一種深度生成模型的超參數(shù)自適應(yīng)優(yōu)化法
2018-04-11 06:34:25姚誠偉陳根才
實(shí)驗(yàn)室研究與探索 2018年2期
姚誠偉, 陳根才
(浙江大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,杭州 310027)
0 引 言
深度生成模型(Deep Generative Model, DGM)[1]作為深度學(xué)習(xí)模型的重要分支之一,不僅在各類監(jiān)督學(xué)習(xí)領(lǐng)域取得優(yōu)異的效果[2-4],而且在很多非監(jiān)督學(xué)習(xí)領(lǐng)域領(lǐng)中有著獨(dú)特的優(yōu)勢(shì),如降維分析[5]、信息檢索[6]、特征提取[7]等。DGM包括兩種經(jīng)典模型:深度置信網(wǎng)絡(luò)(Deep Belief Network, DBN)[7]和深度玻耳茲曼機(jī)(Deep Boltzmann Machine, DBM)[8]。該類深度模型的共同特點(diǎn)是它們都由一種稱為受限玻耳茲曼機(jī)(Restricted Boltzmann Machine, RBM)[7]的基本構(gòu)件層層堆疊而構(gòu)成的,因此DGM也是一種多層圖概率模型。利用這種基于圖概率模型的逐層訓(xùn)練策略,DGM可以非常好地對(duì)大量數(shù)據(jù)進(jìn)行非監(jiān)督方式的多層次特征提取[1],大大提升其在大數(shù)據(jù)分析和人工智能中應(yīng)用效果。
盡管DGM在各類機(jī)器學(xué)習(xí)任務(wù)中取得極大成功,然而如其他深度模型一樣,在面對(duì)實(shí)際數(shù)據(jù)和應(yīng)用時(shí),DGM的部署和訓(xùn)練是一件非常困難的事。主要原因是DGM有著眾多的超參數(shù),在利用實(shí)際數(shù)據(jù)對(duì)模型進(jìn)行訓(xùn)練之前必須為這些超參數(shù)設(shè)置合適的值,否則在訓(xùn)練中深度模型的參數(shù)很容易崩潰或無法學(xué)到有用的特征[9]。這些超參數(shù)包括:學(xué)習(xí)速度、動(dòng)量系數(shù)、參數(shù)懲罰系數(shù)、丟棄比例、batch的大小,以及定義網(wǎng)絡(luò)結(jié)構(gòu)的超參數(shù)等等。由于深度模型的訓(xùn)練需要巨大的計(jì)算資源,人工多次嘗試選擇合適的超參數(shù)不僅需要豐富的經(jīng)驗(yàn),而且非常費(fèi)時(shí)費(fèi)力。
為此,近年來面向機(jī)器學(xué)習(xí)的超參數(shù)自動(dòng)優(yōu)化方法越來越得到學(xué)術(shù)界的重視。目前,比較主流的方法是基于黑盒的貝葉斯優(yōu)化方法,其中具有代表性的有基于時(shí)序模型的算法配置(Sequential Model-based Algorithm Configuration, SMAC)[10]、Parzen樹估測(cè)(Tree Parzen Estimator, TPE)[11]和Spearmint算法[12]。由于這些方法需要重復(fù)多次運(yùn)行被優(yōu)化模型,以獲取優(yōu)化所必需的驗(yàn)證誤差,所以在優(yōu)化深度模型時(shí)它們的效率很低。另一種思路是自適應(yīng)的優(yōu)化方法,目前比較主流的方法有AdaGrad[14]、AdaDelta[15]、 RMSProp[16]、Adam[17]等。但這些方法大多只對(duì)學(xué)習(xí)速度進(jìn)行優(yōu)化,無法同時(shí)綜合優(yōu)化多個(gè)超參數(shù)。
本文利用DGM逐層訓(xùn)練的特點(diǎn),提出一種以神經(jīng)元激活的稀疏度(sparsity of Hidden Units, SHU)為目標(biāo)值,利用高斯過程(Gaussian Process, GP)[18]動(dòng)態(tài)對(duì)多個(gè)超參數(shù)進(jìn)行同時(shí)優(yōu)化的方法。神經(jīng)元激活狀態(tài)往往被領(lǐng)域?qū)<矣糜诒O(jiān)控DGM的訓(xùn)練過程是否處于理想狀態(tài)。在訓(xùn)練的中間階段,每一隱藏層的神經(jīng)元被激活太多或太少都會(huì)降低特征的提取效果。因此,本文利用當(dāng)前迭代時(shí)神經(jīng)元激活狀態(tài),通過比較不同超參數(shù)組合下,神經(jīng)元激活狀態(tài)的變化,利用GP預(yù)測(cè)其中最合適組合,進(jìn)行下一迭代的訓(xùn)練。該方法的優(yōu)勢(shì)在于通過自適應(yīng)的策略同時(shí)優(yōu)化多個(gè)超參數(shù),毋需象傳統(tǒng)貝葉斯方法那樣重復(fù)訓(xùn)練整個(gè)模型,同時(shí)自適應(yīng)的策略也大大提升DGM的特征提取的性能指標(biāo),以及對(duì)不同網(wǎng)絡(luò)結(jié)構(gòu)的穩(wěn)定性。
1 深度生成模型

