基于文本相似度的高校圖書館電子資源建設研究
2018-03-02 08:04:16孫慧
智能計算機與應用 2018年1期
孫 慧
(長春師范大學 圖書館, 長春 130032)
引言
大數據環境背景下,高校圖書館數字資源建設是圖書館建設的最重要的組成部分,高校圖書館數據庫資源的建設情況不僅反映了高校資源建設的重視程度,更在一定層面反映了學校教學和科研的發展水平。此外,高校資源建設情況還與高校的學科建設和服務等級密不可分[1]。
通常情況下,按照數據來源,數據庫可分為購買數據庫、試用數據庫、自建數據庫和特色數據庫;按照數據庫的語種,可分為中文數據庫、英文數據庫、西文數據庫及多語種數據庫;按照數據庫資源類型,可分為數據、期刊、電子書、多媒體、參考工具、平臺、專利、報紙、古籍、技術標準、多出版類型等[2]。
1 高校數據庫資源獲取
1.1 數據來源
本次研究搜集的數據庫資源數據主要來自于各高校圖書館網站中資源欄目,據教育部公示2016全國最新高校名單統計,共有2 879所高校,每所高校網站分別具有幾十到幾百個不等的電子資源數據庫[3]。本文有針對性地搜集了截至2017年8月國內30所重點高校使用的數據庫作為數據分析樣本,主要搜集數據庫資源的名稱、語種、類型以及學科服務范圍等信息[4]。
1.2 數據獲取工具
本文研究處理的數據主要是通過八爪魚采集器對高校圖書館網站的資源模塊使用數據獲取方式得到的。八爪魚采集器是一款業界領先的新一代、智能、通用的網頁數據采集器,能迅速采集各種資源,使用簡單,而且全部可視化操作[5]。通過八爪魚數據采集器提取的數據可以導入/導出多種格式的數據文件,如:導入SqlServer、MySql數據庫、導出到excel或txt等。
1.3 數據獲取結果
本文數據獲取結果為30個國內重點高校圖書館數據。結果中包括有:綜合類院校15個,理工類院校8個,師范類院校4個,財經類院校3個,具體的數據獲取結果見表1所示。其中,資源種類是指該校圖書館網站上顯示的數據庫總個數;學科分類是指是否可以根據學科來查看數據庫;語種分類是指是否可以根據數據庫語言類別來查看數據庫;類型分類是指使用數據庫時是否可以根據數據、期刊、電子書、多媒體、參考工具、平臺、專利、報紙、古籍、技術標準、多出版類型等來檢索數據庫[6]。

表1 30所國內高校圖書館資源建設情況Tab. 1 Resources construction of 30 domestic university libraries
通過數據搜集得到的30所高校圖書館網站的數據庫列表,共采集到6 796條信息紀錄。
2 文本相似度數據分析
2.1 數據標準化
數據標準化主要是將數據進行規范化處理,轉換為有利于數據分析的數據,本文的數據標準化研究主要可解析為如下設計內容:
(1)去除重復數據。如:同一個圖書館數據庫列表中會出現“中國知網鏡像”與“中國知網主站”兩個電子資源,實質為同一資源的2種存儲方式,需要去除重復的記錄。
(2)合并相同數據項。如:對于中國知網碩博論文、中國知網期刊全文數據庫,需要進行合并,統稱為中國知網數據庫。
(3)規范化數據庫命名法。如:“國務院發展研究中心信息網”與“國研網”雖然數據庫名稱文字標識不同,但屬于同一個數據庫,統稱為國研網,而對于英文數據庫統一使用英文拼寫和簡寫方法命名,去除中文詞匯命名。
2.2 數據分析程序
對于搜集得到的 6 796條數據庫信息,分析可知其中的很多信息記錄表征的都是同一數據庫,譬如很多學校都使用中國知網CNKI數據庫,復旦大學圖書館數據庫列表中對該數據庫命名為“中國知網”,而吉林大學圖書館數據庫列表中命名為“中國知網CNKI”,為此就需要一種有效的數據分析方法進行文字的相似度比較。本文即使用VBA語言實現了一種文本相似度比較的程序,實現數據的統計與分析。基礎研究數據源如圖1所示。其中,Sheet1名字為數據源,Sheet2名字為相似度,用來保存比較結果[7]。

