基于Minibatch-kMeans和XGBoost算法的大型場所WLAN室內定位的方法
2018-02-14 12:49:08李斌張金煥封靖川
數字技術與應用 2018年10期
李斌 張金煥 封靖川


摘要:基于RSS的WLAN指紋定位算法,針對大型場所的室內定位數據維數高,計算量大,定位精度不高的問題,本文提出一種基于先聚類再分類的方法.本文用Minibatch-kMeans先聚類分區定位,然后采用XGBoost分類算法在子區域精確定位,解決了大型場所室內定位數據維數高,運算速度慢的問題,并提高了定位的精度。本文提出的算法具有很大的應用價值和應用前景。
關鍵詞:WLAN室內定位; Minibatch-kMeans;XGBoost;數據降維
中圖分類號:TP212? ? 文獻標識碼:A? 文章編號:1007-9416(2018)10-0000-00
越來越多的移動互聯網應用希望可以獲得用戶的位置信息來對用戶提供更智能更精確的服務,目前相當成熟的GPS技術僅僅限于用于室外。基于802.1lb/g/n協議的無線局域網被廣泛部署于全世界不用環境,如商場、寫字樓、機場大廳等,幾乎覆蓋了絕大多數人類活動的室內環境。因此基于WiFi信號的室內定位成為目前十分熱門和前景廣闊的研究方向。目前基于WiFi信號的定位定位方法中,大致可以分為幾何測距法和位置指紋法。由于位置指紋法無需提前獲取無線WiFi接入點的位置和定位精度高,因此成為目前更熱門的定位方法。
但是在實際應用過程中,特別是針對于大型場所,位置指紋法仍然存在如下兩個挑戰:
(1)需要參考的AP(無線WiFi接入點)越來越多,如某大型商場可以檢測到10000個AP,因此位置指紋庫數據維數高,導致計算和存儲開銷十分巨大。
(2)如何研發出性能更好的匹配算法,取得更高的定位準確率。因此,為了解決這兩個挑戰,本文提出一種基于結合MiniBatch-kMeans聚類和XGBoost分類算法的定位算法。
1 國內外研究現狀
常用的指紋定位匹配算法有神經網絡法、KNN法,加權K近鄰法等。這些算法都是基于RSS進行指紋的匹配或映射得到最終的定位位置。
1.1 KNN(K 鄰近法)算法
在KNN相似度匹配時,選取歐式距離最小的前K個點,將K個點的幾何質心作為定位位置的估計。2000年微軟研究院P.Bahl等人提出RADAR定位系統就是應用的KNN算法。
1.2 WKNN算法
WKNN法是KNN法的進一步改進,與KNN匹配算法相比.最大的不同在于選擇出歐式距離最小的前K個點后,按照每個參考點對定位點的貢獻程度,給每個參考點一個權值,最后將K個點加權質心作為定位的估計位置。
1.3 深度學習法
深度學習的概念源于人工神經網絡的研究。含多隱層的多層感知器就是一種深度學習結構。深度學習通過組合低層特征形成更加抽象的高層表示屬性類別或特征,以發現數據的分布式特征表示。Gibran Felix等人應用深度學習的方法來處理復雜環境中室內定位的問題, 提高了算法的泛化能力,得到了較高的準確率。
2方法
2.1 MiniBatch-kMeans先聚類分區
本文采用Mini-BatchKMeans聚類算法法來對數據進行分區降維處理。我們發現很多大型場所內的一定區域范圍內,只需部分AP即可實現定位,大部分AP在該區域內獲取不到RSS信息,所以我們可以先對大型場所進行分區,剔除對該區域無用的AP,從而達到降維的效果。本文采用Mini-BatchKMeans的方法進行自動聚類分區。
算法在兩個主要步驟之間迭代。第一步,從數據集中隨機抽取b個樣本,形成一個小批量,然后將這些分配給最近的質心。在第二步中,質心被更新。與K-Means相反,這是在每個樣本的基礎上完成的。對于小批量中的每個樣品,指定的質心通過將樣品的流動平均值和先前分配給該質心的所有樣品進行更新。這具有降低質心隨時間變化的速率的效果。執行這些步驟直到達到收斂或預定次數的迭代。
2.2 XGBoost再分類
完成了聚類算法區域劃分后,就可以對于每個子區域用分類方法進行訓練。運用XGBoost作為我們的分類器。XGBoost是一個端到端的可擴展算法系統,XGBoost就是基于GDBT,并對GDBT做了如下改進:(1)損失函數從平方損失推廣到二階可導的損失。GDBT擬合殘差可以逼近到真值,是因為使用了平方損失作為損失函數。XGBoost的方法是,將損失函數做泰勒展開到第二階,使用前兩階作為改進的殘差。(2)加入了正則化項在決策樹中,模型復雜度體現在樹的深度上。XGBoost使用了一種替代指標,即葉子節點的個數來表示模型的復雜度。并通過正則化來限制模型的復雜度。(3)支持列抽樣。列抽樣是指,訓練每棵樹時,是從特征抽取一部分來訓練這棵樹,而不是使用所有特征。
