基于RBF網絡的城市垃圾產量預測及可視化
2018-03-02 05:24:26秦緒佳鄭紅波張美玉浙江工業大學計算機科學與技術學院浙江杭州310023
中國環境科學 2018年2期
關鍵詞:模型
秦緒佳,彭 潔,徐 菲,鄭紅波,張美玉 (浙江工業大學計算機科學與技術學院,浙江 杭州 310023)
城市垃圾指大量以固態形式呈現的廢物混合物.隨著市民消費水平整體提高,日漸增長的垃圾排放量致使“垃圾圍城”的現象成為全球趨勢.日前,大量露天堆放的垃圾嚴重影響居民生活、城市容貌、經濟建設、資源永續和生態環境等.因此,控制未來城市垃圾產量成為各環保組織的一個重要研究課題.
研究我國城市垃圾產量的變化規律及發展趨勢,不但能為城市環境規劃運行和監管等決策提供數據支持,還能為垃圾廢物的清掃、運輸和處理擬定合理的實施方案.可見,有必要建立合適的預測模型來高效合理的預測未來幾年的垃圾排放量.
目前,國內常用的預測方法包括灰色分析模型、BP神經網絡模型、多元線性回歸模型、時間序列法等.依據全省管理現狀,文獻[1-2]通過建立灰色分析模型分別對遼寧省未來2012~ 2020年及西安市2011~2020年的生活垃圾產量進行預測,模型精度較高,方法合理且有意義.基于傳統BP神經網絡,文獻[3]基于污染物濃度及可見度,建立風險神經網絡預測模型,對天津市歷年氣象數據檢驗并預測.文獻[4]以深圳市2004~2012年的生活垃圾產量為樣本,建立基于時間序列分析的ARIMA模型.方法較好地預測生活垃圾產量的季節性變化規律.此外,國外學者Noori等[5]將人工智能技術中向量機的概念應用于垃圾預測,但該方法發展不成熟,尚處于摸索階段,存在許多不確定因素.目前,現存的預測模型大都存在相同的特點,即根據未篩選的變量集或基于現狀,主觀地篩選變量作為擬影響因素,來建立垃圾產量的預測模型.
互信息用來度量多個變量間的親密度,即互相包含的信息含量.RBF網絡衍生于數值分析中初次提到的多變量插值的徑向基算法[6].與其他多層反向傳播網絡類似,它是一種包含輸入層、隱含層和輸出層的高效的三層前饋式網絡拓撲結構.RBF網絡不但收斂速度相對較快,而且能以不同精度逼近連續函數.
為克服現存方法精度不高,計算量大及未篩選影響因素等問題,本文提出一種基于互信息確定影響因素,徑向基函數網絡訓練及相對平均誤差反向修正建立預測模型的新方法.實驗結果顯示,采用本文建立的RBF網絡預測模型對全國各省市城市垃圾排放量進行預測,不但具有收斂速度快和預測精確度較高等優勢,還具有一定的理論和實踐意義.
1 基于互信息的垃圾產生量影響因素的確定
據統計,對預測垃圾未來產量的影響要素有很多,比如內在因素、自然環境以及社會經濟等[7].本文根據內在因素建立各省份垃圾排放量的預測模型,其中預擬影響因素包括地區生產總值、居民消費水平、社會消費品零售值、金融及建筑業增加值等18項,預擬定影響因素及2014年部分省垃圾產量[8](部分數據)如表1所示.
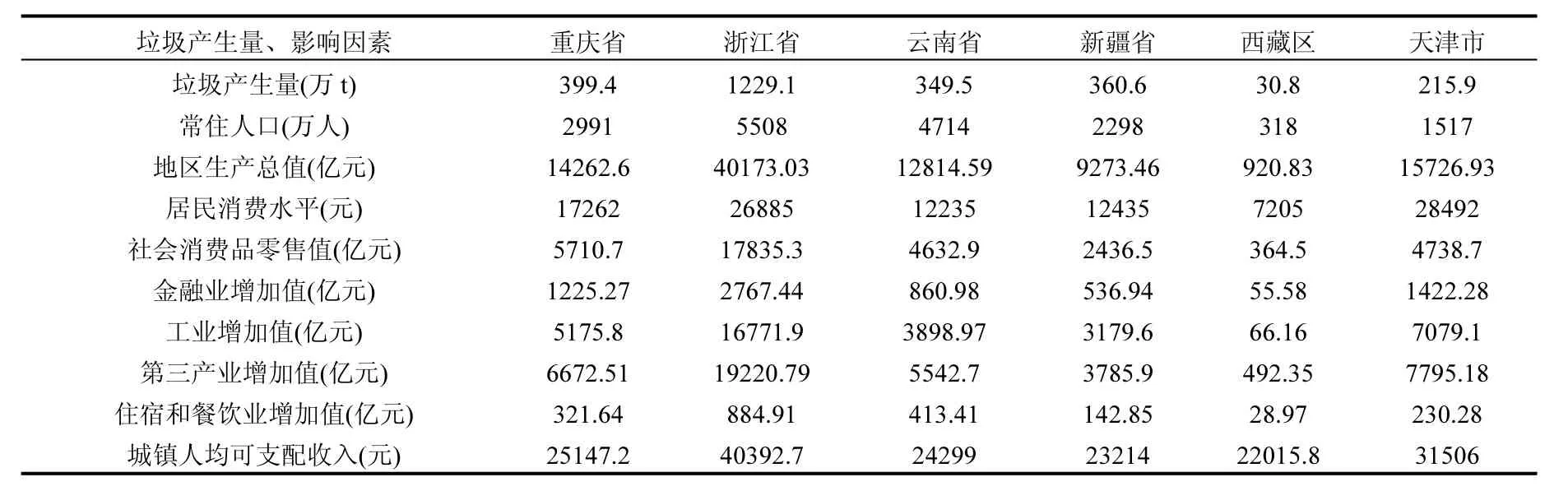
表1 垃圾產生量及擬定影響因素(部分數據)Table 1 Waste production and possible influence factors (partial data)
合適的變量集可直接決定模型建立的精確度.一般地,相關變量有利于建立準確的預測模型,而冗余變量不但增加模型計算的復雜度,而且掩蓋變量間的相關作用.為降低冗余變量帶來的干擾,建立高效的預測模型,本文利用多變量間的相關性分析確定一個變量關系最密切的子變量集.一般地,可以采用獨立成分分析(ICA)[9]、主成分分析(PCA)、典型相關分析(CCA)、聚類分析和互信息等方法進行多元變量的相關性分析[10].其中互信息起源于信息論中的熵,即信號在傳輸過程中丟失的信息量,常被用來度量多個變量間的親密度.該方法不但能定性地推測變量間的關系變化趨勢,還能定量地確定變量間的具體數值關系.
下面將基于K-近鄰估計互信息,并根據互信息篩選影響城市垃圾產生量的主要因素.
1.1 K-近鄰的互信息估計
定義兩個連續變量X和Y,假設μx(x)、μy(y)和u( x, y)依次是X、Y的邊際密度函數和聯合密度函數.根據信息論的相關理論,X和Y之間的互信息可寫成:

若上式I越大,說明變量X與Y親密度越高,彼此的共同信息量越多.相反,若互信息I值越小,甚至為0時,說明這兩個變量相互包含的信息含量很少,甚至相互獨立.
此外,計算變量X、Y的熵及聯合熵是估計互信息的另一種簡便方法,如下式:

式中:
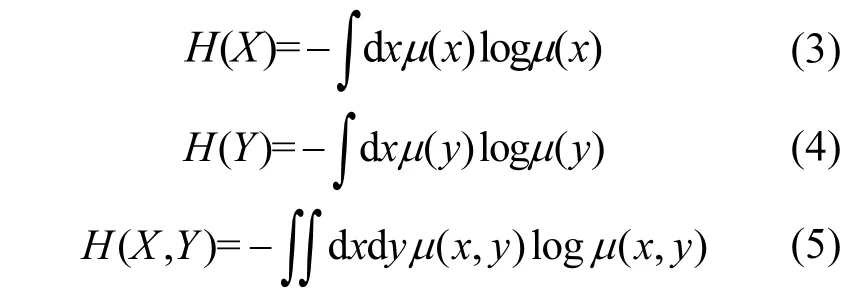
由于分別對邊際密度函數和聯合密度函數近似估計會帶來較大誤差,為克服這一缺點,Kraskov等[11]提出了基于K-近鄰的互信息估計法來減少誤差.該算法的主要思想是:假設連續變量X和Y構成向量空Z=(X, Y),則向量空間內每個樣本點zi=(xi, yi)的K-近鄰可利用最大范數計算:

在空間Z上,假設樣本點zi=(xi, yi)到其k-近鄰距離為ε(i)/2,且該點投影到X軸和Y軸的距離分別為εx(i )/2和εy(i)/2.在X空間中,到xi的歐氏距離小于ε(i)/2的樣本點的數目為nx( i);在Y空間中,到yi的歐氏距離小于ε(i)/2的樣本點數目為ny(i).則X和Y的互信息可由以下公式估計:

式中:ψ(x)為digamma函數,簡記為ψ(x)=Γ(x)-1dΓ(x)/dx ,該式滿足ψ(x+1)=ψ(x)+1/x,ψ(1)≈-0.5772156.若將上述公式擴展到高維空間,多維變量間的互信息可表示為:

1.2 基于K-近鄰的互信息的多變量選擇
由于輸入的多變量之間并非局限于線型關系,因此,為了分析不同輸入變量對互信息量的影響,本文采用以互信息為基礎的特征選擇[12]算法分析多變量間的相關關系,進而識別并移除冗余、無關的變量.早期Battiti等[13]提出基于互信息的特征選擇MIFS算法,隨后大量改進的評價標準相繼涌現,如MIFS-U[14]、mRMR[15]、PMI[16]、NMIFS[17]、CMINN[18]等.下文引入多變量信息作為選擇相關變量的評價標準[19-20],即在高維空間中多個變量間的互信息.在該方法中,對于給定的輸入特征變量,該方法既考慮與輸出特征變量也考慮與已選特征變量的關系.
假設3個連續變量X、Y和Z的互信息記為I( X; Y;Z),則其可表示為:

式中:上式前項稱為條件互信息量[21],即在已知某個條件Z的情況下,變量X和Y通訊傳遞后獲得的信息量.條件互信息可表示為:

因此,條件互信息一定為非負值,結合上節基于K-近鄰的互信息估計,該條件互信息估計可寫為:

根據上述公式(2)、(9)和(11)可以估計連續變量X、Y和Z的互信息.但是,與條件互信息不同,多變量互信息的值可能為正值也可為負值.當多信息I>0時,說明特征變量X和Y互補;當多信息I<0時,意味著Z是冗余變量,故當添加Z作為條件時反而降低X與Y的依賴程度;當多信息I=0時,表示Y和Z之間的依賴關系與X基本無關.依據上述性質,本文關于多特征變量選擇評價標準的定義如下:
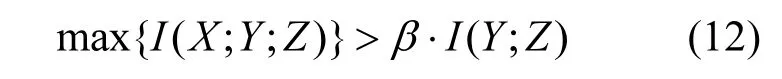
式中:X為待選變量;Y為已選變量;Z為類變量;β為用戶自定義量.上式用來衡量變量Y和Z的依賴性受變量X影響的程度.當滿足上述公式時,則認為X是相關變量,否則是冗余變量.
綜上,假設算法的輸入變量分別是: U=D(F,C)為訓練數據集,F為所有輸入特征變量,C為類變量;輸出變量是選擇特征集S,則基于 K-近鄰互信息方法確定影響因素的步驟如表2:

表2 基于K-近鄰互信息的確定影響因素算法Table 2 Algorithm of determining influence factors based on k-neighbor mutual information
2 基于RBF網絡的城市垃圾產量預測
與其他多層反向傳播網絡類似,徑向基網絡函數是一種包含輸入層、隱含層和輸出層的收斂速度很快的3層前饋式網絡拓撲結構,它不但有可能滿足實時性要求,而且能以不同精度逼近連續函數.本文關于預測城市垃圾產生量的RBF網絡結構如圖1所示.

圖1 RBF網絡Fig.1 Radial basis function network
在上述模型中,輸入層是由樣本數據構成,輸出單元是對隱單元激活后的簡單線性函數.通過對激活函數參數的調整,隱含層神經元不但能將低維空間模式轉成高維空間,還能將非線性映射轉換成線性映射.當輸入樣本值越鄰近基函數的中心,隱含層單元的激活程度越高、權重越高,故RBF網絡的輸出值為:


本文采用兩階段預測垃圾產量的方法,第一階段基于RBF網絡訓練出初始預測模型.該階段首先根據改進的K-means++算法確定徑向基函數網絡的隱含層節點中心,然后利用梯度下降法調節基函數中心c、擴展常數σ和權值w等參數.第二階段利用相對平均誤差對初始模型反向誤差修正獲得垃圾產生量的最終預測模型.
2.1 數據預處理
考慮到影響城市垃圾產生量的因素的基本量綱不同,為消除不同量綱對實驗結果造成的影響,首先對所有輸入數據進行歸一化預處理,即把所有因素轉化為0~1之間的數據.通過歸一化不僅提高模型的精度,也增加模型收斂速度.我們采用線性變換對所有影響因素進行歸一化:

式中:min和max分別為訓練樣本數據的最小值和最大值.此外,實驗結束時還通過反歸一化恢復數據.
2.2 確定初始參數
2.2.1 確定聚類中心 本文基于一種改進的方法——K-means++聚類[22]算法確定徑向基函數的中心并且以自適應的方式確定隱含層單元數量k.替代傳統的隨機選取,利用K-means++聚類網絡初始化k個聚類中心,然后根據K-means方法重新調整聚類中心.關于確定初始聚類中心算法如表3所示,自適應確定隱含層單元數量k值的方法如表4所示:
2.2.2 確定擴展常數 根據上節可確定的每個徑向基函數的中心距離其他徑向基函數中心的最短距離di=mjin(ci-cj),j=1,2,...k ,其中ci為徑向基函數中心,且j≠i,λ為重疊系數,則擴展常數σi為可表示為:

2.2.3 確定權值 本文假設隨機給定[-1,1]的數值確定隱含層節點至輸出層節點之間的權值wi( i=1,2,...k ).
2.3 網絡訓練及參數修正
根據RBF網絡拓撲結構可知,通過調節最小化目標函數中隱單元中心、擴展常數和權值來實現梯度網絡訓練.神經網絡學習的目標函數為:


表3 確定初始聚類中心的算法Table 3 Algorithm of determining initial clustering centers

表4 自適應確定k值方法Table 4 Adaptive determination of k value method
式中:E為徑向基函數的全局誤差;k為隱含層節點的數量;ei為第i個樣本點的預測模型輸出值和實際值的誤差,計算如下:
到0.93 V,體偏置從0.6 V到-1.8 V,而PMOS閾值電壓從-0.32 V降低到-1.01V,體偏置從-0.6 V到1.8 V。

式中:yi為樣本實際值;f( xi)為該樣本經RBF網絡訓練的輸出值;m為輸入樣本的數量;wj為隱含層到輸出層單元的權重,Φ(Xi-cj)為基函數,本文選用高斯函數作為激活函數;Xi為第i個樣本的輸入值;cj為第j個徑向基函數的中心.
為使目標函數E最小,本文采用梯度下降法調節徑向基函數中心c、擴展常數σ和權值w:
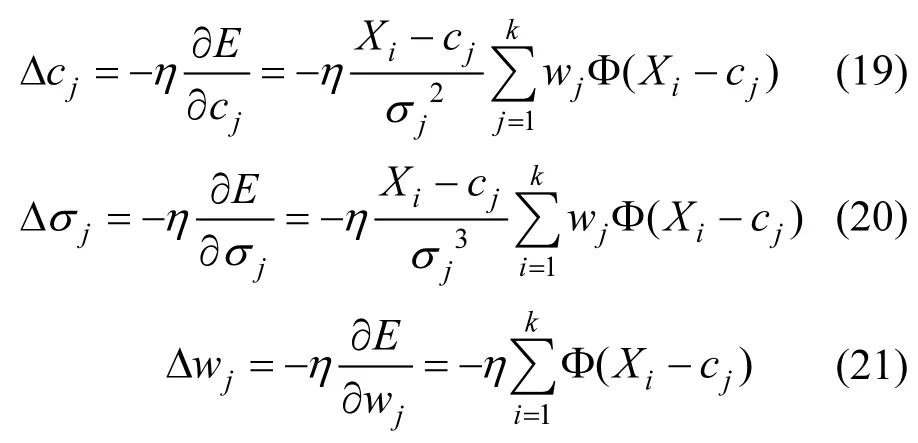
式中:η為學習率,采用自適應調節學習率的方法,當前迭代次數記為i,總共迭代次數記為n,學習率與迭代次數間的關系可表示為:

重復上述過程,直至完成迭代,或當前預測值與真實值的方差小于用戶定義的最小方差,即S2<,則迭代結束,初始模型訓練完成.
2.4 誤差反向修正
采用上述方法對全國各省市垃圾產量建立徑向基網絡函數獲得初始預測模型,但不同省份對徑向基函數網絡的適應性不同.下面利用相對平均誤差反向修正初始結果獲得最終預測模型.具體修正方式如下:

2.5 整體算法流程
綜上所述,基于徑向基函數(RBF)網絡建立全國城市垃圾排放量預測模型的基本思路如下:已知樣本輸入數據,通過徑向基函數網絡構造的線性公式,利用樣本預測值和實際值間的誤差調節徑向基函數中心、擴展常數和權值,經過誤差反向修正,獲得最終預測模型.模型預測流程如圖2所示:

圖2 預測模型流程Fig.2 The flow chart of the prediction model
3 結果分析及可視化
選取我國各省2004~2011年垃圾產生量的影響因素和2006~2013年的垃圾產生量的實際數據作為網絡訓練樣本,2012~2013年的影響因素和2014~2015年的垃圾量數據為模型檢驗樣本,并利用該模型預測及可視化全國各省市2017~2018年的垃圾產量.
首先對18個擬影響因素(表1中僅列出了其中9個)建立K-近鄰估計互信息,根據互信息篩選出對城市垃圾產生量有主要影響的8個因素,即預測模型的輸入變量.確定的影響因素分別為常住人口、地區生產總值、社會消費品零售值、金融業增加值、工業增加值、批發和零售業增加值、住宿和餐飲業增加值和第三產業增加值.其中,社會消費品零售值與城市垃圾產生量負相關,其他項與城市垃圾產生量正相關.
根據RBF網絡的拓撲結構,采用兩階段的徑向基函數網絡對垃圾產量進行預測,并以Choropleth地圖對全國各省的垃圾產生量進行可視化.Choropleth地圖(也稱為分級統計圖)是指對數據屬性值劃分為不同等級,并選擇合適的色級,以反映數據在地理上的分布差異.通過比較2014~2015年全國各省檢驗樣本基于RBF模型的預測值和實際輸出值,獲得模型的相對誤差及平均相對誤差.由于檢驗樣本數據量較大,表5僅列出部分省市數據、樣本最優相對誤差和平均相對誤差.表中平均相對誤差為所有樣本數據相對誤差的平均值.圖3為浙江省垃圾產量預測變化曲線.圖4為基于Choropleth地圖我國2015~2016年垃圾產生量的分布圖及2017~2018年的垃圾產生量預測分布.

圖3 浙江省垃圾產生量預測變化曲線Fig.3 The prediction curve of waste production in Zhejiang province

表5 實際與預測數據對比(部分數據)Table 5 Comparison between actual and predicted data (partial data)
實驗結果發現:由圖4所示,近幾年廣東省垃圾產量在全國范圍內一直位居首位.整體而言,華東地區垃圾產生量較多且有明顯增多的跡象.大部分省市垃圾產生量有略微的增長,其中山東省增長最快;少量省市垃圾產生量降低,其中黑龍江和吉林減少最明顯.由圖3所示,浙江省垃圾產量模型曲線擬合比較好.
對比現有相關文獻,文獻[2]采用GM(1,1)模型預測建成土地面積及居民可支配收入的相對平均誤差為5.7%和11.11%.文獻[4]建立ARIMA模型的相對平均誤差為5.288%,但最大絕對百分比誤差高達 25.775%.本文通過對2014~2015年全國各省市檢驗樣本基于RBF模型得到的預測值和實際輸出值的比較,理論上計算得出相對平均誤差是6.43%,相當于預測精度為93.57%.其中,相對平均誤差最優值為0.1%,相當于預測精度為99.9%. 近些年,隨著城市生活垃圾管理體系的不斷變化,垃圾的處理方式在不斷升級,從露天堆積和焚燒、隨地填埋到資源回收再利用,再到盡力減少源頭垃圾量.由于本文目標是預測2017~2018年的垃圾產生量,一般地,在短期內垃圾的管理方式變化基本不大,故對本文的預測模型影響不大.因此,本文建立的兩段式徑向基函數網絡模型的預測精度較高,能較好的對城市垃圾的產生量進行預測.