圖1受限玻耳茲曼機(jī)(RBM)示意圖
深度生成模型是一種垂直多層的圖概率模型,它的基本構(gòu)件是RBM[7],如圖1所示,其中雙線圓圈代表輸入神經(jīng)元,細(xì)線圓圈代表隱藏層神經(jīng)元。RBM最大的特點(diǎn)是各層內(nèi)部神經(jīng)元之間沒有鏈接,這大大加快了層與層之間的隨機(jī)采樣效率。輸入層可以接受各種類型的數(shù)據(jù),包括:二進(jìn)制、實(shí)數(shù)和k組(k-array)數(shù)據(jù)。以二進(jìn)制為例,假設(shè)v∈{0,1}D為輸入層,h∈{0,1}F為隱藏層,則RBM的能量公式定義如下[1]:
E(v,h;θ)=
(1)
式中:W為單元之間的連接參數(shù);a,b為偏離項(xiàng)。為簡(jiǎn)化表達(dá),設(shè)θ={W,a,b},則模型的聯(lián)合概率定義如下[1]:
(2)

(3)
(4)
式中,g(x)=1/(1+e-x)。RBM訓(xùn)練的目的是獲得優(yōu)化的參數(shù)W,為此,Hinton和他的小組提出了對(duì)比散度(Contrastive Divergence)的算法[1]:
ΔW=α(EPdata[vhT]-EPT[vhT])
(5)
式中:α為學(xué)習(xí)速度,EPdata[·]為數(shù)據(jù)依賴期望值,EPT是利用Gibbs鏈近似所得的模型依賴期望值。
利用RBM堆疊,根據(jù)結(jié)構(gòu)和訓(xùn)練策略的差異,DGM又分為兩大經(jīng)典模型:DBN和DBM,如圖2所示。其中,DBN是混合概率圖模型,除了頂層為無向圖以外,其他各層均為有向圖;DBM則是完全無向圖,它們的訓(xùn)練方法詳見文獻(xiàn)[1]。


