基于SVM的高維混合特征短文本情感分類
2018-03-05 02:40:35王義真
計算機技術與發展 2018年2期
王義真,鄭 嘯,后 盾,胡 昊
(安徽工業大學 計算機科學與技術學院,安徽 馬鞍山 243032)
0 引 言
隨著移動互聯網的高速發展,智能終端的普及,用戶通過移動網絡更容易獲取和發布互聯網信息。社交媒體的興起,加速了用戶自由表達對人或事的態度、觀點以及情感傾向。近年來網絡上涌現的短文本迅速膨脹,如商品評論、影評、移動短信、微博、論壇等,僅靠人工的方法難以應對網上海量信息的收集和處理。傳統的基于關鍵字的檢索,文本的分類,文本的聚類往往忽略了文本中的情感。因此迫切需要計算機幫助用戶快速獲取和整理這些情感相關信息。文本情感分類主要是通過分析用戶發表的主觀性文本內容,挖掘其情感傾向,從而判斷其情感傾向的極性(如:正向,負向,中立)。針對文本的情感分析有利于更好地了解用戶的情感觀點,從中發現商業價值,增強用戶體驗。文本根據長度的不同可以分為長文本和短文本兩類。由于短文本具有發布頻率快、參與者多、長度較短、結構差異大、交互性強、口語化、省略化、特征關鍵詞稀疏等特性,直接采用現有的情感傾向分類方法對短文本分類的準確率較低。此外,短文本在社區問答[1]、搜索引擎[2]等領域發揮了重要作用,短文本的情感分析日益受到學術界和工業界的廣泛關注。
目前,國內外短文本的情感分析主要是針對微博、在線評論等短文本。在國外,短文本的情感分析研究主要分為主題無關的情感分析和主題相關的情感分析。情感分析的研究思路主要分為兩種:一種是基于語義的研究方法,主要利用現有情感詞典或建立傾向性語義模式庫,應用情感規則匹配的方式實現文本語義的理解,從而實現對文本的情感識別。文獻[3]利用詞典中情感詞和短語的相關極性和強度,并采用集約化和否定化計算文本的情感得分。文獻[4]結合詞典和規則來計算文本的情感極性。重點是情感評價詞語或其組合的極性判斷以及極性求和的方法。另一種是基于機器學習的研究方法,將情感分析看做分類問題。Pang等[5]將機器學習方法應用于電影評論的二分類問題;Kang等[6]提出應用在酒店評論的樸素貝葉斯的改進算法;Liu等[7]提出應用在Tweet的自適應協同訓練算法。
傳統的方法或只依賴情感知識(需要建設情感詞典或領域性情感詞庫),或只側重從大量的訓練集中抽取情感特征,而大量的工作表明,這兩者之間相互依賴、互為補充。雖然針對文本的情感分析研究已經取得了一定的成果,如果能將兩者很好地進行融合,必將對情感分類的效果有很大的提升。基于此,文中提出基于SVM的高維混合特征模型。在短文本的特征提取上,兼顧了情感和語義兩者,充分挖掘短文本的情感特征,并且引入了新的特征。
1 相關工作
情感分析[8](sentiment analysis),又稱傾向性分析,意見抽取(opinion extraction),意見挖掘(opinion mining),情感挖掘(sentiment mining),主觀分析(subjectivity analysis),它是對帶有情感色彩的主觀性文本進行分析、處理、歸納和推理的過程。情感分析自從2002年由Bo Pang提出后,獲得了很大程度的關注,特別是在在線評論的情感傾向性分析上獲得了很大的發展,具有很大的研究和應用價值。由于短文本的特殊性,直到近些年,人們才開始關注微博等短文本情感分析任務。
