基于詞向量與可比語料庫的雙語詞典提取研究
2018-03-06 11:11:31柳路芳周凌寒
計算機工程與科學 2018年2期
柳路芳,李 波,陳 鵬,周凌寒,王 兵
(1.華中師范大學計算機學院,湖北 武漢 430079;2.北京吉威時代軟件股份有限公司,北京100043)
1 引言
隨著世界經濟一體化的持續推進,不同國家和地區的人們交流日趨頻繁,跨語言交流中的語言不通問題亟待解決,而傳統的語言學習、翻譯方式越來越不能適應當今快節奏的生活。在這樣的背景下,利用計算機技術來進行跨語言自然語言的自動處理研究變得愈發重要和有價值。在跨語言自然語言處理應用中,雙語詞典是一項基本資源,具有極其重要的作用。傳統的人工方法或基于平行語料庫構建雙語詞典的方法開銷較大,且構建的雙語詞典在時效性和完整性方面不甚理想。近年來,使用計算機技術自動提取雙語詞典得到了許多研究人員的關注[1]。
一般而言,雙語詞典提取方法按照所使用的語料庫類型進行劃分,可以分為以下兩類:
第一類為基于平行語料庫的方法。該方法將平行語料庫作為語料資源,利用平行語料庫中的文檔對齊信息來進行雙語詞典提取[2],平行語料庫有高質量的互譯信息,故在構建雙語詞典的過程中具有較好的提取效果。但平行語料庫存在構建困難的不足,目前平行語料庫僅存在于少數語種和領域中,嚴重影響了該方法的推廣使用[3]。
第二類為基于可比語料庫的方法。可比語料庫中含有大量交叉卻又非嚴格互譯的信息,這些互譯詞語基本出現在語義相近但語言不同的上下文環境中,這也是該抽取方法的基礎[4,5]。可比語料庫易于獲取,覆蓋范圍廣泛,相較于基于平行語料庫的方法,在互聯網技術不斷發展的今天,具有更大的發展空間。
現階段,基于可比語料庫的雙語詞典抽取相關研究還不夠成熟,抽取算法的性能還不能滿足實際應用的需求,且大部分研究都集中在特定領域的相關專業術語的抽取。因此,近來有許多學者對其進行優化改進,尤其是最近神經網絡算法被應用在機器學習等相關領域并取得了非常好的效果,其在自然語言處理領域應用的代表性成果之一——詞向量[6],逐步被廣泛應用在語義擴展和情感分析等領域中,在單語種環境中可以對兩個詞語的詞向量直接計算相似度且兼顧平滑功能。鑒于此,本文提出了一種基于詞向量與可比語料庫的雙語詞典抽取方法,在一定程度上提升了雙語詞典的提取準確率。
2 基本假設與相關研究
2.1 基本假設
Rapp等人[7]研究表明,在單語種文本中一個單詞盡管會出現在不同的文本中,但是與之共同出現的單詞集合是大體相同的,也就是說詞語之間的相關關系具有穩定性,后來,有其他研究者將這種相關性擴展到了多種語言中。因此,對于可比語料庫中單詞之間的相關性,本文做出以下假設:
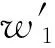
(2)單詞之間的相關性具有對稱性。即單詞w1和單詞w2的相關度與單詞w2和單詞w1的相關度相同。
2.2 相關研究
目前,基于可比語料庫的雙語詞典抽取算法主要有以下幾種:
(1)Tanaka等人[8]提出的基于中間語言的算法。Tanaka等人提出了一種利用中間語言從可比語料庫中進行雙語詞典提取的方法,其主要思想是通過一種相對通用的語言如英語等作為中間語言,然后利用這種中間語言的詞表將源語言的單詞轉換為中間語言,再將轉換后的單詞轉換到目標語言,最終完成雙語詞典的提取。然而,這種方法是基于單個單詞的,其抽取效果受中間語言的詞表的影響較大,在實際應用中,單個的單詞常常不能表達一個比較完整的含義,而是需要與其他單詞結合起來才能表達一個完整的含義,不同的單詞組合則表達不同的含義。因此,這種基于單詞表的抽取算法的抽取效果不甚理想。
