Hadoop集群中影響應用性能的因素分析
2018-04-13 10:03:26馬生俊陳旺虎郭宏樂喬保民李新田
小型微型計算機系統 2018年4期
馬生俊,陳旺虎,郭宏樂,喬保民,李新田
(西北師范大學 計算機科學與工程學院,蘭州 730070) E-mail:1780761723@qq.com
1 引 言
隨著科學研究、社交網絡、電子商務、互聯網、移動通信等領域的蓬勃發展,每天都有大量數據的產生,且數據產生的速度越來越快.據統計,平均每秒有200萬用戶在使用谷歌搜索,Facebook用戶每天共享的內容多達40億條,Twitter每天處理的數量超過3.4億[1].根據IDC(國際數據公司)的研究,與2009年相比,全球數字信息總量將在2020年增長44倍,估計能達到35.2ZB[2].數據來源廣而快,數據量龐大而多樣,常規的處理技術和方法已經很難滿足處理需求.云計算(Cloud Computing)[3]應運而生,以并行編程模型、海量數據分布存儲、海量數據管理、資源管理和虛擬化等為主要技術,其中編程模型和海量數據分布存儲是最核心的技術.Hadoop[4]作為云計算的一款開源實現工具,被越來越多的國內外IT公司和高校院所應用和研究,如:雅虎的云計算系統、IBM 的藍云項目、亞馬遜的EC2都是基于Hadoop 的實現;BAT(百度、阿里、騰訊)、華為、中國移動、網易、金山等公司都不同程度的采用 Hadoop進行應用研發[5].
隨著Hadoop被工業界和學術界越來越廣泛地應用和高度地重視.近年來,為了在大數據處理方面取得較高的效率,研究者們在Hadoop框架與功能增強方面針對不同的應用領域做了相應的改進和優化,使性能取得了一定的改善[6].研究者們一方面著眼于優化存儲方案,另一方面致力于提升處理能力,其目的是提高Hadoop集群環境的效率,減少處理成本.如:文獻[7]針對異構的Hadoop集群提出了一種自適應平衡的數據存儲策略;文獻[8]針對Hadoop存儲系統存儲成本高、可擴展性低、節點負載均衡不足等問題,提出了一種基于范德蒙碼的分散式動態存儲策略;文獻[9]針對云環境和服務器集群兩種不同的環境,分析處理大數據所面臨的機遇和方法,在云環境中處理大數據時,提出并設計了以資源配置和任務調度為主要問題的優化方案.
Hadoop集群環境中如何提高應用性能、減少執行時間已成為研究的熱點.工欲善其事必先利其器,從而分析影響應用性能的因素至關重要.文中重點關注數據集類型、數據塊大小,集群環境規模等因素;探討不同規模的集群環境中,輸入不同類型的數據集,分割成不同大小的數據塊對應用性能的影響;通過實驗,給出不同規模的集群環境中,輸入不同類型的數據集,分割不同大小的數據塊對應用性能影響的變化規律;分析實驗結果,得出如何提高應用性能的結論.
本文貢獻:初步探索了在Hadoop集群環境中影響應用性能的數據集類型,數據塊大小,集群規模等因素,發現處理不同類型的數據集時,一方面我們應該清楚集群規模越大并不一定應用性能越好,另一方面我們可以適當的增大數據塊的大小、減少map任務數以取得較好的性能.
論文后續內容安排:第二部分介紹相關工作;第三部分針對Hadoop云平臺詳細分析HDFS(Hadoop Distributed File System)和MapReduce并分析數據集類型和數據塊大小對應用性能的影響;第四部分介紹實驗,給出實驗結果,分析結果發現數據集類型、數據塊的大小、集群環境規模對應用性能的影響規律;第五部分給出結論并指出接下來的工作.
2 相關工作
Hadoop作為一種新的計算模式以其自身的特點和優勢已被廣泛應用,如何提高應用性能、減少執行時間已成為研究的熱點.Hadoop集群環境中影響應用性能的因素很多,研究者們根據不同的領域,對多種因素已開展了許多研究,主要涉及文獻有[10-20]等.
