學習矢量量化神經網絡在財務失敗預測中的應用
2018-03-22 08:12:44康彩麗
長治學院學報 2018年5期
康彩麗
(山西大同大學 渾源師范分校,山西 渾源 037400)
財務失敗又叫財務困境、財務危機,是指企業沒有按時履行合同,清償到期息金而產生的困難和危機,其具體表現包括持續性虧損、無償付能力、違約和破產等。實際上,很多企業的財務危機是一個循序漸進的過程,都是隨著財務狀況從異常到惡化,最終產生財務失敗的。中國加入世界貿易組織以來,金融銀行業的競爭也逐漸激烈,中國證券市場逐步開放,并與世界金融業市場接軌。國內證券市場監管的不完善、上市公司的坑蒙拐騙,給金融業投資者的信念以嚴重打擊。由此可見,幫助投資者避免風險,對不同上市公司企業財務狀況進行判別,是迫切需要解決的問題。
2 LVQ神經網絡概述
學習矢量量化 LVQ(Learning Vector Quantization)神經網絡由芬蘭學者Teuvo Kohonen提出,屬于前向神經網絡,在模型判別和優化領域有著廣泛的應用。
2.1 LVQ神經網絡結構
LVQ神經收集是由輸入層、隱含層與輸出層三層構成。其中,在網絡的輸入層和隱含層之間是完全連接的,在隱含層與輸出層間是部分連接,每個隱含層神經元和輸出層神經元的不同組相連接。LVQ神經網絡結構如圖1所示。
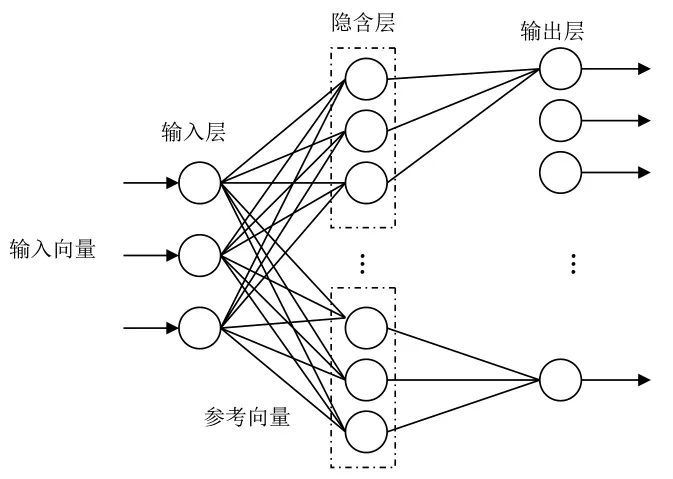
圖1 LVQ神經網絡布局圖
2.2 學習矢量量化網絡算法流程
LVQ算法的訓練過程如圖2所示。
由圖可見,首先初始化網絡設定變量和參量。令
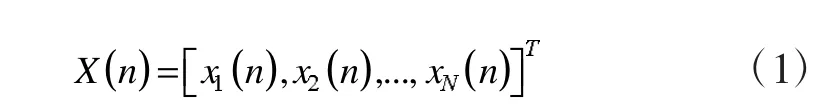
為輸入向量或稱訓練樣本。令
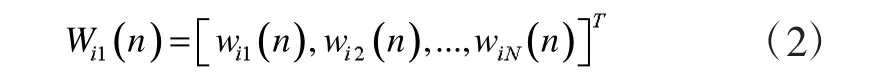
為權值向量,i=1,2,…,M。選擇學習速率的函數η(n),設n為迭代次數,N為迭代總次數,令學習速率為η(0),權值向量為Wi(0),再從訓練集合中選取輸入向量。通過歐氏距離最小準則為
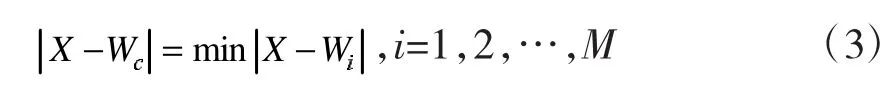
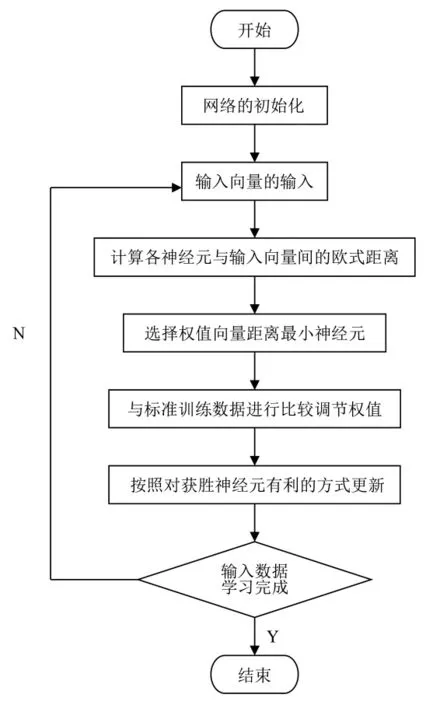
圖2 LVQ的訓練過程圖
最后,尋找得出獲勝的神經元,從而實現了神經元的競爭過程。根據前面學習原則調動獲勝神經元權值向量,可以鑒定分類是否正確。鑒定迭代次數是否超出跨越N,再改變學習速率η(n),如果n≤N就轉到輸入向量作為輸出,否則完成迭代過程。
2 財務失敗預測模型的建立
