廣告話語中動態多模態隱喻的形式表征研究*
——聚焦模態調用特征及理據
2018-03-09 03:12:38王小平
外語學刊 2018年5期
關鍵詞:模態
王小平 王 軍
(蘇州大學,蘇州 215006)
提 要:本文在改進多模態隱喻標注方式的基礎上,以30則電視公益廣告為例,聚焦廣告話語中動態多模態隱喻的形式表征問題。研究發現,動態多模態隱喻形式表征在模態調用層面表現出一定的規律性:(1)多模態隱喻表征模態配置總體上呈現多元化態勢;(2)圖像、文字、聲音3類模態調用總量的分布較均衡;(3)不同概念域的模態調用特征呈現分化:源域模態復雜度高于目標域,且兩者顯現出不同的模態偏好。針對上述特征,本文深入分析其模態調用理據。
1 引言
表征是認知科學的核心概念,指可反復指代某一外部或想象事物的任何符號或符號集(李恒威等 2008:27)。它涉及兩個不同的階段:第一,作為賴以處理、存儲和表達信息的承載結構,是認知過程或狀態的產生基礎;第二,作為知識的表征,可理解為語義的認知加工和概念化過程。然而,當前語言學界有關隱喻表征的研究主要聚焦于第二個方面,基于具體語料探究道德、運動、情感等不同概念的認知表征,較少關注表征作為承載信息的形式化系統,其信息的組織形式。多模態隱喻植根于多模態語篇,其表征過程訴諸多樣化的模態調用及配置,與普通文字隱喻相比,涉及更為復雜的形式化系統及信息組織機理,因此,多模態隱喻的形式表征是一個值得深入探索的話題。
當前,“模態調用”(陳松菁 2016:70)是多模態隱喻形式表征研究關注的熱點問題,研究焦點主要關涉多模態隱喻表征過程中所調用的模態配置及其理據。但目前研究者主要圍繞漫畫(Erden 2009,俞燕明 2013)、海報(王天翼 甘霖 2015)、平面廣告(Forceville 1996)以及敘事繪本(趙秀鳳 2016)等靜態多模態語篇展開研究,并未將動態圖像、動態多模態隱喻納入考察范圍。此外,多模態隱喻的“模態調用”除隱喻總體的模態配置之外,源域和目標域各自的模態配置及“模態使用偏好”(Sobrino 2016:73)以及各模態的調用及分布也值得繼續關注。
電視廣告話語作為典型的動態多模態語篇研究重點關注廣告內部隱喻的動態建構、隱轉喻的互動、多模態互文等問題,對動態多模態隱喻的形式表征研究卻鮮有涉及。本文在修訂多模態隱喻標注及分類方法的基礎上,探索廣告話語中動態多模態隱喻表征的模態調用特征及理據。研究聚焦以下幾個方面:(1)廣告話語中多模態隱喻的模態配置類型有哪些,源域和目標域的模態配置有何異同;(2)各模態總體的調用情況如何?源域和目標域是否具有模態使用偏好;(3)動態多模態隱喻形式表征的模態調用理據是什么。
2 語料提取及相關處理
2.1 語料選取
本文以30則電視公益廣告為研究語料,它們都來源于全國優秀廣播電視公益廣告作品庫,該庫由中國中央電視臺(CCTV)官方網站承辦。截止本文成文時,已收錄電視公益廣告803部,且相關語料一直在不斷地更新擴充,語料兼具代表性與時效性,可體現當前國內電視廣告制作的較高水準。該作品庫以作品主題為標準將公益廣告分為6個類別:文明道德類、環境保護類、安全教育類、反腐倡廉類、法制宣傳類、節日紀念類,為體現本研究語料的代表性,我們從以上主題類別中分別隨機挑選5則公益廣告,共計30則,組成小型自建多模態語料庫。
2.2 多模態隱喻的識別