文獻[10]從應用著手分析Hadoop存在的不足,利用作業和任務的多重并發平衡磁盤和網絡帶寬,減小傳輸瓶頸出現的可能性,以提高系統性能;該文獻采用固定規模的集群環境進行實驗,文中沒有考慮集群規模發生變化時應用的性能將出現什么變化.文獻[11]針對由物理機和虛擬機混合組成的異構集群環境進行Hadoop性能測試,得出由于虛擬機的高I/O開銷,導致Hadoop的性能相比傳統的純物理節點集群急劇降低;該文獻采用不同的數據量進行測試;但沒有考慮集群環境規模和數據塊大小的變化對固定數據量執行時間的影響.文獻[12]和文獻[13]從單機環境和分布式環境的角度采用多種經典數據集測試Hadoop框架的幾種文件輸入方式處理小文件的性能差異,得出減少任務數有利于提高性能的結論;但是,兩文獻只是從單一角度進行實驗說明,未對單機和分布式兩種環境進行統一的測評.文獻[14]通過在Amazon EC2(Elastic Compute Cloud)的兩種不同類型的虛擬機上搭建Hadoop集群環境測試Wordcount,TeraSort等多種應用,得出集群規模的變大可提高應用處理效率、減少執行時間;該文獻考慮了集群規模的變化對應用性能的影響,但沒有考慮數據集類型以及對相同大小的數據集分割成不同大小的數據塊對應用性能的影響.文獻[15]通過在OpenStack云平臺搭建Hadoop集群測試影響應用執行性能的因素,得出數據量的大小和集群規模是影響應用性能的主要因素;該文獻采用任務數的默認個數,沒有考慮在數據量和集群規模一定時劃分不同大小的數據塊對應用執行性能的影響.文獻[10-15]不同程度的從各個方面探討影響Hadoop框架性能的因素,但是尚未對集群環境規模、數據集類型、數據塊大小進行深入的探討.
此外,文獻[16]考慮了影響節點存儲性能的CPU、內存、系統結構、磁盤的讀寫速度等因素,提出了一種對節點存儲性能進行度量的方法,在數據存儲時綜合考慮節點的存儲性能和節點與客戶端的網絡距離兩個因素進行數據節點的選擇,改進數據放置的負載均衡、提高異構集群的數據傳輸速率.文獻[17]提出了一種基于XOR碼的編碼和譯碼方式相對簡單的優化策略,可進行數據的恢復操作.文獻[18]針對作業過程中數據傳輸和數據處理流程,提出了虛擬網絡拓撲結構的優化機制,減少了數據傳輸和處理的總開銷,提高了MapReduce云框架處理大數據的整體性能.文獻[19]為大規模增量計算擴展了Hadoop框架提出了一種新的Hadoop框架——Incoop.Morton K[20]等人為有效預測作業結束時間提出了一種計算MapReduce執行進度的算法等很多算法層面的改進.文獻[16-20]從Hadoop框架著手,針對不同的應用領域,采用不同的方法對其進行改進和優化,期望提高Hadoop框架的性能.
上述研究中,有從Hadoop框架本身出發補充其不足,擴展其應用領域;更有探討影響Hadoop集群環境性能的因素,如集群環境的異構,內部處理機制,集群規模以及網絡環境等多種因素.但是,沒有將集群規模、數據集類型和數據塊的大小對Hadoop集群環境性能的影響進行統一分析.文中重點關注了輸入不同類型的數據集,分割不同大小的數據塊在不同規模的集群中對應用性能的影響.
3 Hadoop介紹及因素分析
Hadoop是由Apache Software Foundation 公司受到 Google Lab 開發的 Map/Reduce 和 GFS(Google File System) 的啟發所開發的分布式系統基礎架構.Hadoop框架最核心的設計是HDFS和MapReduce.HDFS為海量的數據提供了永久存儲,則MapReduce為海量的數據提供了高效計算[21].
3.1 HDFS數據分布存儲技術
HDFS是一個主/從(Master/Slave,M/S)結構的存儲海量數據的系統,用來存儲大量的數據.用戶看來,HDFS與傳統的文件系統一樣,可以通過目錄對文件執行增刪改查等操作.有一個主節點(Namenode)和若干從節點(Datanode)組成.Namenode負責管理文件系統的命名空間,記錄文件數據塊在每個Datanode上的位置和副本信息,協調客戶端(Client)對文件的訪問,記錄命名空間內的改動或命名空間本身屬性的改動.Datanode存放實際的數據,一個文件被物理地切割成若干數據塊(Block)(默認大小為64M),這些Block盡可能分散地存儲在不同的Datanode上,HDFS為保證數據的安全性在不同的機架上設置了Block的副本(默認備份數為3).
HDFS的工作過程是Client請求操作文件的指令由Namenode接收,Namenode將存儲數據的Datanode的IP返回給客戶端,并通存放副本的Datanode,由Client直接從Datanode讀取文件數據.與此同時,Namenode更新其的元數據內容,不參與文件的傳送.整個文件系統采用標準的TCP/IP協議通信.其系統的架構如圖1所示.