(2)Rapp等人[9]提出的基于詞語關系矩陣的算法。基于2.1節的假設,在單語環境中,單詞與單詞之間存在一定的相關性,因此可以通過先確定源語言語料中的單詞與種子詞典中源語言單詞之間的相關性以及目標語言語料庫中的單詞與種子詞典中目標語言單詞之間的相關性來間接確定源語言與目標語言之間的相關性。基于此,Rapp等人提出了基于詞語關系矩陣的方法從可比語料庫中提取雙語詞典,其基本思想是通過構建源語言和目標語言的單詞共現矩陣,然后通過計算矩陣的相似度來得出源語言和目標語言的相似度。
(3)Fung等人[10]提出的基于上下文空間模型的算法。Fung等人在上述Rapp等人的思想的基礎上通過向量空間模型完成了雙語詞典抽取工作。其基本思想是首先為兩種語言語料庫中的所有單詞構建上下文向量,向量中包含了與該詞共同出現的單詞信息并且這里的上下文窗口大小不是固定的,它根據單詞出現的次數的不同而變化;然后根據一些已知的互譯詞對完成源語言向量到目標語言向量的映射;接著在目標語言向量空間中將轉換后的向量與目標語言中所有單詞的向量計算相似度并排序;最終根據排序結果獲取候選翻譯,從而獲得雙語詞典。由于向量空間模型的原理較為簡單,因此許多研究者利用已知的多語種互譯詞對以及高可比性的語料等外部資源對該模型進行了一系列的優化和改進,并將其應用于各種特定的自然語言處理任務中。
(4)Mikolov等人[11]提出的基于詞向量的算法。Mikolov等人于2013年提出了一種將單詞進行向量化表示的方式,具體做法是利用神經網絡語言模型以及Google海量的語料庫將單詞訓練成為一個低維的實數向量。同時,他利用這種方式將兩種語言的語料庫中的單詞分別表示成詞向量,從而構成了源語言和目標語言向量空間,并證明了兩個向量空間之間存在線性關系。基于此,通過訓練一個線性轉換矩陣實現了從源語言向量空間到目標語言向量空間的轉換,最后計算詞向量之間的相似度通過相似度排名來完成雙語詞典的提取工作。實驗表明,與其他抽取算法相比,其抽取準確率有了較大幅度的提升。
3 基于詞間關系的雙語詞典抽取
根據2.1節所描述的基本假設,我們將單詞之間的相關性作為區分單詞的重要特征,提出了一種基于詞向量利用詞語間關系進行可比語料庫中雙語詞典抽取的方法。其基本思路是:
(1)將源語言和目標語言語料庫中的詞語訓練成詞向量;
(2)將(1)中轉換后得到的詞向量結合已知的種子詞典構建詞間關系矩陣,從而使源語言與目標語言關聯起來;
(3)計算(2)中源語言單詞與目標語言單詞之間的詞間關系向量的相似度,獲得兩種語言中兩個單詞之間互譯程度的量化結果;
(4)對相似度進行排序,選取相似度最大的前N個單詞作為源語言中該單詞的翻譯候選集合。
算法具體流程如圖1所示。
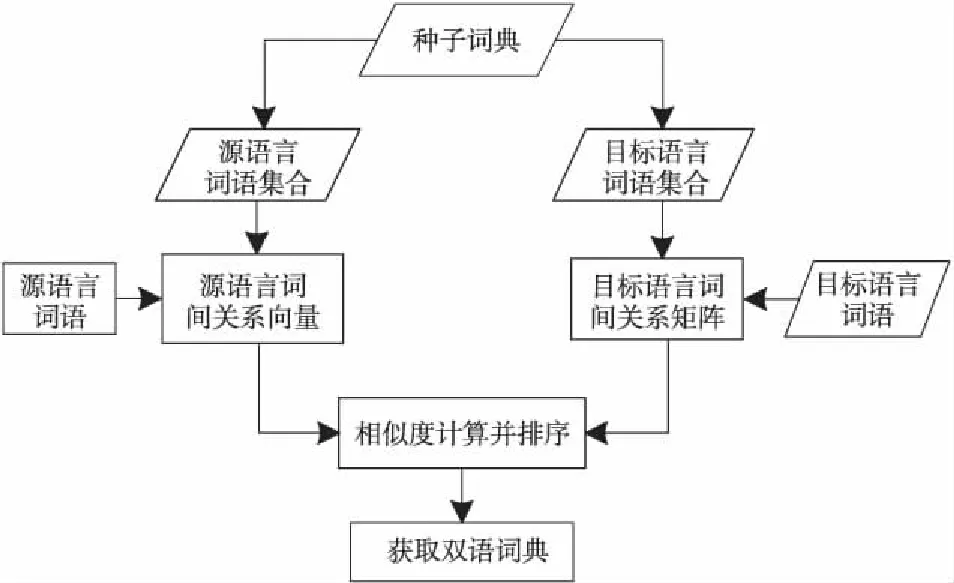
Figure 1 Bilingual lexicon extraction based on words’ correlation 圖1 基于詞間關系的雙語詞典抽取
如圖1所示,該抽取算法的具體步驟如下:
(1)從通用雙語詞典中抽取種子詞。設種子詞對的數量為n,則形成的種子集合表示為{wsi,wti},i∈{1,2,…,n},ws為源語言單詞,wt為ws在目標語言中對應的翻譯,i為單詞ws在種子詞典中的索引。
(2)通過已構建的源語言詞向量構建源語言語料中每個單詞與種子詞典中源語言單詞的相關度。設種子詞典中的單詞對數目為k,源語言語料庫中單詞的詞向量為n維,則種子詞典中源語言單詞集合可表示為{ws1,ws2,…,wsk},其對應的詞向量表示為{vs1,vs2,…,vsk},vsi∈Rm,i∈{1,2,…,k}。對于源語言語料庫中的某一個測試單詞wsx及其對應的詞向量表示vsx(vsx∈Rm),其與種子詞語集合中的每個詞語相關度量化表示如下:
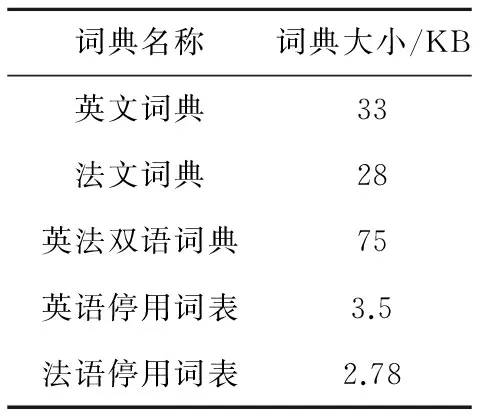
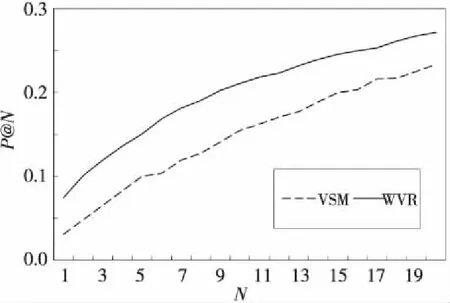
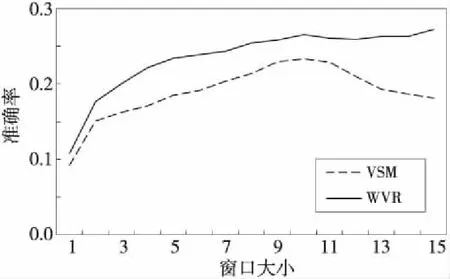
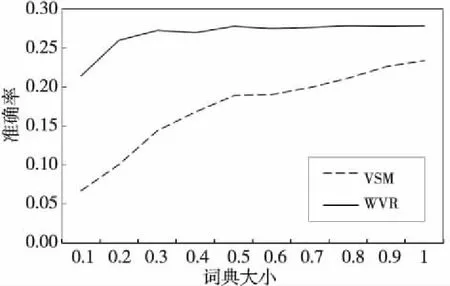
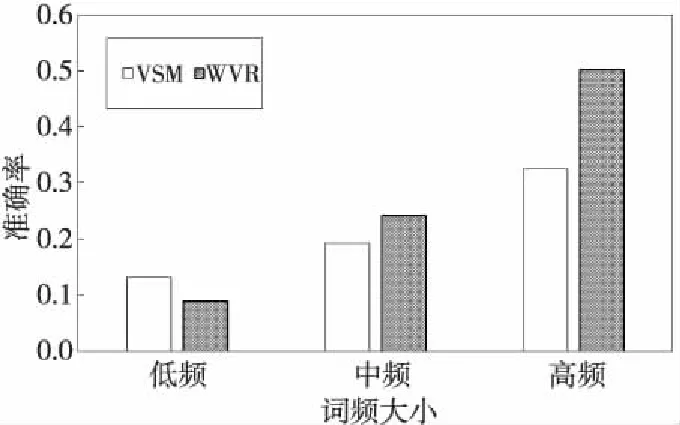
M(vsx,vsi)=∑1 j∈{1,2,…,k} (1) 其中,vsi∈{vs1,vs2,…,vsk},vsxj和vsij分別表示詞向量vsx和vsi的第j維分量。 假設上述計算完成后得到的未知單詞wsx與種子詞語集合的相關度向量用vms表示,其中vms第j維分量的值即表示其與源語言種子詞語集合中下標索引值為j的源語言詞語的相關度值,且vms∈Rk。 (3)通過已構建的目標語言詞向量構建目標語言語料中每個單詞與種子詞典中目標語單詞的相關度。設與源語言使用相同的種子詞典,且目標語言語料庫中單詞的詞向量為m維,則種子詞典中源語言單詞集合可表示為{wt1,wt2,…,wtk},其對應的詞向量表示為{vt1,vt2,…,vtk},vti∈Rn,i∈{1,2,…,k}。對于目標語言語料庫中的某一個未知單詞wtx及其對應的詞向量vtx(vtx∈Rn),其與種子詞語集合中的每個詞語相關度量化表示與源語言相同。 同樣假設計算后得到的未知詞語wtx與種子詞語集合的相關度向量用vmt表示,其中第j維分量的值即表示其與目標語言種子詞語集合中下標索引值為j的目標語言詞語的相關度值,且vmt∈Rk。最終將目標語言語料庫中的每個單詞都計算過后即可形成目標語言詞間關系矩陣。 (4)根據(3)中得到的目標語言詞間關系矩陣,計算源語言詞間關系向量vms與目標語言詞間關系向量vmt的相似度。根據其相似度的大小來判斷二者之間是否為互譯關系,相似度越大,其被視為互為翻譯的可能性越大。本文采用了夾角余弦公式計算兩個向量之間的相似度,其計算公式如下: (2) 其中,vmsi是指源語言單詞在第i維上的分量,vmti是指目標語言單詞在第i維上的分量,m是指該源語言單詞與目標語言單詞都有分量的維數,n指源語言單詞有分量的維數。 《資治通鑒》選取史料固然嚴謹,但也存在瑕疵。如何決定材料與記錄的真實可靠,往往不可依據權威,而要看材料是否原始。如果有幾種相關紀錄,可以通過對照比勘看出問題。對于非正史材料,應該謹慎地考察,沒有實據,不如用既有材料。唐史史料基本可以追索淵源,不必臆斷。在有確實可依的史料時,我們依據最初記錄,這是比較可靠的。 (5)對上述得到的相似度進行排序,選取前N個詞語作為源語言單詞wsx的候選翻譯集合,最終完成雙語詞典的提取。 我們的實驗選擇英文和法文兩個語種,并將英文作為源語言,法文作為目標語言。考慮到語料收集的難度,我們使用跨語言信息檢索論壇(http://www.clef-campaign.org)上的相關信息作為實驗語料,語料庫的具體規模如表1所示。 此外,訓練詞典也是本文實驗中的一項重要資源,本文實驗中使用的詞典來源于Google翻譯[12],具體介紹如表2所示。 Table 1 Experimental corpus Table 2 Training dictionary size 本文實驗首先需要對語料庫進行預處理。其中主要的預處理工作包括: (1)去除文本中無用的特殊符號; (2)根據指定停用詞詞表去除文本中停用詞; (3)因為本實驗只采用語料庫中特定詞性的單詞,因此需要對源語言和目標語言語料庫中的所有詞語做詞根還原以及詞性標注工作; 然后,需要對語料庫中的詞語構建詞向量。