圖2深度置信網(wǎng)絡(luò)(DBN)與深度玻耳茲曼機(jī)(DBM)
圖中hi代表第i層隱藏層神經(jīng)元所組成的向量;Wi代表各層間的連接參數(shù)。
就像其他很多深度模型一樣,訓(xùn)練DGM最大的挑戰(zhàn)就是防止模型的過度擬合和參數(shù)崩潰。為此很多輔助機(jī)制被提了出來[9],如:利用動(dòng)量原理防止參數(shù)的巨烈波動(dòng);利用參數(shù)懲罰機(jī)制防止參數(shù)崩潰;利用丟棄部分神經(jīng)元或它們的鏈接方式防止過度擬合;以及根據(jù)訓(xùn)練集合理設(shè)計(jì)網(wǎng)絡(luò)結(jié)構(gòu)等等。這些輔助機(jī)制大大提升DGM的性能,然而為了調(diào)整和控制這些輔助機(jī)制,眾多的超參數(shù)也被發(fā)明出來,其中最為常用如表1所示。針對(duì)新的訓(xùn)練任務(wù)時(shí),即使領(lǐng)域?qū)<乙埠茈y一蹴而就找到的這么多超參數(shù)的優(yōu)化組合配置。

表1 深度生成模型的常用超參數(shù)的說明
2 超參數(shù)優(yōu)化算法
在訓(xùn)練DGM時(shí),大量的實(shí)踐經(jīng)驗(yàn)表明:在少數(shù)情況下被激活的神經(jīng)元比大多數(shù)情況下被激活的神經(jīng)元更加有價(jià)值[9]。因?yàn)閷?duì)于一個(gè)有效的DGM來講,當(dāng)特點(diǎn)神經(jīng)元被激活時(shí),表示模型從特定數(shù)據(jù)中探測(cè)到了特定的特征。圖3顯示了訓(xùn)練RBM時(shí)的4個(gè)模擬例子,其中3個(gè)是不理想的狀態(tài),一個(gè)為理想狀態(tài)。在此模擬例子中,數(shù)據(jù)的類別順序是被打亂的。其中,圖3(a)顯示隱藏層中大部分的神經(jīng)元被激活,很可能模型的參數(shù)W變得過大導(dǎo)致無法識(shí)別有效特征;圖3(b)則是圖3(a)反面,大部分神經(jīng)元都無法被激活,很可能參數(shù)變得過小而失去探測(cè)特征的能力;圖3(c)是一個(gè)有趣的例子,表示不管給任何數(shù)據(jù),其中部分神經(jīng)元總是被激活,導(dǎo)致神經(jīng)元的利用率不高;圖3(d)是相對(duì)比較理想的狀態(tài),當(dāng)某一數(shù)據(jù)到來時(shí)只會(huì)激活其中部分神經(jīng)元。
為在訓(xùn)練過程中得到較好的神經(jīng)元激活狀態(tài),提出了一種神經(jīng)元稀疏度的懲罰項(xiàng),利用交叉熵的方法實(shí)現(xiàn)實(shí)際激活比例與目標(biāo)激活比例之間的調(diào)和[9]。與此同時(shí),一個(gè)新的超參數(shù)——稀疏度懲罰系數(shù)被發(fā)明了出來。該方法無法把多個(gè)超參數(shù)之間相互微妙的影響關(guān)系考慮進(jìn)去。因此,本文提出一種新的以神經(jīng)元激活的稀疏度為目標(biāo)值,利用GP對(duì)稀疏度進(jìn)行預(yù)測(cè),并選出可能使神經(jīng)元激活狀態(tài)較優(yōu)的超參數(shù)組合的方法。


圖34個(gè)模擬RBM訓(xùn)練中隱藏層神經(jīng)元激活狀態(tài)圖,其中橫坐標(biāo)表示隱藏層的神經(jīng)元序號(hào),縱坐標(biāo)表示min-batch的大小
該方法的優(yōu)化法策略是在每次迭代時(shí),先固定當(dāng)前的超參數(shù),通過前一節(jié)描述的訓(xùn)練過程學(xué)習(xí)模型的參數(shù)W;然后固定W,利用GP學(xué)習(xí)并預(yù)測(cè)超參數(shù)。