在構建分析財務失敗預測模型時,建構破產預測模型的財務數據均來自我國上市公司的可靠數據,其中選用的財務破產公司是指持續兩年虧本(即為凈利潤<0)或每股純財產小于股票面值,并將選中行業的其他公司為一般公司,以財務狀況異常第一次發作日為基準日,選取這些公司在基準日前兩年的財務報表數據。共選取了財務狀況異常的102家公司,正常的481家公司,共583家公司構建了樣板的集合。這里選取了14個公司作為樣本,其中8個是非ST公司,6個是ST公司。
2.1 練習和嘗試集合的割據
把全部樣板數據分成訓練集與測試集。討論結果顯示,在分類模型的構建過程中,要想所建模型具有較強的健壯性,就必須讓訓練集合中兩類樣本數據的數目相同,所以本次實踐的練習集是由ST和非ST公司各自的5個樣本組成。測驗集中1個為ST公司,3個為非ST公司,用于預測評估在訓練集上構建的LVQ網絡模型的預測精度。
2.2 財務指標的選取
利用LVQ算法進行財務失敗預測時,首先應該提出有關財務失敗的重要指標確定網絡結構。財政預測指標的選取在很大程度上在很大程度上決定了預測模型的預測精度。Altman在成立企業破產預測的Zeta模型時,最早的財務標準選用遵循了兩個準則:一是該目標在以前的研究中出現的頻率;二是目標和要研究問題的潛在相關性。文章中財務指標的采取主要結合以下幾個原則:(1)顯示公司償還本息能力的原則;(2)反映公司運營收益原則;(3)結合以往倒閉預警研究采取的財務標準;(4)可實踐性原則;(5)可比性原則。
本著全面反應企業的財務狀況、增長可操作性、下降預測成本的原則,概括并借鑒前人的研究成果,考慮上述原則后,LVQ預測模型的特征向量是以下五個財務指標。
(1)凈資產收益率,可衡量公司對股東投入資本的利用效率,凈資產收益率=稅后利潤/所有者權益。它彌補了每股稅后利潤指標的不足。
(2)流動比率=流動資產/流動負債,它是反映企業變現能力的重要指標。
(3)股本權益比率從不同的側面來反映企業長期財務狀況,股本權益比率=股本權益總額/資產總額,這個比率越大,資產負債比率就越小,相應的企業財務風險就越小,該企業償還長期債務的能力就越強。
(4)總資產增長率越高,表明企業一定時期內資產經營規模擴張的速度越快。總資產增長率=本年總資產增長額/年初資產總額×100%,其中,本年總資產增長額=年末資產總額-年初資產總額。
3 在MATLAB環境下實現財務失敗預測
根據LVQ神經網絡理論,在MATLAB軟件中編寫程序實現基于LVQ神經網絡的財務失敗預測。
3.1 財務失敗預測的MATLAB實現
3.1.1 輸入向量的目標向量設計
這里用5個ST公司與5個非ST公司的樣板作為網絡的訓練樣本。
p=[0.26 0.23 0.65 0.21 0.78 0.75 0.82 0.19 0.83 0.16;
0.12 0.11 0.50 0.14 0.52 0.49 0.51 0.13 0.57 0.16;
