基于維基百科的短文本相關(guān)度計(jì)算
2018-03-02 09:22:49段利國李愛萍
計(jì)算機(jī)工程 2018年2期
荊 琪,段利國,李愛萍,2,趙 謙
(1.太原理工大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,太原 030600; 2.武漢大學(xué) 軟件工程國家重點(diǎn)實(shí)驗(yàn)室,武漢 430072)
0 概述
語義相關(guān)度計(jì)算作為自然語言處理領(lǐng)域一項(xiàng)基本性的研究工作,廣泛地應(yīng)用于查詢擴(kuò)展、詞義消歧、機(jī)器翻譯、知識抽取、自動糾錯(cuò)等領(lǐng)域[1]。隨著社交媒體的出現(xiàn),例如BBS、貼吧、聊天工具等,文本已成為重要的信息載體,其規(guī)模呈現(xiàn)出爆炸式的增長趨勢,尤其是短文本,作為一種新興的文本信息源,已成為了人們交流以及表達(dá)的重要形式。
目前,對于中文語義相關(guān)度的計(jì)算方法大多以相似度計(jì)算為基礎(chǔ),然而相似度并不能完全替代相關(guān)度,相似度指的是“相像、相類”,具有可替代性;相關(guān)度反映的是“互相涉及、彼此關(guān)聯(lián)”,通常高頻出現(xiàn)在同一語境中的共現(xiàn)詞相關(guān)度較高,即相關(guān)性具有不可替換性。可以把相似性當(dāng)作相關(guān)性計(jì)算的一個(gè)特征因子,作為最終結(jié)果的一部分。
由于短文本所表達(dá)的信息有限,因此需要大量的背景知識來對樣本特征進(jìn)行擴(kuò)展,獲取背景知識的方法可以分為2類:一類是基于語義詞典,如WordNet、Hownet等;另一類是對大規(guī)模語料庫進(jìn)行統(tǒng)計(jì)分析來獲取背景知識。
維基百科是目前世界上最大的、多語種的、開放式的在線百科全書。目前含有35萬條中文條目,這些條目之間相互鏈接構(gòu)成了一個(gè)巨大的語義網(wǎng)絡(luò),很多研究者都青睞于利用維基百科來計(jì)算語義相關(guān)性。文獻(xiàn)[2]將基于Wordnet的一些經(jīng)典算法用到維基百科的分類圖中,證明了維基百科在相關(guān)度計(jì)算中的可行性。文獻(xiàn)[3]提出了利用維基百科解釋文檔來計(jì)算兩個(gè)純文本之間的相關(guān)度,該算法被稱為明確語義分析(Explicit Semantic Analysis,ESA),但是該方法沒有考慮短文本的結(jié)構(gòu)信息。文獻(xiàn)[4]通過從維基百科中收集突出的概念以及概念的解釋文檔,對ESA方法進(jìn)行改進(jìn),提出了突出語義分析(Salient Semantic Analysis,SSA)方法,但該方法的缺點(diǎn)在于構(gòu)建語義空間的過程中,不斷稀釋原文本的語義信息,因此在短文本相關(guān)度計(jì)算方面具有局限性。
隨著維基百科的普及和盛行,近年來越來越多的學(xué)者投入到中文維基百科的研究中。文獻(xiàn)[5-6]利用維基百科文檔間的鏈接結(jié)構(gòu)提取了近40萬對語義相關(guān)詞,并計(jì)算了語義相關(guān)度。但該方法沒有考慮到維基百科類別信息。文獻(xiàn)[7-8]采用倒排索引進(jìn)行加權(quán),通過兩向量間的余弦夾角計(jì)算兩個(gè)詞語的語義相關(guān)度。文獻(xiàn)[9]利用類別信息擴(kuò)展文本特征,進(jìn)而對文本之間的相關(guān)度進(jìn)行計(jì)算。文獻(xiàn)[10-11]采用統(tǒng)計(jì)規(guī)律和類別信息相結(jié)合的方式,通過構(gòu)建概念集合的方式擴(kuò)展短文本向量的信息,從而實(shí)現(xiàn)短文本之間的相關(guān)度計(jì)算。這些方法都只對維基百科的結(jié)構(gòu)進(jìn)行直接利用,并沒有深入挖掘維基百科中的語義信息以及結(jié)構(gòu)信息,也沒有考慮短文本中詞語權(quán)重的問題。