一般而言,當前的短文本情感分析任務主要關注于特征提取和分類器選擇兩個部分。由于短文本特征非常稀疏,Flekova等[9]通過計算同義詞詞典詞匯語義相似度拓充twitter情感特征,并結合詞典、n-gram等特征訓練支持向量機分類器。Kokciyan等[10]則加入了主題標簽、上下文、指示等特征構建twitter情感分析系統。由于中文短文本的復雜性,不少研究人員利用現有的通用詞典WordNet或 HowNet,進行擴展來獲取大量的極性詞語及極性。楊超等[11]在HowNet和NTUSD的基礎上進行擴展,建立了一個具有傾向程度的情感詞典。基于情感詞典和修飾詞詞典,計算句子的傾向性,最后得到一條評論的傾向性。何鳳英等[12]以HowNet情感詞語集為基準,構建中文基礎情感詞典,利用詞典及程度副詞和否定副詞詞典計算情感詞的極性,利用詞典及程度副詞和否定副詞詞典來獲取博文的情感傾向性。研究發現,綜合考慮三種因素,采用支持向量機(SVM)和信息增益(IG),以及TF-IDF(term frequency-inverse document frequency)作為特征項權重,三者結合對微博的情感分類效果最好。謝麗星等[13]針對中文微博消息展開了情感分析方面的初步調研,實驗對比了三種情感分析的方法,包括表情符號的規則方法、情感詞典的規則方法、基于SVM的層次結構多策略方法,結果證明基于SVM的層次結構多策略方法效果最好。
2 情感特征的構造
2.1 表情符號特征
文中通過對微博、在線評論等主流網站采集一定規模的數據后,發現短文本語料中包含豐富的表情符號。有些表情含有明顯的情感傾向,利用正則表達式能夠提取文本的表情符號。選擇了表1具有代表性的帶情感傾向的表情符號。
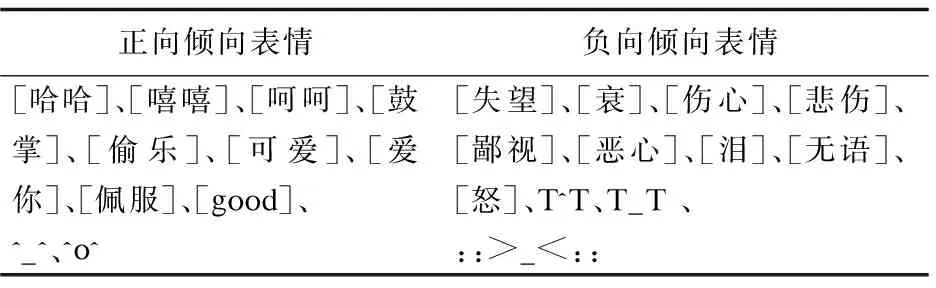
表1 表情符號列表
選擇的依據:一是出現頻次越高,選取的機會越大;二是根據經驗知識判定表情符號情感傾向。最終在抽取特征后形成:

另外,網民在發表這些評論信息結束時會使用一個或者多個表情用于更好地表達自己的情感,而這些表情看上去是圖片,實際上是由特殊符號組成。
例如,這部電影真心不錯[good]。由此可見,最后一個表情能夠表達網民發表的短文文本情感傾向。在該特征的提取方面,發現正則表達式能夠很好地處理這種有特殊表情符號組成的表情。
2.2 詞聚類特征
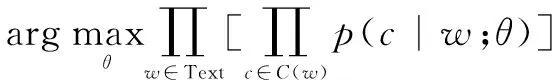
其中,C(w)表示一組單詞w的上下文。文中使用該工具運用在收集到的語料庫上聚100類后得到1 533個基元。
2.3 詞性標注特征
常見的分詞系統的詞性標注的粒度能達到:名詞、動詞、形容詞、副詞等。文中選用中科院的ICTCLAS[15]作為分詞系統,它能將詞性標注粒度更為細分。例如,名詞可以分成人名、地名;形容詞可以分為副形詞、名形詞、形容詞性語素、形詞詞性慣用語。