圖1 數據源信息表Fig. 1 Data source information table
文本比較相似度程序的關鍵功能可表述如下:
(1)自動獲取數據總行數。
(2)設置比較行,不包含表頭,設置從某幾行到某幾行進行比較。
(3)根據相似度閾值的設置,篩選符合相似度閾值的數據會被復制到圖1相似度的表中。
(4)設置復制行數是指保存相似度結果時,需要復制的源數據的行數。
(5)連續比較,程序每次運行不清空上次比較結果并設定數據追加,否則每次運行前將清空相似度表。
2.3 算法原理
本文給出的文本相似度分析算法的研究原理是:從2個字符串的左邊開始比較,計算并記錄已經比較過的子串的距離,然后進一步得到下一個字符位置時的距離,距離就是用來計算從源串s轉換到目標串t所需要的最少的插入、刪除和替換的數目,算法流程設計如圖2所示[8]。
計算相似度的數學表達式為:
Q=(rep/Longer)^2*L(L=1)
(1)
其中,Q為相似度百分比,取值范圍為0~100;rep為重疊率為1的情況下,計算不同字符的個數,即為需要替換的字符個數;Longer為需比較的2個字符串較長字符串的長度值[9]。
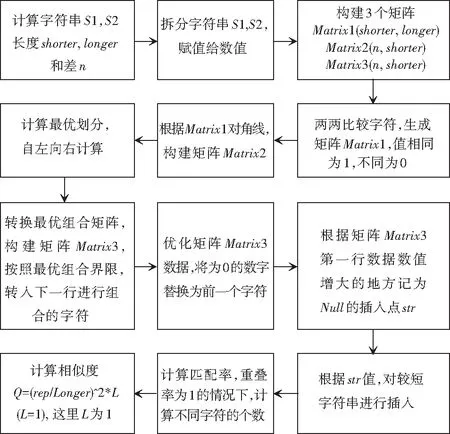
圖2 數據分析算法Fig. 2 Data analysis algorithm
3 數據分析結果
本文分析結果設置程序的相似度閾值為60~100,目的是最大可能地去除相似度較高的數據庫信息,精確篩選結果。由于英文和外文期刊名稱的巨大區別性,及中文和外文期刊配置提供的服務有所不同,可以依據語種針對所得到的30所高校的數據庫列表中的數據展開統計分析,并分別給出如下研究處理結果[10]。
3.1 中文數據庫分析結果
圖3顯示了在30所高校中排名前15的中文數據庫的使用情況信息,排名先后順序為中國知網(CNKI)、KUKE數字音樂圖書館、人大報刊復印資料、新東方多媒體學習庫、中文社會科學引文索引(CSSCI)、維普期刊資源整合平臺、讀秀搜索、國研網、NoteExpress參考文獻管理軟件、中國基本古籍庫、超星電子圖書、超星數字圖書館、EPS全球統計數據/分析平臺、超星學術視頻。

圖3 中文數據庫使用情況Fig. 3 Chinese database usage
由圖3結果可見,中文數據庫中使用以人文社會科學領域中的各個學科為主,而且是以期刊和電子圖書為主,高校比較注重英語、音樂、經濟、古籍等方面資料的學習[11]。
3.2 外文數據庫分析結果
圖4 顯示了在30所高校中排名前15的外文數據庫的使用情況信息。排名先后順序為:HeinOnline(著名的法學期刊全文數據庫)、Taylor & Francis、ACM Digital Library、 Science Online(即《科學》在線)、Wiley Online Library、ACS(美國化學學會)、Nature、Annual Reviews(專注于出版綜述期刊,回顧本學科最前沿的進展,為科學研究提供方向性指導)、MyiLibrary(世界領先的集成性電子書平臺)、Encyclopedia Britannica Online(享有盛譽的綜合性英文百科全書)、Elsevier ScienceDirect、OCLC FirstSearch、Web of Science、Oxford Scholarship Online(專門收錄牛津大學出版社最優秀的學術專著圖書)、MathSciNet(美國數學學會出版的《數學評論》)。
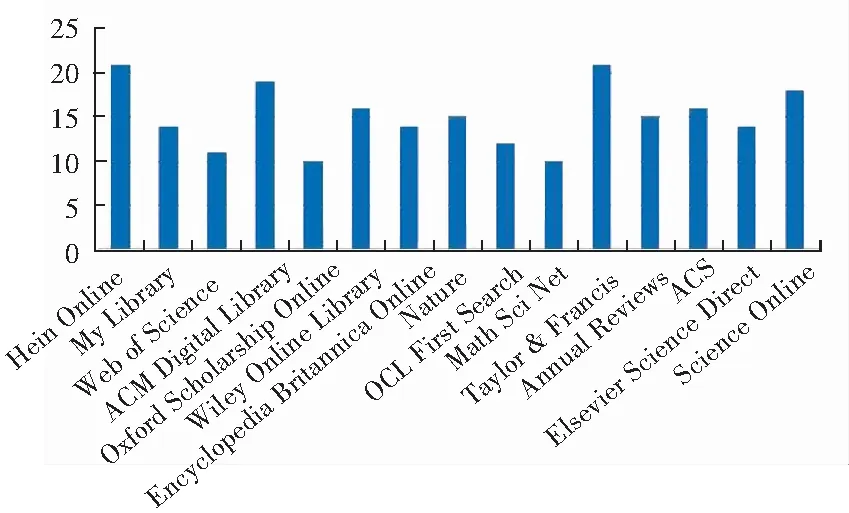
圖4 外文數據庫使用情況Fig. 4 Foreign language database usage
由圖4結果可以看出,外文數據庫主要以自然科學為主,人文科學為輔,并且是以高水平的期刊和圖書為主,各高校比較注重數學、計算機、化學、生物等學科的建設和發展。
4 應用