本文將維基百科作為外部語義知識庫,利用維基百科的結(jié)構(gòu)特征,如維基百科的分類體系結(jié)構(gòu)、摘要中的鏈接結(jié)構(gòu)、正文中的鏈接結(jié)構(gòu)以及重定向消歧頁等,提出類別相關(guān)度與鏈接相關(guān)度相結(jié)合的詞語相關(guān)度計(jì)算方法。在此基礎(chǔ)上,提出基于詞形結(jié)構(gòu)、詞序結(jié)構(gòu)以及主題詞權(quán)重的句子相關(guān)度計(jì)算方法。
1 基于維基百科的詞語相關(guān)度計(jì)算
維基百科具有多樣的數(shù)據(jù)結(jié)構(gòu)。圖1展示了一個(gè)基本的維基百科文檔頁面,并對本文所用到的鏈接結(jié)構(gòu)、重定向、消歧頁、摘要、類別等信息進(jìn)行說明。
1.1 類別相關(guān)度
維基百科中的每個(gè)條目對應(yīng)于網(wǎng)站上的一個(gè)頁面,每個(gè)條目都?xì)w屬于一個(gè)或多個(gè)類別。例如:“實(shí)驗(yàn)”所屬的類別為“化學(xué)”和“物理”。維基百科提供了類別索引這一工具來組織和表達(dá)文檔之間的層次以及類別結(jié)構(gòu),除了根結(jié)點(diǎn)之外,其余的每個(gè)條目都可以在維基百科中找到其相應(yīng)的位置。維基百科的層次分類結(jié)構(gòu)如圖2所示。
傳統(tǒng)的語義相關(guān)度計(jì)算方法使用的是分類圖最短路徑方法,該方法首先將兩個(gè)詞匹配到一個(gè)語義網(wǎng)絡(luò)的概念結(jié)點(diǎn),然后利用概念結(jié)點(diǎn)在分類圖上的路徑信息實(shí)現(xiàn)相關(guān)度計(jì)算[12]。對于待比較的兩個(gè)詞wa和wb,在分類圖中查找兩詞語的最小公共父類los,計(jì)算兩個(gè)詞語到最小公共父類的距離len(a)、len(b),距離越遠(yuǎn),相關(guān)關(guān)聯(lián)越小。兩個(gè)詞語的相關(guān)度計(jì)算為:
loga(len(wa)+len(wb))
(1)
其中,len(a)、len(b)分別表示詞語wa、wb到最小公共父類的距離。
利用數(shù)據(jù)結(jié)構(gòu)的知識,可以把維基百科的層次分類圖轉(zhuǎn)化為樹狀結(jié)構(gòu)。在樹狀結(jié)構(gòu)中,需要考慮詞語類別的深度信息,深度信息可以說明它在維基百科分類體系中的地位。在以上公式的基礎(chǔ)上加入深度信息可以得到如下公式:
Simdca(wa,wb)=Simca(wa,wb)×
(2)
其中,depth(wa)表示詞語wa在維基百科分類樹中的深度。
1.2 鏈接相關(guān)度
維基百科中每個(gè)條目的解釋文檔中還含有豐富的鏈接信息,除了普通的解釋條目外,維基百科還含有多種引導(dǎo)性的條目,例如重定向條目和消歧義條目,利用這些鏈接可以有效計(jì)算兩個(gè)詞條的相關(guān)度。維基百科的鏈接結(jié)構(gòu)如圖3所示。

圖3 維基百科鏈接結(jié)構(gòu)示意圖
1.2.1 鏈接的重定向
