基于特征選擇的K-means聚類異常檢測方法
2018-04-10 01:46:21◆樊蓉李娜
網(wǎng)絡(luò)安全技術(shù)與應(yīng)用 2018年4期
◆樊 蓉 李 娜
?
基于特征選擇的K-means聚類異常檢測方法
◆樊 蓉 李 娜
(四川大學(xué)計(jì)算機(jī)學(xué)院 四川 610065)
K-means算法是一種采用距離作為相似性評(píng)價(jià)指標(biāo)的聚類算法,其快速簡潔的特點(diǎn)在異常檢測場景中有一定的應(yīng)用價(jià)值。但是,傳統(tǒng)的K-means聚類算法在選取初始中心和度量相似性上有一定缺陷。針對(duì)傳統(tǒng)的K-means算法中存在的問題,本文對(duì)原有的方法進(jìn)行了改進(jìn)。第一,在初始化聚類中心時(shí)選取了一種優(yōu)化的方法作為初始聚類中心,替代原有的隨機(jī)選擇方法以減少計(jì)算量和迭代次數(shù)。第二,采用基于信息熵屬性加權(quán)的樣本相似性度量來進(jìn)一步精確樣本差異。實(shí)驗(yàn)過程中,針對(duì)異常檢測數(shù)據(jù)含有冗余特征,對(duì)樣本數(shù)據(jù)做了冗余特征過濾,實(shí)驗(yàn)結(jié)果表明改進(jìn)之后的方法較傳統(tǒng)的K-means算法有更好的檢測效果。
K-means算法;異常檢測;聚類;冗余特征
0 引言
異常檢測就是假設(shè)入侵行為異常于正常行為,如果當(dāng)前行為與正常行為存在一定的偏差就認(rèn)為系統(tǒng)受到攻擊[1]。這個(gè)特點(diǎn)使其有能力識(shí)別未知類型的攻擊,異常檢測是入侵檢測方面的一個(gè)研究熱點(diǎn)。從Wenke Lee[2]使用數(shù)據(jù)挖掘方法得到屬于不同數(shù)據(jù)的行為輪廓開始,聚類算法在異常檢測方面廣為使用。江頡[3]和Aljarah[4]針對(duì)K值選取提出的改進(jìn)聚類算法,周涓等人[5]針對(duì)中心選取提出的一種多個(gè)聚類中心選擇算法等。K-means聚類算法在異常檢測方面有著廣泛的應(yīng)用和良好的效果。但是存在幾個(gè)問題,一是K個(gè)中心初始位置的選取和確定,中心初始位置選擇不好會(huì)導(dǎo)致迭代次數(shù)增多和計(jì)算量增大,嚴(yán)重影響聚類效果;二是樣本度量問題,K-means算法采用各屬性無差異的歐式距離來計(jì)算樣本之間的相似性,沒有考慮不同屬性權(quán)重對(duì)樣本的影響使得相似性度量不準(zhǔn)確;三是冗余屬性和噪音會(huì)對(duì)聚類結(jié)果產(chǎn)生偏離,計(jì)算時(shí)對(duì)效率影響較大。針對(duì)方法涉及的幾個(gè)問題,本文提出一種基于特征選擇的K-means聚類算法。首先,采用Fisher特征選擇對(duì)特征重要度排序,用順序前向最優(yōu)搜索的方法快速確定所選特征數(shù)量由小到大的最優(yōu)特征子集,所選的特征子集能最大程度的代表原始特征,并且去除不必要的特征和噪音。其次,采用一種優(yōu)化的方法來選取初始聚類中心以減少計(jì)算量和迭代次數(shù);最后,計(jì)算各屬性的信息熵作為屬性權(quán)重來度量樣本之間的差異,區(qū)別不同屬性對(duì)樣本的貢獻(xiàn)。本文提出的方法在異常檢測方面取得不錯(cuò)的檢測效果。