圖4 基于2015~2018年Choropleth的垃圾產生量可視化分布Fig.4 The visualization of waste production based on Choropleth from 2015 to 2018
4 結論
運用具有較強非線性處理能力和逼近能力的徑向基函數網絡建立預測模型,并預測及可視化我國2017~2018年全國各省市垃圾排放量.
由于城市垃圾產量受到許多因素的影響,合適的變量集可直接決定模型的預測精度.故本文首先基于K-近鄰互信息的多變量選擇特征準則剔除冗余、無關因素,從18個擬影響因素中確定了8個影響垃圾排放量的因子;然后基于RBF網絡訓練得出垃圾產生量初始預測模型,并對初始預測結果誤差反向修正獲得最終預測模型.通過比較檢驗樣本預測值和實際觀測值,大部分省市垃圾產生量仍有略微的增長,尤其廣東省穩居首位,相反,黑龍江和吉林等少量省市垃圾產生量有所降低.
[1] 王東明,呂洪濤.基于灰色預測模型的遼寧省城市生活垃圾產生量預測 [J]. 環境保護與循環經濟, 2013,33(4):30-31+44.
[2] 李艷平,麻敏潔,魯來鳳.基于多模型擬合的西安市生活垃圾量預測 [J]. 計算機工程與應用, 2015,(6):222-226.
[3] 王 愷,趙 宏,劉愛霞,等.基于風險神經網絡的大氣能見度預測 [J]. 中國環境科學, 2009,29(10):1029-1033.
[4] 吳靈玲,盧加偉,廖利,等.基于ARIMA模型的生活垃圾產生量預測 [J]. 環境衛生工程, 2013,(5):1-4.
[5] Noori R, Abdoli M A, Ghasrodashti A A, et al. Prediction of municipal solid waste generation with combination of support vector machine and principal component analysis:a case study of mashhad [J]. Environmental Progress & Sus-tainable Energy,2009,28(2):249-258.
[6] 鄭劍鋒,焦繼東,孫力平.基于神經網絡的城市內湖水華預警綜合建模方法研究 [J]. 中國環境科學, 2017,37(5):1872-1878.
[7] 何德文,金 艷,柴立元,等.國內大中城市生活垃圾產生量與成分的影響因素分析 [J]. 環境衛生工程, 2005,13(4):7-10.
[8] 國家統計局.中國統計年鑒 [M]. 北京:中國統計出版社,2016:71-612.
[9] Lee T W. Independent Component Analysis: Theory and Applications. Boston: Kluwer Academic Publisher, 1998.
[10] 王展青.核統計成分分析及其在人臉識別中的應用研究 [D].華中科技大學, 2008.
[11] Alexander Kraskov, Harald Stogbauer, Peter Grassberger.Estimating mutual information [J]. Physical Review E. 2004,69(6):066138.
[12] 邊肇祺,張學工.模式識別 [M]. 北京:清華大學出版社, 2000:176-177.
[13] Battiti R. Using mutual information for selecting features in supervised neural net learning. [J]. IEEE Transactions on Neural Networks, 1994,5(4):537-550.
[14] Kwak N, Choi C H. Input feature selection for classification problems. [J]. IEEE Transactions on Neural Networks, 2002,13(1):143-159.
[15] Peng H, Long F, Ding C. Feature Selection Based on Mutual Information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy [J]. IEEE Transactions on Pattern Analysis &Machine Intelligence, 2005,27(8):1226-38.
[16] May R J, Maier H R, Dandy G C, et al. Non-linear variable selection for artificial neural networks using partial mutual information [J]. Environmental Modelling & Software, 2008,23(10/11):1312-1326.
[17] Estévez P A, Tesmer M et al. Normalized mutual information feature selection [J]. IEEE Transactions on Neural Networks,2009,20(2):189-201.
[18] Tsimpiris A, Vlachos I, Kugiumtzis D. Nearest neighbor estimate of conditional mutual information in feature selection [J]. Expert Systems with Applications, 2012,39(16):12697-12708.
[19] Mcgill W J. Multivariate information transmission [J].Psychometrika, 1954,19(2):93-111.
[20] Vergara J R, Estévez P A. A review of feature selection methods based on mutual information [J]. Neural Computing and Applications, 2014,24(1):175-186.
[21] Tsimpiris A, Vlachos I, Kugiumtzis D. Nearest neighbor estimate of conditional mutual information in feature selection [J]. Expert Systems with Applications, 2012,39(16):12697-12708.
[22] Arthur D, Vassilvitskii S. k-Means++: the advantages of careful seeding, in: SODA ’07 [C]. Proceedings of the Eighteenth Annual ACM-SIAM Symposiumon Discrete algorithms, Society for Industrial and Applied Mathematics, 2007:1027-1035.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