維基百科向用戶提供了命名重定向功能,如果兩個(gè)條目的相關(guān)度達(dá)到一定程度,就將它們合并到同一個(gè)條目中,避免同一個(gè)事物有多個(gè)不同的條目。絕大多數(shù)情況下,維基百科重定向是對完全同一種事物的2種說法,例如周樹人與魯迅。少數(shù)情況下是將2個(gè)關(guān)聯(lián)性很強(qiáng)的條目放在一起,例如病態(tài)矩陣與條件數(shù)。所以,對于待比較的兩個(gè)詞語wa、wb,首先在維基百科的重定向列表中查找,若兩個(gè)詞互為重定向詞或者含有相同的重定向詞,則認(rèn)為相關(guān)性為1;否則,查找各自的重定向詞,用其代替該詞參與之后的計(jì)算;若兩詞無重定向詞,則跳過此步。
1.2.2 鏈接的向量構(gòu)建
根據(jù)維基百科解釋頁面的特點(diǎn):每個(gè)頁面的首段為概念的摘要,所以出現(xiàn)在摘要中的詞語更能表達(dá)該條目的含義,帶有更強(qiáng)的語義信息,應(yīng)該賦予更高的權(quán)重。維基百科中鏈接詞的數(shù)目過于繁多,構(gòu)建出的向量維度過大,計(jì)算出的相關(guān)度過小。因此對摘要和全文分別計(jì)算其鏈接相關(guān)度,并賦予相應(yīng)的權(quán)重。
對于詞w可以構(gòu)建它的摘要、文檔鏈接向量:
Abstractw=[ (w1,fa(w1)),(w2,fa(w2)),…,
(wi,fa(wi)),…,(wn,fa(wn))]
(3)
Textw=[ (w1,ft(w1)),…,(w2,ft(w2)),…,
(wi,ft(wi)),…,(wn,ft(wn))]
(4)
其中,wi表示出現(xiàn)在摘要、文檔中的鏈接條目,fa(wi)表示wi這一條目在摘要中出現(xiàn)的頻率,ft(wi)表示wi這一條目在該概念文檔里出現(xiàn)的頻率。
1.2.3 鏈接的相關(guān)度計(jì)算
對于兩個(gè)詞語之間的摘要鏈接相關(guān)度,用向量之間的內(nèi)積來表示:
(5)
其中,m、n分別代表詞語wa、wb摘要中鏈接條目的數(shù)目。
對于兩個(gè)解釋文檔的鏈接向量,由于概念文檔所含的條目過于繁多,因此頻率值過小,對它進(jìn)行開方運(yùn)算以達(dá)到放大頻率的目的,使得求得的相關(guān)度不會接近于0。利用向量之間的夾角余弦值計(jì)算,如式(6)所示。
(6)
其中,m、n分別代表詞語wa、wb的解釋文檔中鏈接條目的數(shù)目。
因此,兩詞語之間的鏈接相關(guān)度可以表示為:
simlinks(wa,wb)=α×simabstract+β×simtext
(7)
其中,α、β表示權(quán)重調(diào)節(jié)因子,且α+β=1。經(jīng)實(shí)驗(yàn),當(dāng)α=0.6,β=0.4時(shí)結(jié)果最優(yōu)。
1.3 兩者結(jié)合的相關(guān)度計(jì)算
綜合類別相關(guān)度和鏈接結(jié)構(gòu)的相關(guān)度計(jì)算,利用式(2)可以獲得維基百科的深度加權(quán)類別相關(guān)度,利用式(7)可以獲得兩個(gè)詞語基于鏈接結(jié)構(gòu)的鏈接相關(guān)度計(jì)算,所以詞語wa與wb之間的綜合相關(guān)度為:
sim(wa,wb)=α×simdca+β×simlinks
(8)
其中,α、β表示權(quán)重調(diào)節(jié)因子,且α+β=1。經(jīng)實(shí)驗(yàn),當(dāng)α=0.75,β=0.25時(shí)結(jié)果最優(yōu)。
2 基于維基百科的短文本相關(guān)度計(jì)算
2.1 詞形相關(guān)度
詞形相關(guān)度主要依賴于兩個(gè)短文本的共現(xiàn)詞語的頻率,即兩個(gè)待比較的文本經(jīng)過預(yù)處理之后,共現(xiàn)詞語的頻率越高,相關(guān)度越大。在計(jì)算頻率時(shí),用出現(xiàn)相同詞語的最少次數(shù)來計(jì)算,詞形相關(guān)度可用式(9)計(jì)算。