本文首先將語料庫以句子為單位進行切分整合,然后利用Mikolov等人[13]提出的Word2vec工具分別對兩種語言的詞語構建詞向量。此外,為了得到更佳的詞向量訓練效果,在構建詞向量時,我們將源語言的詞向量空間和目標語言詞向量空間設定不同的維度值,最終訓練完成后得到兩種語言中詞語的詞向量。 最后,通過計算兩個向量之間的相似度,來得到對應的兩個單詞之間的相關性程度。計算兩個K維向量空間中的詞向量vs和vt的相似度,在許多實際應用中常常采用余弦夾角公式,假設使用vsi和vti表示詞向量vs和vt在第i維的分量,則其計算公式可以表示為: (3) 同時,本文將傳統的向量空間模型VSM(Vector Space Model)與基于詞向量的詞間關系模型WVR(Word Vector Relation)進行對比實驗。首先將兩種模型的整體抽取效果進行了對比,然后分析了上下文窗口大小、詞典大小、詞頻等因素對兩種模型最終抽取準確率的影響。 我們用P@N(前N個候選翻譯的準確率)作為評價指標,其計算公式如下: (4) 其中,RT為抽取結果中源語言單詞的數目,即在實驗中表示的是測試詞典的大小;T(wi)是指抽取算法在單詞wi上的抽取結果;d(wi)表示單詞wi在詞典中的翻譯集合。‖S‖是指集合S是否為空,為空則其值為0,否則其值為1。 首先,本文實驗對比了VSM和WVR兩種模型的整體抽取效果,實驗過程中我們使用默認參數(即上下文窗口取10,詞頻為全部詞語),其實驗結果如圖2所示。 Figure 2 Extract results of VSM model and WVR model圖2 VSM模型和WVR模型的抽取結果 如圖2所示,當使用默認參數時,在不同N值下,WVR模型的準確率相較于VSM模型均有一定的提升,如WVR的P@1約為7.5%,較VSM(3.1%)有著極大的優勢。在實際應用中,P@1的性能越好越有利于后續任務的推進,也就具有更高的實際應用意義。 除了整體準確率的比較,我們通過對以往相關文獻的梳理和總結,發現上下文窗口大小、種子詞典、詞頻等因素都會對抽取結果產生一定的影響。因此,下面將對這幾個因素逐一進行分析。 首先,對于上下文窗口而言,其主要影響的是單詞的表達形式及其有效性。比如在VSM模型中,窗口選擇太小會影響單詞的上下文環境,其上下文向量不能完整表達該單詞的語義特征;窗口選擇太大又會出現語義冗余,引入太多噪音產生了語義干擾;而對于WVR模型,窗口的大小不同會影響詞向量的表達形式,進而影響詞語之間的相關性的量化。因此,將上下文窗口的大小作為變量,其他參數設為默認參數(即N取20,詞頻為全部詞頻),則上下文窗口對VSM和WVR兩種模型最終抽取準確率的影響如圖3所示。 Figure 3 Effect of window size on the result of the extraction圖3 窗口大小對抽取結果的影響 如圖3所示,上下文窗口對詞典抽取的準確率具有較大的影響。在初始階段,VSM和WVR模型的準確率均隨著窗口的增大呈現增大的趨勢;當窗口大小達到10之后,WVR的準確率在最優值附近波動,趨于穩定狀態;而VSM的準確率反而有所下降。造成這種情況的原因可能是VSM的窗口過大引入了過多無用信息,從而影響抽取的準確率,而WVR中窗口大到一定程度后對其詞向量的表達影響變小。 其次,種子詞典是從源語言到目標語言轉換的中間橋梁,其大小對抽取的準確率也有著不容忽視的影響。實驗中將種子詞典按比例進行劃分,其中0.1代表種子詞典的1/10,1.0則代表整個種子詞典。