例如,語句是:“又一部國產良心之作 笑點從頭到尾 搞笑卻不乏溫情 真是讓人又哭又笑,同一個道理聽過太多次總覺得平淡無味沒有分量,然而這一次卻說到心里。”標注后:又/d 一/m 部/q 國產/b 良心/n 之/uzhi 作/ng 笑/vd 點/v 從頭到尾/dl 搞/v 笑/v 卻/v 不乏/v 溫情/n 真/d 是/vshi 讓/v 人/n 又/d 哭/v 又/d 笑/v,/wj 同/p 一個/mq 道理/n 聽/v 過/uguo 太/d 多/m 次/qv 總/d 覺得/v 平淡/a 無味/a 沒/d 有/vyou 分量/n,/wj 然而/c 這/rzv 一/m 次/qv 卻/d 說/v 到/v 心里/s 。/wj
2.4 n-gram特征
對于給定的文本,都可以將其看做是長度不同序列的集合。在這些序列中,相鄰的N個字或詞稱為n-gram,n-gram算法的基本思想是通過一個大小為N的滑動窗口將文本內容進行切分,形成長度為N的片段序列,每個片段序列稱為gram。使用n-gram特征,盡可能地獲取有限長度短文本的未登錄情感詞和情感信息。
例如:“乒乓球拍賣啦”,采用傳統的分詞技術,會被切分成“乒乓球/拍賣/啦”或“乒乓/球拍/賣啦”。可見傳統分詞技術對于短文本的分詞存在明顯的缺陷,甚至可能會改變原有評價對象。文中將n-gram作為一類特征用于短文本的情感分析。鑒于此類情況增加n-gram特征:對于1-gram是單個的字或詞對于特征的選擇并沒有多大意義,所以選擇從2-gram開始,但超過4-gram同樣沒什么意義。
2.5 否定特征
含有主觀傾向的語句往往有很明顯的否定詞。與傳統文本情感分類不同,“不”、”沒“等否定詞不再作為停頓詞被刪除。在句子里“不”或“沒”的否定范圍是“不”或“沒”的全部詞。一個詞在不在否定范圍內對正確情感分類產生了很大影響。
例如:“他一直沒上班/他沒一直上班;你沒天天學習/你天天沒學習。”文中采用否定特征是以句子出現否定詞為否定特征的開始直至句子結束都加上否定標記,并且記錄否定詞的個數也作為否定特征的一部分。
2.6 情感詞典
在對文本情感分類時,往往文本中含有的少數帶有情感傾向的詞匯最直接表現文本情感的傾向。如正向詞匯“高興”和負向情感詞“難過”。由于中文詞語的復雜性,情感詞匯非常豐富,多為形容詞、副詞等。文中選擇四個情感詞典進行情感特征選擇。其中包含整理好的HowNet、NTUSD、大連理工大學的本體詞匯以及使用CHI統計對情感短文語料庫構建的AHUT詞典。其中由于前兩者并沒有標注情感詞的情感極性,所以將正向詞匯的得分定為1.0,負向詞匯的得分定為-1.0。在情感詞典特征上,采用下面四個規則進行情感分數的計算。
規則1:分別計算情感文本中的正向詞、負向詞的數量;
規則2:分別計算情感文本中的正向詞、負向詞的得分總數;
規則3:分別計算情感文本中的得分最大正向詞、負向詞的分值;
規則4:分別計算情感文本中的最后一個情感詞的分值。
3 SVM高維混合特征情感分類器
3.1 理論基礎
情感短文本經過特征抽取后得到的是高維稀疏向量矩陣,直接用來作為分類器的訓練和測試數據,選用適合處理大規模文本分類的SVM算法構建情感分類器。給定一組樣本集{xi,yi},i=1,2,…,l,xi∈Rn,yi∈{-1,+1},SVM需要解決如下無約束最優化問題:
(1)
其中,ξ(w;xi,yi)為損失函數;C為懲罰系數;l為樣本總數。