(6)
μy*=m(λ*)+K*K-1(y-mλ(i))
(7)
(8)
式中:y*為預(yù)測(cè)的稀疏度;K是利用GP的協(xié)方差函數(shù)[18]從λ(i)計(jì)算的協(xié)方差矩陣,K*=k(λ*,λ(i)),K**=k(λ*,λ*);mλ(i)為由GP的均值函數(shù)[18]對(duì)λ(i)計(jì)算所得。利用式(6)得出的后驗(yàn)分布,可以快速從眾多超參數(shù)候選中選出最佳超參數(shù)的組合。
算法1基于高斯過程超參數(shù)優(yōu)化算法(在epoch:t)
輸入A(Vtrain),被優(yōu)化的模型;
Vtrain為訓(xùn)練集;
λbest上次迭代的最佳超參數(shù)配置;
Mtrials用來建立GP模型的樣本數(shù)量;
Mpredict預(yù)測(cè)最佳超參數(shù)的嘗試樣本數(shù)量;
interval采樣樣本的定義域范圍;
輸出λbest預(yù)測(cè)的最佳超參數(shù)配置;
1.fori=1 toMtrialsdo
2.在λbest±interval范圍內(nèi)隨機(jī)產(chǎn)生一個(gè)隨機(jī)配置λ(i);
3.λ(i)用訓(xùn)練模型A(Vtrain),計(jì)算yh(t)(i);
4.end for
5.forj=1 toMpredictdo
6.在λbest±interval范圍內(nèi)隨機(jī)產(chǎn)生一個(gè)隨機(jī)配置λ(j);

8.利用公式(9)選擇新的λbest;
9.end for
10.returnλbest。
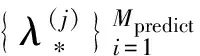
(9)
式中,λbest為上一epoch的最佳組合。
3 實(shí)驗(yàn)分析
在實(shí)驗(yàn)分析中,為驗(yàn)證本方法在以下3個(gè)方面的性能表現(xiàn):
(1) 優(yōu)化效率對(duì)比。與目前主流的超參數(shù)優(yōu)化方法(SMAC和TPE)進(jìn)行對(duì)比,驗(yàn)證本方法對(duì)DGM的超參數(shù)優(yōu)化效率。
(2) 針對(duì)不同DGM網(wǎng)絡(luò)結(jié)構(gòu)時(shí)性能的穩(wěn)定性分析。
(3) 在實(shí)際文本聚類的學(xué)習(xí)任務(wù)中,驗(yàn)證本超參數(shù)優(yōu)化方法在非監(jiān)督學(xué)習(xí)中的優(yōu)越表現(xiàn)。
3.1 超參數(shù)優(yōu)化效率的分析
這里對(duì)比包括本方法(SHU)在內(nèi)的不同的超參數(shù)優(yōu)化方法,比較它們對(duì)DGM的優(yōu)化速度。在DGM中選取其中兩種最經(jīng)典的模型:DBN[7]和DBM[8](見圖2)。
對(duì)比的超參數(shù)優(yōu)化方法包括兩種目前最主流的優(yōu)化器*http://www.automl.org/HPOLIB:SMAC[10]和TPE[11],具體采用了它們針對(duì)深度模型的改進(jìn)型*https://github.com/automl/pylearningcurve predictor。測(cè)試數(shù)據(jù)選擇MNIST手寫體數(shù)字,其中包括60 000個(gè)訓(xùn)練樣本和10 000個(gè)測(cè)試樣本,每個(gè)樣本為28×28像素的手寫體1~9的阿拉伯?dāng)?shù)字。
在針對(duì)MNIST分類任務(wù)中訓(xùn)練DBN和DBM一般劃分兩個(gè)階段:預(yù)訓(xùn)練和精調(diào)。本方法主要針對(duì)預(yù)訓(xùn)練階段。預(yù)訓(xùn)練階段,SHU和SMAC、TPE針對(duì)模型的初始化設(shè)置詳見表2、3。此外目標(biāo)稀疏度選擇為0.05。本方法在用到GP時(shí),length-scale參數(shù)和noise參數(shù)分別設(shè)為1和0.1。在精調(diào)過程中同樣集成SMAC和TPE作為優(yōu)化器,并給予相同的設(shè)置。整個(gè)訓(xùn)練過程的epochs設(shè)為100。測(cè)試指標(biāo)為分類精度。
圖4、5分別給出了在DBN和DBM上優(yōu)化速度的對(duì)比,結(jié)果顯示SHU比SMAC和TPE收斂速度更快,同時(shí)訓(xùn)練過程中的大部分時(shí)間內(nèi)SHU可以取得對(duì)比方法約一半的錯(cuò)誤。因此,該自適應(yīng)的方法不僅可以明顯提升優(yōu)化速度,并且?guī)椭鶧BN和DBM提升分類精度。