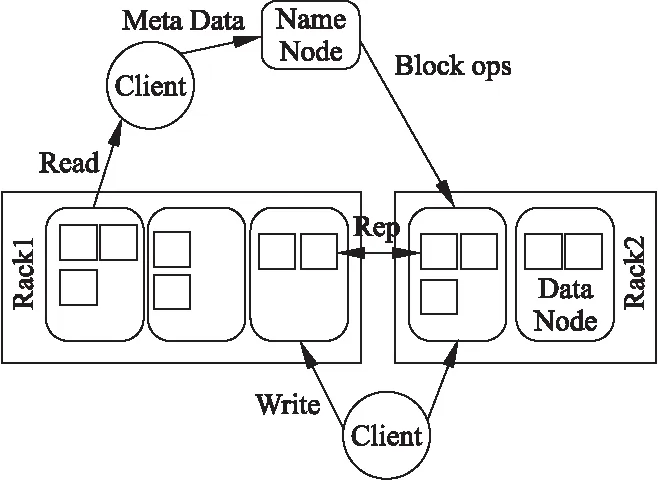
圖1 HDFS架構示意圖Fig.1 HDFS architecture
3.2 MapReduce并行編程模型
MapReduce是一種主/從結構的處理海量數據的并行編程模型和計算框架,用于對大規模數據集的并行處理.MapReduce 采用一種“分解歸約”的基本思想,把對大規模數據集的操作,分發給一個主節點(Jobtracker)管理下的各個分節點(Tasktracker)共同完成,然后整合各個Tasktracker的中間結果得到最終的結果.上述處理過程被MapReduce抽象為map和reduce兩個函數;map函數負責把任務分解成多個子任務,reduce函數負責把子任務處理的結果匯總起來.
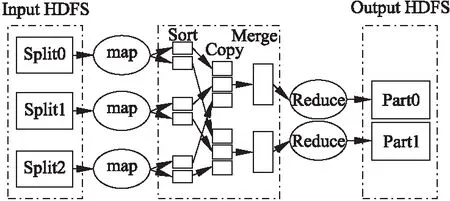
圖2 MapReduce執行過程示意圖Fig.2 MapReduce execution flow
在Map階段,MapReduce將任務的輸入數據邏輯地劃分成固定大小的多個片段(Split),然后將每個Split進一步處理成一批< K1,V1 >(鍵值對).首先,Hadoop為每個Split創建一個map任務用于執行用戶定義的map函數;其次,將對應Split中的< K1,V1 >作為輸入,得到中間結果
3.3 因素分析
通過3.1和3.2對Hadoop核心框架的介紹,可以知道Hadoop處理數據時,先通過HDFS將數據按固定大小物理地分割為多個Block,以Block為單位分散地存儲在節點上;后通過MapReduce將這些Block參照用戶定義邏輯地劃分為多個Split,并以Split為單位處理數據.可見,Block是存儲數據的單位,Split是處理數據的單位.可以將Hadoop數據處理流程用圖3簡單表示.
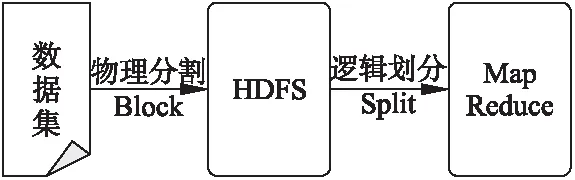
圖3 Hadoop數據處理流程圖Fig.3 Hadoop data processing flow
一般地,采用默認大小將數據集物理地分割為多個Block時,有多少個Block就會邏輯劃分成多少個Split,一個Split就是一個map任務,而一個Split只能包含一個文件中的數據即不會同時包含兩個及以上文件中的數據[22].換句話說,數據集中只有一個文件且數據量大于Block的大小時,有多少個Block就有多少個map任務;數據集中有多個文件且每個文件的數據量都小于Block的大小時,有多少個文件就有多少個map任務.
Hadoop設計的初衷是為了處理大文件數據集,處理數據量少在GB,大至PB,甚至更大的文件數據集[23].大多數企業或者科研單位擁有PB級的存儲數據集,這些數據集既有達到幾十GB的大文件,又有僅為幾十KB的小文件[24];對于幾十GB的大文件,分割的Block數就是執行的map數,對于十幾KB的小文件,文件數才是執行的map數.假設現有一數據集需要處理,其數據量大小為10GB,按照Hadoop默認Block大小(64MB)分割,若數據集只包含一個大文件,則需要執行的map數約為160個;若數據集包含多個平均大小為32KB的小文件,則需要執行的map數約為327680個,相比之下,可以發現處理小文件執行的map數遠遠大于大文件執行的map數.
