引入JVM的情況下,部分測試結果與俄亥俄州立大學Panda教授團隊的RDMA優化后的高性能Memcached相當.在存儲方面,U2cache采用高性能讀友好的NVMe SSD設備來解決服務器節點內存容量不足的問題,設計實現了基于SSD的Memcached存儲擴展機制,并通過輪詢式的用戶級NVMe驅動直接訪問設備,大幅降低了軟件開銷.實驗結果表明,當服務端訪問SSD中4 KB大小以下的數據時,相比傳統的內核存儲棧,U2cache的讀延遲降低了10%以上;對大消息而言,通過數據分片并行流水的優化,性能提升最高超過30%.
[1]Memcached Organization. Memcached—A distributed memory object caching system[EBOL]. 2016 [2016-07-31]. http:memcached.org
[2]Nishtala R, Fugal H, Grimm S, et al. Scaling memcache at Facebook[C]Proc of the 10th USENIX Symp on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2013: 385-398
[3]Twitter Inc. Twemcache[EBOL]. 2016 [2016-07-31]. https:engineering.twitter.comopensourceprojectstwemcache
[4]Cen Wenchu. memcache-client-forjava[EBOL]. (2009-07-30) [2016-07-31]. https:code.google.comarchivepmemcache-client-forjava
[5]Tiwari P. Infographic: The cost of your website and mobile App’s poor performance in 2015[EBOL]. (2015-10-22) [2016-07-31]. http:blog.smartbear.comweb-monitoringcost-of-your-website-and-mobile-apps-poor-performance-in-2015
[6]Cisco Systems Inc. Cisco visual networking index: Forecast and methodology[EBOL]. 2015 [2016-07-31]. http:www.cisco.comcenussolutionscollateralservice-providerip-ngn-ip-next-generation-networkwhite_paper_c11-481360.html
[7]Cohen D, Talpey T, Kanevsky A, et al. Remote direct memory access over the converged enhanced Ethernet fabric: Evaluating the options[C]Proc of the 17th IEEE Symp on High Performance Interconnects. Piscataway, NJ: IEEE, 2009: 123-130
[8]Micron Technology Inc. 3D NAND[EBOL]. 2016 [2016-07-31]. https:www.micron.comaboutemerging-technologies3d-xpoint-technology
[9]Xu Qiumin, Siyamwala H, Ghosh M, et al. Performance analysis of NVMe SSDs and their implication on real world databases[C]Proc of the 8th ACM Int Systems and Storage Conf. New York: ACM, 2015: No.6
[10]Micron Technology Inc. 3D XPoint technology[EBOL]. [2016-07-31]. https:www.micron.comaboutemerging-technologies3d-xpoint-technology
[11]Grun P. Introduction to Infiniband for end users[EBOL]. 2010 [2016-07-31]. https:www.mellanox.compdfwhitepapersIntro_to_IB_for_End_Users.pdf
[12]Li Qiang, Sun Ninghui, Huo Zhigang, et al. T-NBC: Transparent non-blocking MPI collective operations[J]. Chinese Journal of Computers, 2011, 34(11): 2052-2063 (in Chinese)(李強, 孫凝暉, 霍志剛, 等. T-NBC: 透明的MPI非阻塞集合操作[J]. 計算機學報, 2011, 34(11): 2052-2063)
[13]Liu Jiuxing, Wu Jiesheng, Kini S, et al. High performance RDMA-based MPI implementation over InfiniBand[C]Proc of the 17th Annual Int Conf on Supercomputing. New York: ACM, 2003: 295-304
[14]An Zhongqi. Jni-verbs: Access the RDMA verbs API via JNI from Java[EBOL]. (2015-08-12) [2016-07-31]. https:github.comqzan9jni-verbs
[15]Oracle Corporation. Java native interface[EBOL]. 2014 [2016-07-31]. http:docs.oracle.comjavase7docstechnotesguidesjni
[16]Walker D H. A comparison of NVMe and AHCI[R]. Beaverton, OR: The Serial ATA International Organization, 2012
[17]Bj?rling M, Axboe J, Nellans D, et al. Linux block IO: Introducing multi-queue SSD access on multi-core systems[C]Proc of the 6th Int Systems and Storage Conf. New York: ACM, 2013: No.22
[18]Jonathan S. Introduction to the storage performance development kit (SPDK)[EBOL]. 2016 [2016-07-31]. https:software.intel.comen-usarticlesintroduction-to-the-storage-performance-development-kit-spdk
[19]The Apache Software Foundation. ab-Apache HTTP server benchmarking tool[EBOL]. 2016 [2016-07-31]. http:httpd.apache.orgdocscurrentprogramsab.html
[20]Jose J, Subramoni H, Luo Miao, et al. Memcached design on high performance RDMA capable interconnects[C]Proc of the 2011 Int Conf on Parallel Processing. Piscataway, NJ: IEEE, 2011: 743-752
[21]Stuedi P, Trivedi A, Metzler B. Wimpy nodes with 10GbE: Leveraging one-sided operations in RDMA over Ethernet to boost Memcached[C]Proc of the 2012 USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2012: 31-31
[22]Kalia A, Kaminsky M, Andersen D G. Using RDMA efficiently for key-value services[C]Proc of the 2014 ACM Conf on SIGCOMM. New York: ACM, 2014: 295-306
[23]Ko S, Jun S, Ryu Y, et al. A new Linux swap system for flash memory storage devices[C]Proc of Int Conf on Computational Sciences and ITS Applications. Piscataway, NJ: IEEE, 2008: 151-156
[24]Rosenblum M, Ousterhout J K. The design and implementation of a log-structured file system[J]. ACM Trans on Computer Systems, 1992, 10(1): 26-52
[25]Ouyang X, Islam N S, Rajachandrasekar R, et al. SSD-assisted hybrid memory to accelerate Memcached over high performance networks[C]Proc of the 41st Int Conf on Parallel Processing. Piscataway, NJ: IEEE, 2012: 470-479

AnZhongqi, born in 1987. Recieved his master degree in computer science and technology from China University of Petroleum (East China) in 2013. Engineer. His main research interests include high-performance OSR and middleware.

DuHao, born in 1990. MSc candidate. His main research interests include computer architecture and high performance comm-unication (duhao@ncic.ac.cn).


HuoZhigang, born in 1978. PhD, associate professor. His main research interests include fault tolerance in HPC (zghuo@ncic.ac.cn).

MaJie, born in 1975. PhD, professor. His main research interest is high performance communication (majie@ict.ac.cn).
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