表2 本方法針對(duì)模型的超參數(shù)初始化設(shè)置

表3 SMAC和TPE針對(duì)模型的超參數(shù)初始化設(shè)置

圖4 DBN在MNIST上分類實(shí)驗(yàn)中學(xué)習(xí)曲線的對(duì)比
3.2 針對(duì)不同網(wǎng)絡(luò)結(jié)構(gòu)的穩(wěn)定性分析
初次使用DGM的人員由于經(jīng)驗(yàn)不足,往往會(huì)為選擇什么樣的網(wǎng)絡(luò)結(jié)構(gòu)而困擾。本文提出的自適應(yīng)超參數(shù)優(yōu)化方法,最大的優(yōu)勢(shì)之一在于可以很大程度減輕由于網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置的差異而帶來的性能的巨大變動(dòng)。本小節(jié)的實(shí)驗(yàn)重點(diǎn)驗(yàn)證不同網(wǎng)絡(luò)結(jié)構(gòu)下,自適應(yīng)超參數(shù)優(yōu)化方法的穩(wěn)定性。為了顯示本方法的優(yōu)勢(shì),我們與手工超參數(shù)設(shè)置進(jìn)行比較。

圖5 DBM在MNIST上分類實(shí)驗(yàn)中學(xué)習(xí)曲線的對(duì)比
這里選擇深度模型為DBN,測(cè)試數(shù)據(jù)集仍是MNIST,驗(yàn)證標(biāo)準(zhǔn)也是錯(cuò)誤率。根據(jù)多次嘗試,手工選擇一個(gè)較為優(yōu)化的超參數(shù)組合:[η,α,ε]=[0.5,1.0,0.000 1],其中η為動(dòng)量系數(shù),α為學(xué)習(xí)速度,ε為參數(shù)懲罰系數(shù)。針對(duì)自適應(yīng)方法,目標(biāo)稀疏度同樣選擇0.05,[η,α,ε]的初始化與表2相同。實(shí)驗(yàn)中選擇4種不同的網(wǎng)絡(luò)結(jié)構(gòu),分別為[784, 100]、[784, 200, 200]、[784, 500, 100]、[784, 400, 200, 100],如圖6所示。GP的length-scale參數(shù)和noise參數(shù)分別設(shè)為1和0.1。