在數據量一定的情況下,面對大文件和小文件構成的數據集,是采用Hadoop默認的Block大小分割數據,還是根據數據集的構成類型選擇合適的Block大小分割數據,即分割成不同大小的Block會對應用性能有什么樣的影響,性能的差異又如何,急需一個量化的描述.故此,文中主要探討在不同規模的Hadoop集群環境,輸入不同類型的數據集,分割成不同大小的Block對應用性能的影響.
4 實驗分析
4.1 實驗平臺
實驗用到的物理機為11臺聯想 ThinkServer RD650 服務器即11個節點(Node).所有節點的硬件配置是GenuineIntel處理器、32G內存、2T硬盤.所有節點都是CentOS 7.0操作系統,JDK 1.8.0_101JDK環境,Hadoop-2.6.4云框架.實驗系統環境如表1所示.
4.2 實驗設計
實驗中的11個Node,其中一個為主節點(master),其余都為從節點(slave).因實驗用于探討在不同規模的Hadoop集群環境中,輸入不同類型的數據集,分割不同大小的數據塊對應用性能的影響,所以實驗以最簡單也是最能提現MapReduce思想的單詞計數Wordcount程序作為測試應用.由于Hadoop集群環境是一種分布式的環境,在任務執行時需要大量的數據傳輸,為盡可能的減少網絡對實驗的影響,在實驗環境中,將11個Node連接在同一臺普聯TL-SG1024DT千兆機架式交換機上形成一個局域網,網絡帶寬為1000Mb/s,網絡拓撲如圖4所示.
表1 實驗環境
Table 1 Experiment environmnet

操作系統CentOS7.0Hadoop環境Hadoop-2.6.4JDK環境JDK1.8.0_101硬件配置GenuineIntel處理器32G內存2T硬盤
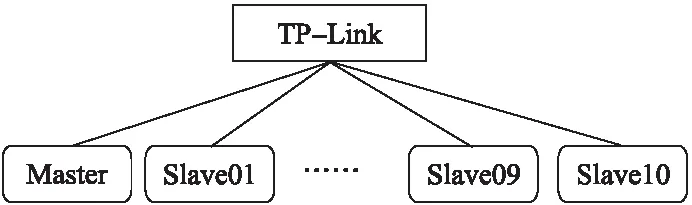
圖4 實驗網絡拓撲圖Fig.4 Network topology desining in the experiment
實驗數據來源于100本英文txt類型的名著,根據不同的數據集類型,將數據進行處理,通過多次拷貝得到實驗要求的數據量2048MB.實驗中Block的大小可修改配置文件(hdfs-site.xml)中dfs.block.size的大小得到滿足實驗要求的Block,其他保持默認配置,如數據備份數為3,Reduce任務數為1.
實驗中不同大小的Block(單位:MB)變化如表2所示.
表2 數據塊大小變化表
Table 2 Value range of Block size
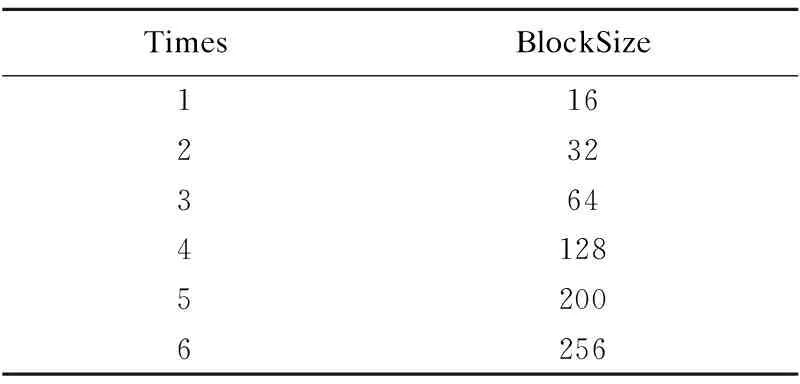
TimesBlockSize116232364412852006256
實驗中集群環境規模采用兩種規模.
ClusterScale-1(CS1):集群環境中只有1個Slave節點.
ClusterScale-2(CS2):集群環境中有10個Slave節點.
實驗中數據集的類型采用兩種類型.
DatasetType-1(DT1):由1個大txt文件組成.
DatasetType-2(DT2):由100個小txt文件組成.
4.3 實驗結果
根據4.2實驗設計,分別在兩種集群環境規模(ClusterScale-1,ClusterScale-2)中對兩類數據集(DatasetType-1,DatasetType-2)設置不同大小的Block進行實驗.對每一次實驗都進行3遍求其平均值,得到map和reduce任務執行時間即M-time和R-time,求和M-time和R-time得到任務執行的總時間T-time,分別得如下結果(時間單位為:ms).
1)在集群規模為ClusterScale-1,數據集類型為DatasetType-1時實,驗結果如表3所示.