(9)
其中,same(A,B)表示兩個(gè)短文本中相同詞語的次數(shù),而count(X)表示短文本X包含的詞語個(gè)數(shù)(包含相同詞語)。
2.2 詞序相關(guān)度
在對短文本語義相關(guān)度研究中,需要考慮詞序,例如:“青蛙吃昆蟲”與“昆蟲吃青蛙”兩句話的詞形相似度為1,而語義相似度并不一致。在相關(guān)度計(jì)算中,詞序可以作為一個(gè)權(quán)重較弱的特征來考慮。短文本的詞序主要表現(xiàn)為同一詞語在各短文本中序號不同,設(shè)same(A,B)為在短文本A和B中共現(xiàn)且只出現(xiàn)一次的詞語集合,對短文本A中的詞語依次進(jìn)行編號,按照此編號來形成短文本B的詞序向量,進(jìn)而得到該向量所構(gòu)成的自然數(shù)的逆序數(shù),代表兩個(gè)短文本中詞語順序不同的個(gè)數(shù),逆序數(shù)越大,詞序相似度越低。因此,詞序相似度可用式(10)計(jì)算。
(10)
其中,Inverse(A,B)表示短文本B相對于A的逆序數(shù),|same(A,B)||same(A,B)-1|為逆序數(shù)最大值的2倍。
2.3 基于詞對的語義相關(guān)度
短文本在語義上的相關(guān)度依賴于詞對之間的關(guān)聯(lián),除了考慮短文本詞形、詞序的結(jié)構(gòu)特點(diǎn),還需考慮短文本的深層語義信息,并且語義相關(guān)度占有較大比重。傳統(tǒng)的短文本相關(guān)度計(jì)算方法是通過對各詞對的相關(guān)度求平均值來獲取的,為了突出更強(qiáng)的語義信息,本文選取兩個(gè)詞對中相關(guān)度最高的詞對計(jì)算。
1)詞對相關(guān)度矩陣構(gòu)建
對于待比較的兩個(gè)短文本A、B,首先經(jīng)過詞形標(biāo)注等預(yù)處理,提取出具有實(shí)際意義的名詞。在構(gòu)建矩陣之前,首先得到兩個(gè)短文本的特征詞集合向量A={a1,a2,…,an},B={b1,b2,…,bm},通過兩向量的笛卡爾積計(jì)算兩詞語的相關(guān)度,構(gòu)建的兩個(gè)向量詞對相關(guān)度矩陣如下:
(11)
其中,sij表示短文本A中的第i個(gè)特征詞與短文本B中第j個(gè)特征詞之間的相關(guān)度。
2)最大匹配組合選擇
本文算法從相關(guān)度矩陣M中由大到小地選取min(m,n)個(gè)詞語組合的相關(guān)度值,要求每個(gè)詞語只出現(xiàn)一次,即在另一短文本中找到與其互為相關(guān)度最大的詞。選取的規(guī)則為:選擇矩陣中相關(guān)度最高的詞aij,即兩個(gè)短文本中相關(guān)度最高的詞語對,去掉第i行第j列,形成一個(gè)(m-1)×(n-1)的矩陣,將該矩陣作為待選擇的矩陣,重復(fù)以上步驟直到矩陣為空。經(jīng)過選擇后,設(shè)最大序列為maxL={a23,a12,a3i,…,am1}。將平均值作為兩個(gè)短文本之間的相關(guān)度,公式為:
(12)
結(jié)合詞形詞序的計(jì)算公式,可以得出短文本相關(guān)度的計(jì)算公式:
Sim(A,B)=α×Simsa(A,B)+β×Siminv(A,B)+
γ×Simword(A,B)
(13)
其中,α+β+γ=1。經(jīng)實(shí)驗(yàn),當(dāng)α=0.25,β=0.15,γ=0.6時(shí)結(jié)果最優(yōu)。
2.4 基于聚類的相關(guān)度計(jì)算方法
