融合上下文依賴和句子語(yǔ)義的事件線索檢測(cè)研究*
2018-03-12 08:38:43邱盈盈姚建民周國(guó)棟
計(jì)算機(jī)與生活 2018年3期
王 凱,洪 宇,邱盈盈,姚建民,周國(guó)棟
蘇州大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,江蘇 蘇州 215006
1 引言
事件線索檢測(cè)(event nugget detection)作為信息抽取(information extraction)的一個(gè)任務(wù),旨在從非結(jié)構(gòu)化的文本中提取觸發(fā)事件的文本片段,并辨別所抽取事件的真?zhèn)涡浴8鶕?jù)KBP 2015(knowledge base population)事件線索檢測(cè)任務(wù)的定義,事件線索檢測(cè)由兩個(gè)子任務(wù)組成:(1)事件線索詞識(shí)別(event nugget recognition),需要抽取出觸發(fā)事件的詞或短語(yǔ),并識(shí)別出事件的類型;(2)事件真?zhèn)涡宰R(shí)別(event realis recognition),在事件線索詞識(shí)別的基礎(chǔ)上,進(jìn)一步辨別出事件發(fā)生的真?zhèn)涡浴楦玫乩斫釱BP評(píng)測(cè)事件線索檢查任務(wù),下面給出一個(gè)完整的事件線索的結(jié)構(gòu)表述。例句1中,事件線索詞為“sends”(譯為運(yùn)送),所觸發(fā)的事件類型為T(mén)ransport-Person,其事件真?zhèn)涡詾锳ctual(表示事件真實(shí)發(fā)生)。本文研究將只專注于事件線索詞識(shí)別部分,即找出事件線索詞并判定其事件類型。
例句1France sends soldiers to Haiti Feb29.
譯文:“法國(guó)于2月29日將士兵運(yùn)送到海地。”
事件線索詞:sends
事件類型:Transport-Person
事件真?zhèn)涡裕篈ctual
事件線索檢測(cè)的研究還在起步階段,現(xiàn)有的方法主要沿用 ACE 2005(automatic content extraction)事件抽取的方法。大部分前人工作將事件檢測(cè)看成一個(gè)分類問(wèn)題,人工精心設(shè)計(jì)了很多的詞匯級(jí)和句法級(jí)的特征(特征工程),并使用已有的自然語(yǔ)言處理工具進(jìn)行獲取(如詞性標(biāo)注、句法分析、命名實(shí)體識(shí)別等工具)。這些方法盡管取得很好的性能,但是一方面會(huì)耗費(fèi)大量的時(shí)間,另一方面會(huì)有特征稀疏和錯(cuò)誤傳遞的問(wèn)題(無(wú)法利用遠(yuǎn)距離的依賴信息和句子的語(yǔ)義信息)。
最近,深度學(xué)習(xí)已經(jīng)在很多自然語(yǔ)言處理任務(wù)上被使用,并被證明是有效的,例如機(jī)器翻譯、分詞和情感分析。深度學(xué)習(xí)模型以詞向量作為輸入,自動(dòng)學(xué)習(xí)特征,解決特征稀疏的問(wèn)題,極小化對(duì)特征提取工具的依賴,減少錯(cuò)誤傳遞,提高模型性能。
前人的很多研究會(huì)提取上下文特征,如句法特征,這樣可以利用更大范圍的信息提高識(shí)別準(zhǔn)確度。如圖1,在S1中,當(dāng)判定候選事件線索詞“release”的事件類型時(shí),句子前面的詞“court”可以幫助將“release”事件類型識(shí)別為“Release-Parole”。然而“court”和“release”之間沒(méi)有直接的依存路徑,很難使用依存句法特征建立兩個(gè)詞之間的聯(lián)系。而常用的上下文詞窗口方法可以簡(jiǎn)單增加窗口大小,將二者連接起來(lái),但這樣會(huì)加劇特征稀疏的問(wèn)題,同時(shí)過(guò)大的窗口會(huì)引入大量噪音。因此,有必要在不增大詞窗口和不使用依存特征的情況下,能夠有效抓取遠(yuǎn)距離的依賴關(guān)系。

Fig.1 An example of event nugget detection圖1 事件線索檢測(cè)示例
對(duì)于一些常用詞,如S2中的“l(fā)oss”,由于其詞義很多,僅僅依靠詞的局部特征很難判定其事件類型。如果能獲取S2句子的語(yǔ)義信息(“gambl”),會(huì)有助于推理出“l(fā)oss”觸發(fā)“Transfer-Money”事件而不是“Die”事件。獲取句子的語(yǔ)義信息,將有助于提高事件線索詞識(shí)別的準(zhǔn)確性。
本文提出一種神經(jīng)網(wǎng)絡(luò)方法,能有效抓取上下文依賴,并學(xué)習(xí)句子的語(yǔ)義表示,用于事件線索檢測(cè)。本文該方法主要由兩部分組成:(1)利用雙向長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(bidirectional long short-term memory,Bi-LSTM)獲取待測(cè)詞前面和后面的上下文依賴關(guān)系;(2)通過(guò)門(mén)控循環(huán)神經(jīng)網(wǎng)絡(luò)(gated recurrent neural network,GRNN)自動(dòng)地從句子所有的詞表示中學(xué)習(xí)句子的語(yǔ)義表示。這些有用的信息自然地被用來(lái)判定待測(cè)詞是否是事件線索詞以及是什么事件類型。在KBP 2015 Event Nugget評(píng)測(cè)提供的數(shù)據(jù)集上的實(shí)驗(yàn)證明,與baseline相比,本文方法取得了明顯的提升。