表3 實驗結果表-11
Table 3 Experiment results-11
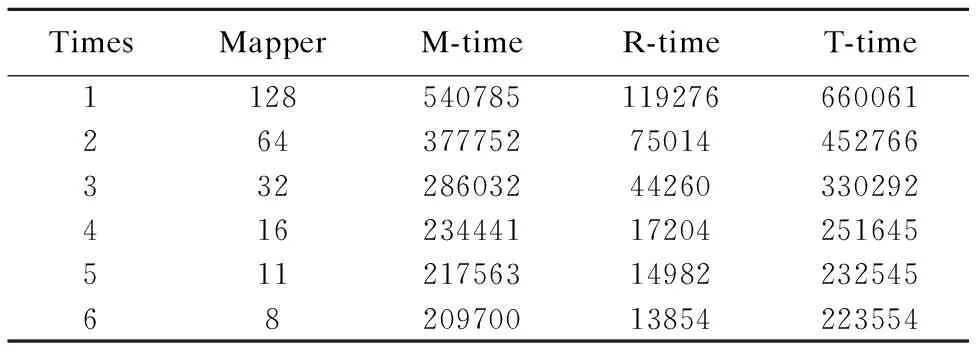
TimesMapperM-timeR-timeT-time1128540785119276660061264377752750144527663322860324426033029241623444117204251645511217563149822325456820970013854223554
2)在集群規模為ClusterScale-1,數據集類型為DatasetType-2時,實驗結果如表4所示.
表4 實驗結果表-12
Table 4 Experiment results-12
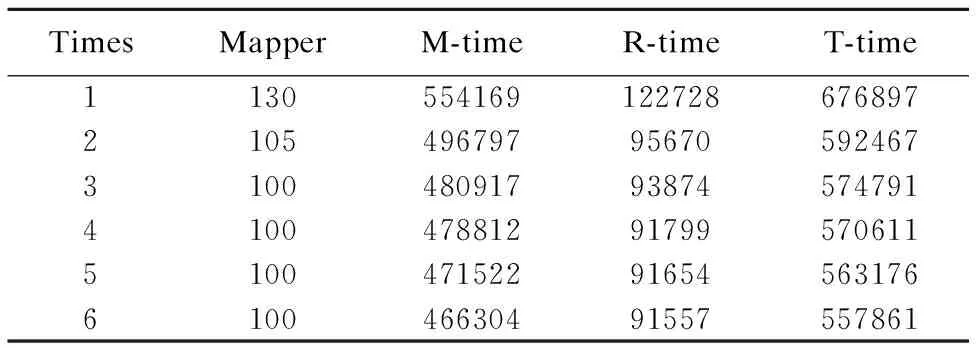
TimesMapperM-timeR-timeT-time1130554169122728676897210549679795670592467310048091793874574791410047881291799570611510047152291654563176610046630491557557861
3)在集群規模為ClusterScale-2,數據集類型為DatasetType-1時,實驗結果如表5所示.
表5 實驗結果表-21
Table 5 Experiment results-21
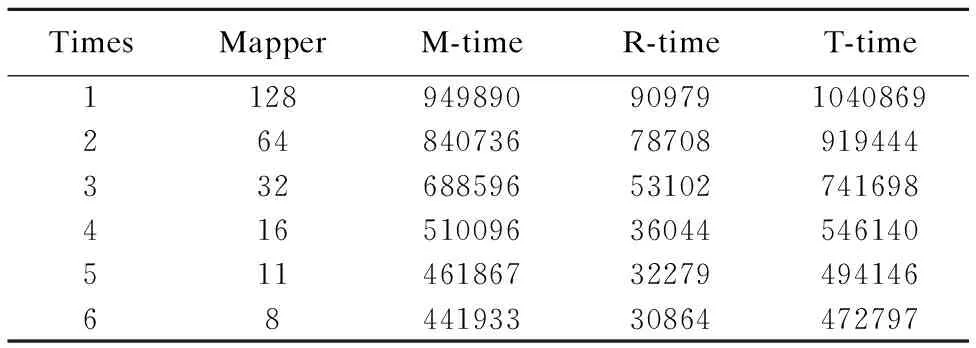
TimesMapperM-timeR-timeT-time1128949890909791040869264840736787089194443326885965310274169841651009636044546140511461867322794941466844193330864472797
4)在集群規模為ClusterScale-2,數據集類型為DatasetType-2時,實驗結果如表6所示.