通常在分類問題中使用標準C-SVM(L1-SVM)作為有效的分類算法。L1-SVM的損失函數是一階范數,而二階L2-SVM的損失函數增加了一個由懲罰因子對角矩陣逆的Hessian矩陣的雙重方法。這提高了求解過程的穩定性。L1-SVM和L2-SVM的損失函數公式分別如下:
max(1-yiwTxi,0)
(2)
max(1-yiwTxi,0)2
(3)
通常在SVM的分類問題中增加一個偏置項b,文中處理偏置項b如下所示:
(4)
其中,B為常數。
式(1)稱作SVM的原始形式,在求解中將其轉變成對偶形式:
(5)
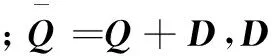
在L1-SVM中,U=C,Dij=0;在L2-SVM中,U=∞,Dij=1/2C,?i。對于式(5)中對偶問題的求解,文獻[16]提供了開源的大規模線性SVM的工具包LIBLINEAR,實現了L1-SVM、L2-SVM等損失函數。
通過實驗對比表明:在處理大規模數據時,L2-SVM的性能優于L1-SVM、PEGASOS、SVMperf。因此,文中同樣選用L2-SVM作為SVM情感分類器的損失函數。
3.2 框架實現
情感文本特征的表示是情感分類的關鍵步驟,包括預處理、中文分詞、特征抽取三個部分。
預處理:目的是將原始文本中涉及到用戶隱私的內容刪除。其中可能會包含超鏈接、用戶名以及一些特定話題。
中文分詞:文中使用的是ICTCLAS分詞工具,為下一步的特征抽取提供較為準確的基元。
特征抽取:第2節已經列舉了實驗所要用到的各種情感特征。
實驗思路:先從目標網站爬取評論、微博等數據進行標注;然后使用k折交叉的方法進行訓練和測試;最后經過情感分類器輸出情感極性(正向、負向、中立),并統計實驗結果。
4 實驗方法及相關分析
4.1 實驗數據及預處理
中文情感文本分析不同于英文,到目前為止情感評測語料庫尚未完善。實驗采用的語料庫是由COAE2014評測提供的語料集和從新浪、京東等國內知名網站上采集的數據組成。文中將語料庫命名為DataSet,其中正向條數為5 200,中立條數為5 600,負向條數為5 430。考慮到短文本內容可能含有用戶的一些隱私信息,所以要對實驗數據進行預處理。文中刪除了語料庫中url鏈接、用戶名、話題等信息。
4.2 評價指標
使用準確率P(precision)、召回率R(recall)和F1值(F-Score)作為評價分類器的性能指標,其具體計算公式如下:
(6)
(7)
(8)
其中,TP表示分類器將輸入文本正確地分類到某個類別的數量;FN表示分類器將輸入文本錯誤地分類到某個類別的數量;FP表示分類器將輸入文本錯誤地排除在某個類別之外的數量。
4.3 實驗結果與分析
文本語料庫經過特征篩選器處理后得到的稀疏向量矩陣,可直接作為情感分類器訓練、測試以及交叉驗證的數據集。
(1)基于5折交叉驗證的實驗結果。
首先對短文本語料庫進行特征抽取(約有267萬),然后對語料庫進行5折交叉驗證的實驗。選用Naive Bayes作為對比的baseline方法,在全部特征上做5折交叉的實驗(見圖1),并且模型參數為默認值。
從圖1可以看出,文中模型的分類效果明顯高于Naive Bayes,其平均準確率為84.69%,平均召回率為83.13%,而平均F1值為83.90%。
(2)不同懲罰系數的實驗比較。