1 一種改進(jìn)的K-means聚類算法
1.1 K-means聚類算法
K-means算法是一種典型的基于距離度量相似性的聚類算法,算法的主要思想是差異最小最相似,根據(jù)樣本之間的相似程度劃分至相應(yīng)的簇內(nèi)[6]。具體流程如圖1所示:

圖1 K-means聚類流程
1.2信息熵屬性權(quán)重確定
信息熵是一種客觀權(quán)重確定方法,它是在原始數(shù)據(jù)的基礎(chǔ)上,表示信息有用程度大小的一種度量方式。具體流程如圖2所示:

圖2 信息熵屬性權(quán)重計(jì)算
1.3改進(jìn)的K-means聚類算法
傳統(tǒng)的K-means聚類算法選擇聚類中心的方法為隨機(jī)選擇,導(dǎo)致聚類迭代次數(shù)增多和計(jì)算量增大,陷入局部最優(yōu)以及樣本各屬性的平等對(duì)待影響聚類效果。為了消除這種影響,本文提出的方法在原有的方法上進(jìn)行改進(jìn),一定程度消除了以上因素的影響。具體流程如圖3所示:

圖3 改進(jìn)k-means聚類流程圖
2 基于特征選擇的K-means聚類異常檢測方法
2.1 Fisher特征選擇
Fisher特征選擇是一種基于距離度量的過濾式特征選擇算法。其基本思想為將不同類樣本間的距離最大化及將同類樣本間的距離最小化[7]。Fisher特征選擇算法流程如下圖4所示:

圖4 Fisher分特征排序
2.2基于特征選擇的K-means聚類異常檢測
首先對(duì)輸入樣本根據(jù)Fisher分進(jìn)行特征選擇,采用前向序列搜索選出能夠代表樣本的最優(yōu)特征子集,然后基于改進(jìn)的K均值算法進(jìn)行聚類,方法流程如圖5所示。
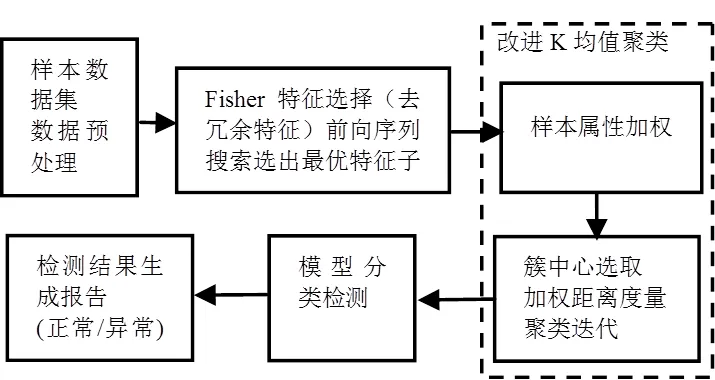
圖5 基于特征選擇的K-means聚類異常檢測流程
3 實(shí)驗(yàn)測試與分析
3.1實(shí)驗(yàn)數(shù)據(jù)與評(píng)價(jià)指標(biāo)
實(shí)驗(yàn)將選取10000條樣本記錄作為實(shí)驗(yàn)數(shù)據(jù)集輸入,每一條樣本記錄由41維向量特征組成。在進(jìn)行實(shí)驗(yàn)之前,對(duì)樣本記錄做標(biāo)準(zhǔn)化和歸一化處理以消除樣本差異及覆蓋等影響。實(shí)驗(yàn)效果則采用檢測率、誤報(bào)率、檢測時(shí)間為評(píng)價(jià)指標(biāo)。其中,樣本集來自當(dāng)前入侵檢測領(lǐng)域權(quán)威數(shù)據(jù)集KDD,實(shí)驗(yàn)平臺(tái)為開放的數(shù)據(jù)挖掘平臺(tái)weka。
3.2實(shí)驗(yàn)設(shè)計(jì)與結(jié)果分析