表6 實驗結果表-22
Table 6 Experiment results-22
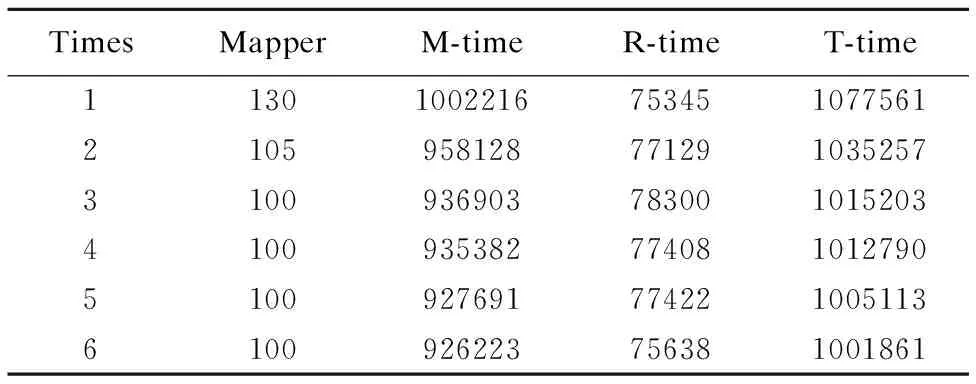
TimesMapperM-timeR-timeT-time1130100221675345107756121059581287712910352573100936903783001015203410093538277408101279051009276917742210051136100926223756381001861
4.4 實驗分析
1) 在集群規模相同、數據集類型不同的情況下由圖5,圖6可知,在由1個Slave或10個Slave節點組成的集群環境下,將數據量相同的兩類數據集分割成不同大小的Block時,處理單文件數據集的時間越來越少于多文件數據集;且隨著Block的增大,處理單文件數據集的時間呈先迅速后緩慢的趨勢越來越少,而處理多文件數據集的時間基本不變.
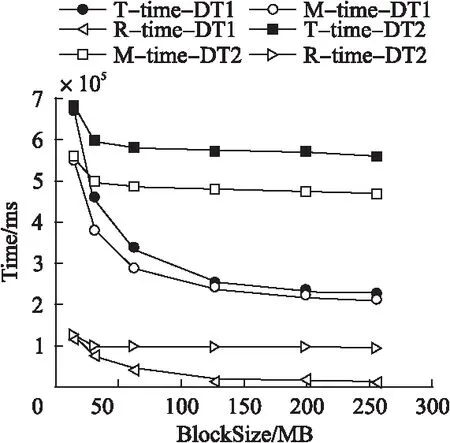
圖5 小規模集群下數據集類型對時間的影響Fig.5 Impact of dataset type on execution time in the 1 slave node cluster
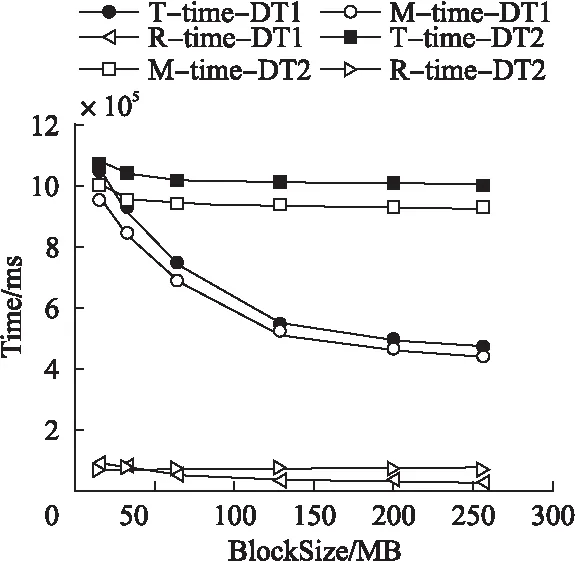
圖6 大規模集群下數據集類型對時間的影響Fig.6 Impact of dataset type on execution time on the 10 slave node cluster
分析表3至表6發現map任務數是導致兩類數據集的處理時間呈上述變化的原因.例如,在Block為16MB時,兩類數據集的map任務數(128,130)基本相等,所以在此處兩類數據集的處理時間基本相等;隨著Block的增大,單文件數據集的map任務數呈指數變化趨勢減少,其處理時間以一致的趨勢減少;而多文件數據集的map任務數基本保持在100未變,其處理時間也以一致的趨勢基本保持不變.