在5折交叉實驗的基礎上,驗證不同懲罰系數C對模型三個評價指標的影響,實驗結果如圖2所示。
對比圖2可以發現,短文本情感分類的各評價指標的變化趨勢一致,懲罰系數在75左右時,實驗效果達到最好。
(3)不同特征組合的實驗對比。
為驗證不同類特征對實驗結果的影響,選用不含有AHUT情感詞典和詞性標注作為base feature,然后依次在上一次特征的基礎上加入AHUT字典、表情符號、詞聚類、n-gram以及否定特征(即所有特征)來對部分語料進行實驗。實驗的平均準確率結果統計如圖3所示。
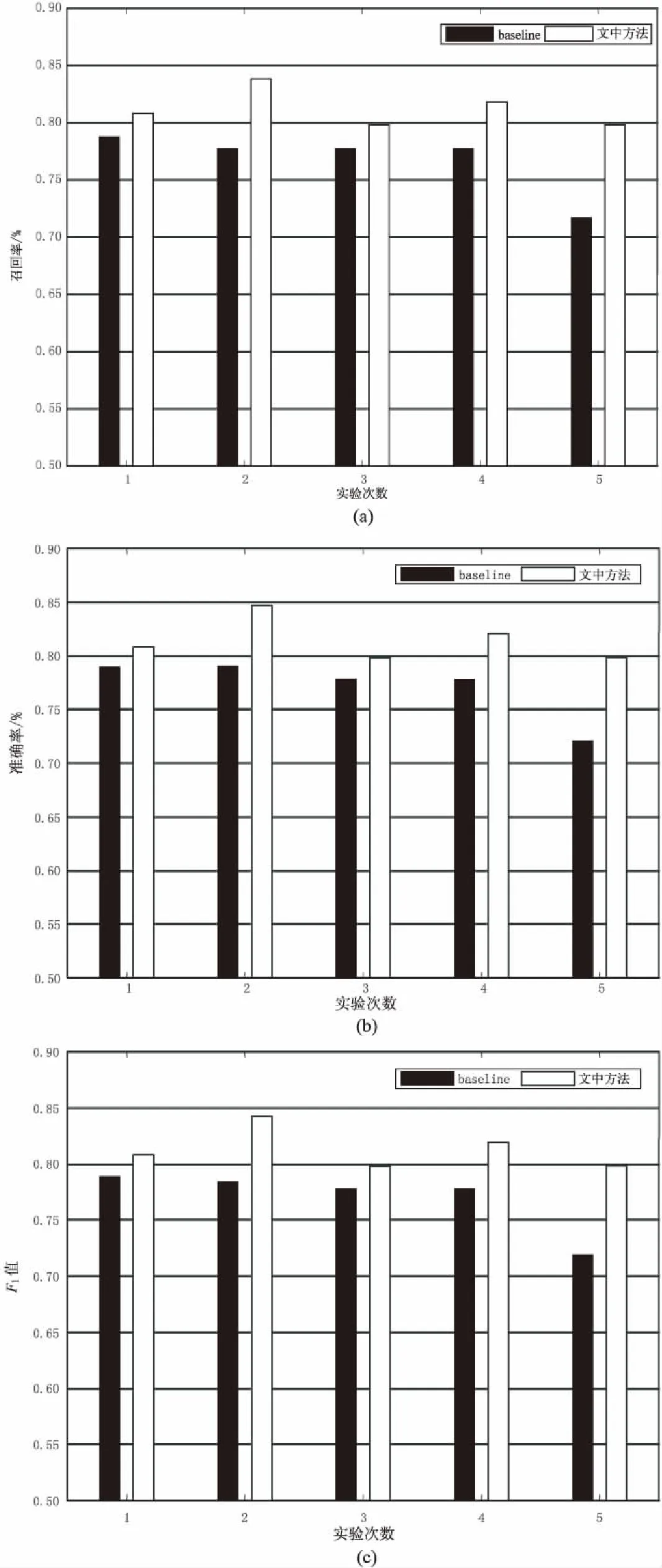
圖1 5折交叉的實驗結果
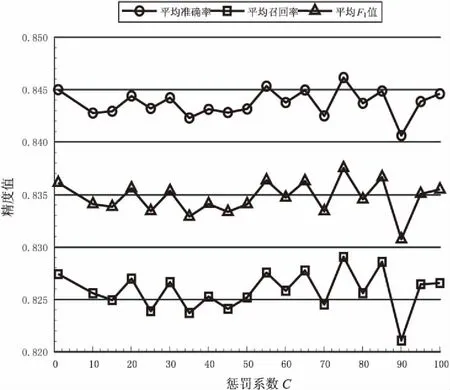
圖2 不同懲罰系數C在5折交叉驗證中的分類性能
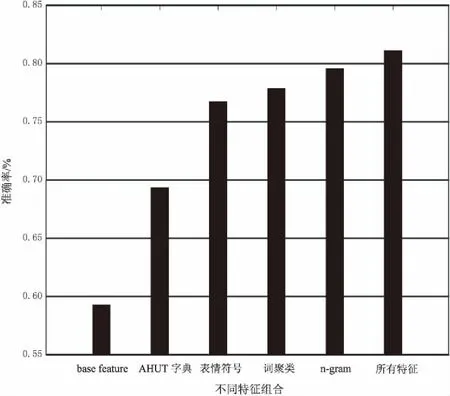
圖3 不同特征組合的實驗結果對比
從圖3可以看出,在base feature的基礎上加入文中構建的AHUT字典后,分類效果提升比較明顯,在加入全部特征后效果達到最好。這是由于文中方法針對短文本抽取的特征有效。但由于實驗特征的組合上采用的是依次增加的方式,而不是隨機選用其中幾類特征的組合,故存在不足。
(4)多種模型的對比。
最后,為進一步驗證提出模型的有效性,在使用同樣語料庫的基礎上與一步三分類方法[13]、Recursive AutoEncoder[17]、Doc2vec方法進行對比,結果如表2所示。

表2 多種模型準確率對比 %
實驗結果表明,提出模型的準確率優于其他幾種模型,驗證了模型的正確性。這是因為與一步三分類方法對比,文中的情感特征增加了詞聚類、否定特征等特征,明顯提高了準確率;與Recursive AutoEncoder、Doc2vec相比,后兩者在準確率多分類上低于二分類。而且,文中在特征選取方面采取正則化手段,避免了特征的二次選擇和“高維”災難。
5 結束語
文中充分考慮短文本的特點,從多維混合特征的角度進行文本的特征抽取,做到盡可能兼顧語義和情感,并且取得了較好的實驗效果,驗證了該方法的有效性和魯棒性。
文中提出了基于SVM的高維混合特征框架,采用正則化的手段解決維數災難問題;彌補了傳統情感字典未標注情感強度值的不足,構建了帶有情感強度值的AHUT情感詞典;考慮到語義對短文本情感分類的正確率影響,將詞聚類加入到情感分析的特征,提高了1.4%的準確率。雖然取得了一定的成果,但也存在不足之處:對情感詞典有一定的依賴;在針對不同特征的組合上,并沒有隨機選取幾種特征的組合進行實驗,可能給實驗的最終結果帶來偏差;無法對海量數據進行實時、并行化處理。接下來的工作將著手解決上述存在的不足之處。
[1] WU H,WU W,ZHOU M,et al.Improving search relevance for short queries in community question answering[C]//Proceedings of the 7th ACM international conference on web search and data mining.New York,NY,USA:ACM,2014:43-52.