本文設(shè)置三組實(shí)驗(yàn):
第一組實(shí)驗(yàn)的目的是證明本文的特征選擇所選出的特征對(duì)于聚類檢測具有可行性。實(shí)驗(yàn)采用Fisher分對(duì)抽樣的41維數(shù)據(jù)進(jìn)行排序的結(jié)果如表1所示:

表1 Fisher分對(duì)數(shù)據(jù)特征排序
為了得到最優(yōu)的特征子集并且不丟失必要的特征,本文采用前向序列搜索依次加入5、3、2、1個(gè)特征進(jìn)行聚類的結(jié)果如圖6所示:
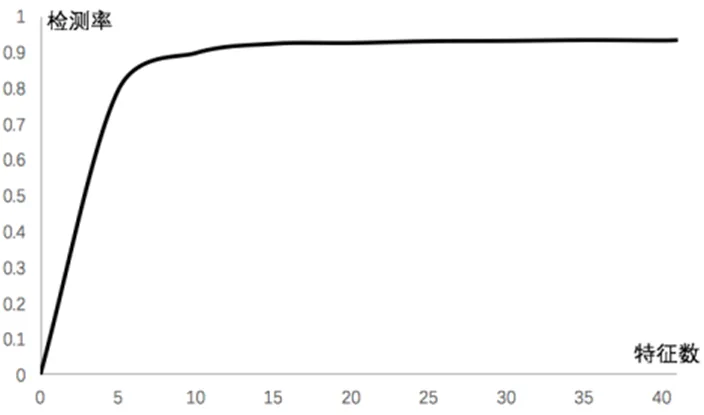
圖6 特征數(shù)與聚類檢測率結(jié)果
通過實(shí)驗(yàn),從圖中可以看出,首先加入前5個(gè)特征有較好的檢測率,然后逐次加入3、2、1個(gè)特征時(shí)檢測率有所提高,當(dāng)所加入的特征數(shù)為11時(shí),檢測率趨于穩(wěn)定,通過前向序列搜索得出最優(yōu)特征子集為{23 32 24 12 3 2 33 27 34 28 4},相比于原始41維數(shù)據(jù),得到的最優(yōu)特征子集能很好的得到檢測效果,與原始的數(shù)據(jù)檢測率相當(dāng),有效的減少了計(jì)算資源。
第二組實(shí)驗(yàn)設(shè)計(jì)了2000條數(shù)據(jù)樣本,分別采用本文改進(jìn)的K-means聚類方法和傳統(tǒng)方法做聚類對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)檢測結(jié)果如圖7所示。
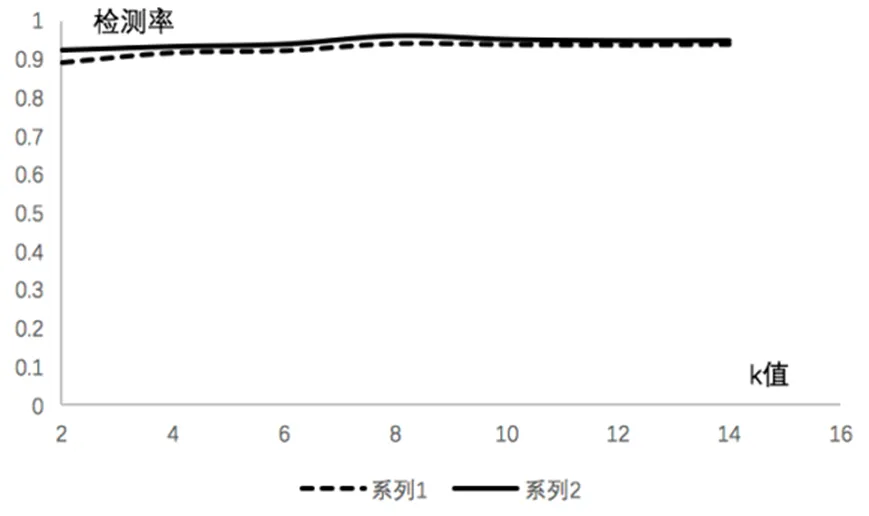
圖7 傳統(tǒng)K-means與改進(jìn)K-means檢測率對(duì)比
圖7中序列1代表傳統(tǒng)的K-means算法,序列2代表改進(jìn)的K-means算法。實(shí)驗(yàn)數(shù)據(jù)分析可以得出在K取不同值情況下檢測結(jié)果也會(huì)隨之變化,當(dāng)K取值為8時(shí),兩種方法的檢測效果都達(dá)到最佳。由于改進(jìn)的方法優(yōu)化聚類中心的選取,采用信息熵加權(quán)的距離計(jì)算,使得檢測率高于傳統(tǒng)方法。
第三組實(shí)驗(yàn)的目的在于驗(yàn)證本文提出的方法能夠取得較好的檢測結(jié)果。設(shè)計(jì)兩組相同數(shù)據(jù)集,采用兩種方法做對(duì)比實(shí)驗(yàn),重復(fù)實(shí)驗(yàn)10次,實(shí)驗(yàn)取平均值。檢測結(jié)果如表2所示:

表2 傳統(tǒng)K-means與本文方法檢測結(jié)果對(duì)比