圖6 不同DBN網(wǎng)絡(luò)結(jié)構(gòu)下的性能比較
圖6展示的實(shí)驗(yàn)結(jié)果顯示,不同DBN的網(wǎng)絡(luò)結(jié)構(gòu)下自適應(yīng)超參數(shù)優(yōu)化方法取得的錯(cuò)誤率明顯低于手工設(shè)置超參數(shù)方法的錯(cuò)誤率,并且性能相對(duì)較為穩(wěn)定。從比較結(jié)果可得,本方法可以幫助提升DBN在實(shí)際應(yīng)用中的穩(wěn)定性。
3.3 針對(duì)文本聚類的實(shí)驗(yàn)分析
DGM最大的優(yōu)勢(shì)在于能夠利用非監(jiān)督學(xué)習(xí)較好地提取數(shù)據(jù)的特征。本小節(jié)選取文本聚類這一典型的非監(jiān)督學(xué)習(xí)任務(wù),利用自適應(yīng)的超參數(shù)優(yōu)化對(duì)DBN進(jìn)行優(yōu)化,并將結(jié)果與目前主流的文本聚類算法,以及手工選取超參數(shù)的DBN做對(duì)比,驗(yàn)證本方法的優(yōu)越性。
這里選用的數(shù)據(jù)集是Reuters-21578數(shù)據(jù)集,它是由路透社提供并被Lewis*http://www.daviddlewis.com/resources/test collections/reuters21578/優(yōu)化過的數(shù)據(jù)集。選取30個(gè)類別,其中包括8 293篇文章和18 933個(gè)詞匯。當(dāng)去掉詞綴、詞根以及停用詞后,選取其中出現(xiàn)頻率最高的3 000個(gè)詞作為字典。
對(duì)比的方法包括:PLSA[19]、LDA[20]、NCut[21]、NMF[22]、lapGMM、Auto-encoder、DBN(手工調(diào)整超參數(shù))[7]。由于本方法是面相超參數(shù)優(yōu)化的,為公平起見,為對(duì)比方法也選擇了目前主流的超參數(shù)優(yōu)化器:SMAC。但是SMAC優(yōu)化器需要根據(jù)訓(xùn)練效果的某個(gè)目標(biāo)值,才能進(jìn)行優(yōu)化,這里采用了Perplexity[20]:
(10)
式中:M是文檔集D的大小;P(wi)是文檔中各個(gè)詞的概率,可以在各自算法的推理過程中得到;li是第i篇文檔的長度。為SMAC選取最大迭代預(yù)算為50。
采用DBN的網(wǎng)絡(luò)結(jié)構(gòu)是[4 000, 900, 400, 400, 30],相應(yīng)超參數(shù)初始化:[η,α,ε]=[0.5,1.0,0.000 1],目標(biāo)稀疏度仍設(shè)為0.05,GP的length-scale參數(shù)和noise參數(shù)分別設(shè)為1和0.1。實(shí)驗(yàn)的評(píng)價(jià)指標(biāo)為最終聚類的精度。
表4給出了Reuters-21578上文本聚類的實(shí)驗(yàn)結(jié)果。結(jié)果顯示基于神經(jīng)元激活稀疏度(SHU)的自適應(yīng)超參數(shù)優(yōu)化方法,不僅明顯提升DBN在文本聚類的性能效果,而且在聚類精度上優(yōu)于目前主流的文本聚類算法。圖7進(jìn)一步展示針對(duì)整個(gè)文本集,DBN最后一層神經(jīng)元激活的狀態(tài),顯示當(dāng)文本屬于某個(gè)類別時(shí),總是有特定的神經(jīng)元會(huì)被激活,表明了基于自適應(yīng)優(yōu)化方法的DBN在特征提取的有效性。

