基于Python的多線程網絡爬蟲的設計與實現
2018-04-10 01:40:00◆孫冰
網絡安全技術與應用 2018年4期
◆孫 冰
?
基于Python的多線程網絡爬蟲的設計與實現
◆孫 冰
(中國石油大學計算機與通信工程學院 山東 266580)
本文主要詳細介紹如何應用Python語言實現一個多線程的網絡爬蟲程序,并在此基礎上搭建特定的測試網站將串行爬蟲程序和多線程爬蟲程序的運行效率進行對比,進而給出提高網絡爬蟲性能的具體方法。
Python;網絡爬蟲;多線程
0 引言
隨著網絡技術的飛速發展,互聯網中的信息呈現爆炸式的增長,互聯網的信息容量也達到了一個前所未有的高度。為了方便人們獲取互聯網中的信息,國內外出現了一批搜索引擎,如Google、百度、Yahoo等等。這些搜索引擎的特點是能盡量多地抓取網頁中的信息,因而容易忽略抓取到的頁面的語義和抓取到的順序等。檢索人需要投入大量時間和精力來完成一次檢索,必要時還需要反復組織自己的檢索語言,以達到檢索的效果。傳統的搜索引擎在返回的結果方面有局限性,網絡爬蟲因此而誕生。網絡爬蟲又名叫網絡機器人,它是一種按照特定規則爬取網頁信息的程序。與傳統搜索引擎不同,網絡爬蟲只爬取想要獲得的特定類型的信息,進而提高搜索引擎的效率。
傳統的搜索引擎通常由網頁搜集、預處理和查詢這三個模塊組成,而網絡爬蟲就存在于網頁搜集這個模塊之中,網絡爬蟲作為搜索引擎[1]的重要組件,它的主要功能就是爬取互聯網上各類信息。網絡爬蟲通常是一個應用程序或者腳本,一般先給定一個入口URL地址,從入口URL開始根據一定的規則獲得這個初始網頁上的所有URL,再通過這些新的URL如此循環往復獲得更多的URL。在這些獲取到的URL中,按照我們需要信息的規則解析該網頁,最后再根據不同的需求對獲取到的數據進行處理。網絡爬蟲與傳統檢索方式對比如圖1所示。
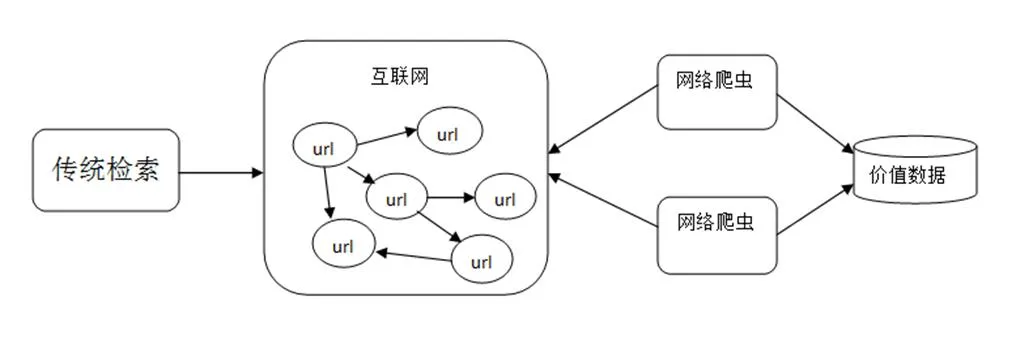
圖1 網絡爬蟲與傳統檢索方式對比圖
理論上任何一種支持網絡通信的語言都可以用來編寫爬蟲程序,目前大多數網絡爬蟲程序是用后臺腳本語言來編寫,其中Python是最為廣泛使用的一種語言,其具有豐富和強大的標準庫供用戶選擇使用[2]。
1 網絡爬蟲的設計實現
本文采用簡單的框架結構來編寫爬蟲程序,分別有以下四個模塊[3]:URL管理器、網頁下載器、網頁解析器、網頁輸出器,這四個模塊共同完成抓取網頁的整個過程。
(1)URL管理器
URL管理器模塊的作用是管理待爬取的URL集合和已爬取過的URL集合。每個網頁爬取的信息,均包括一些指向其他網頁的URL,同樣其他網頁的信息中也包含指向本網頁的URL,因此不同的URL之間存在著一種循環指向的問題。如若對它置之不理,網絡爬蟲程序就會在這些URL之間循環抓取,比較嚴重的情況是兩個URL相互指向對方,如果爬蟲程序一直在這兩個URL之間抓取信息,就會形成死循環。因此URL管理器有一個很重要的作用就是防止重復抓取和循環抓取網頁。
(2)網頁下載器