綜上所述,本文的貢獻(xiàn)如下:
(1)提出一種新的神經(jīng)網(wǎng)絡(luò)模型,并應(yīng)用到事件線索檢測(cè)任務(wù)中,避免了特征工程方法帶來(lái)的特征稀疏和錯(cuò)誤傳遞的問(wèn)題。
(2)在KBP 2015 Event Nugget評(píng)測(cè)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果顯示,本文網(wǎng)絡(luò)方法比傳統(tǒng)特征工程方法和最近提出的神經(jīng)網(wǎng)絡(luò)方法性能都要好。
2 相關(guān)工作
事件線索檢測(cè)是信息抽取和自然語(yǔ)言處理的一個(gè)基礎(chǔ)任務(wù),旨在檢測(cè)出文本中的事件線索詞并判斷事件類型。事件線索詞識(shí)別方面的研究才剛剛起步,主要方法還是沿用事件抽取的方法。
現(xiàn)有事件抽取的方法大多數(shù)把該問(wèn)題看成一個(gè)分類任務(wù),使用詞匯、句法和知識(shí)庫(kù)、詞典等人工設(shè)計(jì)的特征構(gòu)造分類器[1-4]。盡管基于特征的方法很有效,但是實(shí)際應(yīng)用時(shí)會(huì)遇到兩個(gè)問(wèn)題:(1)特征的選擇是一個(gè)人工過(guò)程,需要領(lǐng)域的專業(yè)知識(shí)。這意味著在應(yīng)用到新的領(lǐng)域時(shí),需要做額外的研究,這樣會(huì)限制快速適應(yīng)新領(lǐng)域的能力。(2)用于提取特征的自然語(yǔ)言處理的工具和資源可能會(huì)出現(xiàn)錯(cuò)誤,并把這些錯(cuò)誤傳遞到最后的事件分類。
神經(jīng)網(wǎng)絡(luò)具有很強(qiáng)的特征和語(yǔ)義學(xué)習(xí)能力,能從數(shù)據(jù)中自動(dòng)學(xué)習(xí)文本表示,而且在很多自然語(yǔ)言處理任務(wù)上取得了很好的性能。在事件抽取任務(wù)中,最近有兩個(gè)工作[5-6]探索了神經(jīng)網(wǎng)絡(luò)在事件抽取任務(wù)上的效果,二者都利用神經(jīng)網(wǎng)絡(luò)自動(dòng)學(xué)習(xí)特征,并用來(lái)判斷待測(cè)詞是否是觸發(fā)詞。其中,Chen等人[5]提出DMCNN(dynamic multi-pooling convolutional neural network)模型提取句子層次的特征和語(yǔ)義信息,忽略了待測(cè)詞上下文信息;而Nguyen等人[6]提出了一種融合實(shí)體類別特征和詞位置特征的卷積神經(jīng)網(wǎng)絡(luò),然而該方法把上下文限制在固定的窗口下,導(dǎo)致長(zhǎng)句子中詞義表示的丟失。
3 任務(wù)描述
事件線索檢測(cè)是KBP的一個(gè)任務(wù),旨在從非結(jié)構(gòu)化的文本中自動(dòng)抽取出觸發(fā)事件的詞或短語(yǔ),并對(duì)事件的真?zhèn)涡赃M(jìn)行識(shí)別。為了理解任務(wù),如下給出事件線索檢測(cè)中涉及的相關(guān)術(shù)語(yǔ)定義。
(1)事件線索詞(Event Nugget):觸發(fā)詞或短語(yǔ)(通常為名詞性或動(dòng)詞性的詞或短語(yǔ))。
(2)事件類型(Event Type):描述事件線索的類別,根據(jù)KBP 2015 Event Nugget評(píng)測(cè)的定義,共包含8種事件類別和38種子類別(本文針對(duì)38種事件的子類別進(jìn)行研究,不考慮類別之間的層次關(guān)系)。
(3)事件真?zhèn)涡裕‥vent Realis):描述事件線索發(fā)生的真?zhèn)涡裕ˋctual、General和Other共3種類別。其中Actual表示根據(jù)事件線索在特定時(shí)間和地點(diǎn)確實(shí)發(fā)生的事件;Generic表示泛化事件,即不要求在特定時(shí)間和地點(diǎn)發(fā)生,例如“Use of the death penalty is rare in Indonesia.”(譯文:印度尼西亞的死刑很少),事件線索詞“death”表示Die事件,即為泛化事件;Other表示沒(méi)有發(fā)生的事件、未來(lái)事件和條件事件等。
(4)事件線索描述(event mention):包含事件觸發(fā)詞的短語(yǔ)或句子。
本文專注于事件線索詞的識(shí)別及事件類型判定。下面采用例句2進(jìn)行說(shuō)明:
例句2Two policemen were killed in a bomb attack in Palmanova yesterday.