0.19 0.21 0.50 0.17 0.50 0.50 0.50 0.18 0.51 0.21;
0.32 0.29 0.61 0.27 0.61 0.60 0.60 0.30 0.60 0.23;
0.27 0.20 0.76 0.24 0.69 0.75 0.71 0.21 0.72 0.19];
這些樣本的類別為:
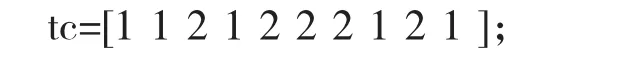
表示第一第二第四第八與第十組樣本屬于一類,即ST公司,其余五組屬于一類,即非ST公司。
將類型向量tc利用函數ind2vec改變為網絡可以使用的目標向量t:
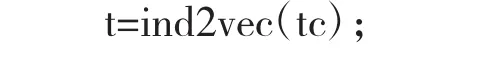
3.1.2 網絡的創建
神經網絡工具箱中作為建立LVQ收集的函數為newlvq,利用該函數創建一個LVQ網絡。
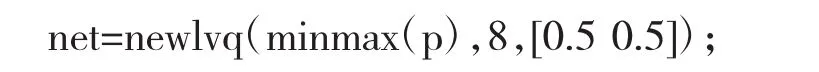
上式中,競爭層神經元的數量為8,[0.5 0.5]表示輸入樣本中兩類數據各占50%,學習速率與學習算法都取默認值,分別是0.01和learnlv1。
3.1.3 網絡的訓練
創建LVQ網絡后就需要有效的對網絡進行訓練。訓練是采取神經網絡工具箱中的train函數,訓練步數為1000。
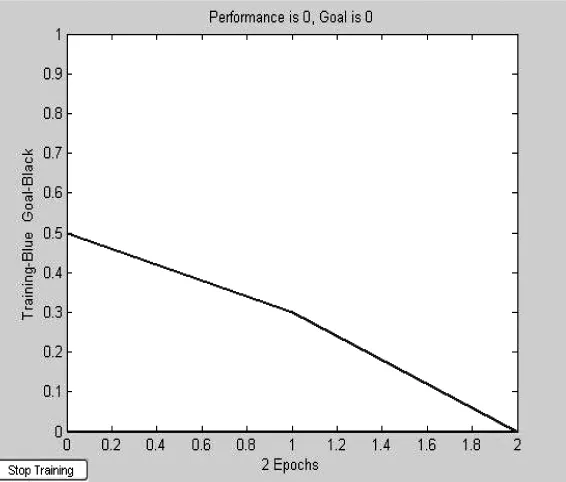
圖3 訓練結果

訓練結果為

可見,網絡的訓練函數為train,經過兩次訓練后,網絡誤差就達到了要求。訓練結果如圖3所示。
3.1.4 仿真
檢查網絡能否對訓練組樣板的輸入向量進行正確分類,是利用仿真函數sim對訓練好的網絡進行仿真。

輸出結果為
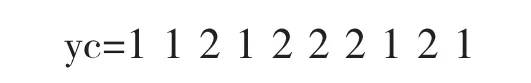
yc=tc,可見網絡的分類是正確的。仿真結果表明,網絡分類的精度非常高。
3.1.5 預測模型的建立
文章采取交織檢驗法對模型進行測試,即利用已構建的LVQ網絡對測試組的數據(后1個ST公司和后3個正常公司)進行劃分。

可見網絡對輸入向量進行了成功分類。
3.2 訓練誤差分析
通過逐步訓練發現當競爭層神經元個數為8時,網絡的收斂速度比較快,而當隱含層神經元的個數為10時網絡的訓練過程卻變得緩慢了。并且將其個數增加到12時顯得訓練過程更為緩慢,表明收斂速度并沒有明顯地隨著隱含層神經元數目的增加而加快的趨勢,從而得出一個重要的結論:并非隱含層神經元的個數越多,網絡的性能就越好。所以需要恰當選取競爭層神經元的個數,才能達到較好的訓練效果,滿足網絡訓練的要求。
4 財務失敗預測的BP網絡模型
4.1 財務失敗預測的BP網絡模型