基于自建的多模態語料庫,本文采取定量為主,定性為輔的研究方法,對所選取語料中的多模態隱喻形式表征問題進行分析。其中,多模態隱喻的識別是后續研究的基礎,因此,對所選的每一則公益廣告都進行窮盡式的研究,在參考Bounegru和Forceville(2011:213)識別方式的基礎上,本文提出以下多模態隱喻的甄別方法:第一,多模態語篇中的兩個概念分屬兩個不同范疇,并存在相似性;第二,兩概念可分別被識解為概念隱喻的源域和目標域,且關系不可逆;第三,兩概念域由兩種及以上模態共同表達。我們依據以上3個步驟對語料中的多模態隱喻進行窮盡性的識別與統計。
2.3 多模態隱喻標注及分類方式
對語料中的多模態隱喻進行識別后,本文對獲取的多模態隱喻進行標注并分類。綜覽相關文獻發現,目前的研究主要基于表征隱喻所調用的模態配置對多模態隱喻進行標注并分類。俞燕明(2013)基于新聞漫畫這一語類,提出圖文隱喻(PVMs)、圖像—符號隱喻(PSMs)、圖像隱喻(PPMs)、源域圖像目標域隱含的隱喻(P?Ms)、目標域隱含的圖像隱喻(V?Ms)等6類表征方式,并在海報(楊友文 2015)、平面廣告(王揚 向恩白 2016)等其他語類中得到驗證,顯示出一定的闡釋力。然而,這一方法存在以下不足:第一,基于靜態多模態語篇提出,且標注公式中僅涉及文字、圖像兩種模態,而動態多模態隱喻表征所調用的模態,配置更為復雜,因此在動態多模態環境中,其適應性存疑;第二,多模態隱喻天然地涉及源域和目標域表征,且兩者在隱喻運作機制中的作用及特征并不相同,因此僅籠統地標注模態類型而忽略源域和目標域的分化,并不能全然體現表征的規律與特征。
針對以上問題,我們提出改進當前的多模態隱喻標注方式,在標注公式中凸顯源域和目標域,并分別標注兩域表征所調用的模態配置;以S和 T分別表示源域和目標域,以p表示圖像模態(pictorial mode),a表示聲音模態 (auditory mode),w表示文字模態 (written language)。假設某隱喻的源域調用圖像模態和聲音模態,可標注為S-ap;目標域若由文字模態和圖像模態表征,則可標注為T-pw,那么,該隱喻可被標注為S-apT-pw. 這一標注方式既可保留俞燕明(2013)標注方法的優點,可清晰突顯調用模態;又可清楚地突顯源域和目標域各自的模態配置及使用偏好,有利于更為系統性地探索多模態隱喻形式表征的規律。本研究擬使用這一方式對語料中的多模態隱喻進行標注,并根據其模態配置進行分類。
3 動態多模態隱喻的模態調用
3.1 模態配置
按照多模態隱喻的識別方法我們對選取語料進行窮盡式的研究,共識別出85條動態多模態隱喻,并依據本文改進的標注方式,將其分為9種不同模態表征類型(見表1)。
表1顯示, 電視廣告話語中多模態隱喻數量最多的3種模態配置類型為:S-apwT-apw(30例,35.29%)、S-apwT-pw(16例,18.82%)、S-apwT-aw(11例,12.94%),占所有模態配置類型的67.05%。以上3類配置都調用圖像、聲音和文字3種模態,源域和目標域的表征模態也較為復雜。除以上3類,S-apT-apw(9例,10.59%)和S-apwT-p(6例,7.06%)兩類也調用3種模態,共計72例,占所有類別的84.7%。這說明,電視廣告話語作為一種動態多模態話語,傾向于使用多種不同模態,調動多重感官參與認知。

表1 電視公益廣告中多模態隱喻模態配置類型①
與此形成鮮明對比的是,數量最少的3類即S-pT-aw(3例,3.53%)、S-pwT-w(2例,2.35%)和S-awT-aw(2例,2.35%)僅占8.23%。分析發現,這幾類模態配置文字模態的比例偏高,而圖像模態使用較少,這說明廣告話語中動態多模態隱喻并不傾向使用較為單一模態,而更傾向于文字與感官模態組合使用。