基于詞對的相關(guān)度比較的是兩個(gè)短文本中特征詞之間的相關(guān)度,而在短文本中,由于每個(gè)特征詞在短文本中的結(jié)構(gòu)不同,所表達(dá)的信息強(qiáng)度也不同,因此每個(gè)特征詞在短文本中的重要性程度對短文本相關(guān)度計(jì)算也有很大影響。對待比較的短文本進(jìn)行聚類,將相關(guān)度較高的聚為一類,利用這種方法可以更好地表達(dá)短文本的語義信息。聚類的算法如圖4所示。

圖4 文本間聚類的過程
短文本經(jīng)過聚類得到組塊,每個(gè)組內(nèi)詞語之間的相關(guān)度較高,實(shí)驗(yàn)認(rèn)為在一個(gè)組內(nèi)的詞語數(shù)量越多,所表達(dá)的語義信息也更強(qiáng)烈,因此也更能代表整個(gè)短文本的含義,應(yīng)該賦以更高的權(quán)重,計(jì)算權(quán)重的公式為:
(14)
其中,Count(Ai)表示詞語ai所在的組中詞語的個(gè)數(shù),m表示短文本A中的詞語個(gè)數(shù)。聚類相關(guān)度計(jì)算公式如式(15)所示。
(15)
其中,Sim(ai,bj)表示短文本A中第i個(gè)詞語與短文本B中第j個(gè)詞語的相關(guān)度,計(jì)算公式為1.3節(jié)中的式(8)。
2.5 短文本相關(guān)度計(jì)算
綜合以上計(jì)算短文本的相關(guān)度方法,得到短文本相關(guān)度計(jì)算步驟如圖5所示。首先對短文本進(jìn)行預(yù)處理,完成詞形相關(guān)度、詞序相關(guān)度的計(jì)算方法;其次通過詞對相關(guān)度矩陣的構(gòu)建,完成基于詞對的語義相關(guān)度計(jì)算,綜合3種方法可得到短文本相關(guān)度;最后利用聚類方法對主題詞進(jìn)行加權(quán),得到聚類相關(guān)度。

圖5 短文本相關(guān)度計(jì)算步驟
3 實(shí)驗(yàn)設(shè)置與結(jié)果分析
3.1 維基百科數(shù)據(jù)預(yù)處理及測試集
維基百科作為最大的百科知識全書,包含有一些特殊的語義結(jié)構(gòu),例如重定向、消歧頁面、導(dǎo)航(分類索引、特色內(nèi)容、新聞動態(tài)、最近更改、隨機(jī)頁面)、幫助、工具等其他服務(wù)。本文所運(yùn)用到的語言信息包括:詞語解釋文檔及文檔之間的鏈接信息和分類數(shù)據(jù),重定向頁面和消歧頁面來處理同義詞和多義詞。
關(guān)于詞語相關(guān)度計(jì)算的測試集選用了人工翻譯WordSimilarity-353測試集[13-14]以及國防科學(xué)技術(shù)大學(xué)所統(tǒng)計(jì)的Words-240[15-16]。短文本相關(guān)度的測試集選擇中國數(shù)據(jù)庫萬維網(wǎng)知識提取大賽所提供的短文本語義相關(guān)度比賽評測數(shù)據(jù)集。
3.2 實(shí)驗(yàn)結(jié)果分析
本實(shí)驗(yàn)首先實(shí)現(xiàn)的是詞語的語義相關(guān)度計(jì)算,將各種方法計(jì)算所得的詞對相關(guān)度與人工標(biāo)注的從高到低排列,隨機(jī)選取的部分詞對經(jīng)過實(shí)驗(yàn)得到的結(jié)果如圖6所示。
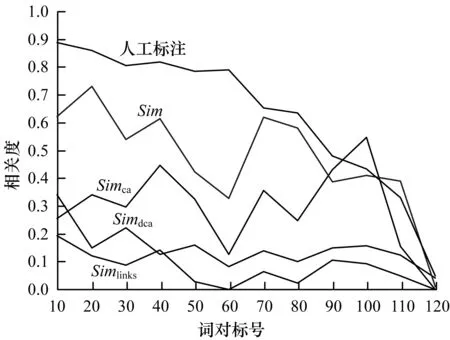
圖6 部分詞語相關(guān)度計(jì)算結(jié)果