網頁下載器的主要功能把網頁對應的URL下載到本地,它是整個爬蟲程序的核心組件。網頁下載器和瀏覽器相似,它從互聯網上下載URL對應的網頁,將其內容按照HTML的格式下載,然后按照本地文件或者本地字符串的形式來存儲,然后再進行后續的分析處理。
(3)網頁解析器
將互聯網上的URL下載到本地后,需要通過網頁解析器對該URL進行解析才能夠提取出所需要的內容。簡而言之,網頁解析器是從網頁中提取人們需要的數據的工具。從一個搜索引擎來看,網頁解析器首先會將網頁中所有的URL提取出來,以便后續進行訪問。本文所做的是一個定向爬蟲,除了將網頁中的待爬取的URL提取出來之外,還要將所需要和感興趣的數據提取出來。即是說網頁解析器會把網頁下載器下載的HTML網頁文檔字符串作為輸入來提取出需要的內容和未訪問過的待爬取的URL列表。
(4)網頁輸出器
網頁輸出器實際是網頁處理的一部分,抓取到網頁的數據后,利用網頁解析器提取出該網頁中需要的數據,然后將這些數據寫入本地的一個HTML文件中。如果想要對抓取到的數據進行其他的處理,就需要修改相應的代碼,增加新的功能模塊。在本課題研究中,主要是將爬取到的網頁內容存儲到本地的HTML文件中,網頁輸出器需要對外提供兩個方法,其主要的方法是實現寫入文件這個功能。
網絡爬蟲運行流程如圖2所示,由爬蟲的總調度程序來啟動或停止爬蟲,查看爬蟲的運行情況。在爬蟲程序中,URL管理器用來管理待爬取的URL列表和已經爬取過的URL列表,從URL管理器中取出一個URL,判斷該URL是否被爬取過,如果是未被爬取的URL,則將這個鏈接發送到網頁下載器。下載器下載由URL鏈接指向的網頁,并將下載下來的內容以字符串的形式存儲下來,然后會把這個字符串提交到網頁解析器,由網頁解析器進行解析,會解析出我們所需要的數據。同時每個頁面中都有指向其他頁面的鏈接,通過網頁解析器把它們都解析出來后,增添到URL管理器中。這三個部分共同構成了一個循環,只要有滿足條件的URL,程序就一直持續運行。
2 并行爬蟲程序的實現
在串行網絡爬蟲的基礎上,可以實現多線程的網絡爬蟲程序,當爬蟲開始執行后,程序向網頁發送訪問網頁的請求,然后程序等待網頁作出響應。等待時間越長,效率也就越低。當程序采用多線程時,交互消息期間的平均等待時間有所降低,可以提高數據抓取的效率。同樣給定一個入口URL,從這個入口URL的網頁頁面內容之中解析出所有的URL鏈接。如果這些鏈接沒有被訪問過,增添到待爬取URL的隊列中,然后再從待爬取的URL列表中取出一條進行訪問和解析。程序中需要增加一段創建線程池的代碼,一開始給定一個最大線程數,每在待爬取的URL列表中取出一個URL時就添加一項任務入隊列,執行任務時,就從隊列中出取出一項任務并執行。
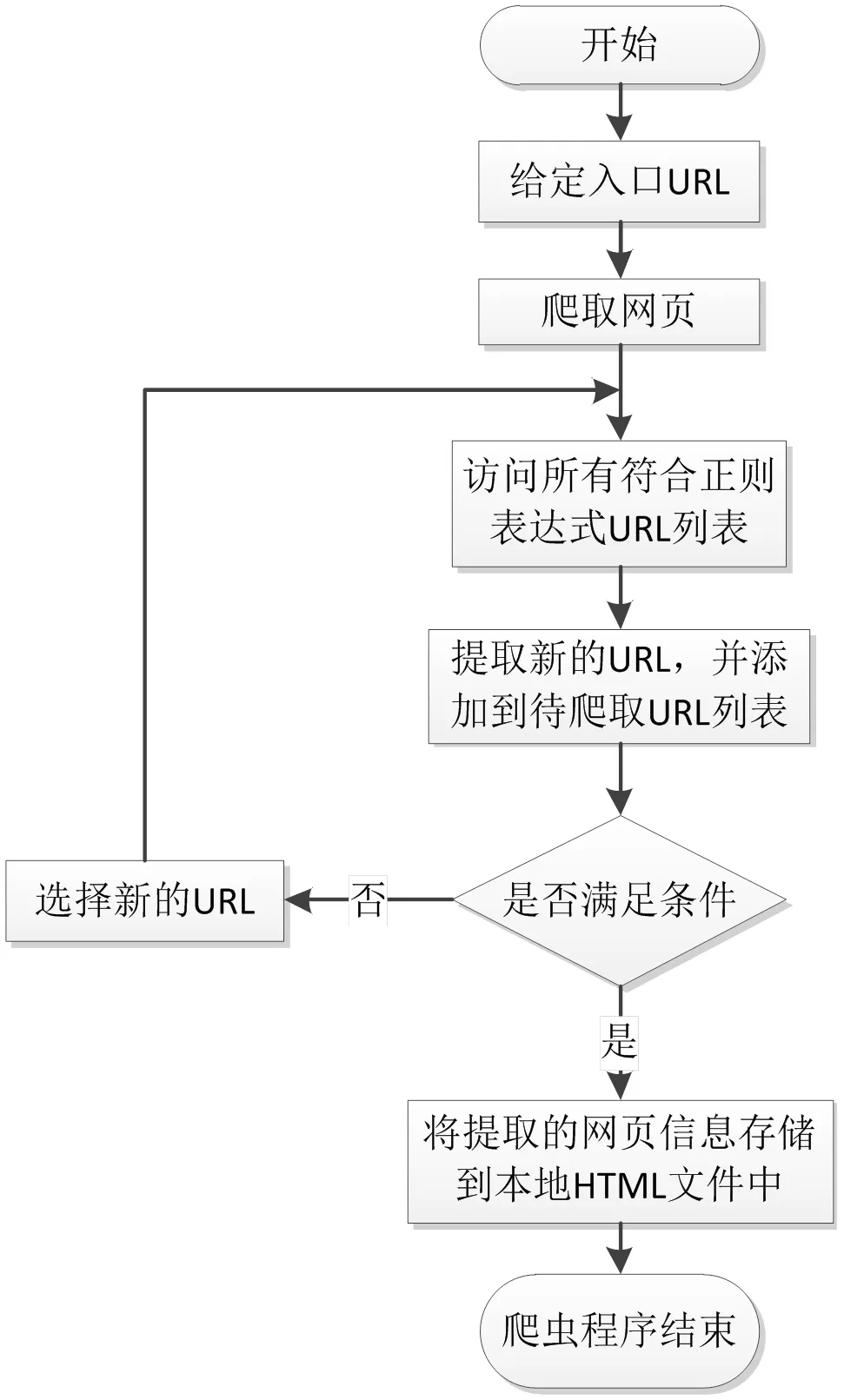
圖2 網絡爬蟲運行流程圖
3 實驗設計與分析