實驗結果如圖4所示。從圖4中可以看出,隨著詞典的增大,兩種模型的準確率有著不同程度的提升,在種子詞典達到原始種子詞典的30%(大約3 000)時,WVR的抽取效果達到最優值并趨于穩定狀態,并且其最優值明顯高于VSM的。由此可見,相較于VSM模型,WVR的抽取效果受種子詞典的影響更小,并且用一個較小的種子詞典便可完成跨語言空間的轉換,從而取得較好的抽取效果。 Figure 4 Effects of seed dictionary size圖4 種子詞典大小對抽取結果的影響 最后,為了評估詞頻對抽取效果的影響,本文將測試單詞按照詞頻大小分為高頻詞、中頻詞和低頻詞三個詞段。假設wTF表示詞頻,則具體劃分標準為: 如圖5所示,在低頻詞段VSM的抽取效果略好于WVR,但隨著詞頻的增大,WVR的抽取效果明顯比VSM更好,尤其在高頻詞段,WVR的抽取效果有顯著的提升,同時也表明WVR方法更適合運用于高頻詞的雙語詞典的抽取。 Figure 5 Effects of word frequency圖5 詞頻對抽取結果的影響 本文提出了一種基于可比語料庫與詞向量的雙語詞典抽取方法,該方法首先利用Word2vec工具從可比語料庫中構建詞向量,然后以種子詞典為中間橋梁,構建詞間關系矩陣,從而評估不同語種之間單詞的相關性,最終獲取雙語詞典。同時,本文將傳統的向量空間模型作為參考,進行對比實驗,實驗表明,相較于基本模型,該算法的整體抽取效果在一定范圍內有著較為顯著的提升。同時,還通過實驗分析了上下文窗口大小、種子詞典大小和詞頻對抽取效果的影響,我們發現,上下文窗口大小在一定程度上對兩種模型都有較大的影響,當窗口達到一定值時,詞間關系模型的準確率達到一個最優值并趨于穩定狀態;對于較高詞頻的單詞,詞間關系模型的抽取準確率明顯高于基本模型;而種子詞典對兩種模型的影響也是不同的,當詞典較小時,詞間關系模型就可以完成跨語言空間的轉換,從而獲取雙語詞典,其抽取效果明顯好于基本模型。雖然本文提出的模型在準確率上有顯著的提升,但實驗過程中也發現了一些不足之處,如語料庫中無用信息過多等。因此,下一步研究方向將集中在如何獲取具有高可比度的語料庫上,以進一步提高雙語詞典的抽取效果。 [1] Miangah T M.Automatic term extraction for cross-language information retrieval using a bilingual parallel corpus[C]∥Proc of the 6th International Conference on Informatics and Systems Special Track on Natural Language Processing,2008:81-84. [2] Veskis K. Generation of bilingual lexicons from a parallel corpus[J].Eesti Rakenduslingvistika Uhingu Aastaraamat,2007(3):355-372. [3] Sun Le. Automatic extraction of bilingual term lexicon from parallel corpora[J].Journal of Chinese Information Processing,2000,14(6):33-39.