[2] TEEVAN J,RAMAGE D,MORRIS M R.#TwitterSearch:a comparison of microblog search and web search[C]//Proceedings of the fourth ACM international conference on web search and data mining.New York,NY,USA:ACM,2011:35-44.
[3] TABOADA M,BROOKE J,TOFILOSKI M,et al.Lexicon-based methods for sentiment analysis[J].Computational Linguistics,2011,37(2):267-307.
[4] YUAN D,ZHOU Y,LI R,et al.Sentiment analysis of microblog combining dictionary and rules[C]//IEEE/ACM international conference on advances in social networks analysis and mining.[s.l.]:IEEE,2014:785-789.
[5] PANG B,LEE L,VAITHYANATHAN S.Thumbs up?:sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 conference on empirical methods in natural language processing-Volume 10.[s.l.]:Association for Computational Linguistics,2002:79-86.
[6] KANG H,YOO S J,HAN D.Senti-lexicon and improved Na?ve Bayes algorithms for sentiment analysis of restaurant reviews[J].Expert Systems with Applications,2012,39(5):6000-6010.
[7] LIU S,LI F,LI F,et al.Adaptive co-training SVM for sentiment classification on tweets[C]//Proceedings of the 22nd ACM international conference on information & knowledge management.New York,NY,USA:ACM,2013:2079-2088.
[8] 趙妍妍,秦 兵,劉 挺.文本情感分析[J].軟件學報,2010,21(8):1834-1848.
[9] FLEKOVA L, FERSCHK O, GUREVYCH I.UKPDIPF:a lexical semantic approach to sentiment polarity prediction in twitter data[C]//Proceedings of the 8th international workshop on semantic evaluation.Dublin,Ireland:[s.n.],2014:704-710.
[10] KOKCIYAN N,ARDA C,OZGUR A,et al.BOUNCE:sentiment classification in twitter using rich feature sets[C]//Proceedings of the 7th international workshop on semantic evaluation.Atlanta,Georgia:ACL,2013:554-561.
[11] 楊 超,馮 時,王大玲,等.基于情感詞典擴展技術的網絡輿情傾向性分析[J].小型微型計算機系統,2010,31(4):691-695.
[12] 何鳳英.基于語義理解的中文博文傾向性分析[J].計算機應用,2011,31(8):2130-2133.
[13] 謝麗星,周 明,孫茂松.基于層次結構的多策略中文微博情感分析和特征抽取[J].中文信息學報,2012,26(1):73-83.
[14] MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems.[s.l.]:[s.n.],2013:3111-3119.
[15] ZHANG H P,YU H K,XIONG D Y,et al.HHMM-based Chinese lexical analyzer ICTCLAS[C]//Proceedings of the second SIGHAN workshop on Chinese language processing-Volume 17.[s.l.]:Association for Computational Linguistics,2003.
[16] FAN R E,CHANG K W,HSIEH C J,et al.LIBLINEAR:a library for large linear classification[J].Journal of Machine Learning Research,2008,9:1871-1874.
[17] 梁 軍,柴玉梅,原慧斌,等.基于深度學習的微博情感分析[J].中文信息學報,2014,28(5):155-161.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