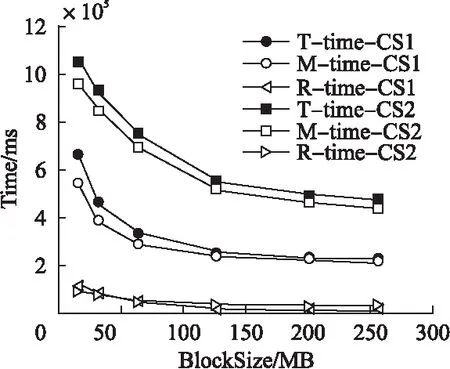
圖7 單文件數據集下集群規模對時間的影響Fig.7 Impact of cluster scale on execution time under the unique file dataset
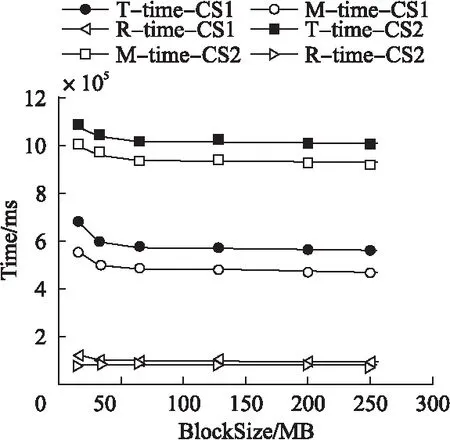
圖8 多文件數據集下集群規模對時間的影響Fig.8 Impact of cluster scale on execution time under the multiple file dataset
2)在數據集類型相同、集群規模不同的情況下.由圖7和圖8可知,在兩種規模的集群環境下,將數據量相同的多文件數據集分割成不同大小的Block處理時,1個Slave節點組成的集群所需的時間大約是10個Slave節點組成的集群所需時間的1/2;然而,reduce任務的執行時間基本相等,map任務的執行時間相差約為1/2,可知map任務是導致此現象的決定因素.
5 總 結
Hadoop集群環境中影響應用性能的因素很多.文中重點關注不同規模的集群環境、不同類型的數據集、不同大小的數據塊對應用性能的影響.采用Hadoop云框架單詞統計(Wordcount)應用作為測試應用進行實驗;分析實驗結果可得,一方面,在相同規模的集群環境下,將數據量相同的兩類的數據集分割成不同大小的Block處理時,隨著Block的增大,兩類數據集的處理時間隨著各自map任務數的變化趨勢變化,且單文件數據集的處理性能明顯優于多文件數據集.另一方面,相同量的數據集下,在兩種規模的集群環境中將數據集分割成不同大小的Block處理時,1個Slave節點組成的集群的處理效率大約是10個Slave節點組成集群的2倍,且map任務的執行效率是導致此現象的決定因素,這是一個奇怪的現象,理應處理相同的數據量,多個節點處理的效率應比單個節點更高才是.
本文工作可以作為研究Hadoop集群環境中影響應用性能因素的一個重要基礎.下一步,將研究文中出現的奇怪現象——大規模集群環境的處理效率遠低于小規模集群環境,進而深入分析和探討Hadoop集群環境中影響應用性能的因素,盡可能全面地分析各種因素對應用性能的綜合影響.
[1] Feng Deng-guo,Zhang Min,Li Hao.Big data security and privacy protection[J].Chinese Journal of Computers,2014,37(1):246-258.
[2] Xu Ji,Wang Guo-yin,Yu Hong.Review of big data processing based on granular computing[J].Chinese Journal of Computers,2015,38(8):1497-1517.
[3] Mell P,Grance T.The NIST definition of cloud computing[J].Communications of the Acm,2011,53(6):50.
[4] Hao Shu-kui.Brief analysis of the architecture of Hadoop HDFS and MapReduce[J].Designing Techniques of Posts and Telecommunications,2012,21(9):37-42.
[5] Wang L,Laszewski G V,Younge A,et al.Cloud computing:a perspective study[J].New Generation Computing,2010,28(2):137-146.
[6] Dong Xin-hua,Li Rui-xuan,Zhou Wan-wan,et al.Performance optimization and feature enhancements of Hadoop system[J].Journal of Computer Research and Development,2013,50(S2):1-15.
[7] Zhang Shao-hui,Zhang Zhong-jun,Yu Lai-xing.A big data placement strategy for adaptive balance data storage in heterogeneous Hadoop cluster[J].Modern Electronics Technique,2016,39(10):49-53.
[8] Song Bao-yan,Wang Jun-lu,Wang Yan.Optimized storage strategy research of HDFS based on vandermonde code[J].Chinese Journal of Computers,2015,38(9):1825-1837.
[9] Ang D,Liu J.Optimizing big data processing performance in the public cloud:opportunities and approaches[J].Network IEEE,2015,29(5):31-35.
[10] Luan Ya-jian,Huang Chong-min,Gong Gao-sheng,et al.Reasearch on performance optimization of Hadoop platfrom[J].Computer Engineering,2010,36(14):262-263.
[11] Liu Dan-dan,Chen Jun,Liang Feng,et al.A performance analysis for Hadoop under heterogeneous cloud computing environments[J].Journal of Integration Technology,2012,1(4):46-51.