經(jīng)過實(shí)驗(yàn)結(jié)果分析,可以得出這4種方法在計(jì)算詞語相關(guān)度時(shí)都有一定的合理性,但是Simdca作為一種Simca的改進(jìn)算法,結(jié)果并沒有比Simca更好,原因在于Simdca加入了深度這一不穩(wěn)定因素,對于同一深度差的詞對相關(guān)度計(jì)算并不明顯,Simlinks的結(jié)果基本都比較小,不超過0.2,因?yàn)榫S基百科中每個(gè)概念的解釋頁面包含太多的鏈接信息,兩個(gè)詞的公共鏈接所占的比率會比較低,相關(guān)度會比較小。結(jié)合表1各個(gè)算法所求得的Spearman相關(guān)系數(shù)可以看出Sim方法求得的相關(guān)系數(shù)最高,并且在0.7以上,與人工標(biāo)注的更接近,實(shí)驗(yàn)結(jié)果最為理想。其中,*表示相關(guān)性在 0.05 層上顯著(雙尾),**表示相關(guān)性在 0.01 層上顯著(雙尾)。
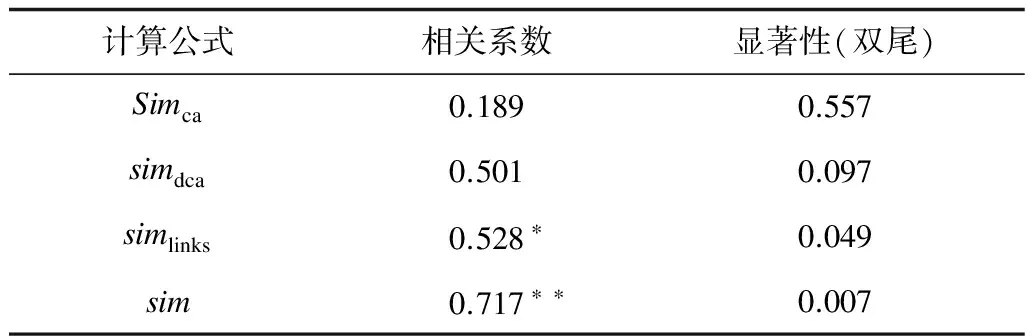
表1 Spearman相關(guān)系數(shù)
在實(shí)現(xiàn)詞語間語義相關(guān)度計(jì)算的基礎(chǔ)上,完成了對句子間相關(guān)度的計(jì)算。由于測試集的測試標(biāo)準(zhǔn)分為4個(gè)等級,并沒有給出具體的相關(guān)度數(shù)值,因此也將實(shí)驗(yàn)的計(jì)算結(jié)果劃分為4個(gè)等級(相關(guān)度為0~0.25對應(yīng)測試集中的0;0.25~0.5對應(yīng)測試集中的1;0.5~0.75對應(yīng)測試集中的2;0.75~1.0對應(yīng)測試集中的3)。 隨機(jī)抽取的計(jì)算結(jié)果如表2所示,準(zhǔn)確率的計(jì)算結(jié)果如圖7所示。

圖7 準(zhǔn)確率比較
從結(jié)果中可以看出基于詞形詞序的準(zhǔn)確率較低,因?yàn)檫@2種方法沒有考慮語義的信息,只考慮了句子的表征信息,基于詞序的方法準(zhǔn)確率最低,因?yàn)樵~序在相關(guān)度計(jì)算中僅起次要作用,詞序不同的情況下兩個(gè)短文本的相關(guān)度有可能很高,所以準(zhǔn)確率最低。而其余的3種方法由于考慮到語義這一層面,取得了較好結(jié)果,準(zhǔn)確率均在50%以上。但使用聚類并沒有提高準(zhǔn)確率,究其原因在于測試集中短文本中可聚類的詞語并不很多,沒有達(dá)到提高句子主題詞權(quán)重的目的。
4 結(jié)束語
本文在目前基于維基百科的語義計(jì)算的基礎(chǔ)上,采用維基百科的類別與鏈接結(jié)構(gòu)特征提出了一種計(jì)算詞語間相關(guān)度的方法,該方法利用摘要以及全文的鏈接相關(guān)度,極大地提高了結(jié)果的準(zhǔn)確性。在計(jì)算出詞語相關(guān)度的基礎(chǔ)上,結(jié)合詞形詞序,并且根據(jù)文本間的聚類來對句子關(guān)鍵詞賦予較高權(quán)重,實(shí)現(xiàn)了句子間相關(guān)度計(jì)算的方法。實(shí)驗(yàn)結(jié)果顯示,與人工判斷的結(jié)果相比較的Spearman相關(guān)系數(shù),比傳統(tǒng)算法高出了很多,短文本間相關(guān)度的準(zhǔn)確率也提高了不少。證明了該方法是可行和有效的。
該方法還有很多需要進(jìn)一步探討和研究的地方,例如:由于聚類的算法需要額外進(jìn)行詞語間的距離以及計(jì)算詞語間的相關(guān)度,因此時(shí)間復(fù)雜度較高。如何提高該方法的時(shí)間效率將是下一步研究的問題之一。
[1] 張紅春.中文維基百科的結(jié)構(gòu)化信息抽取及詞語相關(guān)度計(jì)算[D].武漢:華中師范大學(xué),2011.