觀察表1可以發現,廣告話語中多模態隱喻的源域和目標域由兩種及以上不同模態進行表征的比例很高,這從另一個層面證明動態多模態隱喻模態配置的復雜性。然而,我們也發現兩者的模態配置表現出不同特征。
3.11 源域的模態配置
根據模態配置,可以將表1中多模態隱喻的源域分為5種類型(見表2)。從數據分布上看,源域的模態類型分布較為集中,最為突出的源域模態配置為S-apw(63例,74.12%),占比接近總數的3/4。這一類型調用3類模態,且3者比例均衡,說明在動態多模態環境中,多模態隱喻的源域表征更加注重調動多重感官系統。
分析源域的模態分布后發現,圖像模態在源域模態中的地位幾乎無可替代。如表2所示,除S-aw外,其余4類調用圖像模態占總數的97.65%,表明在動態多模態語篇中圖像模態的特殊地位。

表2 多模態隱喻源域和目標域的模態表征類型
3.12 目標域的模態配置
與源域相比,目標域模態表征類型的數據分布相對分散,最主要的模態配置為T-apw(39例,45.88%),而T-pw和T-aw各16例,分別占18.82%,3類共占目標域模態表征類型的83.52%。從中可以看出,雖然目標域表征同時調用圖像、文字及聲音3類模態的比例也較高(45.88%),但卻遠低于源域(74.12%)。在目標域表征過程中,文字模態一般搭配圖像或聲音模態一同使用,搭配使用的表征類型(71例)占比所有涉及文字模態表征類型(79例)的89.87%。這說明,動態多模態隱喻的目標域訴諸多種感官模態的普遍性。
3.2 模態分布特征
基于表1和表2,我們對電視公益廣告中的3種主要模態即圖像、文字和聲音進行統計,如表3所示:3類模態的使用率都很高,且總體分布較為均衡,文字模態的使用次數最多,共計146次,占比34.84%。圖像模態和聲音模態則分別使用144次和129次,分別占34.37%和30.79%。然而,對比源域和目標域的模態分布情況發現,兩者存在不同的模態偏好。
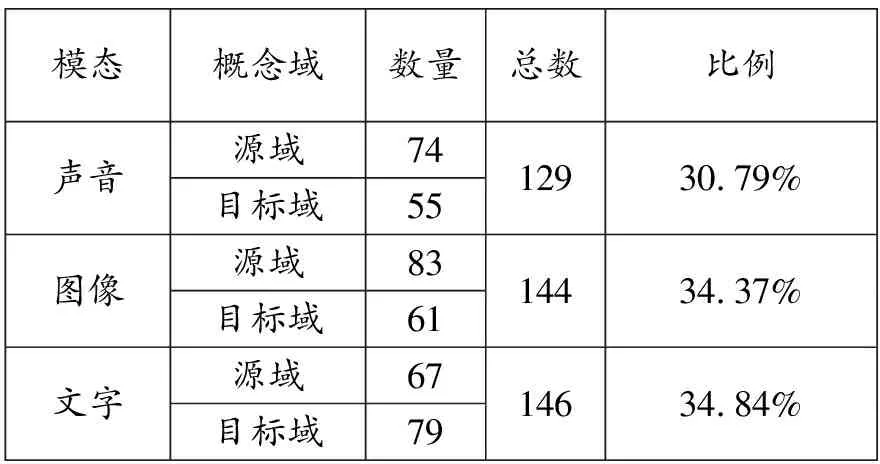
表3 多模態隱喻的模態使用情況
3.21 源域模態使用偏好
在源域表征所涉及的3類模態中,圖像和聲音等具象模態的使用率高于文字模態,其中圖像模態使用次數最多,共計83次(見表3),占所有源域表征類型的97.65%,聲音模態次之(74次),文字模態使用次數最少(67次),這顯示圖像模態在電視廣告這一動態多模態語篇的多模態隱喻表征過程中承載比其他兩者更多的信息內容。但圖像模態通常與其他模態共同參與表征。廣告話語之所以更加依賴圖像、聲音等具象模態,可能與此類模態更具感官吸引力有關。研究表明,“圖像模態在大腦中留下的印象更為深刻”(Siborino 2016:79),且多模態隱喻的運作機制依然是通過源域來理解目標域,即源域的表征更為形象具體,因而可能須要訴諸更多的感官模態。
3.22 目標域模態使用偏好
與源域不同,目標域表征調用最多的模態為文字模態(79次),而后是圖像模態(61次),最少的是聲音模態(55次)。此外,綜合對比目標域的5類模態配置方式發現,其中4類表征類型都用到文字模態,占所有類型的92.94%,這說明文字模態在目標域模態配置中的普遍性。文字模態除參與隱喻表征外,更可發揮對圖像、聲音等模態的錨定作用,降低產生歧義的可能性。