譯文:“昨天在帕爾馬洛城,兩名警察在炸彈襲擊中喪生。”
事件線索檢測(cè)應(yīng)該正確地識(shí)別出句子中單詞“killed”觸發(fā)了事件,并判定觸發(fā)的事件類型是“Die”事件。
4 融合上下文依賴和句子語(yǔ)義的事件線索檢測(cè)方法
本文利用雙向LSTM抓取句子中長(zhǎng)距離依賴關(guān)系,并借助GRNN學(xué)習(xí)句子的語(yǔ)義表示,合并兩個(gè)模型的輸出,進(jìn)而用來(lái)判定待測(cè)詞是否為事件線索詞并判斷其事件類型。下面將詳細(xì)介紹雙向LSTM模型和GRNN模型。
本文利用word2vec工具并且選用skip-gram模型[7],在英文新聞?wù)Z料上訓(xùn)練詞向量(word embedding)來(lái)表示每個(gè)詞。每個(gè)詞表示成低維連續(xù)實(shí)數(shù)向量,即詞向量。所有詞向量存放在詞向量矩陣Lw∈Rd×|V|中,d是詞向量的維度,|V|是詞典的大小。
4.1 LSTM模型
長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(long short-term memory,LSTM)[8]是循環(huán)神經(jīng)網(wǎng)絡(luò)的一個(gè)變種。普通RNN(recurrent neural network)模型在當(dāng)前時(shí)刻隱藏層的狀態(tài)依賴于前一個(gè)時(shí)刻。給定一個(gè)序列X=(x1,x2,…,xt,…,xn),RNN計(jì)算當(dāng)前隱藏狀態(tài)方法如下:

其中,f是非線性激活函數(shù)(sigmoid函數(shù)或tanh函數(shù))。盡管RNN在很多任務(wù)上取得了很好的效果,如語(yǔ)音識(shí)別、語(yǔ)言建模和文本分類,但是由于RNN在反向傳播算法(back propagation through time,BPTT)訓(xùn)練時(shí)會(huì)出現(xiàn)梯度消失和梯度爆炸的問(wèn)題,很難訓(xùn)練學(xué)習(xí)長(zhǎng)距離的依賴信息。
如圖2,LSTM模型通過(guò)設(shè)計(jì)3個(gè)門(mén)和記憶細(xì)胞,使網(wǎng)絡(luò)能學(xué)習(xí)何時(shí)遺忘以前的信息,何時(shí)用新的信息更新記憶細(xì)胞,從而解決普通RNN的固有問(wèn)題。LSTM已經(jīng)成功應(yīng)用到很多NLP(natural language processing)任務(wù)中,如分詞[9]、文本分類[10]和機(jī)器翻譯[11]。因此,可以應(yīng)用LSTM模型從數(shù)據(jù)中學(xué)習(xí)長(zhǎng)距離的依賴信息。
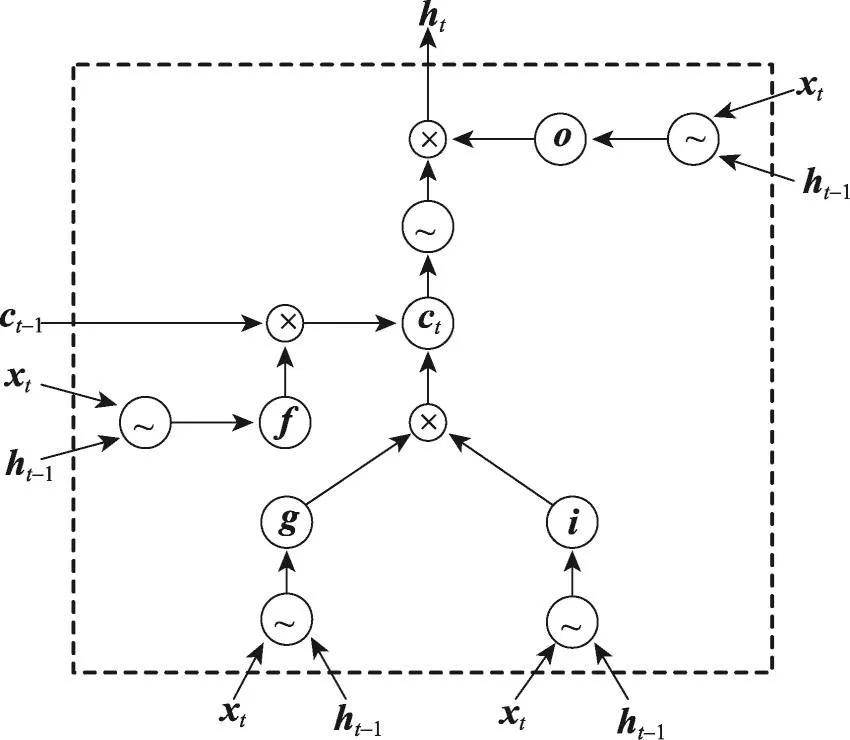
Fig.2 Structure of LSTM圖2LSTM網(wǎng)絡(luò)結(jié)構(gòu)
LSTM模型的核心是記憶細(xì)胞(memory cell),用于保存歷史信息。記憶單元的讀寫(xiě)操作由輸入門(mén)、輸出門(mén)和遺忘門(mén)控制。門(mén)的定義和記憶細(xì)胞的更新和輸出定義如下:

其中,σ表示sigmoid函數(shù);⊙表示向量對(duì)應(yīng)元素的乘積(element-wise multiplication);W、U是權(quán)重矩陣;b表示偏置;it、ft、ot分別表示t時(shí)刻的輸入門(mén)、遺忘門(mén)和輸出門(mén);ct存儲(chǔ)細(xì)胞的狀態(tài);ht是當(dāng)前時(shí)刻的LSTM單元的輸出。需要注意的是本文LSTM模型不包含窺視孔連接(peephole connection)。
LSTM模型構(gòu)造了一個(gè)能存儲(chǔ)歷史信息的記憶細(xì)胞,從而能更好地利用長(zhǎng)距離的依賴信息。LSTM模型在很多NLP任務(wù)中取得了比普通RNN更好的性能提升。
4.2 雙向LSTM模型
單向的LSTM模型只能利用待測(cè)詞之前的上下文,而無(wú)法利用待測(cè)詞之后的上下文信息。在事件線索詞識(shí)別任務(wù)中,人們希望對(duì)于某個(gè)待測(cè)詞進(jìn)行判定時(shí)既可以利用之前的上下文依賴關(guān)系,也可以利用之后的。雙向LSTM模型提供了一個(gè)解決方案,通過(guò)包含兩個(gè)獨(dú)立的正反方向的LSTM層,融合待測(cè)詞之前和之后的上下文。