表4 Reuters-21578上文本聚類的實(shí)驗(yàn)結(jié)果

圖7 Reuters-21578上DBN最后一層神經(jīng)元激活狀態(tài)
4 結(jié) 語
本文提出了一種針對(duì)DGM的超參數(shù)自適應(yīng)優(yōu)化方法。該方法可以在每一epoch的訓(xùn)練過程中,根據(jù)各隱藏層神經(jīng)元激活度的變化,利用GP對(duì)最合適的超參數(shù)組合進(jìn)行預(yù)測(cè),并將預(yù)測(cè)所得超參數(shù)用于下一epoch的訓(xùn)練。該方法能夠在實(shí)驗(yàn)研究和實(shí)際應(yīng)用中,明顯提升DGM優(yōu)化效率。并且,由于該方法對(duì)不同網(wǎng)絡(luò)結(jié)構(gòu)的穩(wěn)定性較好,因此可以幫助缺乏DGM實(shí)驗(yàn)和應(yīng)用經(jīng)驗(yàn)的人員快速上手。進(jìn)一步實(shí)驗(yàn)也顯示在文本聚類的學(xué)習(xí)任務(wù)中,該方法能夠獲得比主流方法更好的性能。
參考文獻(xiàn)(References):
[1]Salakhutdinov R. Learning deep generative models[J].The Annual Review of Statistics and Its Application at Statistics. Annualreviews.org, 2015, 2(1):361-385.
[2]Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553):436-444.
[3]Bengio Y, Lamblin P, Popovici D,etal. Greedy layer-wise training of deep networks[C]// International Conference on Neural Information Processing Systems. MIT Press, 2006:153-160.
[4]Larochelle H, Bengio Y, Louradour J,etal. Exploring strategies for training deep neural networks[J]. Journal of Machine Learning Research, 2009, 1(10):1-40.
[5]Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786):504.
[6]Salakhutdinov R, Hinton G. Semantic hashing[J]. International Journal of Approximate Reasoning, 2009, 50(7).
[7]Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7):1527.
[8]Salakhutdinov R, Hinton G. An efficient learning procedure for deep Boltzmann machines[J]. Neural Computation, 2012, 24(8):1967.
[9]Hinton G E. A Practical Guide to Training Restricted Boltzmann Machines[M]// Neural Networks: Tricks of the Trade. Springer Berlin Heidelberg, 2012:599-619.
[10]Hutter F, Hoos H H, Leyton-Brown K. Sequential Model-Based Optimization for General Algorithm Configuration[M]// Learning and Intelligent Optimization. Springer Berlin Heidelberg, 2011:507-523.
[11]Bergstra J, Bardenet R, Kégl B,etal. Algorithms for Hyper-Parameter Optimization[C]// Advances in Neural Information Processing Systems, 2011:2546-2554.
[12]Snoek J, Larochelle H, Adams R P. Practical bayesian optimization of machine learning algorithms[J]. Advances in Neural Information Processing Systems, 2012, 4:2951.
[13]Domhan T, Springenberg J T, Hutter F. Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves[C]//AAAI Press, 2015.
[14]Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization[J]. Journal of Machine Learning Research, 2011, 12(7):2121-2159.
[15]Dauphin Y N, Vries H D, Bengio Y. Equilibrated adaptive learning rates for non-convex optimization[J]. Computer Science, 2015, 35(3):1504-1512.
[16]Rasmussen C E, Williams C K I. Gaussian process for machine learning[M]// Gaussian processes for machine learning. MIT Press, 2006:69-106.
[17]Hofmann T. Unsupervised learning by probabilistic latent semantic analysis[J]. Machine Learning, 2001, 42(1):177-196.
[18]Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3:993-1022.
[19]Ng A Y, Jordan M I, Weiss Y. On spectral clustering: Analysis and an algorithm[J]. Proceedings of Advances in Neural Information Processing Systems, 2002, 14:849-856.
[20]Bao L, Tang S, Li J,etal. Document clustering based on spectral clustering and non-negative matrix factorization[C]// International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, 2008.
[21]He X, Cai D, Shao Y,etal. Laplacian regularized gaussian mixture model for data clustering[J]. Knowledge & Data Engineering IEEE Transactions on, 2011, 23(9):1406-1418.
[22]Vincent P, Larochelle H, Bengio Y,etal. Extracting and composing robust features with denoisingautoencoders[C]// ICML, 2008:1096-1103.
·名人名言·
想像力比知識(shí)更重要,因?yàn)橹R(shí)是有限的,而想像力概括著世界上的一切,推動(dòng)著進(jìn)步,并且是知識(shí)進(jìn)化的源泉。嚴(yán)肅地說,想像力是科學(xué)研究中的實(shí)在因素。
——愛因斯坦
猜你喜歡
中等數(shù)學(xué)(2022年2期)2022-06-05 07:10:50
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級(jí))(2020年6期)2020-07-25 02:31:36
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級(jí))(2018年9期)2018-09-26 05:59:44