通過本文的研究技術對國內30所重點高校圖書館數據的分析,最終得到了有利于圖書館資源建設的很多數據,可以將這些技術更好地應用于以下工作中。
4.1 依托優勢學科,提高學科服務能力
高校圖書館擁有豐富的數字資源和較為穩定的高素質用戶群。通過了解一家學校的重點學科并對其數字資源建設數據展開實時跟蹤,及對用戶使用行為進行統計,可以分析得到該校的重點學科的研究發展態勢,進而總結提煉為學科發展規律,可以利于有的放矢地制定學科資源建設和發展策略規劃,并對重點學科提供高質量的服務[12]。
4.2 搭建高校聯合采購方案的橋梁
通過電子資源建設的相關數據來探尋各個高校學科發展態勢,分析院校之間使用電子資源的相似性,有助于高校之間學科聯合,為高校未來館際間的進一步資源整合和聯合采購提供了有效的基礎依據。
4.3 促進館際互借與文獻傳遞
通過數據分析,以了解各個高校電子資源的建設情況,這樣就可以得到各高校圖書館資源的來源和渠道,有助于館際互借及文獻傳遞業務的順利開展。
4.4 評估數字資源利用價值
通過采集提取各高校圖書館數據資源信息,可以對研究選擇的高校圖書館的已訂購的數字資源的瀏覽量、下載量等數據進行調查分析,為其它院校選購電子資源發揮有益的參考與借鑒作用。
5 結束語
到目前為止,國內圖書館建設已經步入正軌,數據挖掘與分析技術也陸續涌現,并取得了長足進步。在以后的工作中,可以擴大數據采集的范圍,同時設計優化文本相似度分析算法,得到更加準確的數字資源分析結果,再將其應用于其它數據分析工作中,旨在為大數據環境下數字資源的建設與分析研究提供更多的可行性分析方法及途徑。
[1] 王飛. 基于數據挖掘的高校圖書館個性化推薦服務的應用研究[D]. 呼和浩特: 內蒙古工業大學,2015.
[2] 曾路平. 基于相似度的文本聚類算法研究及應用[D]. 鎮江: 江蘇大學,2009.
[3] 許君寧. 基于知網語義相似度的中文文本聚類方法研究[D]. 西安:西安電子科技大學,2010.
[4] 梁茹,李建霞,劉穎,等. 高校圖書館數字資源綜合服務能力評價[J]. 金融大學圖書館學報,2015(2): 38-46.
[5] 蔣巖波, 陳香珠. 國內高等財經院校圖書館數字資源建設問題研究—基于國內45所財經院校圖書館的調查分析[J]. 圖書情報工作,2015,59(8): 65-71.
[6] 何建新. 大數據時代高校圖書館的數字資源共享策略探討[J]. 現代情報,2014,34(9): 101-104,110.
[7] 李賀,袁翠敏,李亞峰. 基于文獻計量的大數據研究綜述[J]. 情報科學,2014,32(6): 148-155.
[8] WANG Gang,ZHONG Guoxiang. Study on text clustering algorithm based on similarity measurement of ontology [J].Computer Science,2010,37(9): 222-224,228.
[9] 陳大慶,葉蘭,楊巍,等. 電子資源使用統計平臺USSER的設計與實現 [J]. 圖書情報工作,2015,59(1):106-112.
[10]周婕. 高校圖書館電子資源建設實踐與研究 [J]. 情報理論與實踐,2006,29(6):715-718.
[11]陳妙鳳. 試論大數據時代高校圖書館電子資源特色化服務[J]. 才智,2017(5):101.
[12]常定姁. 基于微信的高校圖書館電子資源推廣調查與分析—以“985”高校圖書館為例[J]. 圖書館學研究, 2017(16): 69-77.
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
資源再生(2017年3期)2017-06-01 12:20:59
財經(2017年2期)2017-03-10 14:35:35
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