對(duì)于給定的句子x1,x2,…,xt,…,xn包含n個(gè)詞,每個(gè)詞被表示成d維向量,一個(gè)LSTM計(jì)算待測(cè)詞xt及其左邊句子上下文x1:xt的表示-→ht(從左到右計(jì)算),另一個(gè)LSTM從右到左計(jì)算待測(cè)詞xt及其右邊的上下文xt:xn的表示←-本文將前者稱為前向LSTM(forward LSTM),將后者稱為后向LSTM(backward LSTM)。這兩個(gè)網(wǎng)絡(luò)使用不同的參數(shù),組合起來(lái)稱之為雙向LSTM網(wǎng)絡(luò),如圖3所示。
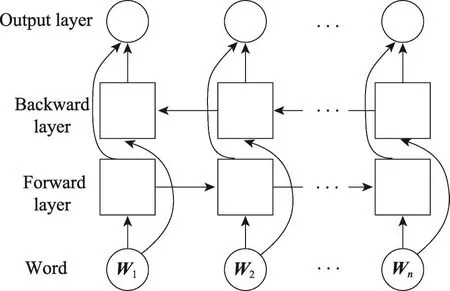
Fig.3 Bidirectional LSTM network圖3 雙向LSTM網(wǎng)絡(luò)

4.3 學(xué)習(xí)句子表示
下一步將是從輸入的句子學(xué)習(xí)包含語(yǔ)義信息的分布式向量表示(distributed vector representation)。
前人工作使用卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)和長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)計(jì)算句子的連續(xù)表示[12-13]。LSTM是當(dāng)前最好的句子語(yǔ)義建模的方法,能從不定長(zhǎng)的句子中學(xué)習(xí)固定長(zhǎng)度的向量,能抓取句子中的詞序信息而不依賴于句法分析。
本文使用一個(gè)經(jīng)過(guò)修改的LSTM模型,將其命名為GRNN,形式化定義如下:
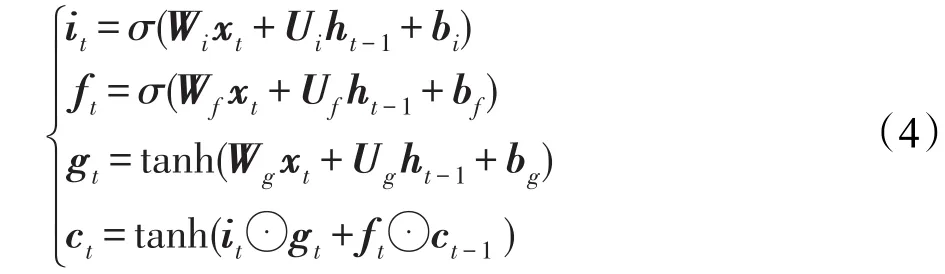
該模型可以看作是去掉輸出門(mén)的LSTM模型,這樣模型會(huì)傾向于不丟棄句子中任何部分的語(yǔ)義信息,從而能得到更好的句子語(yǔ)義表示。圖4左邊的網(wǎng)絡(luò)結(jié)構(gòu)展示了使用最后一個(gè)隱藏狀態(tài)作為句子的語(yǔ)義表示,這是基本的表示方法。除此之外,本文將池化(pooling)應(yīng)用到所有的隱藏狀態(tài)c1,c2,…,cn,獲取句子的語(yǔ)義信息。池化可從變長(zhǎng)句子中抽取固定維度的向量。常見(jiàn)的池化方法有最小池、最大池和平均池,在本文提出的模型中將使用最大池。圖5為本文模型的圖示說(shuō)明,其中h包含雙向LSTM獲取的上下文依賴,s表示GRNN學(xué)習(xí)得到語(yǔ)義表示,h與s串接后輸出到包含softmax的輸出層。
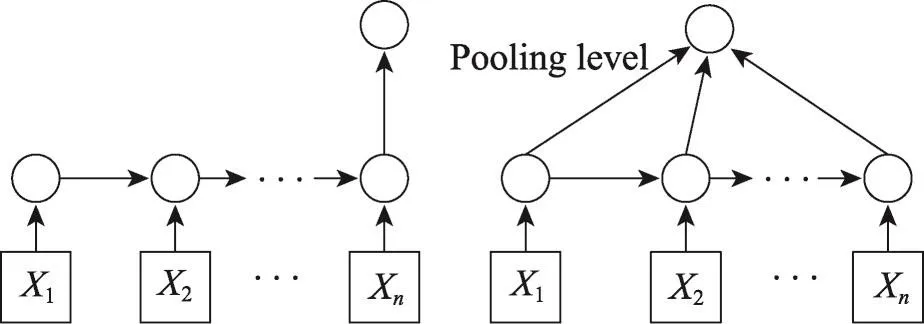
Fig.4 Learning semantic representation of sentence with GRNN圖4 使用GRNN學(xué)習(xí)句子的語(yǔ)義表示
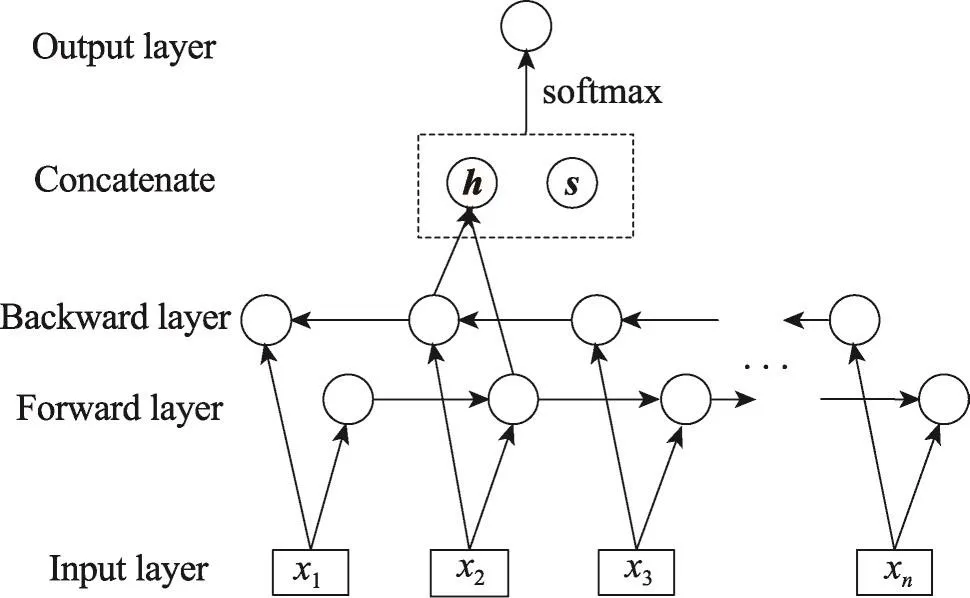
Fig.5 Illustration of this paper model圖5 本文模型的圖示說(shuō)明
4.4 輸出
將雙向LSTM輸出ht與學(xué)習(xí)到的句子語(yǔ)義表示連接起來(lái),得到一個(gè)包含待測(cè)詞上下文依賴關(guān)系和句子的語(yǔ)義向量F=[ht;s]。為了對(duì)待測(cè)詞事件類型進(jìn)行分類,首先增加一個(gè)線性層將向量F變換成長(zhǎng)度等于類別數(shù)量C的實(shí)數(shù)向量,然后增加softmax層使實(shí)數(shù)向量轉(zhuǎn)換成條件概率分布,計(jì)算過(guò)程如下:

其中,W為轉(zhuǎn)移矩陣;O是網(wǎng)絡(luò)的輸出結(jié)果,O的維度C等于事件類型加上“Null”(表示待測(cè)詞不是事件線索詞)的個(gè)數(shù)。為了防止過(guò)擬合,在輸出層之前(倒數(shù)第二層)增加dropout層[14]。
4.5 訓(xùn)練
在模型訓(xùn)練部分,本文使用事件線索的正確分布Pgold(x)和模型預(yù)測(cè)分布P(x)之間的交叉熵(cross entropy)加上L2范式作為損失函數(shù),定義如下:
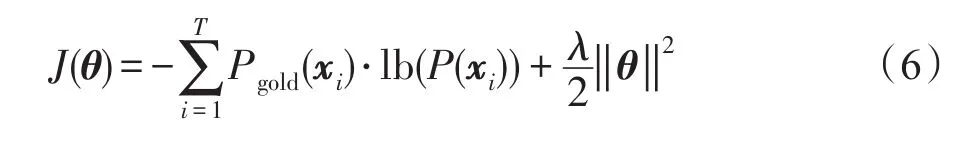
其中,T表示訓(xùn)練集數(shù)量;C是事件類型加上“Null”(表示待測(cè)詞不是事件線索詞)的個(gè)數(shù);xi表示待測(cè)詞;θ表示整個(gè)模型所使用到的參數(shù);Pgold(xi)采用one-hot表示,維度與類別數(shù)目一致,但是只有正確的事件類型對(duì)應(yīng)的那一維是1,其他維度都為0。
為了計(jì)算模型的參數(shù)θ,本文使用帶有Adadelta更新規(guī)則[15]的隨機(jī)梯度下降法來(lái)極小化損失函數(shù)。
5 實(shí)驗(yàn)
5.1 實(shí)驗(yàn)數(shù)據(jù)和評(píng)價(jià)方法
本文針對(duì)事件線索檢測(cè)中的事件線索詞識(shí)別的任務(wù),使用KBP 2015 Event Nugget評(píng)測(cè)提供的訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù),訓(xùn)練數(shù)據(jù)包含158篇文檔,測(cè)試數(shù)據(jù)包含202篇文檔。為了便于調(diào)節(jié)模型參數(shù),本文隨機(jī)從訓(xùn)練數(shù)據(jù)中選取15篇作為開(kāi)發(fā)集,其余143篇作為訓(xùn)練集。測(cè)試數(shù)據(jù)中的全部202篇文檔作為測(cè)試集。
實(shí)驗(yàn)采用準(zhǔn)確率(Precision)、召回率(Recall)和F1值作為評(píng)價(jià)標(biāo)準(zhǔn),并使用KBP 2015官方提供的評(píng)價(jià)工具進(jìn)行計(jì)算。為了便于說(shuō)明,后面將本文提出的模型簡(jiǎn)寫(xiě)成CSNN(context dependency and semantic representation based neural network)。
5.2 參數(shù)設(shè)置
神經(jīng)網(wǎng)絡(luò)的超參數(shù)對(duì)模型的性能有顯著的影響,本文在開(kāi)發(fā)集上調(diào)節(jié)模型的超參數(shù)。詞向量的維度設(shè)置為200維,LSTM和GRNN的隱藏層維度均為100。使用帶mini-batch的隨機(jī)梯度下降法訓(xùn)練,并使用AdaDelta更新規(guī)則。AdaDelta包含兩個(gè)參數(shù)ρ和ε,實(shí)驗(yàn)中ρ設(shè)定為0.9,ε設(shè)定為1E-6。對(duì)dropout層,dropout rate設(shè)定為0.5。使用-0.2到0.2之間均勻分布隨機(jī)初始化模型中的矩陣參數(shù)。
實(shí)驗(yàn)選用的詞向量是利用word2vec工具在英文新聞?wù)Z料上使用skip-gram算法訓(xùn)練得到的。
5.3 對(duì)比系統(tǒng)
本文使用以下系統(tǒng)與本文提出的模型進(jìn)行對(duì)比。
(1)ME(maximum entropy model):使用 Li[1]在ACE事件抽取任務(wù)中所用的詞匯層面和句法層面的特征。
(2)CRF(conditional random field):特征與 ME一致。
(3)DMCNN:Chen等人[5]利用DMCNN模型在ACE 2005事件抽取任務(wù)上取得很好的效果,本文實(shí)現(xiàn)了該模型并應(yīng)用到事件線索任務(wù)上。
(4)CNN:Nguyen等人[6]利用卷積神經(jīng)網(wǎng)絡(luò),并結(jié)合實(shí)體和位置信息,學(xué)習(xí)到有效的特征表示。
(5)BLENDER:KBP 2015事件線索檢測(cè)任務(wù)中取得最好性能的系統(tǒng),利用標(biāo)簽傳播算法擴(kuò)大數(shù)據(jù)集,并使用最大熵分類器對(duì)候選詞進(jìn)行分類。
系統(tǒng)ME和CRF是傳統(tǒng)的基于特征工程的方法,而系統(tǒng)DMCNN和CNN使用神經(jīng)網(wǎng)絡(luò)模型,能自動(dòng)學(xué)習(xí)特征。因?yàn)锽ELNDER系統(tǒng)利用標(biāo)簽傳播算法擴(kuò)大數(shù)據(jù)集,所以后面的實(shí)驗(yàn)結(jié)果分析中沒(méi)有與其進(jìn)行詳細(xì)對(duì)比。