將網絡爬蟲程序的入口地設定為http://stackoverflow.com/questions網頁,設定程序爬取1000個網頁就停止運行,打印程序運行的時間,將串行爬蟲程序和多線程爬蟲程序的運行時間進行對比。以爬取網頁的數量100、300、500、800、1000作為橫坐標,以爬蟲程序的運行時間(單位為s)作為縱坐標,分別畫出不同的網頁規模下,線程個數分別為1、3、5、8、10、15的時候運行時間的變化。折線圖如圖3所示。
從圖3中可以得出下面幾點結論:
當爬取的網頁數量為100的時候,串行爬蟲程序的運行時間和在不同線程個數下爬蟲的運行時間相差不大。當爬取的網頁數量為300和500時,線程數量的增加也并沒有讓運行時間有顯著性的提高。因此使用多線程的爬蟲程序一般也只是在網站規模大,爬取的網頁數量很多時才會有顯著的提升效率的作用。
選定某一個網頁規模觀察數據,會發現線程數增加的時候運行的時間沒有降低反而增加,是因為線程之間進行切換也需要耗費時間。因此增加線程數量并不是絕對的提高線程,根據程序運行的環境的不同,能夠提高爬蟲程序運行效率的最大線程的個數也不相同。

圖3 特定網頁規模下線程數—爬蟲運行時間折線圖
4 總結與展望
通過本文的實驗可以得出,在特定的條件下,通過增加爬蟲程序的線程數能夠提高網絡爬蟲的效率,但是在設置網絡爬蟲線程的時候也要考慮多種因素,比如說過多線程之間的切換所耗費的系統資源以及程序運行時所在網絡情況[4],而且有的網站會限制下載的速度,線程的數量太多時,大量線程訪問網頁,某些線程會被掛起。后期可以考慮在多臺服務器上分布式[5]部署網絡爬蟲,實現分布式爬蟲之間的通信模式,進而提高網絡爬蟲的效率。
[1]薛建春.垂直搜索引擎中網絡蜘蛛的設計與實現[D].北京:中國地質大學檢測技術與自動化裝置自動檢測及應用, 2007.
[2]姜彬彪, 黃凱林, 盧昱江等.基于Python的專業網絡爬蟲的設計與實現[J].企業科技與發展(企業科技創新版), 2016.
[3][澳] Richard Lawson著,李斌譯.用Python編寫網絡爬蟲[M].人民郵電出版社, 2016.
[4]陽國貴, 姜波.線程切換開銷分析工具的設計與實現[J]. 計算機應用, 2010.
[5]王毅桐.分布式網絡爬蟲技術研究與實現[D].成都:電子科技大學信息安全, 2012.
猜你喜歡
人大建設(2019年12期)2019-05-21 02:55:44
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
中華手工(2017年2期)2017-06-06 23:00:31
環球時報(2017-03-30)2017-03-30 06:44:45
中國衛生(2015年3期)2015-11-19 02:53:32
中國衛生(2015年12期)2015-11-10 05:13:38
中外會展(2014年4期)2014-11-27 07:46:46
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
計算機應用文摘(2009年17期)2009-04-29 00:44:03