[12] Yuan Yu,Cui Chao-yuan,Wu Yun,et al.Performance analysis of Hadoop for handling small files in single node[J].Computer Engineering and Applications,2013,49(3):57-60.
[13] Li San-miao,Li Long-shu.Performance analysis of four methods for handling small files in Hadoop[J].Computer Engineering and Applications,2016,52(9):44-49.
[14] Gohil P,Garg D,Panchal B.A performance analysis of MapReduce applications on big data in cloud based Hadoop[C].2014 International Conference on Information Communication and Embedded Systems,Chennai:IEEE,2015:1-6.
[15] Ahmad N M,Yaacob A H,Amin A H M,et al.Performance analysis of MapReduce on OpenStack-based hadoop virtual cluster[C].2014 IEEE 2nd International Symposium on Telecommunication Technologies,Langkawi:IEEE,2014:132-137.
[16] Wang Yong-zhou,Mao Su.A blocks placement strategy in HDFS[J].Computer Technology and Development,2013,23(5):90-92.
[17] Zhu Y,Lee P P C,Hu Y,et al.On the speedup of single-disk failure recovery in XOR-coded storage systems:theory and practice[J].Mass Storage Systems & Technologies,2012,22(5):1-12.
[18] Li Li-yao,Zhao Shao-ka,Xu Hua-rong.MapReduce performance optimization strategy based on a cloud platform[J].Journal of Lanzhou University(Natural Sciences),2015,51(5):752-758.
[19] Bhatotia,Pramod,Wieder,et al.Incoop:MapReduce for incremental computations[C].Proceedings of the 2nd ACM Symposium on Cloud Computing,New York:ACM,2011:1-14.
[20] Morton K,Friesen A,Balazinska M,et al.Estimating the progress of MapReduce pipelines[C].2010 IEEE 26th International Conference on Data Engineering,California:IEEE,2010:681-684.
[21] Junqueira B F,Reed B.Hadoop:the definitive guide[J].Journal of Computing in Higher Education,2001,12(2):94-97.
[22] Tom White.Hadoop:the definitive guide[M].Beijing:Tsinghua University Press,2015:256-258.
[23] Jia Yu-chen.Design and implementation of the key techniques for storing and retrieving massive small files in hadoop[D].Nanjing:Nanjing University of Posts and Telecommunications,2015:3-4.
[24] Llc C S P.Cloud computing introduction[C].2014 IEEE Technology Time Machine Symposium,San Jose:IEEE,2014:1-1.
附中文參考文獻:
[1] 馮登國,張 敏,李 昊.大數據安全與隱私保護[J].計算機學報,2014,37(1):246-258.
[2] 徐 計,王國胤,于 洪.基于粒計算的大數據處理[J].計算機學報,2015,38(8):1497-1517.
[4] 郝樹魁.Hadoop HDFS和MapReduce架構淺析[J].郵電設計技術,2012,21(9):37-42.
[6] 董新華,李瑞軒,周灣灣,等.Hadoop系統性能優化與功能增強綜述[J].計算機研究與發展,2013,50(S2):1-15.
[7] 張少輝,張中軍,于來行.異構Hadoop集群下自適應平衡數據存儲的大數據放置策略[J].現代電子技術,2016,39(10):49-53.
[8] 宋寶燕,王俊陸,王 妍.基于范德蒙碼的HDFS優化存儲策略研究[J].計算機學報,2015,38(9):1825-1837.
[10] 欒亞建,黃翀民,龔高晟,等.Hadoop平臺的性能優化研究[J].計算機工程,2010,36(14):262-263.
[11] 劉丹丹,陳 俊,梁 鋒,等.云計算異構環境下Hadoop性能分析[J].集成技術,2012,1(4):46-51.
[12] 袁 玉,崔超遠,烏 云,等.單機下Hadoop小文件處理性能分析[J].計算機工程與應用,2013,49(3):57-60.
[13] 李三淼,李龍澍.Hadoop中處理小文件的四種方法的性能分析[J].計算機工程與應用,2016,52(9):44-49.
[16] 王永洲,茅 蘇.HDFS中的一種數據放置策略[J].計算機技術與發展,2013,23(5):90-92.
[18] 李立耀,趙少卡,許華榮.基于云平臺的MapReduce性能優化策略[J].蘭州大學學報:自然科學版,2015,51(5):752-758.
[22] Tom White.Hadoop權威指南[M].北京:清華大學出版社,2015:256-258.
[23] 賈玉辰.Hadoop中海量小文件存取關鍵技術的設計與實現[D].南京:南京郵電大學,2015:3-4.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
發明與創新(2016年38期)2016-08-22 03:02:52