5.4 實(shí)驗(yàn)結(jié)果
表1給出了所有方法在KBP 2015測(cè)試集上的實(shí)驗(yàn)結(jié)果。從表1中可以看出:在事件線索詞識(shí)別上,本文方法CSNN相比ME和CRF的準(zhǔn)確率雖然有所降低,但召回率提升很多,最終F1值分別提升5.70%和4.90%;在事件線索詞分類上,CSNN的F1值相比ME和CRF分別提升1.58%和2.95%。CSNN能取得這樣的性能結(jié)果,說(shuō)明本文方法是有效的。ME和CRF是傳統(tǒng)方法,使用了豐富的人工設(shè)計(jì)的特征。而CSNN只使用了詞向量,不需要其他特征。CSNN避免了傳統(tǒng)方法非常耗時(shí)的特征選取過(guò)程,節(jié)省人力和時(shí)間。除此之外,CSNN沒(méi)有使用復(fù)雜的特征提取工具來(lái)抽取特征,避免了錯(cuò)誤傳遞。

Table 1 Overall performance of different methods on test data表1 各方法在測(cè)試集上的性能
Nguyen提出的CNN模型是通過(guò)設(shè)置多個(gè)上下文詞窗口,利用卷積神經(jīng)網(wǎng)絡(luò)抓取待測(cè)詞周圍的上下文特征。但是這樣一方面無(wú)法利用遠(yuǎn)距離的上下文,另一方面上下文窗口增大后會(huì)引入大量噪音。本文提出的CSNN模型通過(guò)雙向LSTM能有效抓取遠(yuǎn)距離的上下文依賴信息,并且LSTM中的遺忘門(mén)能過(guò)濾掉很多噪音。CNN沒(méi)有利用句子的語(yǔ)義信息,因此從表1可以看出,CSNN在事件線索識(shí)別和分類上的性能(F1值)都比CNN要好很多。
DMCNN使用神經(jīng)網(wǎng)絡(luò)模型,能從文本中自動(dòng)抽取詞層面和句子層面的特征。從表1中可以看出,DMCNN比ME和CRF在事件線索詞識(shí)別和分類上的性能都有所提升。然后,DMCNN忽略了上下文的詞依賴,而這對(duì)線索詞識(shí)別是很有幫助的。本文提出的CSNN利用雙向LSTM抓取句子中上下文詞依賴信息,提升時(shí)間線索詞識(shí)別和分類的性能。從表1中可以看出,在事件線索詞識(shí)別和分類上,CSNN較DMCNN的F1值分別提高3.29%、1.05%。
5.5 CSNN學(xué)習(xí)語(yǔ)義表示的效果
本節(jié)將驗(yàn)證CSNN學(xué)習(xí)得到的語(yǔ)義表示是有效的。設(shè)計(jì)了兩個(gè)方法作為baseline系統(tǒng)與CSNN進(jìn)行對(duì)比:Bi-LSTM和Bi-LSTM+CNN。Bi-LSTM可以看作是CSNN去掉GRNN剩下的部分(CSNN-GRNN),不學(xué)習(xí)句子的語(yǔ)義表示,只考慮句子的上下文依賴;Bi-LSTM+CNN是將CSNN中的GRNN和pooling替換成CNN,通過(guò)CNN學(xué)習(xí)句子的表示。
表2展示了Bi-LSTM、Bi-LSTM+CNN和CSNN的結(jié)果。從表2中可以看出,Bi-LSTM(CSNN-GRNN)相對(duì)CSNN在事件線索詞識(shí)別和事件線索詞分類上的F1值分別下降了4.20%和1.74%。這說(shuō)明CSNN學(xué)習(xí)得到的語(yǔ)義表示是有效的,能提高事件線索詞的識(shí)別性能。Bi-LSTM+CNN在事件線索詞識(shí)別和事件線索詞分類上的F1值比要Bi-LSTM(CSNNGRNN)高,但比CSNN分別低3.51%和0.85%,證明了GRNN比CNN能更好地學(xué)習(xí)句子的語(yǔ)義表示。

Table 2 Performance of CSNN without semantic learning and replaced by CNN表2 CSNN去掉語(yǔ)義學(xué)習(xí)以及換成CNN后在測(cè)試集上的性能對(duì)比
5.6 CSNN過(guò)濾上下文噪音的效果