跨域比較發現,源域中圖像、聲音模態的分布高于目標域,文字模態的分布則低于目標域(見表3),這體現出源域和目標域的表征特點。從模態使用偏好可以看出,源域的刻畫總體上比目標域更加形象具體。須要注意的是,我們不能忽視比例偏低模態在其所在概念域中的重要作用,雖然比例偏低,但絕對數量并不少。例如,源域中分布最少的文字模態使用次數仍達67例,占所有源域類型的78.82%,而目標域中分布最少的聲音模態有55例,占64.71%。雖然各種模態比例存在一定差別,但圖像、聲音及文字3種模態的總體調用較為均衡,在一定程度上順應人在認知外部世界過程中依賴多重感官的認知習慣。
4 動態多模態隱喻模態調用的理據
數據顯示,多模態隱喻的模態調用表現出一定的規律性:第一,電視廣告話語作為動態多模態語篇傾向訴諸較為復雜的模態配置,同時調用圖像、聲音及文字3類模態的頻率較高;第二,3類模態分布存在一些差異,但在總量上基本均衡;第三,兩概念域的模態調用特征出現分化,源域的模態配置較目標域更為復雜,且圖像、聲音兩類模態的分布高于目標域,而文字模態的調用則少于目標域。下面,我們分別從3個方面對以上特征的理據性進行解釋。
4.1 模態調用的復雜化
在廣告話語中,多模態隱喻的模態調用呈現復雜化,同時使用圖像、文字和聲音3類模態比例很高,達84.71%。研究發現,這一特征與模態表征及認知過程的具身性相關。
在多模態隱喻表征過程中,人類的多重知覺發揮重要作用。知覺符號論認為,認知植根于認知主體與世界互動所獲得的感覺中(李恒 張積家 2017)。在這一過程中,人并非基于單一渠道,而是訴諸多重感官體驗,而隱喻的多模態化表征正順應這一認知機制。多模態隱喻表征所訴諸的不同模態分別對應人類不同的知覺符號,而知覺符號則對應于認知通道所接受的感官刺激。圖像模態對應于視覺符號,所接收信息是對認知對象視覺特征的歸納與突顯;聲音模態則對應于聽覺符號,接收的信息關涉認知對象聽覺特征。多元化的感官知覺經過提取、加工、抽象、存儲等認知加工過程而形成體驗性符號存儲于人類的認知系統,成為表征事物的知覺符號。在多模態隱喻表征過程中,對應不同知覺的多元化模態通過組合和拼接融入隱喻及整合機制,使調動不同感官協同創生意義成為可能。
認知是知覺和動作的融合與交織,概念由一系列對真實世界、身體狀態、行為內部表征的模擬組成(牛保義 2016:2),因此多模態隱喻在以知覺仿真方式對概念進行仿擬與再現的過程中,必須全方位的考慮認知對象涉及不同感官渠道的知覺特征。以“玫瑰花”為例,若要對其進行全面的仿擬與再現,至少需要考慮3種知覺特征,視覺(花型)、嗅覺(花香)以及觸覺(刺)。在調用相關模態塑造對應的知覺特征基礎上,更要使其與相關事物產生相似性排列,以誘發認知主體對模態表征內容類似的具身體驗。再例如,在某則宣傳食品安全的公益廣告中,食用油被塑造為“武林高手”的隱喻形象,其中視覺通道上,以健壯的男子樣態,紅色拳擊手套以及流暢的武術動作仿擬“武林高手”的視覺特征,配合各種武打音效對相關圖式聽覺特征的仿擬,可全方位地再現武林高手的視聽覺感知特征,成功激活關于武林高手的具身認知,進而成為優質食用油概念化進程的認知參照,以“武林高手”的健壯與高水平映射“食品安全”的可靠性。在上例中,隱喻性概念的表征對應不同感官的多元知覺符號,以調動人大腦中存儲的事物的多模態信息。此外,知覺表征的本質在于認知模仿,其核心在于激活認知主體的感知覺通道及其神經關聯,并對多元感官信息進行整合與表征。
4.2 各模態的分布