通過本組對(duì)比實(shí)驗(yàn)可以看到本文改進(jìn)的方法在檢測的誤報(bào)率相當(dāng)?shù)那闆r下,在檢測率上有一定的提高,在檢測時(shí)間上也有著顯著的縮減。由于采用特征選擇去除不必要特征使得數(shù)據(jù)維數(shù)縮減,減少了聚類時(shí)間,去除的噪音數(shù)據(jù)也消除了對(duì)樣本相似性度量的影響。同時(shí),優(yōu)化的聚類中心選取與加權(quán)的距離度量也使得檢測的檢確率有一定的提升。
4 結(jié)束語
本文通過Fisher進(jìn)行特征選擇過濾了冗余特征,大大縮減了檢測時(shí)間,提高檢測效率,同時(shí)采用改進(jìn)的K-means算法進(jìn)行聚類檢測提高了檢測率。經(jīng)實(shí)驗(yàn)驗(yàn)證可以得到,本文提出的改進(jìn)的K-means聚類異常檢測方法相較于傳統(tǒng)的方法有著較好的檢測效果。
[1]卿斯?jié)h, 蔣建春, 馬恒太等.入侵檢測技術(shù)研究綜述[J]. 通信學(xué)報(bào),2004 .
[2]Lee W, Stolfo S J.A framework for constructing features and models for intrusion detection systems[J].ACM Transactions on Information and System Security(TISSEC),2000.
[3]江頡, 王卓方, 陳鐵明等.自適應(yīng)AP聚類算法及其在入侵檢測中的應(yīng)用[J].通信學(xué)報(bào), 2015.
[4]Aljarah I,Ludwig S A.Parallel particle swarm optimization clustering algorithm based on MapReduce methodology[C]/ /Proc of the 4th World Congress on Nature and Biologically Inspired Computing. [S.l.]: IEEE Press,2012.
[5]周涓, 熊忠陽, 張玉芳等.基于最大最小距離法的多中心聚類算法[J].計(jì)算機(jī)應(yīng)用, 2006.
[6]李銳,李鵬,曲亞東,王斌譯.Peter HARRINGTON.機(jī)器學(xué)習(xí)實(shí)戰(zhàn)[M].北京:人民郵電出版社, 2013.
[7] 程正東,章毓晉,樊祥等.常用Fisher判別函數(shù)的判別矩陣研究[J].自動(dòng)化學(xué)報(bào),2010.
[8]CHENG Zhengdong,ZHANG Yujin,F(xiàn)AN Xiang,et al.Study on Discriminant Matrices of Commonly-Used Fisher Discriminant Functions [J]. SctaAutomaticaSinica,2010.
國家重點(diǎn)研發(fā)計(jì)劃(2016yfb0800604,2016yfb0800605),國家自然科學(xué)基金項(xiàng)目(61572334)。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