CSNN通過(guò)使用雙向LSTM,不僅可以抓取遠(yuǎn)距離的上下文依賴,還能通過(guò)LSTM的遺忘門(mén)過(guò)濾掉待測(cè)詞上下文中的噪音。為了便于比較,本文將CSNN中的雙向LSTM的遺忘門(mén)去掉,這樣就會(huì)一直記錄歷史信息,即上下文詞信息。這樣的模型命名為CSNN-f,與CSNN相比只是去掉了雙向LSTM中的遺忘門(mén),其他都一樣。
實(shí)驗(yàn)結(jié)果如表3所示。CSNN去掉遺忘門(mén)后,事件線索詞識(shí)別和分類的性能都有所下降,尤其是線索詞識(shí)別中F1值下降了2.23%。這是因?yàn)槿サ暨z忘門(mén)后,CSNN-f將會(huì)保存所有的歷史信息,而部分歷史信息包含噪音數(shù)據(jù),是有害的。CSNN可以通過(guò)遺忘門(mén)的開(kāi)關(guān)將這些噪音過(guò)濾掉。

Table 3 Performance of CSNN and CSNN without forgetgate表3 CSNN去掉遺忘門(mén)后性能對(duì)比
6 總結(jié)
本文提出了一種新的事件線索詞檢測(cè)方法,抓取上下文依賴并學(xué)習(xí)句子的語(yǔ)義表示。本文方法利用雙向LSTM模型獲取待測(cè)詞前后的上下文依賴信息,使用GRNN學(xué)習(xí)待測(cè)詞所在句子的語(yǔ)義表示。從實(shí)驗(yàn)結(jié)果可以看出,本文方法在事件線索詞識(shí)別和分類上的性能均比其他baseline方法高,證明了本文方法是有效的。較傳統(tǒng)方法,本文方法不使用任何自然語(yǔ)言處理工具,避免了錯(cuò)誤傳遞;與現(xiàn)有的神經(jīng)網(wǎng)絡(luò)方法相比,本文方法能有效利用上下文依賴和句子的語(yǔ)義信息,提高了事件線索檢測(cè)的性能。
[1]Li Qi,Ji Heng,Huang Liang.Joint event extraction via structured prediction with global features[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics,Sofia,Aug 4-9,2013.Stroudsburg:ACL,2013:73-82.
[2]Liao Shasha,Grishman R.Using document level cross-event inferent to improve event extraction[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics,Uppsala,Jul 11-16,2010.Stroudsburg:ACL,2010:789-797.
[3]Ji Heng,Grishman R.Refining event extraction through crossdocument inferent[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics,Columbus,Jun 15-20,2008.Stroudsburg:ACL,2008:254-262.
[4]Hong Yu,Zhang Jianfeng,Ma Bin,et al.Using cross-entity inference to improve event extraction[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies,Portland,Jun 19-24,2011.Stroudsburg:ACL,2011:1127-1136.
[5]Chen Yubo,Xu Liheng,Liu Kang,et al.Event extraction via dynamic multi-pooling convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing,Beijing,Jul 26-31,2015.Stroudsburg:ACL,2015:167-176.
[6]Nguyen T H,Grishman R.Event detection and domain adaptation with convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics,and the 7th International Joint Conference on Natural Language Processing,Beijing,Jul 27-29,2015.Stroudsburg:ACL,2015:365-371.