圖像、文字及聲音3類模態在多模態隱喻形式表征中所占比重雖存在差別,但總體相對均衡(見表3),這可能與模態表征功能上的互補性相關。作為典型的動態多模態語篇,電視公益廣告在建構過程中需要多元媒介符號的協同作用。在3類模態所構成的“多模態集合”(multimodal ensemble)中,每一類模態基于自身特有的“符號邏輯”(semiotic logic),具有不同的供應特征。圖像模態在廣告話語中以動態圖像的形式出現,其符號邏輯兼具時間性與空間性(Serafini 2010:87)。時間性指其實現過程通過鏡頭或圖像的連續性切換;空間性則指每一個鏡頭或者圖像都是由限定于某空間框架(spatial frame)內的成分共時呈現。在多模態隱喻表征過程中,圖像模態可訴諸連續性畫面再現或仿擬某事的發展過程,進而突顯其動態性特征;而單一鏡頭或畫面則可利用圖像敘事的共現性,提供相對完整的信息內容,推進敘事的進程。
聲音模態作為動態多模態話語中的重要媒介符號,可以突顯多模態隱喻的動態性與敘事性。聲音模態的符號邏輯體現在其物質性(materiality),即都以聲音為載體,這意味著聲音的延續性、音高、音量等不同維度成為其意義潛勢。其中,聲音模態的延續是多模態隱喻在時間維度上具有動態性的重要動因(Forceville 2008:468),而敘事性則可利用聲音模態的兩個不同要素實現:(1)訴諸有聲話語直接引導故事走向與發展;(2)利用音量及音高等變量強調相關信息,表達態度及情感,增強多模態隱喻的敘事性。此外,聲音模態還能打破圖像模態單一畫面的單調,擴大觀眾想象空間,補充相關重要信息,錨定圖像內容。
動態模態的廣泛調用可以加強動態性與敘事性,也會使語篇有相對開放的解讀方式。動態模態在信息呈現及表達過程中雖然較為生動形象,但因其解讀方式主要根據觀者的興趣而并不具有特定的方向性(directionality),會產生歧義或意義模糊(Kress 2009:56)。對此,文字模態可起到補充作用。文字模態的符號邏輯主要體現在文字、短語、句子根據語法及句法乃至社會文化等規則對語言的規定與限制,這一限制直接催生文字模態的“線性”以及“方向性”規則(同上),可在一定程度上錨定圖像解讀方向,減少動態模態引起的歧義性和模糊性,因此文字模態在動態廣告話語中得到廣泛使用。不難發現,圖像、聲音及文字3類模態在電視廣告話語中優勢互補,相得益彰,共同構成這一語類中的模態集合,多模態隱喻可利用模態的協同作用與互補強化其意義表達。
4.3 源域和目標域的模態偏好
動態多模態隱喻源域和目標域在表征過程中對不同模態存有偏好,如表2和表3所示,源域比目標域模態復雜度更高,且前者圖像、聲音模態的分布比文字模態更為廣泛。我們認為,這可能與兩者在隱喻基本運作機制中角色的不同有關。
一般人們認為,隱喻的基本運作機制是通過較為具體的源域來理解或體驗相對抽象的目標域(Schilperoord, Maes 2009:214),即源域為目標域的概念化過程提供較為形象具體的概念參照,這在一定程度上決定源域概念要比目標域的概念結構更為清晰。這一特征在多模態語境中也基本得到延續,雖然多模態隱喻的源域和目標域同時基于具體事物的可能性很高,但是“具體”與“抽象”在這里是一個相對的概念,通常來講,多模態隱喻的源域要比目標域更加形象具體(王揚 向恩白 2016:92),即需要多元模態對其進行刻畫與表征。相關研究證明,模態復雜度與相關概念或活動的復雜程度存在一定的關聯(Norris 2011:82-83),復雜的概念或活動因為涉及更為多元的內容或結構須要調用多元媒介,所以模態配置的復雜度較高。與目標域相比,源域作為認知參照在表征過程中須要呈現更多的細節,結構明顯更為復雜,這可能是源域模態復雜度偏高的原因。