(in Chinese) [4] Tamura A, Watanabe T,Sumita E.Bilingual lexicon extraction from comparable corpora using label propagation[C]∥Proc of Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,2012:24-36. [5] Fung P, Mckeown K.Finding terminology translations from non-parallel corpora[C]∥Proc of Annual Workshop on Very Large Corpora,1997:192-202. [6] Turian J, Ratinov L,Bengio Y.Word representations:A simple and general method for semi-supervised learning[C]∥Proc of the 48th Annual Meeting of the Association for Computational Linguistics,2010:384-394. [7] Rapp R. Identifying word translations in non-parallel texts[C]∥Proc of the 33rd Annual Meeting on Association for Computational Linguistics,1995:320-322. [8] Tanaka K,Umemura K.Construction of a bilingual dictionary intermediated by a third language[C]∥Proc of the 15th Conference on Computational Linguistics,1994:297-303. [9] Rapp R.Automatic identification of word translations from unrelated English and German corpora[C]∥Proc of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics,1999:519-526. [10] Fung P.Compiling bilingual lexicon entries from a non-parallel English-Chinese corpus[C]∥Proc of the 3rd Workshop on Very Large Corpora,2010:173-183. [11] Mikolov T, Le Q V,Sutskever I.Exploiting similarities among languages for machine translation[J].arXiv preprint arXiv,2013:1309-4168. [12] http://translate.google.cn/. [13] Mikolov T.Word2vec project[EB/OL].[2014-11-10].https://code.google.com/p/ word2vec/. 附中文參考文獻: [3] 孫樂.平行語料庫中雙語術語詞典的自動抽取[J].中文信息學報,2000,14(6):33-39.4 實驗與結果分析
4.1 實驗數據與設計

4.2 實驗結果與分析
5 結束語
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