[2] STRUBE M,PONZETTO S.Wiki Related Computing Semantic Relatedness Using Wikipedia[C]//Proceedings of the 21st National Conference on Artificial Intelligence.New York,USA:ACM Press,2006:1419-1424.
[3] GABRILOVICH G,MARKOVITCH S.Computing Semantic Relatedness Using Wikipedia-based Explict Semantic Analysis[C]//Proceedings of the 20th International Joint Conference on Artificial Intelligence.Berlin,Germany:Springer,2007:1606-1611.
[4] HASSAN S,MIHALCEA R.Semantic Relateness Using Salient Semantic Analysis[C]//Proceedings of the 25th AAAI Conference on Artificial Intelligence.[S.l.]:AAAI Press,2011:884-889.
[5] 李 赟.基于中文維基百科的語義知識挖掘相關(guān)研究[D].北京:北京郵電大學(xué),2009.
[6] 李 赟,黃開妍,任福繼,等.維基百科的中文語義相關(guān)詞獲取及相關(guān)度分析計(jì)算[J].北京郵電大學(xué)學(xué)報(bào),2009,32(3):109-112.
[7] 劉 軍,姚天昉.基于Wikipedia的語義相關(guān)度計(jì)算[J].計(jì)算機(jī)工程,2010,36(19):42-46.
[8] 涂新輝,張紅春,周琨峰,等.中文維基百科的結(jié)構(gòu)化信息抽取及詞語相關(guān)度計(jì)算方法[J].中文信息學(xué)報(bào),2012,26(3):109-115.
[9] 王 錦,王會珍,張 俐.基于維基百科類別的文本特征表示[J].中文信息學(xué)報(bào),2011,25(2):27-31.
[10] 范云杰,劉懷亮.基于維基百科的中文短文本分類研究[J].現(xiàn)代圖書情報(bào)技術(shù),2012,28(3):47-52.
[11] 汪 祥,賈 焰,周 斌,等.基于中文維基百科鏈接結(jié)構(gòu)與分類體系的語義相關(guān)度計(jì)算[J].小型微型計(jì)算機(jī)系統(tǒng),2011,32(11):2237-2242.
[12] 諶志群,高 飛,曾智軍.基于中文維基百科的詞語相關(guān)度計(jì)算[J].情報(bào)學(xué)報(bào),2012,31(12):1265-1270.
[13] FINKELSTEIN L,GABRILOVICH E,MATIAS Y,et al.Placing Search in Context:The Concept Revisited[J].ACM Transactions on Information Systems,2002,20(1):116-131.
[14] 夏 天.中文信息處理中的相似度計(jì)算研究與應(yīng)用[D].北京:北京理工大學(xué),2005.
[15] 孫琛琛,申德榮,單 菁,等.WSR:一種基于維基百科結(jié)構(gòu)信息的語義關(guān)聯(lián)度計(jì)算算法[J].計(jì)算機(jī)學(xué)報(bào),2012,35(11):2361-2370.
[16] 伍 賽,楊冬青,韓近強(qiáng).一種基于單詞相關(guān)度的文檔聚類新方法[J].計(jì)算機(jī)科學(xué),2004,31(10):261-263.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
當(dāng)代修辭學(xué)(2011年6期)2011-01-29 02:49:50
外語學(xué)刊(2011年1期)2011-01-22 03:38:33
當(dāng)代修辭學(xué)(2010年1期)2010-01-23 06:35:10
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