利用BP算法進行財務失敗預測時,首先應該確定有關財務失敗的重要指標與BP網絡的結構。同樣選取和前面一樣的5個指標作為輸入向量。以公司是否為ST作為輸出。在具體預測時0表示ST的公司的輸出值,1表示非ST的公司的輸出值,該公司財務狀況越好時輸出值越接近1,反之則越差。因輸入樣本為5個輸入向量,輸入層就一共需要5個神經元。中間隱含層選取11個神經元.輸出層用1個神經元。BP網絡即為5×11×1的結構。網絡中間層的神經元傳遞函數采用的是S型正切函數tansig,輸出層神經元傳遞函數采用的是純線性函數purelin,網絡參數如表2所示。

表2 網絡參數
經過3次訓練后。網絡誤差達到要求,訓練結果如圖4所示。
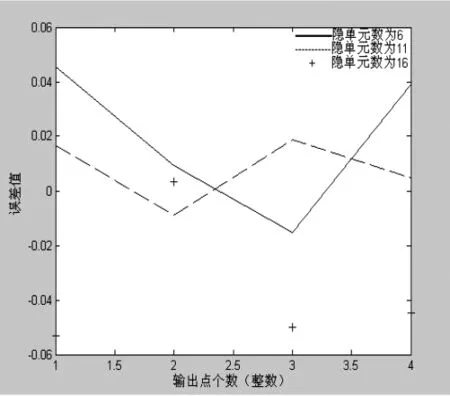
圖4 BP網絡的預測誤差對比曲線
4.2 LVQ網絡模型與BP網絡模型的比較
對比LVQ網絡訓練誤差曲線,雖然兩種模型的訓練次數都是1000,學習速率都是0.01,但明顯地看出,BP網絡模型的訓練時間比較長,訓練過程收斂速度也較緩慢。雖然 MSE=1.86335e-005/0.0001,即輸出的均方誤差已經很小了,但相對LVQ網絡模型誤差較大,網絡的性能還沒有為0,訓練目標誤差也沒有達到0。實驗結果表明,LVQ神經網絡相對傳統的BP網絡方法有較高的預測準確率,對輸入向量實現了成功分類,在這一領域有著良好的應用前景。
5 結束語
財務失敗預測在財務界和實務界引起了極大的關注,它的判別方法和模型層出不窮。由此以來成為了財務管理研究的熱點。企業財務失敗預測有兩個方面的重要性:一是作為早期警告系統,判斷方法和模型可以提醒管理者企業是否在變壞,是否應當采用有針對性的法子避免失敗;二是金融界的決定者能夠對企業做出評估和挑選,是借助于它的判別方法和模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
江西理工大學學報(2022年2期)2022-07-26 07:05:36
活力(2021年6期)2021-08-05 07:24:28
現代企業(2021年2期)2021-07-20 07:57:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代經濟信息(2020年34期)2020-06-08 06:02:40
數學物理學報(2020年2期)2020-06-02 11:29:24
意林·全彩Color(2019年9期)2019-10-17 02:25:48
河南水利年鑒(2017年0期)2017-05-19 02:29:27
光學精密工程(2016年6期)2016-11-07 09:07:19