[7]Le Q,Mikolov T.Distributed representations of sentences and documents[C]//Proceedings of the 31st International Conference on Machine Learning,Beijing,Jun 21-26,2014:1188-1196.
[8]Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[9]Chen Xinchi,Qiu Xipenng,Zhu Chenxi,et al.Long shortterm memory neural networks for Chinese word segmentation[C]//Proceeding of the 2015 Conference on Empirical Methods in Natural Language Processing,Lisbon,Sep 17-21,2015.Stroudsburg:ACL,2015:1197-1206.
[10]Sutskever I,Vinyals O,Le Q.Sequence to sequence learning with neural networks[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems,Montreal,Dec 8-13,2014.Cambridge:MIT Press,2014:3104-3112.
[11]Liu Pengfei,Qiu Xipeng,Chen Xinchi,et al.Multi-timescale long short-term memory neural network for modelling sentences and documents[C]//Proceeding of the 2015 Conference on Empirical Methods on Natural Language Processing,Lisbon,Sep 17-21,2015.Stroudsburg:ACL,2015:2326-2335.
[12]Johnson R,Zhang Tong.Effective use of word order for text categorization with convolutional neural networks[C]//Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,Denver,May 31-Jun 5,2015.Stroudsburg:ACL,2015:103-112.
[13]Kim Y.Convolutional neural networks for sentence classification[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing,Doha,Oct 25-29,2014.Stroudsburg:ACL,2014:1746-1751.
[14]Hinton G E,Srivastava N,Krizhevsky A,et al.Improving neural networks by preventing co-adaptation of feature detectors[J].Computer Science,2012,3(4):212-223.
[15]Zhang Rui,Gong Weiguo,Grzeda V,et al.An adaptive learning rate method for improving adaptability of background models[J].IEEE Signal Processing Letters,2013,20(12):1266-1269.
猜你喜歡
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中外會(huì)展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
外語(yǔ)學(xué)刊(2011年1期)2011-01-22 03:38:33