此外,圖像、聲音模態在源域中的分布之所以比在目標域中更為集中,也與兩者在表征中不同的角色相關。源域作為概念參照所需具體化的表征要求在多模態語篇中體現為圖像、聲音模態的集中調用。由于概念域本質上是一種概念空間,而“概念空間由不同的維度構成,例如顏色、音高、溫度、重量以及其他維度,這些維度都基于我們的感官知覺”(Zenker, G?rdenfors 2015:4),這些固然可以通過文字模態進行描寫,但卻無法完全表現非語言模態的鮮明特色,比如圖像模態在電視廣告中的物質性特征除“顏色”“形狀”“線條”等因素外,還獨具動態性,這賦予它特殊的意義潛勢。目標域在多模態語篇中的表征形式雖然與傳統文本語篇相比也較為復雜,然而作為隱喻的認知對象,其表征義及可識別性不容有過多的模糊空間,因此文字模態作為意義錨定的主要工具,在目標域的分布比源域更為集中。由此可見,源域和目標域自身認知角色的不同是影響概念域模態使用偏好的重要因素。
5 結束語
本文以模態調用特征及其理據性作為切入點,闡釋動態多模態隱喻在電視廣告話語中的形式表征。研究提出在多模態隱喻表達式中分別標注源域和目標域及其各自的模態配置,以改進多模態隱喻的標注方式。對廣告話語的應用分析驗證這一方式對于揭示并細化動態多模態隱喻模態的調用規律的可行性及有效性,此外,通過對多模態隱喻模態配置及其分布理據性的探究,進一步揭示不同模態參與多模態隱喻表征的組合方式及其內在機理。研究結果顯示,動態多模態隱喻的模態組合類型呈現出多元化態勢,這表現在電視廣告中多模態隱喻的表征傾向于同時使用圖像、聲音、文字3類模態;此外,源域和目標域具有不同模態配置類型,并表現出相差迥異的模態使用偏好。前者不僅模態配置類型更為復雜,而且圖像及聲音等模態的調用也遠超后者,顯示出在電視廣告中多模態隱喻形式表征的顯著特征。多模態隱喻的核心要義在于認知模仿,而認知模仿的核心在于激活認知主體不同方面的感知覺通道及其神經關聯,并對多元感官信息進行整合與表征,這可能是不同模態得到廣泛調用的原因。每一類模態基于自身的“符號邏輯”,具有不同的意義潛勢,因此它們總體的分布較為均衡。然而由于源域和目標域認知功能的差異,兩概念域對不同模態表現出不同的使用偏好。在電視廣告這一語類中,不僅要平衡不同模態的調用,更要結合廣告宣達目的、概念域特征及符號邏輯對其進行有側重的運用,以使多模態隱喻的形式表征發揮最大效用。
注釋
①表1和表2中的數據均以四舍五入方式精確至小數點后兩位,所以存在一定的誤差。
猜你喜歡
成都信息工程大學學報(2022年4期)2022-11-18 07:31:14
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:12
工程與建設(2019年1期)2019-09-03 01:12:12
廣州大學學報(自然科學版)(2016年2期)2017-01-15 13:43:00
廣西科技大學學報(2016年1期)2016-06-22 13:10:37
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
振動工程學報(2014年4期)2014-03-01 01:15:31
電影新作(2014年1期)2014-02-27 09:07:36