XGBoost分類過程如下:步驟1:導入RSS訓練數據進行訓練,根據訓練數據的特點,設置模型初始參數設置如:迭代數次、樹的最大深度、損失函數等。步驟2:用訓練數據訓練好的 XGBoost 模型,導入測試集,計算出測試集的結果。步驟3:統計測試集數據預測結果,若預測結果不理想,對XGBoost參數調整,重復1步,第2步,直到達到一定的預測準確率。
2.3 定位階段算法
XGBoost模型訓練好后,就對數據進行預測運算,先進行聚類分區預測,得到分區后,在該區域內做XGBoost再分類預測,最終得到預測結果,定位預測階段的算法流程如下:
輸入:RSS指紋庫 ?? = {??1,??2,...,????,...,????},測試集RSS信息T = {??1,??2,...,????,...,??w}。
輸出:測試集預測結果
(1)For k=mink->maxk do? ?#枚舉區域個數;
(2)MiniBatchKmeans(聚類個數=K,訓練集T) #聚類訓練;
(3)為每個區域建立RSS指紋庫;
(4)MiniBatchKmeans .Predict(T)? #聚類預測每條測試集所屬區域;
(5)XGboost.predict(Ti)#預測測試集位置結果;
(6)統計準確率,比較每次的預測率,特征維數,運算時間找到最佳K的取值。
2.4 定位技術總流程
綜上所述,本文室內方法分為離線訓練階段和在線定位階段,定位技術與方法的總流程如圖1所示。
3實驗與評價
3.1實驗環境和數據
本實驗的數據集來源是來自阿里天池大數據平臺,數據集采集了兩個月20多個商場,平均每個商場近90個商鋪的RSS指紋數據,實驗選取4個商場的數據進行實驗。
3.2 數據預處理
(1)去除無用AP:由于數據集存在大量的移動熱點,我們通過篩選出現頻率大于5次并且出現天數大于一天的AP作為我們參考的AP。(2)歸一化處理:由于收集到的RSS數據分布在[-110,0]之間,不利于聚類和分類算法的收斂,我們對WiFi信號數據進行歸一化處理。
3.3 實驗結果比較評估
我們對不分區和分區方法在特征維數、定位準確率、運行時間三方面進行比較,如表1。
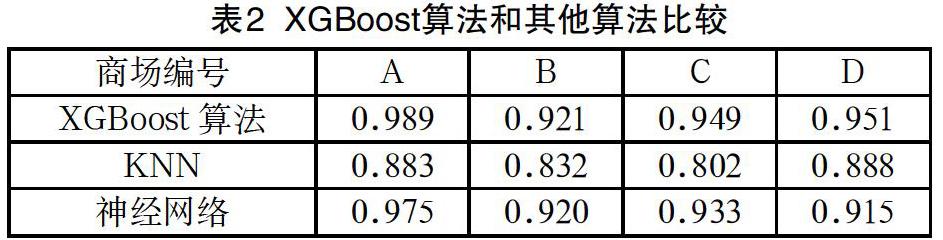
我們發現分區算法在很大程度上降低了數據維數,縮短了運行的時間,并且仍然能保持較高的準確率。將分類算法和KNN、神經網絡算法進行比較,如表2所示我們發現我們的算法準確率都在其他算法之上。
4結語
本文針對基于RSS的WLAN室內定位在大型場所中的問題與挑戰,提出了先聚類分區再分類定位的方法,在分區階段使用Minibatch-kMeans聚類算法對數據進行了有效的降維,節省了約90%的運算時間;在分類定位階段首次使用XGBoost算法進行計算,并和KNN、神經網絡算法進行比較,XGBoost算法在準確率上有更優的表現。
參考文獻
[1]席瑞,李玉軍,侯孟書.室內定位方法綜述[J].計算機科學,2016,43(4):1-6+32.
[2]銳,鐘榜,朱祖禮,馬樂,姚金飛.室內定位技術及應用綜述[J].電子科技,2014,27(03):154-157.
[3]Chen T, He T, Benesty M. Xgboost: extreme gradient boosting[J]. R package version 0.4-2,2015: 1-4.
WLAN Indoor Localization Method with Minibatch-KMeans and XGBoost
LI Bin,ZHANG Jin-huan,FENH Jing-chuan
(Central South University, Changsha Hunan? 410000)
Abstract:Based on the WLAN fingerprint localization algorithm , this paper proposes a method based on pre-cluster classification algorithm , which is implemented by Minibatch-KMeans clustering and XGBoost classification algorithm. It solve the problem of large-scale data dimension ,problem of slow operation speed and improved positioning accuracy. The algorithm proposed in this paper has great application value and prospects.
Key words:WLAN fingerprint localization;Minibatch-KMeans;XGBoost;Dimensionality reduction
